华人“霸榜”ACL最佳长短论文、杰出论文一作,华为、南理工等获奖

作者 | 夕颜、一一
出品 | AI科技大本营(ID:rgznai100)
导读:7 月 31 日晚,自然语言处理领域最大顶会 ACL 2019 在佛罗伦萨进行到了第四天(7 月 29 日-8 月 1 日),当天,组委会最终从提名论文奖项 32 篇候选论文中公布了今年的八个论文奖项,包含 1 篇最佳长论文奖、1 篇最佳短论文奖、5 篇杰出论文奖、1 篇最佳 Demo 论文奖,其中最佳长论文的获奖者被来自中国科学院大学、中国科学院计算技术研究所、腾讯 WeChat AI、华为诺亚方舟实验室、伍斯特理工学院等机构的联合论文所斩获。此外,来自南京理工大学的 Rui Xia 和 Zixiang Ding 获得了杰出论文奖。此次 8 篇获奖论文的 31 位作者中,有 10 位是华人作者,其中 4 篇的一作都是华人作者。
获奖详情

最佳长论文
标题:Bridging the Gap between Training and Inference for Neural Machine Translation
作者:Wen Zhang(中国科学院计算技术研究所), Yang Feng(中国科学院大学), Fandong Meng(腾讯 WeChat AI), Di You(伍斯特理工学院)、Qun Liu(刘群,华为诺亚方舟实验室,CSDN AI开发者大会在邀演讲嘉宾)
论文链接:https://arxiv.org/abs/1906.02448
GitHub 链接:
https://github.com/jasonwu0731/trade-dst
摘要:神经机器翻译(NMT)以预测以上下文词为条件的下一个词的方式,按顺序生成目标词。在训练时,它以 ground truth 词作为上下文进行预测,而在推理时,它必须从头开始生成整个序列,这种差异导致误差累积。此外,词级训练要求所生成的序列与 序列之间严格匹配,这导致对不同但合理的翻译过度校正。
本文中,作者不仅通过 序列中,而且还从在训练期间的预测序列中采样上下文词来解决这些问题,其中预测序列是具有句子级别的最优选择。在中英和 WMT'14 英德翻译任务的实验结果表明,他们的方法在多个数据集上有显著效果。

最佳短论文
标题:Do you know that Florence is packed with visitors? Evaluating state-of-the-art models of speaker commitment
作者:
论文链接:
https://www.aclweb.org/anthology/P19-1412
摘要:当一位演讲者问你知道佛罗伦萨挤满了游客吗?我们让她相信佛罗伦萨挤满了游客,但是,如果她问你是否认为佛罗伦萨挤满了游客?推断说话者承诺对于信息提取和问答是至关重要的。本文中,作者通过分析具有挑战性的自然数据集上模型误差的语言相关性,来探索语言缺陷驱动说话者承诺模型的错误模式的假设。他们在 CommitmentBank 上评估了两个最先进的说话者承诺模型。
他们发现,语言学信息模型优于基于 LSTM 的模型,这表明需要语言学知识来捕获这些具有挑战性的自然数据。他们按语言学特征的细分项目揭示了不对称的错误模式:虽然模型在某些类别上取得了良好的表现(例如,否定),但它们无法泛化到自然语言中的各种语言学结构(例如条件语句),作者们突出了改进的方向。
最佳 Demo 论文
标题:OpenKiwi: An Open Source Framework for Quality Estimation
作者:
论文链接:
https://www.aclweb.org/anthology/P19-3020
摘要:作者介绍了一个基于 PyTorch 的用于翻译质量评估的开源框架OpenKiwi。OpenKiwi支持词级和句子级质量评估系统的训练和测试,实现了 WMT 2015-18 质量评估活动的获奖系统。他们在WMT 2018(英德 SMT 和 NMT)两个数据集上对 OpenKiwi 进行基准测试,在词级任务和句子级任务中展现了最佳性能。
杰出论文

标题:Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts
作者:Rui Xia,Zixiang Ding(南京理工大学)
论文链接:
https://www.aclweb.org/anthology/P19-1096
本文提出一项有趣的任务,联合学习来识别文本中的情绪及其原因。其次,它提出一个有趣的新模型,两种不同类型的多任务体系结构,一种任务是独立的,另一种是交互的。最后,根据互动的方向,可以改进情绪的精确度或原因的 recall。

