实战:人脸识别的Arcface实现 | CSDN博文精选

具体几种人脸检测的方法以及对比可以参考网页:https://www.learnopencv.com/face-detection-opencv-dlib-and-deep-learning-c-python/
from tqdm import tqdm
import shutil
FaceDeteModel_Type = 'cnn'
FaceDeteModel_Path='mmod_human_face_detector.dat'
FaceShapeModel_Path = 'shape_predictor_68_face_landmarks.dat'
if FaceDeteModel_Type == 'cnn':
detector = dlib.cnn_face_detection_model_v1(FaceDeteModel_Path)
else:
detector = dlib.get_frontal_face_detector()
sp = dlib.shape_predictor(FaceShapeModel_Path)
def FaceDeteAlign_CNN(img):
if isinstance(img, str):
img = cv2.imread(img)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
if img.shape[0] * img.shape[1] > 2500000:
img = cv2.resize(img, (0, 0), fx=0.5, fy=0.5)
imgsize = img.shape[0] * img.shape[1]
dets = detector(img, 0)
if len(dets) == 0:
print('未检测到人脸,请重拍')
return
else:
proposal_dets = []
for i, d in enumerate(dets):
if d.confidence > 0.6:
proposal_dets.append(d)
if len(proposal_dets) == 0:
print('人脸质量不佳,请重拍')
return
det = max(proposal_dets, key=(lambda d: d.rect.width() * d.rect.height()))
if det.rect.width() * det.rect.height() / imgsize <= 1/60:
print('未检测到人脸,请重拍')
return
faces = dlib.full_object_detections()
rec = dlib.rectangle(det.rect.left(), det.rect.top(), det.rect.right(), det.rect.bottom())
faces.append(sp(img, rec))
image = dlib.get_face_chip(img, (faces[0]), size=128)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return image
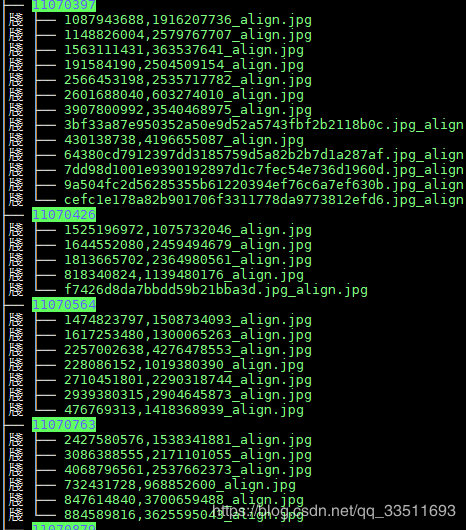
path = '/data/tangsh/face_data/train_celebrity/lfw'
save_path = '/data/tangsh/face_data/train_celebrity/align_flw'
img_file = os.listdir(path)
i = 0
try:
for file in tqdm(img_file):
img_path = os.listdir(os.path.join(path, file))
os.system('mkdir(os.path.join(save_path, file))')
for img_name in img_path:
align_img = FaceDeteAlign_CNN(os.path.join(path, file, img_name))
if align_img is not None:
save_file = os.path.join(save_path, file)
if not os.path.exists(save_file):
os.makedirs(save_file)
print(os.path.join(save_file, img_name))
cv2.imwrite(os.path.join(save_file, img_name), align_img)
