大战三回合:XGBoost、LightGBM和Catboost一决高低 | 程序员硬核算法评测

作者 | LAVANYA
译者 | 陆离
责编 | Jane
出品 | AI科技大本营(ID: rgznai100)
【导读】XGBoost、LightGBM 和 Catboost 是三个基于 GBDT(Gradient Boosting Decision Tree)代表性的算法实现,今天,我们将在三轮 Battle 中,根据训练和预测的时间、预测得分和可解释性等评测指标,让三个算法一决高下!
一言不合就 Battle
GBDT 是机器学习中的一个非常流行并且有效的算法模型,2014 年陈天奇博士提出的 XGBoost 算法就是 GBDT 一个重要实现。但在大训练样本和高维度特征的数据环境下,GBDT 算法的性能以及准确性却面临了极大的挑战,随后,2017 年 LightGBM 应势而生,由微软开源的一个机器学习框架;同年,俄罗斯的搜索巨头 Yandex 开源 Catboost 框架。
XGBoost(eXtreme Gradient Boosting) 特点是计算速度快,模型表现好,可以用于分类和回归问题中,号称“比赛夺冠的必备杀器”。
LightGBM(Light Gradient Boosting Machine)的训练速度和效率更快、使用的内存更低、准确率更高、并且支持并行化学习与处理大规模数据。
Catboost( Categorical Features+Gradient Boosting)采用的策略在降低过拟合的同时保证所有数据集都可用于学习。性能卓越、鲁棒性与通用性更好、易于使用而且更实用。据其介绍 Catboost 的性能可以匹敌任何先进的机器学习算法。
三个都是基于 GBDT 最具代表性的算法,都说自己的性能表现、效率及准确率很优秀,究竟它们谁更胜一筹呢?为了 PK 这三种算法之间的高低,我们给它们安排了一场“最浪漫的 Battle”,通过三轮 Battle 让 XGBoost、Catboost 和 LightGBM 一绝高下!
Round 1:分类模型,按照数据集Fashion MNIST把图像分类(60000行数据,784个特征);
Round 2:回归模型,预测纽约出租车的票价(60000行数据,7个特征);
Round 3:通过海量数据集,预测纽约出租车票价(200万行数据,7个特征);
Battle 规则
在每一轮 PK 中,我们都遵循以下步骤:
1、训练 XGBoost、Catboost、LightGBM 三种算法的基准模型,每个模型使用相同的参数进行训练;
2、使用超参数自动搜索模块 GridSearchCV 来训练 XGBoost、Catboost 和 LightGBM 三种算法的微调整模型;
3、衡量指标:
a.训练和预测的时间;
b.预测得分;
c.可解释性(包括:特征重要性,SHAP 值,可视化树);

