达摩院NLP团队斩获六项世界冠军背后,让AI没有难懂的语言
2018年末,BERT横空出世,它采用自编码对句子进行表示,通过预测掩盖词和上下句之间的关系作为语言模型学习任务,使用更多的数据,更大的模型,在多个自然语言处理(NLP)任务中显著超越之前的结果。这一年被视为预训练语言模型的元年。
2019至今,预训练语言模型呈现百花齐放、百家争鸣态势。其中,既有将自回归和自编码结合的生成式语言模型,也有将多种语言融合的预训练语言模型,更有将语言和图像等模态融合的多模态语言模型。
在阿里巴巴达摩院语言实验室负责人司罗看来,预训练语言模型技术最近的进展极大地推动了自然语言智能的发展,“越来越多的应用与深度语言模型能够结合起来,在业务实践中取得了比较大的实际落地效果。”
与此同时,带着各自的预训练语言模型在各大数据集上同台切磋,成为各大科技公司展现自身技术实力的一大舞台。
当然,阿里巴巴也不例外。近日,达摩院NLP团队自研的预训练模型框架ALICE (ALIbaba Collections of Encoder-decoders), 包括多语言模型VECO、多模态语言模型StructVBERT、生成式语言模型PALM等6大自研模型相继刷新了世界纪录,在预训练模型的竞技中处于领先地位。挑战榜单只是为了验证了技术的领先性,达摩院NLP团队更重要的任务是把模型整合到阿里的技术平台,并应用到阿里内部和外部客户的产品和业务中,验证技术为产品和业务带来的更大价值。
那么,阿里巴巴达摩院成立三年来究竟如何收获技术价值?CSDN与达摩院语言技术实验室三位技术专家司罗、黄非和黄松芳进行了交流,他们从预训练语言模型、阿里NLP技术平台以及行业应用实践三大层面出发,描绘了一幅阿里NLP的全景图。
全面布局预训练语言模型,推动NLP新范式落地
预训练语言模型是自然语言处理的新范式,它可以帮助机器像人类一样理解文本。在“预训练-精调”的框架下,模型可以通过“预训练”阶段从大规模文本中学习到词和词的搭配关系以及句子之间的上下文关系等语言通用知识,继而通过“精调”阶段学习到领域任务特定知识,从而在大量的下游任务中达到更好性能。
从在开源数据集上进行评测到业务实践中的价值体现,预训练语言模型都被证明能够显著提高模型性能和算法效果。同时,从预训练语言模型得到的文本向量表示可以与其他模态下的向量表示很好地结合,从而达到多模态建模,理解并在多个跨模态场景得以应用。
阿里巴巴作为国内最早投入预训练语言模型研究的科技公司之一,目前已经实现了技术的全面布局,达摩院已在通用语言模型StructBERT基础上,拓展到多语言、生成式、多模态、结构化、知识驱动等方面,并在最近全面登顶包括多语言XTREME、多模态VQA在内的多个国际赛事和榜单。
据介绍,参与竞赛的6项自研AI技术均采用了模仿人类的学习模式,并针对领域特性进行了技术革新,全方位提升了机器的语言理解能力,部分能力甚至已超越人类。目前,这些技术均已大规模应用于阅读理解、机器翻译、人机交互等场景。
其中,达摩院NLP团队在BERT的基础上提出优化模型StructBERT,能让机器更好地掌握人类语法,加深对自然语言的理解。StructBERT通过在句子级别和词级别引入两个新的目标函数,打乱句子/词的顺序并使模型对其进行还原的方式,使得模型学习到更强的语言结构信息,使用StructBERT模型好比给机器内置一个“语法识别器”。其相关成果论文已被ICLR-2020收录。
该模型以平均分90.6分曾在自然语言处理领域权威数据集GLUE Benchmark中夺冠。
在StructBERT基础上,达摩院NLP团队进一步提出融入图像模态知识的预训练语言模型StructVBERT,它能同时理解文本与图像模态的信息,并挖掘二者间的关联以进行有效推理。
该模型好比给机器内置了隐式的“图像翻译器”,使机器能以同样的方式理解文本和图像信息,并基于两种模态的信息进行有效地内容整合与理解,显著提高图文问答准确率。
