字符编码简介 ANSI Unicode Unicode big endian UTF-8
1. ASCII码
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和 1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
2、非ASCII编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制 10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0—127表示的符号是一样的,不一样的只是128—255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256x256=65536个符号。
中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的Unicode和UTF-8是毫无关系的。
3、Unicode
Unicode字符集(简称为UCS),国际标准组织于1984年4月成立ISO/IEC JTC1/SC2/WG2工作组,针对各国文字、符号进行统一性编码。1991年美国跨国公司成立Unicode Consortium,并于1991年10月与WG2达成协议,采用同一编码字集。目前Unicode是采用16位编码体系,其字符集内容与 ISO10646的BMP(Basic Multilingual Plane)相同。Unicode于1992年6月通过DIS(Draf International Standard),目前版本V2.0于1996公布,内容包含符号6811个,汉字20902个,韩文拼音11172个,造字区6400个,保留 20249个,共计65534个。Unicode编码后的大小是一样的.例如一个英文字母 "a" 和 一个汉字 "好",编码后都是占用的空间大小是一样的,都是两个字节!
Unicode可以用来表示所有语言的字符,而且是定长双字节(也有四字节的)编码,包括英文字母在内。所以可以说它是不兼容iso8859-1编码的,也不兼容任何编码。不过,相对于iso8859-1编码来说,uniocode编码只是在前面增加了一个0字节,比如字母'a'为"00 61"。
需要说明的是,定长编码便于计算机处理(注意GB2312/GBK不是定长编码),而unicode又可以用来表示所有字符,所以在很多软件内部是使用unicode编码来处理的,比如java。
Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”。具体的符号对应表,可以查询 unicode.org,或者专门的汉字对应表。 http://www.chi2ko.com/tool/CJK.htm
4. Unicode的问题
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。2)unicode在很长一段时间内无法推广,直到互联网的出现。
5.UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
下面,还是以汉字“严”为例,演示如何实现UTF-8编码。
已知“严”的unicode是4E25(100111000100101),根据上表,可以发现 4E25处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是 “11100100 10111000 10100101”,转换成十六进制就是E4B8A5。
6. Unicode与UTF-8之间的转换
通过上一节的例子,可以看到“严”的Unicode码是4E25,UTF-8编码是E4B8A5,两者是不一样的。它们之间的转换可以通过程序实现。
在Windows平台下,有一个最简单的转化方法,就是使用内置的记事本小程序Notepad.exe。打开文件后,点击“文件”菜单中的“另存为”命令,会跳出一个对话框,在最底部有一个“编码”的下拉条。
里面有四个选项:ANSI,Unicode,Unicode big endian 和 UTF-8。
