Yann LeCun推荐!自监督学习、全景FPN...内容平台的四大技术指南

编译整理 | 一一
出品 | AI科技大本营(ID:rgznai100)
去年陷入“数据丑闻”后的 Facebook 日子并不好过,在这之后他们对外界强调的关键词大部分都是“隐私”和“安全”。即便如此,在刚刚过去的 Facebook F8 大会上,扎克伯格忍不住自嘲,由于在数据隐私方面的问题,很多人依然不信任 Facebook。
不过,不止 Facebook 一家公司,如何使用现有的 AI 等技术最大限度保护用户不受伤害是每个公司都要不断探索的问题。而对于经历过一年大风浪的世界级企业, Facebook 为重视数据隐私和平台安全的努力也有目共睹。
Facebook CTO Mike Schroepfer 和 Facebook AI 部门的研究科学家 Manohar Paluri 在近日的 F8 大会上发表了主题演讲,他们主要谈到了如何使用 AI 技术来保护平台用户安全地使用产品,需要做到两点:1、理解内容;2、Facebook 如何使用自监督学习方法来提高内容识别的准确性,同时减少翻译、NLP、图像识别等应用中对标记数据的要求。
Yann LeCun 对此评论称,这有助于改进对具有暴力画面、仇恨的言论、干扰选举、错误信息、僵尸账户等违规内容的过滤。
抛开对 Facebook 依然怀疑的目光,我们或许更应该去看看它在技术上到底做了哪些努力,他们的 AI 等技术实践也可能对其他公司在保护用户数据和使用体验方面有重要的技术指导意义。
具体技术细节,都在以下演讲全文里:
AI 在 Facebook 的各种应用中无处不在,其中最重要的一项工作是帮助我们平台上的用户安全使用。
为了使所有这些系统更加有效,我们需要在两个方面继续改进 AI 技术:理解内容以及使用少量的标记训练数据高效工作。
我们最近在 NLP和 CV 方面取得的进展表明,内容理解方面的工作如何产生效益。在 NLP 领域,我们开发了一个共享的多语言嵌入空间,可以作为一种通用语言来对有害内容进行处理,即使在资源匮乏的语言中也是如此。在 CV 领域,基于行业领先的研究基础,我们可以识别图像中更多部分的内容,并使用标签为视频理解实现创纪录的准确性。
随着我们理解内容的能力在不同模式下不断提升,我们在自监督技术的新前沿也取得了进展。这种技术将通过预训练系统加速学习,可以成为下一代更快、更灵活工具的基础技术。
