李理:为什么说人工智能可以实现?

作者 | Just
出品 | AI科技大本营(ID:rgznai100)
尽管市面上关于深度学习的书籍很多,环信 AI 负责人李理认为大部分只关注理论或只关注实践。于是,基于他对深度学习多年的理解,自己着整理手写了一本深度学习理论与实战书籍。
目前,作者已经将《深度学习理论与实战:提高篇》公开,读者可以免费阅读。这本开源书籍最大的特点是理论结合实战和内容的广度与深度,目标是使用通俗易懂的语言来介绍基础理论和最新的进展,同时也介绍代码实现,将理论知识用于指导实践。
从其目录就可以一目了然。
《深度学习理论与实战:提高篇》阅读链接:
https://fancyerii.github.io/2019/03/14/dl-book/
这本书中,作者在每介绍完一个模型都会介绍它的实现,读者阅读完一个模型的介绍之后就可以运行、阅读和修改一下这些代码,从而可以更加深刻的理解理论知识。

本书第二个比较大的特点就是内容的广度与深度,覆盖听觉、视觉、语言和强化学习四大领域,并涵盖深度学习的大部分常见应用方向。

以视觉和语言为例,不同于市面上大部分只限于介绍 CNN 用于简单的图像分类或者 RNN、seq2seq 模型在 NLP 中的应用介绍的书,《深度学习理论与实战:提高篇》的视觉部分除了介绍 CNN 以及最新的 ResNet 和 Inception 模型之外,还介绍了用于目标检测的 R-CNN、Fast R-CNN、Faster R-CNN 模型;用于实例分割的 Mask R-CNN 模型;用于人脸识别的FaceNet;还包括 Neural Style Transfer 和 GAN(包括 DCGAN 和 Cycle GAN)。语言部分除了很多书都有的 RNN/LSTM/GRU 等基础模型,用于机器翻译、chatbot 的 seq2seq 模型和 Attention 机制之外,还包括最新的 ELMo、OpenAI GPT 和 BERT 等模型。
此外,本书还介绍了 NLP 的很多经典任务,包括语言模型、词性标注、成分句法分析、依存句法分析和机器翻译。

《深度学习理论与实战:提高篇》还用一章的篇幅介绍强化学习的基本概念,包括 MDP、动态规划、蒙特卡罗方法、TD 学习和 Policy Gradient。接着还介绍了 DQN、基于深度学习的 Policy Gradient 算法,最后是介绍 AlphaGo、AlphaGo Zero 和 Alpha Zero 算法。

