当莎士比亚遇见Google Flax:教你用字符级语言模型和归递神经网络写“莎士比亚”式句子...
作者 | Fabian Deuser
译者 | 天道酬勤 责编 | Carol
出品 | AI科技大本营(ID:rgznai100)
有些人生来伟大,有些人成就伟大,而另一些人则拥有伟大。
—— 威廉·莎士比亚《第十二夜》
在几个月前,谷歌的研究人员介绍了机器学习领域的一颗新星——Flax。从那以后发生了很多事情,预发行版有了巨大的改进。作者自己在Flax上进行的CNNs实验已经取得了成果,与Tensorflow相比,它的灵活性仍然非常好。
今天作者将展示递归神经网络(RNNs)在Flax中的一个应用:字符级语言模型。
在许多学习任务中,我们不必考虑对先前输入的时间依赖性。
但是如果我们没有独立的固定大小的输入和输出向量,该怎么办呢?如果我们有向量序列呢?解决方案是递归神经网络。它们允许我们对下面描述的向量序列进行操作。
递归神经网络
在上图中,你可以看到不同类型的输入输出结构:
一对一是典型CNN或多层感知器,一个输入向量映射到一个输出向量。
一对多是用于图像字幕的RNN体系结构。输入是图像,输出是描述图像的单词序列。
多对多:第一种体系结构利用输入序列到输出序列进行机器翻译,如(德语译成英语)。第二个是适用于帧级别的视频字幕。
RNNs 的主要优点是它们不仅依赖于当前输入,而且还依赖于先前的输入。
RNN是一个具有内部隐藏状态h的单元,该状态根据隐藏的大小用零初始化。在每个时间步长t中,我们将输入x_t插入到RNN单元中,并更新隐藏状态。如今,在下一个时间步t +1中,隐藏状态不再用零初始化,而是使用先前的隐藏状态进行初始化。因此,RNN允许保留有关几个时间步长的信息并生成序列。
字符级语言模型
有了这些新知识,我们现在需要为RNN构建第一个应用程序。字符级语言模型是许多任务的基础,例如图片字幕或文本生成。RNN单元的输入是字符序列形式的大量文本。现在的训练任务是学习在给定先前字符序列的情况下如何预测下一个字符。因此,我们在每个时间步长t生成一个字符,而我们先前的字符是x_t-1,x_t-2…。
举例来说,让我们以FUZZY一词作为训练序列,现在的词汇为{'f','u','z','y'}。由于RNN仅适用于向量,因此我们将所有字符转换为所谓的“单热向量”。单热向量由零组成,其中一个基于词表中的位置为一个,对于“Z”,转换后的向量为[0,0,1,0]。
在下图中,你可以看到给定输入“ FUZZ”的示例,我们希望预测单词“ UZZY”的结尾。神经元的隐藏大小为4,我们希望输出层中的绿色数字较高,而红色为较低。
编程
作者在上一篇有关CNNs的文章中解释了Flax的一些基本概念。作为数据集,我们使用类似这样的对话组成莎士比亚的作品:
EDWARD:
Tis even so; yet you are Warwick still.
GLOUCESTER:
Come, Warwick, take the time; kneel down, kneel down: Nay, when? strike now, or else the iron cools.
