吴恩达老师深度学习视频课笔记:优化算法
优化算法能够帮助你快速训练模型。
mini-batch梯度下降法:把训练集分割(split)为小一点的子训练集,这些子集被叫做mini-batch。
batch梯度下降法指的是:同时处理整个训练集,只有处理完整个训练集才更新一次权值和偏置。并且预期每次迭代的成本都会下降,如果成本函数(cost function)J是迭代次数的一个函数,它应该会随着每次迭代而减少,如果J在某次迭代中增加了,那肯定在某处出现了问题。
mini-batch梯度下降法指的是:每次同时处理的是单个mini-batch,而不是同时处理整个训练集,每处理完单个子集时都会更新一次权值和偏置。但是与batch梯度下降法不同的是,如果成本函数(cost function)J是迭代次数的一个函数,则并不是每次迭代J都是下降的,它的趋势是向下,但是也带有更多的噪声;在mini-batch梯度下降法中,没有每次迭代J都是下降的也是可以的,但是走势应该是向下的,如下图:
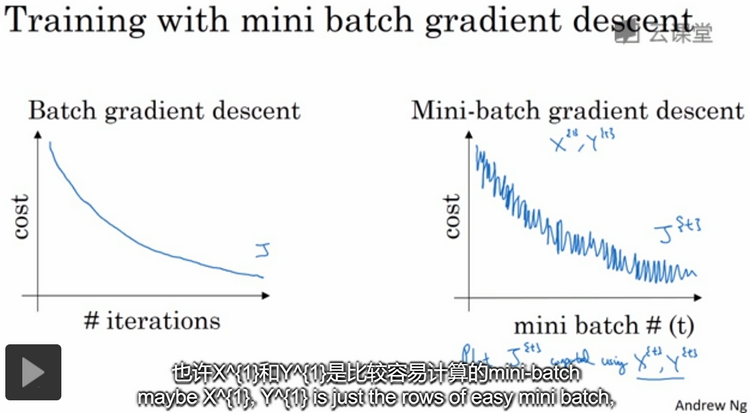
选择mini-batch的大小:假设m为整个训练集的大小。一种极端情况下,如果mini-batch的大小为m,其实就是batch梯度下降法。另一种极端情况下,如果mini-batch的大小为1,则叫做随机梯度下降法(stochastic gradient descent),每个样本都是一个独立的mini-batch。随机梯度下降法永远不会收敛,而是会一直在最小值附近波动,但是并不会在达到最下值时停留下来。实际中,mini-batch的大小应该在1和m之间选择,1太小而m太大,如下图:

如果训练集较少,直接使用batch梯度下降法,样本集较少就没必要使用mini-batch梯度下降法。一般说的少是指样本集总数小于2000.如果样本集数目较大的话,一般的mini-batch大小在64至512之间,如64、128、256、512。考虑到电脑内存布局和访问的方式,有时mini-batch的大小为2的n次方,code会运行的较快一些。
指数加权平均(exponentially weighted averages):关键公式vt=βvt-1+(1-β)θt,如下图,以计算一年中第t天的平均温度为例,图中的v100就是一年中第100天计算的数据。有偏差修正(biascorrection)的指数加权平均。
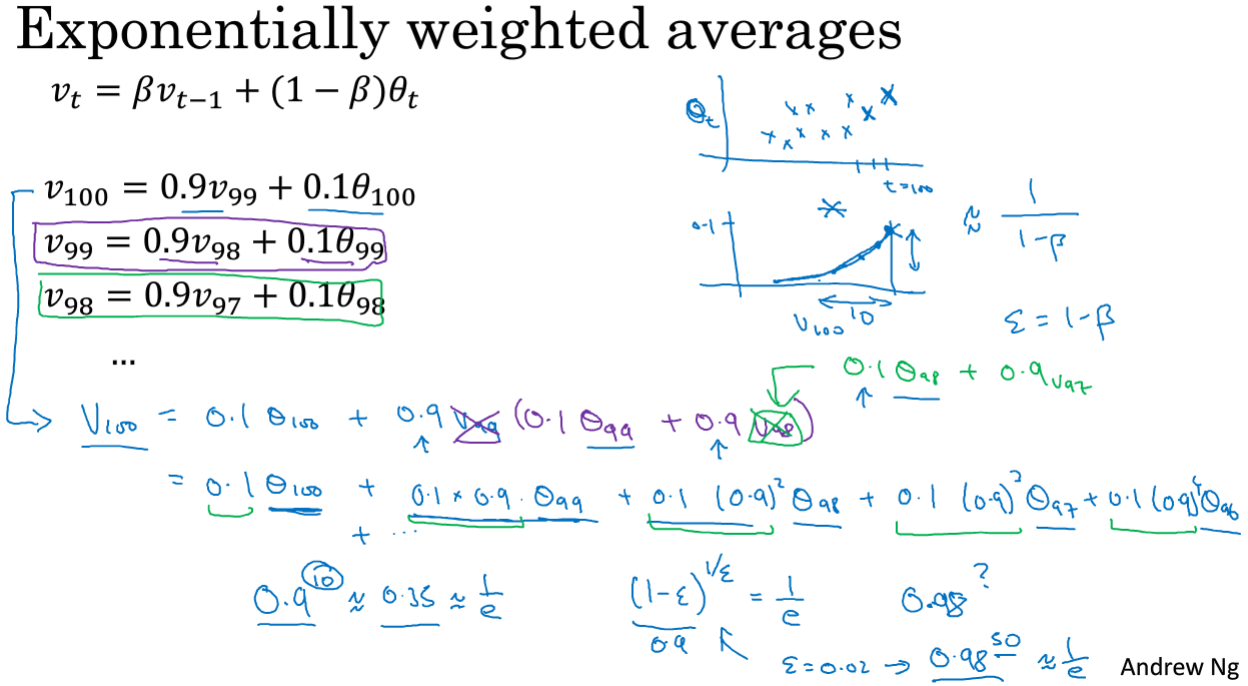
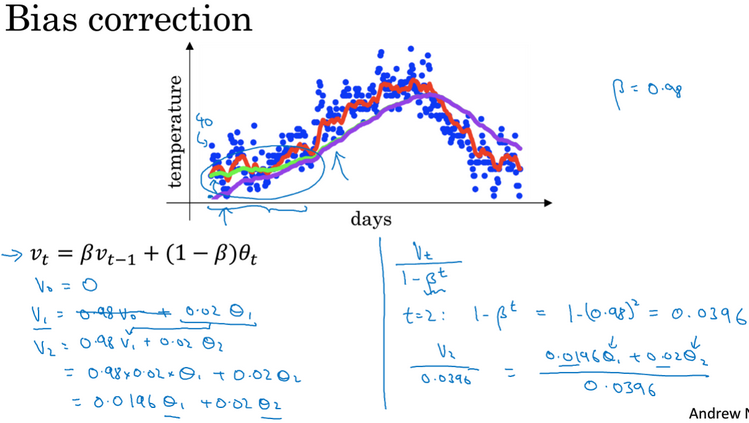
偏差修正(bias correction):可以让平均数计算更加准确。如果你关心初始时期的偏差,在刚开始计算指数加权平均数的时候,偏差修正能帮助你在早期获得更好的估计。即用vt/(1-βt)= (βvt-1+(1-β)θt)/ (1-βt)替代之前vt=βvt-1+(1-β)θt,你会发现,随着t的增加,β的t次方将接近于0,所以当t很大的时候,偏差修正几乎没有作用,如下图:
动量梯度下降法(gradient descent with momentum):运行速度几乎总是快于标准的梯度下降算法。基本的想法就是计算梯度的指数加权平均并利用该梯度更新你的权值。在mini-batch或batch梯度下降法中,第t次迭代过程中,你会计算导数dw,db,如下图:

