吴恩达老师深度学习视频课笔记:循环神经网络
Why sequence models?:序列数据例子,如下图:(1).语音识别(speech recognition):给定一个输入音频片段X,并要求输出片段对应的文字记录Y,这里输入和输出都是序列数据(sequence data)。因为X是按时序播放的音频片段,输出Y是一系列单词。(2). 音乐生成(music generation):只有输出数据Y是序列;输入数据可以是空集,也可以是单一的整数,这个数可能指代你想要生成的音乐风格,也可能是你想要生成的那首曲子的头几个音符。无论怎样,输入X可以是空的或者就是某个数字,然输入Y是一个序列。(3). 情感分类(sentiment classification):输入数据X是序列。(4). DNA序列分析(DNA sequence analysis);(5). 机器翻译(machine translation);(6).视频行为识别(video activity recognition);(7). 命名实体识别(name entity recognition):可能会给出一个句子,要求识别出句中的人名。所有这些问题都可以被称作使用标签数据(X,Y)作为训练集的监督学习。序列问题可以有很多不同的类型,有些问题里输入X和输出数据Y都是序列,但是X和Y有时也会有不一样的长度。在一些问题里,只有X或Y是序列。

符号(Notation):使用x<t>来索引序列中的位置,t意味着它们是时序序列;使用Tx来表示输入序列的长度;使用Ty来表示输出序列的长度;Tx和Ty可以有不同的长度;x(i)<t>来表示训练样本i的输入序列中第t个元素;Tx(i)来表示第i个训练样本的输入序列长度;y(i)<t>来表示训练样本i的输出序列中第t个元素;Ty(i)来表示第i个训练样本的输出序列长度。
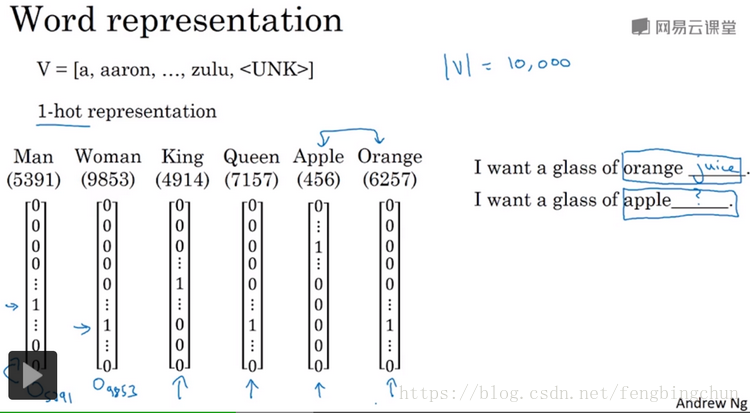
自然语言处理(Natural Language Processing, NLP)怎样表示一个序列里单独的单词,如下图:想要表示一个句子里的单词,第一件事是做一张词表,有时也称为词典(dictionary),意思是列一列你的表示方法中要用到的单词,如第一个单词是a,第二个单词是aaron,等等,用了10000个单词大小的词典。一般常见的词典大小为30000到50000,有的也会用百万词典。接下来你可以用one-hot表示法来表示词典里的每个单词,x<t>指代句子里的任意词,它就是个one-hot向量,是因为只有一个值是1,其余值都是0。

