谷歌新研究:基于数据共享的神经网络快速训练方法

作者 | Google Brain
译者 | 凯隐
责编 | 夕颜
出品 | AI科技大本营(ID:rgznai100)
导读:神经网络技术的普及离不开硬件技术的发展,GPU 和 TPU 等硬件型训练加速器带来的高算力极大的缩短了训练模型需要的时间,使得研究者们能在短时间内验证并调整想法,从而快速得到理想的模型。
然而,在整个训练流程中,只有反向传播优化阶段在硬件加速器上完成,而其他的例如数据载入和数据预处理等过程则不受益于硬件加速器,因此逐渐成为了整个训练过程的瓶颈。本文应用数据共享和并行流水线的思想,在一个数据读入和预处理周期内多次重复使用上一次读入的数据进行训练,有效降低模型达到相同效果所需的总 epoch 次数,在算法层面实现对训练过程的加速。
网络训练的另一个瓶颈
网络训练速度的提升对神经网络的发展至关重要。过去的研究着重于如何在 GPU 和更专业的硬件设备上进行矩阵和张量的相关运算,从而代替 CPU 进行网络训练。GPU 和TPU 等相关专业计算硬件的通用性不像 CPU 那么广泛,但是由于特殊的设计和计算单元构造,能够在一些专门的任务中具有大幅超越 CPU 的表现。
由于 GPU 相关硬件善于进行矩阵和张量运算,因此通常用于训练中的反向传播计算过程,也就是参数优化过程。然而,一个完整的网络训练流程不应该只包含反向传播参数优化过程,还应该有数据的读入和预处理的过程,后者依赖于多种硬件指标,包括 CPU、硬盘、内存大小、内存带宽、网络带宽,而且在不同的任务中细节也不尽相同,很难专门为这个概念宽泛的过程设计专用的硬件加速器,因此其逐渐成为了神经网络训练过程中相对于方向传播过程的另一个瓶颈。
因此,如果要进一步提升训练速度,就需要考虑优化非硬件加速的相关任务,而不仅仅是优化反向传播过程,这一优化可以从两个方面来进行:
(1) 提升数据载入和预处理的速度,类似于提升运算速度
(2) 减少数据载入和预处理的工作量
其中第一个思路更多的需要在硬件层面进行改进,而第二个思路则可以通过并行计算和数据共享,重复利用的方法来实现。
并行化问题
在了解具体的训练优化方法之前,我们需要知道神经网络训练过程中的典型步骤,并做一些合理假设。下图是一个典型的神经网络训练流程:

图1 一种典型的神经网络训练流程
包含了 5 个步骤:read and decode 表示读入数据并解码,例如将图片数据重新 resize成相应的矩阵形式;Shuffle 表示数据打乱,即随机重新排列各个样本;augmentation 表示对数据进行变换和增强;batch 对数据按照 batch size 进行打包;Apply SGD update表示将数据输入到目标网络中,并利用基于 SGD 的优化算法进行参数学习。
不同的任务中或许会增加或减少某些环节,但大致上的流程就是由这5步构成的。此外,网络采用的学习优化算法也会有不同,但都是基于 SGD 算法的,因此一律用“SGD update”来表示。这个流程每次运行对应一个 epoch,因此其输入也就是整个训练数据集。
可并行化是这个过程的重要特点,也是对其进行优化的关键所在。不同的 epoch 流程之间的某些环节是可以同时进行的,例如在上一个 epoch 训练时,就可以同步的读入并处理下一个epoch 的数据。进一步地,作者将该流程划分为两个部分,上游(upstream)过程和下游(downstream)过程。其中上游过程包含数据载入和部分的数据预处理操作,而下游过程包含剩余的数据预处理操作和 SGD update 操作。这个划分并不是固定的,不同的划分决定了上游和下游过程的计算量和时间开销。这样划分后,可以简单地将并行操作理解为两个流水线并行处理,如下图:

