干货 | 时间序列预测类问题下的建模方案探索实践
作者 | 陆春晖
责编 | Carol
出品 | AI科技大本营(ID:rgznai100)
背景
时间序列类问题是数据分析领域中一类常见的问题,人们有时需要通过观察某种现象一段时间的状态,来判断其未来一段时间的状态。而时间序列就是该种现象某一个统计指标在不同时间上的数值,按时间先后顺序排列而形成的序列。
时间序列分析主要针对时间序列类问题的两个领域,一个是对历史区间数据的分析,通过对过往数据特征的提炼总结来进行异常检测和分类;另一类就是对未来数据的分析,根据过去时间点的数据对未来一个时间点或者几个时间点的状态或实际值进行预测。
时间序列预测类问题在金融领域比较常见,例如股票价格的预测,网点现金流量的预测等等,在气象、人口密度预测等领域也有很广泛的应用。传统的时间序列预测模型通常是统计学模型,比如经典的ARMA系列,它们建立在统计学基础上,需要满足一些基本假设(例如平稳性假设等),因此适用场景比较少,在现实中比较容易受限。随着机器学习和深度学习的兴起,时间序列预测类问题越来越多的被抽象为回归问题,从而可以使用机器学习和深度学习的相关模型,不需要受到基本假设的限制,适用范围更广,更受到人们青睐。
本文以疫情期间北京重点区域人群密度情况的预测为例,使用统计学模型ARMA,机器学习模型Xgboost和深度学习模型LSTM分别进行建模,并对这三种建模方案在实际操作时的复杂度、运行效率和预测准确度进行对比分析,从而直观感受每种建模方案的优缺点,为真实场景中建模方案的选择提供帮助和参考。
数据准备
为方便进行模型间的比对,本文使用的数据集只包括北京997个重点区域在2020/01/17至2020/02/15这30天内每个小时的人群密度数据,总共717840条记录。数据包含三个维度,分别是区域ID、时间戳和人群密度指数,数据格式如图1所示。
图1 训练样本示例
训练数据和测试数据都以小时为最小时间步,其中部分区域30天内的人群密度指数趋势如图2所示:
图2部分重点区域30天内人群密度指数趋势
在进行时间序列预测建模之前,首先要进行时间序列的自相关性分析,确定训练数据是符合时间序列要求的。时间序列的自相关性可以理解为时间序列自己与自己(不同滞后项)之间的相关性,本文使用时滞图来观察时间序列的自相关性,时滞图是把时间序列的值及相同序列在时间轴上后延的值放在一起展示,如图3所示。
图3 部分重点区域人群密度指数时滞图
通过观察时滞图发现,各区域的人群密度指数都在对角线附近聚集,存在明显的正相关性,说明各区域的人群密度指数序列符合时间序列的要求,可以使用相关的模型进行预测。为了方便评估模型,总共30天的数据中,选择前27天的数据作为训练集进行模型训练,后3天的数据作为测试集进行模型测试。
模型构建
传统统计学模型、机器学习模型和深度学习模型的构建方法各有不同,本文分别选择每个领域的经典模型,探索建模流程并比对各种构建方案的优缺点和适用性。
3.1、统计学模型ARMA建模流程
ARMA模型全名自回归滑动平均模型,是研究时间序列的重要方法,由自回归模型(简称AR模型)与移动平均模型(简称MA模型)为基础“混合”构成。它的基本思想是:某些时间序列是依赖于时间t的一组随机变量,构成该时间序列的单个序列值虽然具有不确定性,但整个序列的变化却有一定的规律性,可以用相应的数学模型近似描述。通过对该数学模型的分析研究,能够更本质地认识时间序列的结构与特征,达到最小方差意义下的最优预测,其具体建模流程如图4所示。
图4 ARMA模型建模流程图
由于ARMA模型是统计领域的模型,使用它必须首先满足序列平稳性这一前提条件。这是因为在大数定理和中心定理中要求样本同分布(这里同分布等价于时间序列中的平稳性),而统计领域的模型中有很多都是建立在大数定理和中心极限定理的前提条件下的,如果它不满足,得到的许多结论都是不可靠的。本文使用观察法和单位根法进行序列平稳检验。
观察法主要是通过序列自相关图和偏自相关图来观察序列的分布是否始终围绕一个常数上下浮动。单位根法是指通过单位根检验来检查序列中是否存在单位根,如果存在单位根就是非平稳时间序列了。单位根检验的原假设是存在单位根,因此如果得到的统计量显著小于3个置信度(1%,5%,10%)的临界统计值时,说明是拒绝原假设的。另外需要观察P-value是否非常接近0(4位小数基本即可)。
平稳序列
非平稳序列