我们再次使用Google Colab进行训练,因此我们必须再次安装必要的PIP-Packages:
pip install -q --upgrade https://storage.googleapis.com/jax-releases/`nvcc -V | sed -En "s/.* release ([0-9]*)\.([0-9]*),.*/cuda\1\2/p"`/jaxlib-0.1.42-`python3 -V | sed -En "s/Python ([0-9]*)\.([0-9]*).*/cp\1\2/p"`-none-linux_x86_64.whl jax
pip install -q git+https://github.com/google/flax.git@master因为训练任务非常艰巨,你应该使用具有GPU支持的运行。你可以使用以下命令测试是否存在GPU支持:
from jax.lib import xla_bridge
print(xla_bridge.get_backend().platform)
现在我们准备从头开始创建RNN:
class RNN(flax.nn.Module):
"""LSTM"""
def apply(self, carry, inputs):
carry1, outputs = jax_utils.scan_in_dim(
nn.LSTMCell.partial(name='lstm1'), carry[0], inputs, axis=1)
carry2, outputs = jax_utils.scan_in_dim(
nn.LSTMCell.partial(name='lstm2'), carry[1], outputs, axis=1)
carry3, outputs = jax_utils.scan_in_dim(
nn.LSTMCell.partial(name='lstm3'), carry[2], outputs, axis=1)
x = nn.Dense(outputs, features=params['vocab_length'], name='dense')
return [carry1, carry2, carry3], x
在这样的实际训练情况下,我们不使用普通的RNN单元,而是使用LSTM单元。这是更进一步的发展,可以更好地解决梯度消失的问题。为了获得更高的精度,我们使用了三个堆叠的LSTM单元。我们将第一个单元的输出传递给下一个单元,并用自己的隐藏状态初始化每个LSTM单元,这一点非常重要。否则,我们将无法追踪时间依赖性。
最后一个LSTM单元的输出提供给我们密集层。密集层的词汇量和我们词汇量相当。在前面的“模糊”示例中,神经元的数量为四个。如果将“ FUZZ”设置为RNN的输入,则神经元最多产生类似于[1.7,0.1,-1.0,3.1]这样的输出,因为此输出表明“ Y”是最可能的字符。
因为我们有两种不同的模式,所以针对不同的情况,我们将RNN包装在另一个模块中。
class charRNN(flax.nn.Module):
"""Char Generator"""
def apply(self, inputs, carry_pred=None, train=True):
batch_size = params['batch_size']
vocab_size = params['vocab_length']
hidden_size = 512
if train:
carry1 = nn.LSTMCell.initialize_carry(jax.random.PRNGKey(0), (batch_size,),hidden_size)
carry2 = nn.LSTMCell.initialize_carry(jax.random.PRNGKey(0), (batch_size,),hidden_size)
carry3 = nn.LSTMCell.initialize_carry(jax.random.PRNGKey(0), (batch_size,),hidden_size)
carry = [carry1, carry2, carry3]
_, x = RNN(carry, inputs)
return x
else:
carry, x = RNN(carry_pred, inputs)
return carry, x这种情况是:
训练模型,我们要学习如何预测。
预测模型,实际上在这里我们采样一些文本。
在训练模型之前,我们需要使用以下函数创建它:
def create_model(rng):
"""Creates a model."""
vocab_size = params['vocab_length']
_, initial_params = charRNN.init_by_shape(
rng, [((1, params['seq_length'], vocab_size), jnp.float32)])
model = nn.Model(charRNN, initial_params)
return model
我们每个序列长度为50个字符,词汇表包含65个不同的字符。
作为RNN的优化程序,为了避免初始权重过大,我们选择了初始学习率为0.002且权重衰减的Adam优化器。
def create_optimizer(model, learning_rate):
"""Creates an Adam optimizer for model."""
optimizer_def = optim.Adam(learning_rate=learning_rate, weight_decay=1e-1)
optimizer = optimizer_def.create(model)
return optimizer训练模型
在训练模型下,我们将32个序列的批次输入到RNN中。每个序列均取自我们的数据集,并包含两个子序列,一个是子序列的字符从0到49,另一个子序列的字符从1到50。通过这种简单的拆分,我们的网络可以学习到最有可能的下一个字符。在每一批中,我们初始化隐藏状态,并将序列提供给我们的RNN。
@jax.jit
def train_step(optimizer, batch):
"""Train one step."""
def loss_fn(model):
"""Compute cross-entropy loss and predict logits of the current batch"""
logits = model(batch[0])
loss = jnp.mean(cross_entropy_loss(logits, batch[1])) / params['batch_size']
return loss, logits
def exponential_decay(steps):
"""Decrease the learning rate every 5 epochs"""
x_decay = (steps / params['step_decay']).astype('int32')
ret = params['learning_rate']* jax.lax.pow((params['learning_rate_decay']), x_decay.astype('float32'))
return jnp.asarray(ret, dtype=jnp.float32)
current_step = optimizer.state.step
new_lr = exponential_decay(current_step)
# calculate and apply the gradient
grad_fn = jax.value_and_grad(loss_fn, has_aux=True)
(_, logits), grad = grad_fn(optimizer.target)
new_optimizer = optimizer.apply_gradient(grad, learning_rate=new_lr)
metrics = compute_metrics(logits, batch[1])
metrics['learning_rate'] = new_lr
return new_optimizer, metrics
在我们的训练方法中有两个子函数。loss_fn通过将被解释为向量的输出神经元与所需的单热向量进行比较来计算交叉熵损失。因此在“模糊”示例中,我们将有一个输出[1.7,0.1,-1.0,3.1]和一个热向量[0,0,0,1]。现在我们使用以下公式计算损失:
我们不得不从CNN示例中重写一些代码,因为我们现在使用的不是简单类的序列:
@jax.vmap
def cross_entropy_loss(logits, labels):
"""Returns cross-entropy loss."""
