组合游戏系列5: 井字棋、五子棋AlphaGo Zero 算法实战
来源 | MyEncyclopedia
上一篇我们从原理层面解析了AlphaGo Zero如何改进MCTS算法,通过不断自我对弈,最终实现从零棋力开始训练直至能够打败任何高手。在本篇中,我们在已有的N子棋OpenAI Gym 环境中用Pytorch实现一个简化版的AlphaGo Zero算法。本篇所有代码在 github.com/MyEncyclopedia/ConnectNGym 中,其中部分参考了SongXiaoJun 的 github.com junxiaosong/AlphaZero_Gomoku。
第一篇: Leetcode中的Minimax 和 Alpha Beta剪枝
第二篇: 井字棋Leetcode系列题解和Minimax最佳策略实现
第三篇: 井字棋、五子棋的OpenAI Gym GUI环境
第四篇: AlphaGo Zero 强化学习算法原理深度分析
第五篇: 井字棋、五子棋AlphaGo Zero 算法实战
AlphaGo Zero MCTS 树节点
上一篇中,我们知道AlphaGo Zero 的MCTS树搜索是基于传统MCTS 的UCT (UCB for Tree)的改进版PUCT(Polynomial Upper Confidence Trees)。局面节点的PUCT值由两部分组成,分别是代表Exploitation的action value Q值,和代表Exploration的U值。
U值计算由这些参数决定:系数,节点先验概率P(s, a) ,父节点访问次数,本节点的访问次数。具体公式如下
因此在实现过程中,对于一个树节点来说,需要保存其Q值、节点访问次数 visit_num和先验概率 prior。其中,prior在节点初始化后不变,Q值和 visit_num 随着游戏MCTS模拟进程而改变。此外,节点保存了 parent和 children变量,用于维护父子关系。c_puct为class variable,作为全局参数。
class TreeNode:"""MCTS Tree Node"""c_puct: ClassVar[int] = 5 # class-wise global param c_puct, exploration weight factor._parent: TreeNode_children: Dict[int, TreeNode] # map from action to TreeNode_visit_num: int_Q: float # Q value of the node, which is the mean action value._prior: float
和上面的计算公式相对应,下列代码根据节点状态计算PUCT(s, a)。
class TreeNode:def get_puct(self) -> float:"""Computes AlphaGo Zero PUCT (polynomial upper confidence trees) of the node.:return: Node PUCT value."""U = (TreeNode.c_puct * self._prior * np.sqrt(self._parent._visit_num) / (1 + self._visit_num))return self._Q + U
AlphaGo Zero MCTS在playout时遇到已经被展开的节点,会根据selection规则选择子节点,该规则本质上是在所有子节点中选择最大的PUCT值的节点。
class TreeNode:def select(self) -> Tuple[Pos, TreeNode]:"""Selects an action(Pos) having max UCB value.:return: Action and corresponding node"""return max(self._children.items(), key=lambda act_node: act_node[1].get_puct())
新的叶节点一旦在playout时产生,关联的 v 值会一路向上更新至根节点,具体新节点的v值将在下一节中解释。
class TreeNode:def propagate_to_root(self, leaf_value: float):"""Updates current node with observed leaf_value and propagates to root node.:param leaf_value::return:"""if self._parent:self._parent.propagate_to_root(-leaf_value)self._update(leaf_value)def _update(self, leaf_value: float):"""Updates the node by newly observed leaf_value.:param leaf_value::return:"""self._visit_num += 1# new Q is updated towards deviation from existing Qself._Q += 0.5 * (leaf_value - self._Q)
AlphaGo Zero MCTS Player 实现
AlphaGo Zero MCTS 在训练阶段分为如下几个步骤。游戏初始局面下,整个局面树的建立由子节点的不断被探索而丰富起来。AlphaGo Zero对弈一次即产生了一次完整的游戏开始到结束的动作系列。在对弈过程中的某一游戏局面,需要采样海量的playout,又称MCTS模拟,以此来决定此局面的下一步动作。一次playout可视为在真实游戏状态树的一种特定采样,playout可能会产生游戏结局,生成真实的v值;也可能explore 到新的叶子节点,此时v值依赖策略价值网络的输出,目的是利用训练的神经网络来产生高质量的游戏对战局面。每次playout会从当前给定局面递归向下,向下的过程中会遇到下面三种节点情况。
