程序员奶爸用树莓派制作婴儿监护仪:哭声自动通知,还能分析何时喂奶
作者 | Fabio Manganiello
译者 | 弯月,责编 | 杨碧玉
头图 | CSDN 下载自东方 IC
来源 | CSDN(ID:CSDNnews)
首先,告诉大家一个好消息,我当爸爸了!我不得不暂停一下我的项目来承担一些育儿的重任。
我就在想,这些育儿任务可以自动化吗?我们真的可以将给孩子换尿布的任务交给一个机器人吗?我想我们距离那一天还很遥遥。想一想父母的心得多大才能在自己孩子身上测试这类的设备,但如果能够通过自动化提供一定的帮助的话,也能减轻父母的重担。
初为人父,我领悟到的第一件事就是婴儿真的很爱哭,而且即便我在家,也无法保证时刻能够听到孩子宝宝的哭声。通常我们都会使用婴儿监护仪,这就相当于对讲机,即使你在另一个房间也可以听到宝宝的声音。
然而,很快我就意识到商用婴儿监护仪非常笨,比我想要的理想设备差得很远。婴儿监护仪无法检测到宝宝的哭声,它们就像对讲机一样,只是简单地将声音从信号源传递到扬声器。
而且,由于这些监护仪无法将声音播放到其他音频设备上,因此父母必须将扬声器带到不同的房间。通常,婴儿监护仪都带有低功率的扬声器,而且通常无法连接到外部扬声器上。
这意味着,如果我在扬声器所在的房间里播放音乐,而我本人即使与监护仪在同一个房间内,也听不到宝宝的哭声。此外,大多数监护仪使用的都是低功率无线电波,这意味着,如果宝宝在自己房间里,而你需要去地下室的时候,监护仪就无法正常工作了。
因此,我构思了一份智能婴儿监护仪的需求:
能够在任何带有廉价USB麦克风的廉价设备上运行,比如树莓派等。
能够检测到婴儿的哭声,并在宝宝开始哭或停止哭泣的时候通知我(最好通过手机);或者在宝宝哭的时候在仪表板上显示跟踪的数据点;或者执行任何我希望执行的任务。不仅仅是充当哑巴对讲机,将声音从源头传递到唯一的兼容设备上。
能够在任何设备上传输音频流,我自己的扬声器、我的智能手机、我的计算机等。
无论声源与扬声器之间的距离是多少,都能够正常工作,我不需要在房屋内移动扬声器。
配有摄像头,这样我就可以实时检查宝宝的状况;或者在宝宝哭的时候,我可以看到婴儿床的图片或简短的录像,以检查一切是否正常。
下面,我们来看看如何使用我们最喜欢的开源工具来完成这项工作。
录制一些音频样本
首先,入手一款树莓派,在SD卡上安装任何一款兼容的Linux操作系统。推荐使用树莓派3或更高版本来运行Tensorflow模型。此外,还需要入手一个兼容的USB麦克风,任何型号都可以。
然后,安装我们需要的依赖项:
[sudo]apt-get install ffmpeg lame libatlas-base-dev alsa-utils[sudo]pip3 install tensorflow
第一步,我们必须记录足够的音频样本,记录宝宝什么时候哭,什么时候不哭,稍后我们需要这些样本来训练音频检测模型。注意,在此示例中,我将展示如何使用声音检测来识别婴儿的哭声,你也可以使用相同的方法来检测任何类型的声音,只要声音足够长即可(例如警报声或邻居的声音),而且声源必须比背景噪音更大。
首先,看一下音频输入设备:
arecord-l
我的树莓派获得了以下输出(注意我有两个USB麦克风):
****List of CAPTURE Hardware Devices ****card1: Device [USB PnP Sound Device], device 0: USB Audio [USB Audio] Subdevices: 0/1 Subdevice #0: subdevice #0card2: Device_1 [USB PnP Sound Device], device 0: USB Audio [USB Audio] Subdevices: 0/1 Subdevice #0: subdevice #0
我想使用第二个麦克风来记录声音,也就是card 2,device 0。ALSA识别它的方式是hw:2,0(直接访问硬件设备)或plughw:2,0(根据需要推断采样率和格式转换插件)。确保你的SD卡上有足够的空间,或者你也可以使用外部USB驱动器,然后开始录制一些音频:
arecord-D plughw:2,0 -c 1 -f cd | lame - audio.mp3
在你宝宝的房间中,录制几分钟或几小时的音频(最好分别录制很长一段时间的安静、宝宝哭泣和其他不相关的声音),完成后按Ctrl-C结束。你可以根据需要多重复几次这个过程,获取一天中不同时刻或不同天的音频样本。
标记音频样本
在收集到足够的音频样本后,我们需要将它们复制到计算机上,用于训练模型,你可以使用scp复制这些文件,也可以直接从SD卡和USB驱动器上复制。
我们把这些文件保存在同一个目录下,比如~/datasets/sound-detect/audio。此外,我们还需要为每个样本新建一个文件夹。每个文件夹都包含一个音频文件(名为audio.mp3)和一个标签文件(名为labels.json),稍后我们将使用标签文件来标记音频文件,比如“positive”/“negative”音频片段。原始数据库的结构大致如下:
~/datasets/sound-detect/audio -> sample_1 -> audio.mp3 -> labels.json -> sample_2 -> audio.mp3 -> labels.json ...