1)ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)。
2)Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码。这个选项用的little endian格式。
3)Unicode big endian编码与上一个选项相对应。我在下一节会解释little endian和big endian的涵义。
4)UTF-8编码,也就是上一节谈到的编码方法。
选择完”编码方式“后,点击”保存“按钮,文件的编码方式就立刻转换好了。
7. Little endian和Big endian
上一节已经提到,Unicode码可以采用UCS-2格式直接存储。以汉字”严“为例,Unicode 码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
因此,第一个字节在前,就是”大头方式“(Big endian),第二个字节在前就是”小头方式“(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格“(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
8. 实例
下面,举一个实例。
打开”记事本“程序Notepad.exe,新建一个文本文件,内容就是一个”严“字,依次采用ANSI,Unicode,Unicode big endian 和 UTF-8编码方式保存。
然后,用文本编辑软件UltraEdit中的”十六进制功能“,观察该文件的内部编码方式。
1)ANSI:文件的编码就是两个字节“D1 CF”,这正是“严”的GB2312编码,这也暗示GB2312是采用大头方式存储的。
2)Unicode:编码是四个字节“FF FE 25 4E”,其中“FF FE”表明是小头方式存储,真正的编码是4E25。
3)Unicode big endian:编码是四个字节“FE FF 4E 25”,其中“FE FF”表明是大头方式存储。
4)UTF-8:编码是六个字节“EF BB BF E4 B8 A5”,前三个字节“EF BB BF”表示这是UTF-8编码,后三个“E4B8A5”就是“严”的具体编码,它的存储顺序与编码顺序是一致的。
9 国标
9.1 GB码
全称是GB2312-80《信息交换用汉字编码字符集基本集》,1980年发布,是中文信息处理的国家标准,在大陆及海外使用简体中文的地区(如新加坡等)是强制使用的唯一中文编码。P-Windows3.2和苹果OS就是以GB2312为基本汉字编码, Windows 95/98则以GBK为基本汉字编码、但兼容支持GB2312。
双字节编码
范围:A1A1~FEFE
A1-A9:符号区,包含682个符号
B0-F7:汉字区,包含6763个汉字
9.2 GB2312
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从 A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。GB2312-80中共收录了7545个字符,用两个字节编码一个字符。每个字符最高位为0。GB2312-80编码简称国标码。
GB2312支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。
9.3 GB12345-90
1990年制定了繁体字的编码标准GB12345-90《信息交换用汉字编码字符集第一辅助集》,目的在于规范必须使用繁体字的各种场合,以及古籍整理等。该标准共收录6866个汉字(比GB2312多103个字,其它厂商的字库大多不包括这些字),纯繁体的字大概有2200余个。
双字节编码
范围:A1A1~FEFE
A1-A9:符号区,增加竖排符号
B0-F9:汉字区,包含6866个汉字
9.4 GBK
