小白也能看懂:一文学会入门推荐算法库 surprise
来源 | 机器学习与推荐系统
surprise 支持的每个算法本身思路并不复杂,代码也不晦涩难懂,我们主要的目的是理解它的架构,学习框架各个部分的交互。
这篇文章是想从一个整体的视角,以作者最初的思路为主线进行介绍,观察并思考如何一步一步的让模型 run 起来。
先搞个模型跑起来
我们首先从一个总体性的代码看一下,很简单的几行代码,开始我们的 surprise 之旅。
这里需要导入的部分,我都已经重写过了,但是大家可以在自己本地的代码上尝试一下,直接利用 surprise 库就可以运行一个简单的 KNN 算法,本质上也就是基于邻域的协同过滤算法。按照我在代码上标注出来的红线部分,分别给对应的四个 import 模块,前面加上 surpris. 的路径就可以从 surprise 中进行导入。
这里需要提一下,我用的是自己之前已经在 movielens 官网下载的数据集,大家可以自己直接下载,也可以在网上找一下教程,surprise 支持自动下载 movielens 的数据集。
接下来我们只看 surprise_code() 函数,这个函数就是我们需要学习的所有内容,从这个例子开始,我们要去一步步深扒 surprise 的执行过程。
def surprise_code():reader = Reader(line_format="user item rating", sep=',', skip_lines=1)data = Dataset.load_from_file('./ml-latest-small/ratings.csv', reader)algo = KNNBasic()perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=2, verbose=0)
for keys in perf:print(keys, ": ", perf[keys])
对核心的 surprise_code() 函数,可以分为两个部分来看:数据载入,算法执行并检测结果。
数据载入,由 Reader 和 Dataset 两个类来提供功能,具体的思路是由 Reader() 提供读取数据的格式,然后 Dataset 按照 Reader 的设置来完成对数据的载入。
算法执行并检测结果,这里由一个 cross_validate() 来完成,提前导入需要执行的算法并实例化,然后将数据,算法,要检测的指标等都传入 cross_validate(),它会完成对算法的训练拟合,然后进行预测结果,再对结果进行验证,最终返回目标的检测指标对应的结果。
所以我们可以看到直接调用接口是很容易跑起来一个模型的,仅这么几行简单的代码就可以将一个算法完整的运行起来。但是如果要深入到代码的执行细节上,就需要捋顺它们的关系,然后抽丝剥茧一点点展开。
我们可以提前将上面的算法执行并检测结果分成了两部分,也就是将整个工作流程划分为三部分:数据载入,算法设计,结果评估。这样子更加细化的一步当然没问题,逻辑上这样子也更容易理解。
现在捋顺了算法的执行思路以后,我们开始从数据集的载入开始去分析源码。
trick:在正式细节代码前,分享一些关于我学习源码的方法,不一定适合所有人,也不一定适合所有源码,仅供大家参考:
首先,要像我们一样完成一个非常简单的 demo,如这一小节的标题一样,先搞个模型跑起来。至少我们得会用它,能用起来,这样子我们才能分析下去。
其次,我们再捋顺模型的流程,划分为几个主要的部分,按照这个逻辑顺序,从最初的部分开始,尝试自己完成该模块的功能。导入自己写的部分,替代掉源码的那一部分,看看前面的 demo 能不能继续运行,检查结果是否一致。
最后,不要在分析的时候,拘泥于细节,先完成该模块的主要功能。如果这部分功能与其它模块相关,可以先导入相关的模块,直接使用。不要尝试一步将某一个模块写的尽善尽美。
这三个提到的内容,我们在接下来的文章可以再进一步体会。
从第一部分的数据载入开始
我们前面分析了数据载入部分,由 Reader 和 Dataset 两个类来提供功能。接下来要做的就是捋顺这部分内容,然后自己尝试写出来对应的模块,并且替代进去,看看我们前面的代码能不能继续正常运行。
当我们到了这一步的时候,首先就是打开这两个模块,看一看代码,了解一下它们的功能。在【第二篇文章:推荐实践(2):数据集的载入与切割】中,对这两部分的内容进行了仔细分析,我在这里就总体性的介绍一下,不深入到代码细节上去了。
reader = Reader(line_format="user item rating", sep=',', skip_lines=1)对于这个 Reader() 类,主要的功能是设置一个读取器。从 Reader 的使用也可以看出来,要求的输入是每行的格式,每行的分隔符,要忽略的行数。