图1 基础并行操作,idle表示空闲时间
上面的流水线处理上游过程,下面的处理下游过程。为了更好地表示对应关系,我在原图的基础上添加了一个红色箭头,表示左边的上游过程是为右边的下游过程提供数据的,他们共同构成一个 epoch 的完整训练流程,并且必须在完成这个 epoch 的上游过程后才可以开始其下游过程,而与左侧的上游过程竖直对应的下游过程则隶属于上一个 epoch了。
从图中可以看到,上游过程需要的时间是比下游过程更长的,因此在下游过程的流水线中有一部分时间(红色部分)是空闲的等待时间,这也是本文中的主要优化对象。此处做了第一个重要假设:上游过程的时间消耗大于下游过程,这使得训练所需时间完全取决于上游过程。如果是小于关系,那么优化的重点就会放到下游过程中,而下游过程中主要优化内容还是反向传播过程。因此这个假设是将优化内容集中在下游过程流水线的充分条件。
那么如何利用这部分空闲时间呢?答案是继续用来处理下游过程,如下图:

图2 单上游过程对应多下游过程
同一个上游过程可以为多个下游过程提供数据(图中是 2 个),通过在上游过程和下游过程的分界处添加一个额外的数据复制和分发操作,就可以实现相同的上游数据在多个下游过程中的重复利用,从而减少乃至消除下游过程流水线中的空闲时间。这样,在相同的训练时间里,虽然和图1中的一对一并行操作相比执行了相同次数的上游过程,但是下游过程的次数却提升了一定的倍数,模型获得了更多的训练次数,因此最终性能一定会有所提升。
那么进一步,如果要达到相同的模型性能,后者所需执行的上游过程势必比前者要少,因此从另个角度来讲,训练时间就得到了缩短,即达到相同性能所需的训练时间更少。
但是,由于同一个上游过程所生成的数据是完全相同的,而在不同的反向传播过程中使用完全相同的数据(repeated data),和使用完全不同的新数据(fresh data)相比,带来的性能提升在一定程度上是会打折扣的。这个问题有两个解决方法:
(1)由于下游过程并不是只包含最后的 SGD update 操作,还会包含之前的一些操作(只要不包含 read and encode 就可以),而诸如 shuffle 和 dropout 等具有随机性的操作会在一定程度上带来数据的差异性,因此合理的在下游过程中包含一些具有随机性的操作,就可以保证最后用于 SGD update 的数据具有多样性,这具体取决于上下游过程在整个流程中的分界点。
(2)在进行分发操作的同时对数据进行打乱,也能提高数据的多样性,但由于数据打乱的操作本身要消耗计算资源,因此这不是一个可以随意使用的方法。
我们将这种对上游过程的数据重复利用的算法称为数据交流 data echoing,而重复利用的次数为重复因子 echoing factor。
数据重复利用效率分析
假设在完成一个上游过程的时间内,可以至多并行地完成 R 个下游过程,而数据的实际重复使用次数为e,通常 e 和 R 满足 e<R,这也符合我们的第一个假设。因此,一个完整的 epoch 训练流程所需的时间就为:
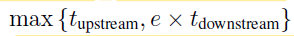
在此基础上,可以得到以下关于训练效率的结论:
(1)只要e不大于R,那么训练时间就完全取决于上游过程所需的时间,而总训练时间就取决于上游过程的次数,也就是第一条流水线的总时长。
(2)由于重复数据的效果没有新数据的效果好,因此要达到相同的模型性能,数据交流训练方法就需要更多的 SGD update操作,也就是需要更多下游过程。理论上,只要下游过程的扩张倍数小于e倍,那么数据交流训练方法所需的总训练时长就小于传统训练方法。
(3)由于e的上限是R,那么R越大,e就可以取得越大,在下游过程只包含SGD update过程时,R最大。进一步地,若此时重复数据和新数据对训练的贡献完全相同,那么训练加速效果将达到最大,即训练时间缩短为原来的1/R。