return -jnp.mean(jnp.sum(nn.log_softmax(logits) * labels))
训练步骤中的另一种方法是exponential_decay。我们使用的是Adam优化器,初始学习率为0.002。为了避免太强烈的振荡,我们想每五个周期降低学习率。在每五个周期之后,因子0.97乘以我们的初始学习率,x是多长时间我们达到五个时期。
你将再次看到Flax的优势,即以轻松灵活的方式集成自己的学习速率调度程序。
预测模型
现在我们要评估学习模型,因此我们从词汇表中选择一个随机字符作为切入点。像在训练中一样,我们初始化隐藏状态,但是这次只是在采样开始时。现在子函数推断将一个字符作为输入。对于隐藏状态,我们在每个时间步长后输出,并在下一个时间步长中将它们输入到RNN中。因此,我们不会失去时间依赖性。
@jax.jit
def sample(inputs, optimizer):next_inputs = inputsoutput = []batch_size = 1carry1 = nn.LSTMCell.initialize_carry(jax.random.PRNGKey(0), (batch_size,),512)carry2 = nn.LSTMCell.initialize_carry(jax.random.PRNGKey(0), (batch_size,),512)carry3 = nn.LSTMCell.initialize_carry(jax.random.PRNGKey(0), (batch_size,),512)carry = [carry1, carry2, carry3]def inference(model, carry):carry, rnn_output = model(inputs=next_inputs, train=False, carry_pred=carry)return carry, rnn_outputfor i in range(200):carry, rnn_output = inference(optimizer.target, carry)output.append(jnp.argmax(rnn_output, axis=-1))# Select the argmax as the next input.next_inputs = jnp.expand_dims(common_utils.onehot(jnp.argmax(rnn_output), params['vocab_length']), axis=0)return output
这种方法称为“贪婪采样”,因为我们总是取输出向量中概率最大的字符。还有更好的采样方法,比如波束搜索,在此就不做介绍。
训练和样本循环
至少我们可以在训练和样本循环中调用所有编写的函数。
def train_model():"""Train and inference """rng = jax.random.PRNGKey(0)model = create_model(rng)optimizer = create_optimizer(model, params['learning_rate'])del modelfor epoch in range(100):for text in tfds.as_numpy(ds):optimizer, metrics = train_step(optimizer, text)print('epoch: %d, loss: %.4f, accuracy: %.2f, LR: %.8f' % (epoch+1,metrics['loss'], metrics['accuracy'] * 100, metrics['learning_rate']))test = test_ds(params['vocab_length'])sampled_text = ""if ((epoch+1)%10 == 0):for i in test:sampled_text += vocab[int(jnp.argmax(i.numpy(),-1))]start = np.expand_dims(i, axis=0)text = sample(start, optimizer)for i in text:sampled_text += vocab[int(i)]print(sampled_text)
每隔10个周期后,我们会生成一个文本示例,并且在开始时看起来非常重复:
peak the mariners all the merchant of the meaning of the meaning of the meaning of the meaning of the meaning of the meaning…
但是我们变得越来越好,经过100个周期的训练,莎士比亚的作品似乎还活着,并在写新的文字!
This is a shift respected woman to the king's forth,
To this most dangerous soldier there and fortune.
ANTONIO:
If she would concount a sight on honour
Of the moon, why,...