标题:Studying Summarization Evaluation Metrics in the Appropriate Scoring Range
作者:Maxime Peyrard(洛桑联邦理工学院(EPFL))
论文链接:
https://www.aclweb.org/anthology/P19-1502
本文解决了自动文本摘要任务中一个长期存在的问题:如何衡量摘要内容的合适性?其次,它为“内容重要性”提出了 3-part 的理论模型,此外,它还提出了评价指标并对标准指标和人类判断进行了对比。

标题:Transferable Multi-Domain State Generator for Task-Oriented
作者:Chien-Sheng Wu, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher and Pascale Fung(香港科技大学、Salesforce 研究院)
论文链接:https://arxiv.org/abs/1905.08743
本文解决了传统但尚未解决的问题:对话状态跟踪中的不可见状态,证明了可以从用户话语中生成对话状态。其次,论文中提出的新方法可以扩展到大型值集并处理以前不可见的值。除了展示最新的研究成果外,本文还研究了针对新领域的小样本学习。

标题:Zero-Shot Entity Linking by Reading Entity Descriptions
作者:Lajanugen Logeswaran, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, Jacob Devlin and Honglak Lee(密歇根大学、谷歌研究院)
论文链接:
https://arxiv.org/pdf/1906.07348.pdf
本文提出了一种新的词义消歧系统,并注重提高不常见单词和未见过的单词的表现。其次,sense selection任务被作为一项持续任务对待,并且用到了资源组合。最终的结果具有洞察力,达到了最佳结果。