若局面节点是游戏结局(叶子节点),可以得到游戏的真实价值 z。从底部节点带着z向上更新沿途节点的Q值,直至根节点(初始局面)。
若局面节点从未被扩展过(叶子节点),此时会将局面编码输入到策略价值双头网络,输出结果为网络预估的action分布和v值。Action分布作为节点先验概率P(s, a)来初始化子节点,预估的v值和上面真实游戏价值z一样,从叶子节点向上沿途更新到根节点。
若局面节点已经被扩展过,则根据PUCT的select规则继续选择下一节点。
海量的playout模拟后,建立了游戏状态树的节点信息。但至此,AI玩家只是收集了信息,还仍未给定局面落子,而落子的决定由Play规则产生。下图展示了给定局面(Current节点)下,MCST模拟进行的多次playout探索后生成的局面树,play规则根据这些节点信息,产生Current 节点的动作分布 ,确定下一步落子。
MCTS Playout和Play关系
Play 给定局面
对于当前需要做落子决定的某游戏局面,根据如下play公式生成落子分布 ,子局面的落子概率正比于其访问次数的某次方。其中,某次方的倒数称为温度参数(Temperature)。
class MCTSAlphaGoZeroPlayer(BaseAgent):def _next_step_play_act_probs(self, game: ConnectNGame) -> Tuple[List[Pos], ActionProbs]:"""For the given game status, run playouts number of times specified by self._playout_num.Returns the action distribution according to AlphaGo Zero MCTS play formula.:param game::return: actions and their probability"""for n in range(self._playout_num):self._playout(copy.deepcopy(game))act_visits = [(act, node._visit_num) for act, node in self._current_root._children.items()]acts, visits = zip(*act_visits)act_probs = softmax(1.0 / MCTSAlphaGoZeroPlayer.temperature * np.log(np.array(visits) + 1e-10))return acts, act_probs在训练模式时,考虑到偏向exploration的目的,在 落子分布的基础上增加了 Dirichlet 分布。
class MCTSAlphaGoZeroPlayer(BaseAgent):def get_action(self, board: PyGameBoard) -> Pos:"""Method defined in BaseAgent.:param board::return: next move for the given game board."""return self._get_action(copy.deepcopy(board.connect_n_game))[0]def _get_action(self, game: ConnectNGame) -> Tuple[MoveWithProb]:epsilon = 0.25avail_pos = game.get_avail_pos()move_probs: ActionProbs = np.zeros(game.board_size * game.board_size)assert len(avail_pos) > 0# the pi defined in AlphaGo Zero paperacts, act_probs = self._next_step_play_act_probs(game)move_probs[list(acts)] = act_probsif self._is_training:# add Dirichlet Noise when training in favour of explorationp_ = (1-epsilon) * act_probs + epsilon * np.random.dirichlet(0.3 * np.ones(len(act_probs)))move = np.random.choice(acts, p=p_)assert move in game.get_avail_pos()else:move = np.random.choice(acts, p=act_probs)self.reset()return move, move_probs
一次完整的对弈
一次完整的AI对弈就是从初始局面迭代play直至游戏结束,对弈生成的数据是一系列的 。
如下图 s0 到 s5 是某次井字棋的对弈。最终结局是先手黑棋玩家赢,即对于黑棋玩家 z = +1。需要注意的是:z = +1 是对于所有黑棋面临的局面,即s0, s2, s4,而对应的其余白棋玩家来说 z = -1。
一局完整对弈
以下代码展示如何在AI对弈时收集数据