除了理论和实践的通俗易懂描述外。作者还在本书的序言《深度 | 人工智能究竟能否实现?》一文中还“大胆”表达了对于人工智能的个人看法,这些观点某种程度上都不同于主流观点。
比如,对于人工智能究竟能否实现这一让很多人皱眉头的问题,作者基于自己对人工智能的认知和定义,给出了肯定的答案。基于此,AI科技大本营采访了作者李理,跟他聊了聊为什么笃定人工智能可以实现,什么时候实现,以及他对深度学习发展的看法。
以下为采访内容,一如写书的风格,他对每个问题都给出了详实的回答。
AI科技大本营:您在书中指出理论上人工智能可以实现,并从诸多角度做了解释,比如情绪和情感机器也是可以有的,机器还能进行艺术“创作”,这些角度的解释可能大多是违反人们现有认知的,有人可能会质疑这是为了给“实现人工智能”这个目标,特意去找了一些牵强的“哲学性”论证,而且这些论据看上去全是实现人工智能的必要条件,您对人工智能的实现是否过于乐观了?
李理:这其实可以说是我个人的一种信仰,就像在前言里提到的:"在一本技术类的书籍里是否应该增加单独一章来讨论哲学问题,我犹豫了很久。这些内容很可能会被读者认为毫无价值,让读者白花了冤枉钱。"因为当时写这些内容时并没有想到要把提高篇免费开放,所以我确实是犹豫了很久的。但是最后冒着被读者抱怨和吐槽的风险,我还是决定"强行加塞"进去这一章的内容,因为这是我十多年来思考的一些东西,也是让我一直在这个领域不断学习的动力。(十多年前 AI 并不热门,更不是"显学"。)
这只是我的个人观点,并没有期望大家都能认同。但是这里我只想提一点,那就是智能并没有我们自认为的那么与众不同,因此从理论上并不能证明只有人才可以拥有这种能力,就像佛教认为的人人都可以成佛,成佛并不需要超高的智商、显赫的家世,它只需要观点的改变。同样的,我们只需要认为人类没有什么特殊的,那么创造和人类同等智能甚至比人类更智能的智能体就是完全有可能的。
当然这需要"舍弃"很多我们自认为值得骄傲,而别的生物不可能拥有的东西,比如情感、灵感和自由意志之类的东西。就像要成为觉悟者需要舍弃很多日常根深蒂固的观点一样,比如我们必须接受诸行无常和诸法无我这样的观点。
AI科技大本营:作为一个人工智能的从业者来说,您希望人工智能可以实现,甚至最终可以制造出和人一样甚至比人更加智能的机器,如果让您做一个大胆的预测,那么真正的人工智能什么时候会实现?它的实现有哪些必备条件?
李理:做这样的预测是很费力不讨好的事情,虽然我认为人工智能一定可以实现,但是我并不关心它是明天就能实现还是一百年后才能实现。你的问题里提到"真正的"人工智能什么时候实现,隐含的意思就是现在很多"假的"人工智能,包括现在很多人也把人工智能划分为"强人工智能"和"弱人工智能"。我个人不是很认同这样的观点,这只是研究的不同方向,而不是"真的"或者"假的"智能、"强的"或者"弱的"智能。我并不认为用大脑下围棋是比用手捡垃圾更"强"的智能。
即使一定要冒天下之大不韪来预测"人工智能什么时候会实现",我们也需要先对怎么样叫"实现"了人工智能达成一个共识。在大众的观点里,实现科幻电影里的那种人形的机器人就是"实现"了人工智能,当然它还需要足够"智能"让我们分辨不出它是真人还是机器人,因此它必须和人很像,有情感和欲望,比如史蒂文·斯皮尔伯格导演的电影《人工智能》里的机器人。
如果是这个目标的话,我觉得短期内很难实现。不过难实现的原因是和技术无关的,而是我们不可能让它出现。这是什么意思呢?我们先抛开能否实现的问题,自己问一下如果这样的机器人做出来了我们怎么对待它们?
对于大部分人来说,机器人就是一种更加智能的工具而已。从石器时代、铁器时代、蒸汽时代、电气时代再到现在的信息时代,我们使用更加先进便捷的工具来改变生产和生活。工具的目的是延伸和拓展人类的能力。我们跑得不快,但可以借助骑马和开车日行千里;我们跳得不高,更不会飞,但是借助飞机火箭上天入地。
工具总体来看可以分为两类:拓展人类体力能力的工具和拓展人类脑力能力的工具。现在很多机械的脑力劳动都可以由计算机完成,但传统的计算机程序只能帮我们扩充记忆和完成简单机械的计算。我们有容量更大速度更快的存储器,可以编制财务软件来进行财务核算,但却无法实现需要“智能”才能来完成的事情。
如果是从这个角度来看,实现智能的工具已经成为现实了。比如工厂里以前需要人类灵巧的手才能做出来的东西现在很多都可以用机器来替代,我们家里的洗衣机、洗碗机和扫地机器人帮我们做了很多家务。
但是我们并不需要它们有情感,否则换位思考一下:它们为什么愿意甘愿当牛做马像"奴隶"一样伺候我们呢?它会不会在给我们开车的时候威胁我们呢,甚至偷偷按下美国总统的核按钮呢?这也是很多人担心人工智能会带来灾难的原因,打个不恰当的比喻就是奴隶主会担心奴隶们造反。
这里就不讨论人工智能的这种风险了,因为我本人对这个问题并不感兴趣,或者说我根本不担心这个问题。
下面这段假想的对话来说明我为什么不担心。青年问禅师:"如果所有人都去当和尚,人类不就灭亡了?"禅师笑这说:"这和'请不在这里的同学举一下手'一样可笑。"
什么样的人就会做出什么样的"人工智能",它只是我们智能和世界观的延伸而已。因此我觉得短期内,那种具有人类情感的机器人是不可能出现的。
至于说实现需要的条件,也许哪天人类可以"接受"这种"人造"的智能体,那么就有可能实现吧。我觉得那个时代人类的世界观和宇宙观应该经过了一次很大的变化和突破。
AI科技大本营:您在书中还提到了一个有意思的观点:“研究基础的行动能力(Robotics)比研究高层的语义更有意义,因为常识来源于此。”您的意思应该是我们对语言的研究的还是表层,这有点像是研究人工智能时应用层要有成果,最重要的是基础技术层有所突破,但看上去研究基础的行动能力并不容易,现在甚至可能都不知道具体从何着手?
李理:我的专业和现在从事的方向都是 NLP,但做得越久我觉得越沮丧。虽然目前的深度学习使得 NLP 更加简单,在很多任务上的指标也越来越高,但是我个人觉得目前的这些方法都不能真正的解决问题。
