通过 Python 代码实现时间序列数据的统计学预测模型
来源 | DeepHub IMBA
封图 | CSDN 付费下载于视觉中国
在本篇中,我们将展示使用 Python 统计学模型进行时间序列数据分析。 目标是:根据两年以上的每日广告支出历史数据,提前预测两个月的广告支出金额。
原始数据:2017-01-01 到 2019-09-23 期间的每日广告支出。
数据准备:划分训练集和测试集。
df1 = data[['Date','Spend']].set_index('Date') train = df1.iloc[:933,:]test = df1.iloc[933:,:] test.shape,train.shape
测试集大小:(63,1);训练集大小:(933,1)。
统计模型与统计要素
时间序列分析常用统计模型
单变量时间序列统计学模型,如:平均方法、平滑方法、有/无季节性条件的 ARIMA 模型。
多变量时间序列统计学模型,如:外生回归变量、VAR。
附加或组件模型,如:Facebook Prophet、ETS。
结构化时间序列模型,如:贝叶斯结构化时间序列模型、分层时间序列模型。
在本篇文章中,我们主要关注 SARIMA 和 Holt-winters 方法。
单变量时间序列统计学模型的关键要素
如果我们想要对时间序列数据进行上述统计学模型分析,需要进行一系列处理使得:
(1)数据均值
(2)数据方差
(3)数据自协方差
这三个指标不依赖于时间项。即时间序列数据具有平稳性。
如何明确时间序列数据是否具有平稳性?
可以从两个特征进行判断。
(1) 趋势,即均值随时间变化;
(2) 季节性,即方差随时间变化、自协方差随时间变化。
若满足以上两个条件,则时间序列数据不符合平稳性要求。
可以通过以下方法消除上述问题:
变换,如:取对数、取平方等。
平滑处理,如:移动平均等。
差分。
分解。
多项式拟合,如:拟合回归。
ARIMA:差分整合移动平均自回归模型
Autoregressive Integrated Moving Average model (ARIMA),差分整合移动平均自回归模型。ARIMA(p,d,q)主要包含三项:
p:AR项,即自回归项(autoregression),将时间序列下一阶段描述为前一阶段数据的线性映射。
d项,即积分项(integration),时间序列的差分预处理步骤,使其满足平稳性要求
q:MA项,即移动平均项(moving average),将时间序列下一阶段描述为前一阶段数据平均过程中的残留误差的线性映射。
该模型需要指定 p d q 三项参数,并按照顺序执行。ARIMA 模型也可以用于开发 AR, MA 和 ARMA 模型。
ACF 和 PACF 图
自相关函数,autocorrelation function(ACF),描述了时间序列数据与其之后版本的相关性(如:Y(t) 与 Y(t-1) 之间的相关性)。
偏自相关函数,partial autocorrelation function(PACF),描述了各个序列的相关性。
通过 PACF 图可以确定 p
通过 ACF 图可以确定 q
SARIMA
季节性差分自回归滑动平均模型,seasonal autoregressive integrated moving averaging(SARIMA),在 ARIMA 模型的基础上进行了季节性调节。
其形式为:SARIMA(p,d,q)(P,D,Q)s,其中P,D,Q为季节参数,s为时间序列周期。
案例:通过 SARIMA 预测广告支出
首先,我们建立 test_stationarity 来检查时间序列数据的平稳性。
from statsmodels.tsa.stattools import adfuller df1=df.resample('D', how=np.mean)def test_stationarity(timeseries): rolmean = timeseries.rolling(window=30).mean() rolstd = timeseries.rolling(window=30).std() plt.figure(figsize=(14,5)) sns.despine(left=True) orig = plt.plot(timeseries, color='blue',label='Original') mean = plt.plot(rolmean, color='red', label='Rolling Mean') std = plt.plot(rolstd, color='black', label = 'Rolling Std') plt.legend(loc='best'); plt.title('Rolling Mean & Standard Deviation') plt.show()print ('<Results of Dickey-Fuller Test>') dftest = adfuller(timeseries, autolag='AIC') dfoutput = pd.Series(dftest[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])for key,value in dftest[4].items(): dfoutput['Critical Value (%s)'%key] = value print(dfoutput) test_stationarity(df1.Spend.dropna())通过 test_stationarity 函数,可以绘制移动平均值以及标准差,并且通过 Augmented Dickey-Fuller test 输出 P 值。
