深度学习中的注意力机制(一)
作者 | 蘑菇先生
来源 | NewBeeNLP
头图 | CSDN下载自视觉中国
目前深度学习中热点之一就是注意力机制(Attention Mechanisms)。Attention源于人类视觉系统,当人类观察外界事物的时候,一般不会把事物当成一个整体去看,往往倾向于根据需要选择性的去获取被观察事物的某些重要部分,比如我们看到一个人时,往往先Attend到这个人的脸,然后再把不同区域的信息组合起来,形成一个对被观察事物的整体印象。
「同理,Attention Mechanisms可以帮助模型对输入的每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销,这也是Attention Mechanism应用如此广泛的原因」,尤其在Seq2Seq模型中应用广泛,如机器翻译、语音识别、图像释义(Image Caption)等领域。Attention既简单,又可以赋予模型更强的辨别能力,还可以用于解释神经网络模型(例如机器翻译中输入和输出文字对齐、图像释义中文字和图像不同区域的关联程度)等。
本文主要围绕核心的Attention机制以及Attention的变体展开。
Seq2Seq Model
Attention主要应用于Seq2Seq模型,故首先简介一下Seq2Seq模型。Seq2Seq模型目标是学习一个输入序列到输出序列的映射函数。应用场景包括:机器翻译(Machine translation)、自动语音识别(Automatic speech recognition)、语音合成(Speech synthesis)和手写体生成(Handwriting generation)。
Seq2Seq模型奠基性的两个工作如下:
NIPS2014:Sequence to Sequence Learning with Neural Networks[1]
该论文介绍了一种基于RNN(LSTM)的Seq2Seq模型,基于一个Encoder和一个Decoder来构建基于神经网络的End-to-End的机器翻译模型,其中,Encoder把输入编码成一个固定长度的上下文向量,Decoder基于「上下文向量」和「目前已解码的输出」,逐步得到完整的目标输出。这是一个经典的Seq2Seq的模型,但是却存在「两个明显的问题」:
把输入的所有信息有压缩到一个固定长度的隐向量,忽略了输入的长度,当输入句子长度很长,特别是比训练集中所有的句子长度还长时,模型的性能急剧下降(Decoder必须捕捉很多时间步之前的信息,虽然本文使用LSTM在一定程度上能够缓解这个问题)。
把输入编码成一个固定的长度过程中,对于句子中每个词都赋予相同的权重,这样做是不合理的。比如,在机器翻译里,输入的句子与输出句子之间,往往是输入一个或几个词对应于输出的一个或几个词。因此,对输入的每个词赋予相同权重,这样做没有区分度,往往使模型性能下降。
注意上图中Encoder得到的上下文向量「仅用于作为Decoder的第一个时间步的输入」。
Decoder的另一个输入是前一时刻的单词 ,需要注意的是,在训练阶段 是「真实label」(需要embedding一下),而不是上一时刻的预测值。而在测试阶段,则是上一时刻的预测值(具体使用时需要借助beam-search来得到最优翻译序列)。
但是实际训练过程中,「label是否使用真实数据2种方式,可以交替进行」,即一种是把标准答案作为Decoder的输入,还有一种是把Decoder上一次的输出的结果作为输入,因为如果完全使用标准答案,会导致收敛的过快,导致测试的时候不稳定。
另外,上述输入输出中的每个单词,都要借助「embedding」技术。
EMNLP2014:Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation[2]
和NIPS2014几乎同时发表,思想也是一样的。只不过在这篇文章中,作者提出了一种新的RNN Cell,即GRU代替LSTM来构建Seq2Seq模型。
还有一点不同的是,Encoder得到的上下文向量会作用于Decoder「每一个时间步」的预测。
总结起来:RNN-based Encoder-Decoder Framework,目标是预测 ,其中 都是one-hot向量。
「Encoder」
给定输入,,将其编码为上下文向量 .