拿现在最先进的 BERT 模型来说,它的关键是从未标注的语料里学习一个句子的语义表示。它能够从海量的文本中通过词之间的共现关系学习到某种程度的"语义"关系,从而能够把一个句子编码成一个向量。但它的问题是没有一个坚实的"根基"。
什么叫"理解"了一句话?这是一个很难定义的问题。比如有人跟我们说“今天晚上八点会下雨",那么我们"理解"了什么东西呢?
首先,我们需要有时间的概念。由于生物钟,我们能够感受时间,并且对于现代社会的人,我们对于时间有一个更细粒度的划分,有今天、晚上和八点这样的时间概念。古人可能不能理解"八点",但他们有类似“戌时”的概念。
其次,这里隐含了空间的概念,默认就是我们说话所在的这片区域。另外我们还要能够理解下雨是什么意思,它可能会淋湿我们的身体。但什么叫淋湿?是液态的水附着在生物体的皮肤上从而导致这个生物体感觉寒冷和不舒服。什么叫寒冷?动物在接触到比它体温低的物体时产生的一种感觉……这样的问题可以不断重复下去,如果用人类的字典或者百科全书来解释的话最终就会形成循环解释。
不管人类的知识多么复杂,但归根结底都是人类的基本感受。无论最终的概念多么抽象,比如微积分的概念,它都是一系列其它抽象概念组合起来的,而其它抽象概念又是由另外一些概念组合起来。最终它一定会和我们最基本的某种感受建立起联系,也许最下层的联系和微积分这个概念需要经过成千上万个其它概念的连接。
因此从这个角度来说,如果要让机器"真正理解"语言,我们必须先实现基础的"人"的能力,比如行走、跳远等对身体的基本平衡和控制能力。现在的AI只是在研究"大脑",这当然是人区别动物最重要的特征之一,但是如果我们连一个基本的动物的能力都实现不了,那么肯定是不能实现我们期待的人工智能的。一个人的"大脑"是不能脱离他的身体而存在的,大脑的骄傲或者自卑、高兴与悲伤都和整个身体的状态密切相关。
AI科技大本营:最近,业界已经有深度学习技术的潜力已经抵达天花板?结合您在业界的实践经验,你对深度学习技术的未来发展如何看?
李理:我觉得深度学习的技术一直都在稳步的发展,只不过以前大家并不太关注这个领域,所以等到某些突破性的应用如 AlphaGo 或者无人驾驶出现在大家面前时大家会觉得是非常大的突破。
但是如果我们阅读关于 AlphaGo 以及围棋的发展过程就会发现它其实也是一点点的进步然后到底某个临界值,所谓量变引起质变的过程。现在大家关注的多了,就会觉得没有那么大的突破。另外一些人为了某些目的过分夸大计算的进展,从而让大家产生很多不切实际的期望,这也会让大家觉得现在的发展可能变慢了。
深度学习技术肯定会不断的发展,我们很多现在使用的方法会被更新更好的方法替代。但是有一点我觉得是不变的,那就是深度学习或者说神经网络它的基本世界观——联结主义。
联结主义认为智能是由简单单元的联结和形成的。具体来说,人类的大脑的功能就是由大量简单的神经元的联结而实现的。(人工)神经网络最初就是借鉴人类大脑提出的计算模型。神经网络领军人物之一 Geoffrey Hinton 本人就是研究认知心理学(cognitive psychologist)的,很多网络结构比如卷积神经网络(CNN),循环神经网络(RNN)都部分的借鉴了人脑的工作原理。不过人工神经网络更多的是从宏观层面的角度来借鉴人脑,但具体的实现层面更加简化和关注实用性。它的一个基本观点其实就是:人脑并不特殊,我们可以从原理上实现和它同等功能的机器,虽然人脑是基于化学的生物的而目前的计算机是基于电子的。
AI科技大本营:《深度学习理论与实战:提高篇》的谋篇布局是为什么是按照听觉、视觉、语言和强化学习四个部分划分来写的?
李理:这样划分有如下一些原因。
第一,和本书的姊妹篇《深度学习理论与实战:基础篇》不同,基础篇更多的是介绍深度学习的基础知识,因此是从算法的角度组织内容,比如有单独介绍全连接网络、卷积神经网络和循环神经网络的章节。这些算法虽然各有侧重,但在很多具体的领域都有应用,比如卷积神经网络不但是计算机视觉的核心算法,在语音识别、自然语言处理和强化学习里可以应用。而提高篇会更加深入的研究这些领域怎么使用深度学习的算法来达到 state of the art 的效果,因此它的内容是根据听觉、视觉、语言和强化学习这个四大方向来组织的。
第二,我认为这是智能的层次结构。我们的智能首先体现在感知层面,而人类最重要的感知能力就是视觉和听觉。视觉和听觉都是对底层信号的感知,但是相对来说听觉更"高层"一些(注意是高层而不是高级,我一直不认为智能有什么高下只分,要想实现真正的智能,必须要底层到高层的统一的智能体)。我这里说的"高层"指的是听觉和语言的关系更加密切一些,当然视觉其实也是有很多"语义"的,只不过目前的研究还是在比较浅层的内容。
比如我们现在的算法能够识别这是一只猫,甚至能够标注出一个像素是不是一个猫的一部分。但是我们还不能识别这种猫的表情——它是高兴还是愤怒、它是在爬墙还是在躺着。当然也可以用现在的算法来做——我们标注数据训练模型就可以了。但是这样的表情太多了,标注成本太高,而且人类似乎也不是这样来了解其它动物(包括其他人)的表情。这里的"表情"其实也是某种"语言",这是我们人类给猫的表情打的标签,我们认为猫很萌,但是在老鼠看来可不是这样。
视觉和听觉作为人类与外界沟通最主要的两种感觉,经历了长期的进化。大部分动物都有发达的视觉与听觉系统,很多都比人类更加发达。拿视觉来说,老鹰的视力就比人类发达的多,而且很多动物夜间也有很强的视力,这是人类无法比拟的。但是人类的视觉应该有更多高层概念上的东西,因为人类大脑的概念很多,因此视觉系统也能处理更多概念。比如人类能利用钢铁,对汽车有细微的视觉感受,但是对于一条狗来说可能这些东西都是 Other 类别,它们可能只关注食物、异性、天敌等。
听觉系统也是如此,很多动物的听觉范围和精度都比人类高得多。但它们关注的内容也很少,大部分是猎物或者天敌的声音。人类与大部分动物最大的区别就是社会性,社会性需要沟通,因此语言就非常重要。一些动物群落比如狼群或者猴群也有一定的社会性,像狼群狩猎是也有配合,猴群有严格的等级制度,但是相对于人类社会来说就简单得多。一个人能力相当有限,但是一个人类社会就非常强大,这其实就跟一个蚂蚁非常简单,但是整个蚁群非常智能类似。
