对比四种爬虫定位元素方法,你更爱哪个?
作者 | 陈熹
来源 | 早起Python
头图 | 下载于视觉中国
在使用Python本爬虫采集数据时,一个很重要的操作就是如何从请求到的网页中提取数据,而正确定位想要的数据又是第一步操作。本文将对比几种 Python 爬虫中比较常用的定位网页元素的方式供大家学习:
1.传统
BeautifulSoup操作2.基于
BeautifulSoup的 CSS 选择器(与PyQuery类似)3.XPath
4.正则表达式
参考网页是当当网图书畅销总榜:
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1
我们以获取第一页 20 本书的书名为例,先确定网站没有设置反爬措施,是否能直接返回待解析的内容:
import requestsurl = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
print(response)
仔细检查后发现需要的数据都在返回内容中,说明不需要特别考虑反爬举措。
审查网页元素后可以发现,书目信息都包含在 li 中,从属于 class 为 bang_list clearfix bang_list_mode 的 ul 中。
进一步审查也可以发现书名在的相应位置,这是多种解析方法的重要基础
传统 BeautifulSoup 操作
经典的 BeautifulSoup 方法借助 from bs4 import BeautifulSoup,然后通过 soup = BeautifulSoup(html, "lxml") 将文本转换为特定规范的结构,利用 find系列方法进行解析,代码如下:
import requests
from bs4 import BeautifulSoupurl = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).textdef bs_for_parse(response):soup = BeautifulSoup(response, "lxml")li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li') # 锁定ul后获取20个lifor li in li_list:title = li.find('div', class_='name').find('a')['title'] # 逐个解析获取书名print(title)if __name__ == '__main__':bs_for_parse(response)成功获取了 20 个书名,有些书面显得冗长可以通过正则或者其他字符串方法处理,本文不作详细介绍。
基于 BeautifulSoup 的 CSS 选择器
这种方法实际上就是 PyQuery 中 CSS 选择器在其他模块的迁移使用,用法是类似的。关于 CSS 选择器详细语法可以参考:http://www.w3school.com.cn/cssref/css_selectors.asp由于是基于 BeautifulSoup 所以导入的模块以及文本结构转换都是一致的:
import requests
from bs4 import BeautifulSoupurl = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).textdef css_for_parse(response):soup = BeautifulSoup(response, "lxml") print(soup)if __name__ == '__main__':css_for_parse(response)然后就是通过soup.select 辅以特定的 CSS 语法获取特定内容,基础依旧是对元素的认真审查分析:
import requests
from bs4 import BeautifulSoup
from lxml import htmlurl = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).textdef css_for_parse(response):soup = BeautifulSoup(response, "lxml")li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li')for li in li_list:title = li.select('div.name > a')[0]['title']print(title)if __name__ == '__main__':css_for_parse(response)XPath
XPath 即为 XML 路径语言,它是一种用来确定 XML 文档中某部分位置的计算机语言,如果使用 Chrome 浏览器建议安装 XPath Helper 插件,会大大提高写 XPath 的效率。
之前的爬虫文章基本都是基于 XPath,大家相对比较熟悉因此代码直接给出:
import requests
from lxml import htmlurl = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).textdef xpath_for_parse(response):selector = html.fromstring(response)books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li")for book in books:title = book.xpath('div[@class="name"]/a/@title')[0]print(title)if __name__ == '__main__':xpath_for_parse(response)正则表达式
如果对 HTML 语言不熟悉,那么之前的几种解析方法都会比较吃力。这里也提供一种万能解析大法:正则表达式,只需要关注文本本身有什么特殊构造文法,即可用特定规则获取相应内容。依赖的模块是 re。
首先重新观察直接返回的内容中,需要的文字前后有什么特殊:
import requests
import reurl = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
print(response)观察几个数目相信就有答案了:<div class="name"><a href="http://product.dangdang.com/xxxxxxxx.html" target="_blank" title="xxxxxxx">书名就藏在上面的字符串中,蕴含的网址链接中末尾的数字会随着书名而改变。
分析到这里正则表达式就可以写出来了:
import requests
import reurl = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).textdef re_for_parse(response):reg = '<div class="name"><a href="http://product.dangdang.com/\d+.html" target="_blank" title="(.*?)">'for title in re.findall(reg, response):print(title)if __name__ == '__main__':re_for_parse(response)可以发现正则写法是最简单的,但是需要对于正则规则非常熟练。所谓正则大法好!
小结
当然,不论哪种方法都有它所适用的场景,在真实操作中我们也需要在分析网页结构来判断如何高效的定位元素,最后附上本文介绍的四种方法的完整代码,大家可以自行操作一下来加深体会。
import requests
from bs4 import BeautifulSoup
from lxml import html
import reurl = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).textdef bs_for_parse(response):soup = BeautifulSoup(response, "lxml")li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li')for li in li_list:title = li.find('div', class_='name').find('a')['title']print(title)def css_for_parse(response):soup = BeautifulSoup(response, "lxml")li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li')for li in li_list:title = li.select('div.name > a')[0]['title']print(title)def xpath_for_parse(response):selector = html.fromstring(response)books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li")for book in books:title = book.xpath('div[@class="name"]/a/@title')[0]print(title)def re_for_parse(response):reg = '<div class="name"><a href="http://product.dangdang.com/\d+.html" target="_blank" title="(.*?)">'for title in re.findall(reg, response):print(title)if __name__ == '__main__':# bs_for_parse(response)# css_for_parse(response)# xpath_for_parse(response)re_for_parse(response)
更多精彩推荐
☞明年,我要用 AI 给全村写对联☞Ant Design 遭删库!☞每年节省170万美元的文档预览费用,借助机器学习的DropBox有多强?☞三年投 1000 亿,达摩院何以仗剑走天涯?点分享点收藏点点赞点在看
相关文章:

2017年安全漏洞审查报告:安全补丁在不断增加,用户却不安装
软件漏洞难修复吗?年度FLexera漏洞审查报告显示,全部安全漏洞当中有81%已经拥有与之匹配的修复补丁,但多数常见软件项目的补丁安装率却相当低下。 作为一家面向应用程序开发商与企业客户的软件安全漏洞管理解决方案厂商,Flexera S…
Visual SourceSafe简明培训教程
名称Visual SourceSafe简明培训教程(Visual SourceSafe Training Short Course) 作者晨光(Morning) 简介对于采用Visual SourceSafe 6.0作为版本控制工具的项目及产品开发,本教程针对不同用户角色,提供有关该软件的若干使用指导…

水母智能联合蚂蚁森林、犀牛智造等,用AI助力非遗出圈,39万人开工得“福”
如今过年越来越有年味了,许多淡出已久的中国传统年俗,以更有趣、更年轻新潮、更科技的方式回到了大家身边。集五福、写福字、贴福字,挂福饰品,当然还有接“福袋”!人工智能实现智能设计已经相当成熟,已有微…
绿色信托任重道远 应建立补偿机制?
作为绿色金融的分支之一,绿色信托面临的状况不如绿色信贷、绿色债券,整体规模尚小,且监管方面的鼓励措施未有明确,甚至连概念都尚未统一。 日前,北京大学法学院非营利组织法研究中心与中航信托联合发布《2016年绿色信托…
解读C#正则表达式
多少年来,许多的编程语言和工具都包含对正则表达式的支持,.NET基础类库中包含有一个名字空间和一系列可以充分发挥规则表达式威力的类,而且它们也都与未来的Perl 5中的规则表达式兼容。 此外,regexp类还能够完成一些其他的功能&am…

wpa_supplicant学习
2019独角兽企业重金招聘Python工程师标准>>> interface gtk makefile wrapper buffer methods 目录(?)[-] 本来以为这个东西只有在Atheros的平台上用的突然发现Ralink的平台也可以用甚至还看到还有老美把这个东西往android上移植看来是个好东西学习一下 官方…
一张图,看编程语言十年热度变化
作者 | 叶庭云来源 | 修炼Python头图 | 下载于视觉中国什么是 TIOBE 排行榜TIOBE 排行榜是根据互联网上有经验的程序员、课程和第三方厂商的数量,并使用搜索引擎(如Google、Bing、Yahoo!)以及Wikipedia、Amazon、YouTube 统计出排名数据&…
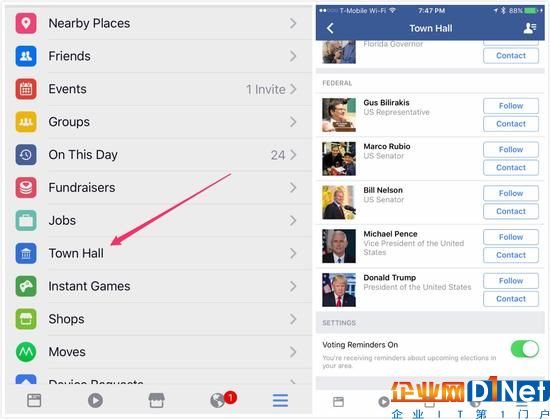
小扎的野心不止做社交 市政厅的上线说明了这一点
一个月前,扎克伯格刚在一封6千字长信里宣布了自己要做一个全球社区的理想,日前Facebook就上线了个叫“市政厅”的政务服务功能。 美国的用户在“市政厅”的功能页填写完自己的地理位置信息之后,可以看到当地政府官员的名单,包括美…
C#调用存储过程简单完整例子
CREATE PROC P_TEST Name VARCHAR(20), Rowcount INT OUTPUT AS BEGINSELECT * FROM T_Customer WHERE NAMENameSET RowcountROWCOUNT END GO ---------------------------------------------------------------------------------------- --存储过程调用如下: -------------…
高手的习惯:pythonic风格代码
来源 | Python大数据分析责编 | 寇雪芹头图 | 下载于视觉中国什么是pythonicpythonic是开发者们在写python代码过程中总结的编程习惯,崇尚优雅、明确、简单。就好比中文的笔画,讲究先后顺序,最符合文字书写的习惯。因为是习惯,不是…