是LSTM或GRU, 是时间步 的单词的one-hot表示,先经过embedding矩阵 嵌入后作为RNN在 时刻的输入, 是 时间步的encode; 是时间步 的encode。
是上下文向量,是关于 的函数。 是输入的最大长度。最简单的,,即最后一个时间步得到的encode作为上下文向量。
「Decoder」
Decoder在给定上下文向量 以及已经预测的输出 条件下,预测下一个输出 。换句话说,Decoder将输出 上的联合分布分解为有序条件分布 (ordered conditionals):
其中,, 是输出的最大长度。
使用RNN,每个条件分布可以写成下式:
是输出词的one-hot向量(全连接+softmax激活后得到), 是前一时刻已经预测的输出词的one-hot向量,先经过 embedding后再作为 的输入。 是一个非线性函数(e.g., 全连接+softmax),输出关于 的概率分布。(, 是LSTM/GRU)是RNN的隐藏层状态。(注意, 不是RNN提取隐藏层状态的LSTM或GRU,而是隐藏层后面接的全连接层或其他非线性函数,LSTM或GRU提取的Decoder隐状态和上下文向量以及已经预测的输出都将作为 的输入,用于预测概率分布)。
Attention
如上文所述,传统的Seq2Seq模型对输入序列缺乏区分度,存在明显的两大问题。因此,有大牛提出使用Attention机制来解决问题。下面将按照Attention的不同类型重点介绍一些Attention上的研究工作。
Basic Attention
本小节介绍最传统和基础的Attention模型的应用。首先直观感受下Attention机制的一个示意动图。
Machine Translation
ICLR2015: Neural Machine Translation by Jointly Learning to Align and Translate[3]
这是ICLR2015提出的文章,机器翻译的典型方法。作者在RNN Encoder-Decoder框架上,引入了Attention机制来同时进行翻译和对齐。使用bidirectional RNN作为Encoder,Decoder会在翻译的过程中通过模拟搜索源句子focus到不同部位上来进行更准确的解码。模型示意图如下:
首先将Decoder中的条件概率写成下式:
其中, 一般使用softmax全连接层(或多加几层,输入的3个向量concat到一起后进行Feed Forward), 是Decoder中RNN在时间步 的隐状态,根据如下LSTM或GRU函数计算得到:
是关于前一时刻Decoder端隐状态 ,前一时刻已经预测的输出 的embedding表示 以及该时刻 的上下文向量 的函数。 是LSTM或GRU。
注意,和已有的encoder-decoder不同,这里的条件概率对「每一个目标单词」 都需要有一个「不同的」上下文向量 。
而上下文向量 取决于Encoder端输入序列encode后的RNN隐状态 (bidirectional RNN,因此 包含了输入句子 位置周围的信息,)
而每一个权重 使用softmax转换为概率分布:
而 是输出 和输入 的对齐模型(alignment model),衡量了输入位置 周围的信息和输出位置 的匹配程度。
得分依赖于Decoder端 时刻的「前一时刻的隐状态」 和Encoder端 时刻的隐状态。文中使用前馈神经网络学习对齐模型,并且和其他组件联合学习, 实际上学到的是soft alignment,因此可以很容易应用梯度反向传播。
总之, 可以理解为衡量了输出单词 和输入单词 的对齐程度,而 是 时刻,所有encode隐状态根据该对齐程度得到的期望上下文向量,是所有对齐情况下的期望。 衡量了在计算下一个decoder隐状态 和预测 过程中,相对于前一个decoder隐状态 ,不同 的重要性程度。这一「Decoder中的」注意力机制使得只需要关注源句子部分的信息,而不是像此前工作中非要将源句子「所有的信息」都编码成固定长度的上下文向量来用。
Image Caption
ICML2015: Show, Attend and Tell- Neural Image Caption Generation with Visual Attention[4]
Kelvin Xu等人在该论文中将Attention引入到Image Caption中。Image Caption是一种场景理解的问题,这是视觉领域重要的一个研究方向。场景理解的难点在于既要进行物体识别,又要理解物体之间的关系。这相当于要让机器拥有模仿人类将大量显著的视觉信息压缩为描述性语言的能力。
模型包括两个部分:Encoder和Decoder。其中,Encoder会使用CNN提取图片低层特征;Decoder会在RNN中引入注意力机制,将图片特征解码为自然语言语句。模型总的示意图如下:
如上图,模型把图片经过CNN网络,变成特征图。LSTM的RNN结构在此上运行Attention模型,最后得到描述。
「目标:」 输入一个图像,输出该图像的描述 ,其中 是词典词汇的数量, 是词的one-hot表示向量, 是描述的长度。
「Encoder」
在encoder端,模型使用CNN来提取L个D维vector,每一个都对应图像的一个区域(这里粗体表示向量):
在原论文中,原始图像先经过center cropped变为 的图像,然后经过卷积和pooling操作,共4次max pooling,最后得到 的feature map,feature map个数共512个,即512个通道。这里 对应的就是196个区域数量,每个区域都是原始图像经过下采样得到的,因此可以通过4次上采样能够恢复原始图像中对应区域。而 ,即每个区域的向量化表示是由所有的feature map相应位置数值构造而成。
与此前的工作使用Softmax层之前的那一层vector作为图像特征不同,本文所提取的这些vector来自于 「low-level 的卷积层,这使得Decoder可以通过从所有提取到的特征集中,选择一个子集来聚焦于图像的某些部分」。这样子就有点像NLP里的seq2seq任务了,这里的输入从词序列转变成了图像区域vector的序列。作为类比,图像上的 个区域( 平展开为196)就相当于句子的长度(单词的数量 );每个区域的D维向量化表示是由D个Filter提取的该区域的特征concat在一起形成的向量,类比于句子每个单词的embedding经过RNN提取的「隐状态向量」。
上下文向量 计算如下:
即,在给定一组提取到的图像不同区域的向量表示 ,以及不同区域相应的权重 条件下,计算上下文向量,最简单的方式是使用上文所述的加权和来处理。本文使用了两种Attention Mechanisms,即Soft Attention和Hard Attention。我们之前所描述的传统的Attention Mechanism就是Soft Attention。Soft Attention是参数化的(Parameterization),因此可导,可以被嵌入到模型中去,直接训练,梯度可以经过Attention Mechanism模块,反向传播到模型其他部分。相反,Hard Attention是一个随机的过程,根据 随机采样。Hard Attention不会选择整个encoder的输出做为其输入,Hard Attention会依概率来采样输入端的隐状态一部分来进行计算,而不是整个encoder的隐状态。为了实现梯度的反向传播,需要采用蒙特卡洛采样的方法来估计模块的梯度。
而权重 的计算,作者引入了一个Attention模型,实际上就是上篇文章MT任务中的对齐模型。
是当前要预测的「输出词」的位置, 是输入词的位置。
「Decoder」
使用LSTM来解码并生成描述词序列,LSTM结构单元如下:
具体LSTM的计算:(可以发现如何将 融入到LSTM中的,实际上就是多一个线性变换,再全部加起来)
第一个式子实际上是四个式子,分别得到输入门、遗忘门、输出门和被输入门控制的候选向量。其中,三个门控由sigmoid激活,得到的是元素值皆在 0 到 1 之间的向量,可以将门控的值视作保留概率;候选向量由tanh激活,得到的是元素值皆在-1到1之间的向量。 是仿射变换,在上式也就是要对最右边的三项进行加权求和,可以将T理解为分块矩阵。最右边的三个式子,其中 是「输出词的embedding matrix」, 是one-hot词表示, 用来lookup,得到dense词向量表示。 是前一时刻的decoder状态, 是LSTM真正意义上的“输入”,代表的是捕捉了特定区域视觉信息的上下文向量,既然它和时刻 有关,就说明它是一个动态变化的量,在不同的时刻将会捕捉到与本时刻相对应的「相关图像区域」。这个量将由attention机制计算。
第二个式子是更新旧的记忆单元,element-wise 的运算表示三个门控将对各自控制的向量的每个元素做“取舍”:0 到 1 分别代表完全抛弃到完全保留。第三个式子是得到隐状态。
有了隐状态,就可以计算词表中各个词的概率值,那么取概率最大的那个作为当前时刻生成的词,并将作为下一时刻的输入。其实就是softmax全连接层(两层MLPs+softmax)。 是单词的数量。
原论文中还有一些比较有意思的Trick。
解码的输出:模型生成的一句caption被表示为各个词的one-hot编码所构成的集合,输出的caption y表示为:
是字典的单词个数, 是句子长度。 的形式为 ,即只有第 处位置为1,其它位置为0。
RNN建模时, 会用在embedding,将稀疏one-hot向量转成dense的embedding向量。模型的输出概率 会用于拟合真实的 。
LSTM初始输入:
LSTM中的记忆单元与隐藏单元的初始值,是两个不同的多层感知机,采用所有特征区域的平均值来进行预测的:
图像的encode:
文中使用VGGnet作为encoder进行编码,且不进行finetuning。encoder得到 的feature maps。因此decoder处理的是flattened ()。
Caption的Decode:
在decode时,由于模型每次更新所需要的时间正比于最长的句子,如果随机采样句子进行解码,训练时间会很长。为了解决这个问题,文中会在预处理环节,将句子按照长度分组。每次更新时,随机采样一个长度,然后使用相应的分组内的句子进行训练,这样就能显著提高运行效率。
个人觉得输出词的embedding matrix也可以使用word2vec预训练好的词向量代替,文中没提到。
Speech Recognition
NIPS2015: Attention-Based Models for Speech Recognition[5]
给定一个英文的语音片段作为输入,输出对应的音素序列。Attention机制被用于对输出序列的每个音素和输入语音序列中一些特定帧进行关联。
Entailment
ICLR2016: Reasoning about Entailment with Neural Attention[6]
语义蕴含,句子关系推断方面的早期工作,也是采用了基本的Attention模型。给定一个用英文描述的前提和假设作为输入,输出假设与前提是否矛盾、是否相关或者是否成立。举个例子:前提:在一个婚礼派对上拍照;假设:有人结婚了。该例子中的假设是成立的。Attention机制被用于关联假设和前提描述文本之间词与词的关系。
Text Summarization
EMNLP2015: A Neural Attention Model for Sentence Summarization[7]
给定一篇英文文章作为输入序列,输出一个对应的摘要序列。Attention机制被用于关联输出摘要中的每个词和输入中的一些特定词。
参考资料:
[1]Sequence to Sequence Learning with Neural Networks:
https://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf
[2]Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation:
https://www.aclweb.org/anthology/D14-1179
[3]ICLR2015: Neural Machine Translation by Jointly Learning to Align and Translate:
https://arxiv.org/pdf/1409.0473.pdf
[4]ICML2015: Show, Attend and Tell- Neural Image Caption Generation with Visual Attention:
https://arxiv.org/pdf/1502.03044.pdf
[5]NIPS2015: Attention-Based Models for Speech Recognition:
https://arxiv.org/pdf/1506.07503.pdf
[6]ICLR2016: Reasoning about Entailment with Neural Attention:
https://arxiv.org/pdf/1509.06664.pdf
[7]EMNLP2015: A Neural Attention Model for Sentence Summarization:
https://www.aclweb.org/anthology/D/D15/D15-1044.pdf
更多精彩推荐强化学习:10种真实的奖励与惩罚应用
NLP实战:利用Python理解、分析和生成文本 | 赠书
AI 隐身术,能让物体在视频中消失的魔法
CPU究竟是如何执行任务的?
太扎心!人艰不拆!16 个程序员专属笑话讲给你听
相关文章:

Hibernate 异常org.hibernate.LazyInitializationException: could not initialize prox
Hibernate的Lazy初始化1:n关系时,必须保证是在同一个Session内部使用这个关系集合,不然Hiernate将抛出异常。 两种处理方法: 一、这是延时加载的问题,把有关联的所有pojo类,在hibernate.cfg.xml文件中。一般在many-to-…
XHTML基础问答
