如何让机器像人一样多角度思考?协同训练来帮你


作者 | 宁欣
头图 | 下载于视觉中国
出品 | AI科技大本营(ID:rgznai100)
本文目录
0. 摘要
1. 引言
2. 协同训练介绍
3. 协同训练改进
3.1 基于视图划分的协同训练
3.2 基于学习器差异化的协同训练
3.3 基于标签置信度的协同训练
4. 协同训练应用
5. 总结与展望
摘要
协同训练算法是机器学习中半监督学习的主要方法之一,通过多个学习器的相互协作探索无标记数据中的有效信息。为了深入了解协同训练的发展,把握当前研究的热点和趋势,本文对现有协同训练算法进行整理和总结,并按照改进策略对相关方法进行分类,对一些典型方法进行详细介绍。其目的在于了解现有方法优势,发现仍然存在的问题,提出改进策略和建议,并对未来的发展趋势进行预测和展望。

引言
按照学习方式的不同,机器学习可以分为监督学习、无监督学习和半监督学习。其中,半监督学习结合了监督学习与无监督学习,采用自训练的思想,即利用在有标记数据集上训练好的模型对无标记数据进行自动标注,通过标签置信度评估将可信度较高的自标记样本加入到有标记数据集中,进一步提升模型的泛化能力。协同训练作为半监督学习的基础,容易实现,且对大部分的机器学习算法都有很好的兼容性,受到研究人员的关注,协同训练的发展历程如图1所示。
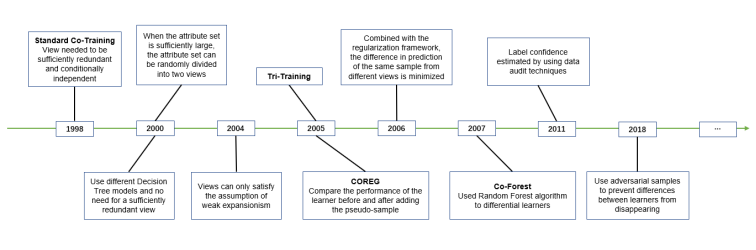
图1 协同训练发展的主要历程
传统协同训练算法主要应用了机器学习中的一些常见模型,如支持向量机,决策树等。随着深度学习的发展,研究人员逐渐将深度学习与协同训练进行结合,对协同训练的方法进行了改进和创新。本文旨在对相关领域的方法进行分类和总结,与之前协同训练综述相比有以下不同:(1)以协同训练中三大关键步骤为视角,综述近些年协同训练领域的创新点;(2)介绍了一些将深度学习技术与协同训练技术相结合的算法。
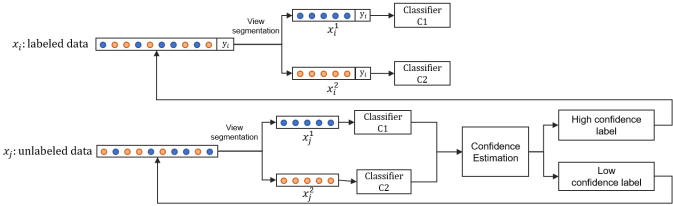
图2 协同训练算法的基本步骤
协同训练作为多视角学习的一种方法,通过多个学习器之间互相协作,提升模型的泛化能力。以两个视图下协同训练为例,标准的算法流程如图2所示:给定有标记数据xi (i = 1, 2, …, n)和无标记数据xj (j = 1, 2, …, m),首先对有标记数据xi进行视图分割,得到两个不同视图下的数据表达xi1和xi2,使用不同视图的数据训练两个具有差异的分类器C1,C2并将其作为初始分类器;接着使用初始分类器对无标记样本进行标签置信度估计,将可信样本加入到已标记数据中继续进行迭代训练,以优化分类器;当所有无标记样本都经过分类器的自标注,模型训练也就结束。

协同训练算法的发展
在一些研究任务中,数据集样本中可能包含多种属性,每种属性代表当前样本在不同维度上的特征表达,所有样本的单一属性即被称为数据的一个“视图(View)”。协同训练算法可以根据数据集中属性的个数分为多视图学习与单视图学习。不论单视图学习还是多视图学习,其目的都是让学习器之间产生差异,但是基本思路有所不同。