从这个类实例时的输入上,我们可以判断出来,这个 Reader() 类的作用是构造一个读取器对象 reader,这个读取器 reader 包含了一些如何去读数据的属性。比如 reader 知道每行的数据是按照 “user item rating” 来分布的,知道每行数据由符号 "," 分割开,知道第一行的数据应该被跳过。
所以我们在构建了这个 reader 以后,就可以将它传给 Dataset() 类,来辅助我们从数据集中,按照我们想要的格式读取出来数据内容。
data = Dataset.load_from_file('./ml-latest-small/ratings.csv', reader)
由于这里我们选择了使用自己已经下载的数据集,调用的就是 Dataset.load_from_file() 方法。可以看到的是,这个方法的输入有两个参数,第一个是数据集的路径,第二个就是刚刚实例化的读取器 reader。
所以这个 load_from_file() 在读取数据时,就会按照 reader 的定义的格式来读取,最终返回一个自定义的数据格式。其实如果看了代码,我们可以看到这里返回的数据格式是:dataset.DatasetAutoFolds,但是正如我们前面说的,对于源码不要陷入细节。我们知道这两步对原始的数据集文件进行了处理,得到了后续可以处理的数据格式,就 OK 啦。
进行结果交叉验证
在完成数据集的载入以后,我们选择的是利用 cross_validate() 执行算法并交叉检验。这一部分的内容,我们分为两部分去介绍。
首先忽略掉算法的实现,直接调用算法的接口。这也是一个很实用的 trick,适当的时候忽略掉一些代码实现,即使你接下来要用到它,也可以直接调源码的接口。所以我们这里忽略了 KNN 算法的实现,直接调用它来实现训练拟合以及后续在测试集上的预测。
那么 cross_validate() 里面是什么呢?我们看一下 validate 中的内容:
validate 中有两个函数,分别是 cross_validate() 和 fit_and_score()。我们简单的介绍一下它们的功能,让大家可以继续没有障碍的阅读当前这篇文章。
algo = KNNBasic()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=2, verbose=0)可以看到 cross_validate() 是被调用的外部接口,很容易可以猜到,fit_and_score() 是在 cross_validate() 中被调用的。
对 cross_validate() 而言,它的输入有算法对象,数据集,需要测量的指标,交叉验证的次数等。这里简单的介绍一下它的内部逻辑。它对输入的数据 data,分成 cv 份,然后每次选择其中一份作为测试集,其余的作为训练集。在数据集划分完后,对它们分别调用 fit_and_score(),去进行算法拟合。
这里注意一个小细节,对数据集的划分不是静态全部划分完,然后分别在数据集上进行训练和验证,而是利用输入的 data 构造一个生成器,每次抛出一组划分完的结果。
对 fit_and_score() 函数,它对输入的算法在输入的训练集上进行拟合,然后在输入的测试集上进行验证,再计算需要的指标。
在进行到这里的时候,同样忽略掉对预测结果进行指标测量的步骤,直接调用 surprise 中的 accuracy 来进行处理。当然到后面我们会补充这些内容,这里要注意的重点是如何进行交叉验证。
这一部分内容的核心是,在有了我们第 2 节输入的数据后,该如何进行数据集的划分以及如何进行算法的训练和验证。所以我们关注的重点是数据集在进行 k 折交叉验证时如何划分,又如何调用接口完成算法在数据集上的训练和测试。
说这一段的意思是想告诉大家,在阅读源码,或者仿写源码时,需要把握住自己在这一步骤的核心思路,屏蔽掉暂时不重要,或者对当前步骤不是很关键的内容。哪怕只是调用各个接口来完成自己当前步骤的任务,只要你把握住了它们的交互关系,处理流程就 OK。
再补充忽略的算法部分
打开上面的 fit_and_score() 函数,我们可以看到对 algo 的使用只有两句代码,一个是训练阶段的 algo.fit(trainset) ,一个是测试阶段的 algo.test(testset)。前者是对算法在训练集上进行拟合,而后者是对算法在测试集上进行测试。
针对 knn 的算法而言,算法的实现上是比较简单的。主要包括了一个 fit() 方法,和一个 estimate() 方法。这里主要是需要对类间的继承关系进行梳理。
在 surprise 中,所有的算法类都继承于一个父类:algo_base(),这个类中抽象出来了一些子类都容易用到的方法,有的给出了具体的实现,有的只是抽象出了一个接口,如 fit() 方法,在 algo_base() 中和其子类 knn() 中都有定义。
