Spark Streaming笔记整理(二):案例、SSC、数据源与自定义Receiver
[TOC]
实时WordCount案例
主要是监听网络端口中的数据,并实时进行wc的计算。
Java版
测试代码如下:
package cn.xpleaf.bigdata.spark.java.streaming.p1;import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;import java.util.Arrays;/*** 使用Java开发SparkStreaming的第一个应用程序** 用于监听网络socket中的一个端口,实时获取对应的文本内容* 计算文本内容中的每一个单词出现的次数*/
public class _01SparkStreamingNetWorkWCOps {public static void main(String[] args) {if(args == null || args.length < 2) {System.err.println("Parameter Errors! Usage: <hostname> <port>");System.exit(-1);}Logger.getLogger("org.apache.spark").setLevel(Level.OFF);SparkConf conf = new SparkConf().setAppName(_01SparkStreamingNetWorkWCOps.class.getSimpleName())/** 设置为local是无法计算数据,但是能够接收数据* 设置为local[2]是既可以计算数据,也可以接收数据* 当master被设置为local的时候,只有一个线程,且只能被用来接收外部的数据,所以不能够进行计算,如此便不会做对应的输出* 所以在使用的本地模式时,同时是监听网络socket数据,线程个数必须大于等于2*/.setMaster("local[2]");/*** 第二个参数:Duration是SparkStreaming用于进行采集多长时间段内的数据将其拆分成一个个batch* 该例表示每隔2秒采集一次数据,将数据打散成一个个batch(其实就是SparkCore中的一个个RDD)*/JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(2));String hostname = args[0].trim();int port = Integer.valueOf(args[1].trim());JavaReceiverInputDStream<String> lineDStream = jsc.socketTextStream(hostname, port);// 默认的持久化级别StorageLevel.MEMORY_AND_DISK_SER_2JavaDStream<String> wordsDStream = lineDStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterable<String> call(String line) throws Exception {return Arrays.asList(line.split(" "));}});JavaPairDStream<String, Integer> pairsDStream = wordsDStream.mapToPair(word -> {return new Tuple2<String, Integer>(word, 1);});JavaPairDStream<String, Integer> retDStream = pairsDStream.reduceByKey(new Function2<Integer, Integer, Integer>() {@Overridepublic Integer call(Integer v1, Integer v2) throws Exception {return v1 + v2;}});retDStream.print();// 启动流式计算jsc.start();// 等待执行结束jsc.awaitTermination();System.out.println("结束了没有呀,哈哈哈~");jsc.close();}
}启动程序,同时在主机上使用nc命令进行操作:
[uplooking@uplooking01 ~]$ nc -lk 4893
hello youe hello he hello me输出结果如下:
-------------------------------------------
Time: 1525929096000 ms
-------------------------------------------
(youe,1)
(hello,3)
(me,1)
(he,1)同时也可以在Spark UI上查看相应的作业执行情况:
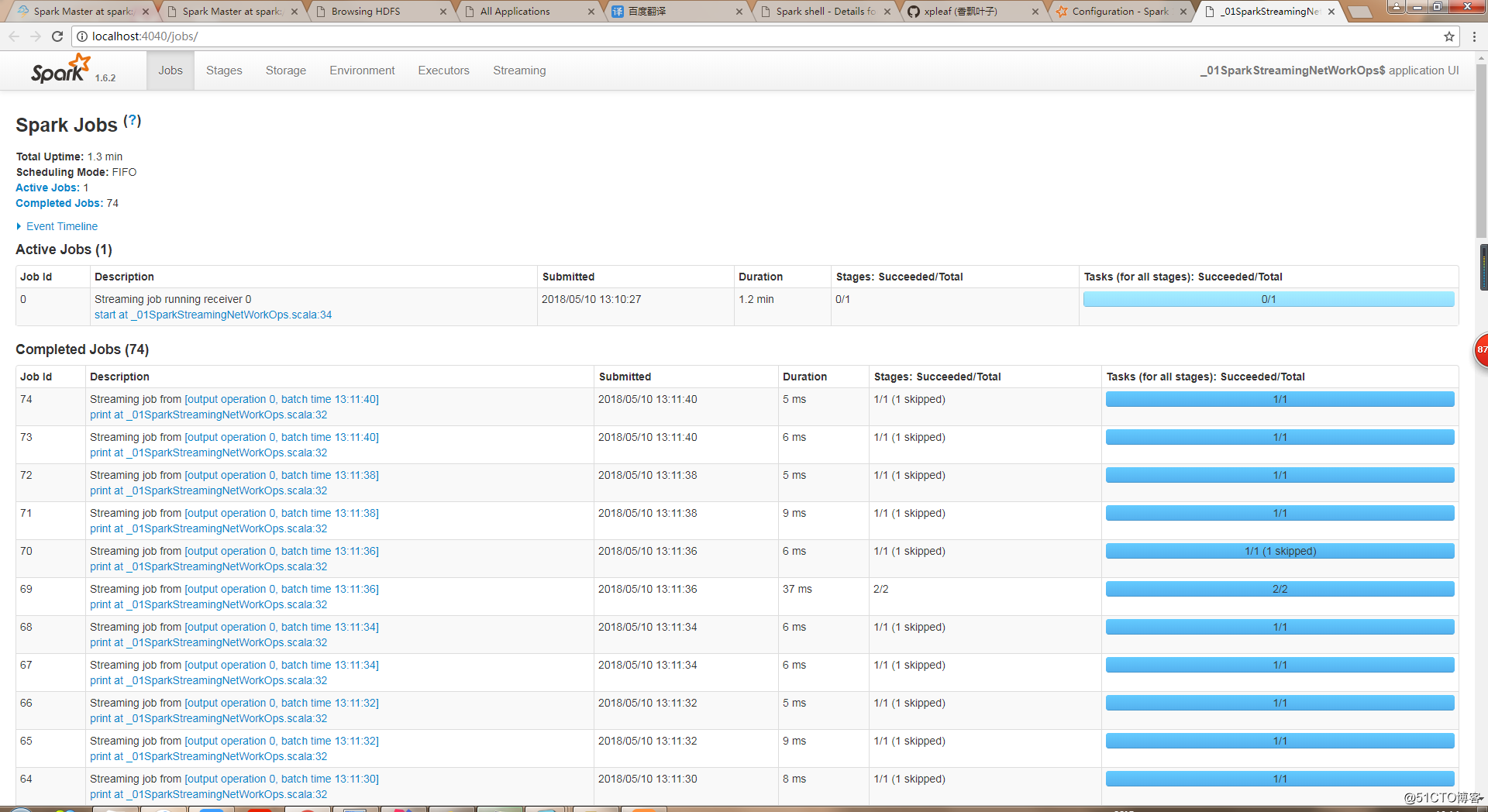
可以看到,每2秒就会执行一次计算,即每隔2秒采集一次数据,将数据打散成一个个batch(其实就是SparkCore中的一个个RDD)。
Scala版
测试代码如下:
package cn.xpleaf.bigdata.spark.scala.streaming.p1import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}object _01SparkStreamingNetWorkOps {def main(args: Array[String]): Unit = {if (args == null || args.length < 2) {System.err.println("""Parameter Errors! Usage: <hostname> <port>|hostname: 监听的网络socket的主机名或ip地址|port: 监听的网络socket的端口""".stripMargin)System.exit(-1)}Logger.getLogger("org.apache.spark").setLevel(Level.OFF)val conf = new