10大经典排序算法,20+张图就搞定
作者 | 李肖遥
来源 | 技术让梦想更伟大
冒泡排序
简介
冒泡排序是因为越小的元素会经由交换以升序或降序的方式慢慢浮到数列的顶端,就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名冒泡排序。
复杂度与稳定性
思路原理
以顺序为例
从第一个元素开始一个一个的比较相邻的元素,如果第一个比第二个大即a[1]>a[2],就彼此交换。
从第一对到最后一对,对每一对相邻元素做一样的操作。此时在最后的元素应该会是最大的数,我们也称呼一遍这样的操作为一趟冒泡排序。
针对所有的元素重复以上的步骤,每一趟得到的最大值已放在最后,下一次操作则不需要将此最大值纳入计算。
持续对每次对越来越少的元素,重复上面的步骤。
直到所有的数字都比较完成符合a[i]<a[i+1],即完成冒泡排序。
图示过程
以数组数据{ 70,50,30,20,10,70,40,60}为例:
如图,每一次排序把一个最大的数被放在了最后,然后按照这个趋势逐渐往前,直到按从小到大的顺序依次排序。
到了第4轮的时候,整个数据已经排序结束了,但此时程序仍然在进行。
直到第5,6,7轮程序才算真正的结束,这其实是一种浪费算力的表现。
主要代码实现
void bubble_sort(int a[],int n) {for(int i=0; i<n; i++) {for(int j=0; j<n-i; j++) {if(a[j]>a[j+1]) { swap(a[j],a[j+1]); //交换数据 } } }}
注意,由于C++的namespace std命名空间的使用,std自带了交换函数swap(a,b),可以直接使用,其功能是交换a与b的两个值,当然你可以自定义swap函数,其模板代码为:
template<class T> //模板类,可以让参数为任意类型void swap(T &a,T &b) {T c(a); a=b; b=c;}
或者指定类型修改为整形,如:
void swap(int &a, int &b) { //指定类型int temp = a; a = b; b = temp;}
选择排序
简介
选择排序是一种简单直观的排序算法,它从待排序的数据元素中选出最小或最大的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小或最大元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。
复杂度与稳定性
过程介绍(以顺序为例)
首先设置两个记录i和j,i从数组第一个元素开始,j从(i+1)个元素开始。
接着j遍历整个数组,选出整个数组最小的值,并让这个最小的值和i的位置交换。
i选中下一个元素(i++),重复进行每一趟选择排序。
持续上述步骤,使得i到达(n-1)处,即完成排序 。
图示过程:
以数据{2,10,9,4,8,1,6,5}为例
如图所示,每次交换的数据使用红颜色标记出,已经排好序的数据使用蓝底标注,
每一趟从待排序的数据元素中选出最小的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。
我们只需要进行n-1趟排序即可,因为最后剩下的一个数据一定是整体数据中最大的数据。
代码实现
void select_sort(int a[],int n){int temp;for(int i=0;i<n-1;i++){ temp=i; //利用一个中间变量temp来记录需要交换元素的位置for(int j=i+1;j<n;j++){if(a[temp]>a[j]){ //选出待排数据中的最小值 temp=j; } } swap(a[i],a[temp]); //交换函数 }}
相比冒泡排序的不断交换,简单选择排序是等到合适的关键字出现后再进行交换,并且交换一次就可以达到一次冒泡的效果。
插入排序
简介
插入排序是一种最简单的排序方法,对于少量元素的排序,它是一个有效的算法。
复杂度与稳定性
过程介绍
首先将一个记录插入到已经排好序的有序表中,从而一个新的、记录数增1的有序表。
每一步将一个待排序的元素,按其排序码的大小,插入到前面已经排好序的一组元素的适当位置上去,直到元素全部插入为止。
可以选择不同的方法在已经排好序数据表中寻找插入位置。根据查找方法不同,有多种插入排序方法,下面要介绍的是直接插入排序。
每次从无序表中取出第一个元素,把它插入到有序表的合适位置,使有序表仍然有序。
第一趟比较前两个数,然后把第二个数按大小插入到有序表中;
第二趟把第三个数据与前两个数从后向前扫描,把第三个数按大小插入到有序表中;
依次进行下去,进行了(n-1)趟扫描以后就完成了整个排序过程。
图示过程
以数组数据{ 70,50,30,20,10,70,40,60}为例:
将红色的数据依次插入组成一个逐渐有序的数组
代码实现
