关于Spark NLP学习,你需要掌握的LightPipeline(附代码)| CSDN博文精选
作者 | Veysel Kocaman, Data Scientist & ML Researcher ANKIT CHOUDHARY
翻译 | 赵春光
校对 | 申利彬
来源 | 数据派THU
(*点击阅读原文,查看作者更多精彩文章)
【导读】Pipeline具体来说是一个多阶段的序列,每个阶段由一个Transformer或者Estimator组成。各个阶段按顺序执行,并将输入的DataFrame转换和传递给下一个阶段。数据如此按序的在pipeline中传递。我们现在再来看看Spark NLP是如何使用Annotator和Transformer的。
本文是Spark NLP Library中各annotator系列中的第2篇文章,介绍Spark NLP中是如何使用Annotator和Transformer。如果你想更多的学习Spark NLP及对应的概念,请先阅读下述文章:
Introduction to Spark NLP: Foundations and Basic Components (Part-I)https://medium.com/spark-nlp/introduction-to-spark-nlp-foundations-and-basic-components-part-i-c83b7629ed59
本文主要是作为上篇文章的延续。
在机器学习中,常见的一种做法是运行一系列的算法来处理和学习数据。这种算法序列常被称作做Pipeline。
Pipeline具体来说是一个多阶段的序列,每个阶段由一个Transformer或者Estimator组成。各个阶段按顺序执行,并将输入的DataFrame转换和传递给下一个阶段,数据如此按序的在pipeline中传递。每个阶段的transform()方法函数更新这组数据集并传递到下一阶段。因为有了pipeline,训练数据和测试数据会通过确保一致的特征处理环节。
每个使用的annotator 会在pipeline中的这个data frame新添一列。
我们现在来看一下Spark NLP是如果使用Annotator和Transformer完成上述过程。假如我们需要将如下几个环节逐一施加在data frame上:
文本分离成语句
分词
正交化
得到词嵌入向量
下面是通过Spark NLP实现这个pipeline的代码:
1from pyspark.ml import Pipeline23document_assembler = DocumentAssembler()\ .setInputCol(“text”)\ .setOutputCol(“document”)45sentenceDetector = SentenceDetector()\ .setInputCols([“document”])\ .setOutputCol(“sentences”)67tokenizer = Tokenizer() \ .setInputCols([“sentences”]) \ .setOutputCol(“token”)89normalizer = Normalizer()\ .setInputCols([“token”])\ .setOutputCol(“normal”)
10
11word_embeddings=WordEmbeddingsModel.pretrained()\ .setInputCols([“document”,”normal”])\ .setOutputCol(“embeddings”)
12
13nlpPipeline = Pipeline(stages=[ document_assembler, sentenceDetector, tokenizer, normalizer, word_embeddings, ])
14
15pipelineModel = nlpPipeline.fit(df)接下来我们加载了一组数据到这个pipeline中,看一下模型如何工作。
Dataframe样本(5452行)
然后运行上述pipeline,我们会得到一个训练好的模型。之后我们用它转换整个DataFrame。
1result = pipelineModel.transform(df)
2result.show()转换前20行数据用了501毫秒;转换整个data frame共用了11秒。
1%%timeresult = pipelineModel.transform(df).collect()
2>>>CPU times: user 2.01 s, sys: 425 ms, total: 2.43 s
3Wall time: 11 s如果我们想把这个pipeline保存到硬盘,然后调用它转换一行文字,在线转换时间会多长呢?
1from pyspark.sql import Row
2text = "How did serfdom develop in and then leave Russia ?"
3line_df = spark.createDataFrame(list(map(lambda x: Row(text=x), [text])), ["text"])
4%time result = pipelineModel.transform(line_df).collect()
5
6>>>CPU times: user 31.1 ms, sys: 7.73 ms, total: 38.9 msWall time: 515 ms转换一行短文字的时间也是515毫秒!几乎是和之前转换20行的时间一致。所以说,效果太好。实际上,类似的情况也发生在使用分布式处理小数据的时候。分布式处理和云计算主要是用来处理大数据,而使用Spark来处理小型数据其实是杀鸡用牛刀。
实际上,由于它内部的机制和优化后的构架,Spark仍适用于中等大小单机可处理的数据。但不建议使用Spark来处理仅仅是几行的数据, 除非使用Spark NLP。
打个比方,Spark 好像一个火车和一个自行车赛跑。自行车会在轻载的时候占上风,因为它更敏捷、提速更快,而重载的火车可能需要一段时间提速,但最终还是会速度更快。
所以,如果我们想要预测的时间更快该怎么办呢?使用LightPipeline。
LightPipeline
LightPipelines 是Spark NLP对应的Pipeline, 等同于Spark ML Pipeline, 但是用于处理更小的数据。它们适用于小数据集、调试结果,或者是对一次性服务API请求的训练或预测。
