实战:CNN+BLSTM+CTC的验证码识别从训练到部署 | 技术头条

作者|_Coriander
转载自Jerry的算法和NLP(ID: gh_36eba310d433)
1.前言
本项目适用于Python3.6,GPU>=NVIDIA GTX1050Ti,原master分支已经正式切换为CNN+LSTM+CTC的版本了,是时候写一篇新的文章了。
长话短说,开门见山,网络上现有的代码以教学研究为主,本项目是为实用主义者定制的,只要基本的环境安装常识,便可很好的训练出期望的模型,重定义几个简单的参数任何人都能使用机器学习技术训练一个商业化成品。
如果对于DLL调用感兴趣或是其他语言的TensorFlow API感兴趣的移步以下两个项目:
https://github.com/kerlomz/captcha_library_c
https://github.com/kerlomz/captcha_demo_csharp
笔者选用的时下最为流行的CNN+BLSTM+CTC进行端到端的不定长验证码识别,代码中预留了DenseNet+BLSTM+CTC的选项,可以在配置中直接选用。首先,介绍个大概吧。
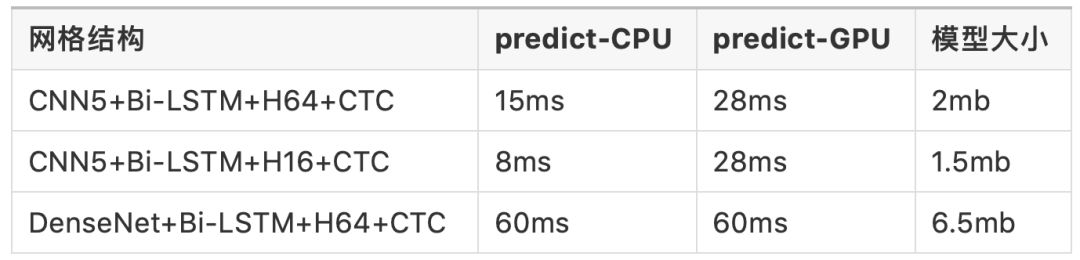
H16/H64指的是Bi-LSTM的隐藏神经元个数num_units,这里注意,你没有看错,也没有写反,LSTM有时序依赖,tf.contrib.rnn.LSTMCell的实现没能很充分的利用GPU的计算资源,底层kernel函数之间的间隙非常大,不利于充分的利用 GPU 的并行性来进行计算。所以本项目使用GPU训练,使用CPU进行预测。预测服务部署项目源码请移步此处:
https://github.com/kerlomz/captcha_platform
2.环境依赖
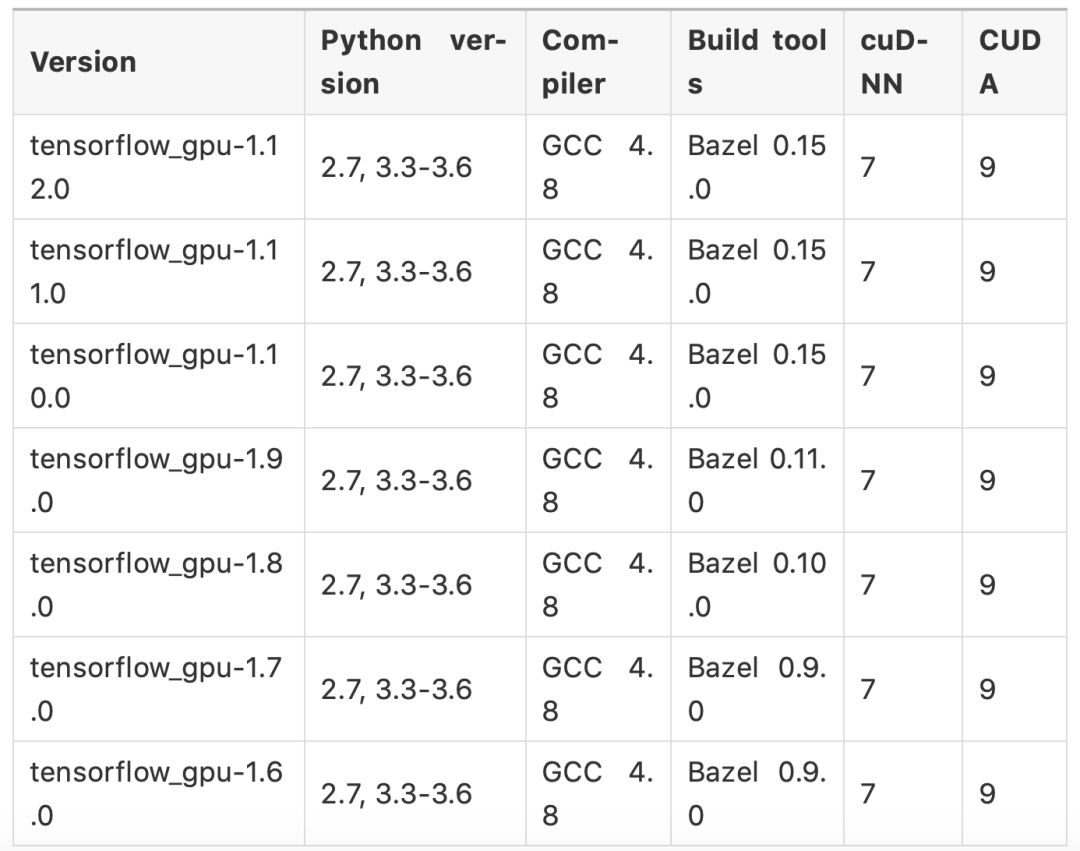
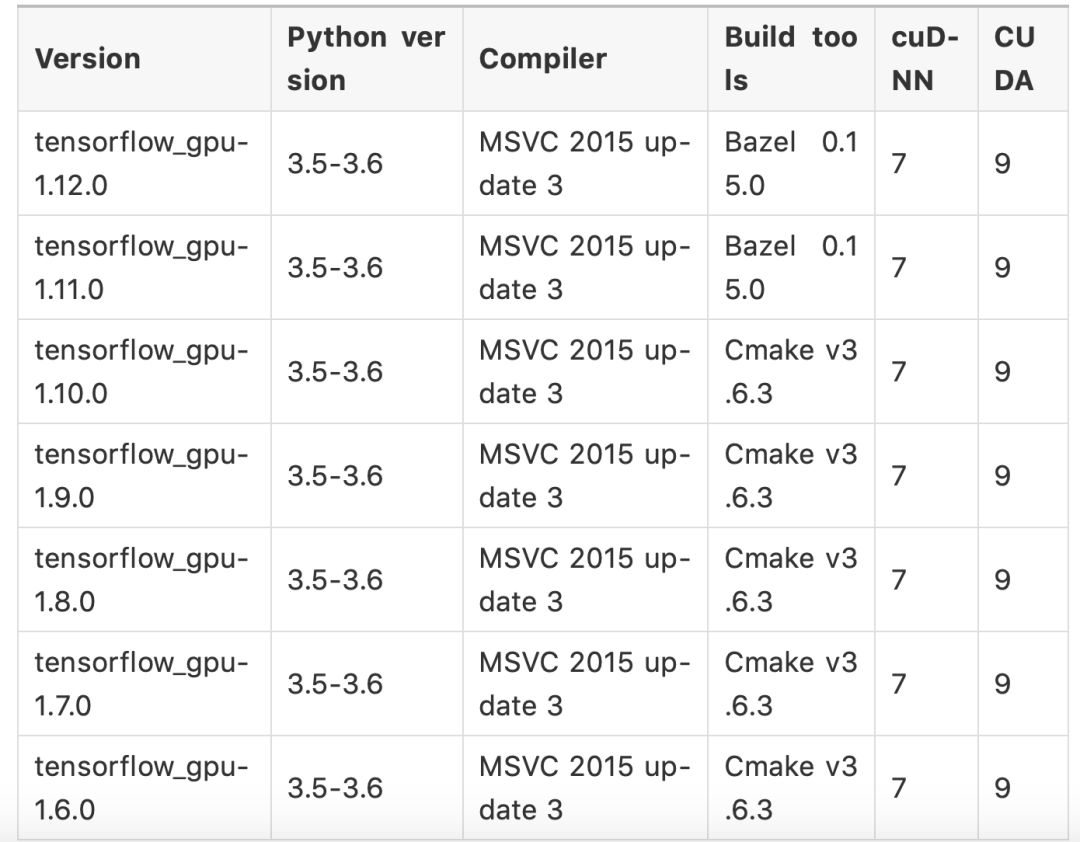
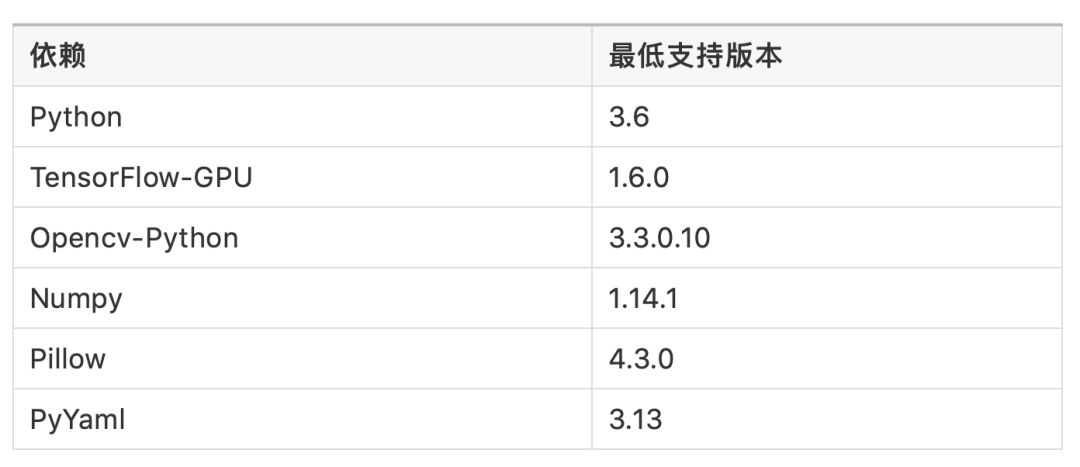
关于CUDA和cuDNN版本的问题,不少人很纠结,这里就列出官方通过pip安装的TensorFlow的版本对应表:
Linux
Windows
如果希望使用上面对应之外的搭配的CUDA和cuDNN,可以自行编译TensorFlow,或者去Github上搜索TensorFlow Wheel找到第三方编译的对应版本的whl安装包。提前预警,若是自己编译将会苦难重重,坑很多,这里就不展开了。
2.1 本项目环境依赖
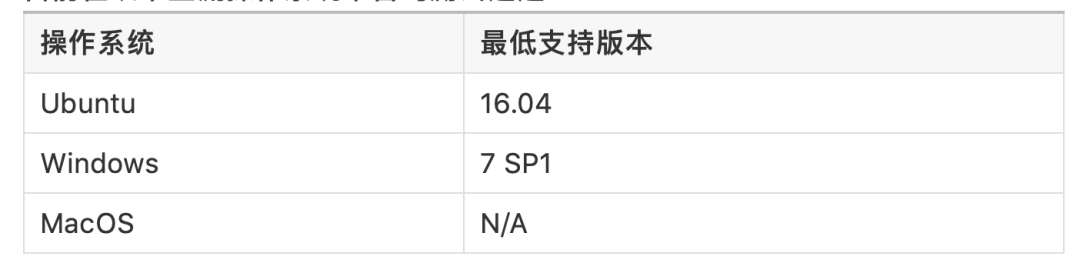
目前在以下主流操作系统平台均测试通过:
本训练项目主要的环境依赖清单如下
2.1.1 Ubuntu 16.04 下的 Python 3.6
1)先安装Python环境
sudo apt-get install openssl
sudo apt-get install libssl-dev
sudo apt-get install libc6-dev gcc
sudo apt-get install -y make build-essential zlib1g-dev libbz2-dev libreadline-dev $ libsqlite3-dev wget curl llvm tk-dev
wget https://www.python.org/ftp/python/3.6.6/Python-3.6.6.tgz
tar -vxf Python-3.6.6.tar.xz
cd Python-3.6.6
./configure --prefix=/usr/local --enable-shared
make -j8
sudo make install -j8
经过上面指令就安装好Python3.6环境了,如果提示找不到libpython3.6m.so.1.0就到/usr/local/lib路径下将该文件复制一份到/usr/lib和/usr/lib64路径下。
2)安装相关依赖(这一步Windows和Linux通用)
可以直接在项目路径下执行pip3 install -r requirements.txt安装所有依赖,注意这一步是安装在全局Python环境下的,强烈建议使用虚拟环境进行项目间的环境隔离,如Virtualenv或Anaconda等等。
我一般使用的是Virtualenv,有修改代码需要的,建议安装PyCharm作为Python IDE
virtualenv -p /usr/bin/python3 venv # venv is the name of the virtual environment.
cd venv/ # venv is the name of the virtual environment.
source bin/activate # to activate the current virtual environment.
cd captcha_trainer # captcha_trainer is the project path.
pip3 install -r requirements.txt
2.1.2 Ubuntu 16.04 下的 CUDA/cuDNN
网上看到过很多教程,我自己也部署过很多次,Ubuntu 16.04遇到的坑还是比较少的。14.04支持就没那么好,如果主板不支持关闭SecureBoot的话千万不要安装Desktop版,因为安装好之后一定会无限循环在登陆界面无法进入桌面。
网上教程说要加驱动黑名单什么的我直接跳过了,亲测没那个必要。就简单的几步:
1. 下载好安装包
注意下载runfile类型的安装包,deb安装会自动安装默认驱动,极有可能导致登陆循环。
NVIDIA 驱动下载:
https://www.geforce.cn/drivers
CUDA 下载地址:
https://developer.nvidia.com/cuda-downloads