在多模态视觉问答与推理VQA Challenge 2020 Test-Standard数据集上,达摩院NLP团队的多模态语言模型StructVBERT以76.36分排名第一。
同样基于StructBERT的模型还有结构化语言模型StructuralLM。它充分利用图片文档数据的二维位置信息,并引入文本框位置预测的预训练任务,帮助模型感知图片不同位置之间词语的关系,这对于理解真实场景中的图片文档十分重要。
StructuralLM模型目前在Document VQA榜单上排名第一,同时在表单理解FUNSD数据集和文档图片分类RVL-CDIP数据集上也超过现有的预训练模型。
VECO模型(Variable Encoder-decoder,可变的编码-解码器模型)则将单语言模型扩展到了100多种语言,并借鉴于“积木”搭建的可变化(Variable)思想,通过重新整合编码器(Encoder)和解码器(Decoder)的核心组件,这使得训练的模型最终在Fine-tune阶段可以选择需要的模块来组合,从而形成适用于针对NLU(自然语言理解)任务的Encoder架构和针对NLG(自然语言生成)任务的Encoder-Decoder架构。
其中的亮点在于,这种预训练进行“整合”并在Fine-tune阶段进行“拆分”的思想完全脱离了传统的Pretrain-Finetune的范式,不仅在业界首次提出这种新的模型训练范式,而且在多个评测和下游任务中验证了这种方法的有效性。比如该模型在多语言预训练模型的测评榜单XTREME上以平均分73.9排名第一,超过Google的mBERT和Facebook的XLM-R等主流多语言模型。
在生成式语言模型方面,达摩院NLP团队创新性提出了PALM (Pre-training an Autoencoding & autoregressive Language Model),它将预测后续文本作为其预训练目标,而非重构输入文本。它在一个模型中使用自编码方式来编码输入文本,同时使用自回归方式来生成后续文本。这种预测后续文本的预训练促使该模型提高对输入文本的理解能力,从而在下游的各个语言生成任务上取得更好的效果。
目前,这个新生成模型PALM在MS MARCO自然语言生成NLG公开评测上取得了排行榜第一,同时在摘要生成标准数据集CNN/DailyMail和Gigaword上也超过了现有的各个预训练生成语言模型。该模型可被用于问答生成、文本复述、回复生成、文本摘要、Data-to-Text等生成应用上。
篇章排序作为检索式问答的重要一环,可以结合机器阅读理解能力,帮助构建集生成、检索与抽取一体的闭环搜索问答整体链路。
达摩院NLP团队提出的统一的编码器-解码器模型(UED, United Encoder-Decoder)通过预训练一套整体的编码器-解码器网络同时进行问题生成和段落排序,使模型具备更强的段落摘要与文本匹配能力,并利用二阶段Fine-tuning策略进一步提升粗排召回率。
在MS MARCO榜单上,达摩院NLP团队在继核心机器阅读理解任务多次夺冠后,进一步刷新篇章排序任务榜单结果,并于去年的国际标准信息检索评测TREC 2019 Deep Learning Track的段落检索和文档检索任务上均取得第一名。
随着数据量及模型的极速膨胀,大规模深度学习训练的收敛变得极具挑战性,阿里巴巴内部计算资源和训练平台提供了诸如高效混合精度计算、快速自适应收敛方法、优化通信时间等丰富的训练支持,为突破多项NLP技术指标打下基础。
为了更好地应用上述大部分模型,阿里内部还有一个语言模型平台。在这个平台上,不管是通用语言模型还是多语言、多模态模型,阿里的各个团队可以做领域模型或任务模型的训练,进行模型的蒸馏和测试,并直接部署上线调用。目前,阿里巴巴集团内超过100多个业务部门都在利用该平台来搭建业务应用,日均调用量超过9亿,已经有超过50个活跃场景。
