基于AWS-ELK部署系统日志告警系统
前言
运维故障排障速度往往与监控系统体系颗粒度成正比,监控到位才能快速排障
在部署这套系统之前,平台所有系统日志都由Graylog+Zabbix,针对日志出现的错误关键字进行告警,这种做法在运维工作开展过程中暴露出多个不足点,不详述;在考虑多方面原因后,最终对日志告警系统进行更换,选用的方案是:ELK + Kafka+ Filebeat + Elastalert
本文主要以两个需求为主轴做介绍
- 非工作时间服务器异常登录告警
- 系统日志出现错误关键字告警
架构

服务选型
| name | version | info |
|---|---|---|
| Amazon Elasticsearch Service | v6.2 | AWK官网部署教程 |
| Logstash | v6.2.3 | 选用与ES相同版本 |
| Filebeat | v6.2.3 | 选用与ES相同版本 |
| Confluent(Kafka) | v4.0 | 这里推荐 Confluent 的版本,Confluent 是 kafka 作者 Neha Narkhede 从 Linkedin 出来之后联合 LinkedIn 前员工创建的大数据公司,专注于 kafka 的企业应用。 |
| Elastalert | v0.1.29 | 原先考虑采用X-Pack但由于AWS目前还不支持 |
部署
本文采用的操作系统 :CentOS release 6.6
Filebeat
# 下载源
$ curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.3-x86_64.rpm# 安装
$ sudo rpm -vi filebeat-6.2.3-x86_64.rpmLogstash
# 导入Yum源
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
$ cat <<EOF > /etc/yum.repos.d/logstash.repo
[logstash-6.x]
name=Elastic repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF# 安装
yum install logstash -yElastalert
# pip直接安装
$ pip install elastalert# 如果出现依赖包报错,以下为常用开发所需依赖包
$ yum install -y zlib openssl openssl-devel gcc gcc-c++ Xvfb libXfont Xorg libffi libffi-devel python-cffi python-devel libxslt-devel libxml2-devel zlib-devel bzip2-devel xz-libs wget配置
Filebeat
/etc/filebeat/filebeat.yml
filebeat.config:prospectors:path: /etc/filebeat/conf/*.ymlreload.enabled: truereload.period: 10soutput.kafka:# kafkaNode为Kafaka服务所在服务器 hosts: ["kafkaNode:9092"]# 索引取fields.out_topictopic: "%{[fields][out_topic]}"partition.round_robin:reachable_only: false
/etc/filebeat/conf/base.yml
# 收集系统日志
- type: logpaths: - /var/log/messages- /var/log/syslog*exclude_files: [".gz$"]exclude_lines: ["ssh_host_dsa_key"]tags: ["system_log"]scan_frequency: 1sfields:# 新增字段用于辨别来源客户端server_name: client01# 索引out_topic: "system_log"multiline:pattern: "^\\s"match: after# 收集登录日志
- type: logpaths:- /var/log/secure*- /var/log/auth.log*tags: ["system_secure"]exclude_files: [".gz$"]scan_frequency: 1sfields:server_name: client01out_topic: "system_secure"multiline:pattern: "^\\s"match: afterLogstash
/etc/logstash/conf.d/system_log.conf
input {kafka {bootstrap_servers => "kafkaNode:9092"consumer_threads => 3topics => ["system_log"]auto_offset_reset => "latest"codec => "json"}