作者:阿捷 2004-6-26 1:43:36本文是2002年为硅谷动力网站翻译的稿件。当时xhtml1.0刚刚开始被设计师所接触,所以有下面这个基础问答。 HTML语言是我们建立网页的工具,从它出现发展到现在,规范不断完善,功能越来越强。…
958毕业,苦学Java,竟被二本毕业生吊打!网友:确实厉害!
最近收到一位中型公司 HR 的反馈,她说,我推荐的一个普通本二毕业生在校招面试中表现非凡,当时两个人争抢一个名额,他竟然完胜另一位 985 毕业生。普通本二毕业生对公司的技术提问对答如流,曾在小公司实习,做…
css布局中的居中问题
css布局中的居中问题 作者:阿捷 2004-7-5 14:35:49#sample{HEIGHT:240px;WIDTH:400px;BACKGROUND: url(http://www.w3cn.org/style/001/logo_w3cn_194x79.gif) #CCC no-repeat center;} 如何使DIV居中 主要的样式定义如下: body {TEXT-ALIGN: center;…
领域驱动设计_软件核心复杂性应对之道
领域驱动设计_软件核心复杂性应对之道转载于:https://www.cnblogs.com/MarvinGeng/archive/2013/02/21/2920968.html
谈谈Boost网络编程(2)—— 新系统的设计
写文章之前。我们一般会想要採用何种方式,是“开门见山”,还是”疑问式开头“。写代码也有些类似。在编码之前我们须要考虑系统总体方案,这也就是各种设计文档的作用。在设计新系统之初,我基本的目的是:保证高效率&…
64岁Python之父退休失败,正式加入微软搞开源
来源 | CSDN今天,64岁的Python 之父 Guido van Rossum 在 Twitter 上正式宣布,退休太无聊,如今加入了微软开发者部门。Guido van Rossum 去年宣布退出 Python 核心决策层事实上,近几年来,随着人工智能的飞速发展&#…
Java实现HTTP文件下载(转)
文章出自: http://www.360doc.com/content/12/1218/17/2718300_254818081.shtml 本人用这种方法解决了工作中遇到的问题,再次谢谢文章的作者. 序言 许多用户可能会遇到这样的情况:在网站上发现一个很好的资源,但是这个资源是分成了很多个文件存放的&…
初学web标准的几个误区
初学web标准的几个误区作者:阿捷 2004-7-7 11:37:11非常高兴地看到很多设计师开始关注和尝试使用web标准制作网页。但从网友们的问题和制作中发现几个问题,在这里特别提醒一下: 1.不是为了通过校验才标准化。 web标准的本意是实现内容(结构…
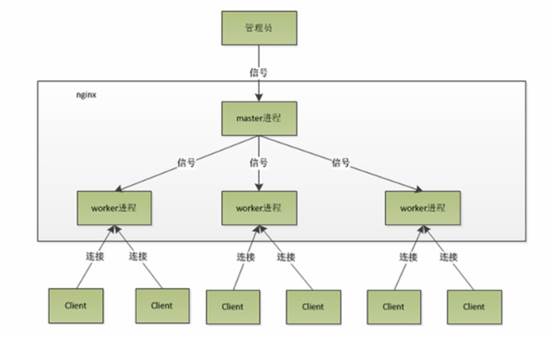
nginx系列:nginx反向缓存代理详解
小生博客:http://xsboke.blog.51cto.com如果有疑问,请点击此处,然后发表评论交流,作者会及时回复。-------谢谢您的参考,如有疑问,欢迎交流一、 代理和nginx相关概念1. 代理类型正向代理:代理局域网对internet的连接请求反向代理&…

编辑PDF文档,Word 2013可以是您的选择
题外话:记得刚进公司的时候,几乎所有的培训文档都是PDF、标准文档,公司使用的软件是Adobe Acrobat 5.0(不知道多少钱,呵呵),软件当然是购买正版的;去年,公司购买了新版本…

中国人工智能学会2020年度优秀科技成果出炉,百度文心ERNIE入选
11月14日,由中国人工智能学会(CAAI)主办的2020第十届中国智能产业高峰论坛(CIIS 2020)正式开幕,CAAI理事长戴琼海院士、何积丰院士、何友院士、王恩东院士、陆军院士等多位中外院士、专家齐聚嘉兴南湖&…
web标准,我们去向何方?一些想法...
web标准,我们去向何方?一些想法...作者:阿捷 2004-7-5 0:52:42原文作者:Veerle 原文出处:veerle.duoh.com 原文发表时间:2004年6月14日 译者注:本文是"你应该关注web标准的真正原因"…
事件源ES的优势
多年来,开发人员实现持久性使用传统的创建、读取、更新、删除(CRUD)模式。正如前面介绍的,如果采购模型实现持久性存储状态更改为历史事件捕获业务活动发生之前写的数据存储。这将事件存储机制,允许他们被聚合,或者放在一个组与逻辑边界。事件采购的模式之一,使并发、分布式系统…

你应该关注web标准的真正原因
你应该关注web标准的真正原因作者:阿捷 2004-7-4 2:28:39原文作者:Andrei Herasimchuk 原文出处:designbyfire.com 原文发表时间:2004年6月11日 译者前言:这是一篇让人震惊的文章。作者的分析深刻,文笔犀…
为什么我们需要开源的系统芯片?
