赠书 | 从阿里到Facebook,一线大厂这样做深度学习推荐系统
本文内容节选自《深度学习推荐系统》一书。
由美国Roku推荐系统架构负责人、前Hulu高级研究员王喆精心编著,书中包含了这场革命中一系列的主流技术要点:深度学习推荐模型、Embedding技术、推荐系统工程实现、模型评估体系、业界前沿实践…………
深度学习在推荐系统领域掀起了一场技术革命,本书是一本致力于提高一线算法工程师们工业级推荐系统实践能力的技术干货。
想要了解关于推荐系统的更多干货知识,关注AI科技大本营并在评论区分享你对本文的学习心得,我们将从中选出5条优质评论,各送出《深度学习推荐系统》一本。活动截止时间为5月13日晚8点。
推荐系统领域是深度学习落地最充分,产生商业价值最大的应用领域之一。
一些最前沿的研究成果大多来自业界巨头的实践。从Facebook 2014年提出的GBDT+LR组合模型引领特征工程模型化的方向,到2016年微软提出Deep Crossing模型,谷歌发布Wide&Deep模型架构,以及YouTube公开其深度学习推荐系统,业界迎来了深度学习推荐系统应用的浪潮。
时至今日,无论是阿里巴巴团队在商品推荐系统领域的持续创新,还是Airbnb在搜索推荐过程中对深度学习的前沿应用,深度学习已经成了推荐系统领域当之无愧的主流。
对从业者或有志成为推荐工程师的读者来说,处在这个代码开源和知识共享的时代无疑是幸运的。我们几乎可以零距离地通过业界先锋的论文、博客及技术演讲接触到最前沿的推荐系统应用。
本章的内容将由简入深,由框架到细节,依次讲解Facebook、Airbnb、YouTube及阿里巴巴的深度学习推荐系统。希望读者能够在之前章节的知识基础上,关注业界最前沿的推荐系统应用的技术细节和工程实现,将推荐系统的知识融会贯通,学以致用。
2014年,Facebook发表了广告推荐系统论文Practical Lessons from Predicting Clicks on Ads at Facebook[1],提出了经典的GBDT+LR的CTR模型结构。严格意义上讲,GBDT+LR的模型结构不属于深度学习的范畴,但在当时,利用GBDT模型进行特征的自动组合和筛选,开启了特征工程模型化、自动化的新阶段。
从那时起,诸如Deep Crossing、Embedding等的深度学习手段被应用在特征工程上,并逐渐过渡到全深度学习的网络。从某种意义上讲,Facebook基于GBDT+LR的广告推荐系统成了连接传统机器学习推荐系统时代和深度学习推荐系统时代的桥梁。此外,其在2014年就采用的在线学习、在线数据整合、负样本降采样等技术至今仍具有极强的工程意义。
2019年,Facebook又发布了最新的深度学习模型DLRM[2](Deep Learning Recommender Model),模型采用经典的深度学习模型架构,基于CPU+GPU的训练平台完成模型训练,是业界经典的深度学习推荐系统尝试。
本节先介绍Facebook基于GBDT+LR组合模型的推荐系统实现,再深入到DLRM的模型细节和实现中,一窥社交领域巨头企业推荐系统的风采。
8.1.1 推荐系统应用场景
Facebook广告推荐系统的应用场景是一个标准的CTR预估场景,系统输入用户(User)、广告(Ad)、上下文(Context)的相关特征,预测CTR,进而利用CTR进行广告排序和推荐。需要强调的是:Facebook广告系统的其他模块需要利用CTR计算广告出价、投资回报率(Return on Investment,ROI)等预估值,因此CTR模型的预估值应是一个具有物理意义的精准的CTR,而不是仅仅输出广告排序的高低关系(这一点是计算广告系统与推荐系统关键的不同之处)。Facebook也特别介绍了CTR校正的方法,用于在CTR预估模型输出值与真实值有偏离时进行校正。
8.1.2 以GBDT+LR组合模型为基础的CTR预估模型
简而言之,Facebook的CTR预估模型采用了GBDT+LR的模型结构,通过GBDT自动进行特征筛选和组合,生成新的离散型特征向量,再把该特征向量当作LR模型的输入,预测CTR。