100个周期训练准确性为86.10%,我们的学习率降至0.00112123。
结论
字符级语言模型的基础是一个能够完成文本的强大工具,可以用作自动补全。可以用作自动补全。也可以利用这个概念来学习一篇文章的观点。但是,生成完整的新文本是一项非常困难的任务。
我们的模型输出的句子看起来像莎士比亚的文本,但它缺乏意义。大家也可以尝试用这种模型并根据有意义的输入创建更有意义的句子。
Flax功能强大且工具众多,但仍处于开发的初期阶段,但它们在开发我喜欢的框架方面处于良好的发展状态。真正巧妙的是,我们只需要稍微更改一下“旧” CNN代码即可在现有基础上使用RNN。
但是Flax仍然缺少它自己的输入管道,因此作者已经用Tensorflow编写了它。如果你想尝试使用作者的代码,你可以在Github Repo中找到用于数据集创建和完整RNN的代码(https://github.com/Skyy93/CharacterLevelModelFlax/)。
原文:https://hackernoon.com/shakespeare-meets-googles-flax-8m1r34q9
本文为 AI 科技大本营翻译,转载请经授权。
今日福利
遇见陆奇
同样作为“百万人学 AI”的重要组成部分,2020 AIProCon 开发者万人大会将于 7 月 3 日至 4 日通过线上直播形式,让开发者们一站式学习了解当下 AI 的前沿技术研究、核心技术与应用以及企业案例的实践经验,同时还可以在线参加精彩多样的开发者沙龙与编程项目。参与前瞻系列活动、在线直播互动,不仅可以与上万名开发者们一起交流,还有机会赢取直播专属好礼,与技术大咖连麦。
门票限量大放送!今日起点击阅读原文报名「2020 AI开发者万人大会」,使用优惠码“AIP211”,即可免费获得价值299元的大会在线直播门票一张。限量100张,先到先得!快来动动手指,免费获取入会资格吧!
点击阅读原文,直达大会官网。
你点的每个“在看”,我都认真当成了AI
相关文章:

netbackup错误之can not connect on socket(25)
rhel5.5上安装netbackup 7.0,这个版本只能安装在64位系统上。安装完netbackup 7.0后,发现登录界面一直报java认证失败,查看了下日志文件,报如下内容: 查了下系统设置,发现/etc/hosts文件里的主机名对应的IP…

支撑Spring的基础技术:泛型,反射,动态代理,cglib等
1.静态代码块和非静态代码块以及构造函数 出自尚学堂视频:《JVM核心机制 类加载全过程 JVM内存分析 反射机制核心原理 常量池理解》 public class Parent {static String name "hello";//非静态代码块{System.out.println("1");}//静态代码块…
深度干货!如何将深度学习训练性能提升数倍?
作者 | 车漾,阿里云高级技术专家顾荣,南京大学副研究员责编 | 唐小引头图 | CSDN 下载自东方 IC出品 | CSDN(ID:CSDNnews)近些年,以深度学习为代表的人工智能技术取得了飞速的发展,正落地应用于…

VIM变IDE
2019独角兽企业重金招聘Python工程师标准>>> 根据这篇博文写了个脚本,简单的解压插件和复制配置,可以帮大家快速配置一个VIM。 脚本中使用rpm安装ctags,所以只支持redhat系的,debian系的要自己安装ctags. 脚本放在gith…
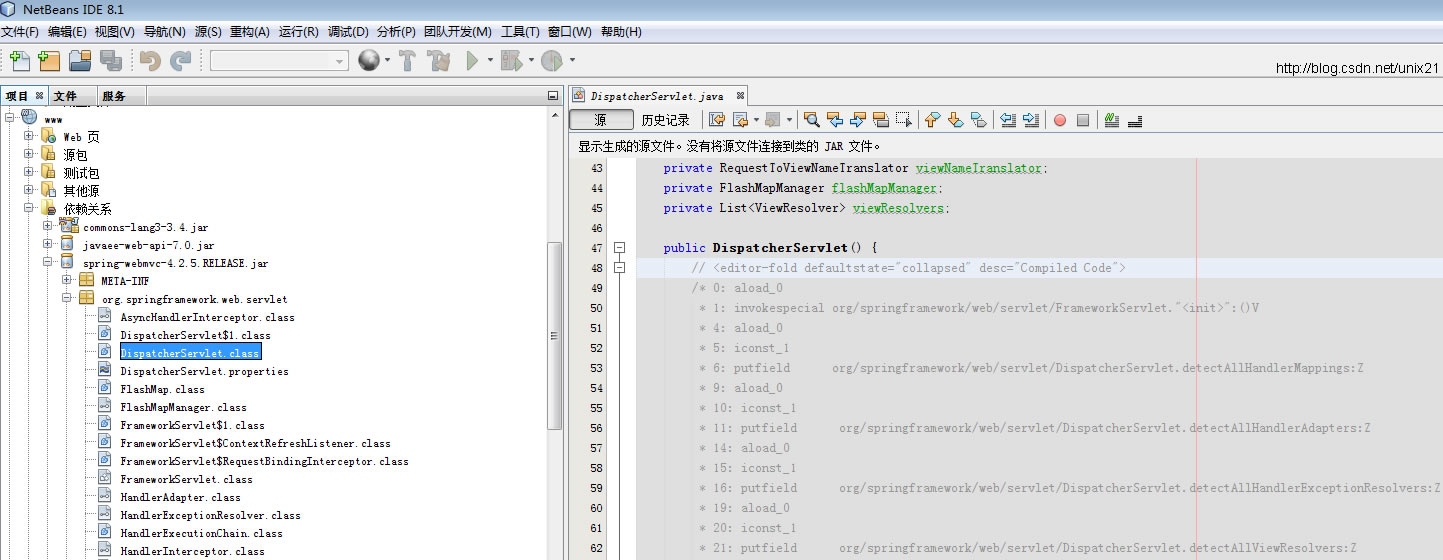
