释放CPU,算力经济下DPU芯片的发展机遇
当前承载算力的基础设施是各种规模的的数据中心,从几十个服务器节点的小规模企业级计算中心到数万个节点的巨型数据中心,通过云计算的模式对应用层客户提供存储、软件、计算平台等服务。这个生态直接承载了全球数十万亿美元规模的数字经济,而且对全球服务业、工业、农业的渗透率随着大数据、5G、人工智能等技术的发展还在不断提高。算力,已不仅仅是一个技术指标,它已经成为了先进生产力的代表。
算力源于芯片,通过基础软件的有效组织,最终释放到终端应用上。目前数据中心中核心算力芯片包括CPU、GPU、FPGA和少量的ASIC,其中各类通用CPU的占比还是绝对统治地位。数据显示目前CPU的年出货量超过200亿颗,其中数据中心中使用的服务器端CPU的出货量约2000万颗,PC(包括桌面、工作站等)端约2.6亿颗。仅在2020年第4季,全球基于ARM IP的芯片出货达到了创纪录的67亿颗;GPU的出货量也非常可观,超过4亿颗(包括Intel、AMD的集成核显),大部分都应用在各种终端设备中,如大量消费级和工业级电子产品中。在云端,高性能CPU和GPU是主要的两种算力芯片——也是规模最大,单价最高,应用环境最复杂的芯片。
负载分化:从存内计算到网内计算,出现大量可从CPU卸载的任务
计算的两个核心要素:数据和计算,在数据和计算之间通过复杂的存储层次来均衡带宽、延迟、容量、成本等因素,尽可能让计算芯片对数据能做到“随用随取”,然而这在物理上是不可能实现的。将数据从生产侧或存储侧搬运到计算节点上也需要时间和能耗。为了把数据搬运到完成布尔逻辑的计算单元,已经消耗了90%以上的能耗了。过去50年,乘着摩尔定律的东风,单颗计算芯片的处理性能指数增长,然而访存带宽受限于管脚数和时钟频率仅能做到线性增长,相对而言数据搬运的开销被继续放大了。端到端的延迟越来越难以控制,要把处理器“喂饱”也变得越来越困难。为了不浪费处理器计算容量,只好通过各种共享机制来相互隐藏数据搬运的延迟和开销——而这本身就是一种开销。
一个直接的想法就是将数据靠近计算芯片、或者将计算芯片靠近数据,而且是物理临近。出现了“存内处理(PIM,Process In Memory)”的概念,也称之为"In-Memory Computing”,存内计算。例如,将一些地址计算,地址转换,校验码计算、查找表等设置在存储控制器中。但这本质上是卸载了部分CPU负载的计算到内存控制器,其实并没有把CPU完全“嵌入”内存,但也算是一种间接的存内计算的实现方式。还有一种更依赖新型器件技术的“存算一体”,比如非易失性存储单元的阻抗(或导纳)作为被存数据,当在一端施加输入数据(电压),输出就是二者的乘积,再通过模拟信号处理,模拟-数字转换后,得到CPU可以处理的二进制数据;当把这些节点组织成一个阵列,就相当于完成了一次两个向量的乘累加(MAC)操作。
另外一种存算融合的方式是“近内存计算(Near-Memory Computing)”, 主要体现为放置更多的存储器件(包括非易失性存储器件)到片上,可以视为一种通过片上集成大内存作为一级高速缓存,这种方式更多是存储技术和集成技术来驱动的,比如已经开始采用的高带宽存储器(HBM), 得益于3D集成技术,单个存储堆栈带宽即可以达到100GB/s,相比于GDDR5的DRAM的28GB/s,有接近4倍的提升!本质上来看,CPU的存储层次之所以发展为多层、多级,也是为了使处理器更“靠近”数据。