循环神经网络模型:命名实体识别不能使用标准神经网络的原因:(1). 输入和输出数据在不同例子中可以有不同的长度;(2). 一个单纯的神经网络结构并不共享从文本的不同位置上学到的特征。而循环神经网络针对序列数据就没有以上两个缺点。
循环神经网络,如下图:假如你从左往右的顺序读句子,第一个单词假如是x<1>,将第一个词输入一个神经网络层,然后尝试预测输出y<1>,判断这是否是人名的一部分。循环神经网络做的是,当它读到句中的第二单词时,假如是x<2>,它不是仅用x<2>就预测出y<2>,它也会输入一些来自时间步(time-step)1的信息。具体而言,时间步1的激活值就会传递到时间步2。然后,在下一个时间步,循环神经网络输入单词x<3>,然后它尝试输出预测结果y<3>,等等。一直到最后一个时间步,输入x<Tx>,然后输出y<Ty>.在这个例子中Tx=Ty,如果Tx!=Ty那么这个网络结构需要作出一些改变。在每一个时间步中,循环神经网络传递一个激活值到下一个时间步中用于计算。要开始整个流程,我们在零时刻,需要编造一个激活值,这通常是零向量。也有些研究员会随机用其它方法初始化a<0>,不过使用零向量作为零时刻的伪激活值是最常见的选择。循环神经网络的画法一般有两种,一种是分步画法,一种是图表画法。循环神经网络是从左向右扫描数据,同时每个时间步的参数也是共享的。我们用wax来表示从x<1>到隐藏层的连接,每个时间步使用的都是相同的参数Wax,而激活值也就是水平连接是由参数waa决定的,同时每一个时间步都使用相同的参数waa,同样的,输出结果由wya决定。在这个循环神经网络中,它的意思是在预测y<3>时,不就要使用x<3>的信息,还要使用来自x<1>和x<2>的信息。因为来自x<1>的信息可以通过这样的路径来帮助预测y<3>。这个循环神经网络的一个缺点就是,它只使用了这个序列中之前的信息来做出预测,尤其,当预测y<3>时它没有用到x<4>,x<5>,x<6>等等的信息,所以这就有一个问题。所以这个特定的神经网络结构的一个限制是它在某一个时刻的预测仅使用了从序列中之前的输入信息并没有使用序列中后部分的信息。双向循环神经网络(BRNN)可以处理这个问题。

循环神经网络前向传播(forward propagation):一般开始先输入a<0>,它是一个零向量,接着,这就是前向传播过程,循环神经网络经常选用tanh作为激活函数,有时也会用ReLu等,选用哪个激活函数是取决于你的输出y。它的公式如下:

下图是RNN前向传播的简单公式:

Backpropagation through time:如下图,反向传播的计算方向与前向传播基本上是相反的。前向传播计算:假入一个输入序列,x<1>,x<2>,x<3>,…,x<Tx>,然后用x<1>和a<0>计算出时间步(time step)的激活项a<1>,再用x<2>和a<1>计算出a<2>,然后再计算出a<3>,一直到a<Tx>。为了真正计算出a<1>,还需要一些参数,wa和ba。这些参数在之后的每个时间步都会被用到,于是继续用这些参数计算出a<2>,a<3>等等。所有的这些激活项最后都要取决于参数wa和ba.有了a<1>神经网络就可以计算第一个预测输出y<1>,接着到下一个时间步继续计算出y<2>,y<3>等等一直到y<Ty>。为了计算y,你需要参数wy和by,它们被用于y的所有节点。然后为了计算反向传播,还需要一个损失函数,如标准logistic回归损失函数,也叫交叉熵(cross entropy)损失函数。通过y<1>可以计算对应的损失函数,即第一个时间步的损失函数L<1>,第二个时间步的损失函数L<2>,一直到最后一个时间步的损失函数L<Ty>。最后为了计算出总体的损失函数要把它们都加起来。然后通过公式计算出最后的L。反向传播算法需要在相反的方向上进行计算和传递。在这之后你就可以计算出所有合适的量,然后就可以通过导数相关的参数用梯度下降法来更新参数。

不同类型的循环神经网络:如下图,(1). 多对多结构(many-to-many architecture):因为输入序列有很多的输入而输出序列也有很多输出。(2). 多对一结构(many-to-one architecture):因为它有很多的输入,然后输出一个数字。(3). 一对一结构(one-to-one architecture):类似于一个小型的标准的神经网络,输入x然后得到输出y。(4). 一对多结构:如音乐生成。多对多结构可以是输入和输出长度是不同的,如机器翻译。