Spark NLP LightPipelines 是将Spark ML Pipelines 转换成了一个单机但多线程的任务,对于小型数据(不大于5万个句子)速度会提升10倍。
这些Pipeline的使用方法是插入已训练(已拟合)的模型,然后会标注纯文本。我们都不需要把输入文字转换成Dataframe就可以输入pipeline,虽然pipeline当初是使用Dataframe作为输入。这个便捷的功能适用于使用已训练的模型对少数几行文字进行预测。
1from sparknlp.base import LightPipeline
2LightPipeline(someTrainedPipeline).annotate(someStringOrArray)下面是一些LightPipelines可用的方法函数。我们还可以用字符列表作为输入文字。
https://nlp.johnsnowlabs.com/api/#com.johnsnowlabs.nlp.LightPipeline
我们可以很方便的创建LightPipelines,也不需要处理Spark Datasets。LightPipelines运行的也很快,而且在驱动节点工作时可执行并行运算。下面是一个应用的例子:
1from sparknlp.base import LightPipeline2lightModel = LightPipeline(pipelineModel, parse_embeddings=True)3%time lightModel.annotate("How did serfdom develop in and then leave Russia ?")4>>>5CPU times: user 12.4 ms, sys: 3.81 ms, total: 16.3 ms6Wall time: 28.3 ms7{'sentences': ['How did serfdom develop in and then leave Russia ?'],8 'document': ['How did serfdom develop in and then leave Russia ?'],9 'normal': ['How',
10 'did',
11 'serfdom',
12 'develop',
13 'in',
14 'and',
15 'then',
16 'leave',
17 'Russia'],
18 'token': ['How',
19 'did',
20 'serfdom',
21 'develop',
22 'in',
23 'and',
24 'then',
25 'leave',
26 'Russia',
27 '?'],
28 'embeddings': ['-0.23769 0.59392 0.58697 -0.041788 -0.86803 -0.0051122 -0.4493 -0.027985, ...]}
29这个代码用了28毫秒!几乎是使用Spark ML Pipeline时的20倍速度。
上面可以看出,annotate只返回了result的属性。既然这个嵌入向量数组储存在embedding属性的WordEmbeddingModel标注器下,我们可以设置parse_embedding = True 来分析嵌入向量数据。否则,我们可能在输出中只能获得嵌入向量的分词属性。关于上述属性的更多信息见以下连接:
https://medium.com/spark-nlp/spark-nlp-101-document-assembler-500018f5f6b5
如果我们想获取标注的全部信息,我们还可以使用fullAnnotate()来返回整个标注内容的字典列表。
1result = lightModel.fullAnnotate("How did serfdom develop in and then leave Russia ?")2>>>3[{'sentences': [<sparknlp.base.Annotation at 0x139d685c0>],4 'document': [<sparknlp.base.Annotation at 0x149b5a320>],5 'normal': [<sparknlp.base.Annotation at 0x139d9e940>,6 <sparknlp.base.Annotation at 0x139d64860>,7 <sparknlp.base.Annotation at 0x139d689b0>,8 <sparknlp.base.Annotation at 0x139dd16d8>,9 <sparknlp.base.Annotation at 0x139dd1c88>,
10 <sparknlp.base.Annotation at 0x139d681d0>,
11 <sparknlp.base.Annotation at 0x139d89128>,
12 <sparknlp.base.Annotation at 0x139da44a8>,
13 <sparknlp.base.Annotation at 0x139da4f98>],
14 'token': [<sparknlp.base.Annotation at 0x149b55400>,
15 <sparknlp.base.Annotation at 0x139dd1668>,
16 <sparknlp.base.Annotation at 0x139dad358>,
17 <sparknlp.base.Annotation at 0x139d8dba8>,
18 <sparknlp.base.Annotation at 0x139d89710>,
19 <sparknlp.base.Annotation at 0x139da4208>,
20 <sparknlp.base.Annotation at 0x139db2f98>,
21 <sparknlp.base.Annotation at 0x139da4240>,
22 <sparknlp.base.Annotation at 0x149b55470>,
23 <sparknlp.base.Annotation at 0x139dad198>],
24 'embeddings': [<sparknlp.base.Annotation at 0x139dad208>,