SparkConf().setAppName(_01SparkStreamingNetWorkOps.getClass.getSimpleName).setMaster("local[2]")val ssc = new StreamingContext(conf, Seconds(2))val hostname = args(0).trimval port = args(1).trim.toIntval linesDStream:ReceiverInputDStream[String] = ssc.socketTextStream(hostname, port)val wordsDStream:DStream[String] = linesDStream.flatMap({case line => line.split(" ")})val pairsDStream:DStream[(String, Integer)] = wordsDStream.map({case word => (word, 1)})val retDStream:DStream[(String, Integer)] = pairsDStream.reduceByKey{case (v1, v2) => v1 + v2}retDStream.print()ssc.start()ssc.awaitTermination()ssc.stop() // stop中的boolean参数,设置为true,关闭该ssc对应的SparkContext,默认为false,只关闭自身}
}启动程序,同时在主机上使用nc命令进行操作:
[uplooking@uplooking01 ~]$ nc -lk 4893
hello youe hello he hello me输出结果如下:
-------------------------------------------
Time: 1525929574000 ms
-------------------------------------------
(youe,1)
(hello,3)
(me,1)
(he,1)StreamingContext和DStream详解
StreamingContext的创建方式
1、在Spark中有两种创建StreamingContext的方式
1)根据SparkConf进行创建
val conf = new SparkConf().setAppName(appname).setMaster(master);
val ssc = new StreamingContext(conf, Seconds(10));2)还可以根据SparkContext进行创建
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(10));appname,是用来在Spark UI上显示的应用名称。master,是一个Spark、Mesos或者Yarn集群的URL,或者是local[*]。
2、batch interval:Seconds(10)可以根据我们自己应用程序的情况进行不同的设置。
StreamingContext的创建、启动和销毁
一、一个StreamingContext定义之后,必须执行以下程序进行实时计算的执行
1、创建输入DStream来创建输入不同的数据源。
2、对DStream定义transformation和output等各种算子操作,来定义我们需要的各种实时计算逻辑。
3、调用StreamingContext的start()方法,进行启动我们的实时处理数据。
4、调用StreamingContext的awaitTermination()方法,来等待应用程序的终止。可以使用CTRL+C手动停止,或者就是让它持续不断的运行进行计算。
5、也可以通过调用StreamingContext的stop()方法,来停止应用程序。
二、备注(十分重要)
1、只要我们一个StreamingContext启动之后,我们就不能再往这个Application其中添加任何计算逻辑了。比如执行start()方法之后,还给某个DStream执行一个算子,这是不允许的。
2、一个StreamingContext停止之后,是肯定不能够重启的。调用stop()之后,不能再调用start()
3、必须保证一个JVM同时只能有一个StreamingContext启动。在你的应用程序中,不能创建两个StreamingContext。
4、调用stop()方法时,会同时停止内部的SparkContext,如果不希望如此,还希望后面继续使用SparkContext创建其他类型的Context,比如SQLContext,那么就用stop(false)。
5、一个SparkContext可以创建多个StreamingContext,只要上一个先用stop(false)停止,再创建下一个即可。(注意与第2点的区别,这里是再创建了一个StreamingContext)
输入DStream和Receiver

输入DStream代表了来自数据源的输入数据流。我们之前做过了一些例子,比如从文件读取、从TCP、从HDFS读取等。每个DSteam都会绑定一个Receiver对象,该对象是一个关键的核心组件,用来从我们的各种数据源接受数据,并将其存储在Spark的内存当中,这个内存的StorageLevel,我们可以自己进行指定,老师在以后的例子中会讲解这部分。
Spark Streaming提供了两种内置的数据源支持:
1、基础数据源:SSC API中直接提供了对这些数据源的支持,比如文件、tcp socket、Akka Actor等。
2、高级数据源:比如Kafka、Flume、Kinesis和Twitter等数据源,要引入第三方的JAR来完成我们的工作。
3、自定义数据源:比如我们的ZMQ、RabbitMQ、ActiveMQ等任何格式的自定义数据源。关于自定义数据源,老师在讲解最后一个项目的时候,会使用此自定义数据源如果从ZMQ中读取数据。官方提供的Spark-ZMQ是基于zmq2.0版本的,因为现在的 生产环境都是基于ZMQ4以上的版本了,所以必须自己定义并实现了一个自定义的receiver机制。
Spark Streaming的运行机制local[*]分析
1、如果我们想要在我们的Spark Streaming应用中并行读取N多数据的话,我们可以启动创建多个DStream。这样子就会创建多个Receiver,老师最多的一个案例是启动了128个Receive,每个receiver每秒的数据是1000W以上。