Language model and sequence generation: 用RNN构建一个语言模型。什么是语言模型,如下图,一个好的语音识别系统能够识别出非常相似的两句话。语言识别系统使用一个语言模型计算出相似的两句话各自的可能性,比如概率值,某个特定的句子出现的概率是多少。语言模型所做的基本工作就是:输入一个句子,准确地说是一个文本序列,y<1>,y<2>,一直到y<Ty>,然后语言模型会估计某个句子序列中各个单词出现的可能性。

如何建立一个语言模型:如下图,为了使用RNN建立出这样的模型,首先需要一个训练集,包含一个很大的英文文本语料库,或者其它的你想用于构建模型的语言的语料库,语料库(word corpus)是自然语言处理(NLP)的一个专有名词,意思就是很长的或者说数量众多的英文句子组成的文本。比如你在训练集中得到这么一句话,Cats average 15 hours of sleep a day,你要做的第一件事就是将这个句子标记化,意思就是建立一个字典,然后将每个单词都转换成对应的one-hot向量,也就是字典中的索引,可能还有一件事就是你要定义句子的结尾,一般的做法就是增加一个额外的标记叫做EOS,它表示句子的结尾。这样能够帮你搞清楚一个句子什么时候结束。EOS标记可以被附加到训练集中每一个句子的结尾,这样你可以使你的模型能够准确识别句子的结尾。在标记化的过程中,你可以自己决定要不要把标点符号看成是标记。下图中忽略标点符号。如果你的训练集中有一些词并不在你的字典中,此时可以把不在字典中的词替换成一个叫做UNK的代表未知词的标志。我们只针对UNK建立概率模型而不针对这个具体的词。完成标志化的过程后,这意味着将输入的句子都映射到了各个标志上或者说字典中的各个词上。

下一步,我们要建立一个RNN来构建这些序列的概率模型。如下图,在第0个时间步,你要计算激活项a<1>,它是以x<1>作为输入的函数,而x<1>会被设为全为0的集合,也就是0向量,在之前的a<0>按照惯例也设为0向量,于是a<1>要做的就是通过softmax进行一些预测来计算出第一个词可能会是什么,其结果就是y<1>,这一步其实就是通过softmax层来预测字典中的任意单词,会是第一个词的概率,所以y<1>的输出是softmax的计算结果,它只是预测第一个词的概率,而不去管结果是什么。如果字典大小是10000,那么softmax层可能输出10000种结果,也有可能是10002种结果,因为你还可能加上了未知词和句子结尾这两个额外的标志。然后RNN进入下一个时间步,在下一个时间步中,使用激活项a<2>,在这步要做的是计算出第二词会是什么,现在依然传给它正确的第一个词,我们会告诉它第一个词就是Cats,也就是y<1>,这就是为什么x<2>=y<1>,然后在第二个时间步中,输出结果同样经过softmax层进行预测。然后再进行RNN的下一个时间步,现在要计算a<3>,为了预测第3个词,我们现在给它前两个词,告诉它Cats average是句子的前两个词,所以这个输入x<3>=y<2>,现在要计算序列中下一个词是什么。以此类推,一直到最后第9个时间步,然后把x<9>=y<8>,它会输出y<9>,最后得到的结果会是EOS标志。所以RNN中的每一步都会考虑前面得到的单词,比如给它前3个单词,让它给出下个词的分布,这就是RNN如何学习,从左到右每次预测一个词。接下来,为了训练这个网络,我们要定义代价函数(cost function)。

