服务器架设笔记——使用Apache插件解析简单请求
一般来说,对于一个请求,服务器都会对其进行解析,以确定请求的合法性以及行进的路径。于是本节将讲解如何获取请求的数据。(转载请指明出于breaksoftware的csdn博客)
我们使用《服务器架设笔记——编译Apache及其插件》一文中的方法创建一个Handler工程——get_request。该工程中,我们可以操作的入口函数是
static int get_request_handler(request_rec *r)
{r->content_type = "text/html"; 通过该入口函数,我们可以直接得到的数据就是request_rec结构体对象指针r。通过查阅源码,我们得到其定义
/*** @brief A structure that represents the current request*/
struct request_rec {/** The pool associated with the request */apr_pool_t *pool;/** The connection to the client */conn_rec *connection;/** The virtual host for this request */server_rec *server;/** Pointer to the redirected request if this is an external redirect */request_rec *next;/** Pointer to the previous request if this is an internal redirect */request_rec *prev;/** Pointer to the main request if this is a sub-request* (see http_request.h) */request_rec *main;/* Info about the request itself... we begin with stuff that only* protocol.c should ever touch...*//** First line of request */char *the_request;/** HTTP/0.9, "simple" request (e.g. GET /foo\n w/no headers) */int assbackwards;/** A proxy request (calculated during post_read_request/translate_name)* possible values PROXYREQ_NONE, PROXYREQ_PROXY, PROXYREQ_REVERSE,* PROXYREQ_RESPONSE*/int proxyreq;/** HEAD request, as opposed to GET */int header_only;/** Protocol version number of protocol; 1.1 = 1001 */int proto_num;/** Protocol string, as given to us, or HTTP/0.9 */char *protocol;/** Host, as set by full URI or Host: */const char *hostname;/** Time when the request started */apr_time_t request_time;/** Status line, if set by script */const char *status_line;/** Status line */int status;/* Request method, two ways; also, protocol, etc.. Outside of protocol.c,* look, but don't touch.*//** M_GET, M_POST, etc. */int method_number;/** Request method (eg. GET, HEAD, POST, etc.) */const char *method;/*** 'allowed' is a bitvector of the allowed methods.** A handler must ensure that the request method is one that* it is capable of handling. Generally modules should DECLINE* any request methods they do not handle. Prior to aborting the* handler like this the handler should set r->allowed to the list* of methods that it is willing to handle. This bitvector is used* to construct the "Allow:" header required for OPTIONS requests,* and HTTP_METHOD_NOT_ALLOWED and HTTP_NOT_IMPLEMENTED status codes.** Since the default_handler deals with OPTIONS, all modules can* usually decline to deal with OPTIONS. TRACE is always allowed,* modules don't need to set it explicitly.** Since the default_handler will always handle a GET, a* module which does *not* implement GET should probably return* HTTP_METHOD_NOT_ALLOWED. Unfortunately this means that a Script GET* handler can't be installed by mod_actions.*/apr_int64_t allowed;/** Array of extension methods */apr_array_header_t *allowed_xmethods;/** List of allowed methods */ap_method_list_t *allowed_methods;/** byte count in stream is for body */apr_off_t sent_bodyct;/** body byte count, for easy access */apr_off_t bytes_sent;/** Last modified time of the requested resource */apr_time_t mtime;/* HTTP/1.1 connection-level features *//** The Range: header */const char *range;/** The "real" content length */apr_off_t clength;/** sending chunked transfer-coding */int chunked;/** Method for reading the request body* (eg. REQUEST_CHUNKED_ERROR, REQUEST_NO_BODY,* REQUEST_CHUNKED_DECHUNK, etc...) */int read_body;/** reading chunked transfer-coding */int read_chunked;/** is client waiting for a 100 response? */unsigned expecting_100;/** The optional kept body of the request. */apr_bucket_brigade *kept_body;/** For ap_body_to_table(): parsed body *//* XXX: ap_body_to_table has been removed. Remove body_table too or* XXX: keep it to reintroduce ap_body_to_table without major bump? */apr_table_t *body_table;/** Remaining bytes left to read from the request body */apr_off_t remaining;/** Number of bytes that have been read from the request body */apr_off_t read_length;/* MIME header environments, in and out. Also, an array containing* environment variables to be passed to subprocesses, so people can* write modules to add to that environment.