2、但是要注意的是,我们Spark Streaming Application的Executor进程,是个长时间运行的一个进程,因此它会独占分给他的cpu core。所以它只能自己处理这件事情了,不能再干其他活了。
3、使用本地模式local运行我们的Spark Streaming程序时,绝对不能使用local或者 local[1]的模式。因为Spark Streaming运行的时候,必须要至少要有2个线程。如果只给了一条的话,Spark Streaming Application程序会直接hang在哪儿。 两条线程的一条用来分配给Receiver接收数据,另外一条线程用来处理接受到的数据。因此我们想要进行本地测试的话,必须满足local[N],这个N一定要大于2
4、如果我们想要在我们的Spark进群上运行的话,那么首先,必须要求我们的集群每个节点上,有>1个cpu core。其次,给Spark Streaming的每个executor分配的core,必须>1,这样,才能保证分配到executor上运行的输入DStream,两条线程并行,一条运行Receiver,接收数据;一条处理数据。否则的话,只会接收数据,不会处理数据。
DStream与HDFS集成
输入DFStream基础数据源
基于HDFS文件的实时计算,其实就是监控我们的一个HDFS目录,只要其中有新文件出现,就实时处理。相当于处理实时的文件流。
===》Spark Streaming会监视指定的HDFS目录,并且处理出现在目录中的文件。
1)在HDFS中的所有目录下的文件,必须满足相同的格式,不然的话,不容易处理。必须使用移动或者重命名的方式,将文件移入目录。一旦处理之后,文件的内容及时改变,也不会再处理了。
2)基于HDFS的数据结源读取是没有receiver的,因此不会占用一个cpu core。
3)实际上在下面的测试案例中,一直也没有效果,也就是监听不到HDFS中的文件,本地文件也没有效果;
基于HDFS的实时WordCounter案例实战
测试代码如下:
package cn.xpleaf.bigdata.spark.scala.streaming.p1import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}/*** SparkStreaming监听hdfs的某一个目录的变化(新增文件)*/
object _02SparkStreamingHDFSOps {def main(args: Array[String]): Unit = {Logger.getLogger("org.apache.spark").setLevel(Level.OFF)val conf = new SparkConf().setAppName(_02SparkStreamingHDFSOps.getClass.getSimpleName).setMaster("local[2]")val ssc = new StreamingContext(conf, Seconds(5))val linesDStream:DStream[String] = ssc.textFileStream("hdfs://ns1/input/spark/streaming/")
// val linesDStream:DStream[String] = ssc.textFileStream("D:/data/spark/streaming")linesDStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).print()ssc.start()ssc.awaitTermination()ssc.stop()}
}DStream与Kafka集成(基于Receiver方式)
Spark与Kafka集成的方式
1、利用Kafka的Receiver方式进行集成
2、利用Kafka的Direct方式进行集成
Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以从代码中简单理解成Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据了。
基于Kafka的Receiver方式集成
这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
补充说明:
(1)、Kafka中的topic的partition,与Spark中的RDD的partition是没有关系的。所以,在KafkaUtils.createStream()中,提高partition的数量,只会增加一个Receiver中,读取partition的线程的数量。不会增加Spark处理数据的并行度。
(2)、可以创建多个Kafka输入DStream,使用不同的consumer group和topic,来通过多个receiver并行接收数据。
(3)、如果基于容错的文件系统,比如HDFS,启用了预写日志机制,接收到的数据都会被复制一份到预写日志中。因此,在KafkaUtils.createStream()中,设置的持久化级别是StorageLevel.MEMORY_AND_DISK_SER。
与Kafka的集成--Maven
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka_2.10</artifactId><version>1.6.2</version>
</dependency>Kafka启动、验证和测试
启动kafka服务
kafka-server-start.sh -daemon config/server.properties创建topic
kafka-topics.sh --create --topic spark-kafka --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181 --partitions 3 --replication-factor 3列举kafka中已经创建的topic
kafka-topics.sh --list --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181列举每个节点都保护那些topic、Partition