作为沟通,人类至少有视觉和听觉两种主要的方式,但最终主要的沟通方式语言却是构建在听觉的基础上的。为什么进化没有选择视觉呢?当然有偶然的因素,但是我们可以分析(或者猜测)一下可能的原因。
你也许会说声音可以通过不同的发音来表示更多的概念,而且声音是时序信号,可以用更长的声音表示更复杂的概念。
但这是说不通的,人类能比动物发出更多不同种类的声音,这也是进化的结果。用脸部或者四肢也能表达很多不同的概念,就像残疾人的手语或者唇语,或者科幻小说《三体》里的面部表情交流。如果进化,面部肌肉肯定会更加发达从而能够表示更多表情。
至于时序就更没有什么了,手语也是时序的。
当然声音相对于视觉还是有不少优势的:
声音通过声波的衍射能绕过障碍物,这是光无法办到的(至少人类可见的光波是不行的)
衍射的结果就是声音比光传播得远
晚上声音可以工作,视觉不行(其实夜视能力也是进化出来的)
声音是四面八方的,视觉必须直面(当然有些动物的视角能到 360 度),背对你的人你是看不到他的表情的。
可以做很多分析,但不管怎么样,历史没法重新选择,事实就是人类的进化选择了声音,因此 Speech 就成了 Language 的一部分了。当然还有一些听觉的内容,比如 Music,我们可以认为是另外一种语言,它最终的目的还是用于沟通人类的情感,否则即使天籁之音也是毫无意义的。
强化学习和视觉、听觉和语言其实不是一个层面上的东西,它更多的是和监督学习、非监督学习并行的一类学习机制(算法),但是我认为强化学习是非常重要的一种学习机制。
监督学习的特点是有一个“老师”来“监督”我们,告诉我们正确的结果是什么。在我们在小的时候,会有老师来教我们,本质上监督学习是一种知识的传递,但不能发现新的知识。对于人类整体而言,真正(甚至唯一)的知识来源是实践——也就是强化学习。比如神农尝百草,最早人类并不知道哪些草能治病,但是通过尝试,就能学到新的知识。学到的这些知识通过语言文字记录下来,一代一代的流传下来,从而人类社会作为整体能够不断的进步。
和监督学习不同,没有一个“老师”会“监督“我们。比如下围棋,不会有人告诉我们当前局面最好的走法是什么,只有到游戏结束的时候我们才知道最终的胜负,我们需要自己复盘(学习)哪一步是好棋哪一步是臭棋。自然界也是一样,它不会告诉我们是否应该和别人合作,但是通过优胜劣汰,最终”告诉”我们互相协助的社会会更有竞争力。和前面的监督非监督学习相比有一个很大的不同点:在强化学习的 Agent 是可以通过 Action 影响环境的——我们的每走一步棋都会改变局面,有可能变好也有可能变坏。
它要解决的核心问题是给定一个状态,我们需要判断它的价值(Value)。价值和奖励(Reward)是强化学习最基本的两个概念。对于一个 Agent(强化学习的主体)来说,Reward 是立刻获得的,内在的甚至与生俱来的。比如处于饥饿状态下,吃饭会有 Reward。而 Value 是延迟的,需要计算和慎重考虑的。比如饥饿状态下去偷东西吃可以有 Reward,但是从 Value(价值观)的角度这(可能)并不是一个好的 Action。
为什么不好?虽然人类的监督学习,比如先贤告诉我们这是不符合道德规范的,不是好的行为。但是我们之前说了,人类最终的知识来源是强化学习,先贤是从哪里知道的呢?有人认为来自上帝或者就是来自人的天性,比如“人之初性本善”。如果从进化论的角度来解释,人类其实在玩一场”生存”游戏,有遵循道德的人群和有不遵循的人群,大自然会通过优胜劣汰”告诉”我们最终的结果,最终我们的先贤“学到”了(其实是被选择了)这些道德规范,并且把这些规范通过教育(监督学习)一代代流传下来。
鉴于其重要性,我决定把强化学习作为一个单独的部分来介绍。其实我觉得强化学习更重要的用处是在更底层的运动控制上,比如怎么灵活的控制机械手抓取物体——要实现这个三岁小孩能够完成的任务其实并不简单。本来我是想在这里加入一些 Robotics 的内容,但是由于时间和水平的限制,这一部分内容我还在学习过程中,本着避免不懂装懂误人子弟的原则,本书不会加入任何我自己还不理解的内容。但是我觉得这个方向也是人工智能非常非常重要的部分,而且目前这个方向使用的还是比较传统的方法,深度学习应该会能发挥更加重要的作用。
AI科技大本营:介绍一下即将出版《深度学习理论与实战:基础篇》是一本什么样的书(包括内容涵盖情况,面向的读者群)?
李理:基础篇已经在编辑出版中,预计年中可以和读者见面。
基础篇的内容不仅包含人工智能、机器学习及深度学习的基础知识,如卷积神经网络、循环神经网络、生成对抗网络等,而且也囊括了学会使用 TensorFlow、PyTorch 和 Keras 这三个主流的深度学习框架的最小知识量;不仅有针对相关理论的深入解释,而且也有实用的技巧,包括常见的优化技巧、使用多 GPU 训练、调试程序及将模型上线到生产系统中。
本书希望同时兼顾理论和实战,使读者既能深入理解理论知识,又能把理论知识用于实战,因此本书每介绍完一个模型都会介绍其实现,读者阅读完一个模型的介绍之后就可以运行、阅读和修改相关代码,从而可以更加深刻地理解理论知识。
回顾人工智能几十年经历过的起起落落,希望对人工智能及深度学习感兴趣的读者通过本书的学习能够更加理性地看待这个行业,理解人工智能尤其是深度学习的原理并应用,根据当前的技术现状合理地应用深度学习去改变人们的工作、生活和学习。
(*本文为 AI科技大本营原创文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
6月29-30日,2019以太坊技术及应用大会 特邀以太坊创始人V神与以太坊基金会核心成员,以及海内外知名专家齐聚北京,聚焦前沿技术,把握时代机遇,深耕行业应用,共话以太坊2.0新生态。
扫码或点击阅读原文,既享优惠购票!