我们将在此重点介绍 Facebook 如何提高内容理解系统的准确性和效率,并找到通过较少监督学习方法来完成更多工作的新方法。
一、使用多语言句子嵌入来处理违规内容
为了检测人们何时发布了违规内容,我们的系统需要理解语言。具体来说,我们的系统使用机器学习来扫描给定的句子并回答一系列问题,例如“它是否有害的(hateful)?”使用这些问题的答案,以及互动的语境和其他信号,我们可以确定系统是否采取行动,例如标记给人工审核员。
为了让 ML 系统来回答这些问题,我们则需要用给定语言的数千个例子来进行训练。世界上大约有 6500 种语言,这包括目前缺乏大量培训数据集的语言,找到足够的例子来开发支持所有语言的内容理解系统是巨大的挑战。
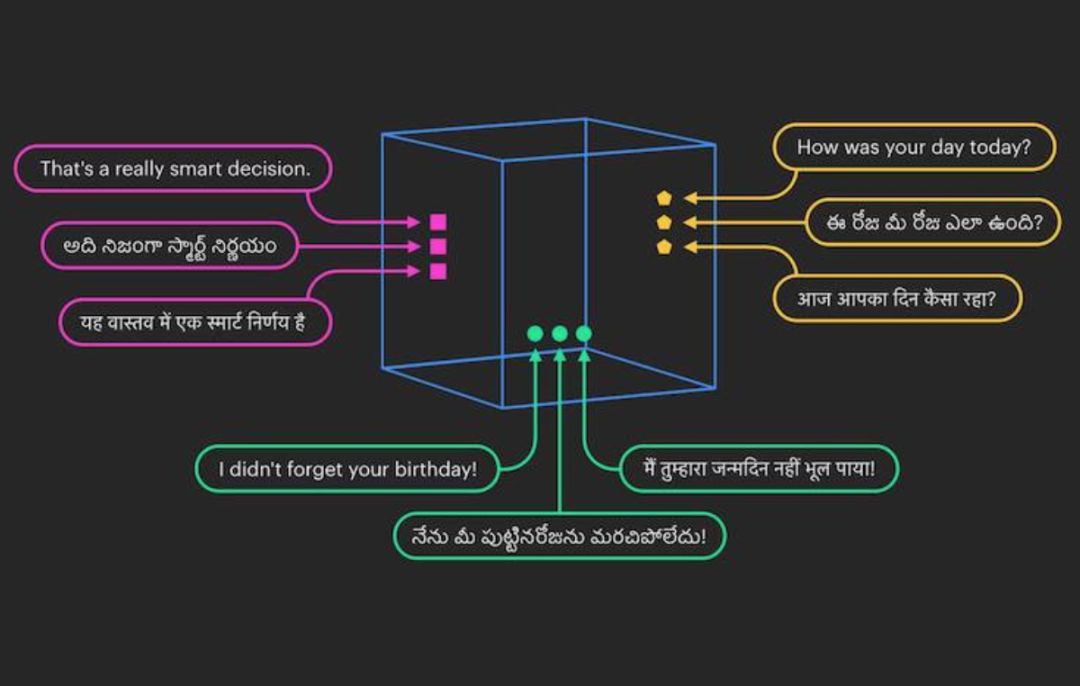
通过在共享嵌入空间中以多种语言映射相似的句子,我们可以更好地理解相关内容而无需翻译每个句子。
为了帮助解决训练数据的稀缺性,我们正利用我们最近开源的工具包 LASER(Language-Agnostic SEntence Representations),该工具包通过训练单个模型来理解大量语言。以前我们需要为每种语言准备不同的模型,LASER 的表示空间允许我们训练一种语言模型,然后将该模型应用于一系列语言,而无需特定语言的训练数据,也无需进行翻译,这被称为“零样本迁移学习(zero-shot transfer learning)”。LASER 还允许我们通过在语言未知的表示空间内将这些句子相互映射,来识别出在意义上相似的句子。
LASER 开源地址:https://github.com/facebookresearch/LASER
对于希望系统可以增加理解语言数量的研究人员来说,这样的跨语言技术提供了一种更具可扩展性的替代方案,可以尝试收集和注释每种语言的数据。这种方法还允许我们挖掘用于机器翻译的并行训练数据,并且对于低数据资源语言(我们的训练示例较少)特别有用。识别跨语言的类似句子有助于同时捕获多种语言的类似违规行为。为了生成每个句子级别的嵌入,我们首先使用字节对编码表示给定句子的单词,然后使用一个五层双向 LSTM(长短期记忆)模型,然后是最大池化(max pooling)操作(因为句子包含任意字数)。
通过大规模训练这个系统——93 种语言,属于 30多个语系并用 22 种不同的脚本编写,我们能够获得与语言无关的句子嵌入,并且能够支持自动检测违规行为的这种能力尤其与低资源语言相关。
