无监督机器学习中,最常见4类聚类算法总结 | 技术头条
 点击上方↑↑↑蓝字关注我们~
点击上方↑↑↑蓝字关注我们~
「2019 Python开发者日」,购票请扫码咨询 ↑↑↑
编译 | 安然、狄思云
来源 | 读芯术(ID:AI_Discovery)
在机器学习过程中,很多数据都具有特定值的目标变量,我们可以用它们来训练模型。
但是,大多数情况下,在处理实际问题时,数据不会带有预定义标签,因此我们需要开发能够对这些数据进行正确分类的机器学习模型,通过发现这些特征中的一些共性,来预测新数据的类。
无监督学习分析过程
开发无监督学习模型需遵循的整个过程,总结如下:
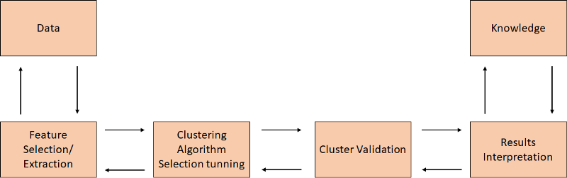
无监督学习的主要应用是:
按某些共享属性对数据集进行分段。
检测不适合任何组的异常。
通过聚合具有相似属性的变量来简化数据集。
总之,主要目标是研究数据的内在(和通常隐藏)的结构。
这种技术可以浓缩为无监督学习试图解决的两种主要类型的问题。如下所示:
聚类
维度降低
在本文中,我们将重点关注聚类问题。
聚类分析
在基本术语中,聚类的目的是在数据中的元素内找到不同的组。为此,聚类算法在数据中找到结构,以使相同聚类(或组)的元素彼此比来自不同聚类的元素更相似。
以可视方式想象一下,我们有一个电影数据集,并希望对它们进行分类。我们对电影有如下评论:
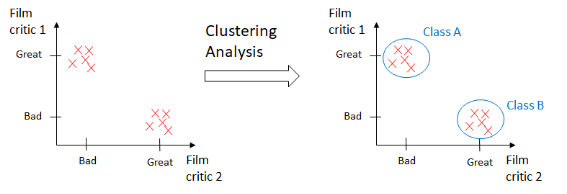
机器学习模型将能够在不知道数据的任何其他内容的情况下推断出两个不同的类。
这些无监督学习算法具有令人难以置信的广泛应用,并且对于解决诸如音乐、文档或电影分组之类的实际问题,以及基于其购买来找到具有共同兴趣的客户非常有用。
下面是一些最常见的聚类算法:
K均值聚类
分层聚类
基于密度的扫描聚类(DBSCAN)
高斯聚类模型
K均值聚类
K均值算法非常容易实现,并且在计算上非常有效。这是它为何如此受欢迎的主要原因。但是,在非球形的群体中识别类别并不是很好。
关键概念
平方欧几里德距离(Squared Euclidean Distance)
K均值中最常用的距离是欧氏距离平方。m维空间中两点x和y之间的距离的示例是:
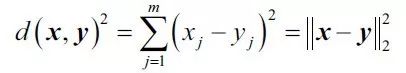
这里,j是采样点x和y的第j维(或特征列)。
集群惯性
集群惯性是聚类上下文中给出的平方误差之和的名称,表示如下:
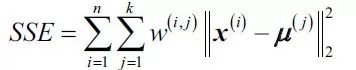
其中μ(j)是簇j的质心,并且如果样本x(i)在簇j中则w(i,j)是1,否则是0。
K均值可以理解为试图最小化群集惯性因子的算法。
算法步骤
1. 选择k值,即我们想要查找的聚类数量。
2. 算法将随机选择每个聚类的质心。
3. 将每个数据点分配给最近的质心(使用欧氏距离)。
4. 计算群集惯性。
5. 将计算新的质心作为属于上一步的质心的点的平均值。换句话说,通过计算数据点到每个簇中心的最小二次误差,将中心移向该点。
6. 返回第3步。
K-Means超参数
簇数:要生成的簇和质心数。
最大迭代次数:单次运行的算法。
数字首字母:算法将使用不同的质心种子运行的次数。根据惯性,最终结果将是连续运行定义的最佳输出。