这些技术都是局部计算和存储的融合技术,即以单机、单节点为优化对象。如果把一座数据中心视为一台计算机,正所谓"The Datacenter as a Computer", 那么计算的分布就有新的可能性。数据中心虽然可以逻辑上被视为一台计算机,但其中的节点是需要通过网络互连的。计算的分配、存储的共享、硬件资源的虚拟化等,都将成为整合数据中心资源的开销。而数据中心的CPU和GPU都不是针对数据中心的这些负载来设计的,诸如网络协议处理、存储压缩、数据加密。网卡设备在数据中心中起到了关键作用。既然网卡可以处理物理层和链路层的数据帧,为什么不继续卸载网络层和部分应用层的计算到网卡上来呢?所以网卡从只负责节点间的“互连互通”到可以帮助CPU处理一些底层数据处理,其名称也就从NIC(Network Interface Card)升级成了SmartNIC。网卡也从单纯的处理数据帧变成了附带更多计算业务的“小服务器”,拓展成真正的“网内计算(In- Network Computing)”。
无论是存内计算、近内存计算、还是网内计算、其最终的目的都是将数据所经历的的存储、传输、计算的环节做有针对性的处理,提升系统的整体效率。
计算组织:从“端-云”一体,到“端-边缘-云”一体
为了承载AIoT、自动驾驶、V2X、智慧城市、智能安防等新兴产业,计算的组织也有了很多新的变化。从端-云一体,到端-边缘-云一体,例如未来自动驾驶中,车将会成为边缘的一个载体;在5G时代,5G基站也可能会成为一个边缘节点,云计算的部分计算功能会下放到边缘端的算力节点上,获得更及时响应时间,更节省的网络带宽 。除 了 边 缘 计 算 , 在 端 - 云 之 间 甚 至 有 研 究 人 员 提 出 了 “ 雾 计 算 (Fog Computing)”,“霾计算(Mist Computing)”,来不断地将计算进行分层处理,以获得更好的服务质量,更低的成本。类似于一个国家的行政治理结构:省、市、区、县等,上级负责所辖的下一级整体规划,下级负责具体实施;在下一级能处理的业务,就不需要往上一级推送。这样就可以有序得将计算合理分配到各个计算层次。每个终端业务无须关心是哪一朵“云”在提供服务,也不需要关心有多少层“云”、是“云”还是“雾”在提供服务。计算能力将会像电力一样,通过端-边缘-云一体化系统,“输送”到用户。至于电来自于哪一座发电站,并不重要。这个计算组织结构的变化,直接影响了计算指标的演变:从高性能到高效能,进而到高通量,最终落实到高生产率计算。
体系结构:通用、专用并举孕育了“X”PU的新机遇

目前各类CPU(包括服务器端、桌面端、移动端、工控和各类嵌入式场景等)的年出货量超过百亿颗,全球平均每人都能达到3颗CPU的消费量,基本可以认为CPU已经成为一个泛在的器件。建立在CPU上的软硬件生态,无论是x86还是ARM,也自然成为了整个算力系统的载体,CPU也责无旁贷地成为了这个体系中的主角。随着对图形图像处理的需求,在上世纪90年代出现了GPU,并逐渐发展到目前的GPGPU。随着深度学习算法的爆发,GPU找到了除图像处理之外的施展空间——神经网络模型的训练。直至目前,神经网络训练都是GPU占绝对统治地位。伴随着这第四次AI浪潮,GPU的全球领导厂商NVIDIA的市值也在2020年8月一举超越了X86 CPU的领导厂商Intel,并一骑绝尘。GPU同时也成为了下一代数据中心里算力芯片的又一个重要角色。适逢摩尔定律的放缓,GPU这一领域专用架构(DSA)技术路线下的代表,终于成为成为了数据中心的核心算力芯片之一。DSA这一技术路线已经被业界在大范围内认可,问题是,下一个DSA的代表是谁?

