SIFT特征点匹配中KD-tree与Ransac算法的使用
转自:http://blog.csdn.net/ijuliet/article/details/4471311
Step1:BBF算法,在KD-tree上找KNN。第一步做匹配咯~
1.什么是KD-tree(fromwiki)
K-Dimension tree,实际上是一棵平衡二叉树。
一般的KD-tree构造过程:
functionkdtree (list of points pointList, int depth)
{
ifpointList is empty
returnnil;
else {
// Select axis based on depth so thataxis cycles through all valid values
varint axis := depth mod k;
// Sort point list and choose medianas pivot element
selectmedian by axis from pointList;
// Create node and construct subtrees
vartree_node node;
node.location:= median;
node.leftChild:= kdtree(points in pointList before median, depth+1);
node.rightChild:= kdtree(points in pointList after median, depth+1);
returnnode;
}
}
2.BBF算法,在KD-tree上找KNN ( K-nearest neighbor)
BBF(BestBin First)算法,借助优先队列(这里用最小堆)实现。从根开始,在KD-tree上找路子的时候,错过的点先塞到优先队列里,自己先一个劲儿扫到leaf;然后再从队列里取出目前key值最小的(这里是是ki维上的距离最小者),重复上述过程,一个劲儿扫到leaf;直到队列找空了,或者已经重复了200遍了停止。
Step1:将img2的features建KD-tree; kd_root = kdtree_build( feat2,n2 );。在这里,ki是选取均方差最大的那个维度,kv是各特征点在那个维度上的median值,features是你率领的整个儿子孙子特征大军,n是你儿子孙子个数。
/** a node in a k-d tree */ struct kd_node{ int ki; /**< partition key index */ double kv; /**< partition key value */ int leaf; /**< 1 if node is a leaf, 0 otherwise */ struct feature* features; /**< features at this node */ int n; /**< number of features */ struct kd_node* kd_left; /**< left child */ struct kd_node* kd_right; /**< right child */ }; |
Step2: 将img1的每个feat到KD-tree里找k个最近邻,这里k=2。
k= kdtree_bbf_knn( kd_root, feat, 2, &nbrs, KDTREE_BBF_MAX_NN_CHKS );
min_pq = minpq_init(); minpq_insert( min_pq, kd_root, 0 ); while( min_pq->n > 0 && t < max_nn_chks ) //队列里有东西就继续搜,同时控制在t<200(即200步内) { expl = (struct kd_node*)minpq_extract_min( min_pq ); //取出最小的,front & pop expl = explore_to_leaf( expl, feat, min_pq ); //从该点开始,explore到leaf,路过的“有意义的点”就塞到最小队列min_pq中。 for( i = 0; i < expl->n; i++ ) // { tree_feat = &expl->features[i]; bbf_data->old_data = tree_feat->feature_data; bbf_data->d = descr_dist_sq(feat, tree_feat); //两feat均方差 tree_feat->feature_data = bbf_data; n += insert_into_nbr_array( tree_feat, _nbrs, n, k ); //按从小到大塞到neighbor数组里,到时候取前k个就是 KNN 咯~ n 每次加1或0,表示目前已有的元素个数 } t++; } |
对“有意义的点”的解释:
struct kd_node* explore_to_leaf( struct kd_node* kd_node, struct feature* feat, struct min_pq* min_pq )//expl, feat, min_pq { struct kd_node* unexpl, * expl = kd_node; double kv; int ki; while( expl && ! expl->leaf ) { ki = expl->ki; kv = expl->kv; if( feat->descr[ki] <= kv ) { unexpl = expl->kd_right; expl = expl->kd_left; //走左边,右边点将被记下来 } else{ unexpl = expl->kd_left; expl = expl->kd_right; //走右边,左边点将被记下来 } minpq_insert( min_pq, unexpl, ABS( kv - feat->descr[ki] ) ) ;//将这些点插入进来,key键值为|kv - feat->descr[ki]| 即第ki维上的差值 } return expl; } |
Step3: 如果k近邻找到了(k=2),那么判断是否能作为有效特征,d0/d1<0.49就算是咯~
d0 = descr_dist_sq( feat, nbrs[0] );//计算两特征间squared Euclidian distance d1 = descr_dist_sq( feat, nbrs[1] ); if( d0 < d1 * NN_SQ_DIST_RATIO_THR )//如果d0/d1小于阈值0.49 { pt1 = cvPoint( cvRound( feat->x ), cvRound( feat->y ) ); pt2 = cvPoint( cvRound( nbrs[0]->x ), cvRound( nbrs[0]->y ) ); pt2.y += img1->height; cvLine( stacked, pt1, pt2, CV_RGB(255,0,255), 1, 8, 0 );//画线 m++;//matches个数 feat1[i].fwd_match = nbrs[0]; } |
Step2:通过RANSAC算法来消除错配,什么是RANSAC先?
1.RANSAC(Random Sample Consensus, 随机抽样一致)(from wiki)
该算法做什么呢?呵呵,用一堆数据去搞定一个待定模型,这里所谓的搞定就是一反复测试、迭代的过程,找出一个error最小的模型及其对应的同盟军(consensusset)。用在我们的SIFT特征匹配里,就是说找一个变换矩阵出来,使得尽量多的特征点间都符合这个变换关系。
算法思想:
input:
data - a set of observations
model - a model that can be fitted todata