这里帮助大家再进一步梳理算法类之间的关系。对 algo_base() 而言,其是一切 surprise 中的算法的父类。那么以 knn 算法为例,这里就不是由 knn() 直接继承 algo_base() 了,而是先有一个 SymmetricalAlgo() 类继承 algo_base(),然后由对应的 knn() 类继承 SymmetricalAlgo() 类。
这里的 SymmetricalAlgo() 的主要工作是处理 knn 中经常需要考虑的一个问题。基于用户还是基于物品的协同过滤。SymmetricalAlgo() 中主要有两个方法,一个是前面一直提到的 fit() 方法,这里的 fit() 方法主要是对 n_x 和 n_y 等做出调整,判断是基于用户相似性还是基于物品相似性,然后调整对应的数据指标。
另外一个方法则是 switch() 方法,顾名思义,switch() 方法同样是调整对应的指标,调整的依据则是判断是基于用户相似性还是物品相似性,调整后的结果用来在测试时使用。
关于其它的算法我们就不一一展开去分析了,授人以鱼不如授人以渔,通过这一个算法的分析,我们就可以明白如何分析算法的具体实现了,也就可以很容易的了解其它算法的功能组成。
在解决了算法部分的问题后,我们了解了算法之间类的继承关系,以及父类提供的接口和可以使用的方法。接下来即使再写其它算法,我们也可以仿照这个思路,保证这些接口的基础上,实现自己的算法代码。
指标测量和数据集的格式
我们在前面第三部分提到,对于预测结果如何进行指标计算的内容可以暂时忽略,这里我们就补充这一部分内容。之所以选择在这里进行补充,我们可以看到,通过前面几步,已经搭建起来了一个基本完整的 demo。其中只有少量内容调用了源码,对预测结果的指标计算就是其中一个。
指标测量部分唯一需要注意的是预测结果的返回形式,也就是前面 Algo_base() 中 test() 方法返回的结果:predictions。
然后就是对计算的几类指标的定义需要了解:MSE,RMSE,MAE,FCP。前三类都是比较常见的指标,FCP 在源码中给出了一篇 paper 作为 reference,其中的定义也很清晰,我们参考 paper 中的定义便可。
具体的计算方法知道了以后,代码的实现就是很简单的了。利用 numpy 可以快速的计算出想要的结果。
至此,整个 demo 可以运行完毕。但是还有一个前面留下的坑需要填一下,就是前面提到对于数据集的格式的问题。在前面提到的时候,我们说这些内容可以忽略过去。但是,其实在 surprise 中对数据格式的定义还是很值得学习的。
surprise 定义了一个 Trainset() 类,用来储存所有与数据集相关的内容。比如用户数量,物品数量,评分数量等比较简单的内容,以及将数据集中的 user ID 转化为新定义的数据结构中的内部编号 inner ID,获取全局平均评分等稍复杂的功能。
通过定义一个数据集的类,可以对数据集进行一次处理,然后需要相应指标时只需直接调用。剩下了很多的运行时间,而且让代码更简洁。
总结
这篇文章本身算是一篇疏导性的总结,结合之前的文章,大家可以自己复现出来一个 surprise 中的 knn 算法,而且其它部分的接口也介绍的非常清晰。对于想要在 surprise 上继续学习其它算法源码的朋友,可以轻松的按照我们之前的分析基础,继续自己的学习;对于想要进行魔改,加入一些自己想要的算法的朋友,目前的介绍也已经清晰的解释了各个接口,大家对应来封装自己的算法就可以了。
另外一方面,本篇文章也从如何阅读源码的角度为大家分享了一些我自己的经验,或许有些地方可以帮助到大家。从如何开始阅读源码,到从一个小 demo 逐渐剖析,暂时忽略掉一些不重要的模块,一步步的完成自己的代码对源码的替代,以写代读。
更严格的讲,这种以写代读比较适合代码量不超过一万行的小型库。这种级别的代码量,我们可以通过自己完整的写一遍来加深理解。但是更高量级的代码量,就不太适合写了,还是以梳理逻辑架构为主了。
今日福利
遇见陆奇
同样作为“百万人学 AI”的重要组成部分,2020 AIProCon 开发者万人大会将于 7 月 3 日至 4 日通过线上直播形式,让开发者们一站式学习了解当下 AI 的前沿技术研究、核心技术与应用以及企业案例的实践经验,同时还可以在线参加精彩多样的开发者沙龙与编程项目。参与前瞻系列活动、在线直播互动,不仅可以与上万名开发者们一起交流,还有机会赢取直播专属好礼,与技术大咖连麦。
门票限量大放送!今日起点击阅读原文报名「2020 AI开发者万人大会」,使用优惠码“AIP211”,即可免费获得价值299元的大会在线直播门票一张。限量100张,先到先得!快来动动手指,免费获取入会资格吧!