然而在前面已经提到了,对重复利用的数据而言,其效果是不可能和新数据媲美的,这是限制该训练方法效率的主要因素。作者进一步探究了在训练流程中的不同位置进行上下游过程分割和数据交流所带来的影响。
(1)批处理操作(batching)前后的数据交流
如果将批处理操作划分为下游过程,那么由于批处理操作本身具有一定的随机性,不同的下游过程就会对数据进行不同的打包操作,最后送到 SGD update 阶段的数据也就具备了一定的batch间的多样性。当然,如果将批处理操作划分为上游过程,那么R值会更大,可以执行更多次的SGD update 训练操作,当然这些训练过程的数据相似度就更高了,每次训练带来的性能提升也可能变得更少。
(2)数据增强(data augmentation)前后的数据交流
如果在 data augmentation 之前进行数据交流,那么每个下游过程最终用于训练的数据就更不相同,也更接近于新数据的效果,这个道理同批处理操作前后的数据交流是相同的,只不过数据交流操作的插入点更靠前,R值更小,带来的数据差异性也更强。
(3)在数据交流的同时进行数据打乱
数据打乱本质上也是在提升分发到不同下游过程的数据的多样性,但这是一个有开销的过程,根据应用环境的不同,能进行数据打乱的范围也不同。
进一步地,作者通过实验在5个不同的方面评估了数据交流训练方法带来的性能提升,并得到了以下结论:
(1)数据交流能降低训练模型达到相同效果所需的样本数量。由于对数据进行了重复使用,因此相应的所需新数据数量就会减少。
(2)数据交流能降低训练时间。事实上即便是 e>R,在某些网络上仍然会带来训练效果的提升,如下图:
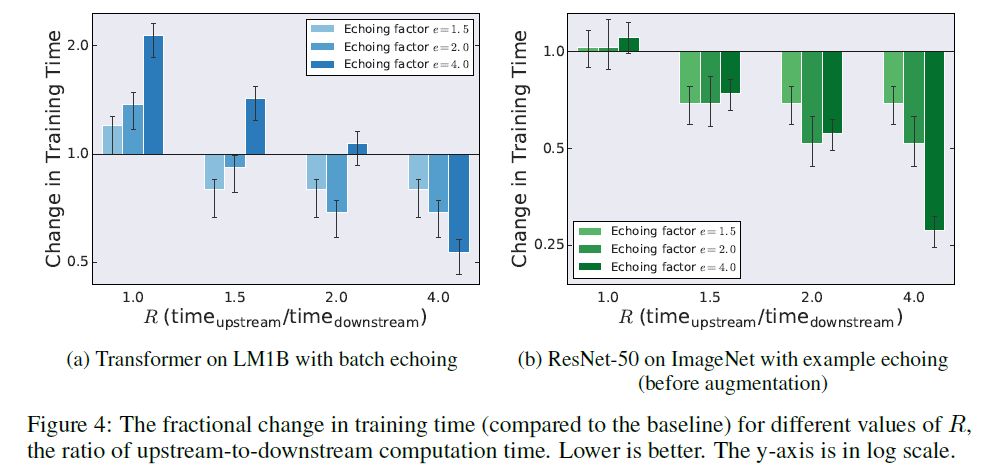
图4 不同的e和R值在两个不同网络中带来的训练时间提升
在 LM1B 数据集中,当 e>R 是总训练时间都是扩大的,而在 ImageNet 数据集中,只要R 大于1.5, e 越大,训练时间就越小,作者并没有对这个结论给出解释,笔者认为这是以为因为在ImageNet 数据集中,重复数据带来的性能衰减 小于 重复训练带来的性能提升,因此,e 越大,达到相同性能所需的训练时间越少,只是 LMDB 对重复数据的敏感度更高。
(3)batch_size越大,能支持的e数量也就越大。进一步的,batch_size越大,所需要的训练数据也就越少。
(4)数据打乱操作可以提高最终训练效果,这是一个显而易见的结论。
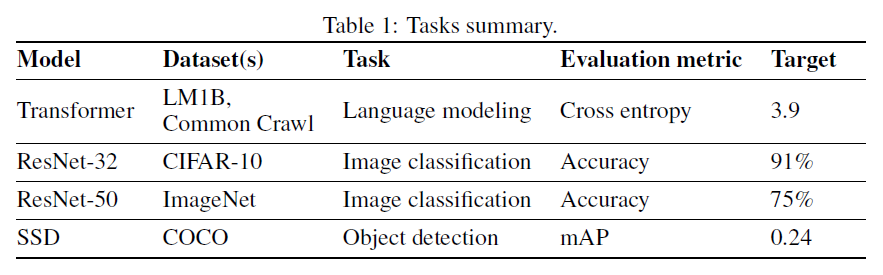
(5)在数据交流的训练方法下,模型仍然能训练到和传统训练方法一样的精度,也就是不损失精度。作者在 4 个任务上进行了对比试验:
总结
本文的核心思想就是数据的重复利用,通过数据的重复利用在并行执行训练流程的过程中执行更多次的参数优化操作,一方面提高了流水线效率,另一方面提高了训练次数,从而降低了达到相同精度所需的训练时间。
原文链接:https://arxiv.org/pdf/1907.05550.pdf
◆
精彩推荐
◆
“只讲技术,拒绝空谈!”2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
目前,大会早鸟票限量发售中~扫码购票,领先一步!
推荐阅读
AI“配”5G,能“生”出怎样的未来?
什么限制了GNN的能力?首篇探究GNN普适性与局限性的论文出炉!
2019年最新华为、BAT、美团、头条、滴滴面试题目及答案汇总
10分钟学会用Pandas做多层级索引
中国第一程序员,微软得不到他就要毁了他!
透析《长安十二时辰》里的望楼,人类在唐朝就有 5G 愿望了?
首批 8 款 5G 手机获 3C 认证;iPhone6 系列停产;Android Q Beta 5 发布 | 极客头条
"别太乐观, 冲破黑暗还很远呀! "
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