标题:We need to talk about standard splits
作者:Kyle Gorman(纽约市立大学)、Steven Bedrick(俄勒冈健康与科学大学)
论文链接:
http://wellformedness.com/papers/gorman-bedrick-2019.pdf
GitHub链接:
https://github.com/jojonki/arXivNotes/issues/241
本文质疑了评估NLP模型时广泛使用的方法,其次,使用了 POS 标记来阐释问题。还建议提出系统排名应该基于使用随机分组的重复评估方法。
投稿数翻倍,接收率却创新低
据组委会公布的数据显示,本届 ACL 的注册参会人数达到了 3160 人,这比 ACL 2018 的参会人数(1322 人)足足多出两倍多。
在论文数量上,ACL 2019 相比去年也有大幅提高,论文投稿数量达 2905 篇,几乎是 ACL 2018(1544 篇)投稿的两倍。此外,大会共接收 660 篇论文,包括 447 篇长论文、213 篇短论文。
组委会还统计了提交论文数量排名前 15 位的国家(每个国家提交超过 30 份),其中中国共提交 817 篇,接收 155 篇,接受率为19%。
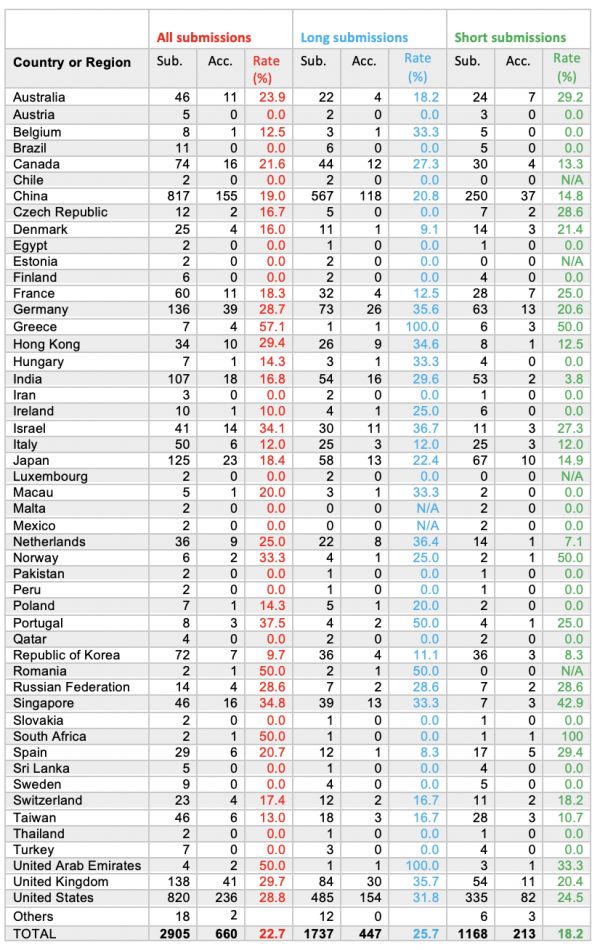
虽然大会接收到的论文投稿增加一倍,但是接收率却创下了三年最低。2018 年,总接收率为 24.9%,2017 年这一数字为 23.3%,而到这可能与今年更严格的论文评审制度有关。
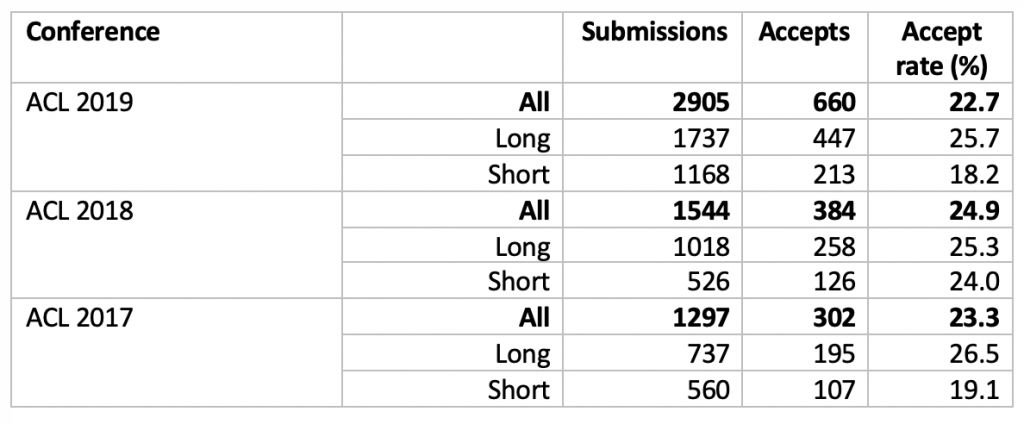
论文接收率最高的国家和地区分别为新加坡(34.8%),以色列(34.1%),英国(29.7) %),中国香港(29.4%)美国(28.8%)和德国(28.7%)。
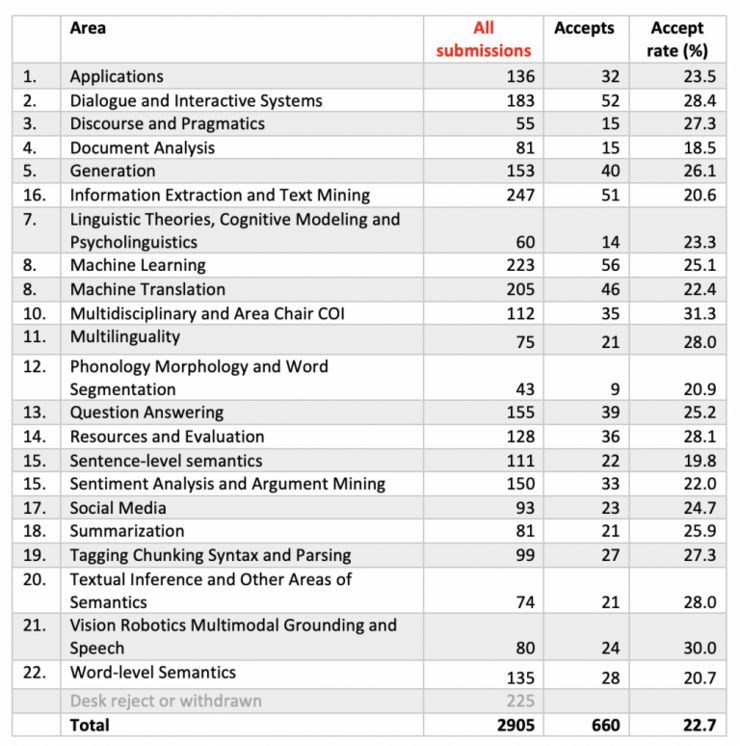
另外,根据组委会公布的数据显示,今年 ACL 不同领域论文的接受率略有区别,其中接收率最低的领域是文档分析(18.5%)、句子级别语义( 19.8%)、信息抽取和文本挖掘(20.6%) 、词级别语义(20.7%) 、音韵学,形态学和单词分割的接收率稍高,为 20.9%。
相比之下,接受率最高的领域是多学科和领域主席 COI(31.3%)。这部分领域包含了资深领域主席审查的与他们自己领域相关的论文。其他接收率相对较高的领域还包括视觉、机器人、多模态语音(30.0%),对话和交互系统(28.4%)和资源与评测(28.1%)。
双层审评审结构,审稿更严格
随着论文投稿数量增长,为了保证审稿的质量,ACL 从 2018 年开始审稿机制也随之发生变化,采用资深领域主席(Senior AC)+领域主席(AC)的双层审评审结构,审稿人的数量也从 1610 人增加到了 2281 人,领域主席(Area Chair)的数量从 61 人增加到了 230 人。