K-Means的挑战
· 任何固定训练集的输出都不会始终相同,因为初始质心是随机设置的,会影响整个算法过程。
· 如前所述,由于欧几里德距离的性质,在处理采用非球形形状的聚类时,其不是一种合适的算法。
应用K均值时要考虑的要点
必须以相同的比例测量特征,因此可能需要执行z-score标准化或max-min缩放。
处理分类数据时,我们将使用get dummies功能。
探索性数据分析(EDA)非常有助于概述数据并确定K-Means是否为最合适的算法。
当存在大量列时,批训练(minibatch)的方法非常有用,但是不太准确。
如何选择正确的K值
选择正确数量的聚类是K-Means算法的关键点之一。要找到这个数字,有一些方法:
领域知识
商业决策
肘部法则
由于与数据科学的动机和性质相一致,肘部法则是首选方法,因为它依赖于支持数据的分析方法来做出决定。
肘部法则
肘部法则用于确定数据集中正确的簇数。它的工作原理是绘制K的上升值与使用该K时获得的总误差。
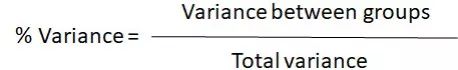
目标是找到每个群集不会显著上升方差的k。
在这种情况下,我们将选择肘部所在的k = 3。
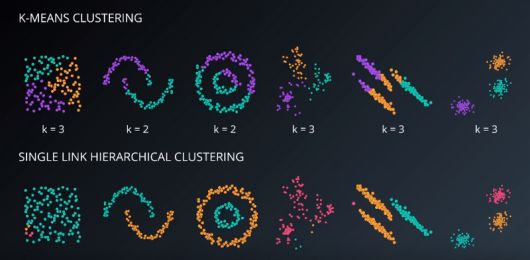
K均值限制
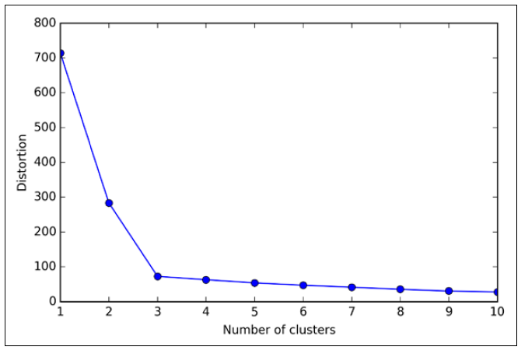
虽然K均值是一种很好的聚类算法,但是当我们事先知道聚类的确切数量以及处理球形分布时,它是最有用的。
下图显示了如果我们在每个数据集中使用K均值聚类,即使我们事先知道聚类的确切数量,我们将获得什么:
将K均值算法作为评估其他聚类方法性能的基准是很常见的。
分层聚类
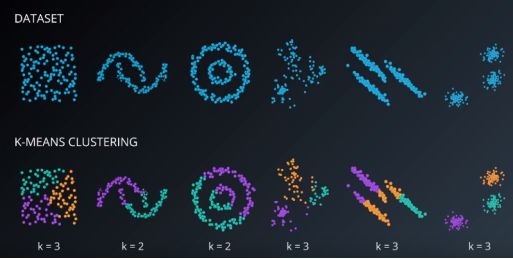
分层聚类是基于prototyope的聚类算法的替代方案。分层聚类的主要优点是不需要指定聚类的数量,它会自己找到它。此外,它还可以绘制树状图。树状图是二元分层聚类的可视化。
在底部融合的观察是相似的,而在顶部的观察是完全不同的。对于树状图,基于垂直轴的位置而不是水平轴的位置进行结算。
分层聚类的类型
这种类型的聚类有两种方法:集聚和分裂。
分裂:此方法首先将所有数据点放入一个集群中。 然后,它将迭代地将簇分割成较小的簇,直到它们中的每一个仅包含一个样本。
集聚:此方法从每个样本作为不同的集群开始,然后将它们彼此靠近,直到只有一个集群。
单链接和完整链接
这些是用于凝聚层次聚类的最常用算法。
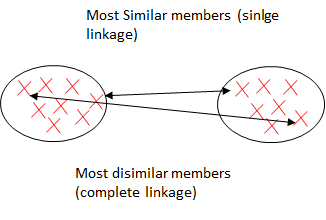
单链接
作为一种凝聚算法,单链接首先假设每个样本点都是一个簇。然后,它计算每对聚类的最相似成员之间的距离,并合并两个聚类,其中最相似成员之间的距离最小。
完整链接
虽然与单链接类似,但其理念恰恰相反,它比较了一对集群中最不相似的数据点来进行合并。
分层聚类的优点
由此产生的层次结构表示可以提供非常丰富的信息。
树状图提供了一种有趣且信息丰富的可视化方式。
当数据集包含真正的层次关系时,它们特别强大。
分层聚类的缺点
分层聚类对异常值非常敏感,并且在其存在的情况下,模型性能显着降低。
从计算上讲,分层聚类非常昂贵。
