赠书 | 新手指南——如何通过HuggingFace Transformer整合表格数据
作者 | Ken Gu
翻译| 火火酱~,责编 | 晋兆雨
出品 | AI科技大本营
头图 | 付费下载于视觉中国
*文末有赠书福利
不可否认,Transformer-based模型彻底改变了处理非结构化文本数据的游戏规则。截至2020年9月,在通用语言理解评估(General Language Understanding Evaluation,GLUE)基准测试中表现最好的模型全部都是BERT transformer-based 模型。如今,我们常常会遇到这样的情形:我们手中有了表格特征信息和非结构化文本数据,然后发现,如果将这些表格数据应用到模型中的话,可以进一步提高模型性能。因此,我们就着手构建了一个工具包,以方便后来的人可以轻松实现同样的操作。
在Transformer的基础之上进行构建
使用transformer的主要好处是,它可以学习文本之间的长期依赖关系,并且可以并行地进行训练(与sequence to sequence模型相反),这意味着它可以在大量数据上进行预训练。
鉴于这些优点,BERT现在成为了许多实际应用程序中的主流模型。同样,借助HuggingFace Transformer之类的库,可以轻松地在常见NLP问题上构建高性能的transformer模型。
目前,使用非结构化文本数据的transformer模型已经为大众所熟知了。然而,在现实生活中,文本数据往往是建立在大量结构化数据或其他非结构化数据(如音频或视觉信息)的基础之上的。其中每一种数据都可能会提供独一无二的信号。我们将这些体验数据(音频、视频或文本)的不同方式称为模态。
以电商评论为例。除了评论文本本身之外,还可以通过数字和分类特征来获取卖家、买家以及产品的相关信息。
在本文中,我们将一起学习如何将文本和表格数据结合在一起,从而为自己的项目提供更强的信号。首先,我们将从多模态学习领域开始——该领域旨在研究如何在机器学习中处理不同的模态。
多模态文献综述
目前的多模态学习模式主要集中在听觉、视觉和文本等感官模态的学习上。
在多模态学习中,有多个研究分支。根据卡内基梅隆大学(Carnegie Mellon University)MultiComp实验室提出的分类方法,我们要处理的问题属于多模态融合(Multimodal Fusion)问题——如何将两种或两种以上的模态信息结合起来进行预测。
由于文本数据是我们的主模态,因此我们将重点关注以文本作为主要模态的文献,并介绍利用transformer架构的模型。
结构化数据的简单解决方案
在深入研究各文献之前,我们可以采取一个简单的解决方案:将结构化数据视为常规文本,并将其附加到标准文本输入中。以电商评论为例,输入可构建如下:Review. Buyer Info. Seller Info. Numbers/Labels. Etc.不过,这种方法有一个缺点,那就是它受到transformer所能处理的最大令牌长度的限制。
图像和文本Transformer
在过去的几年中,用于图像和文本的transformer扩展取得了显著的进步。Kiela等人在2019年发表的论文《Supervised Multimodal Bitransformers for Classifying Images and Text》中,将预训练的ResNet和预训练的BERT分别应用在非模态图像和文本上,并将其输入双向transformer。其关键性创新是将图像特征作为附加令牌应用到transformer模型中。 此外,ViLBERT(Lu et al.,2019)和VLBert(Su et al.,2020)等模型对图像和文本的预训练任务进行了定义。这两个模型都在Conceptual Captions数据集上进行了预训练,该数据集中包含大约330万幅图像-标题对(带有alt文本标题的网络图像)。以上两个模型,对于给定的图像,预训练对象检测模型(如Faster R-CNN)会获取图像区域的向量表示,并将其视为输入令牌嵌入到transformer模型中。
例如,ViLBert对以下目标进行了预训练:
1. 遮蔽多模态建模:遮蔽输入图像和单词令牌。对于图像,模型会预测对应图像区域中捕获图像特征的向量;而对于文本,则根据文本和视觉线索预测遮蔽文本。
2. 多模态对齐:预测图像和文本是否匹配对齐,即是否来自同一图像-标题对。
预训练任务的图像和遮蔽多模态学习示例如下所示:对于给定图像和文本,如果我们把dog遮蔽掉的话,那么模型应该能够借助未被遮蔽的视觉信息来正确预测被遮蔽的单词是dog。
所有模型都使用了双向transformer模型,这是BERT的骨干支柱。不同之处在于模型的预训练任务和对transformer进行的少量添加。在ViLBERT的例子中,作者还引入了一个co-attention transformer层,以明确定义不同模态之间的attention机制。
