tiny-cnn执行过程分析(MNIST)
在http://blog.csdn.net/fengbingchun/article/details/50573841中以MNIST为例对tiny-cnn的使用进行了介绍,下面对其执行过程进行分析:
支持两种损失函数:(1)、mean squared error(均方差);(2)、cross entropy(交叉熵)。在MNIST中使用的是mean squared error,代码段:
// mean-squared-error loss function for regression
class mse {
public:static float_t f(float_t y, float_t t) {return (y - t) * (y - t) / 2;}static float_t df(float_t y, float_t t) {return y - t;}
};class tan_h : public function {
public:float_t f(const vec_t& v, size_t i) const override {const float_t ep = std::exp(v[i]);const float_t em = std::exp(-v[i]); return (ep - em) / (ep + em);}// fast approximation of tanh (improve 2-3% speed in LeNet-5)/*float_t f(float_t x) const {const float_t x2 = x * x;x *= 1.0 + x2 * (0.1653 + x2 * 0.0097);return x / std::sqrt(1.0 + x * x);// invsqrt(static_cast<float>(1.0 + x * x));}*/float_t df(float_t y) const override { return 1.0 - sqr(y); }std::pair<float_t, float_t> scale() const override { return std::make_pair(-0.8, 0.8); }输入层Input:图像大小32*32,神经元数量32*32=1024,代码段:
const int width = header.num_cols + 2 * x_padding;const int height = header.num_rows + 2 * y_padding;std::vector<uint8_t> image_vec(header.num_rows * header.num_cols);ifs.read((char*) &image_vec[0], header.num_rows * header.num_cols);dst.resize(width * height, scale_min);for (size_t y = 0; y < header.num_rows; y++)for (size_t x = 0; x < header.num_cols; x++)dst[width * (y + y_padding) + x + x_padding]= (image_vec[y * header.num_cols + x] / 255.0) * (scale_max - scale_min) + scale_min;S2层:卷积窗大小2*2,输出下采样图数量6,卷积窗种类6,输出下采样图大小14*14,可训练参数1*6+6=12,神经元数量14*14*6=1176;
C3层:卷积窗大小5*5,输出特征图数量16,卷积窗种类16,输出特征图大小10*10,可训练参数6*16*5*5+16=2416,神经元数量10*10*16=1600;
S4层:卷积窗大小2*2,输出下采样图数量16,卷积窗种类16,输出下采样图大小5*5,可训练参数1*16+16=32,神经元数量5*5*16=400;
C5层:卷积窗大小5*5,输出特征图数量120,卷积窗种类120,输出特征图大小1*1,可训练参数5*5*16*120+120=48120,神经元数量1*120=120;
输出层Output:输出特征图数量10,卷积窗种类10,输出特征图大小1*1,可训练参数120*10+10=1210,神经元数量1*10=10。
原有MNIST图像大小为28*28,此处为32*32,上下左右各填补2个像素,填补的像素取值为-1,其它像素取值范围为[-1,1]。
权值和阈值(偏置)初始化:权值采用均匀随机数产生,阈值均赋0。
C1层权值,初始化范围[sqrt(6.0/(25+150)), sqrt(6.0/(25+150))];
S2层权值,初始化范围[sqrt(6.0/(4+1)), - sqrt(6.0/(4+1))];
C3层权值,初始化范围[sqrt(6.0/(150+400)), - sqrt(6.0/(150+400))];
S4层权值,初始化范围[sqrt(6.0/(4+1)), - sqrt(6.0/(4+1))];
C5层权值,初始化范围[sqrt(6.0/(400+3000)), - sqrt(6.0/(400+3000))];
输出层权值,初始化范围[sqrt(6.0/(120+10)), -sqrt(6.0/(120+10))]。
前向传播:
C1层代码段:
vec_t &a = a_[worker_index]; // w*xvec_t &out = output_[worker_index]; // outputconst vec_t &in = *(prev_out_padded_[worker_index]); // inputstd::fill(a.begin(), a.end(), (float_t)0.0);for_i(parallelize_, out_.depth_, [&](int o) {for (layer_size_t inc = 0; inc < in_.depth_; inc++) {if (!tbl_.is_connected(o, inc)) continue;const float_t *pw = &this->W_[weight_.get_index(0, 0, in_.depth_ * o + inc)];const float_t *pi = &in[in_padded_.get_index(0, 0, inc)];float_t *pa = &a[out_.get_index(0, 0, o)];for (layer_size_t y = 0; y < out_.height_; y++) {for (layer_size_t x = 0; x < out_.width_; x++) {const float_t * ppw = pw;const