多视图协同训练是利用同一数据集中的多个属性,例如,多语言数据中的不同语种,文件数据中的标题与内容。通过有标记数据的训练,每个学习器都能够初步认知属于自己属性集下的信息,并与其他学习器形成差异。最初的协同训练算法由Blum和Mitchell提出,他们假定样本空间存在两个充分冗余且满足条件独立性的自然分割视图,其中任意一个视图数据都足以训练出一个强学习器。随后,Nigam等人将协同训练与EM模型进行了对比,表明在条件独立性假设成立的情况下,协同训练的效果更好,并且他们还证明了在自然分割不成立时,人工分割视图可以起到一定的作用。在此基础上,Balcan等人认为视图只需满足条件更弱基于扩张性的假设,进一步放宽对视图的要求。
与多视图学习所利用的充分冗余和条件独立性所不同,单视图学习通过初始学习器差异化设计来挖掘数据中的有用信息。这些差异可以体现在训练所使用数据集,基础模型和优化算法等几个方面。Goldman和Zhou使用不同决策树算法,从同种属性中训练出两个不同学习器;Zhou和Li在三体训练法中通过Bootstrap采样机制在原数据集上产生了三个数据集,采用相同的基础模型从产生出的每个数据集上训练出一个分类器。马蕾和汪西莉利用遗传算法(GA)与粒子群算法(PSO)分别优化两个支持向量机(SVM)的参数,形成存在差异的GA-SVM和PSO-SVM模型。

协同训练的基本步骤
通过对众多协同训练算法的整理和分类,协同训练算法主要包含:视图获取,学习器差异化,标签置信度评估等步骤,如图3所示。
3.1视图获取
由于许多数据集并不具备可自然分割的特性,大多数情况下,经过人工分割后的视图,无法同时保证每个视图的充分性以及条件独立性。若视图之间独立性强,则视图内特征相互依赖较强,视图的充分性降低;反之,若视图的充分性强,则视图之间的独立性较弱。为了更好平衡视图的充分性与独立性之间的关系,近些年来,多视图获取的研究工作主要集中在以下几个方面:随机子空间分割算法,基于视图充分性的分割算法,基于视图独立性的分割算法,自动分割算法等等。
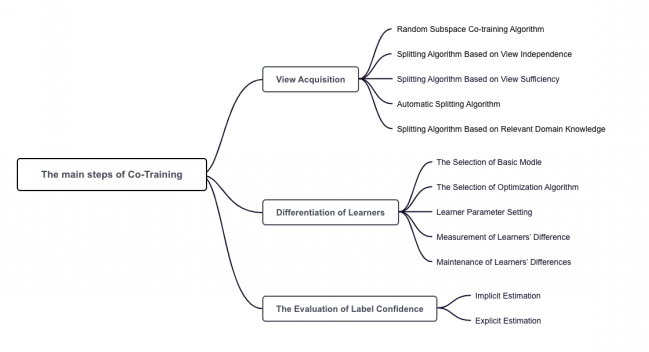
图3 协同算法的基本步骤
3.1.1基于随机子空间的视图分割算法
Wang等人认为标准协同训练算法中的两个视图在某些情况下无法涵盖全局信息,即每个视图的充分性无法保证。例如,在立体三维视图中,如果只获得物体的正视图和俯视图是无法还原出整体图形的。王娇等人提出基于随机子空间的协同训练算法(Random Subspace Co-training, RASCO)将两个视图推广到多视图,并且进一步讨论了子空间个数及维度对分类性能的影响。相关实验表明,随机子空间越多,分类器的错误率越低。当数据中包含很多不相关的特征时,RASCO往往无法选择出最优的特征子空间,甚至可能出现一个子空间中都是不相关的特征,特征相关度不高可能会使相应子空间训练出的分类器精度下降。