Python让你成为AI 绘画大师,简直太惊艳了!(附代码))
作者 | 李秋键
责编 | 李雪敬
头图 | CSDN下载自视觉中国
引言:基于前段时间我在CSDN上创作的文章“CylcleGAN人脸转卡通图”的不足,今天给大家分享一个更加完美的绘制卡通的项目“Learning to Cartoonize Using White-box Cartoon Representations”。
首先阐述下这个项目相对之前分享的卡通化的优势:
1、普遍适用性,相对于原来人脸转卡通而言,这个项目可以针对任意的图片进行卡通化转换,不再局限于必须是人脸图片或一定尺寸;
2、卡通化效果更好。
具体效果如下图可见:
其主要原理仍然是基于GAN网络,但主要三个白盒分别对图像的结构、表面和纹理进行处理,最后得到了优于其他方法的图像转化方法 CartoonGAN。
而今天我们就将借助论文所分享的源代码,构建模型创建自己需要的人物运动。具体流程如下。
实验前的准备
首先我们使用的python版本是3.6.5所用到的模块如下:
argparse 模块用来定义命令行输入参数指令。
Utils 是将其中常用功能封装成为接口。
numpy 模块用来处理矩阵运算。
Tensorflow 模块创建模型网络,训练测试等。
tqdm 是显示循环的进度条的库。
网络模型的定义和训练
因为不同的卡通风格需要特定任务的假设或先验知识来开发对应的算法去分别处理。例如,一些卡通工作更关注全局色调,线条轮廓是次要问题。或是稀疏干净的颜色块在艺术表达中占据主导地位。但是针对不同的需求,常见模型无法有效的实现卡通化效果。
故在文章中主要通过分别处理表面、结构和纹理表示来解决这个问题:
(1)首先是网络层的定义:
1.1 定义resblock保证在res block的输入前后通道数发生变化时,可以保证shortcut和普通的output的channel一致,这样就能直接相加了。
def resblock(inputs, out_channel=32, name='resblock'):with tf.variable_scope(name):x = slim.convolution2d(inputs, out_channel, [3, 3], activation_fn=None, scope='conv1')x = tf.nn.leaky_relu(x)x = slim.convolution2d(x, out_channel, [3, 3], activation_fn=None, scope='conv2')return x + inputs
1.2 定义生成器函数:
def generator(inputs, channel=32, num_blocks=4, name='generator', reuse=False):with tf.variable_scope(name, reuse=reuse):x = slim.convolution2d(inputs, channel, [7, 7], activation_fn=None)x = tf.nn.leaky_relu(x)x = slim.convolution2d(x, channel*2, [3, 3], stride=2, activation_fn=None)x = slim.convolution2d(x, channel*2, [3, 3], activation_fn=None)x = tf.nn.leaky_relu(x)x = slim.convolution2d(x, channel*4, [3, 3], stride=2, activation_fn=None)x = slim.convolution2d(x, channel*4, [3, 3], activation_fn=None)x = tf.nn.leaky_relu(x)for idx in range(num_blocks):x = resblock(x, out_channel=channel*4, name='block_{}'.format(idx))x = slim.conv2d_transpose(x, channel*2, [3, 3], stride=2, activation_fn=None)x = slim.convolution2d(x, channel*2, [3, 3], activation_fn=None)x = tf.nn.leaky_relu(x)x = slim.conv2d_transpose(x, channel, [3, 3], stride=2, activation_fn=None)x = slim.convolution2d(x, channel, [3, 3], activation_fn=None)x = tf.nn.leaky_relu(x)x = slim.convolution2d(x, 3, [7, 7], activation_fn=None)#x = tf.clip_by_value(x, -0.999999, 0.999999)return x
def unet_generator(inputs, channel=32, num_blocks=4, name='generator', reuse=False):with tf.variable_scope(name, reuse=reuse):x0 = slim.convolution2d(inputs, channel, [7, 7], activation_fn=None)x0 = tf.nn.leaky_relu(x0)x1 = slim.convolution2d(x0, channel, [3, 3], stride=2, activation_fn=None)x1 = tf.nn.leaky_relu(x1)x1 = slim.convolution2d(x1, channel*2, [3, 3], activation_fn=None)x1 = tf.nn.leaky_relu(x1)x2 = slim.convolution2d(x1, channel*2, [3, 3], stride=2, activation_fn=None)x2 = tf.nn.leaky_relu(x2)x2 = slim.convolution2d(x2, channel*4, [3, 3], activation_fn=None)x2 = tf.nn.leaky_relu(x2)for idx in range(num_blocks):x2 = resblock(x2, out_channel=channel*4, name='block_{}'.format(idx))x2 = slim.convolution2d(x2, channel*2, [3, 3], activation_fn=None)x2 = tf.nn.leaky_relu(x2)h1, w1 = tf.shape(x2)[1], tf.shape(x2)[2]x3 = tf.image.resize_bilinear(x2, (h1*2, w1*2))x3 = slim.convolution2d(x3+x1, channel*2, [3, 3], activation_fn=None)x3 = tf.nn.leaky_relu(x3)x3 = slim.convolution2d(x3, channel, [3, 3], activation_fn=None)x3 = tf.nn.leaky_relu(x3)h2, w2 = tf.shape(x3)[1], tf.shape(x3)[2]x4 = tf.image.resize_bilinear(x3, (h2*2, w2*2))x4 = slim.convolution2d(x4+x0, channel, [3, 3], activation_fn=None)x4 = tf.nn.leaky_relu(x4)x4 = slim.convolution2d(x4, 3, [7, 7], activation_fn=None)#x4 = tf.clip_by_value(x4, -1, 1)return x4
1.3 表面结构等定义:
def disc_bn(x, scale=1, channel=32, is_training=True, name='discriminator', patch=True, reuse=False):with tf.variable_scope(name, reuse=reuse):for idx in range(3):x = slim.convolution2d(x, channel*2**idx, [3, 3], stride=2, activation_fn=None)x = slim.batch_norm(x, is_training=is_training, center=True, scale=True)x = tf.nn.leaky_relu(x)x = slim.convolution2d(x, channel*2**idx, [3, 3], activation_fn=None)x = slim.batch_norm(x, is_training=is_training, center=True, scale=True)x = tf.nn.leaky_relu(x)if patch == True:x = slim.convolution2d(x, 1, [1, 1], activation_fn=None)else:x = tf.reduce_mean(x, axis=[1, 2])x = slim.fully_connected(x, 1, activation_fn=None)return x
def disc_sn(x, scale=1, channel=32, patch=True, name='discriminator', reuse=False):with tf.variable_scope(name, reuse=reuse):for idx in range(3):x = layers.conv_spectral_norm(x, channel*2**idx, [3, 3], stride=2, name='conv{}_1'.format(idx))x = tf.nn.leaky_relu(x)x = layers.conv_spectral_norm(x, channel*2**idx, [3, 3], name='conv{}_2'.format(idx))x = tf.nn.leaky_relu(x)if patch == True:x = layers.conv_spectral_norm(x, 1, [1, 1], name='conv_out'.format(idx))else:x = tf.reduce_mean(x, axis=[1, 2])x = slim.fully_connected(x, 1, activation_fn=None)return x
def disc_ln(x, channel=32, is_training=True, name='discriminator', patch=True, reuse=False):with tf.variable_scope(name, reuse=reuse):for idx in range(3):x = slim.convolution2d(x, channel*2**idx, [3, 3], stride=2, activation_fn=None)x = tf.contrib.layers.layer_norm(x)x = tf.nn.leaky_relu(x)x = slim.convolution2d(x, channel*2**idx, [3, 3], activation_fn=None)x = tf.contrib.layers.layer_norm(x)x = tf.nn.leaky_relu(x)if patch == True:x = slim.convolution2d(x, 1, [1, 1], activation_fn=None)else:x = tf.reduce_mean(x, axis=[1, 2])x = slim.fully_connected(x, 1, activation_fn=None)return x
(2)模型的训练:
使用clip_by_value应用自适应着色在最后一层的网络中,因为它不是很稳定。为了稳定再现我们的结果,请使用power=1.0然后首先在network.py中注释clip_by_value函数。