图5 平稳序列和非平稳序列平稳性检验结果比对(观察法和单位根法)
观察图5的平稳序列可以发现,该序列的自相关图和偏自相关图都是围绕坐标轴上下浮动,存在拖尾现象,其单位根检验统计量为-4.175107明显小于其3个置信度的临界统计值(-3.439740,-2.865684,-2.568977),且P-value为0.000726,接近0,可以拒绝原假设,即该序列不存在单位根,判断是平稳序列。而图5右侧图中,自相关图并未围绕坐标轴上下浮动,且其单位根检验统计量为-3.313199,比99%概率下的临界统计-3.439740值大,且P-value没有明显接近0,不能拒绝原假设,即该序列存在单位根,判断是非平稳序列。
平稳序列可以直接开始建模,如果是非平稳的序列,可以通过差分的方式将其先转化为平稳序列,再进行建模。
ARMA模型建模时通过自相关图和偏自相关图进行模型选型和定阶,其规则如表1所示。
AR(p) | MA(q) | ARMA(p,q) | |
自相关图 | 拖尾 | Q步截尾 | 拖尾(p步收敛) |
偏自相关图 | P步截尾 | 拖尾 | 拖尾(q步收敛) |
表1 ARMA模型选型和定阶规则
选型确定后的定阶可以根据模型的AIC/BIC准则确定,能够弥补自相关图和偏自相关图定阶的主观性。AIC准则全称最小化信息量准则,是衡量统计模型拟合优良性的一种标准,建立在熵的概念上,可以权衡所估计模型的复杂度和此模型拟合数据的优良性。BIC准则是贝叶斯信息准则,在AIC准则的基础上有所改进,AIC和BIC的值都是越小越好。
ARMA模型参数确定后就可以使用时间序列数据进行训练。训练结束后可以对残差进行白噪声检验,来判断所建模型是否提取了原数据的足够信息,白噪声检验也可以借助自相关图和偏自相关图来判断,观察各期滞后是否还有显著的自相关性和偏自相关性。
由于ARMA模型是单变量时间序列模型,一次只能对一个重点区域进行建模,总共997个重点区域,需要为每个区域单独建模,共需建立模型997个,且每个序列的平稳性都不确定,需要单独进行检验,过程比较繁琐。部分区域预测结果如图6所示。
图6 部分区域ARMA模型预测结果
3.2、机器学习模型XGBoost建模流程
XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。它在Gradient Boosting框架下实现机器学习算法。XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。使用XGBoost模型处理时间序列预测类问题,需要将其转换成回归问题再进行构建,其具体建模流程如下图所示。
图7 XGBoost模型建模流程图
使用机器学习类的模型进行时间序列预测,不需要进行平稳性检验,直接对训练数据进行相关预处理即可,包括查重、查缺、清洗错误等。
由于需要转换成回归问题,机器学习类模型往往需要通过特征工程,从单一的时序特征中构造适合回归模型的特征集,再基于特征集而非时序特征本身进行模型的训练。一般来说可以提取时间截面特征、统计特征、滑窗特征等,也可以借助一些特征提取工具,例如tsfresh工具包等,将一维时序特征转换成多维截面特征。
训练数据和测试数据都需要通过特征工程提取出特征集,然后把训练特征集输入XGBoost模型,进行训练。这一过程中可以通过调节参数来提高模型的准确率,降低过拟合。
XGBoost模型的调参相对比较复杂,包括三大类参数:通用参数、booster参数以及学习目标参数。通用参数控制在提升(boosting)过程中使用哪种booster,常用的booster有树模型(tree)和线性模型(linear model)。Booster 参数具体取决于使用哪种booster。学习目标参数用于控制学习的场景,例如在回归问题中会使用不同的参数控制排序。除了以上参数还可能有其它参数,在命令行中使用。XGBoost模型的调参通过交叉验证函数CV来实现,通过遍历参数设定值找到最优的迭代次数等。
XGBoost模型的优化主要通过是特征工程和模型调参的迭代来实现,这是一个相对复杂并且需要技巧和时间的过程,需要在实践中摸索经验。
XGBoost模型的构建不需要区分区域,只需把区域当作一维特征输入模型即可,可以进行整体建模。使用XGBoost模型预测部分区域的结果如图8所示。
图8 部分区域XGBoost模型预测结果