NVIDIA在2020年公布了对这个问题的看法,他认为在未来,CPU、GPU、DPU将成为数据中心的三个重要算力芯片,这与我们两年前的看法不谋而合。我们认为,CPU优势是通用和所承载的复杂的业务生态,其定义了软件生态和系统的可用性。GPU作为流媒体处理的核心,将继续朝着AR、VR的方向发展。行业预测在5G时代,90%的数据都将是视频、图片等非结构化数据,GPU必将成为这处理这类负载的主要引擎。而DPU,将会成为SmartNIC的下一代核心引擎,将软件定义网络,软件定义存储,软件定义加速器融合到一个有机的整体中,解决协议处理,数据安全、算法加速等“CPU做不好,GPU做不了”的计算负载。我们也大胆预测,未来数据中心的算力引擎将出现CPU、GPU和DPU并举的情景。DPU不仅仅是网卡芯片,而是全面成为“软件定义硬件”的重点对象。同时,DPU的市场也不会局限在服务器端,也会出现在边缘端,例如智能驾驶的V2X场景,用于解决实时视频结构化、传感器数据融合,和一些消费级的DPU产品,用于在隐私保护等业务上提升终端的用户体验。
DPU如何变革下一代计算基础设施
DPU是 Data Processing Unit的简称。
DPU将作为CPU的卸载引擎,释放CPU的算力到上层应用。以网络协议处理为例,要线速处理10G的网络需要的大约4个Xeon CPU的核,也就是说,单是做网络数据包处理,就可以占去一个8核高端CPU的一半的算力。如果考虑40G、100G的高速网络,性能的开销就更加难以承受了。Amazon把这些开销都称之为“Datacenter Tax”——还未运行业务程序,先接入网络数据就要占去的计算资源。AWS Nitro产品家族旨在将数据中心开销(为虚机提供远程资源,加密解密,故障跟踪,安全策略等服务程序)全部从CPU卸载到Nitro加速卡上,将给上层应用释放30%的原本用于支付“Tax” 的算力!
DPU将成为新的数据网关,将安全隐私提升到一个新的高度。在网络环境下,网络接口是理想的隐私的边界,但是加密、解密的算法开销都很大,例如国密标准的非对称加密算法SM2、哈希算法SM3和对称分组密码算法SM4。如果用CPU来处理,就只能做少部分数据量的加密。在未来,随着区块链承载的业务的逐渐成熟,运行共识算法POW,验签等也会消耗掉大量的CPU算力。而这些都可以通过将其固化在DPU中来实现,甚至DPU将成为一个可信根。