class MCTSAlphaGoZeroPlayer(BaseAgent):def self_play_one_game(self, game: ConnectNGame) \-> List[Tuple[NetGameState, ActionProbs, NDArray[(Any), np.float]]]:""":param game::return:Sequence of (s, pi, z) of a complete game play. The number of list is the game play length."""states: List[NetGameState] = []probs: List[ActionProbs] = []current_players: List[np.float] = []while not game.game_over:move, move_probs = self._get_action(game)states.append(convert_game_state(game))probs.append(move_probs)current_players.append(game.current_player)game.move(move)current_player_z = np.zeros(len(current_players))current_player_z[np.array(current_players) == game.game_result] = 1.0current_player_z[np.array(current_players) == -game.game_result] = -1.0self.reset()return list(zip(states, probs, current_player_z))
Playout 代码实现
一次playout会从当前局面根据PUCT selection规则下沉到叶子节点,如果此叶子节点非游戏终结点,则会扩展当前节点生成下一层新节点,其先验分布由策略价值网络输出的action分布决定。一次playout最终会得到叶子节点的 v 值,并沿着MCTS树向上更新沿途的所有父节点 Q值。从上一篇文章已知,游戏节点的数量随着参数而指数级增长,举例来说,井字棋(k=3,m=n=3)的状态数量是5478,k=3,m=n=4时是6035992 ,k=m=n=4时是9722011 。如果我们将初始局面节点作为根节点,同时保存海量playout探索得到的局面节点,实现时会发现我们无法将所有探索到的局面节点都保存在内存中。这里的一种解决方法是在一次self play中每轮playout之后,将根节点重置成落子的节点,从而有效控制整颗局面树中的节点数量。
class MCTSAlphaGoZeroPlayer(BaseAgent):def _playout(self, game: ConnectNGame):"""From current game status, run a sequence down to a leaf node, either because game ends or unexplored node.Get the leaf value of the leaf node, either the actual reward of game or action value returned by policy net.And propagate upwards to root node.:param game:"""player_id = game.current_playernode = self._current_rootwhile True:if node.is_leaf():breakact, node = node.select()game.move(act)# now game state is a leaf node in the tree, either a terminal node or an unexplored nodeact_and_probs: Iterator[MoveWithProb]act_and_probs, leaf_value = self._policy_value_net.policy_value_fn(game)if not game.game_over:# case where encountering an unexplored leaf node, update leaf_value estimated by policy net to rootfor act, prob in act_and_probs:game.move(act)child_node = node.expand(act, prob)game.undo()else:# case where game ends, update actual leaf_value to rootif game.game_result == ConnectNGame.RESULT_TIE:leaf_value = ConnectNGame.RESULT_TIEelse:leaf_value = 1 if game.game_result == player_id else -1leaf_value = float(leaf_value)# Update leaf_value and propagate up to root nodenode.propagate_to_root(-leaf_value)
编码游戏局面
为了将信息有效的传递给策略神经网络,必须从当前玩家的角度编码游戏局面。局面不仅要反映棋盘上黑白棋子的位置,也需要考虑最后一个落子的位置以及是否为当前玩家棋局。因此,我们将某局面按照当前玩家来编码,返回类型为4个棋盘大小组成的ndarray,即shape [4, board_size, board_size],其中
第一个数组编码当前玩家的棋子位置
第二个数组编码对手玩家棋子位置
第三个表示最后落子位置
第四个全1表示此局面为先手(黑棋)局面,全0表示白棋局面
例如之前游戏对弈中的前四步:
s1->s2 后局面s2的编码:当前玩家为黑棋玩家,编码局面s2 返回如下ndarray,数组[0] 为s2黑子位置,[1]为白子位置,[2]表示最后一个落子(1, 1) ,[3] 全1表示当前是黑棋落子的局面。
编码黑棋玩家局面 s2
s2->s3 后局面s3的编码:当前玩家为白棋玩家,编码返回如下,数组[0] 为s3白子位置,[1]为黑子位置,[2]表示最后一个落子(1, 0) ,[3] 全0表示当前是白棋落子的局面。
编码白棋玩家局面 s3
具体代码实现如下。