3.3.神经网络模型LSTM
除了统计学模型和机器学习模型以外,深度学习的神经网络模型在时间序列预测类问题上也有比较好的表现,其中LSTM模型应用最为广泛。LSTM模型全名长短期记忆人工神经网络,是一种时间递归神经网络(RNN),可以很好地解决长时依赖问题。使用LSTM模型建模流程如图所示。
图9 LSTM模型建模流程图
神经网络类模型在做数据预处理时,往往需要对数据进行归一化处理,将每组数据都变为-1到1之间的数,这样可以加快网络的训练速度。训练数据和测试数据应该通过同样的归一化处理再进行训练和预测,输出的预测结果再进行反归一化还原成原始的数据。
神经网络的特征工程比较简单,只需要将原始的时序数据通过时间滑窗进行时间步的拼接即可。例如需要根据过去9天的历史数据预测未来3天的数据,将时间滑窗设定为12天,沿着时间序列滑行,每次选出12天的数据,前9天做为训练数据,后3天做为训练数据的标签,如图10所示。
图10 利用时间滑窗构建时序特征集
构建完时序特征集后即可设计合适的网络结构,这也是神经网络模型的构建重点。时间序列预测的类型和对应可行的LSTM模型网络结构有以下几种,可以根据具体训练数据调整LSTM模型的网络结构参数。本文进行的预测属于输入输出均为单序列多个时间步的类型,选择双层LSTM网络结构。
类型 | 示意图 | LSTM网络结构 |
输入单序列多个时间步,输出单序列单个时间步 | 单层,隐藏单元50个 | |
输入多序列多个时间步,输出单序列单个时间步 | 单层,隐藏单元50个 | |
输入多序列多个时间步,输出多序列单个时间步 | 单层,隐藏单元100个 | |
输入单序列多个时间步,输出单序列多个时间步 | 两层,第一层隐藏单元100个,第二层隐藏单元100个 | |
输入多序列多个时间步,输出单序列多个时间步 | 两层,第一层隐藏单元100个,第二层隐藏单元100个 | |
输入多序列多个时间步 输出多序列多个时间步 | 两层,第一层隐藏单元200个,第二层隐藏单元200个 |
表2 时序序列预测类型和对应LSTM网络结构
设定完模型迭代次数epoch即可开始进行LSTM模型的训练,神经网络类型的模型训练时间相对其他模型而言比较久,对内存的消耗也比较大,为了减轻内存压力,可以采用批处理的策略进行训练,即将训练样本划分批次,一次处理一批样本。使用LSTM模型预测部分区域的结果如下图所示。
图11 部分区域LSTM模型预测结果
结论和展望
三种不同类型的模型在时间序列预测领域各有优缺点,它们人工介入的程度,构建时间和在测试集上的准确率(用MSE错误率表示)如下表所示。
模型类别 | 人工介入程度 | 构建时间 | 平均MSE错误率 |
统计模型ARMA | 较大,需要人工进行平稳性判断和模型定阶 | 约83分钟 | 7.779 |
机器学习模型XGBoost | 中等,需要进行特征工程和模型调参 | 约20分钟 | 6.67040 |
深度学习模型LSTM | 较小,只需设定网络结构和特征集 | 约36分钟 | 16.427 |
表12 模型对比
通过三种类型模型的建模流程和预测效果比对,可以发现统计模型ARMA需要更大程度的人工参与,本身又是单变量模型,不能整体构建,必须分区域单独构建,即使模型拟合本身速度不慢,构建所花费的时间也较其他两种模型多的多,并不是特别适合工业环境使用。
机器学习模型XGBoost在三种模型里,构建时间花费最小,同时预测效果最好,唯一不足的地方是准确率比较明显的依赖于特征工程和模型调参,这两部分也对使用者的经验要求比较高。
深度学习模型LSTM的人工参与程度最小,基本上只需设定下网络结构和简单构建时序特征集,也不需要专门去做特征提取和模型调参。但是其构建时间明显要比机器学习时间长,并且在不是大数据量的情况下准确率并没有明显的优势。
综上所述,三种类型的模型各有所长和不足,一般来说,统计类模型适合于数据量较小同时工业化需求不高的情况,机器学习类模型更广泛适合于工业化情境,而深度学习模型在大数据量的预测上更具备优势。
作者介绍:
陆春晖,毕业于南开大学,中国农业银行研发中心高级工程师
本文为作者原创投稿,未经授权请勿转载。
推荐阅读
饿了么交易系统5年演化史
360金融首席科学家张家兴:别指望AI Lab做成中台
我们想研发一个机器学习框架,6 个月后失败了
那个分分钟处理 10 亿节点图计算的 Plato,现在怎么样了?