这种方法与我们的跨语言预训练研究一起,将提高我们以多种语言处理仇恨言论、欺凌和其他违规行为的能力,而无需额外语言标记的训练数据。这两种技术都将支持我们现有的多语言词汇嵌入,它将来自不同语言的相似词语映射到同一个空间(与 LASER 的句子级别映射相反)。这些嵌入已经部署到生产中,用于包括识别违规内容等广泛的跨语言理解任务。
二、全景 FPN:图片和视频理解的最新技术
人们在我们的平台上分享了数十亿张图片,那么理解其中的内容对保护人们的安全至关重要。即使是简单的像素分析可能足以让我们的系统识别图片中的单个对象,我们甚至可以进一步推动业界领先的 CV 能力,并让系统了解这些对象之间的联系,以判断违规行为。
(注:近日,基于何恺明团队提出的“全景分割”任务开始变得热门,今年1月他们公布了《Panoptic Feature Pyramid Networks》论文。)
论文链接:https://arxiv.org/abs/1901.02446
我们的系统擅长识别图片前景中的对象,例如狗或球,但目前还是难以理解面积较大,包含较少像素集合的构成图片的背景。使用全景 FPN(Panoptic FPN)这种新的对象识别方法,我们可以在一个统一的神经结构上同时执行实例分割任务(用于前景)和语义分割任务(用于背景)。
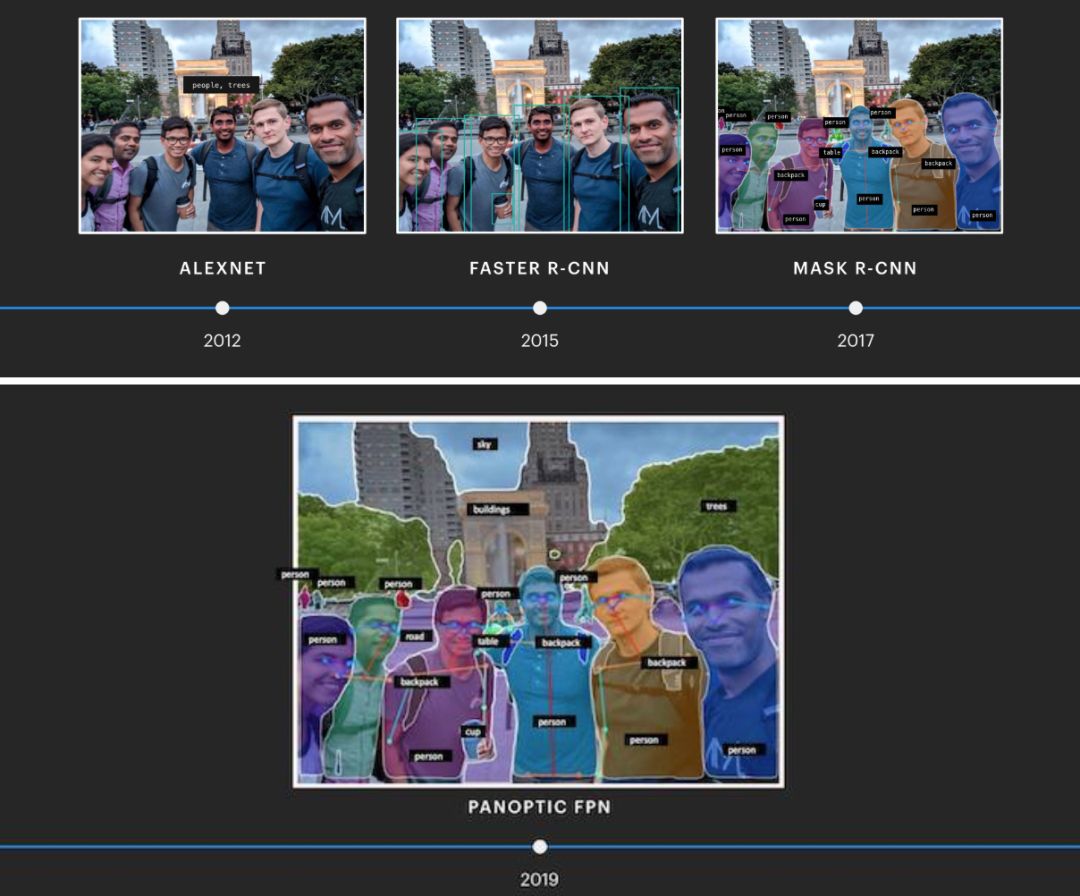
多年来,Facebook 的 CV 系统逐渐识别到更多的图像组件,现在可以通过单个网络检测前景和背景中的对象。这样可以更好地理解照片的整体背景,以及更高计算效率的图像识别。
Facebook 的实践结果表明,与只做一个或其他网络相比,全景 FPN 几乎可以将执行实例和语义分段所需的整体计算效率提升一半。在实践中能使系统更好地了解图像,这在判定是否违规时很重要。但是这项工作也会影响其他应用,例如可能会改变我们用来向视障人士描述图像的自动转换文字功能。
与图片中的查找违规行为相比,在视频中的难度是数量级的。理解视频意味着要考虑构成给定帧序列的大量图像和该序列中所表示的移动,同时还要处理非视觉输入,例如音频。
由于存在这样的挑战,视频理解还处于起步阶段。我们在准确性和效率方面始终如一地在推动最先进的技术,部分是通过将系统的注意力和训练集中在最相关的数据上。例如,通过将 3D 卷积分解为 2D 和 1D 卷积(分别与给定视频序列中的空间和时间相关),我们减少了可训练参数的数量。或者,我们可以保持相同数量的参数并提高准确性。总之使用此框架,我们可以找到准确性和效率之间的平衡点。