作者 | bunnie译者 | 弯月,编辑 | 杨碧玉来源 | CSDN(ID:CSDNnews)现代的小型电子产品往往基于某个高度集成的芯片构建,这种芯片称为“系统芯片”(System on aChip,缩写:SoC…
InnoDB和MyISAM区别
MySQL作为当前最为流行的免费数据库服务引擎,已经风靡了很长一段时间,不过也许也有人对于MySQL的内部环境不很了解,尤其那些针对并发性处理的机制。今天,我们先了解一下MySQL中数据表的分类,以及它们的一些简单性质。 …
图书管理系统5W1H
Who 图书管理员 When 图书管理员在图书馆借阅期间管理用户的借书还书,非借阅时间管理后台图书、管理用户信息 Where 借书台、办公室 What 一个图书管理系统,能实现图书的借书还书操作、管理后台图书信息、管理用户信息 Why 能够方便快捷的实现图…
程序员奶爸用树莓派制作婴儿监护仪:哭声自动通知,还能分析何时喂奶
作者 | Fabio Manganiello译者 | 弯月,责编 | 杨碧玉头图 | CSDN 下载自东方 IC来源 | CSDN(ID:CSDNnews)首先,告诉大家一个好消息,我当爸爸了!我不得不暂停一下我的项目来承担一些育儿的重任。…
python快速小教程
http://www.cnblogs.com/vamei/archive/2012/09/13/2682778.html
web标准的投资回报
web标准的投资回报(ROI)作者:阿捷 2004-7-6 0:17:49原文作者:D. Keith Robinson 原文出处:asterisk 原文发表时间:2004年6月1日 用web标准开发能够带来实际利益,这一点还有人怀疑吗? 如果有,…

使用javascript让项目支持热插拔
2019独角兽企业重金招聘Python工程师标准>>> 突然想起之前做过的一个小项目,项目虽小,需求却不小,要求解析特定格式的字符串,并且特定格式并非一成不变,想要一套系统能够支持解析多变的规则且更改规则时不能…

设计模式:状态模式(State Pattern)
作者:Wang Juqiang 创建于:2012-07-16 出处:http://www.cnblogs.com/wangjq/archive/2012/07/16/2593485.html 收录于:2013-03-01 结构图 意图 允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。 适用性…
拼命学的编程,你却可能错过一个亿!
先来看 2 则新闻:近日 AI 圈最火的新闻当属“AI独角兽依图科技上市”,“AI四小龙”先后开启了上市之路,继旷视科技、云从科技分别谋求港股、A股上市后,依图科技也加入了 IPO 队伍。国内 AI 科技公司的发展,也标志着国家…
web标准的商业价值
web标准的商业价值作者:阿捷 2004-7-3 0:37:26原文来自:adaptivepath.com 作者介绍:Jeffrey Veen是AdaptivePath.com的合伙人之一,专门研究网页设计新技术,你可以在他的个人站点veen.com上学到更多知识。 自从开始we…

OO真经——关于面向对象的哲学体系及科学体系的探讨(上)
http://www.cnblogs.com/leoo2sk/archive/2009/04/09/1432103.html 目录 Catelog 序言 Perface 真经第一章:世界 Waltanschauung 真经第二章:抽象 Abstraction 真经第三章:层次 Arrangement 真经第四章:继承 Inheritance 真经第五…
一次防CC***案例
本文来自 :http://baiying.blog.51cto.com/1068039/1113087 名词解释:摘自百度百科 名称起源 CC Challenge Collapsar,其前身名为Fatboy***,是利用不断对网站发送连接请求致使形成拒绝服务的目的, CC***是DDOS(分布…

滴滴联合比亚迪:首款定制网约车D1发布
11月16日,滴滴出行举办“滴滴开放日”,正式发布全球首款定制网约车D1。这款车基于滴滴平台上5.5亿乘客、上千万司机需求、百亿次出行数据,针对网约车出行场景,在车内人机交互、司乘体验、车联网等多方面进行定制化设计。作为第一款…

表格对决CSS--一场生死之战
表格对决CSS--一场生死之战作者:阿捷 2004-7-19 21:00:54原文作者:Sergio Villarreal 作者简介:墨西哥网页设计师,1993年接触网络,个人主页为Overcaffeinated.net 原文出处:sitepoint.com 原文发表时间&…
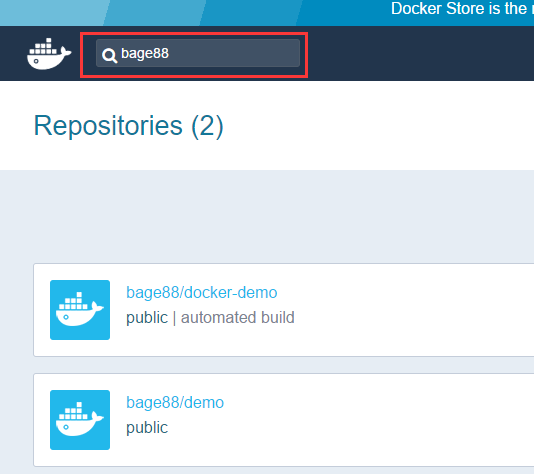
使用Docker-Docker for Web Developers(2)
1. 使用镜像 1.1 在Docker Hub上查找镜像 我们查找一下之前博客里面,推送到Docker Hub里面的bage88/docker-demo,能看到有2个仓库,第一个就是我们上次上传的镜像。点击“Details”进入到详细页面。 1.2 拉取镜像到本地机器 在我们本地虚拟机上…