Yaslan等人对RASCO算法做了进一步改进,提出了Rel-RASCO算法,通过筛选出所有特征中同标签相关性较高的特征,来去掉相关性较低的特征,以保证随机子空间的有效性,其中特征相关性定义为该特征与标签的互信息。图4是Yaslan等人在数据集Audio Genre上的实验结果,可以看出,CoTrain开始时(-B)的分类准确度高于结束时(-E)的分类准确度,这意味着CoTrain并没有从未标记的数据中获益。Rel-RASCO的表现优于RASCO和CoTrain。增加分类器数量K可以提高Rel-RASCO和RASCO的准确性,但K = 10后的增加不如K从5增加到10时的增加显著。
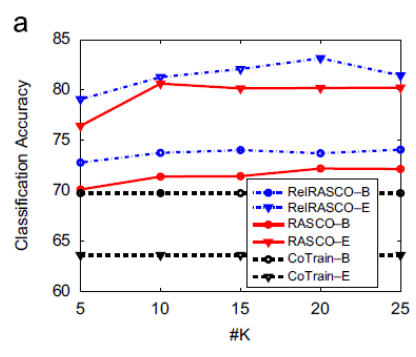
图4:Yaslan等人在Audio Genre数据集上的实验结果
3.1.2 基于视图独立性的视图分割算法
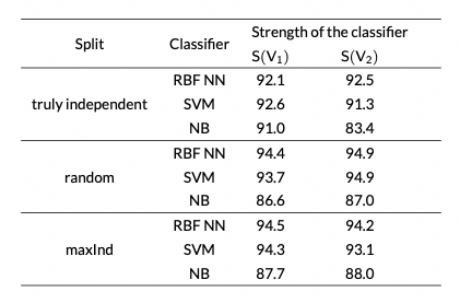
表1 News2x2数据集上分类器的强度
Feger等人使用图的maxInd算法对视图进行分割,在算法中采用条件互信息(Conditional Mutual Information, CondMI)来衡量两个视图之间的独立性和视图中每对特征的独立性。互信息作为衡量特征之间的信息共享量的指标,公式如公式(1),其中H是熵,在互信息的基础上给定类就得到了条件互信息,如公式(2)。该算法可以保证两视图之间的最大独立性,在理想情况下分割后的两属性集之间的CondMI = 0。如表1所示,maxInd的实验结果表明,视图之间独立性更好并不一定意味着协同训练更好,视图分割不仅仅需要考虑视图间的独立性,同时要考虑视图内部特征间的依赖性,如何权衡两者之间的关系,对协同训练很重要。
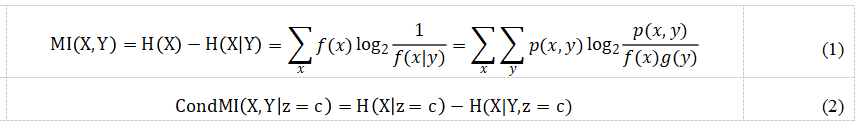
随后,Tang等人通过条件互信息和卡方条件统计量(CHI)评估两个特征之间的相互独立性,并进一步提出了特征子集划分方法PMID-MI和PMID-CHI算法。唐焕玲的算法相对于随机划分更容易让视图之间的条件独立性更强,实验表明协同训练使用这两种算法划分的错误率要低于使用随机划分算法。
3.1.3基于视图充分性的分割算法
Sheng利用粗糙集理论来完成视图的分割。属性约简是粗糙集理论重要研究内容之一,能有效地将高维数据降至低维属性子空间而不造成分类信息的损失,并且可以去除一些冗余属性。盛小春等人利用这一理论在核心属性基础上,依次加入重要性最大的属性,直至当前互信息与原互信息相等时最优粗糙子空间形成。该算法以保证分割后的属性集与原属性集充分性相等为前提,并在该前提下尽可能使分割后的视图之间的独立性最大。他们将该算法与标准协同训练算法,自训练算法在初始标记数据比例为仅为10%的多个UCI数据集上进行对比,结果如表2,结果表明当前算法的错误率最小。
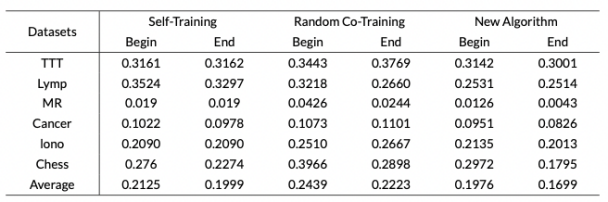
表2 不同数据集上各种算法错误率比较(标记数据的百分比为10%)