点击阅读原文,直达大会官网。
你点的每个“在看”,我都认真当成了AI
相关文章:

开发人员必备网站
http://www.gotapi.com/语言:英语简介:HTML,CSS,XPATH,XSL,JAVASCRIPT等API的查询网站。http://www.w3schools.com/语言:英语简介:W3C制定的标准诸如XML,HTML,XSL等等的在线学习教程。http://www.xml.org.cn/语言:中文…
iOS实现依赖注入
依赖注入(Dependency Injection)这个词,源于java,但在Cocoa框架中也是十分常见的。举例来说:UIView的初始化方法initWithFrame - (id)initWithFrame:(CGRect)frame NS_DESIGNATED_INITIALIZER; 这里的frame传入值,就是所谓的依赖(…
shell语法以及监控进程不存在重启
转码 # dos2unix ./test.sh 权限 # chmod ax ./test.sh语法变量var"111"echo $varecho ${var}运算no14;no25;let resultno1no2echo $result;自增自减少let no let no--[]和let类似result$[ no1 no2 ]result$[ $no1 5 ]也可以使用(()),但使用(())时&…
当莎士比亚遇见Google Flax:教你用字符级语言模型和归递神经网络写“莎士比亚”式句子...
作者 | Fabian Deuser译者 | 天道酬勤 责编 | Carol 出品 | AI科技大本营(ID:rgznai100)有些人生来伟大,有些人成就伟大,而另一些人则拥有伟大。—— 威廉莎士比亚《第十二夜》在几个月前,谷歌的研究人员介绍了机器学习…

netbackup错误之can not connect on socket(25)
rhel5.5上安装netbackup 7.0,这个版本只能安装在64位系统上。安装完netbackup 7.0后,发现登录界面一直报java认证失败,查看了下日志文件,报如下内容: 查了下系统设置,发现/etc/hosts文件里的主机名对应的IP…

支撑Spring的基础技术:泛型,反射,动态代理,cglib等
1.静态代码块和非静态代码块以及构造函数 出自尚学堂视频:《JVM核心机制 类加载全过程 JVM内存分析 反射机制核心原理 常量池理解》 public class Parent {static String name "hello";//非静态代码块{System.out.println("1");}//静态代码块…
深度干货!如何将深度学习训练性能提升数倍?