对比临界值(critical value)可以看到,时间序列数据时非平稳的。
首先我们试试对数变换,能不能使数据达到平稳性要求。
可以看到,利用对数变换df1[‘log_Spend’]=np.log(df1[‘Spend’]),时间序列在阈值为5%时满足平稳性要求。
接下来,我们试试差分操作:test_stationarity(df1[‘Spend’].diff(1).dropna())。
显然,通过差分操作后,效果更好,时间序列在阈值为1%时满足平稳性要求。
然后,我们就可以建立 SARIMA 模型,并且预测 2019-07-23 到 2019-09-23 这两个月间每天的广告指出。
import statsmodels.api as sm fit1 = sm.tsa.statespace.SARIMAX(train.Spend, order=(7, 1, 2), seasonal_order=(0, 1, 2, 7)).fit(use_boxcox=True) test['SARIMA'] = fit1.predict(start="2019-07-23", end="2019-09-23", dynamic=True) plt.figure(figsize=(16, 8)) plt.plot(train['Spend'], label='Train') plt.plot(test['Spend'], label='Test') plt.plot(test['SARIMA'], label='SARIMA') plt.legend(loc='best') plt.show()
现在,让我们通过从 sklearn.metrics 包导入 mean_squared_error,mean_absolute_error 函数计算 mse 和 mae 来检查这个模型的性能。结果如下:
进行数据可视化:
从 mse、mae 以及预测曲线可以看出,SARIMA 模型成功预测了时间序列变化趋势和季节性特征。但是在峰值处的表现仍旧有待提高。
ETS:指数平滑法
ETS,Exponential Smoothing
由于时间序列数据随时间变化但具有一定的随机性,我们通常希望对数据进行平滑处理。为此,我们将使用 ETS 技术,通过指数方法为过去的数据分配较少的权重。同时将时间序列数据分解为趋势(T)、季节(S)和误差(E)分量。
三种常用 ETS 方法如下:
Linear:双指数平滑;
Additive:三指数平滑;
Multiplicative:三指数平滑。
Holt-Winter 季节性预测算法
Holt-winter 季节性预测算法是一种三指数平滑方法。它包含三个主要部分:水平、趋势、季节性分量。
案例:通过 Holt-Winter 季节性预测算法预测广告支出
通过 Holt-winter 季节性预测算法预测 2019-07-23 到 2019-09-23 期间的每日广告支出,代码如下:
from statsmodels.tsa.api import ExponentialSmoothing fit1 = ExponentialSmoothing(np.asarray(train['Spend']) ,seasonal_periods=7 ,trend='add', seasonal='add').fit(use_boxcox=True)test['Holt_Winter'] = fit1.forecast(len(test)) plt.figure(figsize=(16,8)) plt.plot( train['Spend'], label='Train') plt.plot(test['Spend'], label='Test') plt.plot(test['Holt_Winter'], label='Holt_Winter') plt.legend(loc='best') plt.show()
同样,我们通过 mean_squared_error,mean_absolute_error 函数查看 mse 和 mae。
可以看到,H-W 模型同样能够预测时间序列变化趋势和季节性特征。
算法对比
通过将两种算法的预测结果进行对比,可以评价哪种方法预测能力更好。
从图中可以看出,在MSE和MAE均较低的情况下,SARIMA模型的性能略优于Holt-Winter模型。尽管这两种模式都无法完美地抓住峰谷特征,但它们仍然对企业有用。根据数据,平均每月广告支出为2百万美元以上。而这两种算法的MAE大约在6000左右。换言之,对于一家平均每月广告支出为2百万美元的企业,两个月的广告支出预测误差只在6000美元左右,这是相当可观的。
结束语
在本文中,单变量预测方法在广告支出数据上表现良好。但这些方法难以组合/合并新的信号(如事件、天气)。同时这些方法对丢失数据也非常敏感,通常不能很好地预测很长一段时间。
你还想了解深度学习技术的哪些问题,戳文末评论告诉我们,就有机会获得「AI 开发者万人大会」的在线直播门票哦!