这样就可以减缓梯度下降的幅度。不像梯度下降法,每一步都独立于之前的步骤。超参β控制着指数加权平均(exponentially weighted average),β最常用的值是0.9。实际中,在使用梯度下降法或momentum时并不强制(bother)使用偏差修正,因为10次迭代以后,你的移动平移(your moving average)已经过了初始阶段不再是一个具有偏差的预测。vdw的初始值为0,vdw和w具有相同的维数。vdb的初始值也为0和b具有相同的维数。有时会使用vdw=βvdw+dw替代vdw=βvdw+(1-β)dw,一般不这么做。
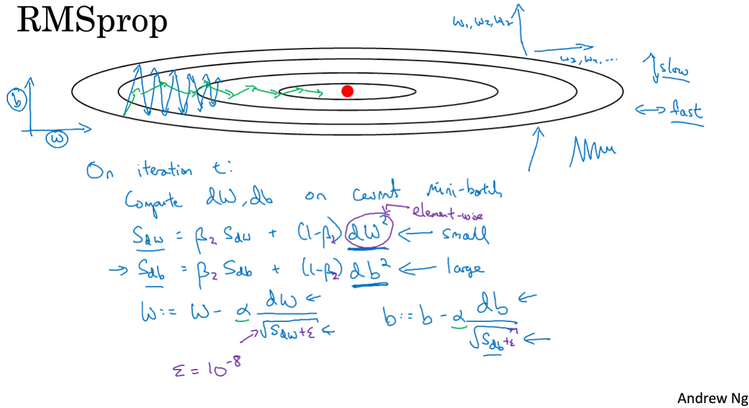
RMSprop(root mean square prop,均方根):也可以加速梯度下降,如下图。在第t次迭代中,RMSprop会照常计算dw,db,保留指数加权平均,使用sdw替代vdw, sdw=βsdw+(1-β)dw2,这样做能够保留导数平方的加权平均数(an exponentially weighted average of thesquares of the derivatives)。sdb类似。接着,RMSprop会这样更新参数值:w=w-αdw/(square root(sdw)),参数b类似。RMSprop和momentum一样,可以消除梯度下降中的摆动,并允许你使用一个更大的学习率α。
Adam(Adaptive Moment Estimation):将momentum和RMSprop结合在一起,如下图。一般使用Adam时,要计算偏差修正。Adam能有效适用于不同的神经网络。在使用Adam时,人们经常赋值超参数β1为0.9, β2为0.999,ε为10-8,经常使用这些缺省值即可,然后尝试不同的α值,看看哪个效果更好。

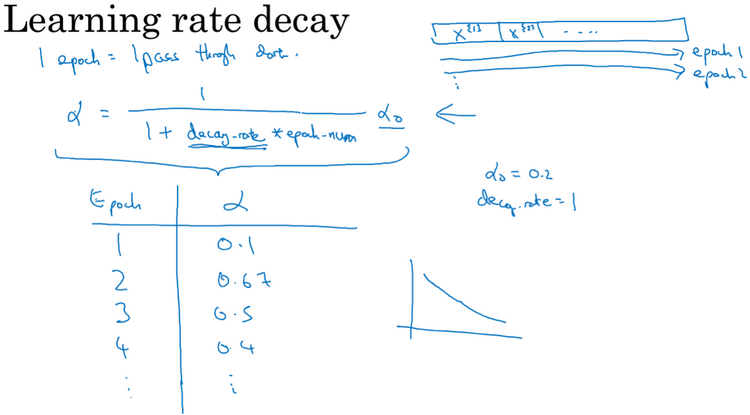
Learning rate decay(学习率衰减):加快学习算法的一个办法就是随时间慢慢减少学习率,称之为学习率衰减,公式如下图。如果使用学习率衰减,需要调的超参包括:α0即初始学习率;衰减率(decay rate);k等。有时人们还会手动衰减,一般只有模型数量小的时候有用。

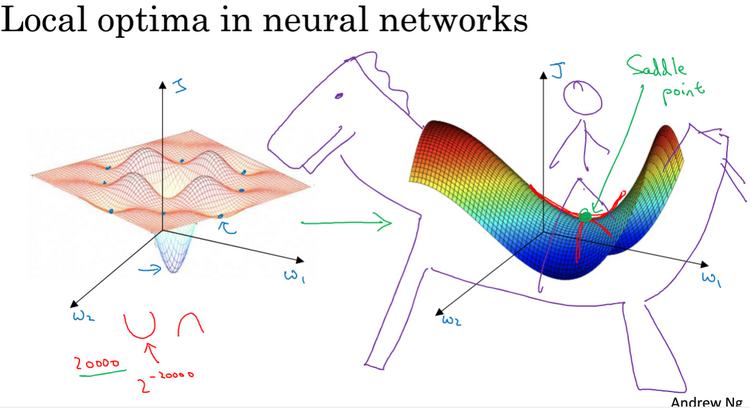
局部最优的问题:创建一个神经网络,通常梯度为零的点,并不是局部最优点,实际上成本函数J的零梯度点通常是鞍点,如下图。一个具有高维空间的函数,如果梯度为0,那么在每个方向它可能是凸函数,也可能是凹函数,在高维度空间更有可能碰到鞍点而不会碰到局部最优。
GitHub: https://github.com/fengbingchun/NN_Test
相关文章:

程序员编程时戴耳机是在听什么?
1024程序员节,CSDN旗下的码书商店为程序员放个“价”,全场所有书籍8折,电子产品可以拥有大额优惠券,购买前可加文末客服微信领取优惠券哦。兰士顿耳机,原价199元,1024专属价159元,购买时候请输入…

Mac中MacPorts安装和使用
文章转载至http://www.zikercn.com/node/8 星期四, 06/07/2012 - 19:02 — 张慧敏 MacPorts简单介绍 MacPorts,以前叫做DarwinPorts,是一个软件包管理系统,用来简化Mac OS X和Darwin操作系统上软件的安装。它是一个用来简化自由软件/开放源码…

小白入门:我是如何学好机器学习的?
作者 | Jae Duk Seo译者 | Tianyu编辑 | 夕颜出品 | AI科技大本营(ID: rgznai100)在我看来,机器学习是一个计算机科学和数学知识相融合的研究领域。虽然这是个很有趣的领域,但它其实没有想象中那么难。我相信只要你有足够的动力、…

数据库服务器 之 PostgreSQL数据库的日常维护工作
来自:LinuxSir.Org摘要:为了保持所安装的 PostgreSQL 服务器平稳运行, 我们必须做一些日常性的维护工作。我们在这里讨论的这些工作都是经常重复的事情, 可以很容易地使用标准的 Unix 工具,比如cron 脚本来实现; 目录1. 综述&…
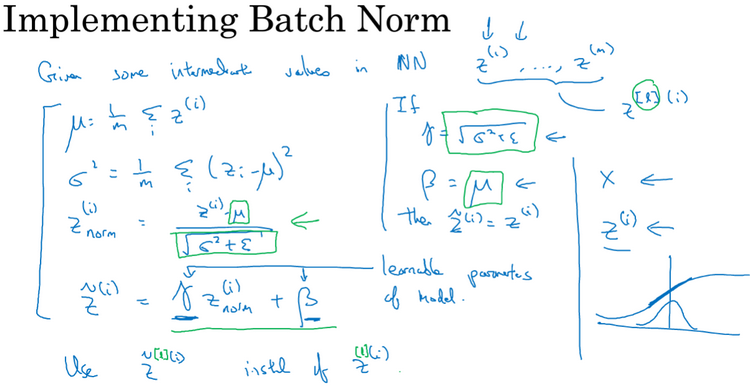
吴恩达老师深度学习视频课笔记:超参数调试、Batch正则化和程序框架
Tuning process(调试处理):神经网络的调整会涉及到许多不同超参数的设置。需要调试的重要超参数一般包括:学习率、momentum、mini-batch size、隐藏单元(hidden units)、层数、学习率衰减。一般对于你要解决的问题而言,你很难提前知道哪个参数…
AD上删除了Exchange容器,再重装时报'找不到企业组织容器
AD上删除了Exchange容器,再重装时报找不到企业组织容器。安装日志如下:[06/16/2014 04:58:15.0054] [0] **********************************************[06/16/2014 04:58:15.0054] [0] Starting Microsoft Exchange Server 2013 Service Pack 1 Setup[06/16/2014 04:58:15.0…
实战:基于OpenPose的卡通人物可视化 | CSDN博文精选
作者 | Wuzebiao2016来源 | CSDN博客前言去年打算用些现成的Pose做些展示,因为以前有在OpenPose做些识别等开发工作,所以这次我就简单在OpenPose上把骨架用动画填充上去,关于能够和人动作联系起来的动画,我找到了Unity提供的示例A…

基于Idea从零搭建一个最简单的vue项目
一、需要了解的基本知识 node.js Node.js是一个Javascript运行环境(runtime),发布于2009年5月,由Ryan Dahl开发,实质是对Chrome V8引擎进行了封装。Node.js对一些特殊用例进行优化,提供替代的API,使得V8在非浏览器环境…