** The difference between headers_out and err_headers_out is that the* latter are printed even on error, and persist across internal redirects* (so the headers printed for ErrorDocument handlers will have them).** The 'notes' apr_table_t is for notes from one module to another, with no* other set purpose in mind...*//** MIME header environment from the request */apr_table_t *headers_in;/** MIME header environment for the response */apr_table_t *headers_out;/** MIME header environment for the response, printed even on errors and* persist across internal redirects */apr_table_t *err_headers_out;/** Array of environment variables to be used for sub processes */apr_table_t *subprocess_env;/** Notes from one module to another */apr_table_t *notes;/* content_type, handler, content_encoding, and all content_languages* MUST be lowercased strings. They may be pointers to static strings;* they should not be modified in place.*//** The content-type for the current request */const char *content_type; /* Break these out --- we dispatch on 'em *//** The handler string that we use to call a handler function */const char *handler; /* What we *really* dispatch on *//** How to encode the data */const char *content_encoding;/** Array of strings representing the content languages */apr_array_header_t *content_languages;/** variant list validator (if negotiated) */char *vlist_validator;/** If an authentication check was made, this gets set to the user name. */char *user;/** If an authentication check was made, this gets set to the auth type. */char *ap_auth_type;/* What object is being requested (either directly, or via include* or content-negotiation mapping).*//** The URI without any parsing performed */char *unparsed_uri;/** The path portion of the URI, or "/" if no path provided */char *uri;/** The filename on disk corresponding to this response */char *filename;/* XXX: What does this mean? Please define "canonicalize" -aaron *//** The true filename, we canonicalize r->filename if these don't match */char *canonical_filename;/** The PATH_INFO extracted from this request */char *path_info;/** The QUERY_ARGS extracted from this request */char *args;/*** Flag for the handler to accept or reject path_info on* the current request. All modules should respect the* AP_REQ_ACCEPT_PATH_INFO and AP_REQ_REJECT_PATH_INFO* values, while AP_REQ_DEFAULT_PATH_INFO indicates they* may follow existing conventions. This is set to the* user's preference upon HOOK_VERY_FIRST of the fixups.*/int used_path_info;/** A flag to determine if the eos bucket has been sent yet */int eos_sent;/* Various other config info which may change with .htaccess files* These are config vectors, with one void* pointer for each module* (the thing pointed to being the module's business).*//** Options set in config files, etc. */struct ap_conf_vector_t *per_dir_config;/** Notes on *this* request */struct ap_conf_vector_t *request_config;/** Optional request log level configuration. Will usually point* to a server or per_dir config, i.e. must be copied before* modifying */const struct ap_logconf *log;/** Id to identify request in access and error log. Set when the first* error log entry for this request is generated.*/const char *log_id;/*** A linked list of the .htaccess configuration directives* accessed by this request.* N.B. always add to the head of the list, _never_ to the end.