}filter {# 排除logstash日志if [source] == "/var/log/logstash-stdout.log" {drop {}}if [fields][out_topic] == "system_log" {date {match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]}grok {match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] }pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" }remove_field => "message"}}
}output {elasticsearch {hosts => ["<亚马逊ES地址>"]index => "%{[fields][out_topic]}_%{+YYYYMMdd}"document_type => "%{[@metadata][type]}"}
}
/etc/logstash/conf.d/secure_log.conf
input {kafka {bootstrap_servers => "kafkaNode:9092"consumer_threads => 3topics => ["system_secure"]auto_offset_reset => "latest"codec => "json"}
}filter {if [fields][out_topic] == "system_secure" {grok {match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?","%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}","%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}","%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}","%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}","%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$","%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] }pattern_definitions => {"GREEDYMULTILINE"=> "(.|\n)*"}remove_field => "message"}}
}output {elasticsearch {hosts => ["<亚马逊ES地址>"]index => "%{[fields][out_topic]}_%{+YYYYMMdd}"document_type => "%{[@metadata][type]}"}
}
Kafka
# 导入
rpm --import https://packages.confluent.io/rpm/4.0/archive.keycat <<EOF > /etc/yum.repos.d/confluent.repo
[Confluent.dist]
name=Confluent repository (dist)
baseurl=https://packages.confluent.io/rpm/4.0/6
gpgcheck=1
gpgkey=https://packages.confluent.io/rpm/4.0/archive.key
enabled=1[Confluent]
name=Confluent repository
baseurl=https://packages.confluent.io/rpm/4.0
gpgcheck=1
gpgkey=https://packages.confluent.io/rpm/4.0/archive.key
enabled=1
EOFyum install confluent-platform-oss-2.11Elastalert
Elastalert可以部署到任何一台能够读取到ES的服务器上;配置文件中
modules.eagle_post.EagleAlerterblacklist_v2经过修改,后面会介绍到
rules/system_log.yaml
es_host: <亚马逊ES地址>
es_port: 80
name: system log rule
type: blacklist_v2
index: system_log*
timeframe:minutes: 1# 监控key
compare_key: system.syslog.message# 出现下面任意关键字将告警,按需添加
blacklist_v2:- "ERROR"- "error"alert: "modules.eagle_post.EagleAlerter"
eagle_post_url: "<eagle>"
eagle_post_all_values: False
eagle_post_payload:server: "fields.server_name"info: "system.syslog.message"source: "source"rules/system_log.yaml
es_host: <亚马逊ES地址>