DPU将成为存储的入口,将分布式的存储和远程访问本地化。随着SSD性价比逐渐变得可接受,部分存储迁移到SSD器件上已经成为可能,传统的面向机械硬盘的SATA协议并不适用于SSD存储,所以,将SSD通过本地PCIE或高速网络接入系统就成为必选的技术路线。NVMe(Non Volatile Memory Express)就是用于接入SSD存储的高速接口标准协议,可以通过PCIe作为底层传输协议,将SSD的带宽优势充分发挥出来。同时,在分布式系统中,还可通过NVMe over Fabric协议扩展到InfiniBand、或TCP互连的节点中,实现存储的共享和远程访问。这些新的协议处理都可以集成在DPU中来实现对CPU的透明处理。进而,DPU将可能承接各种互连协议控制器的角色,在灵活性和性能方面达到一个更优的平衡点。
DPU将成为算法加速的沙盒,成为最灵活的加速器载体。DPU不完全是一颗固化的ASIC,在CXL, CCIX等标准组织所倡导CPU、GPU与DPU等数据一致性访问协议的铺垫下,将更进一步扫清DPU编程障碍,结合FPGA等可编程器件,可定制硬件将有更大的发挥空间,“软件硬件化”将成为常态,异构计算的潜能将因各种DPU的普及而彻底发挥出来。在出现“Killer Application”的领域都有可能出现与之相对应的DPU,诸如传统数据库应用如OLAP、OLTP, 或新兴应用如智能驾驶等。

中科驭数的DPU方案:KPU1+KPU2+......=DPU
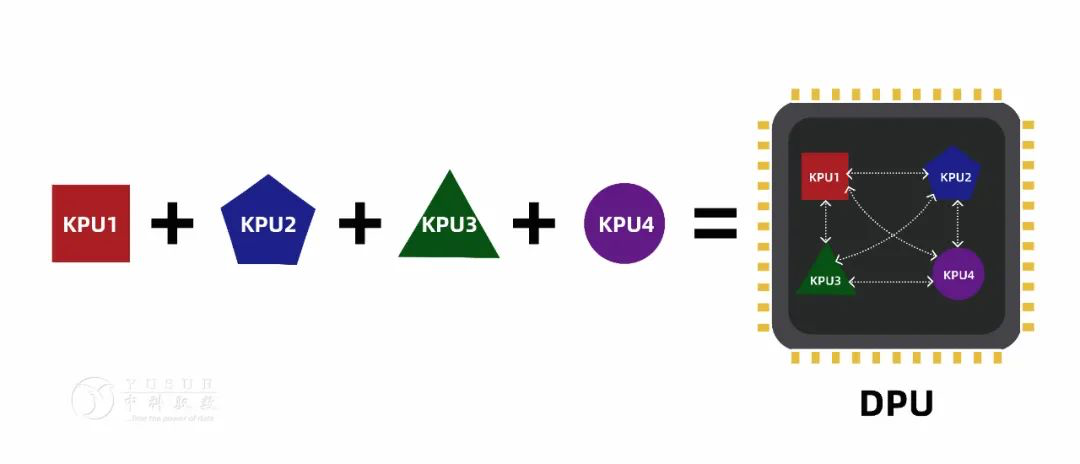
鉴于以上的认知,中科驭数在这条赛道上已经布局。驭数采取了以算法加速为核心,以网络加速为切入点的策略,以清晰的行业应用为驱动,做直接面向应用的DPU。先单点打通,再按需扩展的策略。
现有的DPU大体上有两种类型:1)以通用众核为基础的同构众核DPU,类似早期以处理数据包为目的的网络处理器,例如Broadcom的的Stingray架构,以多核ARM为核心,以众取胜。得益于通用处理器核(绝大部分都是ARM系列),可编程性比较好,但是应用的针对性不够,对于特殊算法和应用的支持相对于通用CPU没有优势。2)以专用核为基础,构建异构核阵列。这种结构针对性强,性能最好,但牺牲了部分灵活性。现有的最新的产品趋势都是二者的折中,而且专用核的比重越来越来大,NVIDIA最新的BlueField2系列DPU的结构就包括4个ARM核再加多个专用加速核区域,Fungible的DPU包含52个MIPS小型通用核,但还包含6个大类的专用核。