else:
i = i+1
print('thr count of none align face', i)
except Exception as error:
print(error)
# 判断当前目录下文件夹里面的图片个数 如果图片的个数少于3删除文件夹
img_file = os.listdir(save_path)
print("len", len(img_file))
for file in tqdm(img_file):
img_path = os.listdir(os.path.join(save_path, file))
print("length", len(img_path))
if len(img_path) < 3:
shutil.rmtree(os.path.join(save_path, file))
# for img_name in img_path:
# os.listdir(os.path.join(path, file))
if opt.display:
visualizer = Visualizer()
device = torch.device("cuda")
train_dataset = Dataset(opt.train_root, opt.train_list, phase='test', input_shape=opt.input_shape)
# Dataset中输入的数据为opt.train_root 数据存放的路径, opt.train_list 每行为训练数据的图片名字 图片的label
f = open('img_train.txt','w')
path = '/data2/fengms/arcface-pytorch-master/data/Datasets/webface/align'
img_file = os.listdir(path)
print("len", len(img_file))
label = 0
for file in img_file:
img_path = os.listdir(os.path.join(path, file))
for img in img_path:
new_context = os.path.join(file, img) + " " + str(label) + '\n'
print(new_context)
f.write(new_context)
label = label + 1
f.close()
classify = 'softmax'
num_classes = 10001 #等于人脸中类别的个数,大于或者小于报错
metric = 'arc_margin'
easy_margin = False
use_se = False
loss = 'focal_loss'
display = False
finetune = False
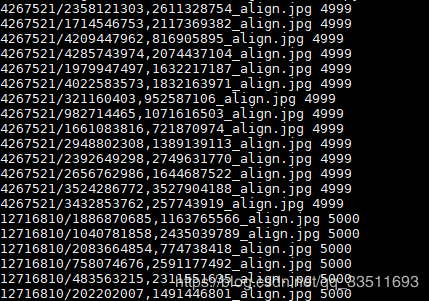
train_root = '/data2/fengms/arcface-pytorch-master/data/Datasets/webface/align'
train_list = '/data2/fengms/arcface-pytorch-master/data/Datasets/webface/img_info.txt'
val_list = '/data/Datasets/webface/val_data_13938.txt'
test_root = '/data1/Datasets/anti-spoofing/test/data_align_256'
test_list = 'test.txt'
lfw_root = '/data2/fengms/arcface-pytorch-master/data/Datasets/lfw/align_flw'
lfw_test_list = '/data2/fengms/arcface-pytorch-master/data/Datasets/lfw/lfw_test_pair.txt'
checkpoints_path = 'checkpoints'
load_model_path = 'models/resnet18.pth'
test_model_path = 'checkpoints/resnet18_110.pth'
save_interval = 10
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.fc5 = nn.Linear(512 * 16 * 16, 512)