下面是比较无聊的部分:标记我们录制的音频文件。这些文件中包含数个小时的你家宝宝的哭声,可能有点自虐的倾向。在你喜欢的音频播放器或Audacity中打开每个数据集的音频文件,并在每个样本的目录中新建一个labels.json文件。确定哭声开始和结束的确切时间,并以time_string -> label的形式将它们的键值结构写入labels.json。例如:
{ "00:00": "negative", "02:13": "positive", "04:57": "negative", "15:41": "positive", "18:24": "negative"}
在上面的示例中,00:00-02:12之间的所有音频片段都被标记为negative,而02:13-04:56之间的所有音频片段都被标记为positive,以此类推。
生成数据集
在标记完所有音频样本后,接下来我们来生成需要传递给Tensorflow模型的数据集。我创建了一个通用库和一套名为micmon的声音监控实用程序。首先我们来安装这个库:
gitclone git@github.com:/BlackLight/micmon.gitcdmicmon[sudo]pip3 install -r requirements.txt[sudo]python3 setup.py build install
这个模型的设计初衷是处理频率样本,而不是原始的音频。原因是,特定的声音具有特定的“频谱”特征,即基准频率(或者基准频率通常所在的狭窄范围)以及基准频率按照一定比例构成的一组特定谐频。而且,这些频率之间的比率既不受振幅的影响(无论输入音量如何,频率的比率都是恒定的),也不受相位的影响(连续的声音具有相同的频谱特征,无论何时开始记录)。与我们将原始音频样本直接发送到模型相比,这种振幅和不随时间变化的特性可以确保这种方法训练出健壮的声音检测模型的概率更大。此外,该模型也更简单(我们可以简单地将频率分组,同时还不会影响性能,如此一来就可以有效地降低维度),更轻量级(无论样本持续时长多少,该模型都拥有50-100个频带的输入值,而原始的音频一秒钟就包含44100个数据点,并且输入的长度会随着样本的持续时间加长而增加),而且不太容易出现过度拟合的情况。
micmon提供了计算音频样本某些片段的FFT(快速傅立叶变换),我们可以使用低通和高通过滤器将所得频谱分组为频带,并将结果保存到一组numpy压缩文件(.npz )。你可以通过在命令行中运行micmon-datagen命令来执行此操作:
micmon-datagen\ --low 250 --high 2500 --bins 100 \ --sample-duration 2 --channels 1 \ ~/datasets/sound-detect/audio ~/datasets/sound-detect/data
在上面的示例中,我们根据存储在~/dataset/sound-detect/audio下的原始音频样本生成数据集,并将生成的频谱数据存储到~/datasets/sound-detect/data。--low和--high分别表示生成的频谱中的最低频率和最高频率。默认值分别为20Hz(人耳可以听到的最低频率)和20kHz(人耳可以听到且无害的最高频率)。但是,最好再进一步限制这个范围,以尽可能捕获我们想要检测的声音,并尽可能去除任何其他类型的音频背景和不相关的谐波。我发现250-2500Hz的范围足以检测婴儿的哭声。婴儿哭声通常音调很高(考虑到歌剧女高音可以达到的最高音调约为1000Hz),通常我们需要将最高频率加倍以确保获得足够高的谐波(谐波是较高的频率,可以产生音色),但是也不需要太高,以免其他背景声音的谐波污染频谱。此外,我还可以去掉250Hz以下的任何声音,婴儿的啼哭声不太可能发生在这些低频上,将它们包含在内可能会导致检测偏斜。有一个好方法是,用Audacity等均衡器/频谱分析仪打开一些positive音频样本,检查哪些频率在positive样本中占主导地位,并将数据集中在这些频率附近。--bins指定了频率空间的组数(默认值:100)。bin的数量越多,意味着频率分辨率(粒度)越也越高,但如果过高,则可能导致模型过度拟合。
该脚本将原始音频分割为较小的片段,并计算出了每个片段的频谱“签名”。--sample-duration指定了每个片段应为多长时间(默认值:2秒)。这个值越大,则持续时间越长的声音效果越好,但是会缩短检测时间,并且可能在声音很短时失败。这个值越小,则持续时间越短的声音效果越好,但是如果声音较长,则捕获的片段可能没有足够的信息来可靠地识别声音。
除了micmon-datagen脚本之外,你也可以制作自己的脚本,通过我提供的micmonAPI生成数据集。例如:
importos
frommicmon.audio import AudioDirectory, AudioPlayer, AudioFilefrommicmon.dataset import DatasetWriter
basedir= os.path.expanduser('~/datasets/sound-detect')audio_dir= os.path.join(basedir, 'audio')datasets_dir= os.path.join(basedir, 'data')cutoff_frequencies= [250, 2500]
#Scan the base audio_dir for labelled audio samplesaudio_dirs= AudioDirectory.scan(audio_dir)
#Save the spectrum information and labels of the samples to a#different compressed file for each audio file.foraudio_dir in audio_dirs: dataset_file = os.path.join(datasets_dir,os.path.basename(audio_dir.path) + '.npz') print(f'Processing audio sample{audio_dir.path}')with AudioFile(audio_dir) as reader, \ DatasetWriter(dataset_file, low_freq=cutoff_frequencies[0], high_freq=cutoff_frequencies[1]) as writer: for sample in reader: writer += sample