void insert_sort(int a[],int n) {int i,j;//外层循环标识并决定待比较的数值for(i=1; i<n; i++) { //循环从第2个元素开始if(a[i]<a[i-1]) {int temp=a[i];//待比较数值确定其最终位置for(j=i-1; j>=0 && a[j]>temp; j--) { a[j+1]=a[j]; } a[j+1]=temp;//此处就是a[j+1]=temp; } }}
希尔排序
简介
希尔排序又称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。
希尔排序是非稳定排序算法,在对几乎已经排好序的数据操作时,效率极高,即可以达到线性排序的效率。
复杂度与稳定性
过程介绍
先将整个待排序的记录序列分组,对若干子序列分别进行直接插入排序,随着增量逐渐减少即整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
过程如下:
选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
按增量序列个数 k,对序列进行 k 趟排序;
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。
仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
图示过程
可以看见,相比直接插入排序由于可以每趟进行分段操作,故整体效率体现较高。
主要代码实现
void shellSort(int arr[], int n) {int i, j, gap;for (gap = n / 2; gap > 0; gap /= 2) {for (i = 0; i < gap; i++) {for (j = i + gap; j < n; j += gap) {for (int k = j; k > i && arr[k] < arr[k-gap]; k -= gap) { swap(arr[k-gap], arr[k]); } } } }}
堆排序
简介
堆排序是指利用堆这种数据结构所设计的一种排序算法,它是一个近似完全二叉树的结构。
同时堆满足堆积的性质:即子结点的键值或索引总是小于或大于它的父节点。
复杂度与稳定性
什么是堆?
由于堆排序比较特殊,我们先了解一下堆是什么。
堆是一种非线性的数据结构,其实就是利用完全二叉树的结构来维护的一维数组,利用这种结构可以快速访问到需要的值,堆可以分为大顶堆和小顶堆。
大顶堆:每个结点的值都大于或等于其左右孩子结点的值
小顶堆:每个结点的值都小于或等于其左右孩子结点的值
过程介绍
首先把待排序的元素按照大小在二叉树位置上排列,且要满足堆的特性,如果根节点存放的是最大的数,则叫做大根堆,反之就叫做小根堆了。
根据这个特性就可以把根节点拿出来,然后再堆化下,即用父节点和他的孩子节点进行比较,取最大的孩子节点和其进行交换,再把根节点拿出来,一直循环到最后一个节点,就排序好了。
由于堆的实现图解需要很长篇幅,故这里不画图,肖遥会单独出一篇堆的图解,感谢关注。其代码实现如下。
主要代码实现
/* Function: 交换交换根节点和数组末尾元素的值*/void Swap(int *heap, int len) {int temp;temp = heap[0]; heap[0] = heap[len-1]; heap[len-1] = temp;}
/* Function: 构建大顶堆 */void BuildMaxHeap(int *heap, int len) {int i,temp;for (i = len/2-1; i >= 0; i--) {if ((2*i+1) < len && heap[i] < heap[2*i+1]) { /* 根节点大于左子树 */ temp = heap[i]; heap[i] = heap[2*i+1]; heap[2*i+1] = temp;/* 检查交换后的左子树是否满足大顶堆性质 如果不满足 则重新调整子树结构 */if ((2*(2*i+1)+1 < len && heap[2*i+1] < heap[2*(2*i+1)+1]) || (2*(2*i+1)+2 < len && heap[2*i+1] < heap[2*(2*i+1)+2])) { BuildMaxHeap(heap, len); } }if ((2*i+2) < len && heap[i] < heap[2*i+2]) { /* 根节点大于右子树 */ temp = heap[i]; heap[i] = heap[2*i+2]; heap[2*i+2] = temp;/* 检查交换后的右子树是否满足大顶堆性质 如果不满足 则重新调整子树结构 */if ((2*(2*i+2)+1 < len && heap[2*i+2] < heap[2*(2*i+2)+1]) || (2*(2*i+2)+2 < len && heap[2*i+2] < heap[2*(2*i+2)+2])) { BuildMaxHeap(heap, len); } } }}
归并排序
简介
归并排序是建立在归并操作上的一种有效,稳定的排序算法,该算法是采用分治法的一个非常典型的应用,其核心思想是将两个有序的数列合并成一个大的有序的序列。