* that way, a sub request's list can (temporarily) point to a parent's list*/const struct htaccess_result *htaccess;/** A list of output filters to be used for this request */struct ap_filter_t *output_filters;/** A list of input filters to be used for this request */struct ap_filter_t *input_filters;/** A list of protocol level output filters to be used for this* request */struct ap_filter_t *proto_output_filters;/** A list of protocol level input filters to be used for this* request */struct ap_filter_t *proto_input_filters;/** This response can not be cached */int no_cache;/** There is no local copy of this response */int no_local_copy;/** Mutex protect callbacks registered with ap_mpm_register_timed_callback* from being run before the original handler finishes running*/apr_thread_mutex_t *invoke_mtx;/** A struct containing the components of URI */apr_uri_t parsed_uri;/** finfo.protection (st_mode) set to zero if no such file */apr_finfo_t finfo;/** remote address information from conn_rec, can be overridden if* necessary by a module.* This is the address that originated the request.*/apr_sockaddr_t *useragent_addr;char *useragent_ip;/** MIME trailer environment from the request */apr_table_t *trailers_in;/** MIME trailer environment from the response */apr_table_t *trailers_out;
};这是个非常大的结构体,可谓是包罗万象。对于初学者来说,想完全弄明白各项是什么还是比较困难的。而我们的需求很简单,我们就列出我们可能需要关心的数据
/** First line of request */char *the_request;请求的第一行数据
/** Protocol version number of protocol; 1.1 = 1001 */int proto_num;/** Protocol string, as given to us, or HTTP/0.9 */char *protocol;/** Host, as set by full URI or Host: */const char *hostname;协议的版本和请求的类型
/** Time when the request started */apr_time_t request_time;请求的时间
/** The URI without any parsing performed */char *unparsed_uri;/** The path portion of the URI, or "/" if no path provided */char *uri;/** The filename on disk corresponding to this response */char *filename;未进行urldecode的URI、经过urldecode的URI和处理该请求的文件路径
/** The PATH_INFO extracted from this request */char *path_info;/** The QUERY_ARGS extracted from this request */char *args;请求中的路径和参数
/** A struct containing the components of URI */apr_uri_t parsed_uri;请求解析的详细结果
char *useragent_ip;请求来源的IP
/** MIME header environment from the request */apr_table_t *headers_in;以table形式保存的http头信息
对于基础数据类型我们很容易编写出例程
if (r->the_request) {ap_rprintf(r, "the request : %s\n", r->the_request);}else {ap_rprintf(r, "the request is NULL\n");}if (r->protocol) {ap_rprintf(r, "protocol : %s\n", r->protocol);}else {ap_rprintf(r, "protocol is NULL\n");}ap_rprintf(r, "proto_num is %d\n", r->proto_num);而对于请求时间apr_time_t类型,我们可以参考《服务器架设笔记——Apache模块开发基础知识》中对模块的介绍。我们查看源码,可以编写出如下例程
static void print_time(request_rec* r) {if (!r) {ap_rprintf(r, "request_rec pointer is NULL\n");return;}char data_str[128] = {0};apr_status_t status = apr_ctime(data_str, r->request_time);if (APR_SUCCESS != status) {ap_rprintf(r, "apr_ctime error\n"); }else {ap_rprintf(r, "ctime\t:\t%s\n", data_str);}apr_time_exp_t exp_t;memset(&exp_t, 0, sizeof(exp_t));status = apr_time_exp_gmt(&exp_t, r->request_time);if (APR_SUCCESS != status) {ap_rprintf(r, "apr_time_exp_gmt error\n");}else {ap_rprintf(r, "exp time\t:\n");ap_rprintf(r, "\ttm_usec\t:\t%d\n", exp_t.tm_usec);ap_rprintf(r, "\ttm_sec\t:\t%d\n", exp_t.tm_sec);ap_rprintf(r, "\ttm_min\t:\t%d\n", exp_t.tm_min);ap_rprintf(r, "\ttm_hour\t:\t%d\n", exp_t.tm_hour);ap_rprintf(r, "\ttm_mday\t:\t%d\n", exp_t.tm_mday);ap_rprintf(r, "\ttm_mon\t:\t%d\n", exp_t.tm_mon);ap_rprintf(r, "\ttm_year\t:\t%d\n", exp_t.tm_year);ap_rprintf(r, "\ttm_wday\t:\t%d\n", exp_t.tm_wday);ap_rprintf(r, "\ttm_yday\t:\t%d\n", exp_t.tm_yday);ap_rprintf(r, "\ttm_isdst\t:\t%d\n", exp_t.tm_isdst);ap_rprintf(r, "\ttm_gmtoff\t:\t%d\n", exp_t.tm_gmtoff);}