Netbeans使用maven下载源码
如果需要研究源码,自然需要下载源码,其实Netbeans使用maven构建项目下载源码非常简单。 springmvc一开始没有下载源码 commons-lang3是下了源码的,下面是对其调用的代码 可以看到点开其代码是源码,也可以打断点 开一个调试 下载源…
讯飞智能语音先锋者:等到人机交互与人类交流一样自然时,真正的智能时代就来了...
作者 | 夕颜出品 | CSDN(ID:CSDNnews)「AI 技术生态论」 人物访谈栏目是 CSDN 发起的百万人学 AI 倡议下的重要组成部分。通过对 AI 生态顶级大咖、创业者、行业 KOL 的访谈,反映其对于行业的思考、未来趋势的判断、技术的实践,以…

今天看到两个题 写出来思考一下
数组中已有升序的6个数,输入一个数插入到数组中该数组仍然升序. 1,6,9,23,56,95 输入一个数 50 输出 1,6,9,23,56,50,95 题目二 输入一个…
android开发之动画的详解 整理资料 Android开发程序小冰整理
2019独角兽企业重金招聘Python工程师标准>>> /** * 作者:David Zheng on 2015/11/7 15:38 * * 网站:http://www.93sec.cc * * 微博:http://weibo.com/mcxiaobing * * 微博:http://weibo.com/93sec.cc */ 个人交流QQ9…

框架源码学习笔记
1.WebListener Servlet3.0提供WebListener注解将一个实现了特定监听器接口的类定义为监听器,这样我们在web应用中使用监听器时,也不再需要在web.xml文件中配置监听器的相关描述信息了。 Web应用启动时就会初始化这个监听器 WebListener public class M…
20万个法人、百万条银行账户信息,正在暗网兜售
导语:推特用户爆料,暗网上正在出售大量中国数个银行的账号信息,经记者调查,本次打包售价 3999 美金中包含 90 万条中国农业银行账号信息,另外一账号还宣称出售二十个数据包,其中包括百万条银行账号数据、12…

2010年9月blog汇总:敏捷个人和模型驱动开发
9月份指标产品开发开始同时进行两个客户的开发,所以考虑了客户化如何开发的问题;在企业定额产品上,参与清单综合单价库的产品架构并做了用户调研前期准备工作;再就是整理了一下模型驱动开发理论以及思考了OpenExpressApp的几个建模…
Tomcat的配置及优化
Tomcat 服务器是基于Apache 软件基金会项目开发的一个免费的开放源代码的Web 应用服务器它是开发和调试JSP 程序的首选,主要用在中小型系统和并发访问用户不是很多的场合,实际Tomcat 部分是Apache 服务器的扩展,但它是独立运行的,…
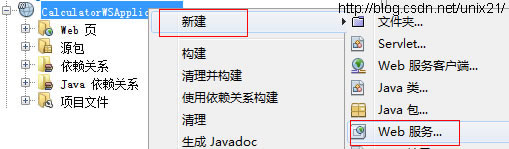
JAX-WS Web 服务开发调用和数据传输分析
一. 开发服务 新建maven的web项目就可以了, 1.新建一个web服务 2.服务名称定义 3.更改配置 4.默认建好的服务文件 5.增加一个add的服务 import javax.jws.WebService; import javax.jws.WebMethod; import javax.jws.WebParam;/**** author Administrator*/ WebSer…
如何在高精度下求解亿级变量背包问题?