基于密度的噪声应用空间聚类(DBSCAN)
DBSCAN是另一种特别用于正确识别数据中的噪声的聚类算法。
DBSCAN分配标准
它基于具有指定半径ε的多个点,并且为每个数据点分配了特殊标签。分配此标签的过程如下:
它是指定数量(MinPts)的相邻点。 如果存在落在ε半径内的此MinPts点数,则将分配核心点。
边界点将落在核心点的ε半径内,但相邻数将少于MinPts数。
每隔一点都是噪点。
DBSCAN 算法
该算法遵循以下逻辑:
1. 确定核心点并为每个核心点或每个连接的核心点组成一个组(如果它们满足标准为核心点)。
2. 确定边界点并将其分配给各自的核心点。
下图总结了这个过程和注释符号。
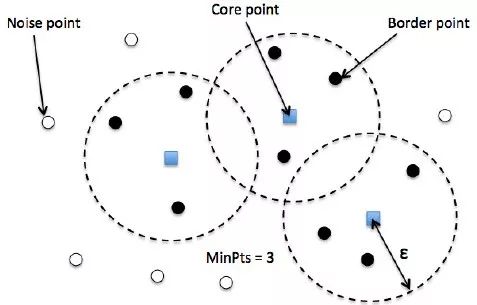
DBSCAN与K均值聚类

DBDSCAN的优点
我们不需要指定群集的数量。
集群可采用的形状和大小具有高度灵活性。
识别和处理噪声数据和异常值非常有用。
DBSCAN 的缺点
处理两个集群可到达的边界点时比较困难。
它没有找到不同密度的井簇。
高斯混合模型 (GMM)
高斯混合模型是概率模型,其假设所有样本是从具有未知参数的有限数量的高斯分布的混合生成的。
它属于软群集算法组,其中每个数据点都属于数据集中存在的每个群集,但每个群集的成员资格级别不同。此成员资格被指定为属于某个群集的概率,范围从0到1。
例如,突出显示的点将同时属于集群A和B,但由于其与它的接近程度而具有更高的集群A的成员资格。

GMM假设每个聚类遵循概率分布,可以是高斯分布或正态分布。它是K-Means聚类的推广,包括有关数据的协方差结构以及潜在高斯中心的信息。
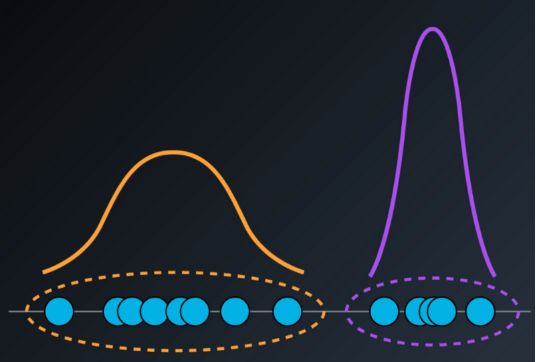
一维GMM分布
GMM将在数据集中搜索高斯分布并将它们混合。
二维GMM
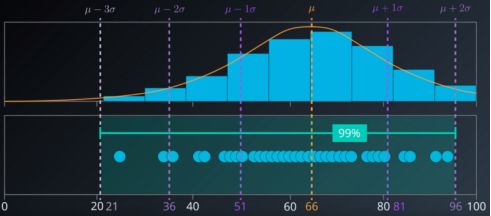
当具有的多变量分布如下时,对于数据集分布的每个轴,平均中心将是μ+σ。
GMM 算法
它是一种期望最大化算法,该过程可概括如下:
1.初始化K高斯分布,可通过μ(平均值)和σ(标准偏差)值来实现。也可从数据集(天真方法)或应用K-Means中获取。
2.软聚类数据:这是“期望”阶段,其中所有数据点将分配给具有各自成员级别的每个聚类。
3.重新估计高斯分布:这是“最大化”阶段,该阶段会对期望进行检查并且将其用于计算高斯的新参数中:新μ和σ。
4.评估数据的对数似然性以检查收敛。日志的相似度越高,我们创建的模型的混合可能越适合数据集。所以,这是最大化的功能。
5.从步骤2开始重复直到收敛。
GMM 的优点
它是一种软聚类方法,可将样本成员分配给多个聚类。这一特性使其成为学习混合模型的最快算法。
集群的数量和形状具有很高的灵活性。
GMM 的缺点
它对初始值非常敏感,这将极大地影响其性能。
GMM可能会收敛到局部最小值,这将是次优解决方案。
当每个混合物的点数不足时,算法会发散并找到具有无限可能性的解,除非人为地规范数据点之间的协方差。
聚类验证
聚类验证是客观和定量评估聚类结果的过程。我们将通过应用集群验证索引来进行此验证。主要有三类:
外部指数