最后,还有由Tan和Mohit于2019年发表的LXMERT——另一个预训练transformer模型,从Transformer 3.1.0版本开始,它已经实现为库的一部分了。LXMERT的输入与ViLBERT和VLBERT相同。但是,LXMERT在聚合数据集上进行预训练,其中也包括视觉问答数据集。LXMERT总共对918万个图像-文本对进行了预训练。
音频、视频、文本对准Transformers
除了用于组合图像和文本的transformer之外,还有针对音频、视频和文本模态的多模态模型。这方面的论文有Tsai等人于2019年发表的《MulT, Multimodal Transformer for Unaligned Multimodal Language Sequences》,以及Rahman等人于2020年发表的《Multimodal Adaptation Gate (MAG) from Integrating Multimodal Information in Large Pretrained Transformers》。
与ViLBert类似,MuIT中也在模态对中采用了co-attention机制。同时,MAG希望通过门控机制在某些transformer层中注入其他模态信息。
文本和知识图谱嵌入式Transformer
有一些研究还将知识图谱看作除文本数据之外的另一重要信息。在Ostendorff等人于2019年发表的《Enriching BERT with Knowledge Graph Embeddings for Document Classification》中,除了元数据特征外,还使用Wikidata 知识图谱中作者实体特征进行图书类别分类。在进入最终分类层之前,模型会将这些特征、书名和描述的BERT输出文本特征进行简单组合。
关键要点
采用针对多模态数据的transformer的目的是要确保多模态之间有attention或权重机制。attention机制可以发生在transformer架构的不同位置,例如编码输入嵌入、在中间注入、或在transformer对文本数据进行编码后进行组合。
多模态Transformers工具包
我们利用从文献综述以及最先进的transformer综合HuggingFace库中学到的知识,开发了一个工具包。该多模态-transformer包拓展了所有HuggingFace 表格数据transformer。欢迎大家点击下方链接查看代码、文档和工作示例。
(链接:
https://github.com/georgianpartners/Multimodal-Toolkit?ref=hackernoon.com)
在更高的层面上,文本数据以及包含分类和数字数据表格特征的transformer模型输出会在组合模块中进行组合。由于我们的数据中没有对齐,所以我们选择在transformer输出之后对文本特征进行组合。组合模块实现了多种整合模态的方法,包括attention和门控方法。点击下方链接,获取更多相关细节。
(链接:
https://multimodal-toolkit.readthedocs.io/en/latest/notes/combine_methods.html?ref=hackernoon.com)
演练
下面,我们将通过一个服装评论推荐示例进行演练。我们将使用Colab笔记本中示例的简化版本,利用Kaggle上的女装电商服装评论,其中包含23000条客户评论。
该数据集中,在标题和评论文本列中有文本数据,在“服装ID”、“部门名称”、和“类别名称”列中有分类特征,在“评级”和“好评数”中有数字特征。
加载数据集
首先,我们将数据加载到TorchTabularTextDataset中,与PyTorch的数据加载器配合作业,包括HuggingFace Transformers文本输入、我们指定的分类特征列和数字特征列。为此,我们还需要加载HuggingFace tokenizer.。
加载表格模型Transformer
接下来,我们用表格模型加载transformer。首先,在TabularConfig对象中指定表格配置。然后将其设置为HuggingFace transformer 配置对象的tabular_config成员变量。这里,我们还要指定表格特性与文本特性的结合方式。在本例中,我们将使用加权和的方法。
在设置好tabular_config集之后,我们就可以使用与HuggingFace相同的API来加载模型。点击下方链接,了解当前包含该表格组合模块的transformer模型列表。
(列表链接:
https://multimodal-toolkit.readthedocs.io/en/latest/modules/model.html?ref=hackernoon.com#module-multimodal_transformers.model.tabular_transformers)
训练
这里,我们可以使用HuggingFace的Trainer。需要指定训练参数,在本例中,我们将使用默认参数。
一起来看看训练中的模型吧!