其中,使用GBDT构建特征工程和利用LR预测CTR两步是采用相同的优化目标独立训练的。所以不存在如何将LR的梯度回传到GBDT这类复杂的训练问题,这样的做法也符合Facebook一贯的实用主义的风格。
在引入GBDT+LR的模型后,相比单纯的LR和GBDT,提升效果非常显著。从表8‑1中可以看出,混合模型比单纯的LR或GBDT模型在损失(Loss)上减少了3%左右。
表8-1 GBDT+LR模型与其他模型的效果对比
在模型的实际应用中,超参数的调节过程是影响效果的重要环节。在GBDT+LR组合模型中,为了确定最优的GBDT子树规模,Facebook给出了子树规模与模型损失的关系曲线(如图8‑1所示)。
图8-1 GBDT子树规模与模型损失的关系曲线
可以看出,在规模超过500棵子树后,增加子树规模对于损失下降的贡献微乎其微。特别是最后1000棵子树仅贡献了0.1%的损失下降。可以说,继续增加模型复杂性带来的收益几乎可以忽略不计,最终Facebook在实际应用中选择了600作为子树规模。
5.3.3节对GBDT+LR的模型更新方式做了介绍,囿于Facebook巨大的数据量及GBDT较难实施并行化的特点,Facebook的工程师在实际应用中采用了“GBDT部分几天更新一次,LR部分准实时更新”的模型更新策略,兼顾模型的实时性和复杂度。
8.1.3 实时数据流架构
为了实现模型的准实时训练和特征的准实时更新(5.3节详细介绍过推荐模型和特征的实时性相关知识),Facebook基于Scribe(由Facebook开发并开源的日志收集系统)构建了实时数据流架构,被称为online data joiner模块(在线数据整合),该模块与Facebook推荐系统其他模块的关系如图8‑2所示。
图8-2 Facebook的online data joiner与其他模块的关系
该模块最重要的作用是准实时地把来自不同数据流的数据整合起来,形成训练样本,并最终与点击数据进行整合,形成完整的有标签样本。在整个过程中,最应该注意的有以下三点。
1.waiting window(数据等待窗口)的设定
waiting window指的是在曝光(impression)发生后,要等待多久才能够判定一个曝光行为是否产生了对应的点击。如果waiting window过大,则数据实时性会受影响;如果waiting window过小,则会有一部分点击数据来不及与曝光数据进行联结,导致样本CTR与真实值不符。这是一个工程调优的问题,需要有针对性地找到与实际业务相匹配的waiting window。除此之外,少量的点击数据遗漏是不可避免的,这就要求数据平台能够阶段性地对所有数据进行全量重新处理,避免流处理平台产生的误差积累。
2.分布式架构与全局统一的action id(行为id)
为了实现分布式架构下曝光记录和点击记录的整合,Facebook除了为每个行为建立全局统一的request id(请求id),还建立了HashQueue(哈希队列)用于缓存曝光记录。在HashQueue中的曝光记录,如果在等待窗口过期时还没有匹配到点击,就会被当作负样本。Facebook使用Scribe框架实现了这一过程,更多公司使用Kafka完成大数据缓存,使用Flink、Spark Streaming等流计算框架完成后续的实时计算。
3.数据流保护机制
Facebook专门提到了online data joiner的保护机制,因为一旦data joiner由于某些异常而失效(如点击数据流由于action id的Bug无法与曝光数据流进行正确联结),所有的样本都会成为负样本。由于模型实时进行训练和服务,模型准确度将立刻受到错误样本数据的影响,进而直接影响广告投放和公司利润,后果是非常严重的。为此,Facebook专门设立了异常检测机制,一旦发现实时样本流的数据分布发生变化,将立即切断在线学习的过程,防止预测模型受到影响。
8.1.4 降采样和模型校正