据 ACL 2019 组委会介绍,今年的评审阵容由 46 位 SAC,184 位 AC 组成, SAC 为 AC 分配论文和审稿人,并为对应的领域做出一些整体性的推荐,184 位 AC 中的每位则只负责各自领域内的一部分论文,然后组织审稿人们进行讨论、为审稿意见撰写意见(meta-review),并做出论文选择推荐。
提名论文华人撑起“半边天”
此次 8 篇获奖论文的 31 位作者中,大约有 10 位是华人作者。而在此前的 32 篇提名名单中,共
1、南京理工大学,夏睿团队
ID: 2714 (long, oral 2D, M14:50)
Title: Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts.
Authors: Rui Xia and Zixiang Ding
2、华为诺亚方舟实验室,刘群团队
ID: 2366 (long, oral 5A, T14:50)
Title: Decomposable Neural Paraphrase Generation
Authors: Zichao Li, Xin Jiang, Lifeng Shang and Qun Liu
3、中科院计算所/腾讯/华为/伍斯特理工学院
ID 1637 (long, oral 6D, W10:50)
Title: Bridging the Gap between Training and Inference for Neural Machine Translation.
Authors: Wen Zhang, Yang Feng, Fandong Meng, Di You and Qun Liu
4、浙江大学/加州大学戴维斯分校/宾夕法尼亚大学
ID: 2577 (long, oral 8A, W17:00)
标题: Persuasion for Good: Towards a Personalized Persuasive Dialogue System for Social Good.
作者: Xuewei Wang, Weiyan Shi, Richard Kim, Yoojung Oh, Sijia Yang, Jingwen Zhang and Zhou Yu
值得注意的是,华为诺亚方舟实验室刘群的 4 篇录用论文中有 2 篇入选最佳长文提名。
ACL、EMNLP、NAACL 和 COLING 是自然语言处理领域的四大国际顶会,其中 ACL(Annual Meeting of the Association for Computational Linguistics)一直以受关注度更广、论文投递数量多著称,无论是正式获奖还是提奖名单,华人作者在 ACL 2019 上的存在感愈来愈强,华人在自然语言处理领域的贡献和影响力可见一斑。有理由相信,来年的 ACL 上华人将斩获更多的荣誉。
(*本文为 AI科技大本营原创文章)
◆
精彩推荐
◆