cuDNN 下载地址:
https://developer.nvidia.com/cudnn
(需要注册NVIDIA账号且登陆,下载deb安装包)
2. 关闭图形界面
Ctrl+alt+F1进入字符界面,关闭图形界面
sudo service lightdm stop
3. 安装Nvidia Driver
命令中的版本自己对应下载的版本改,在上面的下载地址根据自己的显卡型号下载最新版,切记是runfile格式的安装包。
sudo chmod a+x NVIDIA-Linux-x86_64-384.90.run //获取执行权限
sudo ./NVIDIA-Linux-x86_64-384.90.run –no-x-check –no-nouveau-check –no-opengl-files //安装驱动
安装成功以后使用以下命令验证,如果显示显卡信息则表示安装成功
nvidia-smi
4. 安装CUDA
先安装一些系统依赖库
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
执行安装程序,按指示无脑继续就好了,如果提示是否安装驱动选不安装。
sudo sh cuda_9.0.176_384.81_linux.run
安装完如果环境变量没配上去,就写到 ~/.bashrc 文件的尾部
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
然后在终端执行 sudo ldconfig更新,安装完毕就可以重启机器重启图形界面了。
sudo service lightdm start
2.1.3 Windows 系统
在Windows其实简单很多,只要到官网下载安装包无脑安装就可以了,下载连接同Ubuntu,先安装Python,显卡驱动,CUDA,然后下载对应的cuDNN替换到对应路径即可。
花了超长篇幅介绍了训练环境的基本搭建,主要是给尚未入门的读者看的,老鸟们随便跳过。
3.使用
入手的第一步环境搭建好了,那就是准备跑代码了,还是有几个必要的条件,巧妇难为无米之炊,首先,既然是训练,要先有训练集,有一个新手尝鲜的训练集,是mnist手写识别的例子,可以在腾讯云下载:https://share.weiyun.com/5pzGF4V,现在万事俱备,只欠东风。
3.1 定义一个模型
本项目采用的是参数化配置,不需要改动任何代码,可以训练几乎任何字符型图片验证码,下面从两个配置文件说起:
# - requirement.txt - GPU: tensorflow-gpu, CPU: tensorflow
# - If you use the GPU version, you need to install some additional applications.
# TrainRegex and TestRegex: Default matching apple_20181010121212.jpg file.
# - The Default is .*?(?=_.*\.)
# TrainsPath and TestPath: The local absolute path of your training and testing set.
# TestSetNum: This is an optional parameter that is used when you want to extract some of the test set
# - from the training set when you are not preparing the test set separately.
System:
DeviceUsage: 0.7
TrainsPath: 'E:\Task\Trains\YourModelName\'
TrainRegex: '.*?(?=_)'
TestPath: 'E:\Task\TestGroup\YourModelName\'
TestRegex: '.*?(?=_)'
TestSetNum: 1000
# CNNNetwork: [CNN5, DenseNet]
# RecurrentNetwork: [BLSTM, LSTM]
# - The recommended configuration is CNN5+BLSTM / DenseNet+BLSTM
# HiddenNum: [64, 128, 256]
# - This parameter indicates the number of nodes used to remember and store past states.
NeuralNet:
CNNNetwork: CNN5
RecurrentNetwork: BLSTM
HiddenNum: 64
KeepProb: 0.98
# SavedSteps: A Session.run() execution is called a Steps,
# - Used to save training progress, Default value is 100.
# ValidationSteps: Used to calculate accuracy, Default value is 100.
# TestNum: The number of samples for each test batch.
# - A test for every saved steps.
# EndAcc: Finish the training when the accuracy reaches [EndAcc*100]%.
# EndEpochs: Finish the training when the epoch is greater than the defined epoch.
Trains:
SavedSteps: 100
ValidationSteps: 500
EndAcc: 0.975
EndEpochs: 1
BatchSize: 64