Sampling novel sequences(对新序列采样):在你训练一个序列模型之后,要想了解这个模型学到了什么,一种非正式的方法就是进行一次新序列采样。如下图,一个序列模型模拟了任意特定单词序列的概率。我们所要做的就是对这个概率分布进行采样来生成一个新的单词序列。为了进行采样,第一步要做的就是对你想要模型生成的第一个词进行采样。于是你输入x<1>=0,a<0>=0,现在你的第一个时间步得到的是所有可能的输出,是经过softmax层后得到的概率,然后根据这个softmax的分布进行随机采样。softmax分布给你的信息就是第一个词是a的概率是多少,第一个词是aaron的概率是多少,等等,还有第一个词是未知标志的概率是多少。根据向量中这些概率的分布进行采样,这样就能对第一个词进行采样得到y’<1>。然后继续下一个时间步,第二个时间步需要y<1>作为输入,而现在要做的是把刚刚采样得到的y’<1>作为第二个时间步的输入,然后sotfmax层就会预测y’<2>是什么。然后再到下一个时间步,无论你得到什么样的选择结果都把它传递到下一个时间步,一直这样直到最后一个时间步。这就是你如何从你的RNN语言模型中生成一个随机选择的句子。以上是基于词汇的RNN模型,意思就是字典中的词都是英语单词。

根据你实际的需要,你还可以构建一个基于字符的RNN模型。在这种情况下,你的字典仅包含从a到z的字母,可能还会有空格符,还可以有数字0到9,如果想区分大小写字母,还可以再加上大写的字母,还可以看看实际训练集中可能会出现的字符,然后用这些字符组成你的字典。如果你建立一个基于字符的语言模型比起基于词汇的语言模型,你的序列y<1>,y<2>,y<3>等在训练数据中都将是单独的字符而不是单独的词汇。自然语言处理的趋势都是基于词汇的语言模型。
Vanishing gradients(梯度消失) with RNNs:基本的RNN算法会存在梯度消失的问题。以语言模型为例,如下图,基本的RNN不擅长处理长期依赖(long-term dependencies)的问题。如果出现梯度爆炸的问题(导数值很大或出现了NaN)一个解决方法就是用梯度修剪(gradient clipping)。梯度修剪的意思就是观察你的梯度向量,如果它大于某个阈值就缩放梯度向量,保证它不会太大。

Gated Recurrent Unit(GRU,门控循环单元):GRU改变了RNN的隐藏层,使其可以更好地捕捉深层连接并改善了梯度消失问题,如下图:

LSTM(long short term memory) unit:LSTM有时比GRU更有效。LSTM比GRU出现的早。GRU的优点是模型更加简单,更容易创建一个更大的网络,它只有两个门,在计算性上,也运行的更快,它可以扩大模型的规模。但是LSTM更加强大和灵活,它有三个门而不是两个。GRU和LSTM的主要公式如下图:

Bidirectional(双向) RNN:这个模型可以让你序列的某点处不仅可以获取之前的信息还可以获取未来的信息。如下图,给定一个输入序列x<1>到x<4>,这个序列首先计算前向的a<1>,然后计算前向的a<2>,接着a<3>,a<4>。而反向序列,从a<4>开始,反向进行,计算反向的a<3>,计算完了反向的a<3>后可以用这些激活值计算反向的a<2>, 然后是反向的a<1>.把所有的这些激活值都计算完了,就可以预测计算结果了。比如时间步3的预测结果,信息从x<1>过来,流经前向的a<1>到前向的a<2>,到前向的a<3>,再到y<3>,所以从x<1>,x<2>,x<3>来的信息都会考虑在内。而从x<4>来的信息,会流过反向的a<4>,到反向的a<3>再到y<3>,这样使得时间步3的预测结果不仅输入了过去的信息还有现在的信息。这一步涉及了前向和反向的传播信息以及未来的信息。这就是双向循环神经网络,并且这些基本单元不仅仅是标准的RNN单元也可以是GRU单元或LSTM单元。这个双向RNN网络模型的缺点是你需要完整的数据的序列你才能预测任意位置。比如说,你要构建一个语音识别系统,那么双向RNN模型需要你考虑整个语音表达,但是如果直接用这个去实现的话,你需要等待这个人说完,然后获取整个语音表达才能处理这段语音并进一步做语音识别。