这些是我们在标记原始数据时使用的评分方法,这不是这类问题中最常见的情况。我们将一个聚类结构与事先已知的信息相匹配。
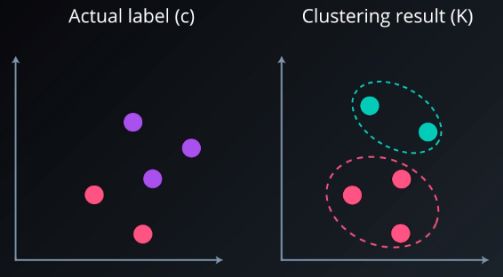
最常用的索引是Adjusted Rand索引。
调整后的兰特指数(ARI)€[-1,1]
我们应首先对其组件进行定义,以便了解:
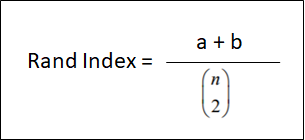
a:是C和K中同一群集中的点数
b:是C和K中不同群集中的点数。
n =是样本总数
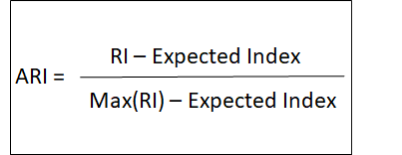
ARI可以获得从-1到1的值。值越高,它与原始数据匹配越好。
内部验证指数
在无监督学习中,我们将使用未标记的数据,这时内部索引更有用。
最常见的指标之一是轮廓系数。
剪影系数:
每个数据点都有一个轮廓系数。
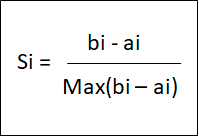
a =同一群集中与其他样本i的平均距离
b =最近邻集群中与其他样本i的平均距离
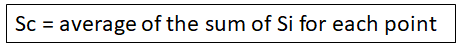
轮廓系数(SC)的值是从-1到1。值越高,选择的K值越好。但是相对于没有达到理想值的情况,超过理想的K值对我们会更加不利。
轮廓系数仅适用于某些算法,如K-Means和层次聚类。它不适合与DBSCAN一起使用,我们将使用DBCV代替。
相关链接:
https://towardsdatascience.com/unsupervised-machine-learning-clustering-analysis-d40f2b34ae7e
(本文为 AI大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
「2019 Python开发者日」演讲议题全揭晓!这一次我们依然“只讲技术,拒绝空谈”10余位一线Python技术专家共同打造一场硬核技术大会。更有深度培训实操环节,为开发者们带来更多深度实战机会。更多详细信息请咨询13581782348(微信同号)。

推荐阅读:
技术头条
收藏指数爆表!CVPR 2018-2019几十篇优质论文解读大礼包! | 技术头条
分析11年21部漫威电影,一览导演、主演、口碑票房最佳......
靠找Bug赚了6,700,000元!他凭什么?
30位90后霸榜! 福布斯: 比你年轻、比你有颜、比你有才华, 就是他们了!
程序员深夜逆行被拦后崩溃欲自杀:老板在催我!女朋友在催我!
微软 CTO 韦青:“程序员 35 岁就被淘汰”是个伪概念 | 人物志
OpenStack已死?恐怕你想多了 | 技术头条

❤点击“阅读原文”,查看历史精彩文章。
相关文章:

自动红眼移除算法 附c++完整代码
说起红眼算法,这个话题非常古老了。 百度百科上的描述: “红眼”一般是指在人物摄影时,当闪光灯照射到人眼的时候,瞳孔放大而产生的视网膜泛红现象。 由于红眼现象的程度是根据拍摄对象色素的深浅决定的,如果拍摄对象的…

【Dlib】在GPU环境中运行dlib中的例子dnn_mmod_ex报错...dlib::cuda_error...Error while calling cudaMalloc...