不同于将给定视频中的每一帧传递给时空卷积神经网络,我们的显着性采样方法是将包含显着性动作的视频隔离开来进行进一步地处理。
为了理解视频中发生的事情,我们将其分解为短片段(每个片段由少量连续帧组成),并通过我们最新的时空模型发送一小组连续帧。然后,我们可以汇总这些信息预测整个视频内容。
然而,在许多视频中,只有少数片段具有针对特定任务的显著性信息,其余的片段则是冗余的或不相关的,例如检测欺凌视频。因此,为了进一步提高视频中发现可操作事件的速度和效率,我们创建了一个显着性采样器。该系统经过训练,专注于包含特定行为的部分,然后更详细地处理这些帧集。这种更有针对性的分析和训练能更快、更准确地视频理解内容。
三、将标签用于视频理解的创纪录准确性
我们还开发了一种不同的方法为识别行为设定了新的技术方法,包括指出内容违规的行为。
这种技术直接建立在我们去年在 F8 大会(2018年5月)上公布的研究成果上,该研究使用带有标签的数十亿公共图像来训练网络,并且能够在图像识别任务中击败最先进的技术。在我们的新方法中,带标签的数据充当了弱监督数据,这意味着标记的训练示例是可使用的,但这并没有完全监督的精确度。
与专门用于训练 AI 模型的标签相比,这样得到的注释噪音大且不精确。但是,这种方法所提供的标记示例的数量表明,我们可以基于前所未有的大量训练数据,而不是通过基于弱监督的训练数据来显着改善视频理解。
在这种情况下,我们训练的最大数据集包含超过 6500 万个带有标签的公共 Instagram 视频。相比之下,当前的行动分类数据集仅包含几十万个视频。使用这些视频带来的技术挑战与十亿次数量级别的图像识别工作类似,例如必须在硬件上进行分布式训练,也有新的挑战,包括处理通常只适用于视频一小部分的标签的事实,比如一个标记为#wedding 和 #dance 的视频可能只是一对新婚夫妇在长时视频中花了几秒钟在跳舞。
尽管存在这种随机噪声问题,但我们发现内容的多样性和示例的绝对规模抵消了标签噪声。通过使用我们的显着性采样器,视频识别模型在三个主要的视频分类基准测试中实现了最先进的精度。这包括在将视频分类为 400 种不同的人类行为类别之一时,在动力学数据集上达到 82.8% 的准确度,这比其他最为先进技术的准确度提高了 5.1%,而错误率相对减少超过了 25%。我们已将这种方法应用于生产系统,将欺凌检测率提高到了近85%。
通过将音频合并到此模型也可以获得更好的结果。我们的实验证明,与使用相同架构和训练过程的视觉模型相比,我们的音视频模型在 AudioSet 音频事件检测基准测试中创造了新的记录——在检测亵渎性内容和成人内容方面的准确性提高了20%。
四、自监督方法在内容理解的应用前景
语言、图像和视频理解方面是 Facebook 持续努力的一部分。但当我们着眼于保持平台安全这一长期任务时,创建可以使用大量未标记数据进行训练的系统将变得越来越重要。
我们今天的大部分系统都依赖于有监督的培训,但这可能会导致一系列的训练挑战,例如在缺乏训练数据,在收集和标记示例以从头开始构建新分类器的长训练时间的情况下,由于新的内容违规事件迅速发酵,如选举等事件已成为有害内容的爆发点,我们有责任加快系统的开发,从而提高响应能力。
一个可能的答案是 Facebook 首席 AI 科学家 Yann LeCun 多年来一直在讨论的自监督方法,而不仅仅依赖于以人类训练为目的标记数据,或者甚至依赖于带有公共标签的图像和视频的弱监督数据。自监督方法能够利用完全无标记的数据,该方法具有通用性,使自监督系统能够使用少量标记数据来概括不可见的任务,并可能使我们更接近实现人类级别智能的 AI 技术目标。
基本上,Facebook AI 团队的曾经研究策略最近都转化成了能提供强大效果的系统,一些自监督的语言理解模型持续领先于使用传统的、完全监督方法训练的系统。
具体来说,我们开发了一些模型,通过训练信号的其余部分来学习预测给定信号的一部分。例如,我们训练其中一个自监督系统,通过掩盖句子中的单词来更好地理解语言,即使模型之前从未见过那个确切的句子。
给出一个像“A conversation about ________ and human connection”这样的短句,人们可以很容易地猜出几个可以填补空白的词,但是这项任务对 AI 来说更具挑战性。这是一个有用且可扩展的训练任务的基础,类似于 Google 同时引入的 BERT 模型来解决任务。我们可以依次清空一个句子的每个单词,并对十亿个单词重复这个过程,这个过程当然无需标记。
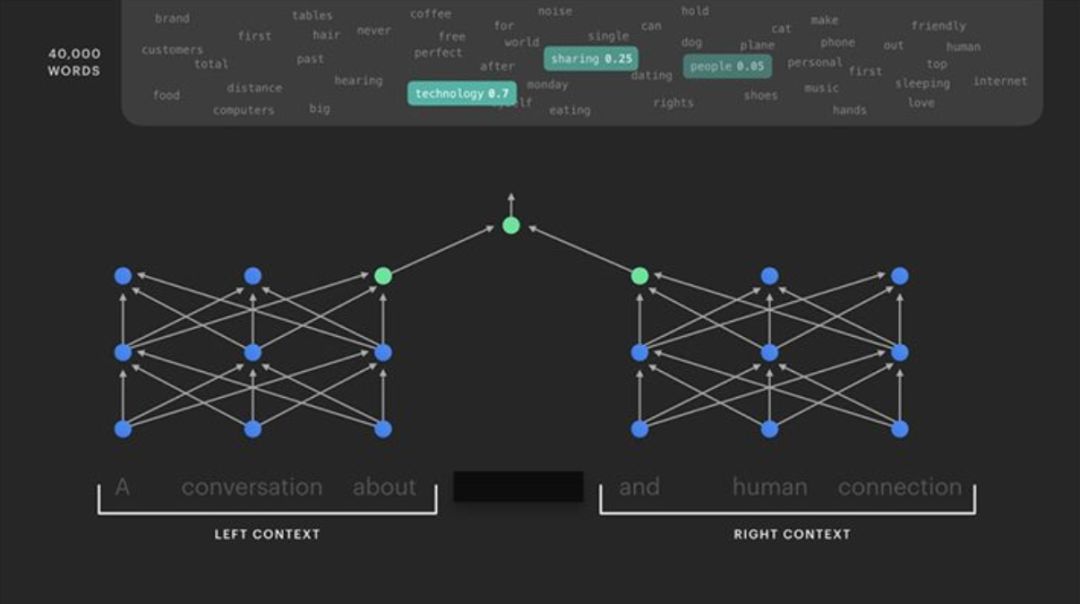
通过分别分析屏蔽字左侧和右侧句子的上下文语境,我们的双向变换模型能够在不依赖标记数据的情况下预测丢失的字词。
为了预测每个隐藏的单词,我们使用双向变换网络(bidirectional transformer networks),通过计算句子的前后状态(掩码右侧和左侧的单词)来模拟句子的其余部分,然后组合这些表示来确定中心词。一旦系统以这种未标记的方式进行了训练,我们就可以使用标记数据对特定任务进行微调,例如用来识别仇恨言论。
在内部测试时,这种自监督和有监督训练的混合使我们能够以少 10 倍的数据训练出比肩完全监督模型能获得的准确度,或者使用相同数量的训练数据,相比完全监督模型能相对减少 20% 的误差。
我们还使用自监督训练来改善语音识别能力。我们创建了一个音频片段几个版本,并且更改了一些音频的部分内容,而模型必须仅使用原始音频作为输入来确定哪个版本是正确的,同样没有转录或使用其他标签。
对于这种方法,我们使用两个堆叠在一起的网络:将原始音频映射到较低时频的特征表示的编码器网络,以及预测正确音频的上下文网络。为了使任务更有效地进行训练,我们通过上下文网络进一步预测未来,使预测问题变得愈加困难。