}其中apr_time_exp_t的定义在《apr_time.h》中。
/*** a structure similar to ANSI struct tm with the following differences:* - tm_usec isn't an ANSI field* - tm_gmtoff isn't an ANSI field (it's a BSDism)*/
struct apr_time_exp_t {/** microseconds past tm_sec */apr_int32_t tm_usec;/** (0-61) seconds past tm_min */apr_int32_t tm_sec;/** (0-59) minutes past tm_hour */apr_int32_t tm_min;/** (0-23) hours past midnight */apr_int32_t tm_hour;/** (1-31) day of the month */apr_int32_t tm_mday;/** (0-11) month of the year */apr_int32_t tm_mon;/** year since 1900 */apr_int32_t tm_year;/** (0-6) days since Sunday */apr_int32_t tm_wday;/** (0-365) days since January 1 */apr_int32_t tm_yday;/** daylight saving time */apr_int32_t tm_isdst;/** seconds east of UTC */apr_int32_t tm_gmtoff;
};对于已分析过了的请求结构体apr_uri_t的例程也非常简单,我就不再列出来,只是把其结构体定义贴一下。大家一看就明白
/*** A structure to encompass all of the fields in a uri*/
struct apr_uri_t {/** scheme ("http"/"ftp"/...) */char *scheme;/** combined [user[:password]\@]host[:port] */char *hostinfo;/** user name, as in http://user:passwd\@host:port/ */char *user;/** password, as in http://user:passwd\@host:port/ */char *password;/** hostname from URI (or from Host: header) */char *hostname;/** port string (integer representation is in "port") */char *port_str;/** the request path (or NULL if only scheme://host was given) */char *path;/** Everything after a '?' in the path, if present */char *query;/** Trailing "#fragment" string, if present */char *fragment;/** structure returned from gethostbyname() */struct hostent *hostent;/** The port number, numeric, valid only if port_str != NULL */apr_port_t port;/** has the structure been initialized */unsigned is_initialized:1;/** has the DNS been looked up yet */unsigned dns_looked_up:1;/** has the dns been resolved yet */unsigned dns_resolved:1;
};这些例程中麻烦的是对apr_table_t的解析。因为网上很难找到对该table的遍历代码,于是我只能参考apr_table_clone中代码得出如下
static void print_table(request_rec *r, const apr_table_t* t) {const apr_array_header_t* array = apr_table_elts(t);apr_table_entry_t* elts = (apr_table_entry_t*)array->elts;for (int i = 0; i < array->nelts; i++) {ap_rprintf(r, "\t%s : %s\n", elts[i].key, elts[i].val);}
}我们请求一个URL:http://192.168.191.129/AP%26AC%3aHE?a=b#c
其返回如下
headers_in startHost : 192.168.191.129Connection : keep-aliveCache-Control : max-age=0Accept : text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8User-Agent : Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.72 Safari/537.36Accept-Encoding : gzip,deflate,sdchAccept-Language : zh-CN,zh;q=0.8
headers_in endheaders_out start
headers_out endthe request : GET /AP%26AC%3aHE?a=b HTTP/1.1
protocol : HTTP/1.1
proto_num is 1001
method : GET
host name : 192.168.191.129
unparsed uri : /AP%26AC%3aHE?a=b
uri : /AP&AC:HE
filename : /usr/local/apache2/htdocs/AP&AC:HE
path info :
args : a=b
user is NULL
log id is NULL
useragent ip : 192.168.191.1
ctime : Mon Feb 16 18:20:39 2015
exp time :tm_usec : 200039tm_sec : 39tm_min : 20tm_hour : 10tm_mday : 16tm_mon : 1tm_year : 115tm_wday : 1tm_yday : 46tm_isdst : 0tm_gmtoff : 0
scheme is NULL
hostinfo is NULL
user is NULL
password is NULL
hostname is NULL
port_str is NULL
path : /AP&AC:HE
query : a=b
fragment is NULL
The sample page from mod_get_request.c相关文章:
如何用Python快速抓取Google搜索?
「免费学习 60 节公开课:投票页面,点击讲师头像」作者 | linksc译者 | 弯月,编辑 | 郭芮来源 | CSDN(ID:CSDNnews)自从2011年 Google Web Search API 被弃用以来,我一直在寻找其他的方法来抓取G…

利用歌词插件 让WMP活起来
如果利用起这个歌词插件的话 是不是可以减少下载那么多播放器和每次更新的烦恼呢?因为WMP是系统自带的.可以下载的插件名称:Wa3 Music Engine 或者乐辞的歌词秀插件转载于:https://blog.51cto.com/david25/84211
Linux性能研究(总)
http://www.vpsee.com/2009/11/linux-system-performance-monitoring-introduction/ http://www.jb51.net/LINUXjishu/34607.html 公司有个测试服务器,上面跑了几个应用和一个DB。 DB被这个几个应用使用。 最近老是被挂掉。 CPU 使用率100%。 搞到最后大家都不能用。…
万字干货:如何从零开始构建企业级推荐系统?