kafka-topics.sh --describe --zookeeper uplooking01:2181, uplooking02:2181, uplooking03:21821 --topic spark-kafkaleader:负责处理消息的读和写,leader是从所有节点中随机选择的.replicas:列出了所有的副本节点,不管节点是否在服务中.isr:是正在服务中的节点.产生数据
kafka-console-producer.sh --topic spark-kafka --broker-list uplooking01:9092,uplooking02:9092,uplooking03:9092消费数据
kafka-console-consumer.sh --topic spark-kafka --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181案例
测试代码如下:
package cn.xpleaf.bigdata.spark.scala.streaming.p1import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}/*** Kafka和SparkStreaming基于Receiver的模式集成*/
object _03SparkStreamingKafkaReceiverOps {def main(args: Array[String]): Unit = {Logger.getLogger("org.apache.spark").setLevel(Level.OFF)val conf = new SparkConf().setAppName(_03SparkStreamingKafkaReceiverOps.getClass.getSimpleName).setMaster("local[2]")val ssc = new StreamingContext(conf, Seconds(5))
// ssc.checkpoint("hdfs://ns1/checkpoint/streaming/kafka") // checkpoint文件保存到hdfs中ssc.checkpoint("file:///D:/data/spark/streaming/checkpoint/streaming/kafka") // checkpoint文件保存到本地文件系统/*** 使用Kafka Receiver的方式,来创建的输入DStream,需要使用SparkStreaming提供的Kafka整合API* KafkaUtils*/val zkQuorum = "uplooking01:2181,uplooking02:2181,uplooking03:2181"val groupId = "kafka-receiver-group-id"val topics:Map[String, Int] = Map("spark-kafka"->3)// ReceiverInputDStream中的key就是当前一条数据在kafka中的key,value就是该条数据对应的valueval linesDStream:ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics)val retDStream = linesDStream.map(t => t._2).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)retDStream.print()ssc.start()ssc.awaitTermination()ssc.stop()}
}在kafka中生产数据:
[uplooking@uplooking02 kafka]$ kafka-console-producer.sh --topic spark-kafka --broker-list uplooking01:9092,uplooking02:9092,uplooking03:9092
hello you hello he hello me输出结果如下:
-------------------------------------------
Time: 1525965130000 ms
-------------------------------------------
(hello,3)
(me,1)
(you,1)
(he,1)在上面的代码中,还启用了Spark Streaming的预写日志机制(Write Ahead Log,WAL)。
如果数据保存在本地文件系统,则如下:
如果数据保存在HDFS中,则如下:
DStream与Kafka集成(基于Direct方式)
Spark和Kafka集成Direct的特点
(1)Direct的方式是会直接操作kafka底层的元数据信息,这样如果计算失败了,可以把数据重新读一下,重新处理。即数据一定会被处理。拉数据,是RDD在执行的时候直接去拉数据。
(2)由于直接操作的是kafka,kafka就相当于你底层的文件系统。这个时候能保证严格的事务一致性,即一定会被处理,而且只会被处理一次。而Receiver的方式则不能保证,因为Receiver和ZK中的数据可能不同步,Spark Streaming可能会重复消费数据,这个调优可以解决,但显然没有Direct方便。而Direct api直接是操作kafka的,spark streaming自己负责追踪消费这个数据的偏移量或者offset,并且自己保存到checkpoint,所以它的数据一定是同步的,一定不会被重复。即使重启也不会重复,因为checkpoint了,但是程序升级的时候,不能读取原先的checkpoint,面对升级checkpoint无效这个问题,怎么解决呢?升级的时候读取我指定的备份就可以了,即手动的指定checkpoint也是可以的,这就再次完美的确保了事务性,有且仅有一次的事务机制。那么怎么手动checkpoint呢?构建SparkStreaming的时候,有getorCreate这个api,它就会获取checkpoint的内容,具体指定下这个checkpoint在哪就好了。