3.1.4自动分割算法
Chen等人提出了一种单视图特征自动分解的算法PMC(Pseudo Multi-view Co-training),他们希望该算法可以自动分割属性集,每个分类器只使用分割后两视图中的一个。该算法初始化两个分类器的权重u和v,并且u和v在同一维度至少有一个为零,即存在约束条件uivi = 0,并将其作为损失函数的约束,两个分类器会将原数据以最优化损失函数为条件进行拆分,进而得到了两个新视图。但由于该约束条件不易优化,于是对该条件进行变形得到式(3)。通过为损失函数添加公式(3)的约束项,进行权重参数更新,完成两个分类器的差异化。进一步地,Chen等人将PMC算法拓展到了多分类,约束项如式(4),其中K为标签类别个数。Chen等人将该算法在Caltech-256数据集的实验结果同随机分割算法做了对比。结果表明,使用该算法错误率要低于其他算法,并且在计算资源的消耗方面,在总量约为80000数据上,PMC完成整个训练花费了大约12个小时。
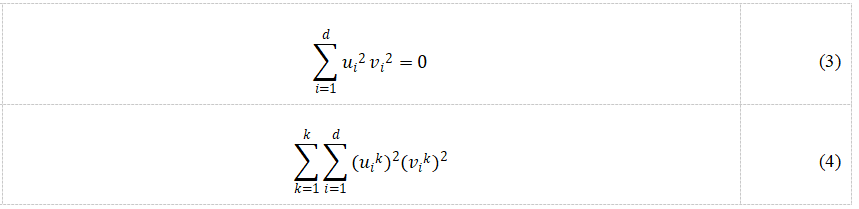
3.1.5基于领域知识的分割算法
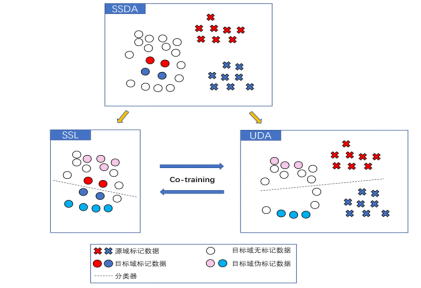
图5 SSDA视图分割原理图
前面的方法都是基于一定的算法完成视图的分割。在专业领域中,先验知识也能对分割视图起到一定的帮助作用。Yang等人利用SSDA的常见数据分布模式,将SSDA分解为两个子问题:半监督学习(Semi-Supervised Learning, SSL)和无监督自适应(Unsupervised Domain Adaptation, UDA)。由于SSL与UDA数据分布的明显不同,则SSL数据与UDA数据就是两个独立性较强的视图,如图5所示。该算法使用置信阈值筛选可信的新标记样本,论文实验结果要优于之前的SOTA论文,并且更为稳定。在生物医疗等领域,张迪等人根据能量代谢守恒的有关理论,提出了基于协同训练的半监督无创血糖检测算法。
根据人体局部产热推算代谢热交换速率,并由代谢热交换速率、血流速度、血氧等生理参数反推血糖值。该算法可以从耗氧量的相关数据测出血糖值,还可以根据能量代谢守恒法反推耗氧量,根据先验知识就能获得两个充分的视图。该算法仅需20%~30%的有标记血糖样本即可使模型基本达到有监督训练的效果,并验证了血糖参数中存在的流形假设。
综上所述,随机子空间协同训练算法更适合处理高维数据,不需要先验知识和复杂的数学设计就能找到最完美的划分。然而,这类算法需要计算最优子空间的数量,计算代价通常较大。基于视图独立性或视图充分性的分割算法通常利用信息论和统计学的知识来评估视图独立性或视图充分性。
然而,视图的独立性和视图的充分性往往不能同时满足。自动分割算法的优点是使用代价函数和优化算法自动完成视图的分割,而不考虑视图之间的关系。然而,由于优化算法的存在,可能会陷入局部最优情况。利用先验知识来分割视图的方法从该领域的特定角度进行分割,降低了探索更好分割的计算成本,但要求算法设计者在相关领域具有一定的基础和专业的知识。