「免费学习 60 节公开课:投票页面,点击讲师头像」作者丨gongyouliu编辑丨zandy来源 | 大数据与人工智能(ID: ai-big-data)最近几个月有很多人咨询作者怎么从零开始搭建工业级推荐系统,有做音视频的、有做新闻资讯的、有…

Mocha BSM基础架构管理——灵活的网络拓扑展现
业务需求与挑战企业的网络拓扑结构与设备时常变化,人工往往难以维护网络拓扑。尤其对于上千台设备的大型网络来说情况更为复杂。当用户网络设备大量增加后,网络结构异常复杂,用户的网络拓扑很难在一个屏幕上展现或者很难找到要查阅的网络拓扑…

服务器架设笔记——打通MySQL和Apache
在《服务器架设笔记——使用Apache插件解析简单请求》一文中,我们已经可以获取请求内容。这只是万里长征的第一步。因为一般来说,客户端向服务器发起请求,服务器会有着复杂的业务处理逻辑。举个例子,大部分客户端软件都有日志模块…
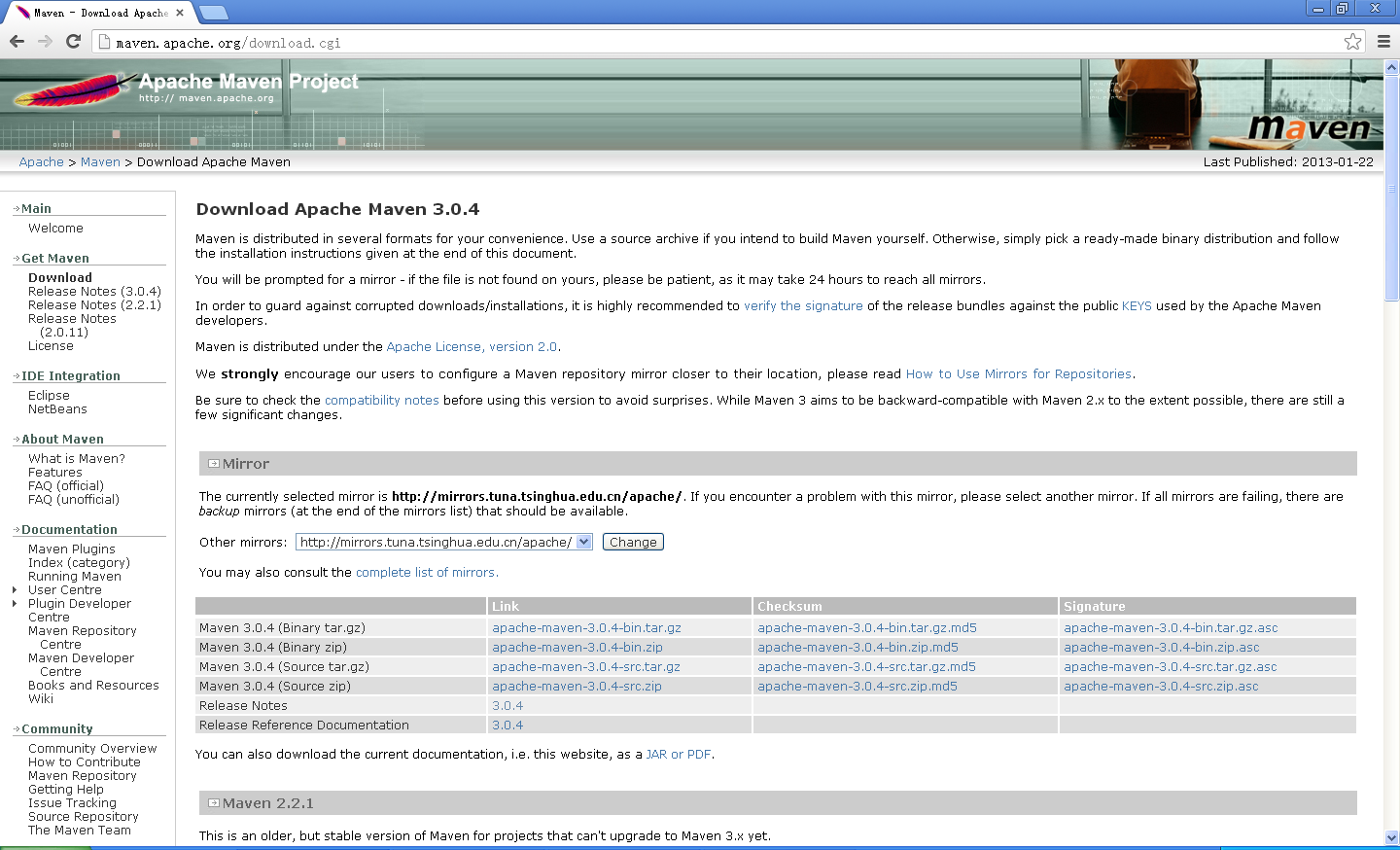
【Maven】maven的安装配置和ecplise结合
2. Maven的安装和配置 2.1. 安装 进入Maven官网的下载页面:http://maven.apache.org/download.cgi,如下图所示: 选择当前最新版本:“apache-maven-3.0.4-bin.zip”,下载到本地,解压缩到本地磁盘D:下。 2…
2020年趋势一览:AutoML、联邦学习、云寡头时代的终结
作者 | Roberto Sannazzaro,Ben Longstaff译者 | 夕颜出品 | AI科技大本营(ID:rgznai100) 【导读】在 2020 年来临之际,新年前夕往往是人们回顾过去一年并展望来年的好时机。本文将深入探讨了关于 AI 的技术和非技术方面的趋势&am…

使用C++实现一套简单的状态机模型——实例
一般来说,“状态机”是一种表达状态转换变换逻辑的方法。曾经有人和我讨论过为什么不直接用ifelse,而要使用“状态机”去实现一些逻辑,认为使用“状态机”是一种炫技的表现。然而对于大型复杂逻辑的变化和跳转,使用ifelse将带来代…
net通过oledb 和ibm自带连接方式,连接db2数据库出错
第一种通过ibm方式连接 DataSet ds new DataSet(); OleDbConnection cn new OleDbConnection( "ProviderIBMDA400.1;Data Source192.168.21.10;User IDb4dd;" "Passwordb4dd;Default CollectionQIBMPP"); …
SAP QM 'QM System' 有什么控制作用?
SAP QM ‘QM System’ 有什么控制作用? QM system可以控制如下二点: 1>如果我方与Vendor的质量标准匹配,且相互认证,那么我方收货后不用检验,系统不产生检验批;如果我方与vendor的质量标准匹配&#x…
使用C++实现一套简单的状态机模型——原理解析