NetGameState = NDArray[(4, Any, Any), np.int]def convert_game_state(game: ConnectNGame) -> NetGameState:"""Converts game state to type NetGameState as ndarray.:param game::return:Of shape 4 * board_size * board_size.[0] is current player positions.[1] is opponent positions.[2] is last move location.[3] all 1 meaning move by black player, all 0 meaning move by white."""state_matrix = np.zeros((4, game.board_size, game.board_size))if game.action_stack:actions = np.array(game.action_stack)move_curr = actions[::2]move_oppo = actions[1::2]for move in move_curr:state_matrix[0][move] = 1.0for move in move_oppo:state_matrix[1][move] = 1.0# indicate the last move locationstate_matrix[2][actions[-1]] = 1.0if len(game.action_stack) % 2 == 0:state_matrix[3][:, :] = 1.0 # indicate the colour to playreturn state_matrix[:, ::-1, :]
策略价值网络训练
策略价值网络是一个共享参数 的双头网络,给定上面的游戏局面编码会产生预估的p和v。
结合真实游戏对弈后产生三元组数据 ,按照论文中的loss 来训练神经网络。
下面代码为Pytorch backward部分。
def backward_step(self, state_batch: List[NetGameState], probs_batch: List[ActionProbs],value_batch: List[NDArray[(Any), np.float]], lr) -> Tuple[float, float]:if self.use_gpu:state_batch = Variable(torch.FloatTensor(state_batch).cuda())probs_batch = Variable(torch.FloatTensor(probs_batch).cuda())value_batch = Variable(torch.FloatTensor(value_batch).cuda())else:state_batch = Variable(torch.FloatTensor(state_batch))probs_batch = Variable(torch.FloatTensor(probs_batch))value_batch = Variable(torch.FloatTensor(value_batch))self.optimizer.zero_grad()for param_group in self.optimizer.param_groups:param_group['lr'] = lrlog_act_probs, value = self.policy_value_net(state_batch)# loss = (z - v)^2 - pi*T * log(p) + c||theta||^2value_loss = F.mse_loss(value.view(-1), value_batch)policy_loss = -torch.mean(torch.sum(probs_batch * log_act_probs, 1))loss = value_loss + policy_lossloss.backward()self.optimizer.step()entropy = -torch.mean(torch.sum(torch.exp(log_act_probs) * log_act_probs, 1))return loss.item(), entropy.item()
参考资料
Youtube, Deepmind AlphaZero - Mastering Games Without Human Knowledge, David Silver
Mastering the game of Go with deep neural networks and tree search
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
AlphaGo Zero论文解析
AlphaZero实战:从零学下五子棋(附代码)
更多精彩推荐
激发企业大“智慧” | 深度赋能AI全场景 揭秘你不知道的移动云
首次在手机端不牺牲准确率实现BERT实时推理,比TensorFlow-Lite快近8倍,每帧只需45ms
美国AI博士一针见血:Python这样学最容易成为高手!
从程序媛到微软全球 AKS 女掌门人,技术女神驾到!
常程跳槽小米,联想:已付竞业协议股权对价 500 万,须偿还
相关文章:
2020职场人裸辞三大原因:不开心、工资低、没有盼头
近期,脉脉发布了《2020职场人裸辞现状调研报道》,报道显示2020最让职场人想裸辞的三大原因为:不开心、工资低、没有盼头。报告数据中还显示,工资不满预期是最让人想要裸辞的主要原因,但有超过6成职场人表示,…

Oracle PL/SQL编程学习笔记:Merge方法的使用