PK 结果揭晓
(一)运行时间& 准确度得分
Top 1:LightGBM
Top 2:CatBoost
Top 3:XGBoost
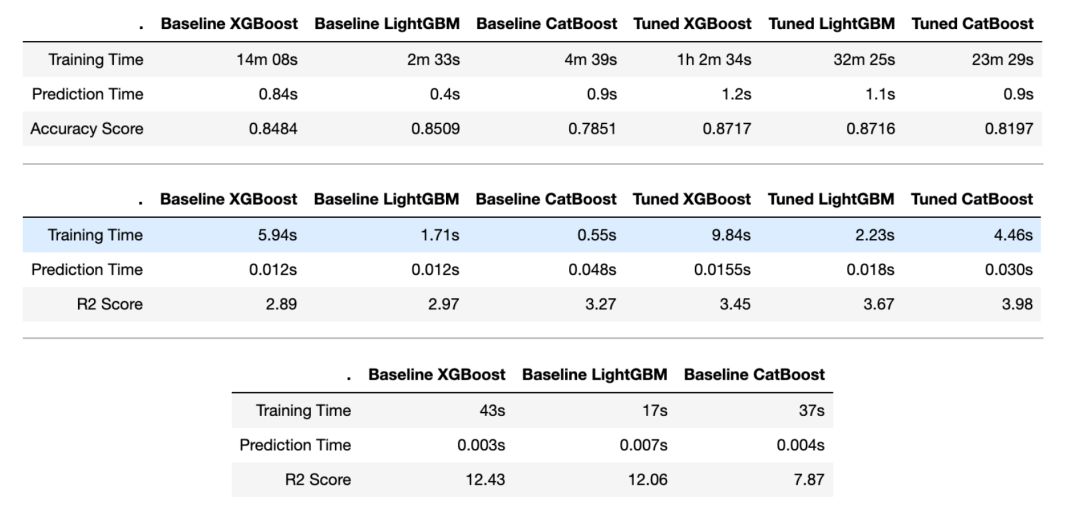
在训练和预测时间两方面,LightGBM 都是明显的获胜者,CatBoost 则紧随其后,而 XGBoost 的训练时间相对更久,但预测时间与其它两个算法的差距没有训练时间那么大。
在增强树(boosted trees)中进行训练的时间复杂度介于?(??log?)和?(?2?)之间,而对于预测,时间复杂度为?(log2 ?),其中? = 训练实例的数量,? = 特征数量,以及? = 决策树的深度。