GBK编码(Chinese Internal Code Specification)是中国大陆制订的、等同于UCS的新的中文编码扩展国家标准。gbk编码能够用来同时表示繁体字和简体字,而gb2312只能表示简体字,gbk是兼容gb2312编码的。GBK工作小组于1995年10月,同年12月完成GBK规范。该编码标准兼容GB2312,共收录汉字 21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。Windows95/98简体中文版的字库表层编码就采用的是GBK,通过 GBK与UCS之间一一对应的码表与底层字库联系。
英文名:Chinese Internal Code Specification
中文名:汉字内码扩展规范1.0版
双字节编码,GB2312-80的扩充,在码位上和GB2312-80兼容
范围:8140~FEFE(剔除xx7F)共23940个码位
包含21003个汉字,包含了ISO/IEC 10646-1中的全部中日韩汉字
转载于:https://blog.51cto.com/laokaddk/476613
相关文章:
ReactiveCocoa代码实践之-更多思考
三.ReactiveCocoa代码实践之-更多思考 1. RACObserve()宏形参写法的区别 之前写代码考虑过 RACObserve(self.timeLabel , text) 和 RACObserve(self , timeLabel.text) 的区别。 因为这两种方法都是观察self.timeLabel.text的属性,并且都能实现功能。估计是作者原本…

Java常用命令及Java Dump
线程Dump,包含所有线程的运行状态。纯文本格式。 堆Dump,包含线程Dump,幵包含所有堆对象的状态。二进制格式。 Java Dump方法 1.使用Java虚拟机制作Dump 指示虚拟机在发生内存不足错误时,自动生成堆Dump -XX:HeapDumpOnOutOfMemoryError 2.使用图形化工具制作Dump 使用JDK…
使用Windows远程登录Ubuntu
一、SSH登录 1、Ubuntu默认没有安装SSH ,可以在新得利软件安装程序里,搜索SSH,标记并安装; 或者使用命令: sudo apt-get install openssh-server sudo /etc/init.d/ssh restart ssh localhost…
紧急更新下降难度,《王者荣耀》绝悟 AI 难倒一片玩家
作者 | 神经星星来源 | HyperAI超神经(ID: HyperAI)在 5 月 1 日~ 5 月 4 日期间,玩家通过《王者荣耀》最新版本客户端进入游戏,即可与绝悟 AI 对战。一时间哀鸿遍野,普通玩家、游戏主播、职业选手,纷纷表示…
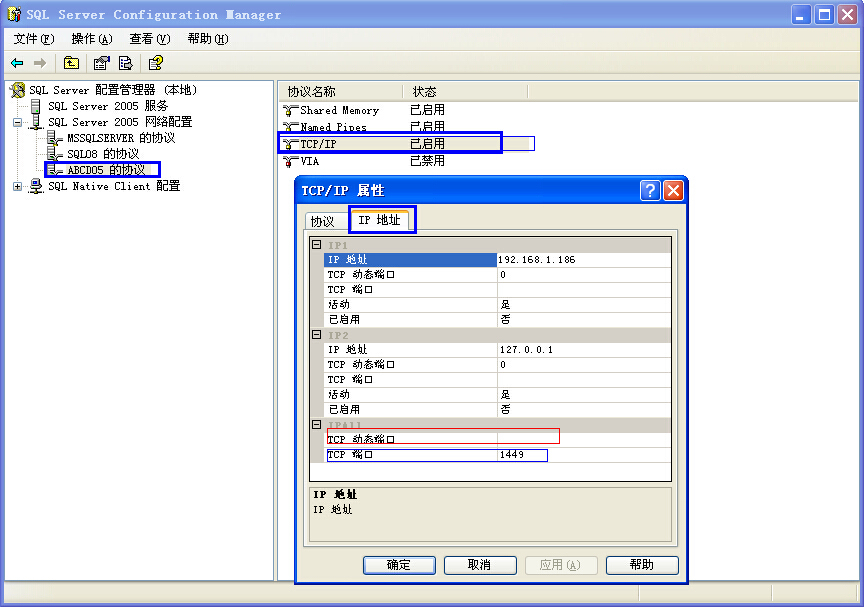
SQL:安装多个实例,修改实例端口号,和IP加端口号连接实例
原文:SQL:安装多个实例,修改实例端口号,和IP加端口号连接实例sql server 安装第一个实例,默认实例的端口是1433, 一个库中如果有多个实例,从第二个实例开始的端口是动态端口,需要的话,自己手工指…
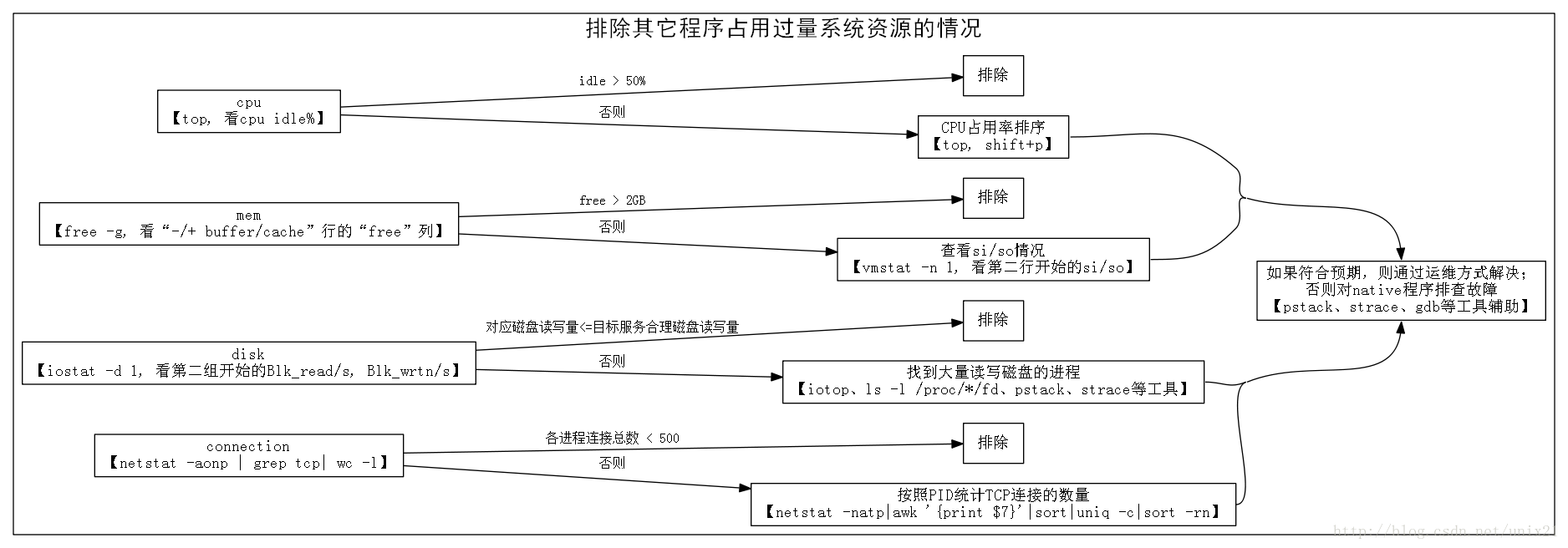
用“逐步排除”的方法定位Java服务线上“系统性”故障
说明:原文地址已经不可访问,其他地方有转载,不过很多丢失图片,所以,找到一处有图的重新配好图。 用“逐步排除”的方法定位Java服务线上“系统性”故障 Posted on 2014/08/25李斯宁(高级测试开发工程师&…
清华硕士爆料:这些才是机器学习必备的数学基础
现如今,计算机科学、人工智能、数据科学已成为技术发展的主要推动力。无论是要翻阅这些领域的文章,还是要参与相关任务,你马上就会遇到一些拦路虎:想过滤垃圾邮件,不具备概率论中的贝叶斯思维恐怕不行;想试…

LINUX环境下资源下载中文目录及中文文件名称问题
为什么80%的码农都做不了架构师?>>> http://www.yeeach.com/2009/04/09/linux%E7%8E%AF%E5%A2%83%E4%B8%8B%E8%B5%84%E6%BA%90%E4%B8%8B%E8%BD%BD%E4%B8%AD%E6%96%87%E7%9B%AE%E5%BD%95%E5%8F%8A%E4%B8%AD%E6%96%87%E6%96%87%E4%BB%B6%E5%90%8D%E7%A7%B…
dojo从asp.net中获取json数据