结果
我们还使用该工具包对女性电商服装评论数据集进行了推荐预测实验,对墨尔本Airbnb开放数据集进行了价格预测实验。前者是一个分类任务,而后者是一个回归任务,结果如下表所示。text_only combine方法是仅使用transformer的基线,本质上与SequenceClassification模型的HuggingFace相同。
不难看出,相比于纯文本方法,表格特征的加入有助于提高性能。此外,表格数据的训练信号越强,性能越好。例如,在评论推荐案例中,纯文本模型就已经是非常强大的基线了。
下一步工作
我们已经在自己的项目中成功使用了这个工具箱,也欢迎大家在自己的下一个机器学习项目中进行试用!
快速回顾一下本文中提到的论文:
图像和文本Transformer
Supervised Multimodal Bitransformers for Classifying Images and Text (Kiela et al. 2019)
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks (Lu et al. 2019)
VL-BERT: Pre-training of Generic Visual-Linguistic Representations (Su et al. ICLR 2020)
LXMERT: Learning Cross-Modality Encoder Representations from Transformers (Tan et al. EMNLP 2019)
音频、视频、文本对准Transformers
Multimodal Transformer for Unaligned Multimodal Language Sequences (Tsai et al. ACL 2019)
Integrating Multimodal Information in Large Pretrained Transformers (Rahman et al. ACL 2020)
知识图谱嵌入式Transformers
Enriching BERT with Knowledge Graph Embeddings for Document Classification (Ostendorff et al. 2019)
ERNIE: Enhanced Language Representation with Informative Entities (Zhang et al. 2019
原文链接:
https://hackernoon.com/a-beginner-guide-to-incorporating-tabular-data-via-huggingface-transformers-052i3zko
本文由AI科技大本营翻译,转载请注明出处
#欢迎留言在评论区和我们讨论#
看完本文,对于表格数据处理你有什么想说的?
欢迎在评论区留言
我们将在 12 月 3 日精选出 3 条优质留言
赠送《Python数据科学实践》纸质书籍一本哦!
更多精彩推荐
U^2-Net跨界肖像画,完美复刻人物细节,GitHub标星2.5K+
Python画出心目中的自己
清华、北大教授同台激辩:脑科学是否真的能启发AI?
想在边缘运行计算机视觉程序?先来迎接挑战!
你熟知的开源项目,幕后推手竟然是他们?
相关文章:

在HTML网页中巧用URL
http://www.cnbruce.com/blog/showlog.asp?cat_id5&log_id657 首先,先放出一个地址给大家测试http://cnbruce.com/test/htmlpro/?namecnbruce&emailcnbruce126.com 1,时下流行的(可能是吧,因为最近问的人比较多…
《iOS 8应用开发入门经典(第6版)》——第1章,第1.6节小结
本节书摘来自异步社区《iOS 8应用开发入门经典(第6版)》一书中的第1章,第1.6节小结,作者 【美】John Ray(约翰 雷),更多章节内容可以访问云栖社区“异步社区”公众号查看 1.6 小结iOS 8应用开发…

用Visual C#创建Windows服务程序