欢迎所有开发者扫描下方二维码填写《开发者与AI大调研》,只需2分钟,便可收获价值299元的「AI开发者万人大会」在线直播门票!
推荐阅读
前百度主任架构师创业,两年融资千万美元,他说AI新药研发将迎来黄金十年
北京四环堵车引发的智能交通大构想
400 多行代码!超详细中文聊天机器人开发指南 | 原力计划
三大运营商将上线 5G 消息;苹果谷歌联手,追踪 30 亿用户;jQuery 3.5.0 发布 | 极客头条
比特币当赎金,WannaRen 勒索病毒二度来袭!
你公司的虚拟机还闲着?基于 Jenkins 和 Kubernetes 的持续集成测试实践了解一下!
从 Web 1.0到Web 3.0:详析这些年互联网的发展及未来方向
你点的每个“在看”,我都认真当成了AI
相关文章:

神色洋溢的 域名背后的故事
前短时间,我刚申请一个域名,好的顶级域名都被被人一拥而上的都强去了,我只好找那些申请好的用户买呀,这叫炒作,就是这样的抄起来的。你说平常一个也就100左右就搞定,可是现在要是到那票手里,那就…

Rust语言开发基础(六)基础语法
2019独角兽企业重金招聘Python工程师标准>>> 一、变量的定义和使用 其它常见的编程语言对变量的定义通常是通过声明类型和使用关键new来创建一个变量,但Rust不是,Rust使用关键字let。 1. 变量绑定通过let实现 fn main() { let x 5; } 2. 变量…
400 多行代码!超详细 Rasa 中文聊天机器人开发指南 | 原力计划
作者 | 无名之辈FTER责编 | 夕颜出品 | 程序人生(ID:coder_life)本文翻译自Rasa官方文档,并融合了自己的理解和项目实战,同时对文档中涉及到的技术点进行了一定程度的扩展,目的是为了更好的理解Rasa工作机制…

Linux配置SSH无密码登陆
可以使用“公钥私钥"认证的方式来进行ssh登录。 所谓 "公钥私钥"认证方式,就是首先在客户机上创建一对公钥和私钥,公钥文件:~/.ssh/id_rsa.pub; 私钥文件:~/.ssh/id_rsa 然后把公钥文件放到目标服务器…

Linux进程浏览器htop安装与使用
htop 是一个 Linux 下的交互式的进程浏览器,可以用来替换Linux下的top命令。当前具有按树状方式来查看进程,支持颜色主题,可以定制等特性。其实htop是top的加强版,增加了很多功能。 官网 http://hisham.hm/htop/ 下载地址http:/…
什么?神经网络还能求解高级数学方程?