es_port: 80
name: system secure rule
type: frequency
index: system_secure*
num_events: 1
timeframe:minutes: 1
filter:
- query:wildcard:system.auth.user : "*"
alert: "modules.eagle_post.EagleAlerter"
eagle_post_url: "<eagle>"
eagle_post_all_values: False# 非工作时间
eagle_time_start: "09:00"
eagle_time_end: "18:00"
eagle_post_payload:user: "system.auth.user"server: "fields.server_name"ip: "system.auth.ssh.ip"event: "system.auth.ssh.event"
Elastalert
自定义type与alert
为了能够将告警接入到Eagle(自研统一接口平台)在尝试使用http_post做告警类型过程中,发现无法传入ES结果作为POST参数,所以对其进行简单修改,新增类型,实现能够无缝接入Eagle
Alert
moudules/eagle_post.py
将文件夹保存到
site-packages/elastalert
import json
import requests
import dateutil.parser
import datetime
from elastalert.alerts import Alerter
from elastalert.util import EAException
from elastalert.util import elastalert_logger
from elastalert.util import lookup_es_keyclass EagleAlerter(Alerter):def __init__(self, rule):super(EagleAlerter, self).__init__(rule)# 设定时间有效范围self.post_time_start = self.rule.get('eagle_time_start','00:00')self.post_time_end = self.rule.get('eagle_time_end','00:00')# post链接self.post_url = self.rule.get('eagle_post_url','')self.post_payload = self.rule.get('eagle_post_payload', {})self.post_static_payload = self.rule.get('eagle_post_static_payload', {})self.post_all_values = self.rule.get('eagle_post_all_values', False)self.post_lock = Falsedef alert(self, matches):if not self.post_url:elastalert_logger.info('Please input eagle url!')return Falsefor match in matches:# 获取所有payloadpayload = match if self.post_all_values else {}# 构建字典for post_key, es_key in self.post_payload.items():payload[post_key] = lookup_es_key(match, es_key)# 获取当前时间login_time = datetime.datetime.now().time()# 获取时间限制time_start = dateutil.parser.parse(self.post_time_start).time()time_end = dateutil.parser.parse(self.post_time_end).time()# 如果在时间范围内,将不做告警self.post_lock = False if login_time > time_start and \login_time < time_end else True# 合并两种类型payloaddata = self.post_static_payloaddata.update(payload)# 发送告警if self.post_lock:myRequests = requests.Session()myRequests.post(url=self.post_url,data=data,verify=False)elastalert_logger.info("[-] eagle alert sent.")else:elastalert_logger.info("[*] nothing to do.")def get_info(self):return {'type': 'http_post'}type
在使用blaklist过程发现改类型是全匹配,为了方便编写配置文件,所以对其做了简单修改
elastalert/ruletypes.py