一.Windows服务介绍: Windows服务以前被称作NT服务,是一些运行在Windows NT、Windows 2000和Windows XP等操作系统下用户环境以外的程序。在以前,编写Windows 服务程序需要程序员很强的C或C功底。然而现在在Visual Studio.Net下&a…
poj 3321 Apple Tree
树状数组 题意:一个树,以树枝连接两个点的形式给出,固定以1为整棵树的根。苹果长在树的节点上,节点上只可能0或1个苹果,一开始每个节点都有1个苹果 有两种操作,C表示更改某个节点的苹果数,0变1,…
人工智能在网络贷款中鲜为人知的事
作者 | Laksh Mohan翻译| 火火酱~,责编 | 晋兆雨出品 | AI科技大本营头图 | 付费下载于视觉中国现在,科技已经成为推动企业发展壮大的基本要素之一。人工智能(AI)就是一个证明此类技术在商业领域走红的好例子,比如网络…

《HTML5与CSS3实战指南》——2.5 构建The HTML5 Herald
本节书摘来自异步社区《HTML5与CSS3实战指南》一书中的第2章,第2.5节,作者: 【美】Estelle Weyl , Louis Lazaris , Alexis Goldstein 更多章节内容可以访问云栖社区“异步社区”公众号查看。 2.5 构建The HTML5 Herald 我们已经介绍了页面结构的基础以及…
用.NET创建Windows服务
用.NET创建Windows服务 译者说明:我是通过翻译来学习C#的,文中涉及到的有Visual Studio.NET有关操作,我都根据中文版的VS.NET显示信息来处理的,可以让大家不致有误解。作者:Mark Strawmyer 我们将研究如何…

BGP local-preference MED属性实验
实验拓扑 实验配置 建立两个AS 65001、65000 AS65000内跑OSPF,并在R1上发布三个网段100.1.1.1 100.1.2.1 100.1.3.1 在R3 R5上聚合后发布给R4。 每台路由器都有一个对应的loopback地址。 实验过程 <R1>dis bgp ro Total Number of Routes: 10 BGP Local route…
加速产业生态算力升级,华为鲲鹏展翅福州
11月20日,为了让更多开发者了解鲲鹏计算生态体系,并且助力行业人才培养,由福建鲲鹏生态创新中心、福州市大数据基地开发有限责任公司联合举办的鲲鹏开发者训练营圆满完成。此次活动现场吸引到了大量的开发者参与,产、学、研各界人…
《CCNP TSHOOT 300-135认证考试指南》——2.2节故障检测与排除及网络维护工具箱
本节书摘来自异步社区《CCNP TSHOOT 300-135认证考试指南》一书中的第2章,第2.2节故障检测与排除及网络维护工具箱,作者 【加】Raymond Lacoste , 【美】Kevin Wallace,更多章节内容可以访问云栖社区“异步社区”公众号查看 2.2 故障检测与排…
在linux系统下实现音视频即时通讯的部分代码
由于使用习惯,Linux在中国受欢迎程度远不如windows,相应的软件也比较少,尤其是音视频类的软件,但是,这并不代表就完全没有。下面介绍一款强大的音视频即时通讯平台给大家,它就是——Anychat for Linux SDK。AnyChat是一…
文本分类六十年
作者 | Lucy出品 | AI科技大本营文本分类是自然语言处理中最基本而且非常有必要的任务,大部分自然语言处理任务都可以看作是个分类任务。近年来,深度学习所取得的前所未有的成功,使得该领域的研究在过去十年中保持激增。这些文献中已经提出了…
web service 和 remoting 有什么区别
其实现的原理并没有本质的区别,在应用开发层面上有以下区别:1、Remoting可以灵活的定义其所基于的协议,如果定义为HTTP,则与Web Service就没有什么区别了,一般都喜欢定义为TCP,这样比Web Service稍为高效一…
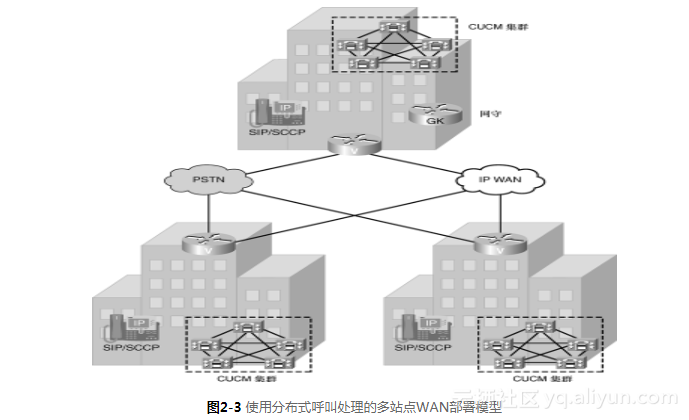
《实施Cisco统一通信管理器(CIPT1)》一2.4 使用分布式呼叫处理的多站点WAN部署模型...