复杂度与稳定性
注:归并排序需要创建一个与原数组相同长度的数组来辅助排序
过程介绍
首先将已有序的子序列合并,得到完全有序的序列,即先使每个子序列有序,再使子序列段间有序。
过程如下:
申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
设定两个指针,最初位置分别为两个已经排序序列的起始位置
比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
重复步骤c直到某一指针超出序列尾
将另一序列剩下的所有元素直接复制到合并序列尾
图示过程
第一次排序将数据分为“两个”一组,组内顺序,其次再逐个的将各组进行整合,最终完成归并排序
主要代码实现
void merge(int arr[],int l,int mid,int r) {int aux[r-l+1];//开辟一个新的数组,将原数组映射进去for(int m=l; m<=r; m++) { aux[m-l]=arr[m]; }
int i=l,j=mid+1;//i和j分别指向两个子数组开头部分
for(int k=l; k<=r; k++) {if(i>mid) { arr[k]=aux[j-l]; j++; } else if(j>r) { arr[k]=aux[i-l]; i++; } else if(aux[i-l]<aux[j-l]) { arr[k]=aux[i-l]; i++; } else { arr[k]=aux[j-l]; j++; } }}
void merge_sort(int arr[],int n) {for(int sz=1; sz<=n; sz+=sz) {for(int i=0; i+sz<n; i+=sz+sz) { //i+sz防止越界//对局部:arr[i...sz-1]和arr[i+sz.....i+2*sz-1]进行排序 merge(arr,i,i+sz-1,min(i+sz+sz-1,n-1)); //min函数防止越界 } }
}
快速排序
简介
快速排序在1960年提出,是考察次数最多的排序,无论是在大学专业课的期末考试,还是在公司的面试测试题目中,快速排序都极大的被使用,在实际中快速排序也极大的被使用。
复杂度与稳定性
过程介绍
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
在数组中选择一个基准点
分别从数组的两端扫描数组,设两个指示标志
从后半部分开始,如果发现有元素比该基准点的值小,就交换位置
然后从前半部分开始扫描,发现有元素大于基准点的值,继续交换位置
如此往复循环,然后把基准点的值放到high这个位置,排序完成
以后采用递归的方式分别对前半部分和后半部分排序,当前半部分和后半部分均有序时该数组就自然有序了。
图示过程
可以看出,在第四趟时已经达到顺序,但是仍然还是会继续计算几趟直到完成全部运算
主要代码实现
void qucik_sort(int a[],int low,int high) {int i,j,temp; i=low; j=high;if(low<high) { temp=a[low]; //设置枢轴while(i!=j) {while(j>i&&a[j]>=temp) { --j; }if(i<j) { a[i]=a[j]; ++i; }
while(i<j&&a[i]<temp) { ++i; }if(i<j) { a[j]=a[i]; --j; } } a[i]=temp; qucik_sort(a,low,i-1); qucik_sort(a,i+1,high); }}
计数排序
简介
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
计数排序算法不是基于元素比较,而是利用数组下标来确定元素的正确位置。
它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k),快于任何比较排序算法。
当然这是一种牺牲空间换取时间的做法,而且当O(k)>O(n*log(n))的时候其效率反而不如基于比较的排序。
复杂度与稳定性
过程介绍
找出待排序的数组中最大和最小的元素
统计数组中每个值为i的元素出现的次数,存入数组C的第i项
对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
图示过程
如下图,A为待排序的数组,C记录A中各个值的数目。
将C[i]转换为值小于等于i的元素个数。
为数组A从后向前的每个元素找到对应的B中的位置,每次从A中复制一个元素到B中,C中相应的计数减一。
当A中的元素都复制到B中后,B就是排序好的结果,如图所示。
代码实现
#include<stdio.h>#include<stdlib.h>#include<string.h>