Deep RNNs:深层神经网络,如下图,用a[l]<t>来表示第t个时间点第l层的激活值:

GitHub: https://github.com/fengbingchun/NN_Test
相关文章:

周伯文对话斯坦福AI实验室负责人:下一个NLP前沿是什么?
出品 | AI科技大本营(ID:rgznai100)10 月 31 日,在北京智源大会上,京东集团副总裁兼人工智能事业部总裁、智源-京东联合实验室主任周伯文,斯坦福人工智能实验室负责人(SAIL)Christopher Manning…
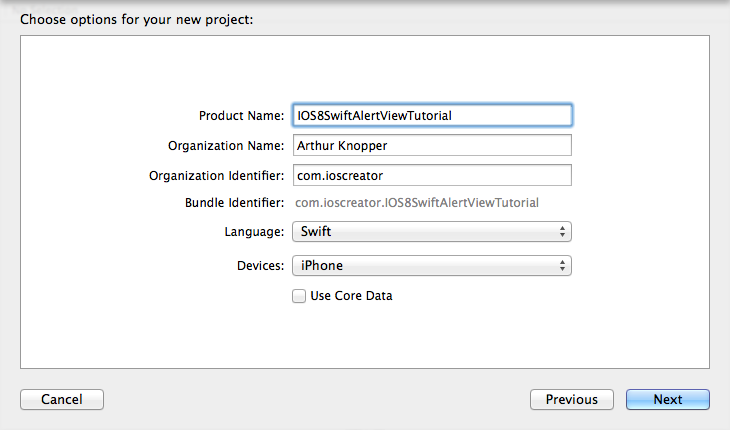
IOS8中SWIFT 弹出框的显示
弹出框不管是在网页端,还是在手机APP端,都是常用的控件.在网页中实现个简单的弹出框只需要调用alert,在IOS中,也不是那么复杂,也是容易使用的. 我先用xcode6创建一个名为iOS8SwiftAlertViewTutorial,设置好相关的信息. 在Storyboard中调整好视图显示方式 拖动一个按钮到主视图…

Maven学习笔记(二) :Maven的安装与配置
在Windows上安装Maven: 1. 首先检查安装JDK通过命令行运行命令:echo %JAVA_HOME%和java -version,能够查看当前java的安装文件夹及java的版本号,maven要求JDK的版本号必须在1.4以上。2. 下载Maven前往maven的下载页面:http://ma…

swift闭包
其实闭包就是函数 作为条件的函数 闭包表达式 首先声明一个数组 <code class"hljs cs has-numbering" style"display: block; padding: 0px; background-color: transparent; color: inherit; box-sizing: border-box; font-family: Source Code Pro, mono…
吴恩达老师深度学习视频课笔记:自然语言处理与词嵌入
Word representation:词嵌入(word embedding),是语言表示的一种方式,可以让算法自动理解一些类似的词比如男人、女人,国王、王后等。通过词嵌入的概念,即使你的模型标记的训练集相对较小,也可以构建NLP(自然…
高文院士:为什么中国的AI发展必须要有开源开放平台?
出品 | AI科技大本营(ID:rgznai100)10 月 31 日,由北京智源人工智能研究院主办的 2019 北京智源大会在国家会议中心开幕,本次大会围绕人工智能基础研究现状及面临的机遇和挑战、人工智能技术未来发展的核心方向等话题,…
libcurl断点下载遇到的问题
最近游戏把资源(图片、配置、lua)的加载、更新全部改了 ,加载其实还好,就是不走之前的zip解压方式。 以前的大体流程: 下载 –> 启动 –> 解压 –> 更新 –> 进入游戏 现在的大体流程: 下载 –…

sqlite3数据的使用(xcode 7,ios9)
由于考虑将来还要开发Android版本app,为了移植方便,所以使用了sqlite3来做数据持久化,到时候把sql语句拷过去还能用。 1、 首先用xcode载入sqlite3类库 选择工程的TARGETS-build phases-link binary with libraries,点击“”按钮&…