为了控制数据规模,降低训练开销,Facebook实践了两种降采样的方法——uniform subsampling(均匀采样)和 negative down sampling(负样本降采样,以下简称负采样)。均匀采样是对所有样本进行无差别的随机抽样,为选取最优的采样频率,Facebook试验了1%、10%、50%、100%四个采样频率,图8-3比较了不同采样频率下训练出的模型的损失。
图8-3 不同采样频率下的模型损失
可以看到,当采样频率为10%时,相比全量数据训练的模型(最右侧100%的柱状图),模型损失仅上升了1%,而当采样频率降低到1%时,模型损失大幅上升了9%左右。因此,10%的采样频率是一个比较合适的平衡工程消耗和理论最优的选择。
另一种方法负采样则保留全量正样本,对负样本进行降采样。除了提高训练效率,负采样还直接解决了正负样本不均衡的问题,Facebook经验性地选择了从0.0001到0.1的负采样频率,试验效果如图8‑4所示。
图8-4 不同负采样频率下的模型损失
可以看到,当负采样频率在0.0250时,模型损失不仅小于基于更低采样频率训练出来的模型,居然也小于负采样频率在0.1时训练出来的模型。虽然Facebook在论文中没有做出进一步的解释,但最可能的原因是通过解决数据不均衡问题带来的效果提升。在实际应用中,Facebook采用了0.0250的负采样频率。
负采样带来的问题是CTR预估值的漂移,假设真实CTR是0.1%,进行0.01的负采样之后,CTR将会攀升到10%左右。为了进行准确的竞价及ROI预估,CTR预估模型是要提供准确的、有物理意义的CTR值的,因此在进行负采样后需要进行CTR的校正,使CTR模型的预估值的期望回到0.1%。校正的公式如(式8‑1)所示。
其中q是校正后的CTR,p是模型的预估CTR,w是负采样频率。通过负采样计算CTR的过程并不复杂,有兴趣的读者可以根据负采样的过程手动推导上面的式子。
8.1.5 Facebook GBDT+LR组合模型的工程实践
Facebook基于GBDT+LR组合模型实现的广告推荐系统虽然已经是2014年的工作,但我们仍能从中吸取不少模型改造和工程实现的经验,总结来讲最值得学习的有下面三点:
1.特征工程模型化
2014年,在很多从业者还在通过调参经验尝试各种特征组合的时候,Facebook利用模型进行特征自动组合和筛选是相当创新的思路,也几乎是从那时起,各种深度学习和Embedding的思想开始爆发,发扬着特征工程模型化的思路。
2.模型复杂性和实效性的权衡
对GBDT和LR采用不同的更新频率是非常工程化且有价值的实践经验,也是对组合模型各部分优点最大化的解决方案。
3.有想法要用数据验证
在工作中,我们往往有很多直觉上的结论,比如数据和模型实时性的影响有多大,GBDT应该设置多少棵子树,到底用负采样还是随机采样。针对这些问题,Facebook告诉我们用数据说话,无论是多么小的一个选择,都应该用数据支撑,这才是一位工程师严谨的工作态度。
8.1.6 Facebook的深度学习模型DLRM
时隔5年,Facebook于2019年再次公布了其推荐系统深度学习模型DLRM(Deep Learning Recommender Model),相比GBDT+LR,DLRM是一次彻底的应用深度学习模型的尝试。接下来将介绍DLRM的模型结构、训练方法和效果评估。
DLRM的模型结构如图8‑5所示,模型各层的作用如下。
图8‑5 DLRM的模型结构
特征工程:所有特征被分为两类:一类是将类别、id类特征用one-hot编码生成的稀疏特征(sparse features);另一类是数值型连续特征(dense features)。
Embedding层:每个类别型特征转换成one-hot向量后,用Embedding层将其转换成维度为n的Embedding向量。也就是说,将稀疏特征转换成Embedding向量。而年龄、收入等连续型特征将被连接(concat)成一个特征向量,输入图中黄色的MLP中,被转化成同样维度为n的向量。至此,无论是类别型稀疏特征,还是连续型特征组成的特征向量,在经过Embedding层后,都被转换成了n维的Embedding向量。