制作一个简单的linux
我这里是借助宿主机做的一个简单的Linux,我们只要知道一个Linux启动过程需要什么,这里制作就简单的多了。不过没有基础的也没关系,我写的很详细,没有基础的看了我写的步骤只要细心也是会做出来的,我这里的小Linux是很简…

nginx是什么,如何使用
一:nginx是什么? 二:nginx作为网关,需要具备什么?(nginx可以作为web服务器,但更多的时候,我们把它作为网关,因为它具备网关必备的功能:) 反向代理…

OpenCV中Mat数据结构使用举例
#include "stdafx.h"#include <string>#include <iostream>#include <opencv2/opencv.hpp>using namespace std;using namespace cv;int _tmain(int argc, _TCHAR* argv[]){//创建一个用13j填充的 7 x 7 复矩阵-----1Mat M(7, 7, CV_32FC2, Scalar…
贾扬清加盟AI开发者大会!早鸟票抢购正式开启
整理 | 夕颜硬核 AI 技术大会,一年参加一次就够了。9 月 6日-7 日,2019 AI 开发者大会(AI ProCon)将在北京富力万丽酒店举行,人工领域技术领袖将再次齐聚一堂,探讨过去一年最新的 AI 技术趋势与变化&#x…
基本控件HyperlinkButton控件
HyperlinkButton控件可用来作为超链接按钮,支持页面导航。 若导航到MainPage.xaml,NavigateUri属性指定单击后导航页面的Uri 若导航到网页,必须同时指定TargetName,否则要报错。 <HyperlinkButton Width"200" Heigh…
江湖又现中科大少年班的传说
作者 | ——,夕颜出品 | AI科技大本营(ID:rgznai100)导读:近日,《日本经济新闻》的一则报道指出:在左右着企业、国家和地区发展的人工智能领域,中科大少年班的人才支撑着中国的发展。中国自动驾…
[JOISC2014]バス通学
[JOISC2014]バス通学 题目大意: 有\(n(n\le10^5)\)个点和\(m(m\le3\times10^5)\)条交通线路。第\(i\)条交通线路可以让你在时间\(x_i\)从\(a_i\)出发,并在\(y_i\)时到达\(b_i\)。\(q(q\le10^5)\)次询问,每次询问若要在时间\(l_i\)到达\(n\)点…
Windows7在Notepad++中配置Python+OpenCV
1、 从http://notepad-plus-plus.org/下载最新的Notepad6.2.1安装; 2、 从http://www.python.org/下载python-2.7.3.msi安装到D:\Python27目录下,并将D:\Python27添加到环境变量Path中; 3、 打开Notepad,按下F5或者运行(R…