Round 1 ~ 3
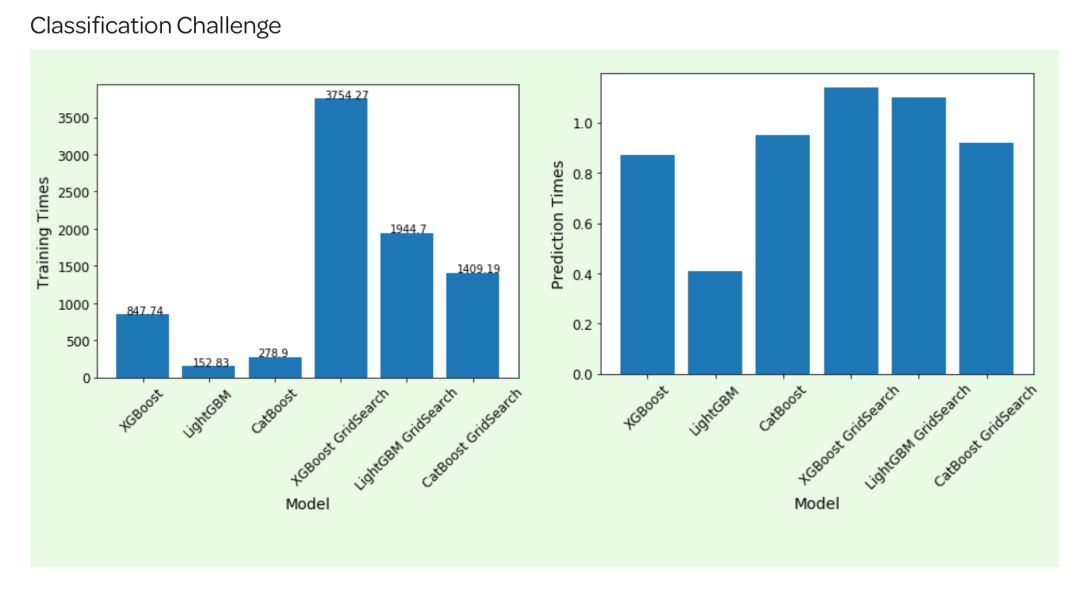
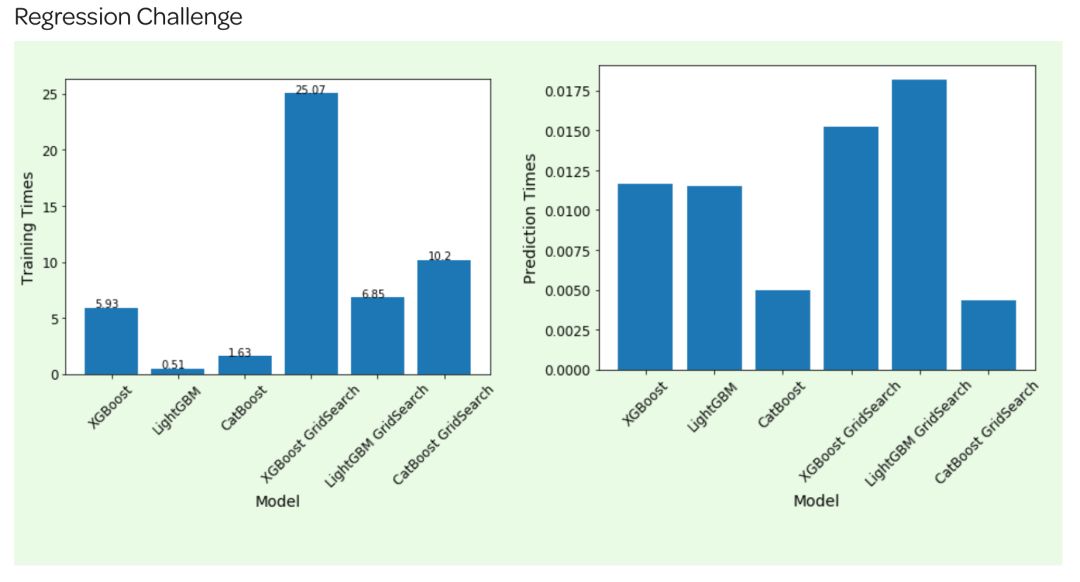
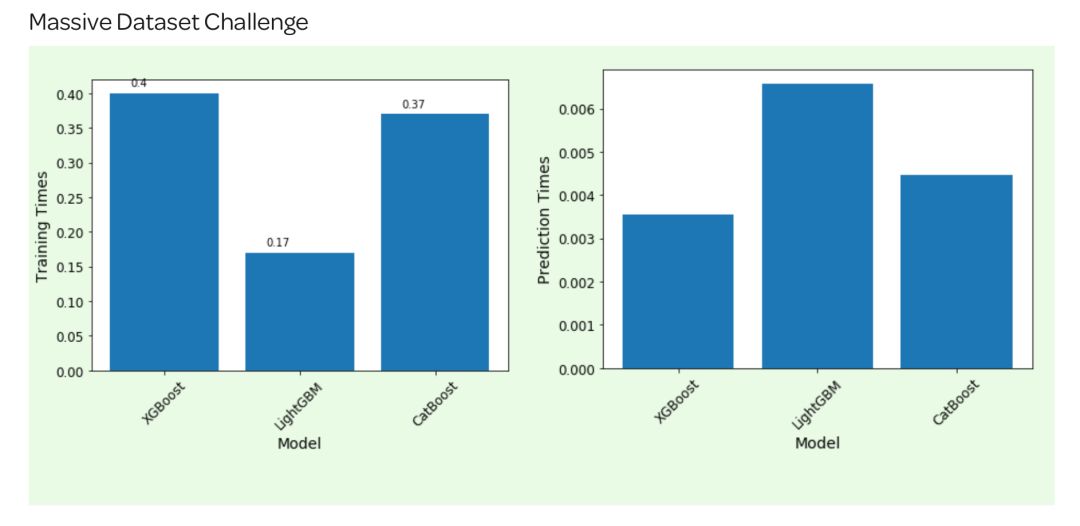
(二)可解释性
一个模型的预测得分仅反映了它的一方面,我们还想知道模型为什么要做出这个预测的。
在这里,我们描绘出了模型特征的重要性和 SHAP 值,还有一个实际的决策树,以便更准确地理解模型的预测。