推荐阅读
阿里带火的中台到底是什么?白话中台战略
入门学习 | 什么是图卷积网络?行为识别领域新星
文件操作So Easy!来,一起体验下Python的Pathlib模块~
有一种青春叫高考,Python爬取历年数据,说说我们一起经历的高考
漫话:如何给女朋友解释什么是编译与反编译
超级黑幕:开发者千万别被算法迷惑了!
鲍岳桥:52 岁还在熬夜写代码! | 人物志
IBM 确认裁员约 1700 人;华为新款操作系统来了!开通 5G 服务不换卡不换号 | 极客头条
9年前他用1万个比特币买了两个披萨, 9年后他把当年的代码卖给了苹果, 成为了GPU挖矿之父
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

【FFmpeg】FFmpeg编解码H264产生马赛克、伪影的解决方法
1、问题描述 使用FFmpeg编码H264,再解码显示时,产生马赛克:有时是在画面静止时,静止时间越长,马赛克、伪影越多;有时是在画面切入切出时;有时是在网络带宽不够时 2、原因分析 2.1 丢帧 网络状况差的情况下(带宽不足),容易丢帧,在视频画面播放过程中,若I帧丢失了,…
LINUX内核升级
内核版本是2.6.18,新的内核是2.6.26。 1.下载新内核,下载网站www.kernel.org 2.copy内核到/usr/local/src下 3.解压内核 解压内核命令 tar -xjvf linux-2.6.26.tar.bz2 4.清理以前编译所生成的文件 命令为 make distclean,如果以前没有编…