中国 App 出海“变形记”
詹克团反攻比特大陆:一场失去人心的自我挽留
你点的每个“在看”,我都认真当成了AI
相关文章:

Redis安装与源码调试
linux版本:64位CentOS 6.5 Redis版本:redis-3.0.6 (更新到2016年1月22日) Redis官网:http://redis.io/ Redis常用命令:http://redis.io/commands 1.安装Redis # wget http://download.redis.io/releases/redis-3.2.6.tar.g…

system pause in C#
方法一: Console.Write("Press any key to continue . . . "); Console.ReadKey(true); 注:也可用ReadLine()或Read(),但是只能对回车进行响应,不能达到anykey的效果。 方法二: 1) 在源文件using处加入using…
C#设置当前程序通过IE代理服务器上网
注意:以下设置只在当前程序中有效,对IE浏览器无效,且关闭程序后,自动释放代码。 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Runtime.InteropServices;public static …
计算机科学精彩帖子收集
linux源码 LXR 源自“the Linux Cross Referencer”,中间的“X”形象地代表了“Cross”。与 Source Navigator 类似,它也是分析阅读源代码的好工具。不同的是,它将源代码借助浏览器展示出来,文件间的跳转过程成了我熟悉的点击超链…
挑战王者荣耀“绝悟” AI,我输了!
作者 | 马超责编 | 伍杏玲出品 | CSDN(ID:CSDNnews)腾讯 AI Lab 与王者荣耀联合研发的策略协作型AI,“绝悟”首次开放大规模开放:5月1日至4日,玩家从王者荣耀大厅入口,进入“挑战绝悟”测试&…
java 注解类说明
一、类中注解 SuppressWarnings ("serial"); 关键字 用途deprecation使用了不赞成使用的类或方法时的警告unchecked执行了未检查的转换时的警告,例如当使用集合时没有用泛型 (Generics) 来指定集合保存的类型。fallthrough当 Switch 程序块直接通往下一种…
《ArcGIS Runtime SDK for Android开发笔记》——(13)、图层扩展方式加载Google地图...