作者 | 车漾,阿里云高级技术专家顾荣,南京大学副研究员责编 | 唐小引头图 | CSDN 下载自东方 IC出品 | CSDN(ID:CSDNnews)近些年,以深度学习为代表的人工智能技术取得了飞速的发展,正落地应用于…

VIM变IDE
2019独角兽企业重金招聘Python工程师标准>>> 根据这篇博文写了个脚本,简单的解压插件和复制配置,可以帮大家快速配置一个VIM。 脚本中使用rpm安装ctags,所以只支持redhat系的,debian系的要自己安装ctags. 脚本放在gith…
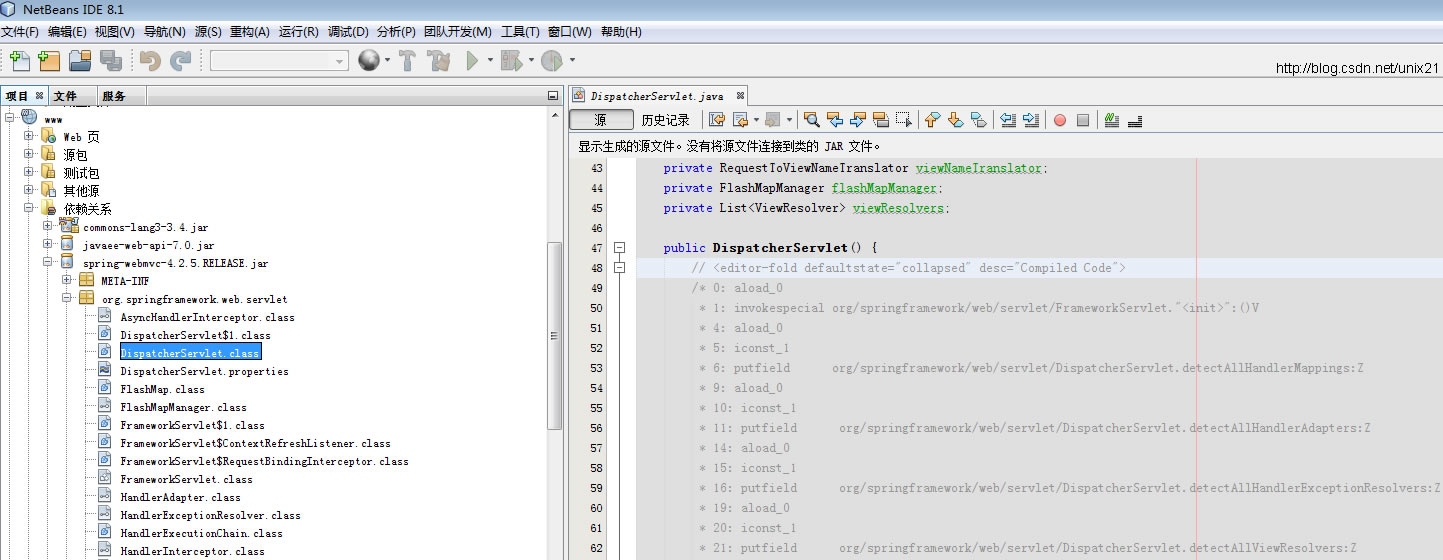
Netbeans使用maven下载源码
如果需要研究源码,自然需要下载源码,其实Netbeans使用maven构建项目下载源码非常简单。 springmvc一开始没有下载源码 commons-lang3是下了源码的,下面是对其调用的代码 可以看到点开其代码是源码,也可以打断点 开一个调试 下载源…
讯飞智能语音先锋者:等到人机交互与人类交流一样自然时,真正的智能时代就来了...
作者 | 夕颜出品 | CSDN(ID:CSDNnews)「AI 技术生态论」 人物访谈栏目是 CSDN 发起的百万人学 AI 倡议下的重要组成部分。通过对 AI 生态顶级大咖、创业者、行业 KOL 的访谈,反映其对于行业的思考、未来趋势的判断、技术的实践,以…
今天看到两个题 写出来思考一下
数组中已有升序的6个数,输入一个数插入到数组中该数组仍然升序. 1,6,9,23,56,95 输入一个数 50 输出 1,6,9,23,56,50,95 题目二 输入一个…
android开发之动画的详解 整理资料 Android开发程序小冰整理
2019独角兽企业重金招聘Python工程师标准>>> /** * 作者:David Zheng on 2015/11/7 15:38 * * 网站:http://www.93sec.cc * * 微博:http://weibo.com/mcxiaobing * * 微博:http://weibo.com/93sec.cc */ 个人交流QQ9…

框架源码学习笔记
1.WebListener Servlet3.0提供WebListener注解将一个实现了特定监听器接口的类定义为监听器,这样我们在web应用中使用监听器时,也不再需要在web.xml文件中配置监听器的相关描述信息了。 Web应用启动时就会初始化这个监听器 WebListener public class M…
20万个法人、百万条银行账户信息,正在暗网兜售
导语:推特用户爆料,暗网上正在出售大量中国数个银行的账号信息,经记者调查,本次打包售价 3999 美金中包含 90 万条中国农业银行账号信息,另外一账号还宣称出售二十个数据包,其中包括百万条银行账号数据、12…

2010年9月blog汇总:敏捷个人和模型驱动开发
9月份指标产品开发开始同时进行两个客户的开发,所以考虑了客户化如何开发的问题;在企业定额产品上,参与清单综合单价库的产品架构并做了用户调研前期准备工作;再就是整理了一下模型驱动开发理论以及思考了OpenExpressApp的几个建模…
Tomcat的配置及优化