def train(args):input_photo = tf.placeholder(tf.float32, [args.batch_size, args.patch_size, args.patch_size, 3])input_superpixel = tf.placeholder(tf.float32, [args.batch_size, args.patch_size, args.patch_size, 3])input_cartoon = tf.placeholder(tf.float32, [args.batch_size, args.patch_size, args.patch_size, 3])output = network.unet_generator(input_photo)output = guided_filter(input_photo, output, r=1)blur_fake = guided_filter(output, output, r=5, eps=2e-1)blur_cartoon = guided_filter(input_cartoon, input_cartoon, r=5, eps=2e-1)gray_fake, gray_cartoon = utils.color_shift(output, input_cartoon)d_loss_gray, g_loss_gray = loss.lsgan_loss(network.disc_sn, gray_cartoon, gray_fake, scale=1, patch=True, name='disc_gray')d_loss_blur, g_loss_blur = loss.lsgan_loss(network.disc_sn, blur_cartoon, blur_fake, scale=1, patch=True, name='disc_blur')vgg_model = loss.Vgg19('vgg19_no_fc.npy')vgg_photo = vgg_model.build_conv4_4(input_photo)vgg_output = vgg_model.build_conv4_4(output)vgg_superpixel = vgg_model.build_conv4_4(input_superpixel)h, w, c = vgg_photo.get_shape().as_list()[1:]photo_loss = tf.reduce_mean(tf.losses.absolute_difference(vgg_photo, vgg_output))/(h*w*c)superpixel_loss = tf.reduce_mean(tf.losses.absolute_difference\(vgg_superpixel, vgg_output))/(h*w*c)recon_loss = photo_loss + superpixel_losstv_loss = loss.total_variation_loss(output)g_loss_total = 1e4*tv_loss + 1e-1*g_loss_blur + g_loss_gray + 2e2*recon_lossd_loss_total = d_loss_blur + d_loss_grayall_vars = tf.trainable_variables()gene_vars = [var for var in all_vars if 'gene' in var.name]disc_vars = [var for var in all_vars if 'disc' in var.name] tf.summary.scalar('tv_loss', tv_loss)tf.summary.scalar('photo_loss', photo_loss)tf.summary.scalar('superpixel_loss', superpixel_loss)tf.summary.scalar('recon_loss', recon_loss)tf.summary.scalar('d_loss_gray', d_loss_gray)tf.summary.scalar('g_loss_gray', g_loss_gray)tf.summary.scalar('d_loss_blur', d_loss_blur)tf.summary.scalar('g_loss_blur', g_loss_blur)tf.summary.scalar('d_loss_total', d_loss_total)tf.summary.scalar('g_loss_total', g_loss_total)update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)with tf.control_dependencies(update_ops):g_optim = tf.train.AdamOptimizer(args.adv_train_lr, beta1=0.5, beta2=0.99)\.minimize(g_loss_total, var_list=gene_vars)d_optim = tf.train.AdamOptimizer(args.adv_train_lr, beta1=0.5, beta2=0.99)\.minimize(d_loss_total, var_list=disc_vars)gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=args.gpu_fraction)sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))train_writer = tf.summary.FileWriter(args.save_dir+'/train_log')summary_op = tf.summary.merge_all()saver = tf.train.Saver(var_list=gene_vars, max_to_keep=20)with tf.device('/device:GPU:0'):sess.run(tf.global_variables_initializer())saver.restore(sess, tf.train.latest_checkpoint('pretrain/saved_models'))face_photo_dir = 'dataset/photo_face'face_photo_list = utils.load_image_list(face_photo_dir)scenery_photo_dir = 'dataset/photo_scenery'scenery_photo_list = utils.load_image_list(scenery_photo_dir)face_cartoon_dir = 'dataset/cartoon_face'face_cartoon_list = utils.load_image_list(face_cartoon_dir)scenery_cartoon_dir = 'dataset/cartoon_scenery'scenery_cartoon_list = utils.load_image_list(scenery_cartoon_dir)for