void CountSort(int *arr, int len){if(arr == NULL) return;int max = arr[0], min = arr[0];for(int i = 1; i < len; i++){if(arr[i] > max) max = arr[i];if(arr[i] < min) min = arr[i]; }int size = max - min + 1;int *count =(int*)malloc(sizeof(int)*size);memset(count, 0, sizeof(int)*size);
for(int i = 0; i < len; i++) count[arr[i] - min]++;//包含了自己!for(int i = 1; i < size; i++) count[i] += count[i - 1];
int* psort =(int*)malloc(sizeof(int)*len);memset(psort, 0, sizeof(int)*len);
for(int i = len - 1; i >= 0; i--){ count[arr[i] - min]--;//要先把自己减去 psort[count[arr[i] - min]] = arr[i]; }
for(int i = 0; i < len; i++){ arr[i] = psort[i]; }
free(count);free(psort); count = NULL; psort = NULL;}void print_array(int *arr, int len){for(int i=0; i<len; i++)printf("%d ", arr[i]);printf("\n");}
int main(){int arr[8] = {2, 5, 3, 0, 2, 3, 0, 3}; CountSort(arr, 8); print_array(arr, 8);
return 0;}
桶式排序
简介
桶排序也称箱排序,原理是将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。
桶排序是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是 比较排序,他不受到 O(n log n) 下限的影响。
复杂度与稳定性
过程介绍
根据待排序集合中最大元素和最小元素的差值范围和映射规则,确定申请的桶个数;
遍历待排序集合,将每一个元素移动到对应的桶中;
对每一个桶中元素进行排序,并移动到已排序集合中。
图示过程
元素分布在桶中:
然后,元素在每个桶中排序:
代码实现
#include<iterator>#include<iostream>#include<vector>using namespace std;const int BUCKET_NUM = 10;
struct ListNode{ explicit ListNode(int i=0):mData(i),mNext(NULL){} ListNode* mNext; int mData;};
ListNode* insert(ListNode* head,int val){ ListNode dummyNode; ListNode *newNode = new ListNode(val); ListNode *pre,*curr; dummyNode.mNext = head; pre = &dummyNode; curr = head;while(NULL!=curr && curr->mData<=val){ pre = curr; curr = curr->mNext; } newNode->mNext = curr; pre->mNext = newNode;return dummyNode.mNext;}ListNode* Merge(ListNode *head1,ListNode *head2){ ListNode dummyNode; ListNode *dummy = &dummyNode;while(NULL!=head1 && NULL!=head2){if(head1->mData <= head2->mData){ dummy->mNext = head1; head1 = head1->mNext; }else{ dummy->mNext = head2; head2 = head2->mNext; } dummy = dummy->mNext; }if(NULL!=head1) dummy->mNext = head1;if(NULL!=head2) dummy->mNext = head2;
return dummyNode.mNext;}
void BucketSort(int n,int arr[]){ vector<ListNode*> buckets(BUCKET_NUM,(ListNode*)(0));for(int i=0;i<n;++i){ int index = arr[i]/BUCKET_NUM; ListNode *head = buckets.at(index); buckets.at(index) = insert(head,arr[i]); } ListNode *head = buckets.at(0);for(int i=1;i<BUCKET_NUM;++i){ head = Merge(head,buckets.at(i)); }for(int i=0;i<n;++i){ arr[i] = head->mData; head = head->mNext; }}