神经网络层(NNs层):Embedding层之上是由三角形代表的神经网络层。也就是说,得到n维的Embedding 向量后,每类Embedding还有可能进一步通过神经网络层做转换。但这个过程是有选择性的,根据调参和性能评估的情况来决定是否引入神经网络层进行进一步的特征处理。
特征交互层(interactions层):这一层会将之前的Embedding两两做内积,再与之前连续型特征对应的Embedding连接,输入后续的MLP。所以这一步其实与3.5节介绍的PNN一样,目的是让特征之间做充分的交叉,组合之后,再进入上层MLP做最终的目标拟合。
目标拟合层:结构图中最上层的蓝色三角代表了另一个全连接多层神经网络,在最后一层使用 sigmoid函数给出最终的点击率预估,这也是非常标准的深度学习模型输出层的设置。
从DLRM的模型结构中可以看出,模型结构并不特别复杂,也没有加入注意力机制、序列模型、强化学习等模型思路,是一个非常标准的工业界深度学习推荐模型。这与Facebook务实的技术风格相关,也说明在海量数据的背景下,简单的模型结构就可以发挥不俗的作用。
8.1.7 DLRM模型并行训练方法
作为一篇来自工业界的论文,模型的实际训练方法往往可以让业界同行收益颇多。Facebook的数据量之大,单节点的模型训练必然无法快速完成训练任务,因此模型的并行训练就是必须采用的解决方法。
简单来说,DLRM融合使用了模型并行和数据并行的方法,对Embedding部分采用了模型并行,对MLP部分采用了数据并行。Embedding部分采用模型并行的目的是减轻大量Embedding层参数带来的内存瓶颈问题。MLP部分采用数据并行可以并行进行前向和反向传播。
其中,Embedding做模型并行训练指的是在一个device(设备)或者计算节点上,仅保存一部分Embedding层参数,每个设备进行并行mini batch梯度更新时,仅更新自己节点上的部分Embedding层参数。
MLP层和特征交互层进行数据并行训练指的是每个设备上已经有了全部模型参数,每个设备利用部分数据计算梯度,再利用全量规约(AllReduce)的方法汇总所有梯度进行参数更新。
8.1.8 DLRM模型的效果
DLRM的训练是在Facebook自研的AI平台Big Basin platform上进行的,平台的具体配置是Dual Socket Intel Xeon 6138 CPU@2.00GHz +8个Nvidia Tesla V100 16GB GPUs。Facebook Big Basin AI硬件平台示意图如图8-6所示。
图8‑6 Facebook Big Basin AI硬件平台
很明显,Big Basin platform是一个高性能的CPU+GPU的组合平台,没有采用类似6.3节介绍的Parameter Server的分布式硬件架构。这节约了大量网络通信的成本,但在扩展性方面没有Parameter Server灵活。
在性能的对比上,DLRM选择了谷歌2017年提出的DCN作为baseline(性能基准)。通过对比本节介绍的DLRM和3.6节介绍的DCN可以发现,DLRM和DCN的主要区别在于特征交叉方式的不同,DLRM采用了不同特征域两两内积的交叉方式,而DCN采用了比较复杂的cross layer的特征交叉方式。以Criteo Ad Kaggle data为测试集,二者的性能对比如图8‑7所示。
图8-7 DLRM与DCN性能对比
可以看出,DLRM在准确率指标上稍胜一筹。当然,模型的性能与数据集的选择、参数的调优都有很大关系,而且DLRM在Adagrad训练方式下的优势已经微乎其微,这里的性能评估读者仅做参考即可。
8.1.9 Facebook深度学习推荐系统总结