(3)由于底层是直接读数据,没有所谓的Receiver,直接是周期性(Batch Intervel)的查询kafka,处理数据的时候,我们会使用基于kafka原生的Consumer api来获取kafka中特定范围(offset范围)中的数据。这个时候,Direct Api访问kafka带来的一个显而易见的性能上的好处就是,如果你要读取多个partition,Spark也会创建RDD的partition,这个时候RDD的partition和kafka的partition是一致的。而Receiver的方式,这2个partition是没任何关系的。这个优势是你的RDD,其实本质上讲在底层读取kafka的时候,kafka的partition就相当于原先hdfs上的一个block。这就符合了数据本地性。RDD和kafka数据都在这边。所以读数据的地方,处理数据的地方和驱动数据处理的程序都在同样的机器上,这样就可以极大的提高性能。不足之处是由于RDD和kafka的patition是一对一的,想提高并行度就会比较麻烦。提高并行度还是repartition,即重新分区,因为产生shuffle,很耗时。这个问题,以后也许新版本可以自由配置比例,不是一对一。因为提高并行度,可以更好的利用集群的计算资源,这是很有意义的。
(4)不需要开启wal机制,从数据零丢失的角度来看,极大的提升了效率,还至少能节省一倍的磁盘空间。从kafka获取数据,比从hdfs获取数据,因为zero copy的方式,速度肯定更快。
Kafka Direct VS Receiver
从高层次的角度看,之前的和Kafka集成方案(reciever方法)使用WAL工作方式如下:
1)运行在Spark workers/executors上的Kafka Receivers连续不断地从Kafka中读取数据,其中用到了Kafka中高层次的消费者API。
2)接收到的数据被存储在Spark workers/executors中的内存,同时也被写入到WAL中。只有接收到的数据被持久化到log中,Kafka Receivers才会去更新Zookeeper中Kafka的偏移量。
3)接收到的数据和WAL存储位置信息被可靠地存储,如果期间出现故障,这些信息被用来从错误中恢复,并继续处理数据。
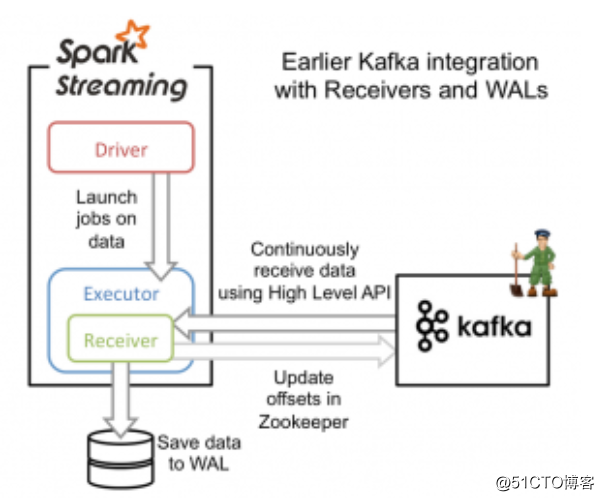
- 这个方法可以保证从Kafka接收的数据不被丢失。但是在失败的情况下,有些数据很有可能会被处理不止一次!这种情况在一些接收到的数据被可靠地保存到WAL中,但是还没有来得及更新Zookeeper中Kafka偏移量,系统出现故障的情况下发生。这导致数据出现不一致性:Spark Streaming知道数据被接收,但是Kafka那边认为数据还没有被接收,这样在系统恢复正常时,Kafka会再一次发送这些数据。
- 这种不一致产生的原因是因为两个系统无法对那些已经接收到的数据信息保存进行原子操作。为了解决这个问题,只需要一个系统来维护那些已经发送或接收的一致性视图,而且,这个系统需要拥有从失败中恢复的一切控制权利。基于这些考虑,社区决定将所有的消费偏移量信息只存储在Spark Streaming中,并且使用Kafka的低层次消费者API来从任意位置恢复数据。
为了构建这个系统,新引入的Direct API采用完全不同于Receivers和WALs的处理方式。它不是启动一个Receivers来连续不断地从Kafka中接收数据并写入到WAL中,而是简单地给出每个batch区间需要读取的偏移量位置,最后,每个batch的Job被运行,那些对应偏移量的数据在Kafka中已经准备好了。这些偏移量信息也被可靠地存储(checkpoint),在从失败中恢复
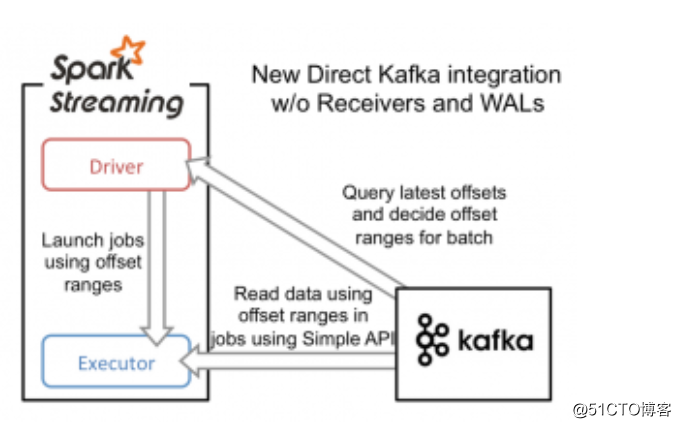
- 需要注意的是,Spark Streaming可以在失败以后重新从Kafka中读取并处理那些数据段。然而,由于仅处理一次的语义,最后重新处理的结果和没有失败处理的结果是一致的。
- 因此,Direct API消除了需要使用WAL和Receivers的情况,而且确保每个Kafka记录仅被接收一次并被高效地接收。这就使得我们可以将Spark Streaming和Kafka很好地整合在一起。总体来说,这些特性使得流处理管道拥有高容错性,高效性,而且很容易地被使用。
案例
测试代码如下:
package cn.xpleaf.bigdata.spark.scala.streaming.p1import kafka.serializer.StringDecoder
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}/*** Kafka和SparkStreaming基于Direct的模式集成** 在公司中使用Kafka-Direct方式*/
object _04SparkStreamingKafkaDirectOps {def main(args: Array[String]): Unit = {Logger.getLogger("org.apache.spark").setLevel(Level.OFF)val conf = new SparkConf().setAppName(_04SparkStreamingKafkaDirectOps.getClass.getSimpleName).setMaster("local[2]")val ssc = new StreamingContext(conf, Seconds(5))// ssc.checkpoint("hdfs://ns1/checkpoint/streaming/kafka") // checkpoint文件也是可以保存到hdfs中的,不过必要性不大了,对于direct的方式来说val kafkaParams:Map[String, String] = Map("metadata.broker.list"-> "uplooking01:9092,uplooking02:9092,uplooking03:9092")val topics:Set[String] = Set("spark-kafka")val linesDStream:InputDStream[(String, String)] = KafkaUtils.// 参数分别为:key类型,value类型,key的×××,value的×××createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)val retDStream = linesDStream.map(t => t._2).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)retDStream.print()ssc.start()ssc.awaitTermination()ssc.stop()}