中科驭数的DPU是以KPU为运算核心,以高速传输和存储总结为接口,弱通用化控制的数据面领域专用处理器。
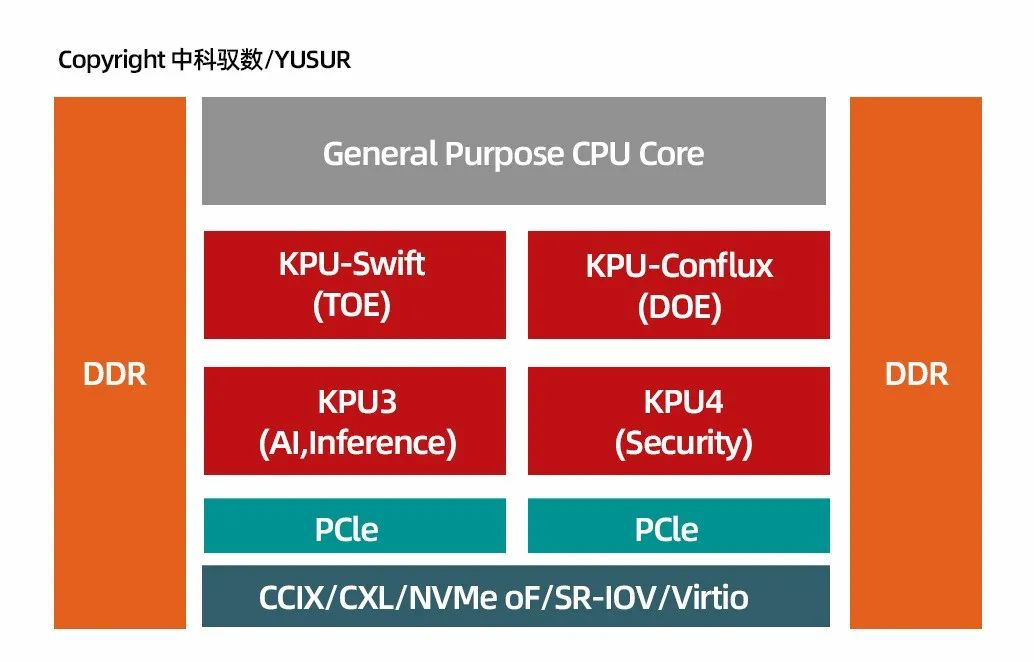
上图展示了驭数DPU的顶层结构,其核心是四类KPU的异构核阵列,分别处理网络协议,OLAP\OLTP处理,机器学习和安全加密运算核。不同于Broadcom,Fungible等厂商,我们将重点放在了异构核上,即以针对性算法加速为核心,驭数提出了KPU架构,来组织异构核。在KPU架构下,驭数提出了完善的L2/ L3/L4层的网络协议处理,提出了直接面向OLAP、OLTP的数据查询处理核,而没有采用原来众核为主的架构。这一路线与NVIDIA的技术路线更接近,但更加侧重异构核的使用。看似牺牲了部分通用核的可编程性,但换来的是更高效的处理效率,更直接的使用接口,更瘦的运行时系统和更佳的虚拟化支持。一个理想的DPU必然不像CPU,才有可能与CPU更好的互补。通用的计算不应该、也不需要卸载到DPU上,而可卸载到DPU上的负载必然也不需要在基础算子层面来进行运算控制。
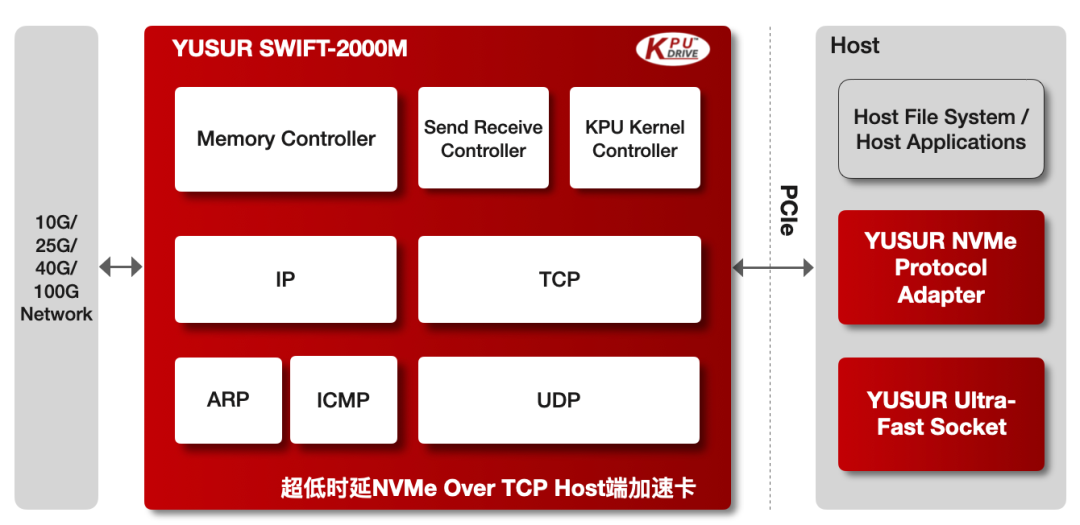
中科驭数的DPU顶层架构支撑了驭数其中一条重要产品线:SWIFT系列的网络加速卡。SWIFT™-2000M是中科驭数KPU-SWIFT™网络加速产品系列中一款超低时延NVMe Over TCP网络端加速卡,基于中科驭数KPU架构和自主研发的全硬件TCP/IP协议簇解决方案,它集成了完整的TCP、UDP、ARP、ICMP和IP等协议处理模块,配套驭数的高性能PCIe驱动和NVMe协议的软件接口适配,从而实现NVMe over TCP的网络 端全功能极速系统。SWIFT™-2000M集成了丰富的系统运行状态监测功能,拥有硬件处理的TCP包传输、数据重传、乱序重排、ping等完备的功能,解决10G/100G高速NVMe-oF场景下网络协议处理CPU资源占用过高、解析过慢的痛点,大幅提升系统吞吐,优化远端存储访问效率。