TestBatchSize: 400
LearningRate: 0.01
DecayRate: 0.98
DecaySteps: 10000
上面看起来好多好多参数,其实大部分可以不用改动,你需要修改的仅仅是训练集路径就可以了,注意:如果训练集的命名格式和我提供的新手训练集不一样,请根据实际情况修改TrainRegex和TestRegex的正则表达式。
TrainsPath和TestPath路径支持list参数,允许多个路径,这种操作适用于需要将多种样本训练为一个模型,或者希望训练一套通用模型的人。为了加快训练速度,提高训练集读取效率,特别提供了make_dataset.py来支持将训练集打包为tfrecords格式输入,经过make_dataset.py打包之后的训练集将输出到本项目的dataset路径下,只需修改TrainsPath键的配置如下即可。
TrainsPath: './dataset/xxx.tfrecords'
TestPath是允许为空的,如果TestPath为空将会使用TestSetNum参数自动划分出对应个数的测试集。如果使用自动划分机制,那么TestSetNum测试集总数参数必须大于等于TestBatchSize测试集每次读取的批次大小。
神经网络这块可以讲一讲,默认提供的组合是CNN5(CNN5层模型)+BLSTM(Bidirectional LSTM)+CTC,亲测收敛最快,但是训练集过小,实际图片变化很大特征很多的情况下容易发生过拟合。DenseNet可以碰运气在样本量很小的情况下很好的训练出高精度的模型,为什么是碰运气呢,因为收敛快不快随机的初始权重很重要,运气好前500步可能对测试集就有40-60%准确率,运气不好2000步之后还是0,收敛快慢是有一定的运气成分的。
NeuralNet:
CNNNetwork: CNN5
RecurrentNetwork: BLSTM
HiddenNum: 64
KeepProb: 0.99
隐藏层HiddenNum笔者尝试过8~64,都能控制在很小的模型大小之内,如果想使用DenseNet代替CNN5直接修改如上配置中的CNNNetwork参数替换为:
NeuralNet:
CNNNetwork: DenseNet
......
model.yaml # 模型配置
# ModelName: Corresponding to the model file in the model directory,
# - such as YourModelName.pb, fill in YourModelName here.
# CharSet: Provides a default optional built-in solution:
# - [ALPHANUMERIC, ALPHANUMERIC_LOWER, ALPHANUMERIC_UPPER,
# -- NUMERIC, ALPHABET_LOWER, ALPHABET_UPPER, ALPHABET]
# - Or you can use your own customized character set like: ['a', '1', '2'].
# CharExclude: CharExclude should be a list, like: ['a', '1', '2']
# - which is convenient for users to freely combine character sets.
# - If you don't want to manually define the character set manually,
# - you can choose a built-in character set
# - and set the characters to be excluded by CharExclude parameter.
Model:
Sites: []
ModelName: YourModelName-CNN5-H64-150x50
ModelType: 150x50
CharSet: ALPHANUMERIC_LOWER
CharExclude: []
CharReplace: {}
ImageWidth: 150
ImageHeight: 50
# Binaryzation: [-1: Off, >0 and < 255: On].
# Smoothing: [-1: Off, >0: On].
# Blur: [-1: Off, >0: On].
# Resize: [WIDTH, HEIGHT]
# - If the image size is too small, the training effect will be poor and you need to zoom in.
# - ctc_loss error "No valid path found." happened
Pretreatment:
Binaryzation: -1
Smoothing: -1
Blur: -1
上述的配置只要关注ModelName、CharSet、ImageWidth、ImageHeight。
首先给模型取一个好名字是成功的第一步,字符集CharSet其实大多数情况下不需要修改,一般的图形验证码离不开数字和英文,而且一般来说是大小写不敏感的,不区分大小写,因为打码平台收集的训练集质量参差不齐,有些大写有些小写,不如全部统一为小写,默认ALPHANUMERIC_LOWER则会自动将大写的转为小写,字符集可定制化很灵活,除了配置备注上提供的几种类型,还可以训练中文,自定义字符集用list表示,示例如下:
CharSet: ['常', '世', '宁', '慢', '南', '制', '根', '难']
可以自己根据收集训练集的实际字符集使用率来定义,也可以无脑网上找3500常用字来训练,注意:中文字符集一般比数字英文大很多,刚开始收敛比较慢,需要更久的训练时间,也需要更多的样本量,请量力而行。