阿里巴巴在这些预训练语言模型领域的突破,将进一步使AI像人一样学习新知识成为可能;更重要的是,在特定领域的应用场景落地上,将帮助AI技术变得更加智能。当然,为了让现有模型和技术产生更大的影响力,阿里技术专家透露,上述模型也会陆续对外开源。
预训练模型对大量计算资源的要求限制了诸多中小公司的应用落地,而如何把语言模型更好地应用在不同的行业和场景中,还需要更多的摸索和尝试,也还有很长一段路要走,阿里技术专家称,未来预训练语言模型会走向更大、更快、更强。阿里达摩院也将在预训练语言模型上持续发力,未来将会深入研究超大模型训练以及联合统一各类任务预训练模型。
打造世界顶级NLP技术体系,让AI没有难懂的语言
阿里在模型问题上做了很多突破,但创新的本质是驱动业务创新并带来业务价值。因此,针对真实场景的多种多样的需求,达摩院不仅建设了深度语言技术体系全面赋能业务,更通过平台化的方式输出NLP技术能力。
其中,NLP技术平台是技术体系化的重要一环。
首先是阿里自然语言技术平台。包括底层数据层,收集了大量的自然语言相关数据,包括分词词性数据,实体语料库、新闻语聊库、情感语聊库等;以及基础算法层,从词法分析到句法分析、语义分析、篇章分析等基础算法。通过上述基础技术,构建了内容搜索、内容推荐、问答、情感分析、意图识别等垂直技术。这些技术结合起来,支撑了很多跟NLP相关的应用,如搜索、推荐、广告、客服、物流等相关工作。
自然语言技术平台现在每天有超过1000个业务方使用,每天的调用量数万亿次。
其次是翻译技术平台。包括底层的语料平台,还有多语言分词、实体识别等多语言NLP相关技术,核心的机器翻译技术包括结合知识的翻译技术,多语言多领域统一框架的翻译技术以及语音,图片,视频等多模态翻译等技术,上述底层技术支撑着相关翻译场景的技术解决方案。
目前,该平台几十个业务方的日调用量约10亿次,帮助创造了数亿美元的国际跨境贸易和其他国际业务商业价值。
根据达摩院提供的数据,多语言NLP和翻译技术每年累计为集团30+国际化核心业务场景提供服务,AliNLP平台日均累计调用量超过数万亿次,特别在搜索query改写、相关性匹配、排序等场景,有效的降低了搜索零少结果,以及提升搜索广告的点击转化。
在几位专家看来,自然语言智能本身的研发,甚至是AI技术的整体研发,如果要让它产生更大的技术落地价值,就需要在场景、数据、知识和算法技术之间进行循环迭代。
阿里内部有着丰富的业务场景,同时通过阿里云还会接触到广阔的外部场景,会提供很多行业场景相关的数据和知识,从而建设更加完善、高效、准确的自然语言基础技术、翻译技术和应用技术。
典型的场景如文本内容审核。互联网上内容良莠不齐,需要对一些涉黄、涉暴等违规内容进行审核。其挑战在于,互联网文字内容涉及到大量的的音变和形变。而为了识别长文本,达摩院NLP团队也加入了语义理解和更深度的综合识别能力。
目前,阿里的NLP技术早已渗透至大众生活的方方面面,如电商、城市大脑,教育、医疗、能源,通信、司法、内容等,这些领域都在因为AI的力量变得更加智能。
总体而言,达摩院在预训练语言模型领域的突破,在一定程度上打破了NLP技术在业务场景落地的困境,同时,其丰富的业务场景转而为预训练语言模型及其NLP技术平台的搭建提供了绝佳的实践土壤。
再硬核的技术终要走向落地,达摩院NLP技术已逐步实现从单点技术到体系化能力的延伸,而现在,他们正在朝着更广阔的目标前行,让NLP技术普惠各行各业,让AI没有难懂的语言。
更多精彩推荐
GitHub多次霸榜,两个月拿下10000+Star,他说基础软件不开源必死无疑
达摩院NLP团队斩获六项世界冠军背后,让AI没有难懂的语言
万字长文总结机器学习的模型评估与调参 | 附代码下载
“Talk is cheap, show me the code”你一行代码有多少漏洞?