无论是GBDT+LR组合模型,还是最新的DLRM模型,Facebook的技术选择总给人非常工业化的感觉,简单直接,以解决问题为主。虽然从学术角度看模型的创新性不足,但业界的从业者却能从中借鉴非常多的工程实践经验。DLRM模型是非常标准且实用的深度学习推荐模型。如果公司刚开始从传统机器学习模型转到深度学习模型,则完全可以采用DLRM作为标准实现。而GBDT+LR组合模型传递出的特征工程模型化及模型组合的思路,对推荐系统技术发展有更深远的影响。
赠书活动
想要了解关于推荐系统的更多干货知识,关注AI科技大本营并在评论区分享你对本文的学习心得,我们将从中选出5条优质评论,各送出《深度学习推荐系统》一本。
▼ 扫码或点击阅读原文获取本书详情 ▼
相关文章:

使用 CAS 在 Tomcat 中实现单点登录
CAS 介绍 CAS 是 Yale 大学发起的一个开源项目,旨在为 Web 应用系统提供一种可靠的单点登录方法,CAS 在 2004 年 12 月正式成为 JA-SIG 的一个项目。CAS 具有以下特点: 开源的企业级单点登录解决方案。CAS Server 为需要独立部署的 Web 应用。…
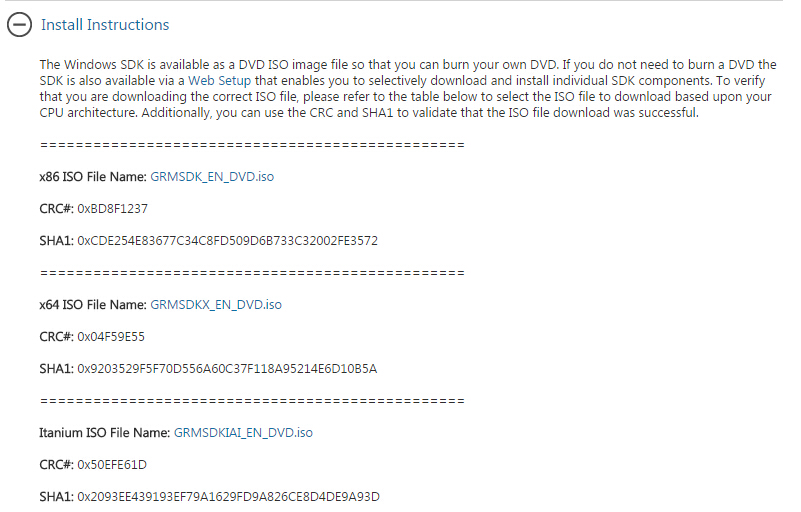
Windows SDK 7.1 (包含directshow)安装配置
最近一直在做毕业设计的事情,需要利用directshow进行视频开发,但是现在单独的directshow包已经没有了,从directx9.0c开始directshow和directx分开发布,现在的directshow已经集成到windows SDK当中了。 但是说实话,由于…
20行Python代码实现视频字符化
来源 | ZackSock(ID:ZackSock)我们经常在B站上看到一些字符鬼畜视频,主要就是将一个视频转换成字符的样子展现出来。看起来是非常高端,但是实际实现起来确实非常简单,我们只需要接触opencv模块,就能很快的实…

隔年的衣服发黄处理方法
1.用菠菜水,将菠菜煮水五分钟,然后用菠菜水除旧衣服黄渍特灵 2.用淘米水泡洗就可以了 3.用温盐水泡上20分钟再洗 4.如果是白颜色衣服的话,你不妨在洗衣服的时候放一点蓝色墨水或者用漂白 转载于:https://blog.51cto.com/wanghu2009/519490

linux监控(陆续补充)
一 定时任务for user in $(cat /etc/passwd | cut -f1 -d:);do crontab -l -u $user;done是否有用户执行了隐藏定时任务? 是否有某个任务正在备份二 网络sysctl -a | grep xx 查看网络内核参数信息ss -s 显示所有存在的连接cat /proc/interrupts 查看中断请求是否…

自绘按钮的实现
如果你希望能够在自己的程序中表现出新意,那么你一定不会仅仅满足于MFC提供那些标准控件。这时,我们就必须自己另外多做些工作了。就改变控件外观这一点来说,主要是利用控件的自绘功能(Owner Draw)实现的。本篇将和各位…
24/4毕业设计小记
折腾了很久了,关于我的毕业设计,一直就没有时间来写博客,今天感冒了,趁着思路不太好的时候就写一篇博客吧!写什么好呢,就写基于vlc sdk的播放器开发吧! 我的项目是关于windows和linux两个平台的…
AI修复100年前晚清影像喜提热搜,这两大算法立功了
整理 | 夕颜来源 | CSDN(ID:CSDNnews)昨天,一条“100 年前北京晚清的影像”喜提热搜,博主用 AI 技术修复了一段 10 多分钟的古董视频,使得 100 多年前老旧的黑白影像变得更加清晰,甚至有了颜色。…
ls和find命令查找的一些小技巧
看到老男孩老师的博客有一篇是要写用三种方法查找修改文件;想来想去后面回去看一下ls和find命令的使用技巧,非常实用这里总结一下、省得每次用都百度:ls命令总结:-t 可以查看相关修改的时间-l 每行显示一个条目-h 可以结合显示文件…

[Android]ListView性能优化之视图缓存