基数排序
简介
基数排序是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,在某些时候,基数排序法的效率高于其它的稳定性排序法。
复杂度与稳定性
图示过程
设有一个初始序列为: R {50, 123, 543, 187, 49, 30, 0, 2, 11, 100}。
过程介绍
任何一个阿拉伯数,它的各个位数上的基数都是以0~9来表示的。所以我们不妨把0~9视为10个桶。
我们先根据序列的个位数的数字来进行分类,将其分到指定的桶中。
分类后,我们在从各个桶中,将这些数按照从编号0到编号9的顺序依次将所有数取出来。
得到的序列就是个位数上呈递增趋势的序列。
按照上图个位数排序:{50, 30, 0, 100, 11, 2, 123, 543, 187, 49}。
接下来对十位数、百位数也按照这种方法进行排序,最后就能得到排序完成的序列。
主要代码实现
public class RadixSort {// 获取x这个数的d位数上的数字// 比如获取123的1位数,结果返回3public int getDigit(int x, int d) {int a[] = {1, 1, 10, 100}; // 本实例中的最大数是百位数,所以只要到100就可以了return ((x / a[d]) % 10); }public void radixSort(int[] list, int begin, int end, int digit) { final int radix = 10; // 基数int i = 0, j = 0;int[] count = new int[radix]; // 存放各个桶的数据统计个数int[] bucket = new int[end - begin + 1];// 按照从低位到高位的顺序执行排序过程for (int d = 1; d <= digit; d++) {// 置空各个桶的数据统计for (i = 0; i < radix; i++) { count[i] = 0; }// 统计各个桶将要装入的数据个数for (i = begin; i <= end; i++) { j = getDigit(list[i], d); count[j]++; }// count[i]表示第i个桶的右边界索引for (i = 1; i < radix; i++) { count[i] = count[i] + count[i - 1]; }// 将数据依次装入桶中// 这里要从右向左扫描,保证排序稳定性for (i = end; i >= begin; i--) { j = getDigit(list[i], d);// 求出关键码的第k位的数字, 例如:576的第3位是5 bucket[count[j] - 1] = list[i];// 放入对应的桶中,count[j]-1是第j个桶的右边界索引 count[j]--; // 对应桶的装入数据索引减一 }// 将已分配好的桶中数据再倒出来,此时已是对应当前位数有序的表for (i = begin, j = 0; i <= end; i++, j++) {list[i] = bucket[j]; } } }public int[] sort(int[] list) { radixSort(list, 0, list.length - 1, 3);return list; }// 打印完整序列public void printAll(int[] list) {for (int value : list) { System.out.print(value + "\t"); } System.out.println(); }public static void main(String[] args) {int[] array = {50, 123, 543, 187, 49, 30, 0, 2, 11, 100}; RadixSort radix = new RadixSort(); System.out.print("排序前:\t\t"); radix.printAll(array); radix.sort(array); System.out.print("排序后:\t\t"); radix.printAll(array); }}
总结
10种排序算法对比,我们了解到了各种排序的原理及优缺点,记住任何一种排序都不是十全十美的,因此在我们实际应用中,最好的方式就是扬长避短。
更多精彩推荐
秋天的第一杯奶茶该买哪家?Python 爬取美团网红奶茶店告诉你
AI视觉大牛朱松纯担任北大AI研究院院长,提出通过构建大任务平台走向通用AI
可租赁、可定制的虚拟人居然还能这么玩?9月25日来百度大脑人像特效专场一探究竟!