来源 | 数据派 THU封图 | CSDN 付费下载于视觉中国 Facebook AI建立了第一个可以使用符号推理解决高级数学方程的AI系统。通过开发一种将复杂数学表达式表示为一种语言的新方法,然后将解决方案视为序列到序列的神经网络的翻译问题,我们构建了一个在解决积…
***和******
网络是一把双刃剑,它在人类社会的发展中起着越来越重要作用,但同时,网络自身的安全问题也像挥之不去的阴影时刻笼罩在人们心头。据不完全统计,全世界平均每 20秒钟就发生一起******事件,互联网上大约有20万个***网站可…

Linux监控工具dstat
dstat是一个用来替换 vmstat,iostat netstat,nfsstat和ifstat这些命令的工具, 是一个全能系统信息统计工具. 与sysstat相比, dstat拥有一个彩色的界面, 在手动观察性能状况时, 数据比较显眼容易观察; 而且dstat支持即时刷新, 譬如输入dstat 3, 即每三秒收集一次, 但最新的数据都…
9月16号晚上,Asuka有一场关于Windows 7组策略的Webcast,欢迎兄弟们来捧场
之所以选题在组策略之一块,是因为Windows 7和2008 R2对于组策略有了很大的功能上的增强,但是很多IT人员都无法意识或者去重视这一块内容,所以我将从下面这3个角度去介绍这些更新。如果您正好有时间,那不妨来技术交流一番:)直播进入…
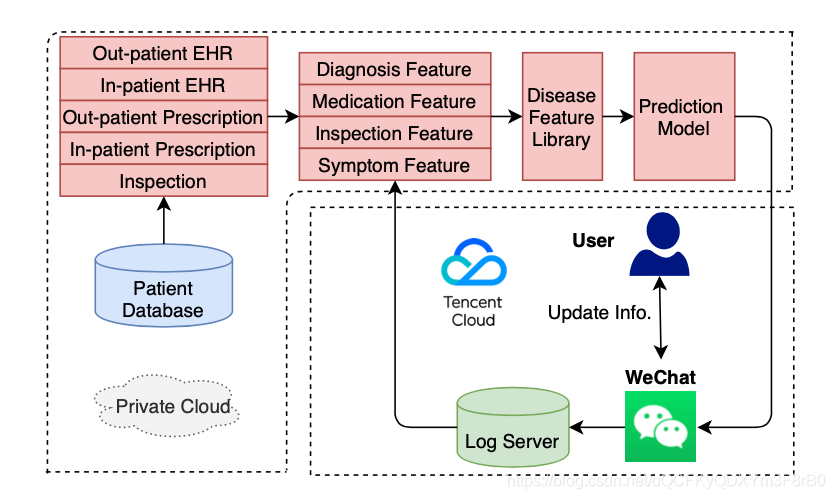
腾讯天衍实验室联合微众银行研发医疗联邦学习 AI利器让脑卒中预测准确率达80%
近几年,医疗行业正在经历一场数字化转型,这场基于大数据和AI技术的变革几乎改变了整个行业的方方面面,将“信息就是力量”这句箴言体现的淋漓尽致,人们对人工智能寄以厚望,希望它能真正深入临床一线,帮助医…
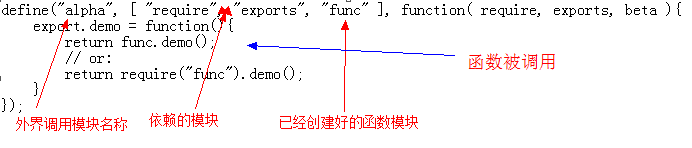
JavaSript模块化 AMD CMD 详解.....
模块化是指在解决某一个复杂问题或者一系列的杂糅问题时,依照一种分类的思维把问题进行系统性的分解以之处理。模块化是一种处理复杂系统分解为代码结构更合理,可维护性更高的可管理的模块的方式。可以想象一个巨大的系统代码,被整合优化分割…
在Eclipse中使用Maven构建Spring项目
最新版的Spring需要使用Maven构建,本文讲述怎么在Eclipse构建Maven项目,以配置Spring项目为例。 maven简单介绍 maven是构建工具,也是构建管理工具。ant只是构建工具,因为不支持生成站点功能,只有预处理,编…
Go 语言官网全新改版
2019独角兽企业重金招聘Python工程师标准>>> 前两天发现 Go 语言官网改版了,布局由原来的左中右变成了上中下结构,主色调没有变,整体依然保持简洁的风格。在首页添加了一个叫 Playground 的模块,它可以编译、运行你输入…
就在今晚 | 港科大李世玮教授问诊未来,开辟大湾区新航路
阳春三月,万象更新,2020年注定是不平凡的一年!有激荡就会遇见变革,有挑战就会迎来机遇。今天总会过去,未来将会怎样?香港科大商学院内地办事处重磅推出全新升级的《袁老师访谈录》全新系列【问诊未来院长系…
NLP(Natural Language Processing)
https://github.com/kjw0612/awesome-rnn#natural-language-processing 通常有: (1)Object Recognition (2)Visual Tracking (3)Image Generation (4)Video Analysis NLP: (1)Language Modeling (2)Speech Recognition…

Linux环境编程
1.__sync_fetch_and_add和__sync_bool_compare_and_swap gcc从4.1.2提供了__sync_*系列的built-in函数,用于提供加减和逻辑运算的原子操作。 其声明如下: type __sync_fetch_and_add (type *ptr, type value, ...) type __sync_fetch_and_sub (type *p…