无论你使用micmon-datagen还是micmon Python API,这一步结束后,你应该能在~/datasets/sound-detect/data找到一堆.npz文件,原始数据集中的每个标记音频文件都有一个。我们可以使用该数据集来训练声音检测的神经网络。
训练模型
micmon使用Tensorflow+ Keras定义和训练模型。我们可以使用提供的Python API轻松完成此操作。例如:
importosfromtensorflow.keras import layers
frommicmon.dataset import Datasetfrommicmon.model import Model
#This is a directory that contains the saved .npz dataset filesdatasets_dir= os.path.expanduser('~/datasets/sound-detect/data')
#This is the output directory where the model will be savedmodel_dir= os.path.expanduser('~/models/sound-detect')
#This is the number of training epochs for each dataset sampleepochs= 2
#Load the datasets from the compressed files.#70% of the data points will be included in the training set,#30% of the data points will be included in the evaluation set#and used to evaluate the performance of the model.datasets= Dataset.scan(datasets_dir, validation_split=0.3)labels= ['negative', 'positive']freq_bins= len(datasets[0].samples[0])
#Create a network with 4 layers (one input layer, two intermediate layers andone output layer).#The first intermediate layer in this example will have twice the number ofunits as the number#of input units, while the second intermediate layer will have 75% of the numberof#input units. We also specify the names for the labels and the low and high frequencyrange#used when sampling.model= Model( [ layers.Input(shape=(freq_bins,)), layers.Dense(int(2 * freq_bins),activation='relu'), layers.Dense(int(0.75 * freq_bins),activation='relu'), layers.Dense(len(labels),activation='softmax'), ], labels=labels, low_freq=datasets[0].low_freq, high_freq=datasets[0].high_freq)
#Train the modelforepoch in range(epochs): for i, dataset in enumerate(datasets): print(f'[epoch {epoch+1}/{epochs}][audio sample {i+1}/{len(datasets)}]') model.fit(dataset) evaluation = model.evaluate(dataset) print(f'Validation set loss andaccuracy: {evaluation}')
#Save the modelmodel.save(model_dir,overwrite=True)
在运行该脚本后(对模型的准确性感到满意之后),你会发现新模型保存在~/models/sound-detect。就我的情况而言,从婴儿的房间中收集约5个小时的声音就足够了,然后再定义一个好的频率范围,将模型的准确度训练到>98%,就万事俱备了。如果你在计算机上训练了该模型,则只需将其复制到树莓派,然后就可以开始下一步了。
使用模型进行预测
下面我们来制作一个脚本,使用麦克风收集到的实时音频数据来运行前面训练好的模型,并在宝宝啼哭时通知我们:
importos
frommicmon.audio import AudioDevicefrommicmon.model import Model
model_dir= os.path.expanduser('~/models/sound-detect')model= Model.load(model_dir)audio_system= 'alsa' # Supported: alsa andpulseaudio_device= 'plughw:2,0' # Get list of recognizedinput devices with arecord -l
withAudioDevice(audio_system, device=audio_device) as source: for sample in source: source.pause() # Pause recording while we process the frame prediction = model.predict(sample) print(prediction) source.resume() #Resume recording
在树莓派上运行这个脚本,并运行一会儿,如果在过去2秒钟内未检测到哭声,则输出negative,否则输出positive。
但是,我们努力了半天,结果只是在宝宝哭的时候,在标准输出中打印消息也没有太大用处,如果能收到通知就好了!我们可以使用Platypush来实现这部分功能。在这个示例中,当检测到哭泣时,我们将使用Pushbullet集成向手机发送消息。下面,我们来安装带有HTTP和Pushbullet集成的Redis(用于Platypush接收消息)和Platypush:
[sudo]apt-get install redis-server[sudo]systemctl start redis-server.service[sudo]systemctl enable redis-server.service[sudo]pip3 install 'platypush[http,pushbullet]'
在智能手机上安装Pushbullet应用,然后去pushbullet.com获取API令牌。然后再创建一个~/.config/platypush/config.yaml文件,以启用HTTP和Pushbullet集成:
backend.http: enabled: Truepushbullet: token: YOUR_TOKEN
下面,我们来修改前面的脚本,将在标准输出打印消息的部分改成触发Platypush可以捕捉到的CustomEvent:
#!/usr/bin/python3
importargparseimportloggingimportosimportsys
fromplatypush import RedisBusfromplatypush.message.event.custom import CustomEvent
frommicmon.audio import AudioDevicefrommicmon.model import Model
logger= logging.getLogger('micmon')defget_args(): parser = argparse.ArgumentParser() parser.add_argument('model_path',help='Path to the file/directory containing the saved Tensorflow model') parser.add_argument('-i', help='Input sounddevice (e.g. hw:0,1 or default)', required=True, dest='sound_device') parser.add_argument('-e', help='Name of theevent that should be raised when a positive event occurs', required=True,dest='event_type') parser.add_argument('-s', '--sound-server',help='Sound server to be used (available: alsa, pulse)', required=False,default='alsa', dest='sound_server') parser.add_argument('-P','--positive-label', help='Model output label name/index to indicate a positivesample (default: positive)', required=False, default='positive',dest='positive_label') parser.add_argument('-N','--negative-label', help='Model output label name/index to indicate a negativesample (default: negative)', required=False, default='negative',dest='negative_label') parser.add_argument('-l','--sample-duration', help='Length of the FFT audio samples (default: 2seconds)', required=False, type=float, default=2., dest='sample_duration') parser.add_argument('-r', '--sample-rate',help='Sample rate (default: 44100 Hz)', required=False, type=int,default=44100, dest='sample_rate') parser.add_argument('-c', '--channels',help='Number of audio recording channels (default: 1)', required=False,type=int, default=1, dest='channels') parser.add_argument('-f', '--ffmpeg-bin',help='FFmpeg executable path (default: ffmpeg)', required=False,default='ffmpeg', dest='ffmpeg_bin') parser.add_argument('-v', '--verbose',help='Verbose/debug mode', required=False, action='store_true', dest='debug') parser.add_argument('-w','--window-duration', help='Duration of the look-back window (default: 10seconds)', required=False, type=float, default=10., dest='window_length') parser.add_argument('-n','--positive-samples', help='Number of positive samples detected over the windowduration to trigger the event (default: 1)', required=False, type=int,default=1, dest='positive_samples')opts, args =parser.parse_known_args(sys.argv[1:]) return optsdefmain(): args = get_args() if args.debug: logger.setLevel(logging.DEBUG)model_dir =os.path.abspath(os.path.expanduser(args.model_path)) model = Model.load(model_dir) window = [] cur_prediction = args.negative_label bus = RedisBus()with AudioDevice(system=args.sound_server, device=args.sound_device, sample_duration=args.sample_duration, sample_rate=args.sample_rate, channels=args.channels, ffmpeg_bin=args.ffmpeg_bin, debug=args.debug) assource: for sample in source: source.pause() # Pause recording while we process the frame prediction = model.predict(sample) logger.debug(f'Sample prediction:{prediction}') has_change = Falseif len(window) < args.window_length: window += [prediction] else: window = window[1:] +[prediction]positive_samples = len([pred forpred in window if pred == args.positive_label]) if args.positive_samples <=positive_samples and \ prediction ==args.positive_label and \ cur_prediction !=args.positive_label: cur_prediction =args.positive_label has_change = True logging.info(f'Positive samplethreshold detected ({positive_samples}/{len(window)})') elif args.positive_samples >positive_samples and \ prediction ==args.negative_label and \ cur_prediction !=args.negative_label: cur_prediction = args.negative_label has_change = True logging.info(f'Negative samplethreshold detected ({len(window)-positive_samples}/{len(window)})')if has_change: evt = CustomEvent(subtype=args.event_type,state=prediction) bus.post(evt)source.resume() # Resume recordingif__name__ == '__main__': main()
将上述脚本保存成~/bin/micmon_detect.py。这个脚本只会在window_length秒的滑动窗口中检测到至少positive_samples个样本时才触发事件(这是为了减少预测错误或临时故障引发的噪声),并且仅在当前预测从negative变为positive时才触发事件,反之亦然。接下来,通过RedisBus将该事件发送到Platypush。这个脚本的通用性非常好,可以处理任何声音模型(不一定是检测婴儿啼哭的声音模型)、任何positive/negative标签、任何频率范围以及任何类型的输出事件。
下面,我们来创建一个Platypush钩子,对事件做出反应并将通知发送到我们的设备上。首先,准备尚未创建的Platypush脚本目录:
mkdir-p ~/.config/platypush/scriptscd~/.config/platypush/scripts#Define the directory as a moduletouch__init__.py#Create a script for the baby-cry eventsvibabymonitor.py
babymonitor.py的内容如下:
fromplatypush.context import get_pluginfromplatypush.event.hook import hookfromplatypush.message.event.custom import CustomEvent @hook(CustomEvent,subtype='baby-cry', state='positive')defon_baby_cry_start(event, **_): pb = get_plugin('pushbullet') pb.send_note(title='Baby cry status',body='The baby is crying!') @hook(CustomEvent,subtype='baby-cry', state='negative')defon_baby_cry_stop(event, **_): pb = get_plugin('pushbullet') pb.send_note(title='Baby cry status',body='The baby stopped crying - good job!')
接下来,创建一个Platypush的服务文件(如果尚不存在的话),然后启动服务,这样它会在意外退出或系统重启时自动启动:
mkdir-p ~/.config/systemd/userwget-O ~/.config/systemd/user/platypush.service \ https://raw.githubusercontent.com/BlackLight/platypush/master/examples/systemd/platypush.servicesystemctl--user start platypush.servicesystemctl--user enable platypush.service
另外,还需要为婴儿监护仪创建一个服务,例如:
~/.config/systemd/user/babymonitor.service
内容如下:
[Unit]Description=Monitorto detect my baby's criesAfter=network.targetsound.target[Service]ExecStart=/home/pi/bin/micmon_detect.py-i plughw:2,0 -e baby-cry -w 10 -n 2 ~/models/sound-detectRestart=alwaysRestartSec=10[Install]WantedBy=default.target
这个服务会启动ALSA设备plughw:2,0上的麦克风监视仪。如果在过去10秒钟内检测到至少2个2秒的positive样本,且前一个状态为negative,则该服务会触发事件baby-cry,并设置state=positive;如果在过去10秒钟内检测到的positive样本少于两个,且前一个状态为positive,则设置state=negative。我们可以通过以下方法启动该服务:
systemctl--user start babymonitor.servicesystemctl--user enable babymonitor.service
检查在宝宝开始哭泣时,是否会收到手机通知。如果没有收到通知,则可以查看音频样本的标签、神经网络的结构和参数、或样本长度/窗口/频带等参数。
另外,这是一个相对比较基本的自动化示例,你可以在此基础之上实验各种自动化任务。例如,你可以使用tts插件向另一个Platypush设备(例如卧室或客厅)发送请求,大声呼喊:“宝宝哭啦”。你还可以扩展micmon_detect.py脚本,以便捕获的音频样本可以通过HTTP流传输,使用Flask打包器和ffmpeg进行音频转换。
还有一个有趣的实验,在婴儿开始/停止哭泣时,将数据点发送到本地数据库。这是一组非常有意义的数据,你可以通过这些数据来记录宝宝何时入睡,何时醒着,何时需要喂奶。监护宝宝是我开发micmon的主要动机,你可以利用相同的过程来训练和使用模型来检测任何类型的声音。最后,你还可以考虑使用优质的移动电源或锂电池来构建移动版的声音监视仪。
婴儿摄像头
在拥有良好的音频输入,并通过某种方法检测到positive音频序列何时开始/停止后,我们可以添加视频输入,以密切关注宝宝。在我的第一次尝试中,我在检测音频的树莓派上搭载了一台PiCamera,但我发现这种配置不切实际。如果你正在寻找一款轻量级的摄像头,可以轻松安装在某个底座或伸缩架上,你可以转动摄像头,随时随地关注你的宝宝,那么你可以将树莓派放在自己的外壳中,然后搭载一盒电池,并在顶部固定一个摄像头就可以了,尽管看上去非常笨重。最终我选择了一款带有PiCamera兼容机壳和小型移动电源的小型树莓派Zero。
图:我的第一个带有摄像头的婴儿监护仪原型
就像在其他设备上一样,你可以将SD卡插入与树莓派兼容的OS。然后将与树莓派兼容的摄像头插入插槽中,确保已在raspi-config中启用摄像头模块,并通过PiCamera集成安装Platypush:
[sudo]pip3 install 'platypush[http,camera,picamera]'
然后在~/.config/platypush/config.yaml中加入摄像头的配置:
camera.pi:listen_port: 5001
你可以检查Platypush重启时的这个配置,并通过HTTP获取摄像机的快照:
wgethttp://raspberry-pi:8008/camera/pi/photo.jpg
或者在浏览器中打开视频:
http://raspberry-pi:8008/camera/pi/video.mjpg
你还可以创建一个钩子,当应用程序启动时,通过TCP/H264传输视频流:
mkdir-p ~/.config/platypush/scriptscd~/.config/platypush/scriptstouch__init__.pyvicamera.py
camera.py的内容如下:
fromplatypush.context import get_pluginfromplatypush.event.hook import hookfromplatypush.message.event.application import ApplicationStartedEvent
@hook(ApplicationStartedEvent)defon_application_started(event, **_): cam = get_plugin('camera.pi') cam.start_streaming()
你可以在VLC中播放视频:
vlctcp/h264://raspberry-pi:5001
或通过VLC应用、RPi Camera Viewer等应用在手机上播放视频。
原文:https://towardsdatascience.com/create-your-own-smart-baby-monitor-with-a-raspberrypi-and-tensorflow-5b25713410ca
本文为 CSDN 翻译,转载请注明来源出处。
更多精彩推荐强化学习:10种真实的奖励与惩罚应用
NLP实战:利用Python理解、分析和生成文本 | 赠书
AI 隐身术,能让物体在视频中消失的魔法
CPU究竟是如何执行任务的?
太扎心!人艰不拆!16 个程序员专属笑话讲给你听
相关文章:

python快速小教程
http://www.cnblogs.com/vamei/archive/2012/09/13/2682778.html
web标准的投资回报
web标准的投资回报(ROI)作者:阿捷 2004-7-6 0:17:49原文作者:D. Keith Robinson 原文出处:asterisk 原文发表时间:2004年6月1日 用web标准开发能够带来实际利益,这一点还有人怀疑吗? 如果有,…

使用javascript让项目支持热插拔
2019独角兽企业重金招聘Python工程师标准>>> 突然想起之前做过的一个小项目,项目虽小,需求却不小,要求解析特定格式的字符串,并且特定格式并非一成不变,想要一套系统能够支持解析多变的规则且更改规则时不能…

设计模式:状态模式(State Pattern)
作者:Wang Juqiang 创建于:2012-07-16 出处:http://www.cnblogs.com/wangjq/archive/2012/07/16/2593485.html 收录于:2013-03-01 结构图 意图 允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。 适用性…
拼命学的编程,你却可能错过一个亿!