# 新增class BlacklistV2Rule(CompareRule):required_options = frozenset(['compare_key', 'blacklist_v2'])def __init__(self, rules, args=None):super(BlacklistV2Rule, self).__init__(rules, args=None)self.expand_entries('blacklist_v2')def compare(self, event):term = lookup_es_key(event, self.rules['compare_key'])# 循环配置文件, 这种做法对性能有一定的损耗,在没找到更合适的解决方案前,就采取这种方式for i in self.rules['blacklist_v2']:if i in term:return True return Falseelastalert/config.py
# 新增
rules_mapping = {'frequency': ruletypes.FrequencyRule,'any': ruletypes.AnyRule,'spike': ruletypes.SpikeRule,'blacklist': ruletypes.BlacklistRule,'blacklist_v2': ruletypes.BlacklistV2Rule,'whitelist': ruletypes.WhitelistRule,'change': ruletypes.ChangeRule,'flatline': ruletypes.FlatlineRule,'new_term': ruletypes.NewTermsRule,'cardinality': ruletypes.CardinalityRule,'metric_aggregation': ruletypes.MetricAggregationRule,'percentage_match': ruletypes.PercentageMatchRule,
}
elastalert/schema.yaml
# 新增- title: BlacklistV2required: [blacklist_v2, compare_key]properties:type: {enum: [blacklist_v2]}compare_key: {'items': {'type': 'string'},'type': ['string', 'array']}blacklist: {type: array, items: {type: string}}
打进Docker
做了个简单DockerFile做参考
FROM python:2.7-alpine
ENV SITE_PACKAGES /usr/local/lib/python2.7/site-packages/elastalert
WORKDIR /opt/elastalertRUN apk update && apk add gcc ca-certificates openssl-dev openssl libffi-dev gcc musl-dev tzdata openntpd && \ pip install elastalert && cp -rf /usr/share/zoneinfo/Asia/Taipei /etc/localtime
COPY ./ /opt/elastalert
CMD ["/opt/elastalert/start.sh"]start.sh
#!/bin/sh
SITE_PATH=/usr/local/lib/python2.7/site-packages/elastalert
CONFIG=/opt/elastalert/config/config.yaml
MODULES=/opt/elastalert/modulesif [ -n "${MODULES}" ]
then\cp -rf ${MODULES} ${SITE_PATH}echo "[-] Copy ${MODULES} to ${SITE_PATH}"
fi\cp -rf elastalert/* ${SITE_PATH}/
echo "[-] Copy elastalert/* to ${SITE_PATH}"
python -m elastalert.elastalert --verbose --config ${CONFIG}基础工作准备就绪,加入Bee容器管理平台完成自动构建。
实现效果

碰到的坑
Zookeeper
问题描述
老版
Kafaka依赖Zookeeper,默认安装时注册地址为:localhost,导致问题的现象:
filebeat错误日志