在使用两个卷积神经网络对原始的、未标记的音频数据进行预训练模型后,系统优化后以解决一项越来越困难的任务:预测不同时间的音频,箭头表示未来进一步的预测。
一旦这种预训练的、自监督模型能很好的理解语音,我们就会使用少量的监督数据:80 小时的转录音频来训练最终的语音识别系统。我们的系统使用的标记数据比最佳系统 Deep Speech 2 少了 150 倍,同时将字词错误率降低了 9%。这项工作使我们能够快速将语音识别功能扩展到更多语言,并且每种语言都不需要大量的转录语音。
这两种方法都侧重于语音和语言理解,但它们也代表了我们如何探索甚至结合不同程度的数据监督的更基础的方法转变。这包括利用大量未标记的训练数据,以及使用少量标记数据来释放自监督系统的巨大潜力。在所有与人工智能相关的任务中,强调自监督可以加速这些任务,但没有一项任务比提高使用我们产品的人的安全更重要。
相关链接:
https://ai.facebook.com/blog/advances-in-content-understanding-self-supervision-to-protect-people/
(本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
CTA核心技术及应用峰会
◆
5月25-27日,由中国IT社区CSDN与数字经济人才发展中心联合主办的第一届CTA核心技术及应用峰会将在杭州国际博览中心隆重召开,峰会将围绕人工智能领域,邀请技术领航者,与开发者共同探讨机器学习和知识图谱的前沿研究及应用。
更多重磅嘉宾请识别海报二维码查看,目前会议早鸟票发售中(原票价1099元),点击阅读原文即刻抢购。添加小助手微信15101014297,备注“CTA”,了解票务以及会务详情。