total_iter in tqdm(range(args.total_iter)):if np.mod(total_iter, 5) == 0: photo_batch = utils.next_batch(face_photo_list, args.batch_size)cartoon_batch = utils.next_batch(face_cartoon_list, args.batch_size)else:photo_batch = utils.next_batch(scenery_photo_list, args.batch_size)cartoon_batch = utils.next_batch(scenery_cartoon_list, args.batch_size)inter_out = sess.run(output, feed_dict={input_photo: photo_batch, input_superpixel: photo_batch,input_cartoon: cartoon_batch})if args.use_enhance:superpixel_batch = utils.selective_adacolor(inter_out, power=1.2)else:superpixel_batch = utils.simple_superpixel(inter_out, seg_num=200)_, g_loss, r_loss = sess.run([g_optim, g_loss_total, recon_loss], feed_dict={input_photo: photo_batch, input_superpixel: superpixel_batch,input_cartoon: cartoon_batch})_, d_loss, train_info = sess.run([d_optim, d_loss_total, summary_op], feed_dict={input_photo: photo_batch, input_superpixel: superpixel_batch,input_cartoon: cartoon_batch})train_writer.add_summary(train_info, total_iter)if np.mod(total_iter+1, 50) == 0:print('Iter: {}, d_loss: {}, g_loss: {}, recon_loss: {}'.\format(total_iter, d_loss, g_loss, r_loss))if np.mod(total_iter+1, 500 ) == 0:saver.save(sess, args.save_dir+'/saved_models/model', write_meta_graph=False, global_step=total_iter)photo_face = utils.next_batch(face_photo_list, args.batch_size)cartoon_face = utils.next_batch(face_cartoon_list, args.batch_size)photo_scenery = utils.next_batch(scenery_photo_list, args.batch_size)cartoon_scenery = utils.next_batch(scenery_cartoon_list, args.batch_size)result_face = sess.run(output, feed_dict={input_photo: photo_face, input_superpixel: photo_face,input_cartoon: cartoon_face})result_scenery = sess.run(output, feed_dict={input_photo: photo_scenery, input_superpixel: photo_scenery,input_cartoon: cartoon_scenery})utils.write_batch_image(result_face, args.save_dir+'/images', str(total_iter)+'_face_result.jpg', 4)utils.write_batch_image(photo_face, args.save_dir+'/images', str(total_iter)+'_face_photo.jpg', 4)utils.write_batch_image(result_scenery, args.save_dir+'/images', str(total_iter)+'_scenery_result.jpg', 4)utils.write_batch_image(photo_scenery, args.save_dir+'/images', str(total_iter)+'_scenery_photo.jpg', 4)
模型的测试和使用
(1)加载图片的尺寸自动处理和导向滤波定义:
def resize_crop(image):h, w, c = np.shape(image)if min(h, w) > 720:if h > w:h, w = int(720*h/w), 720else:h, w = 720, int(720*w/h)image = cv2.resize(image, (w, h),interpolation=cv2.INTER_AREA)h, w = (h//8)*8, (w//8)*8image = image[:h, :w, :]
return image
def tf_box_filter(x, r):k_size = int(2*r+1)ch = x.get_shape().as_list()[-1]weight = 1/(k_size**2)box_kernel = weight*np.ones((k_size, k_size, ch, 1))box_kernel = np.array(box_kernel).astype(np.float32)output = tf.nn.depthwise_conv2d(x, box_kernel, [1, 1, 1, 1], 'SAME')return output