2018-04-25T09:14:55.590+0800 INFO kafka/log.go:36 client/metadata fetching metadata for [[[system_log] kafkaNode:9092]] from broker %!s(MISSING)2018-04-25T09:14:55.591+0800 INFO kafka/log.go:36 producer/broker/[[0]] starting up2018-04-25T09:14:55.591+0800 INFO kafka/log.go:36 producer/broker/[[0 %!d(string=system_log) 0]] state change to [open] on %!s(MISSING)/%!d(MISSING)2018-04-25T09:14:55.591+0800 INFO kafka/log.go:36 producer/leader/[[system_log %!s(int32=0) %!s(int32=0)]]/%!d(MISSING) selected broker %!d(MISSING)2018-04-25T09:14:55.591+0800 INFO kafka/log.go:36 producer/leader/[[system_secure %!s(int32=0) %!s(int=3)]]/%!d(MISSING) state change to [retrying-%!d(MISSING)]2018-04-25T09:14:55.591+0800 INFO kafka/log.go:36 producer/leader/[[system_secure %!s(int32=0) %!s(int32=0)]]/%!d(MISSING) abandoning broker %!d(MISSING)2018-04-25T09:14:55.592+0800 INFO kafka/log.go:36 producer/broker/[[0]] shut down2018-04-25T09:14:55.592+0800 INFO kafka/log.go:36 Failed to connect to broker [[localhost:9092 dial tcp [::1]:9092: getsockopt: connection refused]]: %!s(MISSING)
日志出现两个地址,一个是kafka地址,另外出现一个localhost地址。
这是因为filebeat已经跟kafaka建立了连接,但是从kafaka到zookeeper这一段找不到
解决方法
# get /brokers/ids/0
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://localhost:9092"],"jmx_port":-1,"host":"localhost","timestamp":"1523429158364","port":9092,"version":4}
cZxid = 0x1d
ctime = Wed Apr 11 14:45:58 CST 2018
mZxid = 0x1d
mtime = Wed Apr 11 14:45:58 CST 2018
pZxid = 0x1d
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x162b374170d0000
dataLength = 188
numChildren = 0# 发现注册地址是localhost,修改之
set /brokers/ids/0 {"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://kafkaNode:9092"],"jmx_port":9999,"host":"kafkaNode","timestamp":"1523429158364","port":9092,"version":4}修改完重启,问题解决。
博文链接:http://a-cat.cn/2018/04/29/aws-elk/
转载于:https://blog.51cto.com/maoyao/2109147
相关文章:

《周志华机器学习详细公式推导版》发布,Datawhale开源项目pumpkin-book
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑来源 | Datawhale(ID:Datawhale) 如果让你推荐两本国内机器学习的入门经典作,你会推荐哪些呢?相信大家同我一样ÿ…

JVM内存泄漏检测与处理
JVM内存泄漏检测与处理(JVM Memory Leak detection and handling) JVM垃圾回收机制的原则和方法 JVM垃圾回收中一个基本原则是对象没有被引用或则引用其它对象,换句话说当一个对象在heap 中是隔离(isolation)状态的时候,垃圾回收器…
【Dlib】dlib和opencv的互转
一、dlib::matrix转换成cv::Mat 1、注意事项: 1)将dlib::matrix转成BGR格式后,再转换成cv::Mat,因为cv::Mat中是按照BGR顺序存储 2)注意最后添加的cv::Mat::clone()函数,因为dlib::toMat(tmp)返回的mat数…
原创 人物志|山东省临沭县 - 一位身残志坚的奋斗青年 - 吴忠军
原创 人物志|山东省临沭县 - 一位身残志坚的奋斗青年 - 吴忠军 02972018-04-29 16:15:27 人物志|山东省临沭县 - 一位身残志坚的奋斗青年 - 吴忠军 齐鲁晚报 2018年04月29日 2018年4月29日,山东省临沂市临沭县,一位年轻的小伙子。吴忠军,山东…