搞来有搞去终于有了个结果,主要是一开始犯了一些低级错误。 对于json不太了解的童鞋,可以看看这个:http://www.dreamdu.com/blog/2008/10/19/json_in_javascript/ 这个例子中主要是从数据库中读取数据,转换成JSON格式,…
RHEL5 install
RHEL5 安装转载于:https://blog.51cto.com/bhanv/477708
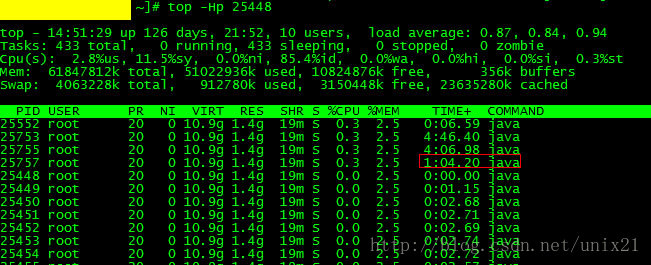
线上java问题排查
0.jps 这个输出java进程pid #jps 查看java的线程 #top -Hp 25448 如图25757这个线程比较耗时,看看他在做什么 注意需要折算出线程pid的16进制值,然后jstack。 可以打印更多信息 #jstack pid | grep -A 20 649d 参考:JVM调优之jstack找出…
GitHub标星10,000+,Apache项目ShardingSphere的开源之路
【编者按】几天前,当 GitHub 全球产品技术生态总经理 Michael Francisco 谈到中国开发者已经成为 GitHub 上最活跃的群体时,有开发者提出数量之后质量也要跟上。的确,过去十数年间,中国开源一直呈现企业热使用热社区冷开发冷的景象…

JAVA中LOCK
原文链接:http://www.cnblogs.com/dolphin0520/p/3923167.html 一.synchronized的缺陷 我们知道如果一个代码块被synchronized修饰了,当一个线程获取了对应的锁,并执行该代码块时,其他线程便只能一直等待,等待获取锁的…
【公开课预告】AutoML知多少
5月7日周四19:00,商汤泰坦公开课第010期,论文解读系列课程第二期即将开播!我们邀请到商汤科技的4位研究员,分享团队在AutoML方面的一系列研究工作,其中包含CVPR 2020、ICLR 2020等多篇最新论文成果,想要了解…
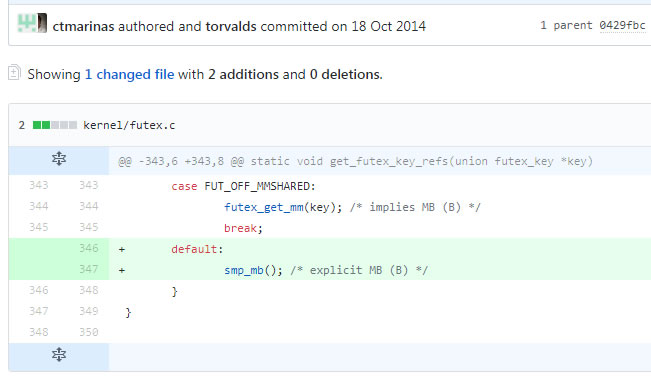
Linux kernel futex.c的bug导致JVM不可用
JVM死锁导致线程不可用,然后会瞬间起N个线程,当然也是不可用的,因为需要的对象死锁,然后耗尽文件句柄导致外部TCP无法建议拒绝服务,jstack之后就会恢复。 解决办法:替换中间件类库 ,比如httpcli…
ruby爬虫综述
http://ihower.tw/blog/archives/2941一个ruby爬虫的例子http://hi.baidu.com/anspider/blog/item/9da210425a0e4e179213c6fb.html
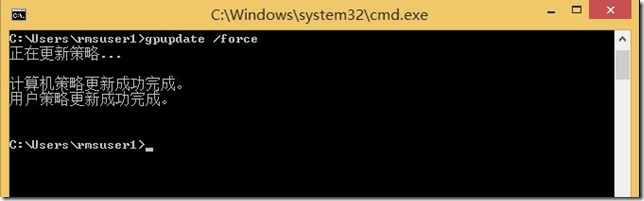
Exchange 2016集成ADRMS系列-12:域内outlook 2010客户端测试
接下来,我们来到域内安装了office 2010的机器上进行测试。 首先我们在客户端上强制刷新组策略,把我们刚才设置的策略刷新下来。 然后我们可以运行gpresult /h result.html来看看策略是不是已经下来了。 策略下来之后,我们打开客户端上面的out…
在Linux下编写Daemon
在Linux下编写Daemon 转自:http://blog.163.com/prevBlogPerma.do?hostmanyhappy163&srl1644768312010718111142260&modeprev 在Linux(以Redhat Linux Enterprise Edition 5.3为例)下,有时需要编写Service。Service也是…
JVM虚拟机参数配置官方文档
JDK8 https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/index.html JDK7 https://docs.oracle.com/javase/7/docs/technotes/tools/solaris/java.html 官方博客 https://blogs.or…
在Rust代码中编写Python是种怎样的体验?