def guided_filter(x, y, r, eps=1e-2):x_shape = tf.shape(x)#y_shape = tf.shape(y)N = tf_box_filter(tf.ones((1, x_shape[1], x_shape[2], 1), dtype=x.dtype), r)mean_x = tf_box_filter(x, r) / Nmean_y = tf_box_filter(y, r) / Ncov_xy = tf_box_filter(x * y, r) / N - mean_x * mean_yvar_x = tf_box_filter(x * x, r) / N - mean_x * mean_xA = cov_xy / (var_x + eps)b = mean_y - A * mean_xmean_A = tf_box_filter(A, r) / Nmean_b = tf_box_filter(b, r) / Noutput = mean_A * x + mean_breturn output
def fast_guided_filter(lr_x, lr_y, hr_x, r=1, eps=1e-8):#assert lr_x.shape.ndims == 4 and lr_y.shape.ndims == 4 and hr_x.shape.ndims == 4lr_x_shape = tf.shape(lr_x)#lr_y_shape = tf.shape(lr_y)hr_x_shape = tf.shape(hr_x)N = tf_box_filter(tf.ones((1, lr_x_shape[1], lr_x_shape[2], 1), dtype=lr_x.dtype), r)mean_x = tf_box_filter(lr_x, r) / Nmean_y = tf_box_filter(lr_y, r) / Ncov_xy = tf_box_filter(lr_x * lr_y, r) / N - mean_x * mean_yvar_x = tf_box_filter(lr_x * lr_x, r) / N - mean_x * mean_xA = cov_xy / (var_x + eps)b = mean_y - A * mean_xmean_A = tf.image.resize_images(A, hr_x_shape[1: 3])mean_b = tf.image.resize_images(b, hr_x_shape[1: 3])output = mean_A * hr_x + mean_breturn output
(2)卡通化函数定义:
def cartoonize(load_folder, save_folder, model_path):input_photo = tf.placeholder(tf.float32, [1, None, None, 3])network_out = network.unet_generator(input_photo)final_out = guided_filter.guided_filter(input_photo, network_out, r=1, eps=5e-3)all_vars = tf.trainable_variables()gene_vars = [var for var in all_vars if 'generator' in var.name]saver = tf.train.Saver(var_list=gene_vars)config = tf.ConfigProto()config.gpu_options.allow_growth = Truesess = tf.Session(config=config)sess.run(tf.global_variables_initializer())saver.restore(sess, tf.train.latest_checkpoint(model_path))name_list = os.listdir(load_folder)for name in tqdm(name_list):try:load_path = os.path.join(load_folder, name)save_path = os.path.join(save_folder, name)image = cv2.imread(load_path)image = resize_crop(image)batch_image = image.astype(np.float32)/127.5 - 1batch_image = np.expand_dims(batch_image, axis=0)output = sess.run(final_out, feed_dict={input_photo: batch_image})output = (np.squeeze(output)+1)*127.5output = np.clip(output, 0, 255).astype(np.uint8)cv2.imwrite(save_path, output)except:print('cartoonize {} failed'.format(load_path))
(3)模型调用
model_path = 'saved_models'load_folder = 'test_images'save_folder = 'cartoonized_images'if not os.path.exists(save_folder):os.mkdir(save_folder)
cartoonize(load_folder, save_folder, model_path)
(4)训练代码的使用:
test_code文件夹中运行python cartoonize.py。生成图片在cartoonized_images文件夹里,效果如下:
总结
将输入图像通过导向滤波器处理,得到表面表示的结果,然后通过超像素处理,得到结构表示的结果,通过随机色彩变幻得到纹理表示的结果,卡通图像也就是做这样的处理。随后将GAN生成器产生的fake_image分别于上述表示结果做损失。其中纹理表示与表面表示通过判别器得到损失,fake_image的结构表示与fake_image,输入图像与fake_image分别通过vgg19网络抽取特征,进行损失的计算。
完整代码链接:https://pan.baidu.com/s/10YklnSRIw_mc6W4ovlP3uw
提取码:pluq
作者简介:
李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。
更多精彩推荐
仅用 4 小时,吃透“百度太行”背后硬科技!
OpenCV 实现视频稳流,附Python与C++代码!| 防抖技术
英伟达收购,ARM也要变美国公司,国产芯出路几何?