在上一文中,我们介绍了该状态机模型的使用方法。通过例子,我们发现可以使用该模型快速构建满足基本业务需求的状态机。本文我们将解析该模型的基础代码,以便大家可以根据自己状态机特点进行修改。(转载请指明出于breaksoftware的c…
干货:NIST评测(SRE19)获胜团队声纹识别技术分析 | CSDN博文精选
作者 | xjdier来源 | CSDN博文精选(*点击阅读原文,查看作者更多精彩文章)近日,NIST说话人识别技术评测 (Speaker Recognition Evaluation,SRE)正式公布榜单,芯片初创公司清微智能和清华大学等机构组成的联队…
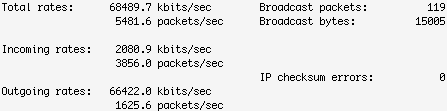
网络系统传输负载测试
网络系统传输负载测试 随着企业各种信息系统相继投入使用,生产、管理信息逐步增加,企业网络规模迅速扩大,信息城域网承受着空前的压力,网络带宽严重不足,网络系统传输丢包、设备死机情况频频发生。我们需要对网络状况做…

android圆形旋转菜单,而对于移动转换功能支持
LZ该公司最近接手一个项目,需要写一个圆形旋转菜单,和菜单之间的移动换位支持,我本来以为这样的demo如若互联网是非常。想想你妈妈也帮不了我,空旋转,但它不能改变位置,所以LZ我们只能靠自己摸索。 最后LZ参…
微信9年:张小龙指明方向,微信AI全面开放NLP能力
作者 | 夕颜责编 | 王金许出品 | AI科技大本营(ID:rgznai100)一年一度的微信公开课 Pro 在广州保利世贸博览馆如期举行。一大早,同在博览馆举办的广州年货促展会参会者,夹杂着参加腾讯公开课的与会者,让这里变得人流攒…

实现HTTP协议Get、Post和文件上传功能——使用WinHttp接口实现
在《使用WinHttp接口实现HTTP协议Get、Post和文件上传功能》一文中,我已经比较详细地讲解了如何使用WinHttp接口实现各种协议。在最近的代码梳理中,我觉得Post和文件上传模块可以得到简化,于是几乎重写了这两个功能的代码。因为Get、Post和文…
第一篇文章,做个纪念
第一篇文章,做个纪念,这个blog好吗?拭目以待!转载于:https://blog.51cto.com/197536/88241

Maven工程引入jar包(转)
Maven项目引入jar包的方法,希望能帮助有需要的朋友们 法一.手动导入:项目右键—>Build Path—>Configure Build Path—>选中Libraries—>点击Add External Jars—>选中已事先下好的Jar包导入即可。 法二.通过pom.xml文件的Dependencies标…
实现HTTP协议Get、Post和文件上传功能——使用libcurl接口实现
之前我们已经详细介绍了WinHttp接口如何实现Http的相关功能。本文我将主要讲解如何使用libcurl库去实现相关功能。(转载请指明出于breaksoftware的csdn博客) libcurl在http://curl.haxx.se/libcurl/有详细的介绍,有兴趣的朋友可以去读下。本文…
32岁程序员,补偿N+2:“谢谢裁我,让我翻倍!” 网友:榜样!