25 <sparknlp.base.Annotation at 0x139d89898>,
26 <sparknlp.base.Annotation at 0x139db2860>,
27 <sparknlp.base.Annotation at 0x139dbbf28>,
28 <sparknlp.base.Annotation at 0x139dbb3c8>,
29 <sparknlp.base.Annotation at 0x139db2208>,
30 <sparknlp.base.Annotation at 0x139da4668>,
31 <sparknlp.base.Annotation at 0x139dd1ba8>,
32 <sparknlp.base.Annotation at 0x139d9e400>]}]fullAnnotate()返回标注类型中的内容和元数据。根据参考文档,这个标定类型有如下属性:
参考文档:https://nlp.johnsnowlabs.com/api/#com.johnsnowlabs.nlp.Annotation
1annotatorType: String,
2begin: Int,
3end: Int,
4result: String, (this is what annotate returns)
5metadata: Map[String, String],
6embeddings: Array[Float]所以,下面的代码可以返回一个句子的起始或者结束:
1result[0]['sentences'][0].begin
2>> 0
3result[0]['sentences'][0].end
4>> 49
5result[0]['sentences'][0].result
6>> 'How did serfdom develop in and then leave Russia ?'嵌入向量每个分词的的元数据也可以得到:
1result[0]['embeddings'][2].metadata
2>> {'isOOV': 'false',
3 'pieceId': '-1',
4 'isWordStart': 'true',
5 'token': 'serfdom',
6 'sentence': '0'}不过我们还没能从LightPipeline得到non-Spark NLP标注器的信息。例如当需要在pipeline中同时使用Spark ML 的功能(如work2vec)和Spark NLP时, LightPipeline只返回Spark NLP annotations 的结果,但不会有没有任何Spark ML models的域输出。所以可以说LightPipeline不会返回Spark NLP标注器以外的任何结果,至少当前如此。
我们计划近期给Spark NLP写一个wrapper,用于兼容的 Spark ML 的所有ML模型。此后大家就可以使用LightPipeline来完成机器学习的案例,来在Spark NLP中训练模型,然后部署实现更快的在线预测。
结语
Spark NLP LightPipelines 是把 Spark ML pipelines转换成了一个单机但多线程的任务,在少量的数据上速度提升可达到10倍。本文讨论了如何将Spark Pipelines转换成Spark NLP Light Pipelines,以便在小数据上获得更快的响应。这也是Spark NLP的最酷的特征之一。我们可以享受Spark强大的数据处理和训练功能,然而在单机运行时使用Light Pipelines来获得更快的预测速度。
希望大家已经渡过上一篇关于official Medium page的文章了,并开始用到Spark NLP。下面是一些相关文章的连接,不要忘记关注我们的主页!
Introduction to Spark NLP: Foundations and Basic Components (Part-I)
https://medium.com/spark-nlp/introduction-to-spark-nlp-foundations-and-basic-components-part-i-c83b7629ed59
Introduction to: Spark NLP: Installation and Getting Started (Part-II)
https://medium.com/spark-nlp/introduction-to-spark-nlp-installation-and-getting-started-part-ii-d009f7a177f3?source=collection_home---6------0-----------------------
Spark NLP 101 : Document Assembler
https://medium.com/spark-nlp/spark-nlp-101-document-assembler-500018f5f6b5
原文标题:
Spark NLP 101: LightPipeline
原文链接:
https://www.kdnuggets.com/2019/11/spark-nlp-101-lightpipeline.html
编辑 | 黄继彦
校对 | 林亦霖
技术的道路一个人走着极为艰难?
一身的本领得不施展?
优质的文章得不到曝光?
别担心,
即刻起,CSDN 将为你带来创新创造创变展现的大舞台,
扫描下方二维码,欢迎加入 CSDN 「原力计划」!
(*本文为AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
点击阅读原文,或扫描文首贴片二维码
所有CSDN 用户都可参与投票和抽奖活动
加入福利群,每周还有精选学习资料、技术图书等福利发送
推荐阅读
“一百万行Python代码对任何人都足够了”
GitHub标星1.5w+,从此我只用这款全能高速下载工具
中国工程师在美遭抢劫电脑遇害,数百人悼念
跟风 Google 只是东施效颦?!
召回→排序→重排:技术演进趋势的深度之旅,2020 必备!
如何写出让同事膜拜的漂亮代码?
同样是写代码,你和大神究竟差在哪里?
互联网公司=21世纪的国营大厂
详解CPU几个重点基础知识
DeFi行业2019全年呈爆炸式增长,8.5亿美元资产锁定在DeFi生态中;行业市值主要由头部项目瓜分 | 报告
你点的每个“在看”,我都认真当成了AI
相关文章:

网络编程--ftp客户端的实现(c#版)
.net2.0对ftp有了一个很好的封装,但是确容易让人忽略ftp的真正内部实现,下面是我实现的ftp客户端的功能,其主要步骤是这样的:1、创建一个FtpWebRequest对象,指向ftp服务器的uri 2、设置ftp的执行方法(上传,下载等) 3、给FtpWebReq…

Windows客户端C/C++编程规范“建议”——文件
7 文件 7.1 正确使用#include 等级:【推荐】 说明:#include <>和#include “”导致编译器在搜索文件时,搜索的路径顺序不同。所以需要正确使用#include,以避免包含错了头文件。 语法形式操作带引号的形式预处理器按以下…

让你的网站支持 Emoji
SegmentFault有用户提出要支持Emoji表情输入,就研究了一下: 要记得备份数据库。 首先Mysql数据库在5.5.3之后开始支持utf8mb4字符集,所以mysql版本是5.5.3+的都可以设置让数据库存储Emoji表情,如果你的应用有移动端的&…

Windows客户端C/C++编程规范“建议”——变量和常量
8 变量和常量 8.1 尽量不要使用全局变量 等级: 【要求】说明:全局变量的滥用和goto的滥用一样,都是一种灾难。它将使得逻辑变得难以调试和控制。8.2 不涉及外部使用的全局变量需要使用static关键字修饰 等级: 【要求】说明&#…
机器学习模型五花八门不知道怎么选?这份指南告诉你
作者 | LAVANYA译者 | 陆离编辑 | 夕颜出品 | AI科技大本营(ID: rgznai100)【导读】在本文中,我们将探讨不同的机器学习模型,以及每个模型合理的使用场景。一般来说,基于树形结构的模型在Kaggle竞赛中是表现最好的&…

WinAPI: FlattenPath、WidenPath
不管什么曲线命令, 到来路径中都会变成 Bezier 线; 也就是说路径中只有直线和 Bezier 线.FlattenPath 和 WidenPath 都能够把路径中的 Bezier 线转换为近似的直线; 不同的是: 用 WidenPath 转换后貌似加宽了线, 其实它是转换成了一个包围路径的新路径(类似区域).本例效果图:代码…