计算机天才Aaron Swartz 名作 《如何提高效率》——纪念真正的“hacker!
如何提高效率 《HOWTO: Be more productive》(如何提高效率)作者:Aaron Swartz 肯定有人跟你说过这样的话,“你有看电视的那么长时间,都可以用来写一本书了”。不可否认写书肯定比看电视更好的利用了时间,但…
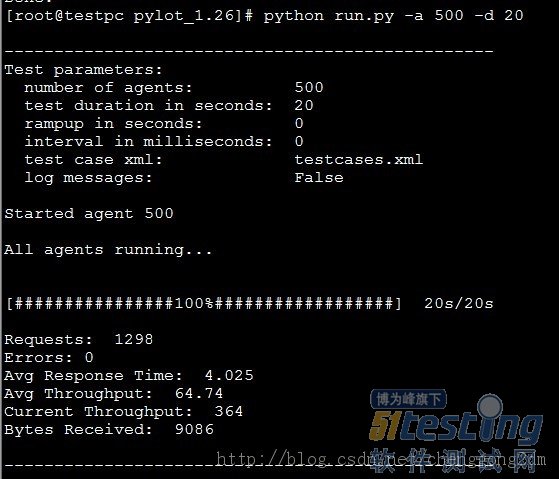
python的web压力测试工具-pylot安装使用
pylot是python编写的一款web压力测试工具。使用比较简单。而且测试结果相对稳定。 这里不得不鄙视一下apache 的ab测试,那结果真是让人蛋疼,同样的url,测试结果飘忽不定,看得人心惊肉跳,摸不着头脑。 下载 pylot官网&a…
快过HugeCTR:用OneFlow轻松实现大型推荐系统引擎
Wide & Deep Learning Wide & Deep Learning (以下简称 WDL)是解决点击率预估(CTR Prediction)问题比较重要的模型。WDL 在训练时,也面临着点击率预估领域存在的两个挑战:巨大的词表(Em…
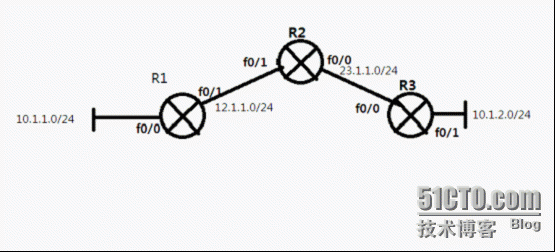
路由的有类和无类
有类和无类路由1.通告时不以主类子网掩码通告,一条路由被通告出去的时候并没有自动汇总,而是以本身的子网掩码通告。即为无类路由。2.被通告的路由化成主类网络后和通告该路由的接口被化成主类网络后相比不是同一个网络,那么这台路由器就产生…
VS2005 常用快捷键
ShiftAltEnter: 切换全屏编辑CtrlB,T / CtrlK,K: 切换书签开关CtrlB,N / CtrlK,N: 移动到下一书签 CtrlB,P: 移动到上一书签 CtrlB,C: 清除全部标签CtrlI: 渐进式搜索 CtrlShiftI: 反向渐进式搜索CtrlF: 查找 CtrlShiftF: 在文件中查找F3: 查找下一个ShiftF3: 查找上一个CtrlH:…
2016政策与市场协同发力大数据,小公司如何搏杀BAT?
大数据这个词来到2016年,绽放出绚烂的光。 先看看最近几天的新闻:大数据分析腐败问题、大数据曝光基友的世界、大数据助交警查处多起毒驾……不仅仅是与经济相关,大数据正在渗透社会各个领域,与传统社会嫁接的大数据,正…
机器学习的第一个难点,是数据探索性分析
作者 | 陆春晖责编 | 寇雪芹头图 | 下载于视觉中国当我们在进行机器学习领域的学习和研究时,遇到的第一个难点就是数据探索性分析(Exploratory Data Analysis)。虽然从各种文献中不难了解到数据探索性分析的重要性和一般的步骤流程࿰…
Asp.net 1.0 升级至 ASP.NET 2.0十个问题总结
1.Global.asax文件的处理形式不一样 转化后将出现错误,在vs2003中Global.asax具有代码后置文件,2.0下, 将代码分离文件移到 App_Code 目录下,以便使其自动变为可通过应用程序中的任意 ASP.NET 页面访问。“Code-behind”属性将从 …
Robotium初探秘
2019独角兽企业重金招聘Python工程师标准>>> Getting started 如果想知道robotium是如何运行、什么样子的,就看下面的步骤。如果想自己新建一个robotium测试工程,点击 此处 要使用Robotium,需要把Robotium.jar放在测试工程的build…
初级Java程序员所面临的4大挑战
一、编码时间过长 作为入门级Java工程师,每周至少编程45小时,而且每个月会有1到2个星期工作50至60小时。从这些数字上看,过去几个月里每周工作将近50小时。80% –90%的工作时间都耗在了电脑前。这样的数字虽然表明了享…
javascript页面跳转常用代码
这东东最难记,每次需要时都是重新到Google上搜,真是烦死了,这回整理一下贴到这。 按钮式: <INPUT name"pclog" type"button" value"GO" onClick"location.hrefhttp://9ba.cn/"> 链…
frame,iframe,frameset之间的关系与区别
2019独角兽企业重金招聘Python工程师标准>>> ■ 框架概念 : 所谓框架便是网页画面分成几个框窗,同时取得多个 URL。只需要 <FRAMESET> <FRAME> 即可,而所有框架标记需要放在一个总起的 html 档,这个档案只…