作者 | Mara Bos,Rust资深工程师译者 | Arvin,编辑 | 屠敏来源 | CSDN(ID:CSDNnews)大约一年前,我发布了一个名为inline-python(https://crates.io/crates/inline-python)的Rust类库…
Docker配置指南系列(二):指令集(二)
pause: 停止一个容器的所有进程语法:ocker pause CONTAINER [CONTAINER...] port: 列出容器的端口映射,或者查看指定开放端口的NAT映射语法:docker port [--help] CONTAINER [PRIVATE_PORT[/PROTO]] ps: 列出容器语法࿱…
无需训练RNN或生成模型,我写了一个AI来讲故事
作者 | Andre Ye译者 | 弯月出品 | AI科技大本营(ID:rgznai100)这段日子里,我们都被隔离了,就特别想听故事。然而,我们并非对所有故事都感兴趣,有些人喜欢浪漫的故事,他们肯定不喜欢…

Java字节码instrument研究
MyAgent项目 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.…
怎样保持良好的心态
有一位朋友有一次气冲冲的跟我说:“气死我了!我刚刚发现我一位员工出了错,令产品出现了质量的问题,我修理了他一顿。。。 我问:”你认为你的生产流程里面可能一点错误都没有吗?“ 他说:”应该不…
web编程速度大比拼(nodejs go python)(非专业对比)
C10K问题的解决,涌现出一大批新框架,或者新语言,那么问题来了:到底谁最快呢?非专业程序猿来个非专业对比。 比较程序:输出Hello World! 测试程序:siege –c 100 –r 100 –b 例子包括࿱…
linux邮件服务
邮件服务要求:l 能够构建完整的邮件系统 能够正确设置DNS邮件服务器记录 l 能够配置sendmail服务器 设置客户端软件使用邮件服务器 准备工作: l 主机名:srv.benet.com /etc/sysconfig/network <永久的> l 域名 正向区域 bt.com完成NDS的…
MaskFlownet:基于可学习遮挡掩模的非对称特征匹配丨CVPR 2020
来源 | 微软研究院AI头条(ID: MSRAsia)编者按:在光流预测任务中,形变带来的歧义与无效信息会干扰特征匹配的结果。在这篇 CVPR 2020 Oral 论文中,微软亚洲研究院提出了一种可学习遮挡掩模的非对称特征匹配模块 &#x…

GDB调试--以汇编语言为例
#rpm -qa |grep gdb 下载: 安装 #tar -zxvf #./configure #make 使用GDB 以汇编语言调试为例 汇编语言实现CPUID指令 CPUID cpuid是Intel Pentinum以上级CPU内置的一个指令(486级以下的CPU不支持),他用于识别某一类型…

汇编语言系统调用过程
以printf为例,详细解析一个简单的printf调用里头,系统究竟做了什么,各寄存器究竟如何变化。 如何在汇编调用glibc的函数?其实也很简单,根据c convention call的规则,参数反向压栈,call…
switch语句中在case块里声明变量会遇到提示“Expected expression before...的问题
switch语句中在case块里声明变量会遇到提示“Expected expression before..."的问题 例如在如下代码中 1case constant:2 int i 1;3 int j 2;4 self.sum i j;5 break;GCC在case语句之后的第一行中声明变量时遇到问题。 这时需要在case块两端添加花括号&am…