推荐阅读
人造器官新突破!美国科学家3D打印出会“呼吸”的肺 | Science
如何确定最佳训练数据集规模?6 大必备“锦囊”全给你了
如何在Python中轻松使用CVS,JSON,XML
算法实现没思路?最全Python算法实现大礼包!(附学习资源)
她说:为啥程序员都特想要机械键盘?这答案我服!
互联网出海十年
太形象了!什么是边缘计算?最有趣的解释没有之一!
安全顾问反水成黑客, 靠瞎猜盗得5000万美元的以太币, 一个区块链大盗的另类传奇
华为员工年薪 200 万!真相让人心酸!

相关文章:

【FFmpeg】打印日志函数分析(可以根据不同级别打印不同颜色的日志)
FFmpeg的打印日志实现在FFmpeg-n4.2.1/libavutil/log.c中。 一、设置log等级 1、设置日志级别 日志默认级别是AV_LOG_INFO static int av_log_level = AV_LOG_INFO;使用av_log_set_level将日志级别设置为调试级别(AV_LOG_DEBUG) av_log_set_level(AV_LOG_DEBUG);源码: …
创建MySQL数据库
创建数据库命令: CREATE DATABASE testdb DEFAULT CHARACTER SET utf8mb4 COLLATE utf8_general_ci; 注意:COLLATE是校对集的意思,可以理解为,排序规则等。字符集选择utf8mb4 参考文档:永远不要在MySQL中使用utf8&…

Android 对象型数据库 db4o
你有木有烦恼过数据库的crud,有木有对sql很烦躁,Android虽然有封装好的ContentProvider,但是操作还是有点复杂了。不是很喜欢。 这两天花时间整了下DB4O,确实很不错,不用建表,不用写sql,只要写好…
【FFmpeg】设置H264参数
0、fffmpeg源码编译时,何时需要连接libx264库? ffmpeg其自带H.264解码功能,但是要实现H.264编码时就需要链接编码库libx264 ubuntu16.04安装libx264的库: sudo apt install libx264-148 sudo apt install libx264-dev一、设置x264参数的接口 // 获取编码器 AVCodec *co…

TIOBE 5 月编程语言排行榜:Python、C++竞争白热化,Objective-C已沦为小众语言
作者 | 屠敏出品 | CSDN(ID:CSDNnews)日前,TIOBE 编程语言社区最新发布了 2019 年 5 月排行榜。和 4 月榜单相比,5 月编程语言排行榜的 Top 10 位置并没有太大变化。但是在 C 和 Python 激烈的竞争局势下,随…
Caused by: org.xml.sax.SAXParseException: 不允许有匹配 [xX][mM][lL] 的处理指令目标。
版权声明:本文为 testcs_dn(微wx笑) 原创文章,非商用自由转载-保持署名-注明出处,谢谢。 https://blog.csdn.net/testcs_dn/article/details/81001749 Caused by: org.xml.sax.SAXParseException: 不允许有匹配 "[xX][mM][lL]" 的处…
Centos 64位使用 yum 会安装两个相同软件包的解决方法
Centos 64位使用 yum 会安装两个相同软件包的解决方法 - 后山一根葱Centos 64位使用 yum 会安装两个相同软件包的解决方法[Linux]post by 后山一根葱 / 2011-6-24 1:43 Friday系统环境:Centos 5.6 X86_64事项:关于yum install 安装两个相同软件包问题今天…