大数据杀熟行为10月1日起明令禁止;阿里一号工程“犀牛制造”正式亮相;iOS 14 正式版发布 | 极客头条
没有 5G 版 iPhone 的苹果秋季发布会,发布了些什么?
相关文章:

Vue 2 | Part 4 v-bind绑定元素属性和样式
这期跟大家分享的,是v-bind指令。它可以往元素的属性中绑定数据,也可以动态地根据数据为元素绑定不同的样式。 绑定属性 最简单的例子,我们有一张图片,需要定义图片的src。我们可以直接在元素的属性里面定义: <div …

在 ASP.NET 中执行 URL 重写
在 ASP.NET 中执行 URL 重写 发布日期: 8/23/2004| 更新日期: 8/23/2004Scott Mitchell 4GuysFromRolla.com 适用范围: Microsoft ASP.NET 摘要:介绍如何使用 Microsoft ASP.NET 执行动态 URL 重写。URL 重写是截取传入 Web 请求并…

win8中使用BitLocker加密
一、加密驱动器二、管理三、TPM转载于:https://blog.51cto.com/jimshu/989359
清华硕士爆料:这些才是机器学习必备的数学基础
现如今,计算机科学、人工智能、数据科学已成为技术发展的主要推动力。无论是要翻阅这些领域的文章,还是要参与相关任务,你马上就会遇到一些拦路虎:想过滤垃圾邮件,不具备概率论中的贝叶斯思维恐怕不行;想试…

Oracle Golden Gate体系架构详解(原创) - CzmMiao的博客生活 - ITeye技术网站
Oracle Golden Gate体系架构详解(原创) - CzmMiao的博客生活 - ITeye技术网站
用C#对ADO.NET数据库完成简单操作
作者:李阳 http://oraasp.vicp.net/article/article.aspx?ID21 数据库访问是程序中应用最普遍的部分。随着C#和ADO.NET的引入,这种操作变得更简单。这篇文章将示范四种最基础的数据库操作。 ● 读取数据。其中包括多种数据类型:整型&#…
用createrepo配置Yum本地源
yum配置本地源, 在网速差的情况下,yum用在线源是一件头痛的事,所以以下为yum的本地源配置可以有好解决这个事。 1,安装createrepo包, 可以用yum安装(yum install createrepo -y); 也可以安装rpm或tar包 (网址:createre…
首次在手机端不牺牲准确率实现BERT实时推理,比TensorFlow-Lite快近8倍,每帧只需45ms...
作者 | 王言治 出品 | AI科技大本营(ID:rgznai100) 基于Transformer的预训练模型在许多自然语言处理(NLP)任务中取得了很高的准确度。但是这些预训练模型往往需要很大的计算量和内存。由于移动平台的存储空间以及计算能力的限制&a…
[svc]caffe安装笔记-显卡购买
caffe,这是是数据组需要做一些大数据模型的训练(深度学习), 要求 服务器显卡(运算卡), 刚开始老板让买的牌子是泰坦的(这是2年前的事情了). 后来买不到这个牌子的,(jd,tb)看过丽台的,看过gtx系列的哪个型号来着, 也不合适,后来买的特斯拉显卡 [查了下一些知名的显卡牌子](https…
AABO:自适应最优化Anchor设置,性能榨取的最后一步 | ECCV 2020
编译 | VincentLee来源 | 晓飞的算法工程笔记Introduction目前,主流的目标检测算法使用多种形状的anchor box作为初始预测,然后对anchor box进行回归调整,anchor box的配置是检测算法中十分重要的超参数。一般而言,anchor box的配…

Android列表控件选项中添加进度框ProgressBar实现