virtualenv 在windows下的绿化方法
virtualenv 在windows下的绿化方法测试环境:windows 7 32 en Python 2.7.3setuptools-0.6c11.win32-py2.7virtualenv-1.9.1-with-pip-1.3.11. f:\> virtualenv my2. 编辑 my/Scripts/activate.bat 前几行中设置VIRTUAL_ENV的那条语句,改为set VIRTUA…
当谈论迭代器时,我谈些什么?
作者 | 樱雨楼编辑 | 豌豆花下猫转载自python猫(ID:python_cat)导语:之前说过,我对于编程语言跟其它学科的融合非常感兴趣,但我还说漏了一点,就是我对于 Python 跟其它编程语言的对比学习,也很感…
Windows7在Eclipse中配置Python+OpenCV
1. 从http://www.oracle.com/technetwork/java/javase/downloads/jdk-7u2-download-1377129.html下载jdk-7u2-windows-i586.exe,安装到D:\ProgramFiles\Java,并将D:\ProgramFiles\Java\jdk1.7.0_02\bin添加到环境变量中; 2. 从…
Pinterest基于AWS规模化使用Apache Kafka的实践经验
在Pinterest,Apache Kafka被用于为实时流应用程序传输数据、记录日志和可视化监控指标。Pinterest的Kafka托管在AWS上,为了实现复制和高可用性,其安装使用了MirrorMaker和DoctorKafka工具。 Pinterest的技术主管Yu Yang写道,Pinte…

Open×××以及其它IP层×××的完全链路层处理的实现
如果Open也能实现传输模式该有多好,如果基于Open实现的产品能仅仅作为一根昂贵的网线串接在用户网络环境,自动捕获感兴趣流量该有多好;如果它能做到只需要配置一个IP即可工作而无需配置任何路由该有多好。我们知道Open是一个用户态的程序&…
Windows 7 64位机上OpenCV2.4.3的编译、安装与配置
1. 从http://sourceforge.net/projects/opencvlibrary/files/opencv-win/2.4.3/下载OpenCV2.4.3; 2. 将OpenCV-2.4.3.exe放到D:\soft\OpenCV2.4.3文件夹下,解压到当前文件夹下,生成一个opencv文件夹; 3. 下载并安…
有望替代卷积神经网络?微软最新研究提基于关系网络的视觉建模
导语:最近两年,自注意力机制、图和关系网络等模型在NLP领域刮起了一阵旋风,基于这些模型的Transformer、BERT、MASS等框架已逐渐成为NLP的主流方法。这些模型在计算机视觉领域是否能同样有用呢?近日,微软亚洲研究院视觉…

Word 2013无法发布文章到博客园
2018年12月12日突然发现word2013无法发布文章到博客园了, 虽然不常发布博客, 但作为一个强迫症患者, 不折腾好了, 吃肉都不香呀! 删除之前的账户, 想重新注册, 居然遇到了灰色对话框!…
1 sec on Large Judge (java): https://github.com/l...
1 sec on Large Judge (java): https://github.com/leoyonn/leetcode/blob/master/src/q029_substring_of_all_words/Solution.java转载于:https://www.cnblogs.com/codingtmd/archive/2013/03/31/5079017.html
性能提升3倍的树莓派4,被爆设计缺陷!
整理 | 屠敏转载自CSDN(ID:CSDNnews)一直以来,素有世界最小电脑之称的 Raspberry Pi(树莓派)是一种独特的存在。它不仅只有一块信用卡般的体积,还具备主机电脑所具备的功能,如运行 L…
Windows7 64位机上Emgu CV2.4.2安装与配置
1. 从http://sourceforge.net/projects/emgucv/?sourcedirectory下载最新的Emgu CV2.4.2; 2. 将libemgucv-windows-x86-gpu-2.4.2.1777拷贝到D:\soft\Emgu2.4.2文件夹下,运行此.exe文件,将其安装到D:\soft\Emgu2.4.2\emgucv-wind…