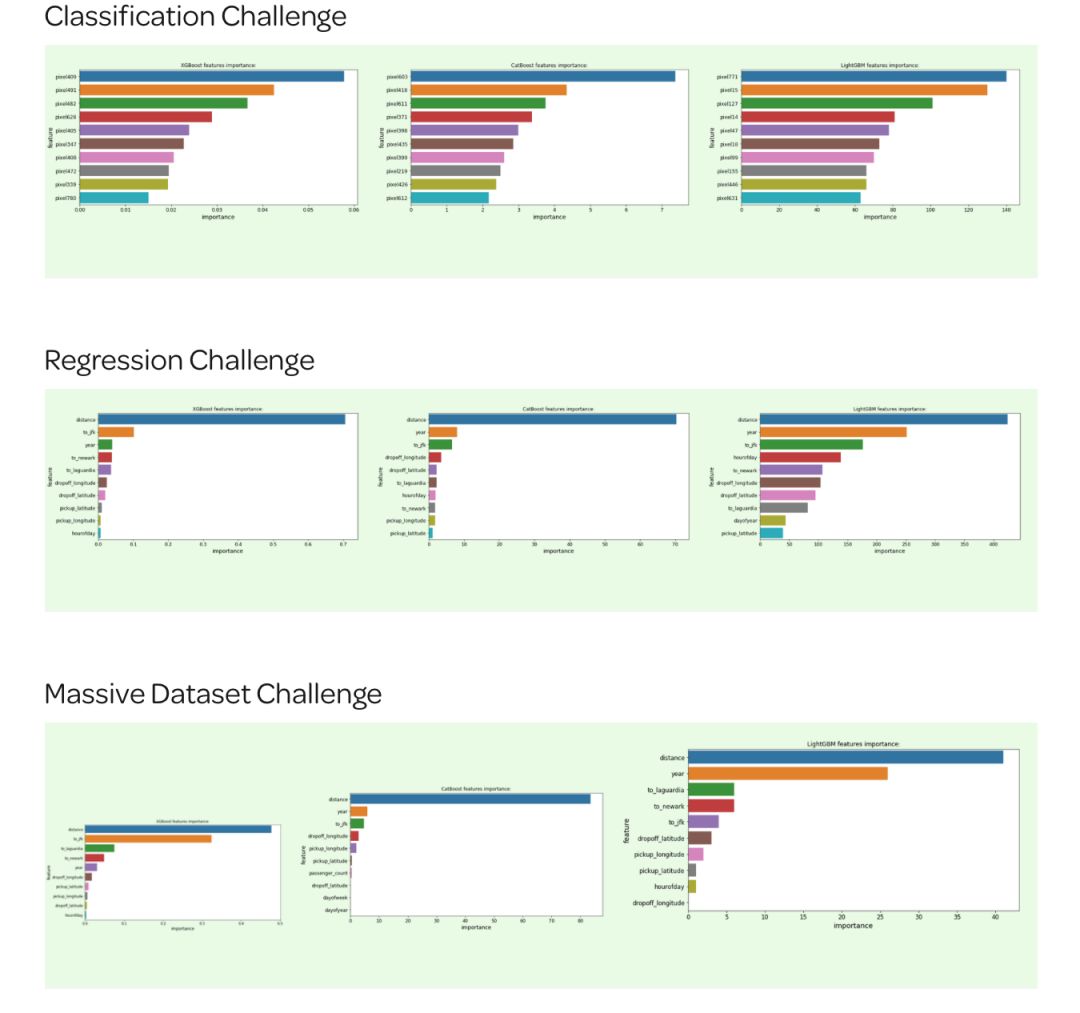
(a)特征的重要性
这三个增强模型都提供了一个 .feature_importances_ attribute 属性,允许我们查看有哪些特征对模型预测的影响是最大的:
Round 1 ~ 3
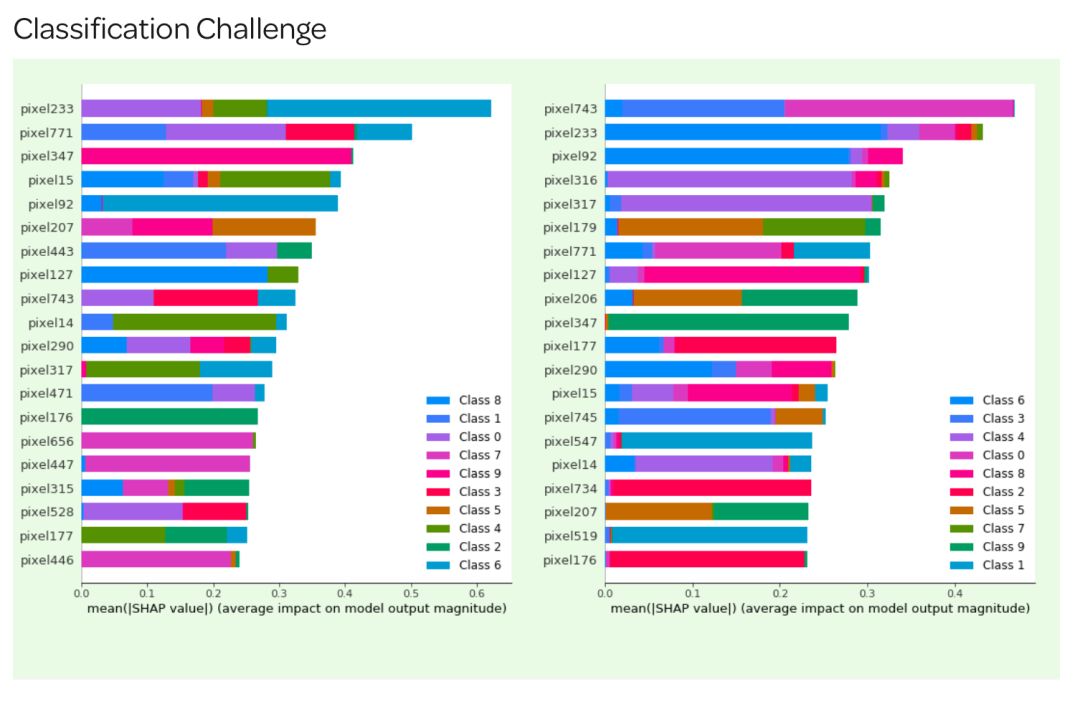
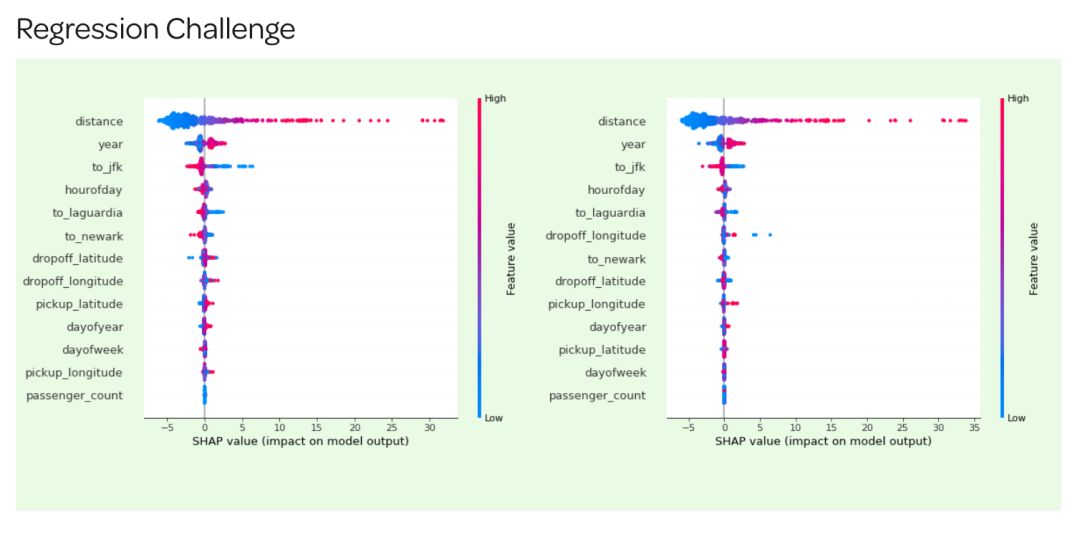
(b)SHAP值
另外一种方法是 SHAP 摘要图,用来了解每个特性对模型输出的影响分布。SHAP 值是在这些特征之间的公平的信用分配,并且具有博弈论一致性的理论保证,这使得它们通常比整个数据集中的那些典型特征的重要性更值得信赖。
Round 1 & 2
(c)绘制决策树
最后,XGBoost 和 LightGBM 这两个算法还允许我们绘制用于进行预测的实际决策树,这对于更好地了解每个特征对目标变量的预测能力非常的有用。而 CatBoost 没有决策树的绘制功能。
如果想看 CatBoost 的结果,这里推荐给大家一个可视化工具:
https://blog.csdn.net/l_xzmy/article/details/81532281
Round 1 & 2