今天有时间就学习了下在ListView、GridView列表项中清加ProgressBar,小马用最简单的代码实现可以通用的功能,人人都能看懂,哈哈,直接说下,如果你的适配器getView方法返回的View是一个自定义控件的话,有点不好实现哦&am…
写一个通用数据访问组件
出处:http://www.csharp-corner.com willsound(翻译) 我收到过好多Email来问我如何用一个通用的数据提供者(data provider)在不失自然数据提供者(native data provider)稳定而强大功能的前提下来访问不同的数据源(data sources).一个小伙子…

InstallShield 2015 LimitedEdition VS2012 运行bat文件
转载:http://www.cnblogs.com/fengwenit/p/4271150.html 运行bat文件 网上很多介绍如何运行bat的方法,但我这个是limted 版本,不适用。 1. 打开 Define Setup Requirements and Actions –> Custom Actions 2. 右健 After Register Product –> Ne…
理解C#中的string类型
作者:未知目的 本文的目的在于揭示和DOTNET及C#相关的一些常见的和不常见的问题。在这些问题中我的第一篇文章和string数据类型有关,string数据类型是一种引用类型,但是当和其他引用类型比较的时候,很多开发人员可能并不能完全理解它的行为。 问题 对于常见的引用类…
最全总结!聊聊 Python 操作PDF的几种方法
作者 | 陈熹来源 | 早起Python前言本文主要涉及:os 模块综合应用glob 模块综合应用PyPDF2 模块操作基本操作PyPDF2 导入模块的代码常常是:from PyPDF2 import PdfFileReader, PdfFileWriter这里导入了两个方法:PdfFileReader 可以理解为读取器…

three.js(六) 地形法向量生成
2019独角兽企业重金招聘Python工程师标准>>> 上一节采用 分形算法生成地形的高度值, 接着我们需要生成每个顶点的法向量。 three.js 的PlaneGeometry 自带有法向量, 法向量分为两种 即 平面法向量 和 平面每个定点法向量。 因此一个n*n 块组成…
ASP.NET中使用多个runat=server form
作者:未知ASP.NET 在同一个页面不支持多个 runatserver forms,要解决这个问题,可以把每个 form 放在一个单独的 panel 控件中,这样用户就可以简单地通过单选按钮在不同 panel 间切换。代码如下:2FormExample.aspx<%…
激发企业大“智慧” | 深度赋能AI全场景 揭秘你不知道的移动云
2020年是人工智能技术发展的关键年。疫情之下,世界见证了人工智能在抗击疫情中发挥的积极作用;今年4月,国家发改委正式将人工智能确定为新基建的重要领域之一。在历史机遇下,AI已实现"质变和量变",正迈入与技…

ExtJS 4.x 得到资源树上任意的节点对象
上半年做ExtJS 4.x 的时候,遇到过对资源树操作的情况: Ext.tree.Panel 如下图:目的: 直接根据每个节点的{任意key : 对应value},就能找到匹配的节点对象 代码如下: refs : [ { selector : rtree, …
【转载】mysql常用函数汇总
转载地址:http://www.jb51.net/article/40179.htm 一、数学函数ABS(x) 返回x的绝对值BIN(x) 返回x的二进制(OCT返回八进制,HEX返回十六进制)CEILING(x) 返回大于x的最小整数值EXP(x) 返回值e(自然对数的底&…
有关java的一些话
2019独角兽企业重金招聘Python工程师标准>>> 跟着做完TankWar,java才算是入门了,真正学习java从看尚学堂马士兵老师的视频开始,至今三个月已过,感谢马老师的精彩讲解,您才是我真正的java入门老师࿰…