我在美团的这两年,想和你分享
作者 | 石晓文来源 | 小小挖掘机(ID:wAIsjwj)012017.08.14,结束了两周的等待,如愿以偿开始了自己的美团实习生活,本来抱着三五个月走人,争取下一份实习的心态,没想到一直到转为暑期实…
【Qt】QtCreator updatePchInfo:switching to none
1、Pch名词解释 Pch(PreCompiled Headers)预编译头文件。 使用方法: CONFIG+=precompile_header PRECOMPILED_HEADER=XXX.h 2、updatePchInfo:switching to none 和QtCreator代码格式化Beautifier插件配置了clang code model有关系。 猜测:clang分析预编译头文件相关,…
学习框架、库的经验
熟悉基础语法把框架的功能过一遍,看看有哪些功能从文档的demo入口去学习上手会更快在你的开发目录要有一个专门写demo的页面,用以调试页面,试验新功能如果框架或者库提供有demo则更好,可以从中得到很多有用的东西

开源应用程序结构
2019独角兽企业重金招聘Python工程师标准>>> 给有兴趣的同学介绍的。这里面介绍了很多著名的开源软件的架构,相信读后会有所收获。 地址:http://www.aosabook.org/en/index.html 转载于:https://my.oschina.net/qinlinwang/blog/71649