未来展望:构建专用处理器系统结构的几个关键点
专用处理器与通用处理器是处理器发展的两个互补的方向,虽然单独一类专用处理器的市场要远小于通用处理器,但是多类专用处理器的市场总和将远远大于通用处理器的市场。而且,专用处理器的发展将会在很多增量的应用市场中占有绝对的性能优势,而受到的通用计算的生态限制更少,有利于专用架构逐步扩展去覆盖更长尾端的应用。
在过去处理器芯片发展的60年里,前50年都是通用处理器的发展以绝对优势占据了处理器芯片的市场份额,相信在接下来的30年,随着数据的爆发和“端云一体”这种计算范式的继续渗透,将形成通用处理器与专用处理器并行的新局面,在2020年7月的COMMUNICATIONS OF THE ACM中,有一篇文章提出了一个新概念:“ASIC Clouds”, 全文标题是“ASIC Clouds: Specializing the Datacenterfor Planet-Scale Applications”,这里的“ASIC”其实就是各种专用处理器的呈现形式,我们相信专用处理器将迎来空前的增长机遇。

我们认为构建专用处理器系统结构有以下几个关键点:
▲ 针对“数据平面”的计算架构
专用计算体系结构和通用计算体系结构的阵地是不同的,专用计算竞争的焦点是数据平面,而通用计算竞争的焦点是控制平面。专用计算好比是造赛车,目标就是快,重点是根据赛道的类型来决定赛车的结构;通用计算好比是造民用车,目标更加的多元化,不仅要兼顾不同路况下的可用性,还要考虑性价比、代际兼容性。所以,以通用CPU的标准来看待专用XPU可能并不合适,甚至会制约了专用处理器的发展。
▲ 融合创新技术
计算架构的范畴不仅仅是狭义的处理器芯片,还包括相应的存储、传输、集成工艺等,是一个系统性概念。专用计算由于其“专用”的属性,对融合新技术更有优势,例如,引入高速非易失性存储(NVMe),利用 “NVMe oF”技术构建更高效的分布式存储系统;将主机内存直接连接在PCIe设备端,建立更大、更快的远程直接内存访问(RDMA);集成HBM支持更大的片上数据集,更高效的数据平面操作;将神经网络计算融入网内计算,透明赋能需要推理的场景。
▲ 面向的领域专用描述语言
应用都是可以进行无二意性的语言进行描述的,专用计算也不例外。对应用的描述层是专用计算架构的边界:描述层之上是客户的实际应用程序,描述层之下都是专用计算系统涉及定制的部分。整个系统的参考边界由传统ISA(指令集)上升到了DSL(Domain-specific Language)。例如,P4编程语言是面向SDN的领域专用语言,专门用于定义路由器和交换机如何转发数据包,属于数据平面的编程语言。至于网络处理器是用ARM还是MIPS,或是X86并不重要。现在的深度学习框架例如TensorFlow,其实也是提供了一整套定义深度学习模型结构、描述模型训练方法的DSL;还有面向数据库的SQL,本身就是一种声明式(Declaritive)的DSL编程语言,有望成为新专用处理器设计的参考边界。
▲ 先垂直深耕,再水平扩展
对于专用计算架构业界的一个普遍的共识是“碎片化”问题,挑战“one-size-fitall”的ASIC商业模式。传统上认为碎片化意味着单个产品线难以上量,难以摊薄芯片研发的巨额一次性投入,即所谓的高昂的NRE成本。一个有商业价值的技术必须建立在“技术闭环”的基础上:研发、使用、反馈、再研发改进、再扩大使用范围……。技术只有投入使用才能体现价值,有使用价值才有可能商业化,才能完成技术闭环到商业闭环的进化。技术闭环的形成需要集中火力,全链条主动出击才能铺就。碎片化并不是“专用”障碍,反而应该是专用技术路线充分利用的优势。
相关文章:

SQLserver安全设置攻略
日前SQL INJECTION的攻击测试愈演愈烈,很多大型的网站和论坛都相继被注入。这些网站一般使用的多为SQLSERVER数据库,正因为如此,很多人开始怀疑SQL SERVER的安全性。其实SQL SERVER2000已经通过了美国政府的C2级安全认证-这是该行业所能拥有的…
undefined symbol: ap_log_rerror;apache2.4与weblogic点so文件
没法子啊;只能用 httpd-2.2.26 https://www.google.com.hk/#newwindow1&qundefinedsymbol:ap_log_rerror&safestrictundefined symbol: ap_log_rerror[rootlocalhost local]# vi apache2/conf/httpd.conf[rootlocalhost local]# ./apache2/bin/apachectl s…

10个Java 8 Lambda表达式经典示例
Java 8 刚于几周前发布,日期是2014年3月18日,这次开创性的发布在Java社区引发了不少讨论,并让大家感到激动。特性之一便是随同发布的lambda表 达式,它将允许我们将行为传到函数里。在Java 8之前,如果想将行为传入函数&…
Sql server 2005带来的分页便利
select threadid from (select threadid, ROW_NUMBER() OVER (order by stickydate) as Pos from cs_threads) as T where T.Pos > 100000 and T.Pos < 100030 如果里面的这个表cs_threads数据量超大,比如,几亿条记录,那这个方法应该是…

想学Python?快看看这个教程!收藏!
Python入门从哪开始,90%以上的书上都是这样讲的:先介绍 Python 的基本语法规则、list、dict、tuple 等数据结构,然后再介绍字符串处理和正则表达式,介绍文件等IO操作.... 就这样一点一点往下说。然而这种按部就班的学习方法&#…
Struts1.x系列教程(4):标签库概述与安装
Struts的整个视图层(就是MVC模式中的View层)是由Struts的定制标签(或者称为定制动作)和客户端代码(Javascript、HTML等)实现的。这些Struts标签被写在JSP页面中,用于生成客户端代码、进行逻辑判断等工作,使…

绿盟科技与CCF成立“鲲鹏”科研基金 计划发力5大领域资助16个项目
【51CTO.com原创稿件】2017年5月10日,由中国计算机学会(CCF)和北京神州绿盟信息安全科技股份有限公司(以下简称:绿盟科技)主办的2017 CCF-绿盟科技“鲲鹏”科研基金新闻发布会于北京隆重举行。双方共同宣布“鲲鹏”科研基金正式成立,该基金将…
修改SQL SERVER内置存储过程
SQLSERVER估计是为了安装或者其它方面,它内置了一批危险的存储过程。能读到注册表信息,能写入注册表信息,能读磁盘共享信息等等……各位看到这儿,心里可能会在想,我的网站中有其它的代码,又不像查询分析器那…