Tomcat 服务器是基于Apache 软件基金会项目开发的一个免费的开放源代码的Web 应用服务器它是开发和调试JSP 程序的首选,主要用在中小型系统和并发访问用户不是很多的场合,实际Tomcat 部分是Apache 服务器的扩展,但它是独立运行的,…
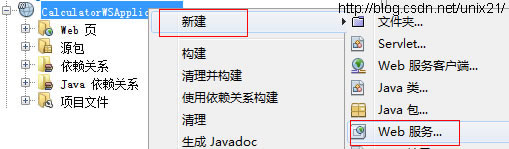
JAX-WS Web 服务开发调用和数据传输分析
一. 开发服务 新建maven的web项目就可以了, 1.新建一个web服务 2.服务名称定义 3.更改配置 4.默认建好的服务文件 5.增加一个add的服务 import javax.jws.WebService; import javax.jws.WebMethod; import javax.jws.WebParam;/**** author Administrator*/ WebSer…
如何在高精度下求解亿级变量背包问题?
导读:国际顶级会议WWW2020将于4月20日至24日举行。始于1994年的WWW会议,主要讨论有关Web的发展,其相关技术的标准化以及这些技术对社会和文化的影响,每年有大批的学者、研究人员、技术专家、政策制定者等参与。以下是蚂蚁金服的技…
收集到的一些网络工程师面试题 和大家分享下
1: 交换机是如何转发数据包的?交换机通过学习数据帧中的源MAC地址生成交换机的MAC地址表,交换机查看数据帧的目标MAC地址,根据MAC地址表转发数据,如果交换机在表中没有找到匹配项,则向除接受到这个数据帧的端口以外的所有端口广播…
incompatible with sql_mode=only_full_group_by
使用mysql 5.7.11-debug Homebrew时报错 错误信息如下: 26 Mar 2016 09:35:23,432 ERROR org.hibernate.engine.jdbc.spi.SqlExceptionHelper:147 - Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column ‘tv2.t_pic_news…
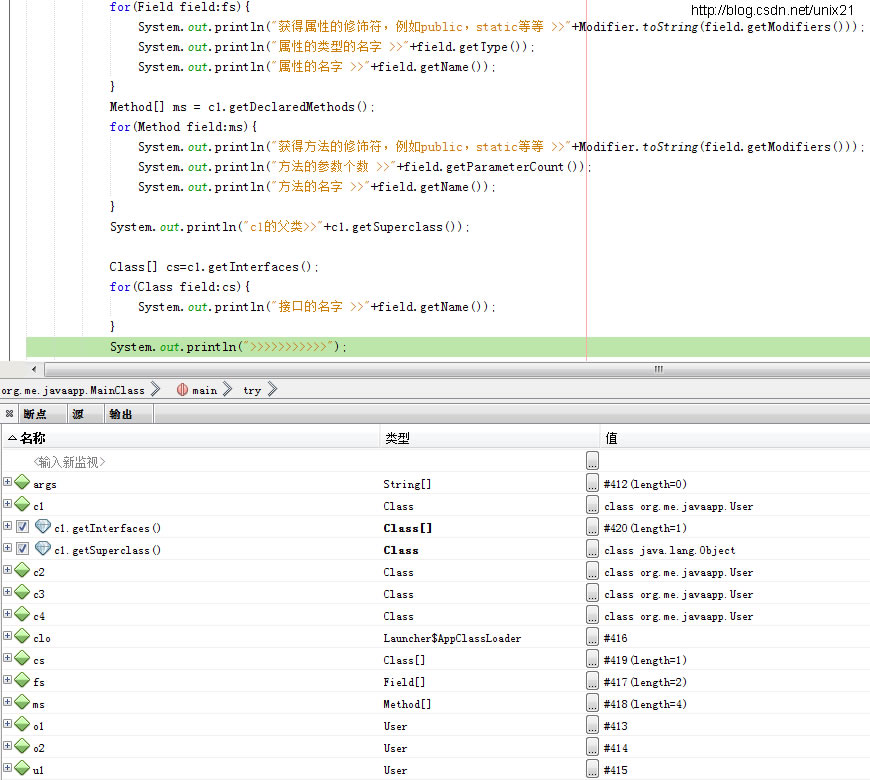
Java动态加载一个类的几种方法以及invoke
一.加载一个类的几种方法 接口 IUser package org.me.javaapp;/**** author Administrator*/ public interface IUser {}User.java /** To change this license header, choose License Headers in Project Properties.* To change this template file, choose Tools | Templ…
今晚20:00 | 港科大郑光廷院士详解人工视觉技术发展及应用
阳春三月,万象更新,2020年注定是不平凡的一年!有激荡就会遇见变革,有挑战就会迎来机遇。今天总会过去,未来将会怎样?香港科大商学院内地办事处重磅推出全新升级的《袁老师访谈录》全新系列【问诊未来院长系…

Openoffice 安装与配置