AI新基建如何构建?浪潮给出了一个答案
作者 | Just出品 | AI科技大本营(ID:rgznai100)伴随生产力升级,社会基础设施也正在发生变化。而智慧时代的新型基础设施,要能够对外提供各种算力服务、数据服务和AI服务。浪潮认为,其核心是计算力的生产中心。因此&…
协作是企业管理的重点和难点
这个问题让我想起了一道数学题,11?。在生活中这个题目的答案会千差万别,更别说一个企业。在我眼中,企业中最难管的是关系,更准确的说是协作。 经理过好几个信息系统建设的项目,小到一个简单的邮件系统&…

使用CSS3美化复选框checkbox
我们知道HTML默认的复选框样式十分简陋,而以图片代替复选框的美化方式会给页面表单的处理带来麻烦,那么本文将结合实例带您一起了解一下使用CSS3将复选框checkbox进行样式美化,并且带上超酷的滑动效果。 查看演示 下载源码HTML 通常我们使用以…
Thift安装
thrift官网http://thrift.apache.org/ #wget http://mirror.bit.edu.cn/apache/thrift/0.9.2/thrift-0.9.2.tar.gz #tar -zvxf thrift-0.9.2.tar.gz # ./configure --prefix/usr/local/thrift #make && makeinstall 增加到环境变量 #export PATH$PATH:/usr/…
“手把手撕LeetCode题目,扒各种算法套路的裤子”
出品 | AI科技大本营(ID:rgznai100)刷LeetCode刷到懵还是一头雾水?莫慌,这里有一个标星27000的算法详解教程。从项目命名来看,作者labuladong就有着要干翻算法的精气神。当然,这个教程不只是为了机械刷题。…
c语言标准库低通的qsort函数不适宜所有排序任务的原因
c语言标准库低通的qsort函数不适宜所有排序任务的原因: 第一:它只能用于内存中的数组排序,不能对链表中的数据排序; 第二:因为它是参数化的函数,所以能对各种数据进行操作,也造成它的运行速度比…
第三周学习进度条
星期日 星期一 星期二 星期三 星期四 星期五 所花时间 下午: 3:00-5:00 上午: 8:00-10:00 下午: 3:00-5:00 下午: 2:30-4:30 下午: 4:30-5:30 下午࿱…

jca分析java dump日志
可以使用jca分析java dump的日志 jca:https://www.ibm.com/developerworks/community/groups/service/html/communityview?communityUuid2245aa39-fa5c-4475-b891-14c205f7333c 运维报说是某机房突然全部都线程阻塞了 其中锁住了tcp的socket,在研究无果的情况下…
shell脚本10
对于使用/bin/bash作为登录shell的系统用户,检查他们在/opt目录中拥有的子目录或文件数量,如果超过100个,则列出具体数值及对应的用户帐号.具体实现: #!/bin/bash DIR"/etc" LMT100 validusersgrep "/bin/bash" /etc/passwd|cut -d ":" -f 1 for…
百度重磅发布云手机:低配置也可玩大型游戏 21
又一个科技巨头发力云游戏。4月15日,百度举行"云手机"线上直播会,发布基于自主研发的ARM服务器的百度"云手机"产品,让用户摆脱硬件的制约,中低端设备也能流畅运行大型游戏和应用。百度"云手机"可以…

创业思维 - Qunar的故事
在这里特别想介绍下Qunar,因为他和我们的最主要的系统-交易系统相关。大家都知道淘宝的交易平台可以说是国内甚至全球最复杂的交易系统。但是我们的交易系统由于承担业务太多,发展太久,历史包裹太重,在业务架构上可以说有很大的问…
“机器学习还是很难用!”