1、前言 http://mt2.google.cn/vt/lyrsm225000000&hlzh-CN&glcn&x420&y193&z9&sGalil 通过图层扩展类的方式加载Google地图的是我们通常获取Google地图的一种方式,根据这种方式我们可以通过拼接地图瓦片Url字符串获取瓦片数据,关…
调试JDK源码-一步一步看HashMap怎么Hash和扩容
调试JDK源码-一步一步看HashMap怎么Hash和扩容 调试JDK源码-ConcurrentHashMap实现原理 调试JDK源码-HashSet实现原理 调试JDK源码-调试JDK源码-Hashtable实现原理以及线程安全的原因 还是调试源码最好。 开发环境 JDK1.8NetBeans8.1 说明:调试HashMap的 publ…
开源一年,阿里轻量级AI推理引擎MNN 1.0.0正式发布
在经过充分的行业调研后,阿里淘系技术部认为当时的推理引擎如TFLite不足以满足手机淘宝这样一个亿级用户与日活的超级App。于是,他们从零开始自己搭建了属于阿里巴巴的推理引擎MNN。1年前,MNN在Github上开源,截止目前获得了3.9k S…
人生在成败中进步
参考文献《佛经》 人生在成败中进步佛经中有云:“菩萨者,福慧深利,道观双流。”“福慧双修”、“福慧双全”是众生成佛的必由之道,也是众生修行的理想追求。人生中,虽然不可能人人都能成佛,但是佛经有云&am…

【原】YUI压缩与CSS media queries下的bug
大概是上个月,使用YUI压缩一个css文件后,发现只要是被压缩后的css文件有部分根本无法工作,一直都不知啥问题引起的,让我感到头疼。 今天发现了只要是在媒体查询中的样式无法起作用,于是才开始怀疑是media被压缩后引起的…
Spring源码分析【4】-Spring扫描basePackages注解
org.springframework.beans.factory.support.DefaultListableBeanFactory 重要数据结构 /** Map of bean definition objects, keyed by bean name */private final Map<String, BeanDefinition> beanDefinitionMap new ConcurrentHashMap<String, BeanDefinition&…
c语言c++语言中静态变量,函数详解
静态变量,静态函数对于一些c,c的初学者来说,造成了不少的困扰。昨晚和寝室的室友讨论到这 个问题,想了一下,作了一下总结:虽然说c和c在很多人的眼里就是孪生姐妹,其实还是有很大区别的。在这里分…
深度解析MegEngine亚线性显存优化技术
基于梯度检查点的亚线性显存优化方法[1]由于较高的计算/显存性价比受到关注。MegEngine经过工程扩展和优化,发展出一套行之有效的加强版亚线性显存优化技术,既可在计算存储资源受限的条件下,轻松训练更深的模型,又可使用更大batch…

2016-04-28
2019独角兽企业重金招聘Python工程师标准>>> 1.提交form表单之前的函数(校验不错):onsubmit"return A();".2.解析XML的方式:2.1.DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准,基于"树"(DocumentBuilderFactory).2.2.SAX的优点类似于…

Spring源码分析【8】-MyBatis注解方法不能重载
代码如下: 这是不可以的,会报错: 2016-08-18 11:36:00,267 [main] ERROR [org.mybatis.spring.mapper.MapperFactoryBean] - Error while adding the mapper interface com.unix21.mapper.UserMapper to configuration.java.lang.IllegalArgu…
不知道这 7 大 OpenCV 函数怎么向计算机视觉专家进阶?
作者 | Lazar Gugleta译者 | Arvin,责编 | 夕颜头图 | CSDN付费下载自视觉中国出品 | CSDN(ID:CSDNnews)计算机视觉和计算机图形学现在非常流行,因为它们与人工智能息息相关,它们主要的共同点是使用同一个OpenCV库&…
MySQL5.5复制新特性