2018年12月,华为HCNP大面积更新题目,军哥独家解题咯
2018年12月,华为HCNP大面积更新题目,乾颐堂军哥独家解题咯2018年是华为认证变动比较大的一年,华为认证走过这几年不得不说是有一定进步的,而且最近华为孟女侠确实让我也小小的骄傲了一把,所以当然希望华为认证能做的更…
关于ProGuard的学习了解(从别处转来)
from:http://www.cnitblog.com/zouzheng/archive/2011/01/12/72639.html在Android项目中用到JNI,当用了proguard后,发现native方法找不到很多变量,原来是被produard优化掉了。所以,在JNI应用中该慎用progurad啊。解决办…
tesseract-ocr3.02字符识别过程操作步骤
1、 从http://code.google.com/p/tesseract-ocr/downloads/list下载tesseract-ocr-3.02-vs2008、tesseract-ocr-3.02.chi_sim.tar、tesseract-ocr-3.02.02.tar、tesseract-ocr-3.02.02-doc-html.tar、leptonica-1.68-win32-lib-include-dirs相关文件; 2、 将所有…
中文repo“霸榜”GitHub Trending,国外开发者不开心了
编译整理 | 一一出品 | AI科技大本营(ID:rgznai100)近日,一位叫Balazs Saros 的国外开发者在Medium上发表了一篇名为"Chinese repos are ruining the Github trending page"的博文,翻译一下他的意思就是“中文 repo 正在…
使用 electron-updater 自动更新应用
前端工程师可以使用 Electron 非常方便的编写出 PC 端应用,而应用更新的方式也有很多,详细可见更新应用程序。 我的项目是基于 electron-vue 搭建的,构建打包生成安装包,则用的是 electron-builder,所以更新自然选择 e…

struts2请求处理过程源代码分析(1)
2019独角兽企业重金招聘Python工程师标准>>> 转载自:http://www.see-source.com/ 源码解析网 网上对于struts2请求处理流程的讲解还是比较多的,有的还是非常详细的,所以这里我就简单地将大概流程总结下,有了个大概印象…
Ubuntu中C代码静态检查工具Splint的安装配置和使用
1、 从http://www.splint.org/download.html下载splint-3.1.2.src.tgz,存放到/home/spring/Splint文件夹下; 2、 打开终端; 3、 解压缩:tar zxvfsplint-3.1.2.src.tgz 4、 安装到/usr/local/splint目录下: …
Fetch 入门
一、什么是Fetch ? Fetch的定义 Fetch本质上是一种标准,该标准定义了请求、响应和绑定的流程。 Fetch标准还定义了Fetch () JavaScript API,它在相当低的抽象级别上公开了大部分网络功能,我们今天讲的主要是Fetch API。Fetch API …

保障数据安全,强调科技向善,旷视发布《人工智能应用准则》
目录 AI应用落地加速 善用科技是关键 《人工智能应用准则》全文 2019年7月17日,旷视正式全文公布基于企业自身管理标准的《人工智能应用准则》(以下简称《准则》)。《准则》从正当性、人的监督、技术可靠性和安全性、公平和多样性、问责和及…
胜者树和败者树 - qianye0905 - 博客园
胜者树和败者树 - qianye0905 - 博客园胜者树和败者树胜者树和败者树都是完全二叉树,是树形选择排序的一种变型。每个叶子结点相当于一个选手,每个中间结点相当于一场比赛,每一层相当于一轮比赛。不同的是,胜者树的中间结点记录的…
C/C++代码静态检查工具PC-lint在VS2008开发环境中的安装配置和使用
PC-Lint偏重于代码的逻辑分析,它能够发现代码中潜在的错误,比如数组访问越界、内存泄漏、使用未初始化变量等。 1、 从http://download.csdn.net/detail/liuchang5/3005191 下载破解版PC-lint9.0; 2、 解压缩到D:\soft\PC-lint,…