前言ListView是Android中最常用的控件,通过适配器来进行数据适配然后显示出来,而其性能是个很值得研究的话题。本文与你一起探讨Google I/O提供的优化Adapter方案,欢迎大家交流。声明 欢迎转载,但请保留文章原始出处:) 博客园&am…
在商业中,如何与人工智能建立共生关系?
作者 | Daniel Williams译者 | 风车云马 责编 | Carol出品 | AI科技大本营(ID:rgznai100)如今这个时代,不管是有意还是不经意,我们都在接触或使用人工智能。在我们的日常生活和商业实践中,各种在线的设备、云计算和边缘…
H.264 基础及 RTP 封包详解
一. h264基础概念 1、NAL、Slice与frame意思及相互关系 1 frame的数据可以分为多个slice. 每个slice中的数据,在帧内预测只用到自己slice的数据, 与其他slice 数据没有依赖关系。 NAL 是用来将编码的数据进行大包的。 比如,每一个slice 数…
点分十进制IP校验、转换,掩码校验
/****************************************************************************** 点分十进制IP校验、转换,掩码校验* 声明:* 本文主要记录如何对IP、掩码进行转换、校验等相关内容,注意大小端的问题。** …
再见 Python,Hello Julia!
作者 | Rhea Moutafis译者 | 苏本如,责编 | 夕颜头图 | CSDN 下载自视觉中国出品 | CSDN(ID:CSDNnews)随着Python的停滞不前,一个新的热门竞争对手崛起了。如果Julia对你来说仍是个谜,别担心。不要误会我的…
【流媒體】jrtplib—VS2010下RTP开源协议库JRTPLIB3.9.1编译
一、JRTPLIB简介 老外用C编写的开源RTP协议库,用来进行实时数据传输,可以运行在 Windows、Linux、 FreeBSD、Solaris、Unix和VxWorks 等多种操作系统上,主页为:http://research.edm.uhasselt.be/~jori/page/index.php?nMain.Home…
揭露Windows中各种不老实的服务
使用电脑经常会碰到各种各样的问题,比如:网上邻居上看不到一个邻居、无法拨号上网、电脑关机速度变慢等,在你尝试了各种方法还没有解决时,不妨到“控制面板→管理工具→服务”中查一查,没准故障的根源就在这里。 …
文本相似度的计算
文本相似度的计算方法有很多,这里简单记录一下 传统的VSM模型: 计算文本相似度的时候主要是使用tfidf来协助生成文档向量 整个文档集合有多少词,就是多少维度 每个文档中的词用tfidf来生成权重,用权重来表示文档的向量 生成向量后…
vc picture控件载入背景图,随控件大小改变
在mfc里,想要在Picture控件中载入一张图片有两种方法:静态的和动态的。静态的方法就是图片先载入资源(.rc)文件中,拥有一个唯一的ID;动态的方法就是制定图片的路径名即可。 当然这样的方法网上一搜有很多&…
真没想到,Python还能实现5毛特效
来源 | ZackSock(ID:ZackSock)图源 | 视觉中国Python牛已经不是一天两天的事了,但是我开始也没想到,Python能这么牛。前段时间接触了一个批量抠图的模型库,而后在一些视频中找到灵感,觉得应该可以通过抠图的…
第八章 VLSM
VSLM(variable length subnet mask)------------可变长长度子网掩码 对于点对点链路而言,最好的子网掩码是:255.255.255.252对于lan而言,好的子网掩码可能是255.255.255.192。vlsm的两个好处:在大型网络中高效地使用寻址ÿ…
Androidstudio下Generate signed apk提示Error: Expected resource of type id [ResourceType]解决办法...