Oracle11g的Merge很强大! 1 create or replace procedure BRANCE_REPORT_MERGE is2 3 begin4 Merge into BRANCHREPORT desttable5 using TEMP_BRANCHREPORT tmptable6 on (desttable.SENDER_IDtmptable.SENDER_ID and desttable.BRANCH_IDtmptable.BRANCH_ID…
2.0中获取数据库连接统计数据
作者: http://blog.joycode.com/liuhuimiao/.NET 2.0中的SqlConnection多了一个StatisticsEnabled属性和ResetStatistics()、RetrieveStatistics()两个方法,用于获取SQLServer的连接统计数据。当然,这样做是以性能损耗为代价的,但…

Python学习day5作业-ATM和购物商城
Python学习day5作业Python学习day5作业ATM和购物商城作业需求ATM:指定最大透支额度可取款定期还款(每月指定日期还款,如15号)可存款定期出账单支持多用户登陆,用户间转帐支持多用户管理员可添加账户、指定用户额度、冻…
60分钟看懂HMM的基本原理
作者 | 梁云1991来源 | Python与算法之美HMM模型,韩梅梅的中文拼音的缩写,所以又叫韩梅梅模型,由于这个模型的作者是韩梅梅的粉丝,所以给这个模型取名为HMM。开玩笑!HMM模型,也叫做隐马尔科夫模型ÿ…

获取远程网卡MAC地址
出自: http://blog.joycode.com/liuhuimiao/朋友mingal急问我有关获取远程网卡MAC地址的ASP.net实现。我一开始以为是获取本机MAC地址,说了几种方法给他。由于他还需要获取服务器(本机)相关信息,如硬盘序列号、CPU信息…
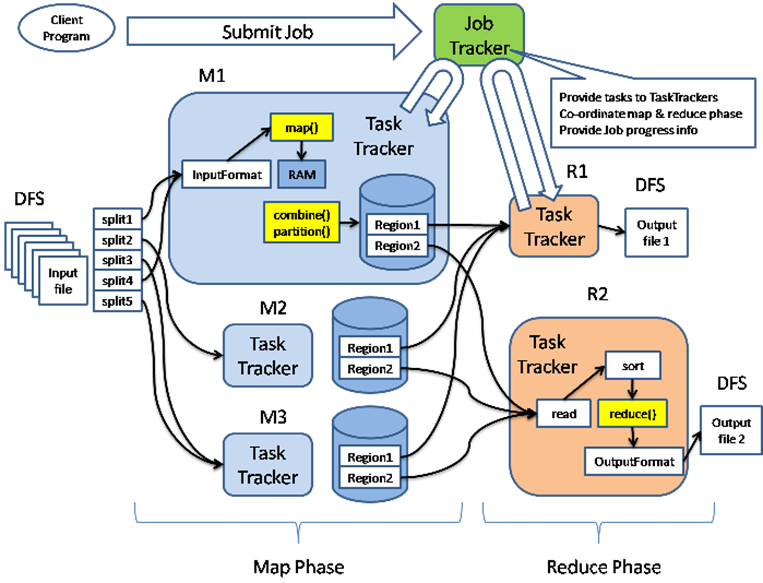
[hadoop源码阅读][9]-mapreduce-概论
hadoop的mapreduce的运行流程大概就是如下图所示了 如果要是文字描述,估计要大篇幅了,大家可以参考下面的参考文档. 参考文档 1.http://caibinbupt.iteye.com/blog/336467 2.http://hadoop.apache.org/docs/r0.19.2/cn/mapred_tutorial.html 3.http://developer.yahoo.com/hado…

【小白的CFD之旅】小结及预告
这是小白系列的索引,后续会继续更新。 已更新的部分 01 引子02 江小白03 老蓝04 任务05 补充基础06 流体力学基础07 CFD常识08 CFD速成之道09 初识FLUENT10 敲门实例11 敲门实例【续】12 敲门实例【续2】13 敲门实例【续3】14 实例反思15 四种境界16 流程17 需要编程…
Kaggle金牌得主的Python数据挖掘框架,机器学习基本流程都讲清楚了
作者 | 刘早起来源 | 早起Python导语:很多同学在学习机器学习时往往掉进了不停看书、刷视频的,但缺少实际项目训练的坑,有时想去练习却又找不到一个足够完整的教程,本项目翻译自kaggle入门项目Titanic金牌获得者的Kernelÿ…
input type右对齐与只读的
右对齐的 <input type"text" style"background:#efefef; text-align:right" readonly value"this" /> 只读的input <input type"text" name"nodeCode" readonly value"<%functionNodeForm.getNodeCode()%…

如何从sdcard读取文件
2019独角兽企业重金招聘Python工程师标准>>> 首先,我们必须明白文件储存格式是有许多种的,如utf-8,unicode等。 那么,我们如何将文件原封不动的读取出来呢,我们可以设定,文件储存的绝对路径为filepath。则代…
HDU 2034 人见人爱A-B
人见人爱A-B Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submission(s): 77157 Accepted Submission(s): 21509 Problem Description参加过上个月月赛的同学一定还记得其中的一个最简单的题目,就是{A}{B}&#…

Java中的包,类的导入,静态导入
包的作用 1. 为了更好的组织代码,能够将自己的代码与代码库的代码分离。 2. 在需要合作完成的工作中,可以使用分包的方式来尽量的减少类命名的冲突。 Sun公司推荐程序员使用公司域名的反向字符作为公司项目的起始包名:如 baidu.com --> c…
实现800*600,1024*768两套分辨率方案
下面这段代码,可以实现800*600,1024*768两套分辨率方案。 <html><head><title>Untitled Document</title><script language"javascript">function go(){var myWidthscreen.widthif (myWidth>800){window.location.repl…
倒计时 4 天!高通人工智能应用创新大赛颁奖典礼线上隆重举行
经过7 个月的激烈角逐,由高通公司(Qualcomm)、中国智谷重庆经开区、CSDN、Testin云测、OPPO、极视角、中科创达、创业邦联合主办,重庆经开区高通中国中科创达联合创新中心协办,TensorFlow Lite 作为开源技术合作伙伴的…
IOS分享扩展使用JS脚本
2019独角兽企业重金招聘Python工程师标准>>> 实现一个分享扩展插件,功能是从Safari网页中截取当前网页的图片内容 基本的步骤总结在下面: 1.创建一个JS文件,命名为MyJavascriptFile.js,文件的功能是解析safari网页内容…
电脑人会得哪些病----------关注健康,关爱生命!