形如上图的图片能轻松训练到95%以上的识别率。
ImageWidth、ImageHeight只要和当前图片尺寸匹配即可,其实这里的配置主要是为了方便后面的部署智能策略。
其他的如Pretreatment之下的参数是用来做图片预处理的,因为笔者致力于做一套通用模型,模型只使用了灰度做预处理。其中可选的二值化、均值滤波、高斯模糊均未开启,即使不进行那些预处理该框架已经能够达到很理想的识别效果了,笔者自用的大多数模型都是98%以上的识别率。
3.2 开始训练
按照上面的介绍,配置只要修改极少数的参数对应的值,就可以开启正式的训练之旅了,具体操作如下:
可以直接使用PyCharm的Run,执行trains.py,也可以在激活Virtualenv下使用终端亦或在安装依赖的全局环境下执行。
python3 trains.py
剩下的就是等了,看过程,等结果。正常开始训练的模样应该是这样的:
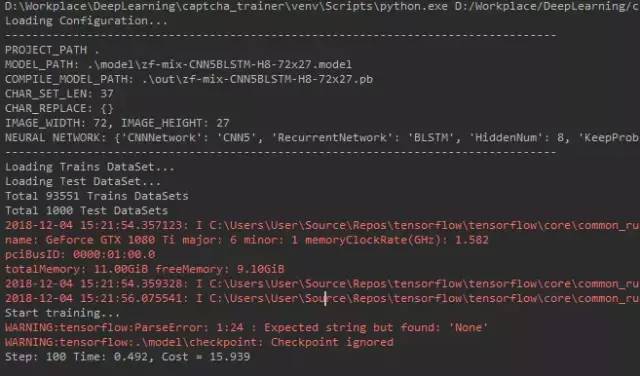
训练结束会在项目的out路径下生成一个pb和yaml文件,下面该到部署环节了。
3.3 部署
真的很有必要认真的介绍一下部署项目,比起训练,这个部署项目倾注了笔者更多的心血,为什么呢?
项目地址:
https://github.com/kerlomz/captcha_platform
真的值得了解的几点:
同时管理多个模型,支持模型热拔插
灵活的版本控制
支持批量识别
服务智能路由策略
首先笔者重写了Tensor Flow的Graph会话管理,设计会话池,允许同时管理多模型,实现多模型动态部署方案。
1)训练好的pb模型只要放在部署项目的graph路径下,yaml模型配置文件放在model,即可被服务发现并加载;
2)如果需要卸载一个正在服务的模型,只需要在model中删除该模型的yaml配置文件,在graph中删除对应的pb模型即可;
3)如果需要更新一个已经服务中的模型,只需修改新版的模型yaml配置文件的版本号高于原模型的版本号,按先放pb后放yaml的顺序,服务便会自动发现新版的模型并加载使用,旧的模型将因版本低于新版模型不会被调用,可以按照上述的卸载方法卸载已被弃用的模型释放内存。
上面的操作中无需重启服务,完全的无缝切换。
Linux:
Tornado:
# 端口 19952
python3 tornado_server.py
Flask
# 方案1,裸启动, 端口 19951
python flask_server.py
# 方案2,使用gunicorn,端口 5000
pip install gunicorn
gunicorn -c deploy.conf.py flask_server:app
Sanic:
# 端口 19953
python3 sanic_server.py
gRPC:
# 端口 50054
python3 grpc_server.py
Windows:
Windows平台下都是通过python3 xxx_server.py启动对应的服务,注意,Tornado、Flask、Sanic的性能在Windows平台都大打折扣,gRPC是Google开源的RPC服务,有较为优越的性能。
3.4 调用/测试
1. Flask服务:

具体参数:
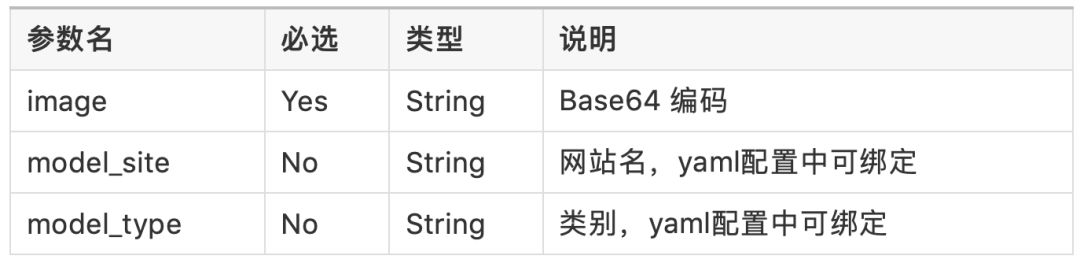
请求为JSON格式,形如:{"image": "base64编码后的图像二进制流"}
返回结果:
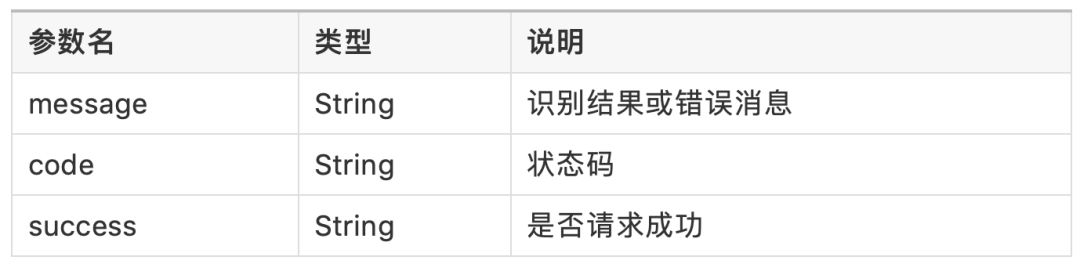
该返回为JSON格式,形如:{"message": "xxxx", "code": 0, "success": true}
2. Tornado服务:

请求参数和返回格式同上
3. Sanic服务:

请求参数和返回格式同上
4. gRPC服务:
需要安装依赖,grpcio、grpcio_tools和对应的grpc.proto文件,可以直接从项目中的示例代码demo.py中提取。
class GoogleRPC(object):
def __init__(self, host: str):
self._url = '{}:50054'.format(host)
self.true_count = 0
self.total_count = 0
def request(self, image, model_type=None, model_site=None):
import grpc
import grpc_pb2
import grpc_pb2_grpc
channel = grpc.insecure_channel(self._url)
stub = grpc_pb2_grpc.PredictStub(channel)
response = stub.predict(grpc_pb2.PredictRequest(
image=image, split_char=',', model_type=model_type, model_site=model_site
))
return {"message": response.result, "code": response.code, "success": response.success}
if __name__ == '__main__':
result = GoogleRPC().request("base64编码后的图片二进制流")
print(result)
3.5 奇技淫巧
该项目还可以直接用于识别带颜色的图片,本质是不同的颜色分别训练,调用的时候通过传参区分,如果希望获得图片中红色的文字,就直接通过参数定位到训练红色的模型,希望获取图片中蓝色的图片就通过参数定位到蓝色模型,如:
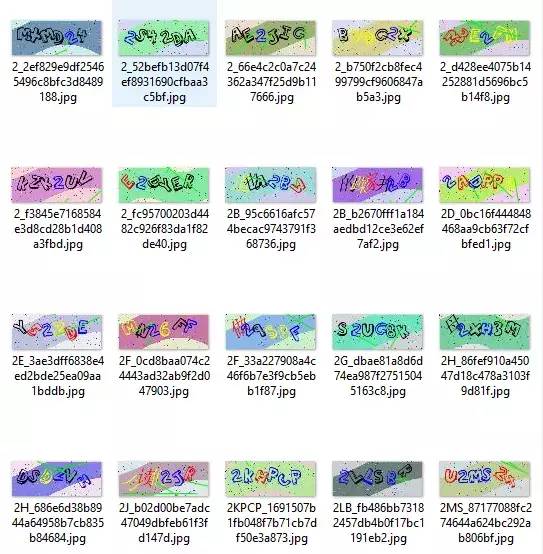

不过这种操作对样本量要求较高,且效率不高,当颜色参数越来越多时就不适用,可以采用颜色提取的方式,这样所需要的样本量将大大减少,但对于颜色提取算法效果要求高了。
还有一种方案是同时预测验证码和每个字符对应的颜色,不过这需要修改现有的神经网络进行支持,在最后一层修改为双输出,一个输出颜色,一个输出对应字符,这对于样本标注的要求较高,也提高的成本,所以如果能用无限生成样本,那问题就迎刃而解了,比如上图,笔者就写了样本生成代码,感兴趣的可以移步:
https://www.jianshu.com/p/da1b972e24f2
其实还有很多很多技巧,例如,用生成的样本代替训练集,其实网上的图片验证码大多是采用开源的,稍作修改而已,大多数情况都能被近似生成出来,上述展示的验证码图片不代表任何实际的网站,如有雷同,纯属巧合,该项目只能用于学习和交流用途,不得用于非法用途。
项目传送门:
https://github.com/kerlomz/captcha_trainer
(本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
5月25-27日,由中国IT社区CSDN与数字经济人才发展中心联合主办的第一届CTA核心技术及应用峰会将在杭州国际博览中心隆重召开,峰会将围绕人工智能领域,邀请技术领航者,与开发者共同探讨机器学习和知识图谱的前沿研究及应用。
目前,会议双日开发者299元盲订票抢购中(原票价1099元),4月23日最后1天,点击阅读原文即刻抢购。扫码添加小助手,备注CTA,了解大会详情。

推荐阅读
深入卷积神经网络背后的数学原理 | 技术头条
开什么玩笑?股票价格如何经得起AI的推敲?| 技术头条
用Python做数据分析,这些基本数据分析技术你知道吗?
Python基础入门:基础语法和变量类型
源码泄露是裁员报复还是程序员反抗 996?
裁员25%, 梅西也拯救不了全球第一款区块链手机!
强推!十大顶级大数据可视化工具 | 程序员硬核评测
程序员的双肩包,大概能装下整个宇宙!
程序员如何向女友解释:为啥软件都要装C盘?