ADO.NET 2.0中的SqlCommand.ExecutePageReader
http://blog.joycode.com/liuhuimiao/在.NET 2.0 PDC或Beta1中,可以看到SqlCommand对象新增了个ExecutePageReader方法,该方法实现了分页读取数据的功能。对于分页读取数据,在ADO.NET1.1中(当然2.0也适合)一般常用动态…
组合游戏系列5: 井字棋、五子棋AlphaGo Zero 算法实战
来源 | MyEncyclopedia上一篇我们从原理层面解析了AlphaGo Zero如何改进MCTS算法,通过不断自我对弈,最终实现从零棋力开始训练直至能够打败任何高手。在本篇中,我们在已有的N子棋OpenAI Gym 环境中用Pytorch实现一个简化版的AlphaGo Zero算法…
2020职场人裸辞三大原因:不开心、工资低、没有盼头
近期,脉脉发布了《2020职场人裸辞现状调研报道》,报道显示2020最让职场人想裸辞的三大原因为:不开心、工资低、没有盼头。报告数据中还显示,工资不满预期是最让人想要裸辞的主要原因,但有超过6成职场人表示,…
Oracle PL/SQL编程学习笔记:Merge方法的使用
Oracle11g的Merge很强大! 1 create or replace procedure BRANCE_REPORT_MERGE is2 3 begin4 Merge into BRANCHREPORT desttable5 using TEMP_BRANCHREPORT tmptable6 on (desttable.SENDER_IDtmptable.SENDER_ID and desttable.BRANCH_IDtmptable.BRANCH_ID…
2.0中获取数据库连接统计数据
作者: http://blog.joycode.com/liuhuimiao/.NET 2.0中的SqlConnection多了一个StatisticsEnabled属性和ResetStatistics()、RetrieveStatistics()两个方法,用于获取SQLServer的连接统计数据。当然,这样做是以性能损耗为代价的,但…

Python学习day5作业-ATM和购物商城
Python学习day5作业Python学习day5作业ATM和购物商城作业需求ATM:指定最大透支额度可取款定期还款(每月指定日期还款,如15号)可存款定期出账单支持多用户登陆,用户间转帐支持多用户管理员可添加账户、指定用户额度、冻…
60分钟看懂HMM的基本原理
作者 | 梁云1991来源 | Python与算法之美HMM模型,韩梅梅的中文拼音的缩写,所以又叫韩梅梅模型,由于这个模型的作者是韩梅梅的粉丝,所以给这个模型取名为HMM。开玩笑!HMM模型,也叫做隐马尔科夫模型ÿ…

获取远程网卡MAC地址
出自: http://blog.joycode.com/liuhuimiao/朋友mingal急问我有关获取远程网卡MAC地址的ASP.net实现。我一开始以为是获取本机MAC地址,说了几种方法给他。由于他还需要获取服务器(本机)相关信息,如硬盘序列号、CPU信息…
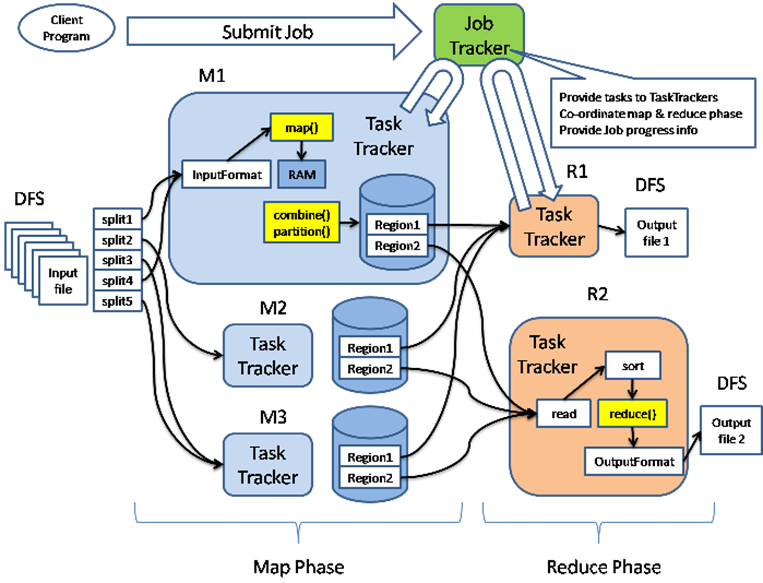
[hadoop源码阅读][9]-mapreduce-概论
hadoop的mapreduce的运行流程大概就是如下图所示了 如果要是文字描述,估计要大篇幅了,大家可以参考下面的参考文档. 参考文档 1.http://caibinbupt.iteye.com/blog/336467 2.http://hadoop.apache.org/docs/r0.19.2/cn/mapred_tutorial.html 3.http://developer.yahoo.com/hado…