评测总结
CatBoost
(1)CatBoost 提供了比 XGBoost 更高的准确性和和更短的训练时间;
(2)支持即用的分类特征,因此我们不需要对分类特征进行预处理(例如,通过 LabelEncoding 或 OneHotEncoding)。事实上,CatBoost 的文档明确地说明不要在预处理期间使用热编码,因为“这会影响训练速度和最终的效果”;
(3)通过执行有序地增强操作,可以更好地处理过度拟合,尤其体现在小数据集上;
(4)支持即用的 GPU 训练(只需设置参数task_type =“GPU”);
(5)可以处理缺失的值;
LightGBM
(1)LightGBM 也能提供比 XGBoost 更高的准确性和更短的训练时间;
(2)支持并行的树增强操作,即使在大型数据集上(相比于 XGBoost)也能提供更快的训练速度;
(3)使用 histogram-esquealgorithm,将连续的特征转化为离散的特征,从而实现了极快的训练速度和较低的内存使用率;
(4)通过使用垂直拆分(leaf-wise split)而不是水平拆分(level-wise split)来获得极高的准确性,这会导致非常快速的聚合现象,并在非常复杂的树结构中能捕获训练数据的底层模式。可以通过使用 num_leaves 和 max_depth 这两个超参数来控制过度拟合;
XGBoost
(1)支持并行的树增强操作;
(2)使用规则化来遏制过度拟合;
(3)支持用户自定义的评估指标;
(4)处理缺失的值;
(5)XGBoost 比传统的梯度增强方法(如 AdaBoost)要快得多;
如果想深入研究这些算法,可以阅读下面相关文章的链接:
LightGBM: 一种高效的梯度增强决策树
https://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
CatBoost: 支持分类特征的梯度增强
http://learningsys.org/nips17/assets/papers/paper_11.pdf
XGBoost: 一个可扩展的树增强系统
https://arxiv.org/pdf/1603.02754.pdf
重要参数解读
下面列出的是模型中一些重要的参数,以帮助大家更好学习与使用这些算法!
Catboost
n_estimators:表示用于创建树的最大数量;
learning_rate:表示学习率,用于减少梯度的级别;
eval_metric:表示用于过度拟合检测和最佳模型选择的度量标准;
depth:表示树的深度;
subsample:表示数据行的采样率,不能在贝叶斯增强类型设置中使用;
l2_leaf_reg:表示成本函数的L2规则化项的系数;
random_strength:表示在选择树结构时用于对拆分评分的随机量,使用此参数可以避免模型过度拟合;
min_data_in_leaf:表示在一个叶子中训练样本的最小数量。CatBoost不会在样本总数小于指定值的叶子中搜索新的拆分;
colsample_bylevel, colsample_bytree, colsample_bynode — 分别表示各个层、各棵树、各个节点的列采样率;
task_type:表示选择“GPU”或“CPU”。如果数据集足够大(从数万个对象开始),那么在GPU上的训练与在CPU上的训练相比速度会有显著的提升,数据集越大,加速就越明显;
boosting_type:表示在默认情况下,小数据集的增强类型值设置为“Ordered”。这可以防止过度拟合,但在计算方面的成本会很高。可以尝试将此参数的值设置为“Plain”,来提高训练速度;
rsm:对于那些具有几百个特性的数据集,rsm参数加快了训练的速度,通常对训练的质量不会有影响。另外,不建议为只有少量(10-20)特征的数据集更改rsm参数的默认值;
border_count:此参数定义了每个特征的分割数。默认情况下,如果在CPU上执行训练,它的值设置为254,如果在GPU上执行训练,则设置为128;
LightGBM
num_leaves:表示一棵树中最大的叶子数量。在LightGBM中,必须将num_leaves的值设置为小于2^(max_depth),以防止过度拟合。而更高的值会得到更高的准确度,但这也可能会造成过度拟合;
max_depth:表示树的最大深度,这个参数有助于防止过度拟合;
min_data_in_leaf:表示每个叶子中的最小数据量。设置一个过小的值可能会导致过度拟合;
eval_metric:表示用于过度拟合检测和最佳模型选择的度量标准;
learning_rate:表示学习率,用于降低梯度的级别;
n_estimators:表示可以创建树的最大数量;
colsample_bylevel, colsample_bytree, colsample_bynode — 分别表示各个层、各棵树、各个节点的列采样率;
boosting_type — 该参数可选择以下的值:
‘gbdt’,表示传统的梯度增强决策树;
‘dart’,缺失则符合多重累计回归树(Multiple Additive Regression Trees);
‘goss’,表示基于梯度的单侧抽样(Gradient-based One-Side Sampling);
‘rf’,表示随机森林(Random Forest);
feature_fraction:表示每次迭代所使用的特征分数(即所占百分比,用小数表示)。将此值设置得较低,来提高训练速度;
min_split_again:表示当在树的叶节点上进行进一步的分区时,所需最小损失值的减少量;
n_jobs:表示并行的线程数量,如果设为-1则可以使用所有的可用线程;
bagging_fraction:表示每次迭代所使用的数据分数(即所占百分比,用小数表示)。将此值设置得较低,以提高训练速度;
application :default(默认值)=regression, type(类型值)=enum, options(可选值)=
regression : 表示执行回归任务;
binary : 表示二进制分类;
multiclass:表示多个类的类别;
lambdarank : 表示lambdarank 应用;
max_bin:表示用于存放特征值的最大容器(bin)数。有助于防止过度拟合;
num_iterations:表示增强要执行的迭代的迭代;
XGBoost 参数
https://xgboost.readthedocs.io/en/latest/parameter.html
LightGBM 参数
https://lightgbm.readthedocs.io/en/latest/Python-API.html
CatBoost 参数
https://catboost.ai/docs/concepts/python-reference_parameters-list.html#python-reference_parameters-list
上面三个文件可以查看这些模型所有超参数。
如果想详细本文的代码和原文,可访问下面的地址:
https://www.kaggle.com/lavanyashukla01/battle-of-the-boosting-algos-lgb-xgb-catboost
https://lavanya.ai/2019/06/27/battle-of-the-boosting-algorithms/
(*本文为 AI科技大本营编译文章,转载请联系 1092722531)
◆
精彩推荐
◆