只需要在报错位置所在的类上面添加: SuppressWarnings("ResourceType") 即可实现Generate signed apk。
对话框窗口最大最小化
mfc里,基于对话框的窗口,具有最大最小化的属性设置。在Border属性里选择Resizing,然后在Maximize和Minimize中选择true。在窗体当中随便拖几个控件,然后运行,此时点击最大化会发现,整个窗体的大小是变大了&…
4场直播,哈工大、亚马逊等大咖为你带来机器学习与知识图谱的内容盛宴
机器学习和知识图谱是当今技术领域的热门话题,随着相关技术的不断发展,无论是对两类技术单独的探讨,还是将机器学习和知识图谱相结合的尝试,都在吸引越来越多的关注。5月16日下午,来自亚马逊、墨奇科技、Second State、…
【失败的尝试】C++中使用string进行switch判断
贴出错误代码: #include <iostream>#include <string>using namespace std;void main(){ string str; cin>>str; switch(str) { case "ab": cout<<"one"<<endl; break; case &…

springmvc 拦截器、国际化、验证
2019独角兽企业重金招聘Python工程师标准>>> springmvc 拦截器 继承了HandlerIntercepter的类可以作为拦截器类: package com.yawn.intercepter;import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse;import o…
由MessageBox和AfxMessageBox的使用异同所感
我记得刚开始学图形界面编程的时候,接触的最早的一个函数应该就是MessageBox,之前都一直是控制台程序,突然能运行蹦出一个对话框感觉还是很新鲜的。当时还利用MessageBox写一些恶搞程序,利用上面的yes or no 按钮进行判断等等。但是说实话感觉…
iRobot的30年成长史
作者 | Colin Angle译者 | 苏本如,编辑 | 郭芮题图视觉中国出品 | AI科技大本营(ID:rgznai100)建造一个漫游者,把它送上月球,出售电影版权。这是我们在1990年开始iRobot时的第一个商业模式,我们…
iPhone开发:通过NSURLRequest获得服务器返回的http header和http status
HTTP连接的头信息包括在NSHTPURLResponse类中。如果你拥有一个NSHTTPURLResponse变量,你可以通过发送allHeaderFields信息,轻而易举地获取以NSDictionary形式保存的头信息。对于一个同步请求 – 由于会引发阻塞所以不推荐使用 – 是很容易初始化一个NSHT…
今天开始记录自己苹果开发博客旅程!~
做ios开发也蛮久了,现在才想到要自己开个博客,然后记录点自己平时工作学习中遇到的各种问题以及解决后的心得。现在公司的app第一个版本已经上线了,更加期待以后的发展和更迭。还记得刚进公司接受项目时那种忐忑不安的心理,现在想…

一步一步实现扫雷游戏(C语言实现)(三)
使用WIN32API连接窗口 此项目相关博文链接 一步一步实现扫雷游戏(C语言实现)(一) 一步一步实现扫雷游戏(C语言实现)(二) 一步一步实现扫雷游戏(C语言实现)(三) 一步一步实现扫雷游戏(…