(*本文为 AI科技大本营转载文章,请联系作者)
◆
彩蛋~ ◆
1024程序员节超值特惠限时秒杀!活动时间:2019年10月24日00:00-24:00凡在此活动期间购买大会单人票,即送价值298元的CSDN VIP年卡!
(VIP年卡特权:全站免广告+600个资源免积分下载+学院千门课程免费看+购课9折)
推荐阅读

你点的每个“在看”,我都认真当成了AI
相关文章:
Windows7/10上快速搭建Tesseract-OCR开发环境操作步骤
之前在https://blog.csdn.net/fengbingchun/article/details/51628957 中描述过如何在Windows上搭建Tesseract-OCR开发环境,那时除了需要clone https://github.com/fengbingchun/OCR_Test 工程外,还需要依赖 https://github.com/fengbingchun/Liblept_T…

C#基础系列:实现自己的ORM(反射以及Attribute在ORM中的应用)
反射以及Attribute在ORM中的应用 一、 反射什么是反射?简单点吧,反射就是在运行时动态获取对象信息的方法,比如运行时知道对象有哪些属性,方法,委托等等等等。反射有什么用呢?反射不但让你在运行是获取对象…
Network | sk_buff
sk_buff结构可能是linux网络代码中最重要的数据结构,它表示接收或发送数据包的包头信息。它在中定义,并包含很多成员变量供网络代码中的各子系统使用。 这个结构被不同的网络层(MAC或者其他二层链路协议,三层的IP,四…
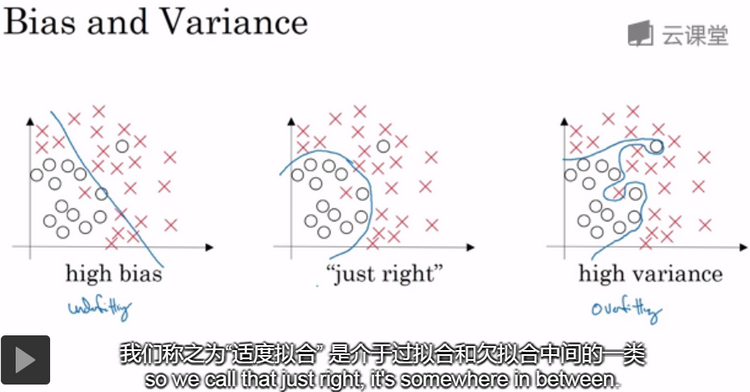
吴恩达老师深度学习视频课笔记:深度学习的实用层面
训练、验证和测试数据集(training、development and test sets):训练神经网络时,我们需要作出很多决策,如神经网络分多少层(layers)、每层含有多少个隐藏层单元(hidden units)、学习率(learning rates)、各层采用哪些激活函数(activation fun…

FtpCopy数据定时自动备份软件(FTP定时备份)
1. 软件说明 FtpCopy是一款免费的FTP数据自动备份软件,如果FtpCopy对您有较大的帮助,欢迎捐赠我们,我们对您表示衷心的感谢! 如果有需求的话会一直更新下去,将软件做到极致! 有问题可直接“反馈留言”。 特…
专注NLP,竹间智能完成4500万美元B+轮融资
近日,竹间智能在成立四周年之际宣布完成4500万美元B轮融资。本轮由某重要战略合作方、云晖资本及领沨资本联合领投,凯思博投资、众安资本、趋势资本、普华资本、一路资本跟投,光源资本担任本轮融资的独家财务顾问。竹间智能方面表示ÿ…

JDBC连接各种数据库方法
为什么80%的码农都做不了架构师?>>> 声明 以下内容收集自网络,并没有亲自测试可用性。 一、Oracle8/8i/9i数据库(thin模式) Class.forName("oracle.jdbc.driver.OracleDriver").newInstance(); String url&…

OpenCV支持中文字符输出实现
在 http://www.opencv.org.cn/forum.php?modviewthread&tid2083&extra&page1 中,作者给出了原始的在OpenCV中 支持中文字符的输入,原始的实现使用的是OpenCV的C接口,使用起来不怎么方便,这里对原作者的实现进行调整&…

CSDN”原力计划“在召唤:技术人请集结,用原创技术影响万千开发者
技术深不可测、薪资难以想象、着装招人吐槽、发量让人惊叹、笑点着实密集、情商令人堪忧......在这个你我他她它通过网络紧密互联、消息实时互通的 21 世纪,人们对身处技术至高点的程序员们仍然有着以上不接地气、呆板保守的误解,对此,操着一…
.asmx支持post请求或者get请求调用(WebService 因 URL 意外地以 结束,请求格式无法识别 的解决方法)...
使用Post调用以asmx形式提供的webservice时,在本机调试没有调用问题。一旦部署至服务器后会提示如下信息: <html><head><title>因 URL 意外地以“/GetCertByToken”结束,请求格式无法识别。</title><meta name&qu…
关于StartCoroutine的简单线程使用
StartCoroutine在unity3d的帮助中叫做协程,意思就是启动一个辅助的线程。 在C#中直接有Thread这个线程,但是在unity中有些元素是不能操作的。这个时候可以使用协程来完成。 使用线程的好处就是不会出现界面卡死的情况,如果有一次非常大量的运…
Robot Framework(十八) 支持工具
5支持工具 5.1库文档工具(libdoc) libdoc是一种用于为HTML和XML格式的测试库和资源文件生成关键字文档的工具。前一种格式适用于人类,后者适用于RIDE和其他工具。Libdoc也没有很少的特殊命令来显示控制台上的库或资源信息。 可以创建文档&…