float_t * ppi = pi + (y * h_stride_) * in_padded_.width_ + x * w_stride_;float_t sum = (float_t)0.0;// should be optimized for small kernel(3x3,5x5)for (layer_size_t wy = 0; wy < weight_.height_; wy++) {for (layer_size_t wx = 0; wx < weight_.width_; wx++) {sum += *ppw++ * ppi[wy * in_padded_.width_ + wx];}}pa[y * out_.width_ + x] += sum;}}}if (!this->b_.empty()) {float_t *pa = &a[out_.get_index(0, 0, o)];float_t b = this->b_[o];std::for_each(pa, pa + out_.width_ * out_.height_, [&](float_t& f) { f += b; });}});for_i(parallelize_, out_size_, [&](int i) {out[i] = h_.f(a, i);}); vec_t& a = a_[index];for_i(parallelize_, out_size_, [&](int i) {const wi_connections& connections = out2wi_[i];a[i] = 0.0;for (auto connection : connections)// 13.1%a[i] += W_[connection.first] * in[connection.second]; // 3.2%a[i] *= scale_factor_;a[i] += b_[out2bias_[i]];});for_i(parallelize_, out_size_, [&](int i) {output_[index][i] = h_.f(a, i);});C3层、C5层代码段与C1层相同。
S4层代码段与S2层相同。
输出层代码段:
vec_t &a = a_[index];vec_t &out = output_[index];for_i(parallelize_, out_size_, [&](int i) {a[i] = 0.0;for (layer_size_t c = 0; c < in_size_; c++) {a[i] += W_[c*out_size_ + i] * in[c];}if (has_bias_)a[i] += b_[i];});for_i(parallelize_, out_size_, [&](int i) {out[i] = h_.f(a, i);});输出层代码段:
vec_t delta(out_dim());const activation::function& h = layers_.tail()->activation_function();if (is_canonical_link(h)) {for_i(out_dim(), [&](int i){ delta[i] = out[i] - t[i]; });} else {vec_t dE_dy = gradient<E>(out, t);// delta = dE/da = (dE/dy) * (dy/da)for (size_t i = 0; i < out_dim(); i++) {vec_t dy_da = h.df(out, i);delta[i] = vectorize::dot(&dE_dy[0], &dy_da[0], out_dim());}} const vec_t& prev_out = prev_->output(index);const activation::function& prev_h = prev_->activation_function();vec_t& prev_delta = prev_delta_[index];vec_t& dW = dW_[index];vec_t& db = db_[index];for (layer_size_t c = 0; c < this->in_size_; c++) {// propagate delta to previous layer// prev_delta[c] += current_delta[r] * W_[c * out_size_ + r]prev_delta[c] = vectorize::dot(&curr_delta[0], &W_[c*out_size_], out_size_);prev_delta[c] *= prev_h.df(prev_out[c]);}for_(parallelize_, 0, (size_t)out_size_, [&](const blocked_range& r) {// accumulate weight-step using delta// dW[c * out_size + i] += current_delta[i] * prev_out[c]for (layer_size_t c = 0; c < in_size_; c++)vectorize::muladd(&curr_delta[r.begin()], prev_out[c], r.end() - r.begin(), &dW[c*out_size_ + r.begin()]);if (has_bias_) {for (int i = r.begin(); i < r.end(); i++)db[i] += curr_delta[i];}}); const vec_t& prev_out = *(prev_out_padded_[index]);const activation::function& prev_h = prev_->activation_function();vec_t* prev_delta = (pad_type_ == padding::same) ? &prev_delta_padded_[index] : &prev_delta_[index];vec_t& dW = dW_[index];vec_t& db = db_[index];std::fill(prev_delta->begin(), prev_delta->end(), (float_t)0.0);// propagate delta to previous layerfor_i(in_.depth_, [&](int inc) {for (layer_size_t outc = 0; outc < out_.depth_; outc++) {if (!tbl_.is_connected(outc, inc)) continue;const float_t *pw = &this->W_[weight_.get_index(0, 0, in_.depth_ * outc + inc)];const float_t *pdelta_src = &curr_delta[out_.get_index(0, 0, outc)];float_t *pdelta_dst = &(*prev_delta)[in_padded_.get_index(0, 0, inc)];for (layer_size_t y = 0; y < out_.height_; y++) {for (layer_size_t x = 0; x < out_.width_; x++) {const float_t * ppw = pw;const float_t ppdelta_src = pdelta_src[y * out_.width_ + x];float_t * ppdelta_dst = pdelta_dst + y * h_stride_ * in_padded_.width_ + x * w_stride_;for (layer_size_t wy = 0; wy < weight_.height_; wy++) {for (layer_size_t wx = 0; wx < weight_.width_; wx++) {ppdelta_dst[wy * in_padded_.width_ + wx] += *ppw++ * ppdelta_src;}}}}}});for_i(parallelize_, in_padded_.size(), [&](int i) {(*prev_delta)[i] *= prev_h.df(prev_out[i]);});// accumulate dwfor_i(in_.depth_, [&](int inc) {for (layer_size_t outc = 0; outc < out_.depth_; outc++) {if (!tbl_.is_connected(outc, inc)) continue;for (layer_size_t wy = 0; wy < weight_.height_; wy++) {for (layer_size_t wx = 0; wx < weight_.width_; wx++) {float_t dst = 0.0;const float_t * prevo = &prev_out[in_padded_.get_index(wx, wy, inc)];const float_t * delta = &curr_delta[out_.get_index(0, 0, outc)];for (layer_size_t y = 0; y < out_.height_; y++) {dst += vectorize::dot(prevo + y * in_padded_.width_, delta + y * out_.width_, out_.width_);}dW[weight_.get_index(wx, wy, in_.depth_ * outc + inc)] += dst;}}}});// accumulate dbif (!db.empty()) {for (layer_size_t outc = 0; outc < out_.depth_; outc++) {const float_t *delta = &curr_delta[out_.get_index(0, 0, outc)];db[outc] += std::accumulate(delta, delta + out_.width_ * out_.height_, (float_t)0.0);}} const vec_t& prev_out = prev_->output(index);const activation::function& prev_h = prev_->activation_function();vec_t& prev_delta = prev_delta_[index];for_(parallelize_, 0, (size_t)in_size_, [&](const blocked_range& r) {for (int i = r.begin(); i != r.end(); i++) {const wo_connections& connections = in2wo_[i];float_t delta = 0.0;for (auto connection : connections) delta += W_[connection.first] * current_delta[connection.second]; // 40.6%prev_delta[i] = delta * scale_factor_ * prev_h.df(prev_out[i]); // 2.1%}});for_(parallelize_, 0, weight2io_.size(), [&](const blocked_range& r) {for (int i = r.begin(); i < r.end(); i++) {const io_connections& connections = weight2io_[i];float_t diff = 0.0;for (auto connection : connections) // 11.9%diff += prev_out[connection.first] * current_delta[connection.second];dW_[index][i] += diff * scale_factor_;}});for (size_t i = 0; i < bias2out_.size(); i++) {const std::vector<layer_size_t>& outs = bias2out_[i];float_t diff = 0.0;for (auto o : outs)diff += current_delta[o]; db_[index][i] += diff;} C1层代码段与C3层相同。
权值和偏置更新代码段:
void update(const vec_t& dW, const vec_t& /*Hessian*/, vec_t &W) {vec_t& g = get<0>(W);for_i(W.size(), [&](int i) {g[i] += dW[i] * dW[i];W[i] -= alpha * dW[i] / (std::sqrt(g[i]) + eps);});}每此循环执行完60000个训练样本,会对10000个测试样本,进行测试,获得识别率。
共迭代30次,然后将最终的权值、偏置等相关参数保持到指定的文件中。
相关文章:

关于element的select多选选择器,数据回显的问题
关于element的select多选,数据回显的问题 在工作中遇到这样一个问题,新建表单时用element的select多选以后,在编辑的时候打开表单发现其他数据能正常显示,多选却无法正常回显。在网上找了很多后,终于解决了这个问题&am…
360金融发布Q2财报:净利6.92亿,同比增长114%,大数据与AI加持的科技服务是新亮点?
8月23日,360金融发布未经审计的2019年第二季度业绩报告。财务数据显示,2019年第二季度,360金融实现收入22.27亿元人民币,较2018年二季度9.79亿元增长128%;净利润为6.18亿元,而去年同期为净亏损1.42亿元&…

SPRING3.X JSON 406 和 中文乱码问题
2019独角兽企业重金招聘Python工程师标准>>> 简要 最近使用Spring3.2.3 版本 在使用 JSON message convertion 的时候,老是出现406 返回类型不匹配的问题,去网上google 了一番 也没有一个明确的说法,只能自己去调试。 Maven 依…

VLFeat开源库介绍及在VS2013中的编译
VLFeat是一个开源的计算机视觉算法库,内容主要包括feature detectors、feature extractors、k-means clustering、randomized kd-tree matching、super-pixelization。它是跨平台的,能够应用在Linux、Mac、Windows平台。它的License是BSD。 在VS2013中编…

人工智能写手,好用吗?
作者 | 王树义来源 | 玉树芝兰(ID:nkwangshuyi)1、印象之前给学生上课的时候,我介绍过利用循环神经网络,仿照作家风格进行创作的机器学习模型。不过,那模型写出来的东西嘛……我的评价是:望之&a…

表单系列之input number总结
各浏览器表现 <input type"number" /> chrome 除数字字符,只可输入e和.IE 除数字字符,其他字符均可输入,无报错Firefox 除数字字符,其他字符均可输入,但会报错移除箭头 //谷歌去除箭头 input::-webki…
Android中Service深入学习
概述 1、当用户在与当前应用程序不同的应用程序时,Service可以继续在后台运行。 2、Service可以让其他组件绑定,以便和它交互并进行进程间通信。 3、Service默认运行在创建它的应用程序的主线程中。 Service的使用主要是因为应用程序里面可能需要长时间地…
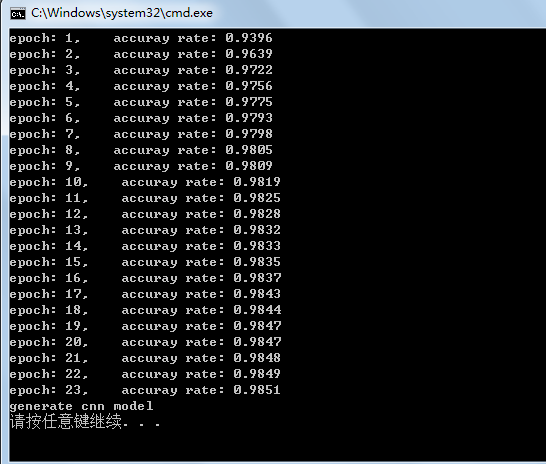
卷积神经网络(CNN)的简单实现(MNIST)
卷积神经网络(CNN)的基础介绍见http://blog.csdn.net/fengbingchun/article/details/50529500,这里主要以代码实现为主。CNN是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。以MNIST作为数据库,仿照…
Tensorflow源码解析5 -- 图的边 - Tensor
1 概述 前文两篇文章分别讲解了TensorFlow核心对象Graph,和Graph的节点Operation。Graph另外一大成员,即为其边Tensor。边用来表示计算的数据,它经过上游节点计算后得到,然后传递给下游节点进行运算。本文讲解Graph的边Tensor&…