Android - 小的特点 - 使用最新版本ShareSDK手册分享(分享自己定义的接口)
前太实用Share SDK很快分享,但官员demo快捷共享接口已被设置死,该公司的产品还设计了自己的份额接口,这需要我手动共享。 读了一堆公文,最终写出来,行,废话,进入主题。 之前没实用过ShareSDK分享…
结合Flink,国内自研,大规模实时动态认知图谱平台——AbutionGraph |博文精选
作者 | Raini出品 | 北京图特摩斯科技 (www.thutmose.cn)(*点击阅读原文,查看作者更多精彩文章)Flink:目前最受关注的大数据技术,最活跃 Apache 项目之一。AbutionGraph:北京图特摩斯科技自研的…
Windows客户端C/C++编程规范“建议”——风格
9 风格 9.1 优先使用匈牙利命名法 等级: 【推荐】说明:该方法由微软总设计师设计。Windows上编程最好遵从该标准。详细介绍见:http://zh.wikipedia.org/wiki/%E5%8C%88%E7%89%99%E5%88%A9%E5%91%BD%E5%90%8D%E6%B3%959.2 变量名结合使用匈牙…
使用GIF(仅限Delphi2007)
-----------uses GIFImg; procedure TForm1.FormCreate(Sender: TObject); begin // 先在窗体上放一个 TImage 组件:Image1; Image1.Picture.LoadFromFile(C:\Example.gif); // AnimationSpeed 设定动画速度,值越大,速度越快…
使用Depth Texture
使用Depth Textures: 可以将depth信息渲染到一张texture,有些效果的制作会需要scene depth信息,此时depth texture就可以派上用场了。 Depth Texture在不同平台上有不同的实现,并且原生的支持也不一样。 UnityCG.cgin…
Exchage 2007 Client Application Functions(2) -- 如何收取邮件
上一篇介绍的Exchange2007客户端程序中怎么发送邮件。现在,我来简单介绍一下怎么收取邮件。来看代码:publicHashtable GetAllMails(DateTime StartDate, DateTime EndDate) { try { if (null this.m_esb) …
VC开发Windows客户端软件之旅——前言
从第一次拖着行李入京找活,至今已工作若干年了。这些年一直追逐自己的梦想,跑过三个城市,换了三份工作,认识了很多业内的朋友。和朋友们闲聊时,发现很多人都已经不再做客户端软件了。有的转去做管理,有的转…
代替Mask R-CNN,BlendMask欲做实例预测任务的新基准?
「免费学习 60 节公开课:投票页面,点击讲师头像」作者 | Hao Chen、Kunyang Sun、Zhi Tian、Chunhua Shen、Yongming Huang、Youliang Yan译者 | 刘畅编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】实例分割是…
如何让ie 7 支持box-shadow
box-shadow是一个很好用并且也常用的css 3属性,但是,如果我们要保证它能在ie 8及更低的版本下运行的话,需要借助一些其他的插件或文件。在这里我主要讲一下,如何用PIE.htc来解决ie 7不支持box-shadow。 代码如下: <…
拥有AI「变声术」,秒杀了多年苦练的模仿艺能
「免费学习 60 节公开课:投票页面,点击讲师头像」作者 | Daniel Chen,爱奇艺资深研发工程师 出品 | AI科技大本营(ID:rgznai100)【导读】什么是Voice Conversion(VC)?它有…

服务器架设笔记——编译Apache及其插件
之前一直从事Windows上的客户端软件开发,经常会处理和服务器交互相关的业务。由于希望成为一个全栈式的工程师,我对Linux上服务器相关的开发也越来越感兴趣。趁着年底自由的时间比较多,我可以对这块做些技术研究。虽然这些知识很基础也很老&a…