先来看 2 则新闻:近日 AI 圈最火的新闻当属“AI独角兽依图科技上市”,“AI四小龙”先后开启了上市之路,继旷视科技、云从科技分别谋求港股、A股上市后,依图科技也加入了 IPO 队伍。国内 AI 科技公司的发展,也标志着国家…
web标准的商业价值
web标准的商业价值作者:阿捷 2004-7-3 0:37:26原文来自:adaptivepath.com 作者介绍:Jeffrey Veen是AdaptivePath.com的合伙人之一,专门研究网页设计新技术,你可以在他的个人站点veen.com上学到更多知识。 自从开始we…

OO真经——关于面向对象的哲学体系及科学体系的探讨(上)
http://www.cnblogs.com/leoo2sk/archive/2009/04/09/1432103.html 目录 Catelog 序言 Perface 真经第一章:世界 Waltanschauung 真经第二章:抽象 Abstraction 真经第三章:层次 Arrangement 真经第四章:继承 Inheritance 真经第五…
一次防CC***案例
本文来自 :http://baiying.blog.51cto.com/1068039/1113087 名词解释:摘自百度百科 名称起源 CC Challenge Collapsar,其前身名为Fatboy***,是利用不断对网站发送连接请求致使形成拒绝服务的目的, CC***是DDOS(分布…

滴滴联合比亚迪:首款定制网约车D1发布
11月16日,滴滴出行举办“滴滴开放日”,正式发布全球首款定制网约车D1。这款车基于滴滴平台上5.5亿乘客、上千万司机需求、百亿次出行数据,针对网约车出行场景,在车内人机交互、司乘体验、车联网等多方面进行定制化设计。作为第一款…

表格对决CSS--一场生死之战
表格对决CSS--一场生死之战作者:阿捷 2004-7-19 21:00:54原文作者:Sergio Villarreal 作者简介:墨西哥网页设计师,1993年接触网络,个人主页为Overcaffeinated.net 原文出处:sitepoint.com 原文发表时间&…
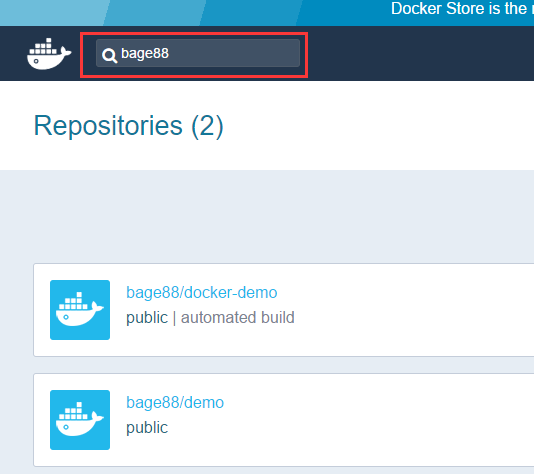
使用Docker-Docker for Web Developers(2)
1. 使用镜像 1.1 在Docker Hub上查找镜像 我们查找一下之前博客里面,推送到Docker Hub里面的bage88/docker-demo,能看到有2个仓库,第一个就是我们上次上传的镜像。点击“Details”进入到详细页面。 1.2 拉取镜像到本地机器 在我们本地虚拟机上…
赠书 | 图像分类问题建模方案探索实践
作者 | 中国农业银行 陆春晖责编 | 晋兆雨出品 | AI科技大本营头图 | 付费下载于视觉中国*文末有赠书福利背景图像分类,是计算机视觉领域的一个核心问题,顾名思义就是输入一张图像,根据内容将其划分到某一个特定的类别。与其他分类问题相比&a…
数据库开发个人总结(ADO.NET小结)
一.用SqlConnection连接SQL Server 1..加入命名空间using System.Data.SqlClient;2.连接数据库SqlConnection myConnection new SqlConnection();myConnection.ConnectionString "user idsa;passwordsinofindb;initial catalogtest;data source127.0.0.1;Con…
PHP 调用C的代码
用php调用C函数,常通过调用系统命令函数的方式来实现,其中主要有system()和exec()两种,还有一种是passthru(),这种方法没有尝试,暂不作讨论。 system()方法输出并返回最后一行的shell结果。 exec()不输出结果,返回最后…
态势“知”多少,点开就知道
2019独角兽企业重金招聘Python工程师标准>>> 态势感知,最核心的是“知” 关于“知” 典故不少 《孙子兵法》六千多字,“知”出现了79次,只有《势篇》与《行军篇》中没有“知”字。 史称两个半完人之一的王阳明 在经过五溺三变的曲…
17 种正则表达式
作者:http://blog.csdn.net/hivak47/archive/2004/10/31/161006.aspx"^/d$" //非负整数(正整数 0) "^[0-9]*[1-9][0-9]*$" //正整数 "^((-/d)|(0))$" //非正整数(负整数 0)…
程序员如何乘风破浪?从数据库历史看技术人发展 | CSDN 高校俱乐部
2009 年我国数据库软件市场规模为 35.03 亿元,2017 年我国数据库软件市场规模增长至 120.00 亿元。8年时间内,我国数据库软件市场始终保持平稳增长,年均复合增长率为 17.5%,且增速呈现递增趋势。根据中研产业研究院估计࿰…