❤点击“阅读原文”,查看更多精彩文章。
相关文章:

MySql练习题参考答案
表结构: /*Navicat Premium Data TransferSource Server : localhostSource Server Type : MySQLSource Server Version : 50624Source Host : localhostSource Database : sqlexamTarget Server Type : MySQLTarget Server Version …

【Qt】Qt源码中涉及到的设计模式
1、单例模式 qApp宏返回指向QApplication的单例 #define qApp (static_cast<QApplication *>(QCoreApplication::instance()))2、MVC模型视图控制器框架 模型是应用程序对象、视图是它的屏幕显示、控制器定义了用户界面对用户输入的反应。 Qt的模型视图框架是经典的MV…
从当前日期算起,获取几天前的日期和几个月前的日期
/*** 从当前日期算起,获取N天前的日期(当前日不算在内),日期格式为yyyy-MM-dd* * param daily 天数* return */public static String getDateByDay(Integer daily) {Date date new Date();int year Integer.parseInt(new Simple…

清华大学人工智能研究院成立听觉智能研究中心,将专注基础研究和成果产业化
4月22日,清华大学人工智能研究院听觉智能研究中心(以下简称听觉中心)成立仪式暨学术前沿报告会在清华大学FIT楼举行。 清华大学副校长、人工智能研究院管委会主任尤政院士在致辞中表示,成立听觉中心是清华大学加速推进人工智能发…

两道面试题,带你解析Java类加载机制
2019独角兽企业重金招聘Python工程师标准>>> 在许多Java面试中,我们经常会看到关于Java类加载机制的考察,例如下面这道题: class Grandpa {static{System.out.println("爷爷在静态代码块");} } class Father extend…
【Qt】监视文件和目录的修改:QFileSystemWatcher
一、说明 QFileSystemWatcher用于监视指定文件或目录列表的更改。 注意:监视文件或目录时需要打开相应的文件描述符,因此被监视的文件或目录数据是有限的,受系统允许的文件描述符数据等限制。 二、常用成员函数 1、public 构造、析构函数: QFileSystemWatcher(const QS…
asp.net 2.0中新增的AppendDataBoundItems .dropdownlist 添加第一项
在asp.net 2.0中,新增了一个AppendDataBoundItems属性,十分方便,使可以在执行数据绑定之前将项添加到 listcontrol 对象中。执行数据绑定之后,项集合中包含数据源中的项以及以前添加的项。如果不在绑定数据之前清除列表项…

用Python实现OpenCV特征提取与图像检索 | Demo
参加「CTA 核心技术及应用峰会」,请扫码报名 ↑↑↑作者|Andrey Nikishaev翻译 | 张蔚敏审校 | reason_W来源 | Python大本营(id:pythonnews)“拍立淘”“一键识花”“街景匹配”……不知道大家在使用这些神奇的功能的时候&#x…
【ffmpeg】编译时报错:error: undefined reference to `av...
1、问题描述 昨天使用ffmpeg库编译demo一切正常,今天再次链接ffmpeg库时报了一堆错误: error: undefined reference to `av_frame_alloc() error: undefined reference to `avio_close(AVIOContext*) error: undefined reference to `avcodec_find_encoder(AVCodecID) erro…
Spring Initializr 构建Spring Boot/Cloud工程
2019独角兽企业重金招聘Python工程师标准>>> 在之前的所有Spring Boot和Spring Cloud相关博文中,都会涉及Spring Boot工程的创建。而创建的方式多种多样,我们可以通过Maven来手工构建或是通过脚手架等方式快速搭建,也可以通过《Sp…

linux下用phpize给PHP动态添加扩展
使用php的常见问题是:编译php时忘记添加某扩展,后来想添加扩展,但是因为安装php后又装了一些东西如PEAR等,不想删除目录重装,别说,php还真有这样的功能。 我没有在手册中看到。 如我想增加bcmath支持&…