作者 | Caleb Kaiser译者 | 香槟超新星,责编 | 郭芮出品 | CSDN(ID:CSDNnews)我是一名Cortex贡献者,Cortex是一个用于在生产中部署模型的开源平台。首先声明,以下内容是基于我对一些机器学习团队的观察总结…
silverlight 无法发布 如何灵活配置IP
灵活配置IP可以有一个工具的 我为了比赛花了 两天工具做了一个配置Silverlight IP的小工具 可以参考 http://download.csdn.net/source/2714688
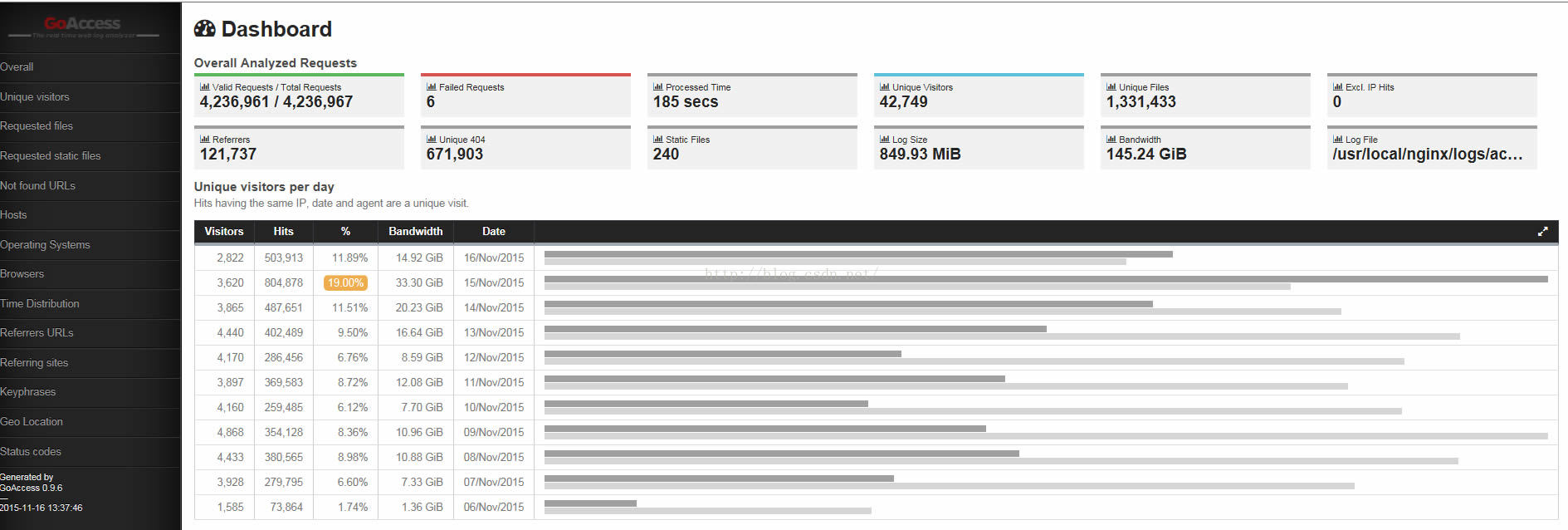
使用GoAccess分析Nginx日志
下载 GoAccess 的源代码、编译和安装: http://www.goaccess.io/download # wget http://tar.goaccess.io/goaccess-0.9.6.tar.gz# tar -xzvf goaccess-0.9.6.tar.gz# cd goaccess-0.9.6/# ./configure --prefix/usr/local/goaccess --enable-geoip --enable-utf8#…