MySQL5.5复制新特性一.MySQL5.5复制改进MySQL5.5版本对MySQL Replication进行了多项的改良,以提供数据的完整性,性能和应用灵活性更高水平。1.Semisynchronous Replication:主从之间的等待机制2.Slave fsync tuning:调整slave fsync包括sync-…
GitLab 8.7发布
日前,GitLab 8.7版发布。该版本中,添加了新功能和优化,并小幅提升了性能。\\8.7版本发布于8.6版本整整30天之后,跟上了每月22日次版本的进度。最新的版本增加了在单个问题上设置到期日期的支持以及以用户所在时区而不是UTC来显示所…
Java飞行记录器 JRockit Flight Recorder JFR诊断JVM的历史性能和操作
需要展开子树,复制堆栈跟踪,就可以查看到代码调用链,看到自己的业务代码,从而定位到最耗时的代码位置:

vi/vim: 使用taglist插件
本节所用命令的帮助入口: :help helptags :help taglist.txt 上篇文章介绍了在vim中如何使用tag文件,本文主要介绍如何使用taglist插件(plugin)。 想必用过Source Insight的人都记得这样一个功能:SI能够把当前文件中的宏、全局变量、函数等t…
学会这些Python美图技巧,就等女朋友夸我了
来源 | ZackSock(ID: ZackSock)Python中有许多用于图像处理的库,像是Pillow,或者是OpenCV。而很多时候感觉学完了这些图像处理模块没有什么用,其实只是你不知道怎么用罢了。今天就给大家带了一些美图技巧,让…
Linux下的softlink和hardlink(转)
Linux中包括两种链接:硬链接(hard link)和软链接(soft link),软链接又称为符号链接(symbolic link)创建命令:ln -s destfile/directory softlink #建立软连接 ln destfile hardlink #建立硬连接in…

ubuntu安装之后的最初几天一路杂记
我就随便写了啊,没那么正式,想到什么就写什么。 由于大四的毕业设计要做一个牵扯到linux的项目,最近不得不再次玩起了ubuntu,其实前一次(大二的时候吧)就已经在电脑上安装过一个ubuntu了,只不过…
百万级访问量网站的技术准备工作[转帖]
当今从纯网站技术上来说,因为开源模式的发展,现在建一个小网站已经很简单也很便宜,所以很多人都把创业方向定位在互联网应用。这些人里大多数不是 很懂技术,或者不是那么精通,而网站开发维护方面的知识又很分散&#x…
智能驾驶L2的黄金时代,打磨地图是关键
作者 | 自动驾驶从业者,中寰卫星黄亮出品 | AI科技大本营(ID:rgznai100)智能驾驶L2,以我们通俗的定义是,以高级辅助驾驶的产品为主的各种巡航产品,包括定速巡航,自适应巡航ACC,预见性…
css中的垂直居中方法
单行文字 (外行高度固定) line-height 行高, 将line-height值与外部标签盒子的高度值设置成一致就可以了。 height:3em; line-height:3em; 多行文字 图文结合(图和单行文字) 图文结合(图和多行文字…

U盘挂载,gedit,vi,文本模式中文乱码等等问题
U盘或硬盘挂载 首先,我们要查看一下磁盘的分区信息sudo fdisk -l (注意注意,是小写的L,不是1,也不是i) 这里可以看到我的硬盘情况,前面几个是win7系统下的C,D ,E ,F 盘。我现在是在图书馆,没…
一次对语音技术的彻底批判
作者 | Alexander Veysov译者 | 孙薇,编辑 | 夕颜出品 | AI科技大本营(ID:rgznai100)ImageNet的出现带来计算机视觉领域的突破发展,掀起了一股预训练之风,这就是所谓的ImageNet时刻。但与计算机视觉同样重要…
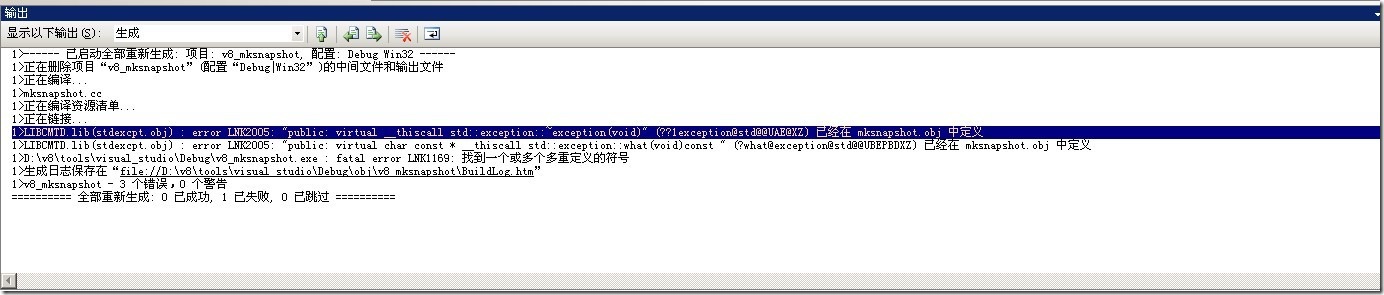
Windows下编译Chrome V8
主要还是参考google的官方文档: How to Download and Build V8 Building on Windows 同时也参考了一些其它的中文博客: 脚本引擎小pk:SpiderMonkey vs V8 Windows 下编译V8引擎-with visual sudio 2010 将google V8 编译成 dll v8学习笔记 步…