吴恩达老师深度学习视频课笔记:序列模型和注意力机制
基础模型:比如你想通过输入一个法语句子来将它翻译成一个英语句子,如下图,seq2seq模型,用x<1>一直到x<5>来表示输入句子的单词,然后我们用y<1>到y<6>来表示输出的句子的单词,如何训…

七个开发者成就百亿市值公司?这个技术思路如今让阿里发扬光大
2015年,马云带领阿里巴巴集团的高管拜访了位于芬兰游戏公司supercell 这家公司开发出了《部落战争》、《皇室战争》、《海岛奇兵》等App端知名游戏图片来自多玩BBS社区但是,这么知名的游戏公司开发团队当时却不足7人!整个团队好像cell一样&am…
Linux学习笔记之文件管理和目录管理类命令
在开始理解Linux文件管理和目录类命令之前,有必要先说一下,关于操作系统在计算机中都做了哪些工作。0、操作系统的工作1、文件管理,增删改查2、目录管理3、进程管理4、软件安装5、运行程序6、网络管理7、设备管理本次笔记介绍的是文件管理和目…
张钹、朱松纯、黄铁军等同台激辩:人工智能的“能”与“不能”
整理 | AI科技大本营编辑部出品 | AI科技大本营(ID:rgznai100)10 月 31 日,由北京智源人工智能研究院主办的 2019 北京智源大会在国家会议中心开幕,本次大会吸引了国际人工智能领域的顶级专家学者参加,围绕人工智能基础…
ssqlit3.0数据库使用方法
由于考虑将来还要开发Android版本app,为了移植方便,所以使用了sqlite3来做数据持久化,到时候把sql语句拷过去还能用。 1、 首先用xcode载入sqlite3类库 选择工程的TARGETS-build phases-link binary with libraries,点击“”按钮&…

GCC中通过--wrap选项使用包装函数
在使用GCC编译器时,如果不想工程使用系统的库函数,例如在自己的工程中可以根据选项来控制是否使用系统中提供的malloc/free, new/delete函数,可以有两种方法: (1). 使用LD_PRELOAD环境变量:可以设置共享库的路径&…
[原]对Linux环境下任务调度一点认识
我一直以来有一个误解,那就是在终端运行某个程序时,按下Ctrl D时我误以为就是杀死了这个进程,今天才知道原来不是。比如我利用libevent在Linux环境下写了一个网络监听程序,当启动程序之后,就会一直监听本地的6789端口…

决策树的C++实现(CART)
关于决策树的介绍可以参考: https://blog.csdn.net/fengbingchun/article/details/78880934 CART算法的决策树的Python实现可以参考: https://blog.csdn.net/fengbingchun/article/details/78881143 这里参考 https://machinelearningmastery.com/impl…

iOS开发-由浅至深学习block
作者:Sindri的小巢(简书) 关于block 在iOS 4.0之后,block横空出世,它本身封装了一段代码并将这段代码当做变量,通过block()的方式进行回调。这不免让我们想到在C函数中,我们可以定义一个指向函数…

Google和微软分别提出分布式深度学习训练新框架:GPipe PipeDream
【进群了解最新免费公开课、技术沙龙信息】作者 | Jesus Rodriguez译者 | 陆离编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】微软和谷歌一直在致力于开发新的用于训练深度神经网络的模型,最近,谷歌和微软分别…

fragment 横竖屏 不重建
2019独角兽企业重金招聘Python工程师标准>>> android:configChanges"screenSize|orientation" 这样设置 切屏时都不会重新调用fragment里面的onCreateView了 转载于:https://my.oschina.net/u/1777508/blog/317811