1、问题描述 在GPU环境下运行dlib中的例子dnn_mmod_ex时,报错: terminate called after throwing an instance of dlib::cuda_errorwhat(): Error while calling cudaMalloc(&data, new_size*sizeof(float)) in file /home/laoer/tools/dlib/dlib…
Exchange 2010正式发布了
2009年11月9号,Exchange 2010正式发布了,下载地址:http://www.microsoft.com/downloa ... 0-879f-d74208d6171d简体中文64位120天试用版转载于:https://blog.51cto.com/287416363/657202
【python】使用python脚本将CelebA中图片按照 list_attr_celeba.txt 中属性处理(删除、复制、移动)
1、目的 CelebA中的照片有四十种属性,参见: 【AI】CelebA数据介绍、下载及说明 根据需求从celebA中获取我们想要的图片,方法是将CelebA中图片按照 list_attr_celeba.txt 中属性执行删除、复制或移动操作。 命令格式: python3 C…
firefly 编译opencv3.3.1, CMake报错
更换gcc编译器可以解决 -D CMAKE_C_COMPILER/usr/bin/gcc-4.8转载于:https://www.cnblogs.com/gabrialrx/p/9001554.html
AI时代,为何机器人公司无法盈利只能走向倒闭?
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑作者 | Bram Vanderborght译者 | 弯月责编 | 屠敏出品 | CSDN(ID:CSDNnews)导语:机器人专家需要公开诚实地讨论我们的成功,而不…
Google Objective-C Style Guide
看题目就知道了~哪天有空翻译成中文的~不多说了~上链接~Google Objective-C Style Guide转载于:https://blog.51cto.com/lulala/659124
ICPC 2019国际大学生程序设计竞赛,中国高校未能夺冠
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑整理 | 琥珀出品 | AI科技大本营(ID:rgznai100)一年一度的国际大学生程序设计竞赛(International Collegiate Programming Contest,ICPC&am…
完爆Facebook/GraphQL,APIJSON全方位对比解析(一)-基础功能
相关阅读: 完爆Facebook/GraphQL,APIJSON全方位对比解析(二)-权限控制 完爆Facebook/GraphQL,APIJSON全方位对比解析(三)-表关联查询 自APIJSON发布以来,不断有网友拿来和Facebook的GraphQL对比, 甚至有不少人声称“完…
【AI】吴恩达斯坦福机器学习中文笔记汇总
1、吴恩达机器学习和深度学习课程的字幕翻译以及笔记整理参见: 以黄海广博士为首的一群机器学习爱好者发起的公益性质项目(http://www.ai-start.com)。 2、黄海广博士公益项目介绍 https://www.jianshu.com/p/16a749e332db 3、吴恩达 斯坦…
【C++】C++命名空间重定向
参见博客: namespace使用总结 命名空间的重定向的格式: namespace newName oldName; 在caffe源码走读时,遇到namespace的重定向用法,以前没有用过,源码如下,其中 GFLAGS_GFLAGS_H_是为了检测gflags的版…
宝宝都能看懂的机器学习世界
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑作者 | 武博士、宋知达、袁雪瑶、聂文韬来源 | 大鱼AI(ID:DayuAI-Founder)人类需要经过各式各样的学习才有办法认识这个世界。 当小朋友第一次看到猫后…
iOS LLDB调试命令(Low Lever Debug)