物联网成网络安全防护新重点!
在昨天的 2019 北京网络安全大会上,工信部负责人表示,我国面向 5G 和车联网将建设网安防护体系,提升监测预警和应急响应能力。其中物联网设备已成为网安防护新重点。为什么工信部会这么重视物联网?物联网开发者的现状又是如何呢&a…
【分享】Java的几个重要词语
Java 是一种解释型语言,由SUN公司开发,基本上属于一个完全面向对象的语言,并且语言的设计仍然以简捷为重点。初学Java肯定会被一些名词给弄晕了,现在集中几个解释一下下。1、JVMJVM是Java Virtual Machine(Java虚拟机)的缩写&…
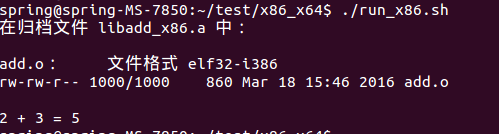
64位Ubuntu上编译32位程序操作步骤
1. 确认主机为64位架构的内核,应该输出为adm64,执行:$ dpkg --print-architecture2. 确认打开了多架构支持功能,应该输出为i386,执行:$ dpkg --print-foreign-architectures如果没有,…
分布式事务中间件 Fescar—RM 模块源码解读
2019独角兽企业重金招聘Python工程师标准>>> 前言 在SOA、微服务架构流行的年代,许多复杂业务上需要支持多资源占用场景,而在分布式系统中因为某个资源不足而导致其它资源占用回滚的系统设计一直是个难点。我所在的团队也遇到了这个问题&…

二维码检测哪家强?五大开源库测评比较
作者 | 周强来源 | 我爱计算机视觉(ID:aicvml)二维码已经进入人们的日常生活中,尤其是日本Denso Wave公司1994年发明的QR码,由于其易于检测、写入信息量大、提供强大的纠错机制,应用最为广泛,可…
linux 内核 出错-HP 方案
2019独角兽企业重金招聘Python工程师标准>>> SUPPORT COMMUNICATION - CUSTOMER ADVISORY Document ID: c03456595 Version: 1 Advisory: Red Hat Enterprise Linux 6 - "P4-Clockmod: Warning: EST-Capable CPU Detected" Messages Logged in /var/log…
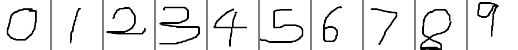
Windows7 64bit VS2013 Caffe test MNIST操作步骤
在http://blog.csdn.net/fengbingchun/article/details/49849225中用Caffe对MNIST数据库进行训练,产生了model。下面介绍下如何将产生的model应用在实际的数字图像识别中。用到的测试图像与http://blog.csdn.net/fengbingchun/article/details/50573841中相同&#…

记住这35个英文单词,你就可以在RPA界混了!
无论是想玩转RPA(机器人流程自动化),还是有意了解、进入这项行业,只有先了解该领域的专有名词(行业术语),才能为之后的活动提供更多的可能。UiBot现为您编译整理了这份机器人流程自动化术语表&a…

福利 | 送你一张通往「2019 AI开发者大会」的门票
2019 AI开发者大会(AI ProCon 2019)是由中国IT社区CSDN主办的AI技术与产业年度盛会。多年经验淬炼,如今蓄势待发:2019年9月6-7日,大会将有近百位中美顶尖AI专家、知名企业代表以及千余名AI开发者齐聚北京,进行技术解读和产业论证。…
收缩日志文件夹
-- MSSQL2005 USE mastergo DECLARE dbname sysname;SET dbnameBSV100;-- 清空日志EXEC (DUMP TRANSACTION [dbname] WITH NO_LOG); -- 截断事务日志:EXEC (BACKUP LOG [dbname] WITH NO_LOG); -- 收缩数据库文件(如果不压缩,数据库的文件不会减小EXEC (DBCC SHR…