推荐阅读
阿里90后科学家研发,达摩院开源新一代AI算法模型
正态分布为何如此重要?
智能文本信息抽取算法的进阶
入门必备 | 一文读懂神经架构搜索
印度人才出口:一半美国科技企业CEO是印度裔 | 数据分析中印青年
为什么说“大公司的技术顽疾根本挽救不了”
25 年 IT 老兵零基础写小说,作品堪比《三体》| 人物志
中小企业搭建混合云,服务器如何选?
从0到1 | 文本挖掘的传统与深度学习算法
一览微软在机器阅读理解、推荐系统、人机对话等最新研究进展 | ACL 2019
1.2w星!火爆GitHub的Python学习100天刷爆朋友圈!
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

云计算之Docker介绍
1. 百科简介 Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从Apache2.0协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。 容器是完全使用沙…

还在纠结垃圾分类问题?带你用Python感受ImageNet冠军模型SENet的强大
作者 | beyondma转载自CSDN博客本月1日起,上海正式开始了“史上最严“垃圾分类的规定,扔错垃圾最高可罚200元。全国其它46个城市也要陆续步入垃圾分类新时代。各种被垃圾分类逼疯的段子在社交媒体上层出不穷。其实从人工智能的角度看垃圾分类就是图像处理…

软件开发流程包含哪些内容
2019独角兽企业重金招聘Python工程师标准>>> 能否开发出一个好的软件,关键是看软件开发前期所做的工作,重点是这个软件有没有一个好的 软件开发流程,因为一个好的软件开发流程关系到到这个软件的成败和最后能达到一个什么的效果&a…
在对话框中应用CScrollView显示图像
1、用vs2008创建一个基于对话框的工程DialogView; 2、添加一个新类CMyDocument,基类为CDocument; 3、添加一个新类CMyView,基类为CScrollView; 4、修改CMyDocument的头文件: #pragma once // CMyDocument …

如何用纯 CSS 创作一个同心圆弧旋转 loader 特效
效果预览 在线演示 按下右侧的“点击预览”按钮在当前页面预览,点击链接全屏预览。 https://codepen.io/zhang-ou/pen/OZmXQX 可交互视频教程 此视频是可以交互的,你可以随时暂停视频,编辑视频中的代码。 请用 chrome, safari, edge 打开观看…

Java长见到的面试题,看你能答出几题,就知道自己有多菜了
作者:Java3y前言只有光头才能变强Redis目前还在看,今天来分享一下我在秋招看过(遇到)的一些面试题(相对比较常见的)0、final关键字简要说一下final关键字,final可以用来修饰什么?这题我是在真实的面试中遇到的,当时答得…
数据结构实验之链表一:顺序建立链表
题目描述 输入N个整数,按照输入的顺序建立单链表存储,并遍历所建立的单链表,输出这些数据。输入 第一行输入整数的个数N;第二行依次输入每个整数。输出 输出这组整数。示例输入 8 12 56 4 6 55 15 33 62 示例输出 12 56 4 6 55 15…

深度学习在人脸检测中的应用 | CSDN 博文精选
作者 | 梁志成、刘鹏、陈方杰责编 | 唐小引转载自CSDN(ID:csdnnews)在目标检测领域,可以划分为人脸检测与通用目标检测,往往人脸这方面会有专门的算法(包括人脸检测、人脸识别、人脸其他属性的识别等)&…
vs2008中,在OCX控件中应用doc/view基本步骤
1、利用向导创建一个MFC ActiveX Control控件CMyOCX; 2、在工程中加入ActivDoc头文件和执行文件; class CActiveXDocTemplate : public CSingleDocTemplate { enum { IDR_NOTUSED 0x7FFF }; CWnd* m_pParentWnd; CFrameWnd* m_pFrameWnd; C…

常见存储过程分页PK赛——简单测试分析常见存储过程分页速度
数据的分页是我们再熟悉不过的功能了,各种各样的分页方式层出不穷。今天我把一些常见的存储过程分页列出来,再简单地测一下性能,算是对知识的总结,也是对您好想法的抛钻引玉。废话不多说,开始吧~~ 1.首先建立一张测试表…

YOLOv3模型剪枝,瘦身80%,提速100%,精度基本不变
作者 | CV君转载自我爱计算机视觉(ID: aicvml)如果要在实际应用中部署目标检测,你会想到哪项算法?在52CV目标检测交流群里,被提及最多的,恐怕就是YOLOv3了。虽然新出的一些算法号称“完胜”“吊打”某某某算…
Ubuntu开发用新机安装流程
1.SSH安装 Ubuntu缺省已安装客户端,此处安装服务端 sudo apt-get install openssh-server 确认sshserver是否启动 netstat -tlp | grep ssh 或 ps -e | grep ssh 未启动,选择启动 sudo /etc/init.d/ssh start 2.问题解决:ACPI Error:Method p…

人工智能六十年技术简史
出品 | AI科技大本营(ID:rgznai100)作者:李理,环信人工智能研发中心vp,十多年自然语言处理和人工智能研发经验。主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设…