60+技术大咖与你相约 2019 AI ProCon!大会早鸟票已售罄,优惠票速抢进行中......2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
推荐阅读
效果惊人!中科院、百度研究院等联合提出UGAN,生成图片难以溯源
认知智能的突围:NLP、知识图谱是AI下一个“掘金地”
你想见的大神都来AI ProCon 2019了,优惠票限时抢购开启
Python之父新发文,将替换现有解析器
华为否认鸿蒙为噱头;谷歌公布 6 大 iOS 漏洞;极客头条
三次创业,三次跨界,这次凭十万行核心C代码登上 GitHub Top 1!
64%的投资者对比特币不感兴趣,那是谁投资了比特币?
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:
设计模式之访问者模式(Visitor)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…

关闭Windows 8的metro UI的方法汇总
http://www.ssdax.com/570.html 上面就是windows8新出现的Metro UI,点击开始菜单就会出现,取代了windows长久以来的开始菜单,有了非常大的突破 不过我发现很多人都在找怎么关闭windows8 的Metro UI,下面介绍两个如何关闭Metro的方…

coredata Lightweight Migration 心得
关于coredata 网上的相关资料比较少,大部分是基本用法。于是便找到苹果官方文档进行深入学习。 分享一下心得,如果用了coredata 必须懂得 coredata Migration,否则app版本更新 core data model schema 变化很大可能导致持久化coredata 出错&a…
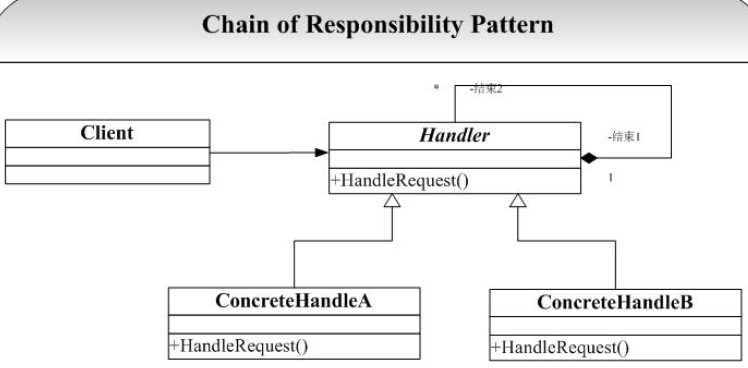
设计模式之职责链模式(Chain of Responsibility)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…

澎思科技与新加坡国立大学等高校共研AI产品加快技术应用落地
2019年7月31日,中国人工智能企业澎思科技宣布新加坡研究院正式揭牌成立,并宣布成立澎思技术委员会,推动全球视野下的人工智能技术研究。同时,澎思科技与新加坡国立大学、新加坡南洋理工学院等重量级机构签订战略合作。未来&#x…
codility上的问题 (22)
问题描述: 用1 * 1, 1 * 2的矩形覆盖一个n行m列的矩形,问有多少种方法。 数据范围 : n [1..10^6], m [ 1..7] 要求复杂度: 时间 O(log(n) * 8 ^m)) 空间 O(4^m) 分析:这个题跟之前那个木块砌墙问题一样…… 稍作修…

session 与 cookie的区别
session和cookie是网站浏览中较为常见的两个概念,也是比较难以辨析的两个概念,但它们在点击流及基于用户浏览行为的网站分析中却相当关键。基于网上一些文章和资料的参阅,及作者个人的应用体会,对这两个概念做一个简单的阐述和辨析…
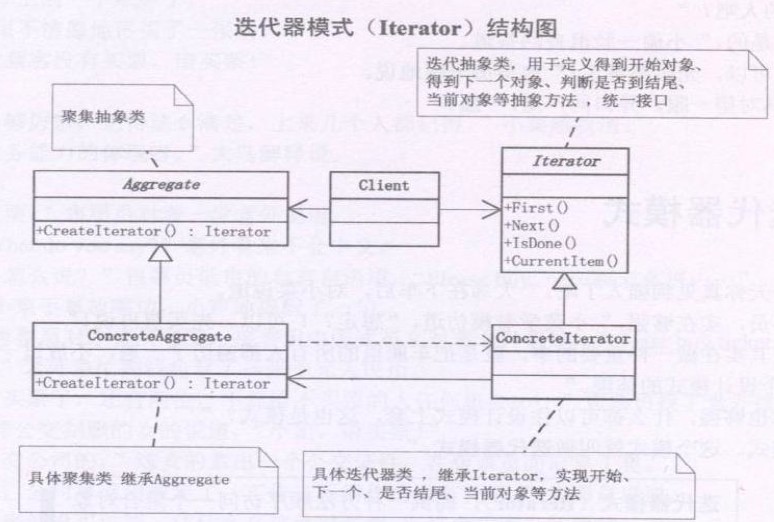
设计模式之迭代器模式(Iterator)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…