陶哲轩实分析 定理 13.3.5 :紧致度量空间上的连续函数一致连续
设 $(X,d_X)$ 和 $(Y,d_Y)$ 都是度量空间,假定 $(X,d_X)$ 是紧致的,如果 $f:X\to Y$ 是函数,那么 $f$ 是连续的当且仅当 $f$ 是一致连续的.证明:当 $f$ 是一致连续时,$f$ 显然是连续的.我们主要证明 $f$ 连续时一致连续.我们采用反证法,假若 $f$ 不是一致收敛的,意味着无论如何…

SQLServer------插入数据时出现IDENTITY_INSERT错误
详细错误信息: 当 IDENTITY_INSERT 设置为 OFF 时,不能为表 Student 中的标识列插入显式值。 原因: 表中存在某个字段是自动增长的标识符 解决方法: set IDENTITY_INSERT Student ON //设置为OFF时表示不能手动给拥有标识符的列插…
ASP.NET 制作让搜索引擎可以友好访问的链接
作者:http://www.donews.net/lealting/archive/2004/03/31/9759.aspx今天看了一篇文章,主要是讲,如何制作让搜索引擎可以友好访问的链接,大概的内容是这样的:很多的时候我们在进行查询的时候,总是会以这样的…
机器学习中的7种数据偏见
作者 | Hengtee Lim翻译 | Katie,责编 | 晋兆雨出品 | AI科技大本营头图 | 付费下载于视觉中国机器学习中的数据偏差是一种错误,其中数据集的某些元素比其他元素具有更大的权重和或表示。有偏见的数据集不能准确地表示模型的用例,从而导致结果…

windows7 下arp 绑定的实现
局域网的arp***常常让人头痛,绑定IP/MAC地址是解决方式之一; 在xp下面绑定mac地址很简单,只需“arp -s IP地址 MAC地址 ”就ok, 在win7下的命令有所不同; 首先,需要查看可用网卡的id,使用命令n…
Asp.net(c#)实现多线程断点续传
http://www.cnblogs.com/bestcomy/archive/2004/08/10/31950.html以前一直错误的认为在ASP.NET中无法通过编程方式实现多线程断点续传,今天终于获得了这样一个解决方案,让我明白要学习的东西还很多。此解决方案基于其它解决方案及相关资料,根…
0.7秒完成动漫线稿上色,爱奇艺发布AI上色引擎
出品 | AI科技大本营(ID:rgznai100)中国漫画的需求量在不断增加,而动漫制作成本一直居高不下。究其原因为动漫制作是一个复杂且耗时的过程,需要大量工作人员在不同阶段进行协作。动漫制作过程中,需先创作关键帧草图&am…
Java Web整合开发读书笔记
下载JDK:http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html 下载Eclipse: http://www.eclipse.org/downloads/ 下载Tomcat: http://tomcat.apache.org/download-70.cgi 正则表达式:http://www.cnblogs.com/deerchao…

ListView中CheckBox使用问题
因为CheckBox的点击事件优先级比ListView的高,所以当ListView中使用CheckBox会导致ListView的setOnItemClickListener失去响应。 解决的方法:在CheckBox中加入android:focusable"false"。使得CheckBox初始的时候没有获取焦点。 假设想在单击C…
网页播放的视频代码
网页播放的视频代码 第一种是通过调用window media player进行播放诸如:wmv,asf等格式文件: <object alignmiddle classOBJECT classidCLSID:22d6f312-b0f6-11d0-94ab-0080c74c7e95 height320 idMediaPlayer width356> <param name"ShowStatusBar…
[Ruby] 模块
1. 命名空间模块定义了一个命名空间,方法和常量可以在其中任意使用而不必担心被其他方法或常量干扰,例如:module Testdef Test.method()end end模块常量的命名和类常量一样,都以大写字母开头,方法定义类似于类方法的定…
10个工程师,9个不合格!
如果你想问最近这些年什么编程语言最值得学习,我会毫不犹豫的告诉你是Python。无论是刚入门的程序员,还是年薪BATJ的技术大牛,都无可否认现在Python对于一个程序员职业发展的重要性。所以不仅是开发小白,甚至很多开发老手…
云计算(2)it 是什么
2015年,全世界在it上面的花费达到3亿8千亿美金之多。 云数据中心:核心基础架构,云计算的物理载体,提供数据处理、存储和高性能计算支撑,包括服务器、存储、冷却、机房空间和能耗管理等。 超大规模的云数据中心…