n - the minimum number of datarequired to fit the model
k - the maximum number of iterationsallowed in the algorithm
t - a threshold value for determiningwhen a datum fits a model
d - the number of close data valuesrequired to assert that a model fits well to data
output:
best_model - model parameters whichbest fit the data (or nil if no good model is found)
best_consensus_set - data point fromwhich this model has been estimated
best_error - the error of this modelrelative to the data
iterations:= 0
best_model:= nil
best_consensus_set:= nil
best_error:= infinity
whileiterations < k //进行K次迭代
maybe_inliers:= n randomly selected values from data
maybe_model:= model parameters fitted to maybe_inliers
consensus_set:= maybe_inliers
forevery point in data not in maybe_inliers
ifpoint fits maybe_model with an error smaller than t //错误小于阈值t
addpoint to consensus_set //成为同盟,加入consensus set
if thenumber of elements in consensus_set is > d //同盟军已经大于d个人,够了
(thisimplies that we may have found a good model,
nowtest how good it is)
better_model:= model parameters fitted to all points in consensus_set
this_error:= a measure of how well better_model fits these points
ifthis_error < best_error
(wehave found a model which is better than any of the previous ones,
keepit until a better one is found)
best_model:= better_model
best_consensus_set:= consensus_set
best_error:= this_error
incrementiterations
returnbest_model, best_consensus_set, best_error
2.RANSAC去除错配:
H= ransac_xform( feat1, n1, FEATURE_FWD_MATCH, lsq_homog, 4,0.01,homog_xfer_err, 3.0, NULL, NULL );
nm = get_matched_features( features, n, mtype, &matched ); /* initialize random number generator */ rng = gsl_rng_alloc( gsl_rng_mt19937 ); gsl_rng_set( rng, time(NULL) ); in_min = calc_min_inliers( nm, m, RANSAC_PROB_BAD_SUPP, p_badxform ); //符合这一要求的内点至少得有多少个 p = pow( 1.0 - pow( in_frac, m ), k ); i = 0; while( p > p_badxform )//p>0.01 { sample = draw_ransac_sample( matched, nm, m, rng ); extract_corresp_pts( sample, m, mtype, &pts, &mpts ); M = xform_fn( pts, mpts, m ); if( ! M ) goto iteration_end; in = find_consensus( matched, nm, mtype, M, err_fn, err_tol, &consensus); if( in > in_max ) { if( consensus_max ) free( consensus_max ); consensus_max = consensus; in_max = in; in_frac = (double)in_max / nm; } else free( consensus ); cvReleaseMat( &M ); iteration_end: release_mem( pts, mpts, sample ); p = pow( 1.0 - pow( in_frac, m ), ++k ); } /* calculate final transform based on best consensus set */ if( in_max >= in_min ) { extract_corresp_pts( consensus_max, in_max, mtype, &pts, &mpts ); M = xform_fn( pts, mpts, in_max ); in = find_consensus( matched, nm, mtype, M, err_fn, err_tol, &consensus); cvReleaseMat( &M ); release_mem( pts, mpts, consensus_max ); extract_corresp_pts( consensus, in, mtype, &pts, &mpts ); M = xform_fn( pts, mpts, in ); |
思考中的一些问题:
features间的对应关系,记录在features->fwd_match里(matching feature from forward
imge)。
1.数据是nm个特征点间的对应关系,由它们产生一个3*3变换矩阵(xform_fn= hsq_homog函数,此要>=4对的对应才可能计算出来咯~),此乃模型model。
2.然后开始找同盟军(find_consensus函数),判断除了sample的其它对应关系是否满足这个模型(err_fn= homog_xfer_err函数,<=err_tol就OK~),满足则留下。
3.一旦大于当前的in_max,那么该模型就升级为目前最牛的模型。(最最原始的RANSAC是按错误率最小走的,我们这会儿已经保证了错误率在err_tol范围内,按符合要求的对应数最大走,尽量多的特征能匹配地上)
4.重复以上3步,直到(1-wm)k <=p_badxform (即0.01),模型就算找定~
5.最后再把模型和同盟军定一下,齐活儿~
声明:以上代码参考Rob Hess的SIFT实现。
其它参考文献:
1、http://www.cnblogs.com/slysky/archive/2011/11/08/2241247.html
2、http://en.wikipedia.org/wiki/Kd_tree
3、http://www.cnblogs.com/tjulxh/archive/2011/12/31/2308921.html
4、http://grunt1223.iteye.com/blog/961063
相关文章:

jQuery带缩略图的宽屏焦点图插件
在线演示 本地下载

追溯XLNet的前世今生:从Transformer到XLNet
作者丨李格映来源 | 转载自CSDN博客导读:2019 年 6 月,CMU 与谷歌大脑提出全新 XLNet,基于 BERT 的优缺点,XLNet 提出一种泛化自回归预训练方法,在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当…

微软MCITP系列课程
http://liushuo890.blog.51cto.com/5167996/d-1转载于:https://blog.51cto.com/showcart/1156172
在Ubuntu11.10中安装配置OpenCV2.3.1和CodeBlocks
1、 打开终端; 2、 执行指令,删除ffmpeg and x264旧版本:sudo apt-get removeffmpeg x264 libx264-dev 3、下载安装x264和ffmpeg所有的依赖:sudo apt-get update sudo apt-get installbuild-essential checkinstall git cmake…
深入浅出Rust Future - Part 1
本文译自Rust futures: an uneducated, short and hopefully not boring tutorial - Part 1,时间:2018-12-02,译者:motecshine, 简介:motecshine 欢迎向Rust中文社区投稿,投稿地址,好文将在以下地方直接展示 Rust中文社区首页Rust…
cmd 修改文件属性
现在的病毒基本都会采用一种方式,就是将病毒文件的属性设置为系统隐藏属性以逃避一般用户的眼睛,而且由于Windows系统的关系,这类文件在图形界面下是不能修改其属性的。但是好在Windows还算做点好事,留下了一个attrib命令可以让我…

Django 视图
Django之视图 目录 一个简单的视图CBV和FBV FBV版:CBV版:给视图加装饰器 使用装饰器装饰FBV使用装饰器装饰CBVrequest对象 请求相关的常用值属性方法Response对象 使用属性JsonResponse对象Django shortcut functions render()redirect()Django的View&am…