OpenCV中基于LBP算法的人脸检测测试代码
下面是OpenCV 3.3中基于CascadeClassifier类的LBP算法实现的人脸检测,从结果上看,不如其它开源库效果好,如libfacedetection,可参考 https://blog.csdn.net/fengbingchun/article/details/52964163 #include "funset.hpp&qu…
解决getOutputStream() has already been called for this response[java io流]
getOutputStream() has already been called for this response以上异常出现的原因和解决方法:jsp中出现此错误一般都是在jsp中使用了输出流(如输出图片验证码,文件下载等),没有妥善处理好的原因。具体的原因ÿ…

吴恩达老师深度学习视频课笔记:构建机器学习项目(机器学习策略)(1)
机器学习策略(machine learning strategy):分析机器学习问题的方法。正交化(orthogonalization):要让一个监督机器学习系统很好的工作,一般要确保四件事情,如下图:(1)、首先,你通常必须确保至少系统在训练集…

内行的AI盛会——北京智源大会带你洞见未来!(含日程及限量优惠)
报名请点击「阅读原文」北京国家会议中心2019年10月31日-11月1日www.baai.ac.cn/2019使用优惠码「BAAICSDN」专享7折优惠学生票仅69元,数量有限,先到先得世界AI看中国,中国AI看北京(长按上图或点击「阅读原文」注册参会࿰…
微软职位内部推荐-Sr. Dev Lead
微软近期Open的职位:JD如果你想试试这个职位,请跟我联系,我是微软的员工,可以做内部推荐。发你的中英文简历到我的邮箱:Nicholas.lu.mail(at)gmail.com转载于:https://www.cnblogs.com/DotNetNuke/p/3885283.html

吴恩达老师深度学习视频课笔记:构建机器学习项目(机器学习策略)(2)
进行误差分析:可进行人工统计或可同时并行评估几个想法。进行误差分析时,你应该找一组错误例子,可能在你的开发集里或者在你的测试集里,观察错误标记的例子,看看假阳性(false positives)和假阴性(false negatives)&…

3D机器人视觉在仓储物流和工业自动化领域的应用 | AI ProCon 2019
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)随着深度学习和机器学习的发展,机器人已经走出实验室,越来越多地地应用于各行各业,其中,仓储物流和工业化领域就有许多适合机器人作业的场景环境。人眼的一大…
【转载】gdi+ 内存泄漏
【转载】http://issf.blog.163.com/blog/static/1941290822009111894413472/ 最近用GDI实现了几个自定义控件,但是发现存在内存泄露问题 BOOL CGdiplusBugDlg::OnEraseBkgnd(CDC* pDC) {Image* pImage Image::FromFile(L"E:\\bac.bmp");Graphics g(pDC-&…
ubuntu fctix
感觉ubuntu自在大ibus输入法用起来实在是灰常蛋痛啊,于是乎就换了fcitx输入法(很多人推荐嘛)在安装之前先说一下fcitx输入法吧。1.添加fcitx源(官方的源是旧版,不推荐使用)fcitx的ppa源,内含fcitx和fcitx-config,使用命令sudo ged…
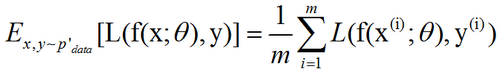
深度学习中的优化简介
深度学习算法在许多情况下都涉及到优化。1. 学习和纯优化有什么不同在大多数机器学习问题中,我们关注某些性能度量P,其定义于测试集上并且可能是不可解的。因此,我们只是间接地优化P。我们系统通过降低代价函数J(θ)来提高P。这一点与纯优化不…
飞凌OK6410开发板移植u-boot官方最新版u-boot-2012.10.tar.bz2
Part0 准备知识 0.1 关键参数说明 0.1.1 开发板说明 OK6410是飞凌公司发布的一款开发板,当前有2个版本,OK6410-A和OK6410-B,我当前使用的是前者;前者也经历过升级,所以有128M ram的和较新的256内存的版本,n…
参数量110亿,附赠750GB数据集,Google提NLP预训练模型T5
整理 | Just,夕颜出品 | AI科技大本营(ID:rgznai100)近日,Google 在最新一篇共有 53 页的论文《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》中,提出了一个最新的预训练模型…