面试一家公司俩不同岗位、技术经理只问婚姻经历:那些奇葩的面试经历
荣耀与美团合作推出 “共享笔记本”;传腾讯建议推出美国版微信,已被否;Debian 10.6 稳定版发布|极客头条
相关文章:

C# MoreLinq 扩展安装
为什么80%的码农都做不了架构师?>>> http://blog.csdn.net/lee576/article/details/42716905 MoreLinq是一个对Linq to object的扩展类库,它是一个开源项目(http://code.google.com/p/morelinq/source/browse 天朝已对google全力封禁,所以要翻墙)&#…

IOS学习博客不错的大部分是原创
http://blog.csdn.net/iukey/article/category/955062

巧用CSS的Light滤镜
作者: 冯永曜Light滤镜能产生一个模拟光源的效果,但使用它要通过调用它的“方法(Method)”来实现,这就要用到一些Javascrpt知识,虽然有一点难度,但产生的效果也是奇特的,你看看下面的…
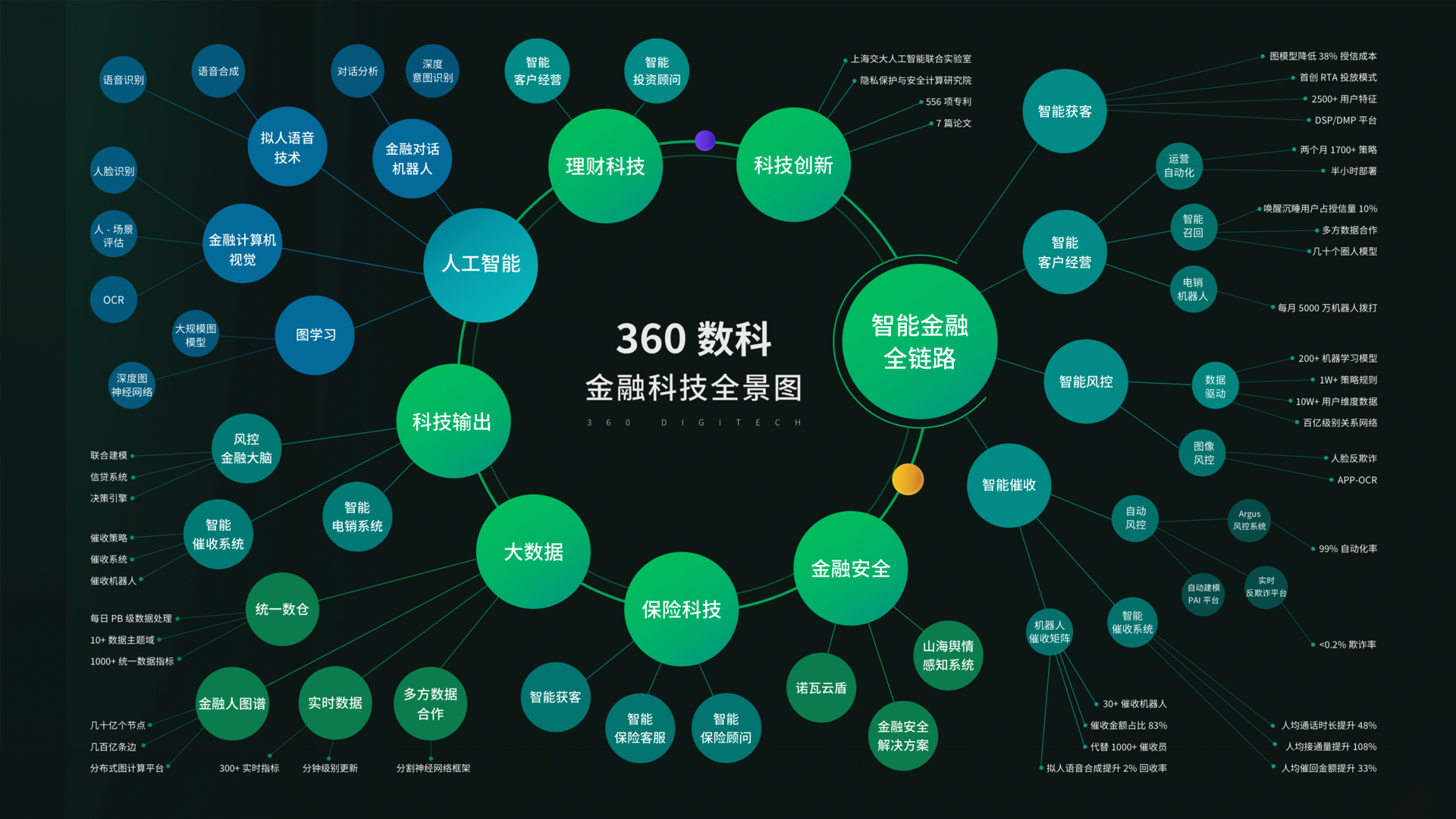
没有场景,不做单点技术输出,360数科如何做金融科技的最佳实践?