百度SLG拿下前锤子科技CTO钱晨,还要合并小鱼在家? | 极客头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑整理 | 一一出品 | AI科技大本营(id:rgznai100)2016 年 7 月,锤子科技前 CTO 钱晨从该公司退休的消息被证实,关于其离职的…

【Dlib】dlib实现深度网络学习之 input层
1、 dlib::input 模板类,深度神经网络的简单输入层,它将某种图像作为输入并将其加载到网络中。 这是一个基本的输入层,它只是简单地将图像复制到一个张量中。 注意:dlib::input只支持输入dlib::matrix和dlib::array2d类型&#x…
首发 | 13篇京东CVPR 2019论文!你值得一读~ 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑编者按:计算机视觉和模式识别大会 CVPR(Conference on Computer Vision and Pattern Recognition)作为人工智能领域计算机视觉方向的重要学术会议…
Windows 活动目录(AD)服务器系统升级到2012之活动目录角色迁移(三)
4.5迁移服务器角色到AD20121. 打开powershell,使用命令迁移服务器角色到AD2008输入命令Ntdsutil输入命令Roles输入命令Connections输入命令Connect to server AD2012,连接AD2012控制器输入命令QUIT输入Transfer infrastructure master命令,转…

《星际争霸2》引擎技术解析
就在SIGGRAPH大会刚结束之后,AMD和暴雪在AMD官方网站上放出了《星际争霸II》的官方技术文档,通过游戏引擎技术的展示让星际迷们感受到越来越多的惊喜。画面优化给CPU带来考验着色方面,在使用原型的基础上利用3D Studio MAX让程序员对整体效果…
回顾与展望:大热的AutoML究竟是什么? | 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑来源 | 第四范式编者按:AutoML(Automatic Machine Learning,自动机器学习)旨在研究在没有专业知识的情况下使用的低门槛甚至零门槛的…
【Python】深度学习中将数据按比例随机分成随机 训练集 和 测试集的python脚本
深度学习中经常将数据分成 训练集 和 测试集,参考博客,修改python脚本 randPickAITrainTestData.py 。 功能:从 输入目录 中随机检出一定比例的文件或目录,移动到保存 测试集目录 中,原输入目录作为训练目录。 import…
docker 系列之 配置阿里云镜像加速器
1.登录阿里云 2.登录后找到右上角的“管理中心”,点击进入后》点击“镜像加速器”;剩下的安装文档配置就好 问题1:配置完后还是提示:Tag latest not found in repository 【本人也是在这里被困了好久,尝试了各种方法】 解决方案:最后发现这里…
LVM-HOWTO/学习笔记(二)
1. 在3块scsi磁盘上创建lv Run pvcreate on the disks # pvcreate /dev/sda # pvcreate /dev/sdb # pvcreate /dev/sdc Create a volume group # vgcreate my_volume_group /dev/sda /dev/sdb /dev/sdc/ Run vgdisplay to verify volume group # vgdisplay # vgdisplay…
【python】使用python脚本将LFW数据中1672组同一个人多张照片拷贝出来
使用python脚本将LFW数据中1672组同一个人多张照片拷贝出来 dataCleaning4multiple.py 源码如下: import os, random, shutil import sys, getopt import stringdef getDir(argv):inPath outPath num2try:opts, args getopt.getopt(argv,"hi:o:n:",[&…
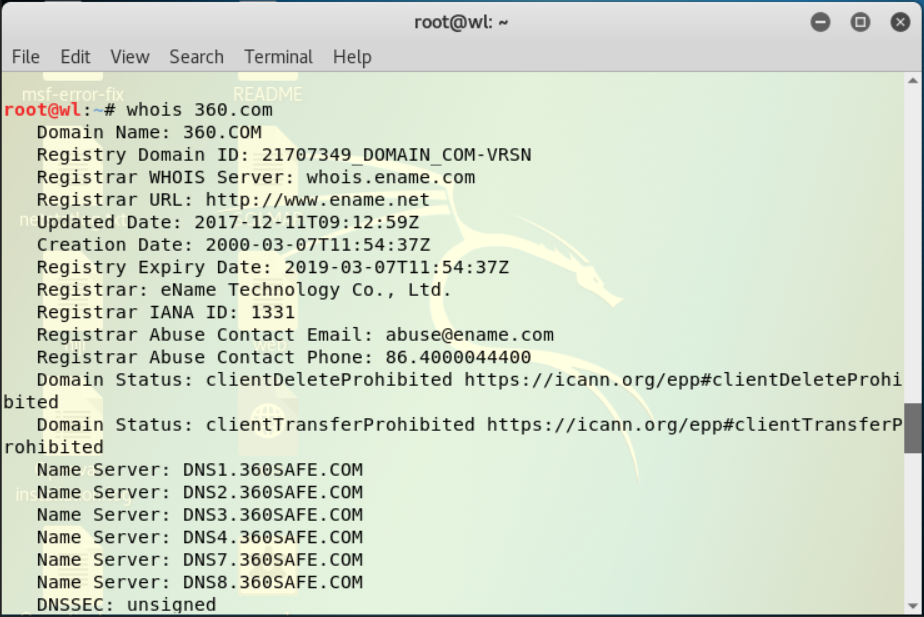
EXP6 信息搜集与漏洞扫描
1.实验有关问题 (1)哪些组织负责DNS,IP的管理。 ICANN是一个集合了全球网络界商业、技术及学术各领域专家的非营利性国际组织,负责在全球范围内对互联网唯一标识符系统及其安全稳定的运营进行协调,它能决定域名和IP地址…

百度发的208亿春晚红包,靠这样的技术送到了你手上 | 解读
2019 年的春晚红包项目对百度而言是一次大考,背后需要强大的技术来支撑。如你所见,百度不负“技术大厂”的标签,春晚红包期间系统稳定运行,没有出现宕机事故。在这样一个庞大而复杂的项目面前,他们是如何去用技术去化解…
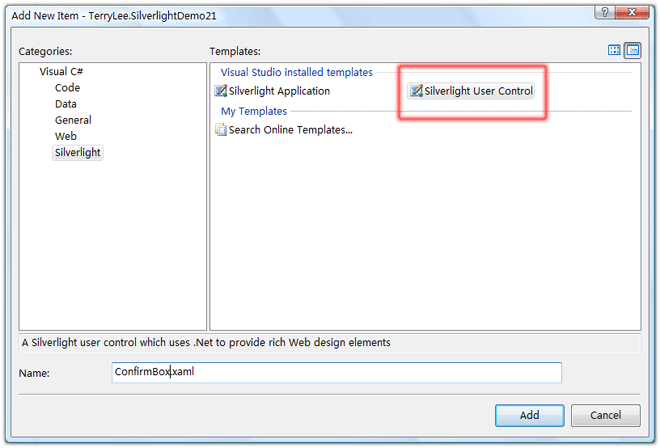
一步一步学Silverlight 2系列(10):使用用户控件
概述 Silverlight 2 Beta 1版本发布了,无论从Runtime还是Tools都给我们带来了很多的惊喜,如支持框架语言Visual Basic, Visual C#, IronRuby, Ironpython,对JSON、Web Service、WCF以及Sockets的支持等一系列新的特性。《一步一步学Silverlig…