科普 | 定义 Eth2.0 中的验证者质量
相关文章:

提权巧用RAR.EXE
rar.exe是什么?它就是大名鼎鼎的winrar自带的命令行解压程序。在提权中我们经常要下载各种敏感文件,比如:SU目录。你想一下,如果su目录文件这么多,难道你要一个个的下载??这明显就很麻烦,有了ra…
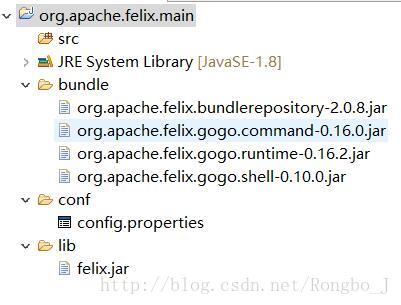
OSGI企业应用开发(二)Eclipse中搭建Felix运行环境
上篇文章介绍了什么是OSGI以及使用OSGI构建应用的优点,接着介绍了两款常用的OSGI实现,分别为Apache Felix和Equinox,接下来开始介绍如何在Eclipse中使用Apache Felix和Equinox搭建OSGI运行环境。 一、搭建Apache Felix运行环境 上篇文章中介绍…
马斯克脑机接口、BrainOS相继发布,不努力也能有出路了
作者 | 马超责编 | Carol封图 | CSDN 下载自视觉中国在北京时间的8月29日凌晨,钢铁侠埃隆马斯克投资1亿多美元的脑机接口初创公司公司Neuralink(http://www.neurolink.company/)进行了一次现场发布会,展示新一代的脑机接口设备。这…
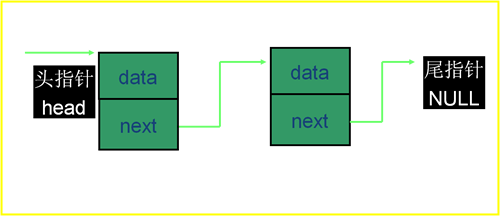
C语言单向链表的实现
一个简单结点的结构体表示为:struct note{int data; /*数据成员可以是多个不同类型的数据*/struct note *next; /*指针变量成员只能是-个*/}; 一个简单的单向链表的图示1.链表是结构、指针相结合…
Java开发常用Linux命令
1.查找文件 find / -name filename.txt根据名称查找/目录下的filename.txt文件。 find . -name "*.xml"递归查找所有的xml文件 find . -name "*.xml" |xargs grep "hello world"递归查找所有文件内容中包含hello world的xml文件 grep -H spring …
数据库开发基本操作-安装Sql Server 2005出现“性能监视器计数器要求”错误解决方法...
今天在安装SQL Server 2005时,出现“性能监视器计数器要求”错误,因为以前出现过这种错误,得到了解决。今天又又出现这种错误,但并不是很清楚当时的解决办法,所以这次把解决方法记录下来,供自己以后参考&am…
华为昇腾师资培训沙龙·南京场 |华为昇腾 ACL 语言开发实践全程干货来了!看完就实操系列...