导读:国际顶级会议WWW2020将于4月20日至24日举行。始于1994年的WWW会议,主要讨论有关Web的发展,其相关技术的标准化以及这些技术对社会和文化的影响,每年有大批的学者、研究人员、技术专家、政策制定者等参与。以下是蚂蚁金服的技…
收集到的一些网络工程师面试题 和大家分享下
1: 交换机是如何转发数据包的?交换机通过学习数据帧中的源MAC地址生成交换机的MAC地址表,交换机查看数据帧的目标MAC地址,根据MAC地址表转发数据,如果交换机在表中没有找到匹配项,则向除接受到这个数据帧的端口以外的所有端口广播…
incompatible with sql_mode=only_full_group_by
使用mysql 5.7.11-debug Homebrew时报错 错误信息如下: 26 Mar 2016 09:35:23,432 ERROR org.hibernate.engine.jdbc.spi.SqlExceptionHelper:147 - Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column ‘tv2.t_pic_news…
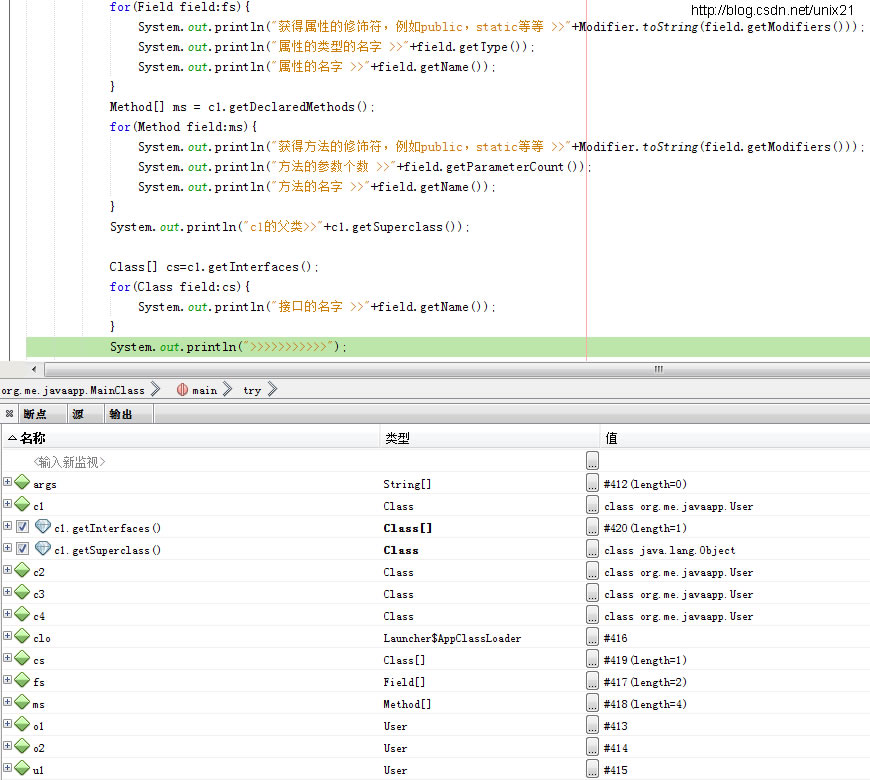
Java动态加载一个类的几种方法以及invoke
一.加载一个类的几种方法 接口 IUser package org.me.javaapp;/**** author Administrator*/ public interface IUser {}User.java /** To change this license header, choose License Headers in Project Properties.* To change this template file, choose Tools | Templ…
今晚20:00 | 港科大郑光廷院士详解人工视觉技术发展及应用
阳春三月,万象更新,2020年注定是不平凡的一年!有激荡就会遇见变革,有挑战就会迎来机遇。今天总会过去,未来将会怎样?香港科大商学院内地办事处重磅推出全新升级的《袁老师访谈录》全新系列【问诊未来院长系…

Openoffice 安装与配置
1、软件下载 路径:http://download.openoffice.org/ 2、软件安装 [rootOpenbo linux]# tar zxvf OOo_3.2.1_Linux_x86_install-rpm-wJRE_zh-CN.tar.gz[rootOpenbo linux]# cd OOO320_m18_native_packed-1_zh-CN.9502/[rootOpenbo OOO320_m18_native_packed-1_zh-CN.…
比较分析与数组相关的sizeof和strlen
// 形如: int a[]{1,2,3,4,5}; char name[]"abcdef";无论是整型数组还是字符数组,数组名作为右值的时候都代表数组首元素的首地址。数组发生降级(数组名退化为数组首元素的地址)的情况:数组传参、数组名参与…
Python正则表达式,看这一篇就够了
作者 | 猪哥来源 | 裸睡的猪(ID: IT--Pig)大多数编程语言的正则表达式设计都师从Perl,所以语法基本相似,不同的是每种语言都有自己的函数去支持正则,今天我们就来学习 Python中关于 正则表达式的函数。re模块主要定义了…
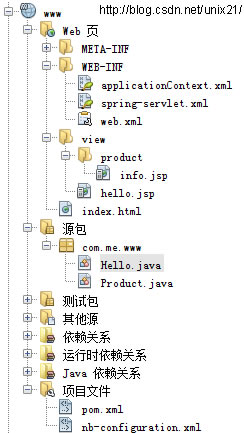
Spring MVC 4