何恺明的GN之后,权重标准化新方法能超越GN、BN吗? | 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑作者 | Siyuan Qiao、Huiyu Wang、Chenxi Liu、Wei Shen、Alan Yuille(Johns Hopkins University,约翰霍普金斯大学)译者 | 刘畅编辑 | Jane出品 | AI科…
【AI】CelebA数据介绍、下载及说明
1、简介 CeleA是香港中文大学的开放数据,包含10177个名人的202599张图片 官网:http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html 下载地址(百度网盘,官方的):http://pan.baidu.com/s/1eSNpdRG 【python】…

Zend Framework Mail通过网易免费邮箱发送邮件
2019独角兽企业重金招聘Python工程师标准>>> 做为一个苦逼的个人站长,做一个小网站,本来愿意来看的人就不多,再弄一个不能找回密码的会员系统?基本上被判死刑了 。阿里云的短信也要钱啊,而且只支持PHP 5.5以…
将shp导入SDE中出现“表或视图不存在”问题
其原因是权限不够,下边代码可以用来检查权限是否够。 private void ESRILicense() { IAoInitialize mAoInitialize new AoInitializeClass(); esriLicenseStatus licenseStatus (esriLicenseStatus)mAoInitialize.IsProductCodeAvai…
【python】使用python脚本将CelebA中同一人的图片捡到对应单独的文件夹中
1、目的 CelebA的所有的照片都在一个文件夹中,为了能在dlib训练人脸识别时,方便使用,将CelebA中同一人的图片捡到对应单独的文件夹中。 【AI】CelebA数据介绍、下载及说明 2、方法 首先创建10178个目录,然后解析Anno/identity_…
仅用语音,AI就能“脑补”你的脸! | 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑作者 | Wav2pix 研究团队译者 | 刘畅编辑 | Jane出品 | AI科技大本营(公众号id:rgznai100)【导语】之前我们为大家介绍过一项非常酸爽的研究“Talking…

如何在SAP云平台上使用MongoDB服务
首先按照我这篇文章在SAP云平台上给您的账号分配MongboDB服务:如何在SAP云平台的Cloud Foundry环境下添加新的Service 然后从这个链接下载SAP提供的例子程序。 1. 使用命令行 cf marketplace查看当前SAP云平台的MongoDB的版本号:在我使用的SAP云平台上是…
C#中将dll汇入exe,并加壳
< DOCTYPE html PUBLIC -WCDTD XHTML StrictEN httpwwwworgTRxhtmlDTDxhtml-strictdtd> 1、合并file1.dll、file2.dll到destination.dll ILmerge /ndebug /target:dll /out:C:\destination.dll /log C:\file1.dll C:\file2.dll 2、合并file1.dll、file2.dll以及myApp.exe…

【AI】dlib中图像标注工具 imglab 详细说明
一、基本用法 imglab是一个在图像上标注矩形的工具。基本方法 1> 获取图片列表:./imglab -c mydataset.xml /tmp/images,/tmp/images为保存图像的文件夹 2> 标注每个图片:./imglab mydataset.xml,使用shift鼠标左键拖动来选…

最萌算法学习来啦,看不懂才怪!| 码书
普通程序员,不学算法,也可以成为大神吗?对不起,这个,绝对不可以。可是算法好难啊~~看两页书就想睡觉……所以就不学了吗?就一直当普通程序员吗?如果有一本算法书,看着很轻松……又有…
Redis 缓存设计原则
基本原则 只应将热数据放到缓存中 所有缓存信息都应设置过期时间 缓存过期时间应当分散以避免集中过期 缓存key应具备可读性 应避免不同业务出现同名缓存key 可对key进行适当的缩写以节省内存空间 选择合适的数据结构 确保写入缓存中的数据是完整且正确的 避免使用耗时…
最强大,最简洁的【禁止输入中文】
方法一:禁止中文输入法 <input type"text" style"ime-mode:disabled">方法二:禁止黏贴,禁止拖拽,禁止中文输入法!这种方法是最强的禁止 中文输入 <input type"text" οnpaste…
无监督机器学习中,最常见4类聚类算法总结 | 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑编译 | 安然、狄思云来源 | 读芯术(ID:AI_Discovery)在机器学习过程中,很多数据都具有特定值的目标变量,我们可以用它们来训练模…