喜大普奔!GitHub官方文档推出中文版
原创整理 | Python开发者(ID:PythonCoder)最近程序员交友圈出了一个大新闻,GitHub 帮助文档正式推出中文版了,之前一直都是只有英文文档,看起来费劲不方便。这份中文文当非常详尽,可以说有了它 …
Linux中获取当前程序路径的方法
1、命令行实现:转自:http://www.linuxdiyf.com/viewarticle.php?id84177 #!/bin/sh cur_dir$(pwd) echo $cur_dir 注意:在cur_dir后没空格,后面也不能有空格,不然它会认为空格不是路径而报错 2、程序实现…
android 关于字符转化问题
今日在写android的客户端,发现字符转化是个大问题。 下面是Unicode转UTF-8的转化,便于以后使用 private static String decodeUnicode(String theString) { char aChar; int len theString.length(); StringBuffer outBuffer new Strin…
30分钟看懂XGBoost的基本原理
作者 | 梁云1991转载自Python与算法之美(ID: Python_Ai_Road)一、XGBoost和GBDTxgboost是一种集成学习算法,属于3类常用的集成方法(bagging,boosting,stacking)中的boosting算法类别。它是一个加法模型,基模型一般选择树模型&…
Linux下遍历文件夹的实现
转自:http://blog.csdn.net/wallwind/article/details/7528474 linux C 遍历目录及其子目录 #include <stdio.h> #include <string.h> #include <stdlib.h> #include <dirent.h> #include <sys/stat.h> #include <unistd.h&…

如何用Python画一棵漂亮的树
Tree海龟绘图turtle 在1966年,Seymour Papert和Wally Feurzig发明了一种专门给儿童学习编程的语言——LOGO语言,它的特色就是通过编程指挥一个小海龟(turtle)在屏幕上绘图。 海龟绘图(Turtle Graphics)后来…
windows7下,Java中利用JNI调用c++生成的动态库的使用步骤
1、从http://www.oracle.com/technetwork/java/javase/downloads/jdk-7u2-download-1377129.html下载jdk-7u2-windows-i586.exe,安装到D:\ProgramFiles\Java,并将D:\ProgramFiles\Java\jdk1.7.0_02\bin添加到环境变量中; 2、从http://www.ec…
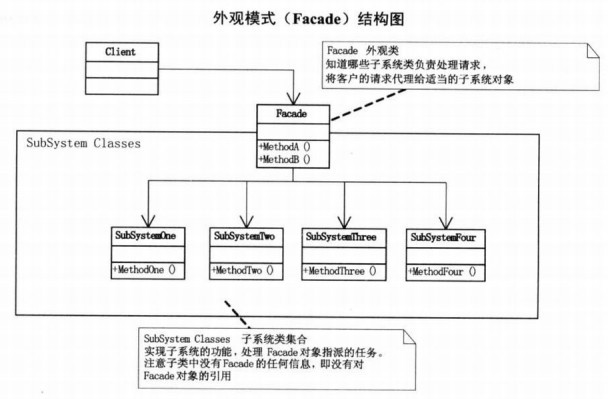
外观模式 - 设计模式学习
外观模式(Facade),为子系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。 怎么叫更加容易使用呢?多个方法变成一个方法,在外观看来,只需知道这个功能完成…
Google最新论文:大规模深度推荐模型的特征嵌入问题有解了!
转载自深度传送门(ID: gh_5faae7b50fc5)导读:本文主要介绍下Google在大规模深度推荐模型上关于特征嵌入的最新论文。 一、背景大部分的深度学习模型主要包含如下的两大模块:输入模块以及表示学习模块。自从NAS[1]的出现以来&#…
[20181204]低版本toad 9.6直连与ora-12505.txt
[20181204]低版本toad 9.6直连与ora-12505.txt--//我们生产系统还保留有一台使用AMERICAN_AMERICA.US7ASCII字符集的数据库,这样由于toad新版本不支持该字符集的中文显示.--//我一直保留toad 9.6的版本,并且这个版本是32位的,我必须在我的机器另外安装10g 32位版本的客户端,这样…
Google揭露美国政府通过NSL索要用户资料
当美国联邦调查局FB或其他美国执法机构进行有关国家安全的调查时,能通过一种“国家安全密函National Security ,NSL)”向服务商索取其用户的个人资料,由于事关国家安全,因此该密函并不需经法院同意。但根据美国电子通讯隐私法的规…
Ubuntu下,Java中利用JNI调用codeblocks c++生成的动态库的使用步骤
1、 打开新立得包管理器,搜索JDK,选择openjdk-6-jdk安装; 2、 打开Ubuntu软件中心,搜索Eclipse,选择Eclipse集成开发环境,安装; 3、 打开Eclipse,File-->New-->Java Proj…
比Hadoop快至少10倍的物联网大数据平台,我把它开源了
作者 | 陶建辉转载自爱倒腾的程序员(ID: taosdata)导读:7月12日,涛思数据的TDengine物联网大数据平台宣布正式开源。涛思数据希望尽最大努力打造开发者社区,维护这个开源的商业模式,他们相信不将最核心的代…