作者 | Just 出品 | AI科技大本营(ID:rgznai100) 从互联网金融公司转变为金融科技公司,品牌升级后的360数科强化了“科技”的外衣。 在近期的首个360数科技术开放日,360数科CEO吴海生表示,他们已经做好金融科技的最佳…

react构建淘票票webapp,及react与vue的简单比较。
前言 前段时间使用vue2.0构建了淘票票页面,并写了一篇相关文章vue2.0构建淘票票webapp,得到了很多童鞋的支持,因此这些天又使用react重构了下这个项目,目的无他,只为了学习和共同进步! 项目技术栈 前端技术…
【机器学习】机器学习算法优缺点对比(汇总篇)
作者 | 杜博亚来源 | 阿泽的学习笔记「本文的目的,是务实、简洁地盘点一番当前机器学习算法」。文中内容结合了个人在查阅资料过程中收集到的前人总结,同时添加了部分自身总结,在这里,依据实际使用中的经验,将对此模型…

PLSQL developer 连接不上64位Oracle 解决办法
在64位Windows2003上安装Oracle后,用PLSQL developer去连接数据库出现报错: Could not load "……\bin\oci.dll" OCIDLL forced to…… LoadLibrary(……oci.dll) returned 0 原因: oci.dll是64位的…

Docker 使用教程
概括 Docker与传统虚拟机的区别 与传统虚拟机的区别 Docker的安装 的安装 Docker daemon , client , containerd 镜像与容器操作 容器运行配置 Docker网络配置 网络配置 Alpine Docker Image 制作自己的 Docker Image …

话说CSS滤镜
作者:http://www.swtv.com.cn/adjunct/nr/css/css.htmAlpha 透明层次:滤镜效果语法:STYLE"filter:filtername(parameter1,parameter2,parameter3...)"其中:filtername为滤镜的名称;parameter1,parameter2等为…
面向隐私AI的TensorFlow深度定制化实践
作者 | Rosetta团队出品 | AI科技大本营(ID:rgznai100)之前我们整体上介绍了基于深度学习框架开发隐私 AI 框架中的工程挑战和可行解决方案。在这一篇文章中,我们进一步结合 Rosetta 介绍如何定制化改造 TensorFlow 中前后端相关组件…

”拿来搞笑“的大学生活
”拿来搞笑“这词,是我舍友对我说过好几遍,我才觉得这词用来形容我大学的生活再恰当不过了,感谢他送给我这个词。 下面就列一下我大学期间”拿来搞笑“的事情: —:无偿捐血400毫升。当时认为是一件微不足道的事情&…

巧用CSS的Border属性
。作者:冯永曜 来源:黄山村夫 制作过网页的人都有为画线而烦恼的经历,本文介绍的小技巧也许对你有所帮助。我们先来认识一下“Border”(画边框),它是CSS的一个属性,用它可以给能确定范围的HTML标…
阿里资深算法专家:如何突围大厂算法面试?
2020 届秋招,算法岗灰飞烟灭。最聪明的应届生 / 程序员 ,都在极度竞争中,面临着前所未有的激烈 PK 。学生因“内卷”而迷茫;初级程序员遇职业发展瓶颈而困惑...面对重重压力,苦不堪言。to do list 上写满计划ÿ…
乡下人最嘲笑城里人的16件事,无语了!