【Android游戏开发二十五】在Android上的使用《贝赛尔曲线》!
首先对于《赛贝尔曲线》不是很了解的童鞋,请自觉白度百科、google等等... 为了方便偷懒的童鞋,这里给个《贝赛尔曲线》百科地址,以及一段话简述《贝赛尔曲线》: 《贝赛尔曲线》白度百科快速地址:http://baike.baidu.co…
Spring Boot 工程集成全局唯一ID生成器 Vesta
2019独角兽企业重金招聘Python工程师标准>>> 本文内容脑图如下: 文章共 760字,阅读大约需要 2分钟 ! 概 述 在前一篇文章 《Spring Boot工程集成全局唯一ID生成器 UidGenerator》 中给大家推荐了一款由百度开发的基于 Snowflake算…
vs2008中,创建基于对话框的mfc动态库步骤
1、利用MFC Dll向导初始生成一个mfc dll(默认设置); 2、添加一个对话框资源; 3、向工程中添加一个.h、.cpp文件,作为外部的接口; 4、.h头文件的格式仿照于基于控制台的dll的头文件格式; 5、.h头文件中包括资源文件头文…
poj3468 A Simple Problem with Integers
http://acm.hust.edu.cn:8080/judge/problem/viewProblem.action?id14607 题意:题目给你n个数,m个操作,接下来一行给你这n个数,接下的几行给出m个操作,Q a b 表示查询区间[a,b]里的数和和。U a b c 表示把区间[a,b]里的数都加上c…
【Luogu】P1613 跑路
【Luogu】P1613 跑路 一、题目 题目描述 小A的工作不仅繁琐,更有苛刻的规定,要求小A每天早上在6:00之前到达公司,否则这个月工资清零。可是小A偏偏又有赖床的坏毛病。于是为了保住自己的工资,小A买了一个十分牛B的空间…
matlab图形用户界面设计简介
1、File->New->GUI->Create New GUI->Blank GUI->OK即可打开图形用户界面开发环境。 在里面可以拖放需要的控件,包括pushbutton、slider、radiobutton、togglebutton、checkbox、listbox、popupmenu、edit text、static text、table、axes、panel、…

旷视发布《人工智能应用准则》,倡导AI技术健康可持续发展
2019年7月8日,旷视宣布推出基于企业自身管理标准的《人工智能应用准则》(以下简称《准则》),旨在从人工智能企业自身的角度,规范、引导人工智能技术正确运用和健康发展,并确保其安全可控可靠,促…
Java知识积累——String引用的判断问题
看如下程序 1 public static void main(String[] args) {2 String a new String("abc");3 String b new String("abc");4 System.out.println(a b); 5 6 String c "abc";7 String d "abc";8 …
windows7下vs2008常见错误解决方法汇总
1、fatal error LNK1000:Internal error during IncrBuildImage 解决方法:选中对应工程-->点击右键,选择Properties-->Configuration Properties-->Linker-->General-->选中Enable Incremental Linking:改为No(/INCREMENTAL:NO),原始选项…

5G对AIoT的作用并无夸大,最大价值在于融合
采访嘉宾 | 崔宝秋、高恩重整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)近年来,AIoT 的概念非常火爆,有不少企业将 AIoT 提升到公司的战略发展高度,然而实际上,走进普通人日常生活并真正实用的 AIoT 产品…
[USACO07JAN]平衡的阵容Balanced Lineup BZOJ 1699
题目背景 题目描述: 每天,农夫 John 的N(1 < N < 50,000)头牛总是按同一序列排队. 有一天, John 决定让一些牛们玩一场飞盘比赛. 他准备找一群在对列中为置连续的牛来进行比赛. 但是为了避免水平悬殊,牛的身高不应该相差太大. John 准备了Q (1 < Q < 18…

深度学习目标检测法进化史,看这一篇就够了
作者 | 黄浴,奇点汽车美研中心首席科学家兼总裁来源 | 转载自知乎专栏自动驾驶的挑战和发展本文将介绍自动驾驶中的深度学习目标检测的基本概念和方法,并对几个主要 Anchor free 方法进行了比较,希望对读者有所帮助,以下为正文&am…
Bridge Pattern
2019独角兽企业重金招聘Python工程师标准>>> http://www.cnblogs.com/hegezhou_hot/archive/2010/12/10/1902185.html 桥接模式的主要目的是将一个对象的变化因素抽象出来,不是通过类继承的方式来满足这个因素的变化,而是通过对象组合的方式来…
matlab神经网络工具箱函数汇总
转自:http://hi.baidu.com/lingyin55/blog/item/7a968ead11fe180c4b36d61e.html 1. 网络创建函数 newp 创建感知器网络 newlind 设计一线性层 newlin 创建一线性层 newff 创建一前馈BP网络 newcf 创建一多层前馈BP网络 newfftd 创建一前馈输入延迟BP网…
[每日短篇] 17 - 正确使用随机数 Random
2019独角兽企业重金招聘Python工程师标准>>> 随机数在系统开发中几乎是不可避免的一个需求,在大多数面试宝典一定会告诉你所谓的随机数其实是“伪”随机数,除此之外也就没有什么别的了。实际上这条知识本身已经是非常落后了,更不用…
LoadRunner的参数化功能分享
LoadRunner的参数化功能分享http://automationqa.com/forum.php?modviewthread&tid1598&fromuid2
MFC菜单的使用
1、 创建弹出菜单: (1)、利用向导,创建一个基于单文档的应用程序; (2)、在资源视图中选中”menu”,鼠标右键插入一新菜单IDR_POPMENU; (3)、在IDR_POPMENU菜单中添加”弹出菜单”选项,在”弹出菜单”下…