php的基础知识(四)
14、数组: 索引数组: 下标就是数字开始的。 $arr [a,b,c,1,2,3]; 关联数组: $arr [ a > b, c > d; e > f ]; 二维数组: 关联和索引混合的。 $arr [ a, b, c, d > [ e > h, f, g ], i, ]; 三维数组和多维数组。 …
【Ubuntu】解决问题:tcp :8080: bind: address already in use
1、问题描述 在ubuntu中启动一个web程序时报错 tcp :8080: bind: address already in use2、原因查找 查找占用8080的服务:sudo netstat -tanlp 注意:不加sudo权限时,不显示PID和程序名字 $ sudo netstat -tanlp 激活Internet连接 (服务器…
ICLR 2019最佳论文揭晓!NLP深度学习、神经网络压缩夺魁 | 技术头条
整理 | Linstansy责编 | Jane出品 | AI科技大本营(id:rgznai100)【导语】ICLR 是深度学习领域的顶级会议,素有深度学习顶会 “无冕之王” 之称。今年的 ICLR 大会将于5月6日到5月9日在美国新奥尔良市举行,大会采用 Ope…
浅析flex中的焦点focus
一、无焦点的困扰——组件监听不到键盘事件原因:只有获得焦点的组件(确切说是InteractiveObject)才能监听到键盘事件的目标阶段;键盘事件(flash.events.KeyboardEvent)参与冒泡阶段,所以焦点组件…
专访NIPS主席:如何保证论⽂评审的公平性?| 人物志
记者 | 阿司匹林编辑 | 琥珀出品 | AI科技大本营(ID:rgznai100)作为人工智能领域顶会 NIPS(Conference and Workshop on Neural Information Processing Systems, 更名为 NeurIPS)的主席,Terrence Sejnowsk…

【H.265】H.265(HEVC)编码过程和名词解释
一、H.265(HEVC)编码过程 和H.264一样,H.265编码由帧内预测、帧间预测、量化、线性变换等步骤。过程大致如下; 1、分块 一帧画面首先被切分成多个互不重叠的块状区域,称为编码单元(H.264称为宏块),分别传输给编码器。 2、帧内预测 图像序列的第一个画面(以及每一个可…

为什么大家都推荐我学Linux
2019独角兽企业重金招聘Python工程师标准>>> 最近朋友总是推荐我去学Linux,我本人虽说是计算机专业的,但是我感觉在上学的时候好像还真没学到东西,现在也是干着一份与计算机半毛钱关系都没有的工作。朋友总是说Linux多好ÿ…
认识HTML5的WebSocket 认识HTML5的WebSocket
2019独角兽企业重金招聘Python工程师标准>>> 在HTML5规范中,我最喜欢的Web技术就是正迅速变得流行的WebSocket API。WebSocket提供了一个受欢迎的技术,以替代我们过去几年一直在用的Ajax技术。这个新的API提供了一个方法,从客户端…
空字符串计数、让字典可排序...Python冷知识(五)
本文转载自Python编程时光(ID: Python-Time)冷知识系列,直至今日,已经更新至第五篇。前四篇给你准备好了,还没阅读的可以学习一下。谈谈 Python 那些不为人知的冷知识(一)谈谈 Python 那些不为人…
后端说:只是你不懂怎么用 headers!
事情是这样的,上一个项目我们的后端提供的接口,一次性返回了所有数据给我,分页功能是前端自己完成的。 那么这次来的新项目,换了个后端,写了另外的接口,我做项目的时候,还是用的之前的前端分页组…

【H2645】H.264的宏块和H.265的编码树单元总结
一、H.264宏块 1、什么是宏块? 先看下面两张图,就能大体知道宏块指的是哪了。 将连续几帧图像分为一组(GOP)在H264中称为一个序列(sequence); 将每帧图像(Frame)划拉几道分成片(slice); 将每片(slice)按照16x16的大小横着竖着划拉成宏块(Maroblock); 将宏块(Maroblock…
android adb root方法
2019独角兽企业重金招聘Python工程师标准>>> 在有些android手机上使用adb root希望获取root权限时出现如下提示信息:adbd cannot run as root in production builds。此时提升root权限的方法是: 1。在android手机上获取超级用户权限ÿ…
10亿级数据规模的半监督图像分类模型,Imagenet测试精度高达81.2% | 技术头条...
译者 | linstancy作者| I. Zeki Yanlniz, Herve Jegou, Kan Chen, Manohar Paluri, Dhruv Mahajan编辑 | 蓝色琥珀鱼,Rachel出品 | AI科技大本营(ID:rgznai100)【导读】本文提出了一种十亿级数据规模的半监督图像分类模型…
【Qt】QtCreator导入cmake工程
QtCreator导入cmake 一、ubuntu系统1、配置cmake编译套件2、导入cmake工程二、windows系统1、下载cmake2、安装cmake3、设置环境变量4、添加cmake5、配置kit6、编译时配置7、cmake选项配置8、编译后,执行安装命令一、ubuntu系统 1、配置cmake编译套件 在QtCreator中依次点击…
腾讯音乐招 iOS 开发, base 深圳,要求:本科、三年、OC,懂音视频开发优先。...
计算机基础扎实,精通 Objective-C,熟悉 iOS 平台并有良好的软件开发经验; 熟悉 https 及流媒体上传下载协议,精通 TCP/IP 协议; 良好的编码风格,以及足够的调试技术和问题解决能力; 责任心强&am…