Silverlight 2中多语言支持实现(上)
引言 最近项目要在Silverlight 2应用程序中实现本地化,原以为这个过程非常简单,却没想到实现的时候一波三折,好在结果还算不错。需求是这样的,用户第一次访问的时候,默认为英文,当用户选择一种显示语言后&a…
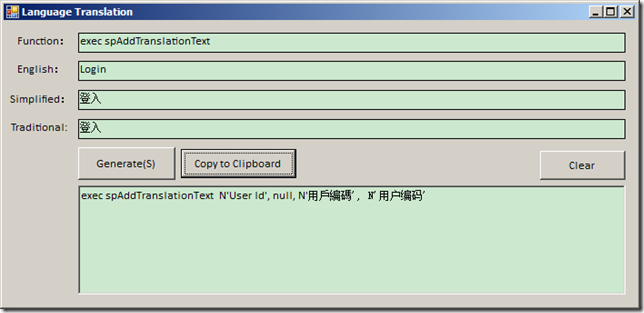
解析大型.NET ERP系统 多国语言实现
实现多国语言有许多种实现方案,无外乎是一种字符串替换技术,将界面控件的文本标签替换成相应语言的文字。.NET Windows Forms实现多国语言的方法有以下几种: 1 .NET的方案,使用资源文件 分别做三个语言的资源文件,比如…
服务器架设笔记——Apache模块开发基础知识
通过上节的例子,我们发现Apache插件开发的一个门槛便是学习它自成体系的一套API。虽然Apache的官网上有对这些API的详细介绍,但是空拿着一些零散的说明书,是很难快速建立起一套可以运行的系统。(转载请指明出于breaksoftware的csd…
解密Elasticsearch技术,腾讯开源的万亿级分布式搜索分析引擎
「免费学习 60 节公开课:投票页面,点击讲师头像」作者 | johngqjiang,腾讯 TEG 云架构平台部研发工程师来源 | 腾讯技术工程(ID:Tencent_TEG)【导读】Elasticsearch(ES)作为开源首选…
Centos5上firefox的升级
Centos5上firefox的升级默认Centos5上firefox的版本是1.5当我们使用yum update firefox提示到的版本还是1.5 可是我们在使用1.5版本的firefox可能会有一些问题,比如打不开QQ空间接下来我们就将系统的firefox从rpm包的1.5版本升级到tar包的3.0首先删除1.5版本的fire…

cheat engine lua
function CEButton1Click(sender) local x getProperty(CETrainer.CEEdit1,"Text")--这句很重要,获取文本框的值 --writeInteger(0x42c0c0,readInteger(0x42c0c0)x)--设置0X42C0C0地址的值 setProperty(CETrainer.CEEdit2,"Text","0001000")--设…
服务器架设笔记——使用Apache插件解析简单请求
一般来说,对于一个请求,服务器都会对其进行解析,以确定请求的合法性以及行进的路径。于是本节将讲解如何获取请求的数据。(转载请指明出于breaksoftware的csdn博客) 我们使用《服务器架设笔记——编译Apache及其插件》…
如何用Python快速抓取Google搜索?
「免费学习 60 节公开课:投票页面,点击讲师头像」作者 | linksc译者 | 弯月,编辑 | 郭芮来源 | CSDN(ID:CSDNnews)自从2011年 Google Web Search API 被弃用以来,我一直在寻找其他的方法来抓取G…
利用歌词插件 让WMP活起来
如果利用起这个歌词插件的话 是不是可以减少下载那么多播放器和每次更新的烦恼呢?因为WMP是系统自带的.可以下载的插件名称:Wa3 Music Engine 或者乐辞的歌词秀插件转载于:https://blog.51cto.com/david25/84211
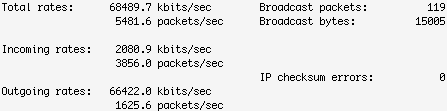
Linux性能研究(总)
http://www.vpsee.com/2009/11/linux-system-performance-monitoring-introduction/ http://www.jb51.net/LINUXjishu/34607.html 公司有个测试服务器,上面跑了几个应用和一个DB。 DB被这个几个应用使用。 最近老是被挂掉。 CPU 使用率100%。 搞到最后大家都不能用。…
万字干货:如何从零开始构建企业级推荐系统?
「免费学习 60 节公开课:投票页面,点击讲师头像」作者丨gongyouliu编辑丨zandy来源 | 大数据与人工智能(ID: ai-big-data)最近几个月有很多人咨询作者怎么从零开始搭建工业级推荐系统,有做音视频的、有做新闻资讯的、有…

Mocha BSM基础架构管理——灵活的网络拓扑展现
业务需求与挑战企业的网络拓扑结构与设备时常变化,人工往往难以维护网络拓扑。尤其对于上千台设备的大型网络来说情况更为复杂。当用户网络设备大量增加后,网络结构异常复杂,用户的网络拓扑很难在一个屏幕上展现或者很难找到要查阅的网络拓扑…

服务器架设笔记——打通MySQL和Apache
在《服务器架设笔记——使用Apache插件解析简单请求》一文中,我们已经可以获取请求内容。这只是万里长征的第一步。因为一般来说,客户端向服务器发起请求,服务器会有着复杂的业务处理逻辑。举个例子,大部分客户端软件都有日志模块…