“996 是福利,007 才是常态”?!千万程序员怒怼每日优鲜!
呔!热度不是你想蹭,想蹭就能蹭……作者 | 仲培艺封图 | CSDN 付费下载自东方IC出品 | 程序人生(ID:coder_life)App Store 评分一日之间从 4.5 断崖直降至 1.5,每日优鲜这是怎么了?究其原因——大…
亚太信息安全领袖成就表彰计划:阿里成中国互联网公司唯一代表
近日,全球最大的信息安全非营利会员组织(ISC)公布了第十二届年度亚太区信息安全领袖成就(亚太区ISLA)表彰计划的获奖者,共有17名人员获得此项殊荣。据悉,(ISC)将于2018年7月9日在香港举行的庆典活动中表彰这17名获奖者…
【C++】clipp 一个命令行参数解析器
1、简介 clipp是一个使用方便、功能强大的命令行解析器,源码只有一个头文件《clipp.h》 github地址:https://github.com/muellan/clipp 2、使用 只演示最简单的例子,更复杂的参见源码中《README.md》。 例如需要如下命令行参数 用法&…
Oracle 聚合函数(Aggregate Functions)说明
Oracle Aggregate Functions用过很多,官网的说明如下:Aggregate Functionshttp://docs.oracle.com/cd/E11882_01/server.112/e26088/functions003.htm#SQLRF20035Aggregatefunctions return a single result row based on groups of rows, rather than o…
【OpenCV】正确创建用于保存YUV420P格式的cv::Mat
1、问题描述 cv::Mat保存RGB24或BRG24格式时,传入宽、高和格式类型CV_8UC3就行了;今天在创建cv::Mat用来保存YUV420P时,有点懵圈了,因为类型是CV_8UC1,直接传宽和高,只能保存Y分量。因此需要宽或者高乘以一…
特斯拉全新自动驾驶芯片最强?英伟达回怼,投资者用脚投票
整理 | 一一出品 | AI科技大本营(ID:rgznai100)马斯克前脚刚说完自家发布的自动驾驶计算机是全球最强,后脚就被英伟达怼了。在刚刚结束的自动驾驶投资者日上,特斯拉发布了全自动驾驶(FSD)计算机(…
2012年我的十大工程9——形象工程
形象对于每一个人来说都很重要,人以群分,物以类聚!说的就是这个道理,不同的人接触不同的社会,不同的级别接触不同的层面。还记得我【千日计划】项目中怎么说的吗?第七项:改良自己的外貌形象。老…
【MySQL】ubuntu16.04安装mysql,然后源码编译Qt5.12.4版本的libqsqlmysql.so
一、Ubuntu16.04.5 安装 MySQL 1、使用apt命令安装 sudo apt install mysql-server安装过程会提示,推荐设置MySQL的root用户密码(注意:这里root不是指ubuntu系统的root) While not mandatory, it is highly recommended that you set a password for the MySQL administr…

A* 算法之父、人工智能先驱Nils Nilsson逝世 | 缅怀
整理 | 琥珀出品 | AI科技大本营(id:rgznai100)2019 年 4 月 23 日,人工智能学科创始研究者之一、斯坦福大学计算机科学系 Kumagai 教授 Nils J. Nilsson 逝世,享年 86 岁。Nils J. Nilsson(1933 年 2 月 6…
类执行方法的过程与运行时
大家都知道,调用一个未声明方法大多数情况下会崩溃,崩溃信息就是unrecognized selector sent to instance;是的,的确大多数情况下是这样的,但是有了运行时就不一定了,这就是我今天的主题——“安全类”(哈哈…
NandFlash系列之一:NorFlash与NandFlash对比
NandFlash系列之一:NorFlash与NandFlash对比作者:刘洪涛,华清远见嵌入式学院高级讲师。FLASH存储器又称闪存,主要有两种:NorFlash和NandFlash,下面我们从多个角度来对比介绍一下。在实际开发中,…
机器学习萌新必备的三种优化算法 | 选型指南
作者 | Nasir Hemed编译 | Rachel出品 | AI科技大本营(id:rgznai100)【导读】在本文中,作者对常用的三种机器学习优化算法(牛顿法、梯度下降法、最速下降法)进行了介绍和比较,并结合算法的数学原…
【MySQL】缩略语PK NN UQ BIN UN ZF AI G、基本操作语句
一、缩略语 PK:primary key 主键 NN:not null 非空 UQ:unique 唯一索引 BIN:binary 二进制数据 UN:unsigned 无符号整数(非负数) ZF:zero fill 填充0 例如字段内容是1 int(4), 则内…

C#(WPF)去除事件中注册的事件处理方法!
在WPF中,移除一个事件中已经注册的处理方法,看似简单,实际还是很痛苦的一件事情。因为C#的灵活性,定义事件的方法也是多种多样。我自己定义了一个事件: public event EventHandler TestEvent; 当我想注销这个事件上注册…

memcached图形界面的监控
wget http://livebookmark.net/memcachephp/memcachephp.zip 前提是已经安装了php和memcached 图形界面的监控是通过memcache.php来实现的, 1.把该php程序拷贝到nginx的html根目录 [rootcacti srv]# cd /usr/local/nginx/html 2. 更改相应的连接IP和端口…

薅百度GPU羊毛!PaddlePaddle大升级,比Google更懂中文,打响AI开发者争夺战
记者 | 阿司匹林出品 | AI科技大本营(ID: rgznai100)深度学习已经推动人工智能进入工业大生产阶段,而深度学习框架则是智能时代的操作系统。在4月23日下午的Wave Summit深度学习开发者峰会上,百度高级副总裁王海峰开场就为深度学习…
vue中axios如何实现token验证
title: vue中axios如何实现token验证 date: 2018-02-08 17:50:07 tags: [axios,vue] 继上篇实现Auth认证之后,然后每个跳转页面都会在后端验证token的存在 然后那天晚上通过模仿Auth发送请求,发送成功(上篇末尾的方式) 但是今天再继续写,发现每个页面请求都要发送token验证 就比…
【视频】视频方面大神博客总结
1、雷霄骅博客 [总结]视音频编解码技术零基础学习方法:雷神对音视频技术的总结,包括:视频播放器原理、流媒体协议、封装格式、视频编码、音频编码、网络视音频平台对比。首先对雷神的顶礼膜拜,学完这篇博客,就算跨入音…
IHttpHandler 在SharePoint中的应用
1. 一个文件名为VCChartHandler.ashx,其文件代码为: <% WebHandler Language"C#" Class"VCSharePoint.BL.VCHandler,VCSharePoint, Version1.0.0.0, Cultureneutral, PublicKeyToken0134fd28ed40d3b2"%>2. 另一个类为VCHandler.cs的文件…