自今年疫情以来,AI 技术加速进入了人们的视线,在抗疫过程中发挥了重要作用,产业发展明显提速,我国逐步走出了一条由需求导向引领商业模式创新、市场应用倒逼基础理论和关键技术创新的发展道路,AI 人才的争夺战也正式打…

设计模式之C#实现---Builder
作者:cuike519的专栏 http://blog.csdn.net/cuike519/我们将要介绍一个和它比较像的创建型模式 Builder (至于关于 Builder 的详细内容您可以参考 GOF 的书,在这里不重复了。)。在 GOF 的书里 Builder 的目的是这样的࿱…

微信小程序开发之不能使用eval函数的问题
2019独角兽企业重金招聘Python工程师标准>>> 一 eval函数问题 JavaScript中的eval函数是颇受开发者争议的问题之一,问题主要在于其可能导致的不安全性。有关此方面问题,在此不再赘述,读者可能很容易地浏览到许多介绍性文章。 但是…

设计模式之C#实现--FactoryMethod
作者:cuike519的专栏 http://blog.csdn.net/cuike519/工厂方法的目的很明确就是定义一个用来创建对象的接口,但是他不直接创建对象,而由他的子类来创建,这样一来就将创建对象的责任推迟到了该接口的子类中,创建什么类…
美国AI博士指出,自学Python到底能做什么
我见过市面上很多的 Python 讲解教程和书籍,他们大都这样讲 Python 的:先从 Python 的发展历史开始,介绍 Python 的基本语法规则,Python 的 list, dict, tuple 等数据结构,然后再介绍字符串处理和正则表达式࿰…
关于微博溯源的后续问题
1、在进行关键词搜索的时候,如何分词,我们不可能用语料库进行匹配,已没有语料可以学习。 2、关于转折点的寻找。目前我们使用高级搜索,从当前时间往前推,根据搜索到微博的条数变化,确定时间发生具体时间&am…
python3的数据类型以及模块的含义
python3的数据类型以及模块的含义购物车转载于:https://blog.51cto.com/11834445/1884901

设计模式之C#实现---- ProtoType
作者: cuike519的专栏 http://blog.csdn.net/cuike519/该模式的意图是:用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。那么首先我们应该已经有了一个对象,同时这个对象还支持自我复制(科隆&…
快速排序(二)最后修改
1 //2012-07-162 void quickSort(element list[], int left, int right)//快速排序3 {4 int ileft;5 int jright;6 7 if(i > j) //判断需要i<j8 return;9 10 element templist[i]; 11 12 while(i<j) 13 { 14 while(i<j …
性能超越GPU、FPGA,华人学者提出软件算法架构加速AI实时化
作者 | 王言治,美国东北大学电子与计算机工程系助理教授出品 | AI科技大本营(ID:rgznai100)近年来,机器学习(Machine Learning)领域的研究和发展可谓是与日俱新,各式各样与机器学习相关的研究成果与应用层出不穷&#…
PHP获取毫秒时间戳,利用microtime()函数
PHP获取毫秒时间戳,利用microtime()函数 php本身没有提供返回毫秒数的函数,但提供了一个microtime()函数,借助此函数,可以很容易定义一个返回毫秒数的函数。php的毫秒是没有默认函数的,但提供了一个microtime()函数&am…
.NET中添加控件数组
作者:cuike519的专栏 http://blog.csdn.net/cuike519/添加控件数组 在.NET里面我好像没有找到有关于控件数组的说明,但是前两天偶在网上看到了一篇关于如何在.NET里面实现控件数组的文章(该文章请参看MSDN).记得大学的时候在使用VB的时候使用过控件数组,可是到了…
如何在机器学习的框架里实现隐私保护?
编者按:数据时代,人们从技术中获取便利的同时,也面临着隐私泄露的风险。微软倡导负责任的人工智能,因此机器学习中的隐私保护问题至关重要。本文介绍了目前机器学习中隐私保护领域的最新研究进展,讨论了机密计算、模型…