Android深入浅出系列之Android工具的使用—模拟器(一)
前言 我们下载的SDK包里面有一个叫“Tools”的文件夹,里面为我们提供了许多与Android开发相关的工具,其中一些是必不可少的,现在我们就介绍一下模拟器 Android模拟器的创建 使用“Android SDK and AVD Manager”可以很方便的创建一个An…

【H2645】帧内预测
1、帧内预测的原理 帧内预测的原理:预测值是该像素周围像素值加权求和(比如平均值)P,它和实际值相减后得到的差值q,如果差值q很小,说明该像素的值可以通过预测得出,可以丢弃了,这就达到压缩编码的目的。当…
程序员神级跳槽攻略:什么时候该跳?做什么准备?到哪里找工作?
为什么80%的码农都做不了架构师?>>> 1、引言 每年的3、4月份都是求职高峰时期,目前已进入6、7月份了,你已经成功换工作了吗? 这次我们想聊的,就是程序员跳槽这件事儿,我打算从三个方面来说&…
周志华等人新著!国内第一部AI本科专业教育培养体系出炉
整理 | 一一出品 | AI科技大本营(ID:rgznai100)不得不感叹,南京大学在人工智能本科教育上的发展速度,确实比国内一众高校快一步。这一次,在AI 本科专业教育培养体系的制定上,南大又一次跑到了最前面。5 月 …
自己实现文本相似度算法(余弦定理)
2019独角兽企业重金招聘Python工程师标准>>> 最近由于工作项目,需要判断两个txt文本是否相似,于是开始在网上找资料研究,因为在程序中会把文本转换成String再做比较,所以最开始找到了这篇关于 距离编辑算法 Blog写的非…

autohotkey快捷键
;已经基本修复了输入带shift的时候跟输入法中英文切换之间的冲突 SetStoreCapslockMode, off SetKeyDelay, 50^CapsLock::#UseHook ;用这个和下面的off能实现代码不冲突,即这个区间的 才有作用,而不出发send right Send {Capslock} #UseHook off returnCapsLock:: Send {Right…
算法实现没思路?最全Python算法实现大礼包!(附学习资源)
整理 | Rachel责编 | Jane出品 | Python大本营(ID:pythonnews)【导语】数据结构与算法是所有人都要学习的基础课程,自己写算法的过程可以帮助我们更好地理解算法思路,不要轻视每一个算法,一些虽然看似容易&…
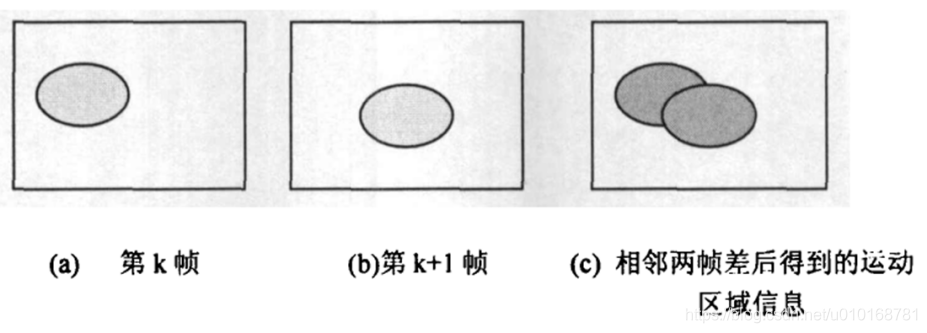
【H2645】帧间预测
1、帧间预测原理 先看下图,对比前后两帧图像,只有圆的位置发生变化,因此我们可以根据前一帧图像以及圆移动的信息,合成后一帧图像。这样少编码一帧图像,大大压缩了数据。 实际情况如下图,比对前后两帧,背景一样,只有两人身体发生微小变化,找出并记录这些变化信息,就…