基于开源TiRG的文本检测与提取实现
在 http://funkybee.narod.ru/ 中作者给出了文本检测和提取的实现,仅有一个.hpp文件,为了在windows上编译通过,这里简单进行了改动,改动后的code如下: #include <math.h> #include <stdio.h> #include &l…
Kaggle Days首次落地中国,日本团队拿下冠军
2019 年 10 月 20 日, 为期两天的 Kaggle Days 中国活动在北京圆满结束。作为全球最知名的线下数据科学活动在中国的首次落地,Kaggle Days 获得了谷歌、Kaggle 以及 16 位来自美国、俄罗斯、捷克、日本以及中国的 Kaggle Grandmaster 以及 Master 的大力…
《WF编程》笔记目录
《WF编程》笔记目录
activity的四种加载模式
在android里,有4种activity的启动模式,分别为: standard, singleTop, singleTask和singleInstance, 其中standard和singleTop类似, singleTask和singleInstance类似, 用法如下: (1).standard和singleTop 这…
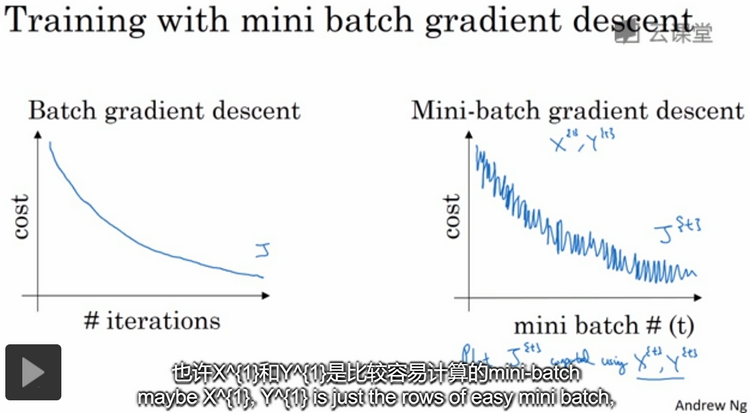
吴恩达老师深度学习视频课笔记:优化算法
优化算法能够帮助你快速训练模型。mini-batch梯度下降法:把训练集分割(split)为小一点的子训练集,这些子集被叫做mini-batch。batch梯度下降法指的是:同时处理整个训练集,只有处理完整个训练集才更新一次权值和偏置。并且预期每次…

程序员编程时戴耳机是在听什么?
1024程序员节,CSDN旗下的码书商店为程序员放个“价”,全场所有书籍8折,电子产品可以拥有大额优惠券,购买前可加文末客服微信领取优惠券哦。兰士顿耳机,原价199元,1024专属价159元,购买时候请输入…

Mac中MacPorts安装和使用
文章转载至http://www.zikercn.com/node/8 星期四, 06/07/2012 - 19:02 — 张慧敏 MacPorts简单介绍 MacPorts,以前叫做DarwinPorts,是一个软件包管理系统,用来简化Mac OS X和Darwin操作系统上软件的安装。它是一个用来简化自由软件/开放源码…