断点 设置断点 $breakpoint set -n XXX set 是子命令 -n 是选项 是--name 的缩写!查看断点列表 $breakpoint list删除 $breakpoint delete 组号禁用/启用 $breakpoint disable 禁用 $breakpoint enable 启用遍历整个项目中满足Game:这个字符的所有方法 $breakpoint set -r Game…
TCP通信速率与延时关系
刚刚研究了链路延时对TCP速率的影响,占位,有空会写一下。转载于:https://blog.51cto.com/csnas/659983
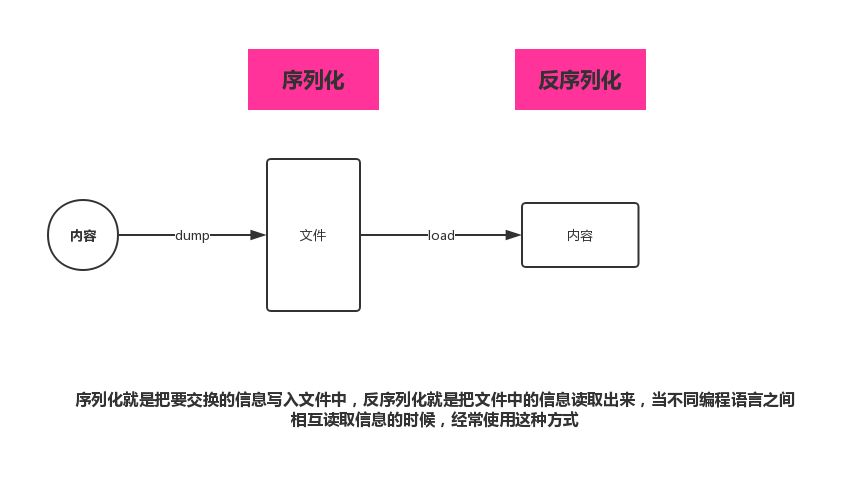
十三、序列化和反序列化(部分转载)
json和pickle序列化和反序列化json是用来实现不同程序之间的文件交互,由于不同程序之间需要进行文件信息交互,由于用python写的代码可能要与其他语言写的代码进行数据传输,json支持所有程序之间的交互,json将取代XML,由…
【C++】google gflags详解
参考博客;https://blog.csdn.net/lezardfu/article/details/23753741 0、简介 gflags是google的一个开源的处理命令行参数的库,使用c开发,具备python接口,可以替代getopt。gflags使用起来比getopt方便,但是不支持参数…
何恺明等人新作:效果超ResNet,利用NAS方法设计随机连接网络 | 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑译者 | 刘畅编辑 | 一一出品 | AI科技大本营(ID:rgznai100)受人工设计的启发,用于图像识别的神经网络从简单的链状模型发展为具有多个分支的网络。ResN…

网络规划设计师考试命题模式持续在变 你变不变
命题模式持续在变 你变不变深入分析2009下半年~2010下半年3次网络规划设计师考试试卷中项目管理模块(约有5~8题,约占总分数的6.67%~10.67%)的命题规律,心中最强烈的一份感觉体现在一个字——变。“变”是事物持续发…
【C++】google glog详解
0、简介 glog是google的日志管理系统,配合gflags库,通过命令行参数管理日志。 源码下载:https://github.com/google/glog ubuntu安装: sudo apt-get install libgoogle-glog*参考博客: https://blog.csdn.net/jcjc91…
仿抖音注册界面制作
话说上次完成了仿抖音我的界面制作之后,今天抽空又把注册界面给做了,还是做了些小改动,将第三方登录去掉了 注册还是老规矩直接奉上psd源码:仿抖音注册界面psd源码 个人博客https://myml666.github.io
00后的AI开发者进阶之道:从入门到鏖战MIT编程大赛 | 人物志
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑作者 | 若名出品 | AI科技大本营(ID:rgznai100)当所有中国的高中生都在拼命为跨过高考这道窄门疲惫不堪时,美国的准高中毕业生们也开始申请大学&#x…
js的全部替换函数replaceAll
JS替换功能函数,用正则表达式解决,js的全部替换,学习js的朋友可以参考下。 alert("abacacf".replace(a,9)); alert("abacacf".replace(/a/g,9)); 第一个运行的结果 9bacaf 这个只是替换了第一个 第二个运行的结果 9b9c9f…

【C++】Google Protocol Buffer(protobuf)详解(一)
1、简介 Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准, Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通…

python使用difflib对比文件示例
使用difflib模块对比文件内容1 示例:字符串差异对比 vim duibi.py#!/usr/bin/env python # -*- coding: utf-8 -*- import re import os import difflib tex1"""tex1: this is a test for difflib ,just try to get difference of the log 现在试试…

技术大佬们都推荐的vim学习指南来了,值得收藏!