}生产数据:
[uplooking@uplooking02 kafka]$ kafka-console-producer.sh --topic spark-kafka --broker-list uplooking01:9092,uplooking02:9092,uplooking03:9092
hello you hello he hello me输出结果如下:
-------------------------------------------
Time: 1525966750000 ms
-------------------------------------------
(hello,3)
(me,1)
(you,1)
(he,1)自定义Receiver
测试代码如下:
package cn.xpleaf.bigdata.spark.scala.streaming.p1import java.io.{BufferedReader, InputStreamReader}
import java.net.Socketimport org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}/*** SparkStreaming自定义Receiver* 通过模拟Network来学习自定义Receiver** 自定义的步骤:* 1.创建一个类继承一个类或者实现某个接口* 2.复写启动的个别方法* 3.进行注册调用*/
object _05SparkStreamingCustomReceiverOps {def main(args: Array[String]): Unit = {if (args == null || args.length < 2) {System.err.println("""Parameter Errors! Usage: <hostname> <port>|hostname: 监听的网络socket的主机名或ip地址|port: 监听的网络socket的端口""".stripMargin)System.exit(-1)}Logger.getLogger("org.apache.spark").setLevel(Level.OFF)val conf = new SparkConf().setAppName(_05SparkStreamingCustomReceiverOps.getClass.getSimpleName).setMaster("local[2]")val ssc = new StreamingContext(conf, Seconds(5))val hostname = args(0).trimval port = args(1).trim.toIntval linesDStream:ReceiverInputDStream[String] = ssc.receiverStream[String](new MyNetWorkReceiver(hostname, port))val retDStream:DStream[(String, Int)] = linesDStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)retDStream.print()ssc.start()ssc.awaitTermination()ssc.stop()}
}/*** 自定义receiver*/
class MyNetWorkReceiver(storageLevel:StorageLevel) extends Receiver[String](storageLevel) {private var hostname:String = _private var port:Int = _def this(hostname:String, port:Int, storageLevel:StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2) {this(storageLevel)this.hostname = hostnamethis.port = port}/*** 启动及其初始化receiver资源*/override def onStart(): Unit = {val thread = new Thread() {override def run(): Unit = {receive()}}thread.setDaemon(true) // 设置成为后台线程thread.start()}// 接收数据的核心api 读取网络socket中的数据def receive(): Unit = {val socket = new Socket(hostname, port)val ins = socket.getInputStream()val br = new BufferedReader(new InputStreamReader(ins))var line:String = nullwhile((line = br.readLine()) != null) {store(line)}ins.close()socket.close()}override def onStop(): Unit = {}
}启动nc,并输入数据:
[uplooking@uplooking01 ~]$ nc -lk 4893
hello you hello he hello me输出结果如下:
(hello,3)
(me,1)
(you,1)
(he,1)相关文章:

复旦邱锡鹏教授公布《神经网络与深度学习》,中文免费下载 | 极客头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑整理 | Jane出品 | AI科技大本营优质的人工智能学习资源一直是大家非常关注的,以往我们也推荐过很多优秀的课程、书籍等,不过大多来自国外的名校、名师,…