〖Linux〗使用Qt5.2.0开发Android的NDK应用程序
2013年12月11日,Qt发布了其新的Qt版本:Qt5.2.0; 利用这个新的版本,我们可以很轻松地制作出Android手机的NDK应用程序。 开发环境:Ubuntu13.10 x86_64 下载链接:http://download.qt-project.org/official_re…

基于 OpenCV 的面部关键点检测实战
【 编者按】这篇文章概述了用于构建面部关键点检测模型的技术,这些技术是Udacity的AI Nanodegree程序的一部分。作者 | 小白责编 | 欧阳姝黎概述在Udacity的AIND的最终项目中,目标是创建一个面部关键点检测模型。然后将此模型集成到完整的流水线中&#…

气温上升影响数据中心节能
也许一些公司都是你熟悉的名字。但你可能不知道的是,这样的公司拥有遍布美国的大型数据中心,包括北弗吉尼亚州。数据中心用于存储、备份和通信业务,使用了大量的电力,为IT设备供电,并保持其冷却其数据中心基础设施。 也…
如何将SQL Server表驻留内存和检测
将SQL Server数据表驻留内存是SQL Server提供的一项功能,在一般小型系统的开发过程中估计很少会涉及到。这里整理了相关文档资料,演示如何把SQL Server中一个表的所有数据都放入内存中,实现内存数据库,提高实时性。 1, DBCC PINTA…

C 一样快,Ruby 般丝滑的 Crystal 发布 1.0 版本,你看好吗?
整理 | 寇雪芹 头图 | 下载于视觉中国 出品 | AI科技大本营(ID:rgznai100) 近日,编程语言 Crystal 发布了 1.0 版本。 Crystal 是一种通用的、面向对象的编程语言,其语法受到 Ruby 语言的启发,具有静态类型检查功能&am…

php in yii framework
为什么80%的码农都做不了架构师?>>> command line php yiic defined(STDIN) or define(STDIN, fopen(php://stdin, r));$_SERVER[argv](2013-12-30 22:44:10) 最近读这本书, 讲使用方法, 每章节各自独立, 配合些源码看(但不要细看, 会干扰进度, 浪费时…

selenium grid2 使用远程机器的浏览器
下载 selenium-server-standalone-3.4.0.jar包在selenium-server-standalone-3.4.0.jar包目录下面执行cmd 命令 java -jar selenium-server-standalone-3.4.0.jar -role hub 启用selenium grid hub, 默认端口 4444注册浏览器客户端,命令行执行ÿ…
Create a restful app with AngularJS/Grails(4)
为什么80%的码农都做不了架构师?>>> #Standalone AngularJS application In the real world applications, it is usually required to integrate the third party APIs into the project. Most of case, the third party service is provided as flexi…

无代码的时代真的来了吗?
所谓“无代码”,并不是不存在代码,无代码平台的开发,给开发者更大的挑战、更多 机会。所以,“无代码”不是解放程序员,而是给程序员提出了更高的要求、带来更大的挑战。作者 | 函子科技陆继恒,Jessica Tang…
实现自适应高度
天修改一个用Excel的报表,有一个数据格是跨两列,一般单格的数据格用自动换行就可以实现自适应高度,但是跨列是不行的.查找google良久,也没发现适合的办法,一阵头痛之后,突然有了灵感,于是马上做试验,还真的实现了.先写出来,如果有困于这个问题的朋友偶然路过,或许还能有一点用处…
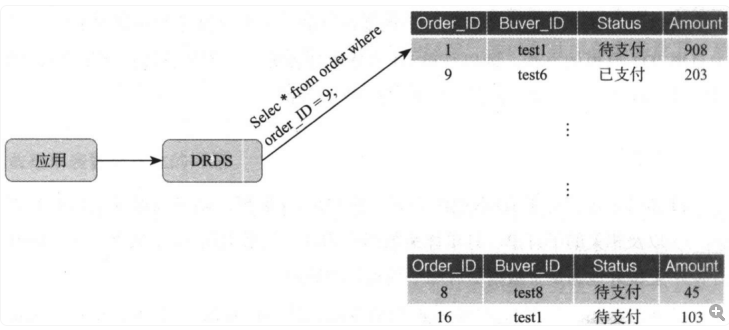
分表分库之一:分布式数据库的常见用法
尽量减少事务边界 采用分库分表的方式将业务数据拆分后,如果每条SQL语句中都能带有分库分表键,分布式服务层对于SQL解析后都能精准地将这条SQL语句推送到该数据所在的数据库上执行,数据库将执行的结果再返回给分布式服务层,分布式…
打印自定义纸张大小
长江支流说的办法保留太多了,结果不行,很多类都是他在程序集里自定义的,源码又没公开 不过还是要感谢他的提示 今天和小陈搞了一天,他在国外的论坛上看到了一篇文章得到了启示,最后我们在凌晨3点终于把自定义纸张的代码给写出来了,看来必须用API,微软的.NET对打印的支持太菜了…