本节书摘来异步社区《实施Cisco统一通信管理器(CIPT1)》一书中的第2章,第2.4节,作者: 【美】Dennis Hartmann译者: 刘丹宁 , 陈国辉 , 卢铭 责编: 傅道坤, 更多章节内容可以访问云栖社区“异步社…
【转】 LDA必读的资料
时间总是不够用,这里就不自己写了,摘自一篇转发的博客,感觉挺有用! 一个大牛写的介绍,貌似需FQ http://tedunderwood.wordpress.com/2012/04/07/topic-modeling-made-just-simple-enough/David M.Blei主页:…
sizeof 操作符详解
1. 定义: sizeof是何方神圣? sizeof 乃 C/C 中的一个操作符(operator)是也。简单说其作用就是返回一个对象或者类型所占的内存字节数。 MSDN上的解释为: The sizeof keyword gives the amount of storage, in bytes, a…
石锤!谷歌排名第一的编程语言,死磕这点,程序员都收益
日本最大的证券公司之一野村证券首席数字官马修汉普森,在Quant Conference上发表讲话:“用Excel的人越来越少,大家都在码Python代码。”甚至直接说:“Python已经取代了Excel。”事实上,为了追求更高的效率和质量&#…

《关系营销2.0——社交网络时代的营销之道》一T表示Technology(技术)
本节书摘来异步社区《关系营销2.0——社交网络时代的营销之道》一书中的第1章,作者: 【美】Mari Smith 译者: 张猛 , 于宏 , 赵俐 责编: 陈冀康, 更多章节内容可以访问云栖社区“异步社区”公众号查看。 T表示Technologyÿ…

jquery拖拽实现UI设计组件
想做一个UI设计的组件,左侧是控件列表,右边是编辑区域,左侧的控件可以重复拖拽到右侧然后进行编辑。 效果草图: 部分js代码: function domop(){//set drag and drop $( "#compls .component" ).each(functi…
六年磨一剑,全时发布音视频会议平台TANG,多款新品亮相
作者 | 高卫华出品 | AI科技大本营时隔六年,全时于11月26日在北京举办了“时间的力量2020新产品发布会“。发布会现场,全时创始人&CEO陈学军回顾了全时近年来的发展历程,并正式推出了全时云会议2020版,全时小智和全时云直播三…
考察新人的两道c语言题目
1> 如何判断一个板子的cpu 是big-endian 还是 Little-endian的?用c实现非常简单,10行左右,就可以判断了, 关键考察新人是否了解了什么是endian ,big-endian与little-endian的区别在哪里, 如果…

《Adobe After Effects CC经典教程》——导读
前 言 After Effects CC提供了一套完整的2D和3D工具,动态影像专业人员、视频特效艺术家、网页设计人员以及电影和视频专业人员都可以用这些工具创建合成图像、动画和特效。After Effects被广泛应用于电影、视频、DVD以及Web的后期数字制作之中。After Effects可以以…
scanf()函数的用法和实践
scanf()函数的用法和实践摘要: 本文阐述了基于ANSI,Win 95,Win NT上的 C/C语言中scanf()函数的用法,以及在实际使用中常见错误及对策。 关键词: scanf()一、 序言 在CSDN论坛的C/C版块,我时常见…
邢波出任全球第一所AI大学校长,履历横跨三门学科
整理 | 高卫华出品 | AI科技大本营近日,世界上第一家研究型人工智能大学——Mohamed bin Zayed University of Artificial Intelligence,简称MBZUAI大学(MBZUAI),任命著名华人AI学术教授邢波为校长。据悉,首…
Ubuntu 10.10 安装 libx11-dev
今天(2013-04-11)尝试安装 ImageMagick,结果发现 config.log 文件中包含了如下错误信息: fatal error: X11/Xlib.h: No such file or directory 也就是说缺少了 libx11-dev 包,心想这有什么难的,直接通过 a…

《计算机组成原理》----2.6 浮点数
本节书摘来自华章出版社《计算机组成原理》一书中的第2章,第2.6节, 作 者 Computer Organization and Architecture: Themes and Variations[英]艾伦克莱门茨(Alan Clements) 著,沈 立 王苏峰…
javascript/dom:原生的JS写选项卡方法
来源:http://www.jb51.net/article/30108.htm <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html xmlns"http://www.w3.org/1999/xhtml"><head><meta http-…
CSDN 星城大巡礼,长沙“科技之星”年度企业评选正式开启
2020年,长沙市委主要领导发出“软件产业再出发”的号召,颁布了软件三年行动计划。今年5月,CSDN 作为专业的 IT 社区,与长沙高新区签约,将全国总部落户长沙,这一战略决策,让CSDN与长沙的联结进一…
Linux下用C获取当前系统时间
#include <time.h> time_t time(time_t calptr); 返回的是日历时间,即国际标准时间公元1970年1月1日00 : 00 : 00以来经过的秒数。然后再调用 char *ctime(const time_t calptr) ; 转化为字符串表示 #include <stdio.h> #inc…
Java程序猿的JavaScript学习笔记(12——jQuery-扩展选择器)
计划按例如以下顺序完毕这篇笔记:Java程序猿的JavaScript学习笔记(1——理念) Java程序猿的JavaScript学习笔记(2——属性复制和继承) Java程序猿的JavaScript学习笔记(3——this/call/apply) J…