二叉树简介及C++实现
二叉树是每个结点最多有两个子树的树结构,即结点的度最大为2。通常子树被称作”左子树”和”右子树”。二叉树是一个连通的无环图。 二叉树是递归定义的,其结点有左右子树之分,逻辑上二叉树有五种基本形态:(1)、空二叉树…

swift实现ios类似微信输入框跟随键盘弹出的效果
为什么要做这个效果 在聊天app,例如微信中,你会注意到一个效果,就是在你点击输入框时输入框会跟随键盘一起向上弹出,当你点击其他地方时,输入框又会跟随键盘一起向下收回,二者完全无缝连接,那么…
行人被遮挡问题怎么破?百度提出PGFA新方法,发布Occluded-DukeMTMC大型数据集 | ICCV 2019...
作者 | Jiaxu Miao、Yu Wu、Ping Liu、Yuhang Ding、Yi Yang译者 | 刘畅编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导语】在以人搜人的场景中,行人会经常被各种物体遮挡。之前的行人再识别(re-id)方法…
WinAPI: Arc - 绘制弧线
为什么80%的码农都做不了架构师?>>> //声明: Arc(DC: HDC; {设备环境句柄}X1, Y1, X2, Y2, X3, Y3, X4, Y4: Integer {四个坐标点} ): BOOL;//举例: procedure TForm1.FormPaint(Sender: TObject); constx1 10;y1 10;…

提高C++性能的编程技术笔记:跟踪实例+测试代码
当提高性能时,我们必须记住以下几点: (1). 内存不是无限大的。虚拟内存系统使得内存看起来是无限的,而事实上并非如此。 (2). 内存访问开销不是均衡的。对缓存、主内存和磁盘的访问开销不在同一个数量级之上。 (3). 我们的程序没有专用的CPUÿ…
2019年不可错过的45个AI开源工具,你想要的都在这里
整理 | Jane 出品 | AI科技大本营(ID:rgznai100)一个好工具,能提高开发效率,优化项目研发过程,无论是企业还是开发者个人都在寻求适合自己的开发工具。但是,选择正确的工具并不容易,有时这甚至是…

swift中delegate与block的反向传值
swift.jpg入门级 此处只简单举例并不深究,深究我也深究不来。对于初学者来说delegate或block都不是一下子能理解的,所以我的建议和体会就是,理不理解咱先不说,我先把这个格式记住,对就是格式,delegate或blo…
Direct2D (15) : 剪辑
为什么80%的码农都做不了架构师?>>> 绘制在 RenderTarget.PushAxisAlignedClip() 与 RenderTarget.PopAxisAlignedClip() 之间的内容将被指定的矩形剪辑。 uses Direct2D, D2D1;procedure TForm1.FormPaint(Sender: TObject); varcvs: TDirect2DCanvas;…

女朋友啥时候怒了?Keras识别面部表情挽救你的膝盖
作者 | 叶圣出品 | AI科技大本营(ID:rgznai100)【导读】随着计算机和AI新技术及其涉及自然科学的飞速发展,整个社会上的管理系统高度大大提升,人们对类似人与人之间的交流日渐疲劳而希望有机器的理解。计算机系统和机械人如果需要…
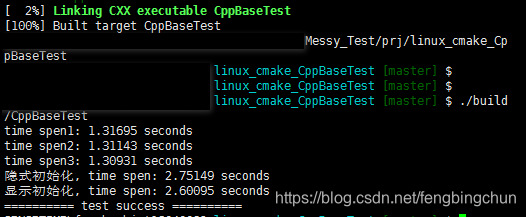
提高C++性能的编程技术笔记:构造函数和析构函数+测试代码
对象的创建和销毁往往会造成性能的损失。在继承层次中,对象的创建将引起其先辈的创建。对象的销毁也是如此。其次,对象相关的开销与对象本身的派生链的长度和复杂性相关。所创建的对象(以及其后销毁的对象)的数量与派生的复杂度成正比。 并不是说继承根…
swim 中一行代码解决收回键盘
//点击空白收回键盘 override func touchesBegan(touches: Set<UITouch>, withEvent event: UIEvent?) { view.endEditing(true) }