看完 50000 张专辑封面,AI 设计师开始疯狂输出
西班牙艺术家利用 StyleGAN2 打造了一个 AI 设计师,借助 50000 张图像自学成才,没想到培养一个印象派设计师这么简单。作者 | 三羊来源 | HyperAI超神经头图 | 网友整理抄袭事件的对比图也许是有些设计太经典出挑,总是让人情不自禁地模仿。日…

XenApp_XenDesktop_7.6实战篇之八:申请及导入许可证
1. 申请许可证Citrix XenApp_XenDesktop7.6和XenServer 6.5申请许可证的步骤是一致的,由于之前我已经申请过XenApp_XenDesktop的许可证,本次以XenServer6.5的许可证申请为例。1.1 在申请试用或购买Citrix产品时,收到相应的邮件,其…
使用Windows操作系统的13个窍门
Windows操作系统的13个使用窍门,很适用。 1.删除Windows下不让删除的文件 有时想删除某个文件,系统会告诉无法删除,换到DOS下或是安全模式虽然可以删除,但是有点麻烦。这时可以用鼠标右键点击回收站,选择“属性”将“回…

如何让机器像人一样多角度思考?协同训练来帮你
作者 | 宁欣头图 | 下载于视觉中国出品 | AI科技大本营(ID:rgznai100)本文目录0. 摘要1. 引言2. 协同训练介绍3. 协同训练改进3.1 基于视图划分的协同训练3.2 基于学习器差异化的协同训练3.3 基于标签置信度的协同训练4. 协同训练应用5. 总结与展望摘要协…

PHP设计模式(4)命令链模式
命令链 模式以松散耦合主题为基础,发送消息、命令和请求,或通过一组处理程序发送任意内容。每个处理程序都会自行判断自己能否处理请求。如果可以,该请求被处理,进程停止。您可以为系统添加或移除处理程序,而不影响其他…
MFC界面库BCGControlBar v25.3新版亮点:Gauge Controls
2019独角兽企业重金招聘Python工程师标准>>> 亲爱的BCGSoft用户,我们非常高兴地宣布BCGControlBar Professional for MFC和BCGSuite for MFC v25.3正式发布!新版本添加了对Visual Studio 2017的支持、增强对Windows 10的支持等。接下来几篇文…

如何使用 ASP.NET 实用工具加密凭据和会话状态连接字符串
文章编号:329290最后修改:2006年4月10日修订:8.0 重要说明:本文包含有关如何修改注册表的信息。修改注册表之前,一定要先进行备份,并且一定要知道在发生问题时如何还原注册表。有关如何备份、还原和修改注册表的更多信息,请单击下…

16款小米新品,刚刚雷军只发了5款
会前,雷军在微博上提前疯狂剧透小米即将发布的新品信息。要发布的产品实在太多了,整合提前发布的信息来看,此次发布会可能会是小米有史以来时间跨度最长、新品数量最多的新品发布会,包括小米11 Pro/Ultra、小米MIX新机、小米11青春…
windows下使用aspell开启emacs的单词拼写检查功能
第一步,你需要下载aspell安装文件和至少一个字典,下载地址为http://aspell.net/win32/. 下载之后,分别安装aspell和字典. 需要注意的是,在64位的WIN7下,“C:\Program Files (x86)”是32位安装程序的默认安装目录,而“C:\Program Files"是64位安装程序的默认安装目录,因此a…

老板来了:人脸识别 + 手机推送,老板来了你立刻知道!
背景介绍 学生时代,老师站在窗外的阴影挥之不去。大家在玩手机,看漫画,看小说的时候,总是会找同桌帮忙看着班主任有没有来。 一转眼,曾经的翩翩少年毕业了,新的烦恼来了,在你刷知乎,…