作者:未知 随着科技水平的提高,现代办公室综合症,特别是高科技病渐渐成为现代职业病。电脑可以说是本世纪最伟大的发明之一,有了它,人们工作、生活、学习的方式都出现了划时代的改变,随着网络与电脑的普及&…
IOS上传图片的方法
下面是图片上传的方法:-(void)loadImage:(NSString*)aurl{NSData *imageData;NSMutableData *postBody;NSString *stringBoundary, *contentType;NSURL *url [NSURL URLWithString:aurl]; //将字符串转换为NSURL格式NSArray *paths…

企业数字化转型,AI平台能力建设是关键
企业数字化转型迎来一波又一波热潮。 IDC研究数据显示,目前中国已有41.4%的企业成为数字化转型的坚定者,到2023年,全球超过一半的GDP将由数字化转型企业的产品和服务推动。 加速数字化转型、让业务智能化,许多行业均认可这是全面…
CSS中连接属性的排序
在CSS超链接的属性中,有四个连接方式: a:link a:hover a:visited a:acticve 之前在使用的时候一直是按照自认为的顺序中去写的,就是 L H V A的排序方式,然而有些时候却发现并不起作用了,查找了一些资料,也上网查找了一…
Spring源代码解析(十):Spring Acegi框架授权的实现
我们从FilterSecurityInterceptor我们从入手看看怎样进行授权的: Java代码 //这里是拦截器拦截HTTP请求的入口 public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException …
可租赁、可定制的虚拟人居然还能这么玩?9月25日来百度大脑人像特效专场一探究竟!...
百度大脑自2016年启动开放以来,已打造成为业内最全面、最领先的AI开放平台,服务规模、调用量都居于业界第一。百度大脑开放日于2019年开办,覆盖北/上/深等地区,成为众多AI开发者、合作伙伴近距离沟通及深度交流,一起分…
提供前进、后退功能及其他JAVASCRIPT速成秘诀
通过了解下面的一些例子,并运用到你的WEB中,不久你马上成为JAVASCIPT的高手。 例(一)、在页面加入当前时间 < script languageJavaScript > tdynew Date(); document.write(当前时间:,tdy.getHours()); document.write(:,td…
C#零碎知识点笔记(容易混淆的一些点)
1:按CWTAB就可以完成打印命令的快速输入; 2:声明变量的时候 记得在使用的时候给这个变量一个初始化; 3:明白 CPU___内存----硬盘 之间的 相互关系; 4:在增加浮点数的时候要记得为每一个变量后边…
正则表达式--检查颜色值
<input type"text" name"color"><input type"button" value"check" οnclick"checkColor(color)">检查一下颜色值 ,正确是#六位十六进制数比如:#3EEF4A <script language"JavaScript">functio…
AI安全最全“排雷图”来了!腾讯发布业内首个AI安全攻击矩阵
近年来,人工智能迅猛发展,与家居、金融、交通、医疗等各个领域深度融合,让人们的生活更为便利。但与此同时,基于人工智能的系统一旦存在风险也将带来更为严重的后果。如何确保人工智能在不同的应用场景下不会被轻易控制、影响或欺…
Tomcat5.5x+jndi配置
1、配置Tomcat5.5.X的Server.xml,在<host>下面加上: <Context path"/JNDIDemo" docBase"D:\workspace\JNDIDemo\WebRoot" debug"0" reloadable"true" crossContext"true"> <Logger cl…

设备物理像素、设备独立像素
视觉稿 在前端开发之前,视觉MM会给我们一个psd文件,称之为视觉稿。 对于移动端开发而言,为了做到页面高清的效果,视觉稿的规范往往会遵循以下两点: 首先,选取一款手机的屏幕宽高作为基准(以前是iphone4的32…
只要你敢进来,没有学不会xml滴
作者:喜悦国际村 开心果1、前言 本贴绝大部分资源均转自 http://www.xml.org.cn/ 声明先,免得有人说偶盗链 SHOW TIME2、黄金装备 XML Explorer简体中文正式版(免费)XML.ORG.CN下载 (推荐这个,简单易用&a…
李彦宏AI布局又下一城,成立生命科学公司“百图生科”
此前业内传闻的“李彦宏将投资生物计算”一事有了新进展。9月25日消息,一家名为“百图生科”(英文简称“BioMap”)的生命科学平台公司正式成立。百度创始人、董事长兼CEO李彦宏确定将作为牵头发起人,亲自出任新公司的董事长&#…