3.2 学习器的差异化
学习器差异化主要通过基础模型和优化算法的选择,学习器参数设置来提供差异化方法,实现单视图协同训练。如何测量两个学习器之间的差异性和如何维系两个学习器之间的分歧是接下来讨论内容。
3.2.1 基础模型的选择
由于不同模型的学习机制或学习偏好有所差异,通过选择不同的基础模型进行协同训练,可以获得更加全面的数据信息。例如,Liu等人分别使用朴素贝叶斯(Naive Bayes, NB),支持向量机(Support Vector Machine, SVM), 神经网络(Neural Network, NN)作为基础模型,通过三个学习器之间的互相协作对数据进行标记工作。首先作为“老师”的两个学习器对当前无标记数据预测得到的标签需一致,其次两位“老师”预测概率需超过各自的置信度阈值。实验结果表明,Liu等人提出的“师生”模型要优于Tri-training和Self-training算法,且使用较少的有标记样本就可以快速达到最优结果。
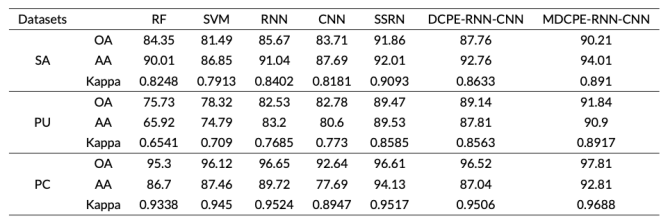
表3 不同方法在SA, PU, PC数据集的分类结果
Ju等人利用卷积神经网络(Convolutional Neural Network, CNN)与循环神经网络(Recurrent Neural Network, RNN)作为基础模型来差异化学习器,并在多分类概率估计算法(Diversity of Class Probability Estimation, DCPE)的基础上提出了改进后的多分类概率估计算法(Modified Diversity of Class Probability Estimation, MDCPE)。论文将最大化分类器c1与c2对同一类别预测概率差异的样本视为可信样本,并由具有较高预测概率的分类器提供另一个具有较低预测概率的分类器,如式(5),反之亦然,如公式(6)。Ju等人在SA,PU,PC三个数据集上进行了实验,在OA,AA,Kappa三个评估指标上对比了MDCPE-RNN-CNN算法与其他算法。实验数据如表3,结果表明MDCPE算法效果优于DCPE算法。
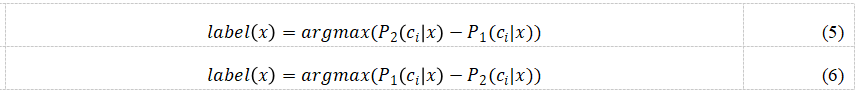
3.2.2 优化算法的选择
Ma和Wang利用支持向量机建立了协同训练的半监督回归模型。该算法利用遗传算法(Genetic Algorithm, GA)与粒子群算法(Particle Swarm optimization, PSO)分别优化两个支持向量机(Support Vector Machine, SVM)的参数,形成存在差异的GA-SVM和PSO-SVM,发挥了支持向量机在解决小样本、非线性回归问题上的优势。实验结果表明了基于支持向量机协同训练的半监督回归模型,有效利用了无标记样本当中的有效信息,提高了回归估计的精度。该算法通过计算计入伪标记样本前后均方误差的差值来表示无标记数据伪标签的置信度。