最低售价17999元,华为发布新一代折叠屏手机Mate X2,将首批升级HarmonyOS
2019年,华为发布第一代折叠屏Mate X,开启了5G折叠屏手机新纪元;2020年,华为发布第二代折叠屏Mate Xs,实现了折叠屏手机从硬件到生态的演进。 2月22日,华为举行新一代折叠旗舰发布会,发布全新折…

「要拼就拼运维」5分钟一台?它让我爱上工作了!
高效运维轻松管理本文转自d1net(转载)
JavaScript去除字符串首尾空格
function trim(str) { return str.replace(//s/g,""); } javascript去除字符串空格的函数 function jtrim(s) { var i,b0,es.length; for(i0;i<s.length;i) //去左空格 if(s.charAt(i)! ){bi;break;} if(is…
server-send event object
http://jamie-wang.iteye.com/blog/1849193 event -- onmessage, onopen, onerror 不是方法,而是事件 http://school.youth.cn/px/lamp/2012/1130/38537.shtml http://www.ibm.com/developerworks/cn/web/1307_chengfu_serversentevent/index.html?cadrs http://bb…
拿来就能用!Dijkstra 算法实现快递路径优化
作者 | 李秋键责编 | 伍杏玲出品 | AI科技大本营(ID:rgznai100)近几年来,快递行业发展迅猛,其中的程序设计涉及到运送路径的最优选择问题,下面我们尝试模拟实现快递路径优化问题,假设为快递公司设计快递投递…

92号油的发动机能加97吗?标号越高不代表就越好
当我们买了车(不管是二手还是新车吧),我们都能很快知道这车的发动机是加什么标号的汽油的。这些信息都能在说明书或者在加油盖附近找到。但同时很多粉丝也在问,我的车是92的,但我加97的话发动机会不会更有力更省油&…
不要跳槽!!!
在这个俗称“金三银四”的跳槽季,很多人都蠢蠢欲动,想要拿更高的薪资,想要去更大的平台......但我也要奉劝大家一句:三思而后行。确实,春节过后,大家都在为开年做准备,跳槽也好,学习…

按下回车键指向下一个位置的一个函数
functiontofocus(itemname) // 按回车置下一个位置 2{ 3vara 4aeval( " document.vouch. "itemname) 5a.focus() 6} 7 在控件中使用onkeypress" javascrip:if(window.event.keyCode13){tofocus(nextformname)}提取下一个控件名