函数图像轻松画:教你用永中图象
函数图像轻松画:教你用永中图象 函数图像轻松画:教你用永中图象转载于:https://blog.51cto.com/premium/933220
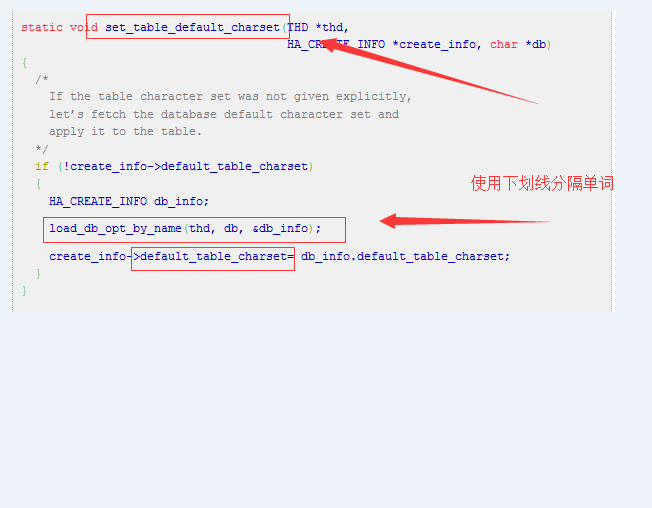
c语言语系的命名风格和java系命名风格
c语言系的命名风格:单词之间使用下划线分隔。如上图。 java语言是另外一个系,javascript属于java语系(当年就是想借助java的名气所以命名javascript)。java语系是驼峰式命名法,如getElementById()。如果使用c语系命名风格则使用下划线分隔 ge…
全国IP地址分配表
xa.sn.cn,西安公众网,西安,陕西,CN,202.100.0.* xa.sn.cn,西安公众网,西安,陕西,CN,202.100.1.* xa.sn.cn,西安公众网,西安,陕西,CN,202.100.2.* xa.sn.cn,西安公众网,西安,陕西,CN,202.100.3.* xa.sn.cn,西安公众网,西安,陕西,CN,202.100.4.* xa.sn.cn,西安公众网,西安,陕西,C…
神同步!美国三地 Tesla 车主,自动驾驶都撞了警车
来源 | HyperAI超神经(ID:HyperAI)内容概要:上周在美国北卡州发生了一起交通事故,一辆自动驾驶模式下的 Tesla 撞击了停靠在路边的警车,虽未造成人员伤亡,但车辆损毁严重。事故调查中发现&#…
Q币才是腾讯真正的世界级产品
本文受《虚拟货币将是下一个大平台》启发而来。何玺认为,腾讯Q币本身就具有全球化虚拟货币的基因。 日前,有媒体报道了Pocket Change获得了由Google Ventures领投的500万美元A轮融资,使其融资总额达到640万美元。 Pocket Change是一个为Andro…

解决Office互操作错误检索COML类工厂中 CLSID为 {xxx}的组件时失败,原因是出现以下错误: 80070005...
Excel为例(其他如Word也适用)文件数据导入时报出以下错误: 检索COML类工厂中 CLSID为 {00024500-0000-0000-C000-000000000046}的组件时失败,原因是出现以下错误: 80070005,如图所示: 可以看到报出的异常类型为:UnauthorizedAcces…
再论制硬盘逻辑锁
姜卓睿 雷必武 一、序言 由于教学工作需要,本人在参看了贵刊98年第4期《硬盘逻辑锁技术研究及应用》与99年第3期《解开硬盘逻辑死锁的一种有效方法》的文章之后,决定以同类方法尝试一下,结果未获得成功,又“苦于”没有KV300 L …
我国科学家成功研制全球神经元规模最大的类脑计算机
来源 | 之江实验室(ID:zhejianglab)9月1日,浙江大学与之江实验室举办成果发布会,共同发布我国首台基于自主知识产权类脑芯片的类脑计算机(Darwin Mouse)。浙江大学校长吴朝晖院士出席并讲话。他…
批处理获取目录下所有文件名
由于要处理一些文件,找了个这样的批处理: 输出目录及子目录下所有的jpg图片的文件名,不含扩展名 1 echo off 2 cd.>List.txt 3 for /f "delims" %%i in (dir /s/a-d /b *.jpg) do >>List.txt echo %%~ni>>JustName.…
1001: 整数求和
描述:求两个整数之和输入:输入数据只包括两个整数A和B。输出:两个整数的和。样例输入:1 2样例输出:3考点:运算符代码: #include <stdio.h> int main() {int a,b;int c;scanf("%d",&a);scanf("%d",&b);cab;printf("%d",…

ASP.NET 2.0 中的新增安全功能
发布日期: 8/26/2004| 更新日期: 8/26/2004Stephen Walther Microsoft Corporation 适用于: Microsoft ASP.NET 2.0 Microsoft ASP.NET framework Microsoft SQL Server Microsoft Visual Studio .NET 摘要:ASP.NET 2.0 包含一些新…