小白入门:我是如何学好机器学习的?
作者 | Jae Duk Seo译者 | Tianyu编辑 | 夕颜出品 | AI科技大本营(ID: rgznai100)在我看来,机器学习是一个计算机科学和数学知识相融合的研究领域。虽然这是个很有趣的领域,但它其实没有想象中那么难。我相信只要你有足够的动力、…
数据库服务器 之 PostgreSQL数据库的日常维护工作
来自:LinuxSir.Org摘要:为了保持所安装的 PostgreSQL 服务器平稳运行, 我们必须做一些日常性的维护工作。我们在这里讨论的这些工作都是经常重复的事情, 可以很容易地使用标准的 Unix 工具,比如cron 脚本来实现; 目录1. 综述&…
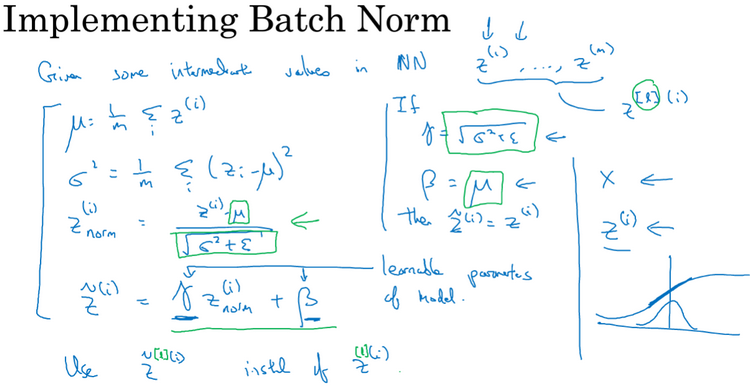
吴恩达老师深度学习视频课笔记:超参数调试、Batch正则化和程序框架
Tuning process(调试处理):神经网络的调整会涉及到许多不同超参数的设置。需要调试的重要超参数一般包括:学习率、momentum、mini-batch size、隐藏单元(hidden units)、层数、学习率衰减。一般对于你要解决的问题而言,你很难提前知道哪个参数…
AD上删除了Exchange容器,再重装时报'找不到企业组织容器
AD上删除了Exchange容器,再重装时报找不到企业组织容器。安装日志如下:[06/16/2014 04:58:15.0054] [0] **********************************************[06/16/2014 04:58:15.0054] [0] Starting Microsoft Exchange Server 2013 Service Pack 1 Setup[06/16/2014 04:58:15.0…
实战:基于OpenPose的卡通人物可视化 | CSDN博文精选
作者 | Wuzebiao2016来源 | CSDN博客前言去年打算用些现成的Pose做些展示,因为以前有在OpenPose做些识别等开发工作,所以这次我就简单在OpenPose上把骨架用动画填充上去,关于能够和人动作联系起来的动画,我找到了Unity提供的示例A…

基于Idea从零搭建一个最简单的vue项目
一、需要了解的基本知识 node.js Node.js是一个Javascript运行环境(runtime),发布于2009年5月,由Ryan Dahl开发,实质是对Chrome V8引擎进行了封装。Node.js对一些特殊用例进行优化,提供替代的API,使得V8在非浏览器环境…

OpenCV中基于LBP算法的人脸检测测试代码
下面是OpenCV 3.3中基于CascadeClassifier类的LBP算法实现的人脸检测,从结果上看,不如其它开源库效果好,如libfacedetection,可参考 https://blog.csdn.net/fengbingchun/article/details/52964163 #include "funset.hpp&qu…
解决getOutputStream() has already been called for this response[java io流]
getOutputStream() has already been called for this response以上异常出现的原因和解决方法:jsp中出现此错误一般都是在jsp中使用了输出流(如输出图片验证码,文件下载等),没有妥善处理好的原因。具体的原因ÿ…

吴恩达老师深度学习视频课笔记:构建机器学习项目(机器学习策略)(1)
机器学习策略(machine learning strategy):分析机器学习问题的方法。正交化(orthogonalization):要让一个监督机器学习系统很好的工作,一般要确保四件事情,如下图:(1)、首先,你通常必须确保至少系统在训练集…

内行的AI盛会——北京智源大会带你洞见未来!(含日程及限量优惠)
报名请点击「阅读原文」北京国家会议中心2019年10月31日-11月1日www.baai.ac.cn/2019使用优惠码「BAAICSDN」专享7折优惠学生票仅69元,数量有限,先到先得世界AI看中国,中国AI看北京(长按上图或点击「阅读原文」注册参会࿰…
微软职位内部推荐-Sr. Dev Lead
微软近期Open的职位:JD如果你想试试这个职位,请跟我联系,我是微软的员工,可以做内部推荐。发你的中英文简历到我的邮箱:Nicholas.lu.mail(at)gmail.com转载于:https://www.cnblogs.com/DotNetNuke/p/3885283.html