免费GPU哪家强?谷歌Kaggle vs. Colab
作者 | Jeff Hale译者 | Monanfei责编 | 夕颜出品 | AI科技大本营(id:rgznai100)谷歌有两个平台提供免费的云端GPU:Colab和Kaggle, 如果你想深入学习人工智能和深度学习技术,那么这两款GPU将带给你很棒学习…
【SVN】svn“E155017工作副本的参考文件损坏、E200014文件校验和不匹配”的解决方法
1、问题描述 在执行svn提交时报错 svn: E155017: 工作副本的参考文件损坏 svn: E200014: ‘test.cpp’ 的文件校验和不匹配: 期望:xxxx 实际:xxxx 2、解决方法 2.1 拷贝 最好将提交的项目拷贝一份; 2.2 删除 使用svn rm --k…

QT程序启动加载流程简介
1. QT应用程序启动加载流程简介1.1 QWS与QPA启动客户端程序区别1.1.1 QWS(Qt Window System)介绍QWS(Qt Windows System)是QT自行开发的窗口系统,体系结构类似X Windows的C/S结构。QWS Server在物理设备上显示,QWS Client实现界面,两者…

QQ2012 Under Ubuntu
下载地址: QQ2012 Under Ubuntu转载于:https://www.cnblogs.com/ismdeep/archive/2012/08/09/2630067.html

25亿布局大湾区,创新工场的AI下一站
2019年6月5日,创新工场大湾区总部正式开业启动,集“产业投资AI 研究院商业赋能落地”三个功能为一体。当天创新工场还首次分享人工智能工程院成立两年来的成绩单,创新奇智的大湾区布局,并发布大湾区人才战略。创新工场也正式宣布第…
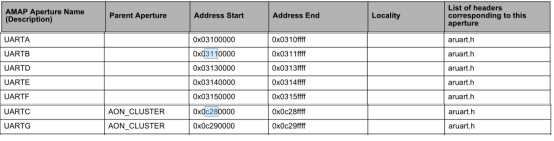
【TX2】TX2开发板系统默认串口有ttyS0(调试口)、ttyTHS1、ttyTHS2、ttyTHS3,通过修改设备树文件,可以新增三个串口
1、简述 TX2开发板系统默认串口有ttyS0(调试口)、ttyTHS1、ttyTHS2、ttyTHS3,通过修改设备树文件,可以新增三个串口。 2、设备树 设备树中关于串口部分的描述 2.1 基础配置 注意:在这里状态都配置成禁止ÿ…
unix的发展
转载http://blog.51cto.com/1193432/1671058转载于:https://www.cnblogs.com/vwei/p/9588823.html
让你的输入框使用Google云语音输入技术
2019独角兽企业重金招聘Python工程师标准>>> 只需一行代码,你的网站上面输入框(input),直接可以在谷歌浏览器(chrome)上面使用Google的云语音输入技术。 在你的输入框input的HTML属性里面&#…

速度超Mask RCNN四倍,仅在单个GPU训练的实时实例分割算法 | 技术头条
作者 | Daniel Bolya Chong Zhou Fanyi Xiao Yong Jae Lee译者 | 刘畅责编 | Jane出品 | AI科技大本营(id:rgznai100)【导读】在论文《YOLACT:Real-time Instance Segmentation》中,作者提出了一种简洁的实时实例分割全…
JSP内置对象基础知识小结
JSP提供9大内置内象:一、request内象:封装了由客户端生成的HTTP请求的所有细节,主要包括了http头信息,系统信息,请求方式,请求参数等。1、获取访问请求参数:request.getParameter("arg&quo…
一个正执行的程序如何启动另一新程序并关闭现执行程序
最简单的方法有两个函数即可实现: //启动新程序WinExec("存放另一新程序的路径", SW_SHOW);//关闭现执行软件 ExitThread(0); 若在win ce 下,用WinExec这个函数就不对了,那时就应该用ShellExecuteEx了。 SHELLEXECUTEINFO ShExecIn…
【android】java.lang.NoClassDefFoundError或classnotfount等异常错误
在android上开发,当导入一个外部的包,可能会出现这类错误,我已经两次碰到了,一次是用科大讯飞的android开发包,另一次是用Jsoup包(html 解析)。 解决方案: 先去掉加入的外部包 不要把…
Java面试题(一)部分题目
博主马上要面对几家公司的面试,故自己准备了点面试题,仅供参考! 1,线程的创建的方式:答:1,继承Thread(注意,此类其实也是实现了Runnable接口的),2,实现Runnable接口2,1. …
在win ce中如何使正在运行的软件自动升级更新
创建两个独立的程序A和B:A是现正在运行的程序,B是用于辅助新版本的A覆盖旧版A 在客户端先运行A,使A提供从服务器端下载新版A放于一临时文件夹中,并运行B,关闭A; 运行的B用于执行:用新版A覆盖旧…