1、软件下载 路径:http://download.openoffice.org/ 2、软件安装 [rootOpenbo linux]# tar zxvf OOo_3.2.1_Linux_x86_install-rpm-wJRE_zh-CN.tar.gz[rootOpenbo linux]# cd OOO320_m18_native_packed-1_zh-CN.9502/[rootOpenbo OOO320_m18_native_packed-1_zh-CN.…
比较分析与数组相关的sizeof和strlen
// 形如: int a[]{1,2,3,4,5}; char name[]"abcdef";无论是整型数组还是字符数组,数组名作为右值的时候都代表数组首元素的首地址。数组发生降级(数组名退化为数组首元素的地址)的情况:数组传参、数组名参与…
Python正则表达式,看这一篇就够了
作者 | 猪哥来源 | 裸睡的猪(ID: IT--Pig)大多数编程语言的正则表达式设计都师从Perl,所以语法基本相似,不同的是每种语言都有自己的函数去支持正则,今天我们就来学习 Python中关于 正则表达式的函数。re模块主要定义了…
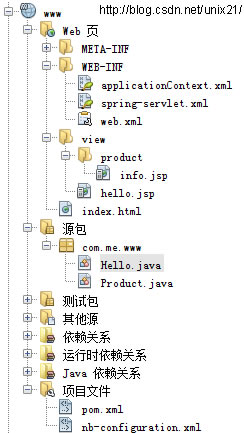
Spring MVC 4
Spring MVC 4 项目文件结构 pom.xml依赖 <properties><endorsed.dir>${project.build.directory}/endorsed</endorsed.dir><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies> …

SQL Server 2008高可用性系列:数据库快照
SQL Server 2008高可用性系列:数据库快照http://database.51cto.com 2010-09-13 14:45 我爱菊花 博客园 我要评论(0)摘要:我们今天要讨论的话题是数据库快照。在SQL Server 2008高可用性中,快照是一项很重要的内容,可以提供至…
PostgreSQL 9.3 beta2 stream replication primary standby switchover bug?
[更新]已有patch. 请参见.PostgreSQL 9.1,9.2,9.3 clean switchover Primary and Standby Patch. http://blog.163.com/digoal126/blog/static/16387704020136197354054/打补丁前的测试 : PostgreSQL 9.3 beta2 无法完成正常的主备角色切换.Primary : psql checkpont; pg_cont…
Apache commons-io
添加引用 <dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.4</version></dependency>按行写: public static void writeFileLineByApacheIO(String fileContent) throws…
Oracle Exadata 简介
随着企业业务的发展,大型数据仓库越来越多,其规模也在迅速扩大,平均每两年规模增大3倍。大型数据仓库要求以最高的磁盘读取速度扫描几十、几百或几千个磁盘,只有磁盘和服务器之间的管道带宽增加10倍或更多才能满足此要求ÿ…