澎思科技成立新加坡研究院,将与多家机构合作研发自动驾驶等项目
2019 年 7 月 31 日,中国人工智能企业澎思科技宣布新加坡研究院正式揭牌成立,并成立澎思技术委员会,由来自新加坡国立大学、新加坡南洋理工学院等四名 AI 专家/教授担任澎思技术委员会首批委员。此外,澎思科技还与新加坡国立大学、…
对象----《你不知道的JS》
最近在拜读《你不知道的js》,而此篇是对于《你不知道的js》中对象部分的笔记整理,希望能有效的梳理,并且深入理解对象 一、语法 对象两种定义形式:声明(文字)形式、构造形式 声明(文字)形式 var…

Android:FragmentTransaction
为什么80%的码农都做不了架构师?>>> FragmentTransaction FragmentManager:能够实现管理activity中fragment. 通过调用activity的getFragmentManager()取得它的实例.。 FragmentTransaction:对fragment进行添加,移除,替换,以及执…
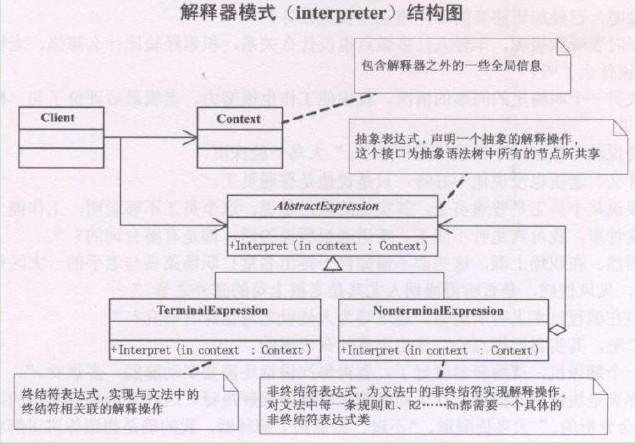
设计模式之解释器模式(Interpreter)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…
自动驾驶激荡风云录:来自圈内人的冷眼解读
作者 | 黄浴,奇点汽车美研中心总裁兼自动驾驶首席科学家编辑 | 夕颜出品 | AI科技大本营(ID:rgznai100)最近一个月,有关自动驾驶的新闻层出不穷,也是少有的热闹。先说正面的吧。激情的焰火 ▌传感器之争2019 年 7 月&a…
激动人心的AutoCAD .net开发技术
自从了解了vsto和sc(SmartClient)技术后,对以前Win32的二次开发技术,再也没有一点兴趣。对Office VBA, AutoCAD lisp, VBA, PowerBuilder PoserScript, MapInfo MapBasic 的开发,简直室深恶痛绝,希望一切…
Linux Shell简介
目录 版权信息前言第一篇:超级工具/Terminals,xterms 和 Shells 一、超级工具二、为了说明 shell ,这里需要一些背景知识。 1、Terminals, xterms 与 Shells2、终端(Terminals)3、xterms4、Shells 三、Shel…
浙大博士130页论文,教你用人工智能挑西瓜
作者 | 神经小姐姐来源 | HyperAI超神经(ID:HyperAI)【导读】要问什么水果和夏天最搭,答案一定是西瓜。作为西瓜生产与消费大国,中国在 2018 年以全世界 20% 的人口消耗掉全世界 70% 的西瓜,人均 100 斤。如…
一些要注意的地方
1、tomcat启动一直保持在starting状态时,最简单的原因就是时间过短,将时间变长就可以了。若还不能解决时,还可能就是端口号被占用了。通过netstat -nao | findstr ""可以看到占用你所使用的端口号的进程id,然后通过tasklist | find…
NEON在Android中的使用举例
1、 打开Eclipse,File-->New-->AndroidApplication Project-->Application Name:Hello-Neon, Project Name: Hello-Neon,Package Name:com.hello_neon.android, Minimum Required SDK:API 9:Android 2.3(Gingerbread),Next-->去掉Create custom launch…
Android中的JSON详细总结
1、JSON(JavaScript Object Notation) 定义: 一种轻量级的数据交换格式,具有良好的可读和便于快速编写的特性。业内主流技术为其提供了完整的解决方案(有点类似于正则表达式,获得了当今大部分语言的支持),从…
新一届最强预训练模型上榜,出于BERT而胜于BERT
作者 | Facebook AI译者 | Lucy编辑 | Jane出品 | AI科技大本营(ID: rgznai100)【导读】预训练方法设计有不同的训练目标,包括语言建模、机器翻译以及遮蔽语言建模等。最近发表的许多论文都使用了微调模型,并预先训练了一些遮蔽语…
Ubuntu 32下Android NDK+NEON的配置过程及简单使用举例
1、 利用VMware在Windows7 64位下安装Ubuntu13.10 32位虚拟机; 2、 从 https://developer.android.com/tools/sdk/ndk/index.html下载android-ndk32-r10-linux-x86.tar.bz2; 3、 将android-ndk32-r10-linux-x86.tar.bz2拷贝到Ubuntu的/home/spring/NE…
Neon Intrinsics各函数介绍
#ifndef __ARM_NEON__ #error You must enable NEON instructions (e.g. -mfloat-abisoftfp -mfpuneon) to use arm_neon.h #endif/*(1)、正常指令:生成大小相同且类型通常与操作数向量相同的结果向量; (2)、长指令:对双字向量操作数执行运算…
ubuntu bind9 配置简单记录
ubuntu bind9 配置简单记录ubuntu版本:Ubuntu 12.04.2bind9安装:apt-get install bind9bind9配置文件目录:/etc/bindbind9主要配置文件:named.conf.local以及对应db配置1,主服务器配置:rootubuntu:/etc/bin…
不止最佳长论文,腾讯AI在ACL上还有这些NLP成果
编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导语】7 月 31 日晚,自然语言处理领域最大顶会 ACL 2019 公布了今年的八个论文奖项,其中最佳长论文的获奖者被来自中国科学院大学、中国科学院计算技术研究所、腾讯 We…
python中package机制的两种实现方式(转载)
当执行import module时,解释器会根据下面的搜索路径,搜索module1.py文件。 1) 当前工作目录 2) PYTHONPATH中的目录 3) Python安装目录 (/usr/local/lib/python) 事实上,模块搜索是在保存在sys.path这个全局变量中的目录列表中进行搜索。 sys…
Magento如何使用和设置CookieSession
2019独角兽企业重金招聘Python工程师标准>>> 给大家介绍两个Magento的核心对象-Mage_Core_Model_Cookie & Mage_Core_Model_Session 首先介绍Mage_Core_Model_Cookie,这个对象主要是用来设置Cookie的,里面主要下列方法&#x…