腾讯AI开源框架Angel 3.0重磅发布:超50万行代码,支持3种算法,打造全栈机器学习平台...
出品 | AI科技大本营(ID:rgznai100)【导语】2019年8月22日,腾讯首个AI开源项目Angel正式发布3.0版本。Angel 3.0尝试打造一个全栈的机器学习平台,功能特性涵盖了机器学习的各个阶段:特征工程,模…
路印协议受邀参加澳洲新南威尔士政府孵化器Haymarket HQ分享论坛
2019年2月15日,澳洲新南威尔士政府孵化器Haymarket HQ和Next Genius 社区联合举办了区块链解决方案分享论坛,路印协议CMO周杰受邀介绍当前交易所现状和路印协议的去中心化解决方案。参与此次论坛的还有区块链开发人员、企业家和去中心化技术爱好者&#…
一步一步指引你在Windows7上配置编译使用Caffe(https://github.com/fengbingchun/Caffe_Test)
之前写过几篇关于Caffe源码在Windows764位上配置编译及使用过程,只是没有把整个工程放到网上,最近把整个工程整理清理了下,把它放到了GitHub上。下面对这个工程的使用作几点说明:1. 整个工程Caffe在Windows7 64位VS2013下编译…

演示:思科IPS在线模式下Inline Interface Mode的响应行为(区别各个防御行为)
演示:思科IPS在线模式下Inline Interface Mode的响应行为演示目标:科IPS在线模式下InlineInterface Mode的响应行为。演示环境:仍然使用图5.16所示的网络环境。演示背景:在VLAN3的主机192.168.4.2上发起对主机192.168.4.1的漏洞扫…

【笔记】重学前端-winter
本文为:winter 发布在极客时间 【重学前端】系列课程的的笔记和总结支持正版哦: https://time.geekbang.org/col... 导语 如果深入进去了解,你会发现,表面上看他们可能是一时忘记了,或者之前没注意但实际上是他们对于前端的知识体…
如何用知识图谱挖掘商业数据背后的宝藏?
这是一个商业时代,一个数据为王的时代,也是一个 AI 迎来黄金发展期的时代。据史料记载,商业在商朝已初具规模。斗转星移,时光流转,到 2019 年,商业形式已发生翻天覆地的变化,但是商业的本质——…
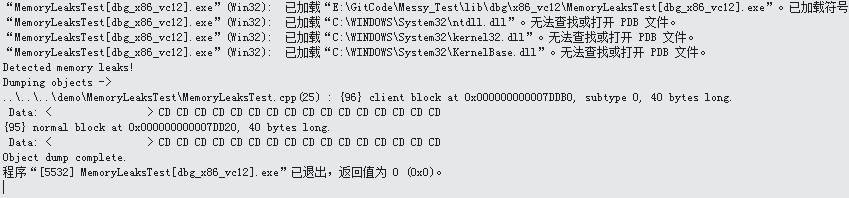
通过define _CRTDBG_MAP_ALLOC宏来检测windows上的code是否有内存泄露
VS中自带了内存泄露检测工具,若要启用内存泄露检测,则在程序中包括以下语句: #define _CRTDBG_MAP_ALLOC #include <crtdbg.h> 它们的先后顺序不能改变。通过包括 crtdbg.h,将malloc和free函数映射到其”Debug”版本_malloc…
java.sql.SQLException: Data truncation: Truncated incorrect DOUBLE value
mysql 报这个异常:java.sql.SQLException: Data truncation: Truncated incorrect DOUBLE value update 表名 set col1 ? and col2 ? where id ? 改为: update 表名 set col1 ? , col2 ? where id ? 用逗号隔开

在Ubuntu14.04 64位上编译CMake源码操作步骤
在Ubuntu上通过apt-get install安装CMake并不是最新版的,这里记录下在Ubuntu上通过源码安装CMake的操作步骤:1. 卸载旧版CMake,执行以下命令:apt-get autoremove cmake如果卸载不掉,则通过执行以下命令删除&…
一份贪心算法区间调度问题解法攻略,拿走不谢
作者 | labuladong来源 | labuladong(ID:labuladong)【导读】什么是贪心算法呢?贪心算法可以认为是动态规划算法的一个特例,相比动态规划,使用贪心算法需要满足更多的条件(贪心选择性质)&#x…
css:z-index
针对position: absolute;解决position:relative;z-index固定定位层级显示问题转载于:https://blog.51cto.com/13507333/2352775