刘铁岩:AI打通关键环节,加快物流行业数字化转型
导语:近日,在微软亚洲研究院创新论坛上,微软亚洲研究院副院长刘铁岩分享了关于“AI物流”行业的实践经验。以下为其发言内容。 随着时代的发展,人工智能成为了决定性的技术,我们所谈的企业数字化转型也正在从“互联网”…
Unity的三种Interceptor
Unity默认提供了三种拦截器:TransparentProxyInterceptor、InterfaceInterceptor、VirtualMethodInterceptor。 TransparentProxyInterceptor:代理实现基于.NET Remoting技术,它可拦截对象的所有函数。缺点是被拦截类型必须派生于MarshalByRe…

Python编写循环的两个建议 | 鹅厂实战
作者 | piglei(腾讯高级工程师)转载自腾讯技术工程知乎专栏循环是一种常用的程序控制结构。我们常说,机器相比人类的最大优点之一,就是机器可以不眠不休的重复做某件事情,但人却不行。而“循环”,则是实现让…

作为JavaScript开发人员,这些必备的VS Code插件你都用过吗
本文翻译自:https://www.sitepoint.com/vs-code-extensions-java-developers/转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。如今,Visual Studio Code无疑是最流行的轻量级…
matlab常遇小问题汇总
1、如何注释掉多行: 同时注释掉多行,有2种方法可行: (1)、选中所有要注释的行,按快捷键"Ctrl R" 或者 选择工具菜单"Text --> Comment"; 如果释放所有要注释的行,则按快捷键"Ctrl T&qu…
《几何与代数导引》习题1.35.4
求直线之间的距离$l_1:\frac{x1}{-1}\frac{y-1}{3}\frac{z5}{2}$.$l_2:\frac{x}{3}\frac{y-6}{-9}\frac{z5}{-6}$.解:点$q(-1,1,-5)$在直线$l_1$上,点$p(0,6,-5)$在直线$l_2$上.$\vec{pq}(-1,-5,0)$.直线$l_1$的方向向量为$(-1,3,2)$,直线$l_2$的方向向量…

深度学习难,这本书让你轻松学深度学习
深度学习在短短几年之内便让世界大吃一惊。它非常有力地推动了计算机视觉、自然语言处理、自动语音识别、强化学习和统计建模等多个领域的快速发展。随着这些领域的不断进步,人们现在可以制造自动驾驶的汽车,基于短信、邮件甚至电话的自动回复系统&#…
matlab中用于小数取整的函数的用法
matlab中小数取整的函数大约有四个:floor、ceil、round、fix 若 A [-2.0, -1.9, -1.55, -1.45, -1.1, 1.0, 1.1, 1.45, 1.55, 1.9, 2.0]; floor:朝负无穷方向靠近最近的整数; floor(A) ans -2 -2 -2 -2 -2 1 1 1 1 …

SQLServer之删除约束
使用SSMS数据库管理工具删除约束 1、连接数据库,选择数据表-》展开键或者约束-》选择要删除的约束-》右键点击-》选择删除。 2、在删除对象弹出框中-》点击确定。 3、刷新表-》展开键或者约束-》查看结果。 使用T-SQL脚本删除约束 语法: --声明数据库使用…
新建silverlight项目提示未将对象设置到实例解决方案
1.打开 visual studio 命令提示 输入一下命令 2.devenv /resetskippkgs 这条命令会启动visual stuio 关闭visual studio然后输入下面的命令3.devenv /setup