「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑作者 | kbsc13,京东算法工程师,研究领域计算机视觉来源 | 机器学习与计算机视觉(ID:AI_Developer)编辑 | Jane【导语】在 Linux 下最常使用的文本编辑…

NoSQl分类
2019独角兽企业重金招聘Python工程师标准>>> http://nosql-database.org/ nosql简单分类 类型 部分代表 特点 列存储 hbase cassandra hypertable 顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩&…
手撕代码之七大常用排序算法 | 附完整代码
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑0.导语本节为手撕代码系列之第一弹,主要来手撕排序算法,主要包括以下几大排序算法:直接插入排序冒泡排序选择排序快速排序希尔排序堆排序归并排序…
【C++】google gtest 详解
1、参考博客; https://blog.csdn.net/baijiwei/article/details/81265491 https://www.cnblogs.com/coderzh/archive/2009/04/06/1426755.html 2、编译和安装 $ git clone https://github.com/google/googletest.git $ cd googletest $ mkdir mybuild $ cd mybui…
JS学习笔记之call、apply的用法
1、call和apply的区别 call和apply唯一的区别是传入参数的形式不同。 apply接受两个参数,第一个参数指定了函数体内this对象的指向,第二个参数为一个带下标的集合,可以是数组,也可以是类数组,apply方法会把集合中的元素…
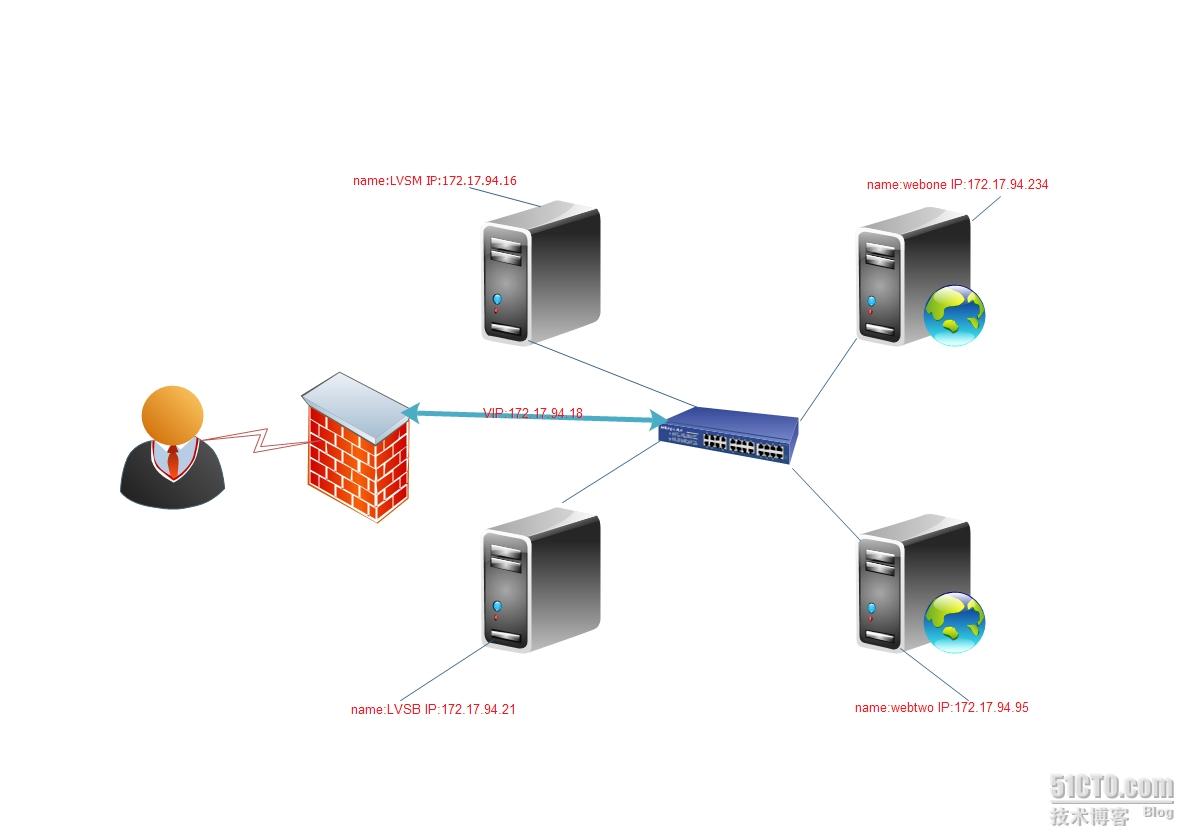
实验LVS+keepalived
lvs说明:目前有三种IP负载均衡技术(VS/NAT、VS/TUN和VS/DR);八种调度算法(rr,wrr,lc,wlc,lblc,lblcr,dh,sh)。在调度器的实现技术中,IP负载均衡技术是效率最高的。在已有的IP负载均衡技术中有通过网络地址转…