2019年的冬天,“冷”的有些频繁。12月19日,《马蜂窝被曝裁员40% UGC模式变现难?》爆火,据悉马蜂窝将裁员40%,交易中心成了“重灾区”,赔偿N2,留下的除搜索推荐、内容中心等核心部门外࿰…
山有木兮木有枝,心悦君兮君不知
《越人歌》今夕何夕兮,搴舟中流。 今日何日兮,得与王子同舟 蒙羞被好兮,不訾诟耻 心几烦而不绝兮,得知王子 山有木兮木有枝,心悦君兮君不知。本是《夜宴》中的,"山有木兮木有枝,心悦君兮君…
浅析电商、社区、游戏常用的 MySQL 架构
一般、或者必须是这样、MySQL 架构一定要结合业务来分析、设计、优化 所以不管是那种架构、根据业务要求组合成符合需求的即是最好的、不能泛泛而谈 同时、也必须注意数据的安全(如ipsec,ssh,vpn传输) 常见的架构都是进行业务切…
基于Co-Attention和Co-Excitation的少样本目标检测 | NeurIPS 2019
「免费学习 60 节公开课:投票页面,点击讲师头像」作者 | VincentLee来源 | 晓飞的算法工程笔记(ID: gh_084c810bc839)导读:论文提出CoAE少样本目标检测算法,该算法使用non-local block来提取目标图片与查询…

服务器架设笔记——搭建用户注册和验证功能
之前介绍的Apache Httpd相关内容,都是些零散的知识点。而实际运用中,我们要根据不同的业务,将这些知识点连接起来以形成各种组合,来满足我们的需求。(转载请指明出于breaksoftware的csdn博客) 本文我将以用…

项目管理过程中应注意的问题
软件项目从角色分工方面可以划分为研发、开发和实施三类,每个类型的项目有各自的管理过程。下面笔者就公司实施类项目的经历,从项目经理的角度谈一谈实施类项目管理过程中应该注意的一些问题,希望大家共勉。确定项目概况俗话说:“…

原创jQuery移动设备弹出框插件——msgalert.js
最近开发经常会用到顶部弹出框,虽然有现成的(bootstrap等),但是都很臃肿,对于有些时候移动端活动页面有点大材小用。所以今晚花了20分钟写了一个通用的插件,我将其命名为msgalert.js。因为定位是jQuery插件,…
AbutionGraph:构建以知识图谱为核心的下一代数据中台
「免费学习 60 节公开课:投票页面,点击讲师头像」作者 | 图特摩斯科技创始人闭雨哲出品 | AI科技大本营(ID:rgznai100)前言图特摩斯科技(Thutmose)基于自研的图形数据库AbutionGraph(实时多维数…
服务器架设笔记——多模块和全局数据
随着项目工程的发展,多模块设计和性能优化是在所难免的。本文我将基于一些现实中可能遇到的需求,讲解如何在Apache的Httpd插件体系中实现这些功能。(转载请指明出于breaksoftware的csdn博客) 之前我碰到两个需求: 需要…
JSP学习笔记(七):使用JavaBean
bean.java publicclassB1 { publicString getString() { return"content"; } }page.jsp <%B1 b1 newB1(); out.print(b1.getString());%>