Linux之bash编程基本语法
在Linux运维工作中,我们为了提高工作效率通常会用bash编写脚本来完成某工作。今天就来为大家介绍bash的一些常见的基本语法。在讲解bash语法之前首先介绍一下bash。bash环境主要是由解释器来完成的。【解释器】:解释命令:词法分析、语法分析、…
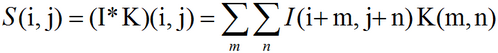
深度学习中的卷积网络简介
卷积网络(convolutional network)也叫做卷积神经网络(convolutional neural network, CNN),是一种专门用来处理具有类似网格结构的数据的神经网络。例如时间序列数据(可以认为是在时间轴上有规律地采样形成的一维网格)和图像数据(可以看作是二维的像素网格)。卷积网…

Windows下搭建PHP开发环境
PHP集成开发环境有很多,如XAMPP、AppServ......只要一键安装就把PHP环境给搭建好了。但这种安装方式不够灵活,软件的自由组合不方便,同时也不利于学习。所以我还是喜欢手工搭建PHP开发环境,需要哪个模块自己安装就行了,…

大数据时代下的新生态、新洞察、新趋势 | 神策 2019 数据驱动大会
10 月 22 日,以“矩•变”为主题的神策 2019 数据驱动大会在北京维景国际大酒店顺利举行,来自全球大数据各大行业的领袖人物聚首北京,融合国际前沿技术与行业实践,深入探讨大数据时代下的新生态、新洞察、新趋势。 大会主题“矩•…
ckedit 文本编辑器
Ckeditor是一个功能非常强大的富文本编辑器,博客园有使用此编辑器,其功能完全可以与MS的Word媲美。 用起来也非常方便。下面是本人总结的安装步骤: 第一步,从http://ckeditor.com/download 下载ckeditor文件包 第二步,…

为什么我害怕数据结构学得好的程序员?
我害怕数据结构学得好的程序员,一跟他们讨论技术,我就感觉自己不是程序员,仅仅是在搬砖维持生活。我所拥有的编程技巧是什么?不就是每个程序员都会的,对数据库的增删改查吗?每一个初入职场的程序员都会。但…
Go语言基础介绍
Go是一个开源的编程语言。Go语言被设计成一门应用于搭载Web服务器,存储集群或类似用途的巨型中央服务器的系统编程语言。目前,Go最新发布版本为1.10.Go语言可以运行在Linux、FreeBSD、Mac OS X和Windows系统上。1. 结构:Go语言的基础组成有以…
强制退出WinForm程序之Application.Exit和Environment.Eixt
这几天在做一个把大量Infopath生成的XML数据,进行处理的程序,我用了MDI子窗体,每个窗体包含了各自的功能,如,遍历目录及其子目录检查文件类型并自动生成Sql语句并入库、对Infopath数据的自动检查、对数据中的某些域的替…
Oracle Study之--Oracle等待事件(3)
Oracle Study之--Oracle等待事件(3)Db file parallel read这是一个很容易引起误导的等待事件,实际上这个等待事件和并行操作(比如并行查询,并行DML)没有关系。 这个事件发生在数据库恢复的时候,…
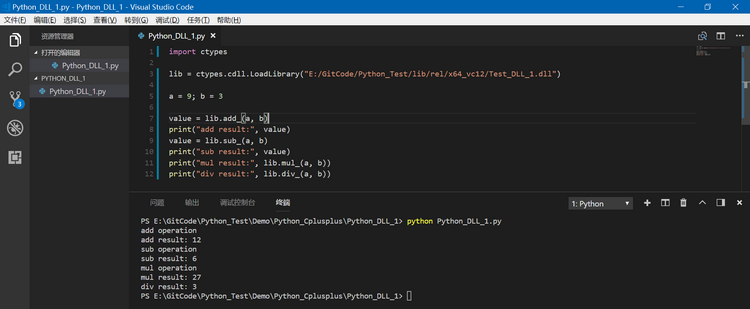
Windows下通过Python 3.x的ctypes调用C接口
在Python中可以通过ctypes来调用动态库中的C接口,具体操作过程如下:1. 使用vs2013创建一个加、减、乘、除的动态库,并对外提供C接口,code内容如下:math_operations.hpp: #ifndef TEST_DLL_1_MATH_OPERATIONS_HPP_ #def…