Script:挖掘AWR实现查询SCN历史增长走势
AWR中记录了快照时间内calls to kcmgas的统计值,calls to kcmgas的意义在于通过递归调用获得一个新的SCN,该统计值可以看做SCN增长速度的主要依据,通过挖掘AWR可以了解SCN的增长走势,对于我们诊断SCN HEADROOM问题有所帮助&#x…
运动目标检测__光流法
以下内容摘自一篇硕士论文《视频序列中运动目标检测与跟踪算法的研究》: 1950年Gibson首先提出了光流的概念,光流(optical flow)法是空间运动物体在观测成像面上的像素运动的瞬时速度。物体在运动的时候,它在图像上对应点的亮度模式也在做相…
读完这45篇论文,“没人比我更懂AI了”
作者 | 黄海广 转载自机器学习爱好者(ID:ai-start-com) 导读:AI领域的发展会是IT中最快的。我们所看到的那些黑科技,其后无不堆积了大量论文,而且都是最新、最前沿的论文。从某种角度来讲,它们所用的技术跟…
深入理解JVM——虚拟机GC
对象是否存活 Java的GC基于可达性分析算法(Python用引用计数法),通过可达性分析来判定对象是否存活。这个算法的基本思想是通过一系列"GC Roots"的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当…

2019年最新华为、BAT、美团、头条、滴滴面试题目及答案汇总
作者 | 苏克1900来源 | 高级农民工(ID:Mocun6)【导语】最近 GitHub 上一个库火了,总结了 阿里、腾讯、百度、美团、头条等国内主流大厂的技术面试题目,目前 Star 2000,还在持续更新中,预计会火下…

华胜天成ivcs云系统初体验2
重启完成以后,就看到传统的linux init3级别的登录界面。输入用户名root 密码:123456 (默认)接下来的工作是配置一些东西,让它跑起来。首先,要修改IP地址,还有机器名。输入命令:ivcs…
OpenCV中响应鼠标信息cvSetMouseCallback函数的使用
转自:http://blog.csdn.net/haihong84/article/details/6599838 程序代碼如下: #include <cv.h> #include <highgui.h> #include <stdio.h void onMouse(int event,int x,int y,int flags,void* param ); int main(int argc, char** …
日常遇到的一些问题或知识的笔记(一)
1、坑爹的sessionStorage 一直以为sessionStorage、localStorage跟cookie一样,只要存在,整个域名下都可见,直到新开了一个窗口tab页,惊奇的发现下面的sessionStorage丢失了! Web Storage 包含如下两种机制:…
你是“10倍工程师”吗?这个事,国外小伙伴们都快“吵”起来了
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】近日,推特上一个话题“10x工程师”异常火爆,引发的热议经久不散。这个话题由一位印度初创公司投资人 Shekhar Kirani 的一条推特引发,他写道;“如果…