【Qt】信号和槽传递自定义结构体
一、使用信号和槽传递自定义结构体 这是一个老问题了,但是每次使用都要bing,因此做个笔记整理下。 一共有三种方法,可以让结构体在信号和槽之间传递。前两种方法可以让结构体在线程之间传递,最后一种方法只能在同一线程中传递。 Q_DECLARE_METATYPE qRegisterMetaType(推…
Tomcat:Connection reset by peer: socket write error
Connection reset by peer: socket write error错误分析及解决 Connection reset by peer: socket write error错误分析: 常出现的Connection reset by peer: 原因可能是多方面的,不过更常见的原因是: ①:服务器的并发连接数超过…
人脸识别的“生意经”
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑作者 | Jeff John Roberts译者 | 孙薇责编 | 琥珀出品 | AI科技大本营(ID:rgznai100)导语:不经意间,科技公司便拿着你的照片,推…
【Qt】pro中使用DEFINES来实现条件编译
1、pro中使用DEFINES来实现条件编译 在Qt的pro文件中使用DEFINES 来实现类似gcc -D的条件编译功能。 如,在pro中: #定义条件编译宏LAOER DEFINES += LAOER #依赖编译宏LAOER的编译选项: contains(DEFINES, LAOER){message(hello Laoer) } #与编译宏LAOER冲突的编译选项: …

nodejs -- promise的返回
为什么80%的码农都做不了架构师?>>> [javascript] view plain copy const a async () > { return Sequelize.findAll({}) //这里返回一个promise,"aaaaa"也行 } const b async ()>{ const result await a…
SQL 将一列数据转为一行字符串[转]
比如:我用select department,userName from users从表中查询出如下数据department | userName--------------- --------------it it1it it2it it3ur ur1ur ur2我能不能用什么SQL对department进行分组然后变成如下的结果呢?department | userName--------…
【C++】C++11的enum class enum struct和enum
1、问题描述 在走读QtCreator中看到一段代码 在QtCreator-v4.9.2源码中 src\plugins\projectexplorer\projectnodes.h enum class NodeType : quint16 {File 1,Folder,VirtualFolder,Project };以前一直使用enum,这里使用的是enum class,新enum的好处…
浙大首届AI专业本科生将于9月入学,纳入竺院图灵班
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑整理 | 琥珀出品 | AI科技大本营(ID:rgznai100)近日,据澎湃新闻报道,浙江大学计算机科学与技术学院副院长、浙江大学人工智能研究所所长吴飞…
解决阿里云无法正常使用samba的问题【转】
转自:https://blog.csdn.net/u011949148/article/details/54311288 昨天在阿里云上申请了一个云服务器,系统用的是ubuntu14.04,由于是免费的(初次使用),配置较低(单核1G内存,40G硬盘…
Google又放大招:高效实时实现视频目标检测 | 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑作者 | 陈泰红,算法工程师,研究方向为机器学习、图像处理来源 | 极市平台(ID:extrememart)图像目标检测是图像处理领域的基础。…
一个java删除文件夹的小方法
java删除文件夹都是从里向外删除,使用递归的方法。public class IO_FILEdemo09 {public static void main(String[] args) {// TODO Auto-generated method stub// 删除目录演示File dir new File("C:\\version1");DeleteAll(dir);}public static void D…
【C++】operator bool() 和 operator const bool() const
1、问题描述 在走读QtCreator源码时,看到如下运算符重载 源码在QtCreator-v4.9.2中 src\plugins\projectexplorer\projectexplorer.h class OpenProjectResult { public:OpenProjectResult(const QList<Project *> &projects, const QList<Project *…
tomcat高并发的配置
以下内容来源于互联网,具体出处不详 据说服务器运行TOMCATJDK环境能负载到动态1W的并发,贴上他的配置,以后有机会在测试! java 环境配置: export JAVA_OPTS"-server -Xms8g -Xmx8g -Xss128k -XX:ParallelGCThread…

【AI】图示:精确度(查准率)Precision、召回率(查全率)Recall
对Precision、Recall的直译是“精确度”和“召回率”,第一次接触这两个词,很难从字面上知道它们的含义。而翻译成“查准率”和“查全率”就比较好理解,下面统一使用“查准率”和“查全率”。 1、真假正负例 真正例(True Positive…

@程序员,如何“终身成长”与跨界?