Spring MVC 4 项目文件结构 pom.xml依赖 <properties><endorsed.dir>${project.build.directory}/endorsed</endorsed.dir><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies> …

SQL Server 2008高可用性系列:数据库快照
SQL Server 2008高可用性系列:数据库快照http://database.51cto.com 2010-09-13 14:45 我爱菊花 博客园 我要评论(0)摘要:我们今天要讨论的话题是数据库快照。在SQL Server 2008高可用性中,快照是一项很重要的内容,可以提供至…
PostgreSQL 9.3 beta2 stream replication primary standby switchover bug?
[更新]已有patch. 请参见.PostgreSQL 9.1,9.2,9.3 clean switchover Primary and Standby Patch. http://blog.163.com/digoal126/blog/static/16387704020136197354054/打补丁前的测试 : PostgreSQL 9.3 beta2 无法完成正常的主备角色切换.Primary : psql checkpont; pg_cont…
Apache commons-io
添加引用 <dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.4</version></dependency>按行写: public static void writeFileLineByApacheIO(String fileContent) throws…
Oracle Exadata 简介
随着企业业务的发展,大型数据仓库越来越多,其规模也在迅速扩大,平均每两年规模增大3倍。大型数据仓库要求以最高的磁盘读取速度扫描几十、几百或几千个磁盘,只有磁盘和服务器之间的管道带宽增加10倍或更多才能满足此要求ÿ…
推荐系统的价值观
作者丨gongyouliu来源丨大数据与人工智能(ID: ai-big-data)推荐系统作为满足人类不确定性需求的一种有效工具,是具有极大价值的,这种价值既体现在提升用户体验上,又体现在获取商业利润上。对绝大多数公司来说ÿ…
PostgreSQL md5 auth method introduce, with random salt protect
在上一篇BLOG中介绍了不要在pg_hba.conf中使用password认证方法, 除非你的客户端和数据库服务器之间的网络是绝对安全的.http://blog.163.com/digoal126/blog/static/1638770402013423102431541/MD5方法,认证过程 : Encrypting Passwords Across A Network The MD5 authenticat…
常用Maven收集以及Maven技巧
1.完整的Maven的pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation"http://maven.apach…
大促下的智能运维挑战:阿里如何抗住“双11猫晚”?
作者 | 阿里文娱技术专家子霖出品 | AI科技大本营(ID:rgznai100)2019 双 11 猫晚在全球近 190 个国家和地区播出,海外重保是首要任务,如何提升海外用户观看猫晚的体验?本文将详解双 11 猫晚国际化的技术挑战和技术策略…