一、出门「taxi」,乘电梯上七楼的健身房,然后在跑步机上挥汗如雨。 二、半夜上网,去歌厅、舞厅,困了不睡觉。之后失眠,再吃安眠药。 三、管儿子叫「小兔崽子」,管宠物狗叫儿子。 四、挑最有特色的饭店吃…
2017浅谈面试(一)
2017给自己一个目标,制定一份计划,新的开始,跟随创业团队风险无处不在,不过还是要选好Boss。 2016一个煎熬,悲剧,没发工资的日子,一等就等了5个月,零散的就拿到了一个半月工资&#…
乘风破浪的PTM:两年来预训练模型的技术进展
作者 | 张俊林来源 | 深度学习前沿笔记专栏Bert模型自18年10月推出,到目前为止快两年了。它卜一问世即引起轰动,之后,各种改进版本的预训练模型(Pre-Training Model, PTM)与应用如过江之鲫,层出不穷。Bert及…

DW中CSS属性详解
作者:未知 来源:5D多媒体 在Dreamweaver的CSS样式里包含了W3C规范定义的所有CSS1的属性,Dreamweaver把这些属性分为Type(类型)、Background(背景)、Block(块)、Box&a…

第十周项目5:贪心的富翁
上机内容:用循环语句完成累加 上机目的:学会循环语句的使用 /* * Copyright (c) 2012, 烟台大学计算机学院 * All rights reserved. * 作 者:孙锐 * 完成日期:2012 年 10 月 31 日 * 版 本 号&…
python requests返回的json对象用json.loads()时转为字典时编码变为了unicode
2019独角兽企业重金招聘Python工程师标准>>> 1.使用simplejson,loads的对象为str,否则还是会转码unicode import simplejson url "" payload {} headers {} r requests.post(url, datapayload, headersheaders)result simplej…
关于Dreamweaver乱码问题的解决方案
原作者:南宫彩虹出处:5D多媒体出现乱码,大致为两种情况: 一是没有标明主页制作所用的文字,这种情况下很简单就可以解决,在<HEAD>区加上<META http-equivContent-Type content"text/html; cha…
百度绝对控股,小度科技独立融资,投后估值200亿元
9月30日,百度宣布旗下智能生活事业群组业务(以下简称“小度科技”)完成了独立融资协议的签署,本轮融资由百度资本及CPE战略领投、IDG资本跟投,投后估值达约200亿元。作为百度的重要战略业务板块,百度公司对…

Android UI开发第二十五篇——分享一篇自定义的 Action Bar
Action Bar是android3.0以后才引入的,主要是替代3.0以前的menu和tittle bar。在3.0之前是不能使用Action Bar功能的。这里引入了自定义的Action Bar,自定义Action bar也不是完全实现了 Action bar功能,只是在外形上相似。自定义Action bar没有…

ADF12C 在线预览PDF文件 afinlineFrame
转载于:https://blog.51cto.com/feitai/1898433
批量消除虚线框
原作者:星之海洋出处:5D多媒体 各位想必都知道,οnfοcus”this.blur()”这条代码能消除链接时的虚线框,但你有没有想过,如果你的网页上有几个甚至上百个链接,而你又想要去掉上面那些讨厌的虚线框…
Python实战 | 送亲戚,送长辈,月饼可视化大屏来帮忙!
中秋节介绍中秋节,又称祭月节、月光诞、月夕、秋节、仲秋节、拜月节、月娘节、月亮节、团圆节等,是中国民间的传统节日。中秋节自古便有祭月、赏月、吃月饼、玩花灯、赏桂花、饮桂花酒等民俗,流传至今,经久不息。每年中秋节到&…
lamp一键安装包
lamp一键安装包 http://58.83.226.93/ http://www.centos.bz/lamp/ http://www.centos.bz/ lamp一键安装包 http://58.83.226.93/ http://www.centos.bz/lamp/ http://www.centos.bz/
快节奏的多人游戏同步 - 示例代码和在线演示
这是一个实现我《快节奏的多人游戏同步》系列文章中主要概念的客户端——服务器架构演示示例(不包括实例插值,那块我还没弄完)建议在阅读完这系列文章后再看这部分。代码是纯JavaScript写的,一页就装下了。少于400行代码ÿ…
探索IE浏览器窗口
探索IE浏览器窗口点燃灵感 星之海洋不知大家是否见过浏览器窗口(哎呦,不要打我!),其实,不要小瞧了这普普通通的windows,除了常用的window.open()与window.resizeTo()方法来开启窗口外&…
新转机!2020年想裸辞的程序员们注意了
近期,脉脉发布了《2020职场人裸辞现状调研报道》,报道显示2020最让职场人想裸辞的三大原因为:不开心、工资低、没有盼头。报告数据中还显示,工资不满预期是最让人想要裸辞的主要原因,但有超过6成职场人表示,…
《ORACLE PL/SQL编程详细》,游标 ,函数,触发器。。
http://www.cnblogs.com/huyong/archive/2012/07/30/2614563.html