文 / Ant说《终身成长》是一碗“鸡汤”并不为过,截止到我看过的前半部分,围绕在一个主题展开——人的潜力是不可知的。换句话说,任何人都有可能成为自己想成为的人。书中列举了大量明星企业与管理者的真实案例,也引用了许多对比实…
TCP通过滑动窗口和拥塞窗口实现限流,能抵御ddos攻击吗
tcp可以通过滑动窗口和拥塞算法实现流量控制,限制上行和下行的流量,但是却不能抵御ddos攻击。 限流只是限制访问流量的大小,是无法区分正常流量和异常攻击流量的。 限流可以控制本软件或者应用的流量大小,从而减少对部署在相同物理…
WPF及Silverlight中将DataGrid数据导出
这段源码是我在项目中实际应用的源码,没有经过删减及处理。 如果你认为有用可以摘去作为自己的导出类中的一个小工具使用。 ///<summary>///数据源导出辅助类 ///</summary>///<remarks>///Author: sucsy ///Create date: 2011-…
首发 | 驭势科技推出“东风网络”:如何找到速度-精度的最优解?| 技术头条...
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑作者 | 驭势科技给定目标硬件,如何确定最优的速度-精度折衷边界?换言之:给定推断延时的限制,模型能达到的最高精度是多少?…
【AI】caffe使用步骤(一):将标注数据生成lmdb或leveldb
1、简述 caffe使用工具 convert_imageset 将标注数据转换成lmdb或leveldb格式,convert_imageset 使用方法可以参考脚本examples/imagenet/create_imagenet.sh。 convert_imageset 在./build/tools/中。 2、convert_imageset命令行参数 ./build/tools/convert_ima…
日本的GMO增加了比特币现金,和另外3种用于贷款项目的加密货币
2019独角兽企业重金招聘Python工程师标准>>> 日本的加密货币交易所 GMO正在不断地向其贷款项目中增加更多的货币,这使得它的客户可以将加密货币借给公司。最初,该项目是为BTC启动的,但现在GMO已经走得更远,并添加了比特…

功能演示:戴尔PowerConnect 8024交换机VLAN的创建与删除
戴尔PowerConnect 8024是一款带24个10 Gb以太网10GBASE-T端口的高密度10 Gb以太网交换机,专为具有高吞吐量和高可用性需求的数据中心、聚合和统一结构部署而设计。 这些高密度10 Gb交换机可用于汇聚型以太网环境,支持密集型虚拟化、iSCSI存储和10 Gb流量…
【AI】caffe使用步骤(二):设计网络模型prototxt
【一】以 lenet_train_test.prototxt 为例 name: "LeNet" layer {name: "mnist"type: "Data"top: "data"top: "label"include {phase: TRAIN}transform_param {scale: 0.00390625}data_param {source: "examples/mnis…
南大和中大“合体”拯救手残党:基于GAN的PI-REC重构网络,“老婆”画作有救了 | 技术头条...
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑编译 | 一一出品 | AI科技大本营(ID:rgznai100)对于喜欢画画的你来说,总是画得七零八落,不堪入目,但现在,有一…
区块链技术应用领域和优势
区块链的应用正成为很多人关注的领域 ,有很多的新应用正在逐步的实施当中,各种的区块链应用也是让众人惊喜不断, 随着区块链技术的发展 ,各行各业在应用中所获取的成效也是越来越大, 这大大激发了人们对于区块链技术的…

Kataspace:用HTML5和WebGL创建基于浏览器的虚拟世界
源自斯坦福的创业公司Katalabs发布了一个用于创建基于浏览器的虚拟世界的开源框架。名叫KataSpace的软件,利用了新兴的HTML5技术,以及WebGL和WebSockets,允许用户无需安装任何插件,直接在浏览器的3D环境中展开互动。Katalabs已经推…
十问陆奇:努力、能力和机遇,谁能帮你跑赢未来?
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑作者 | 陆奇转载自36氪陆奇说:在创业者从0到1的过程中,我们看到的主要挑战有以下几个方面:对需求的理解和判断不够,与目标用户/客户的…
【AI】caffe使用步骤(三):编写求解文件solver.prototxt
【一】参考博客 caffe solver 配置详解:http://www.mamicode.com/info-detail-2620709.html Caffe学习系列(7):solver及其配置:https://www.cnblogs.com/denny402/p/5074049.html 【二】solver求解文件详解 1、solver求解文件例子如下 ne…

MySQL 8.0 Invisible Indexes 和 RDS 5.6 Invisible Indexes介绍
mysql 在8.0的时候支持了不可见索引,称为隐式索引 索引默认是可以的,控制索引的可见性可以使用Invisible,visible关键字作为create table,create index,alter table 来进行定义。RDS 5.6 Invisible Indexes 也是最近刚刚上线的功能。新购买实例目前已经支…
大有可为的“正则表达式”(二)
5.3. 基本和扩展正则表达式Unix支持两种的正则表达式的版本:(1)现代版本:扩展正则表达式(extended regular expression,ERE),属于IEEE1003.2标准,拥有比BRE更多的功能。…