AI+DevOps正当时
随着业务复杂化和人员的增加,开发人员和运维人员逐渐演化成两个独立的部门,他们工作地点分离,工具链不同,业务目标也有差异,这使得他们之间出现一条鸿沟。而发布软件就是将一个软件想从鸿沟的这边送去那边,…
clientdataset 用法
影响ClientDataSet处理速度的一个因素TClientDataSet是Delphi开发数据库时一个非常好的控件。有很强大的功能。我常常用ClientDataSet做MemoryDataSet来使用。还可以将ClientDataSet的数据保存为XML,这样就可以做简单的本地数据库使用。还有很多功能就不多说了。在使…
用vs2010编译vigra静态库及简单使用举例
1、 从 http://ukoethe.github.io/vigra/ 下载最新源代码vigra-1.10.0-src-with-docu.tar.gz,并加压缩到D:\soft\vigra,生成vigra-1.10.0文件夹; 2、 从http://www.cmake.org/cmake/resources/software.html下载CMake并安装; …
39个超实用jQuery实例应用特效
2019独角兽企业重金招聘Python工程师标准>>> 1.Contextual Slideout:上下文滑动特效 2.Revealing Photo Slider:图片幻灯片特效 3.Fancy Box:魔幻盒 4.Scrollable:滚动特效 5.Flip:翻转特效,实现4个方向…