在实验中,作者对GA-SVM模型,PSO-SVM模型,Self-GA模型(使用GA-SVM选择参数),Self-PSO模型(使用PSO-SVM选择参数)和半监督协同回归模型(Semi-SVM)即本论文提出算法进行对比。实验结果表明,在缺乏有标记数据的情况下,半监督协同回归模型相较于基于遗传算法和粒子群算法的支持向量机和半监督学习中的自训练模型有一定的优势,该算法对于数据中的错误标记的抗性相对于其他模型较高,能有效降低数据标记错误产生的噪声影响。
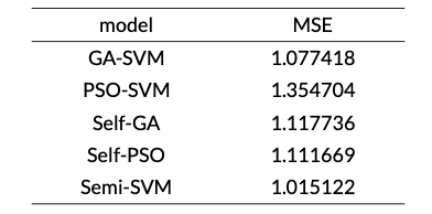
表3 五个回归模型在Boston Housing数据集上的均方误差
3.2.3 学习器参数的设置
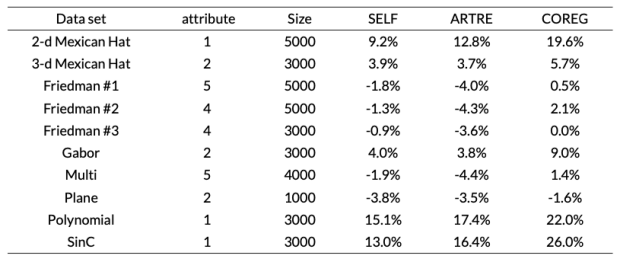
表4 对平均均方误差的改进
在基础学习器上使用不同的参数设置也可以达到差异化学习器的目的。Zhou和Li等人通过使用不同的参数p初始化Minkowski距离在KNN中的度量,利用两个参数不同的回归器进行协同训练,并依据新标记的实例使回归器在已标记数据上错误率减少最多的原则进行标签可信度的评估,提出了基于协同训练的半监督回归算法COREG。具体地,使用新标记实例加入前后不同回归器在已标记实例上的均方误差(MSE)减小值做为最终的评估指标。由于计算所有已标记实例的MSE,计算量过于巨大,为了减少计算量,Zhou等人计算已标记样本中与当前未标记样本K个最邻近样本,通过K个最近邻样本的MSE进行标签置信度的评估,如公式(7),其中c是原回归器,c’是新回归器。
训练完成后,算法的最终决策结果为两个KNN预测结果的平均。实验结果表明,该算法相对于KNN或自训练等算法可以有效地解决了半监督回归问题。表7中的实验结果表明,与ARTRE或自训练算法相比,COREG能够有效地解决半监督回归问题。与标准协同训练算法相比,COREG对视图的冗余性没有要求,因此COREG的应用范围更广一些,但K近邻算法存在计算开销较大的缺陷。
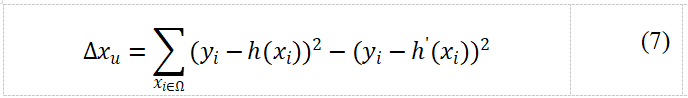
3.2.4 学习器差异性的测量

表5 分类器结果差异矩阵
通过计算候选学习器之间的差异性选出差异性较大的学习器组成基础学习器集,也可以达到学习器差异化的目的,但如何定义并计算学习器之间的差异性是该方法主要面临的问题。为了解决该问题,Kuncheva等人提出了基于Q统计量显式测量各个学习器差异的方法,并且将学习器之间的差异定义为:对于新的数据样本,各个分类器做出不同预测的趋势。Tang等人在人体识别任务中,先利用表5中的分类器与分类样本关系表计算出两个二分类分类器之间的Q统计量,如公式(8),再利用Q统计量衡量两个分类器之间的差异性。
表5中,N11代表两个分类器的分类结果都是正确的样本数量,N10表示ci的分类结果是错误,cj的分类结果是正确的样本数量,其余依次类推。Tang等人利用不同的核函数初始化一批SVM,从这些SVM中选择差异性最大的若干个SVM作为基础的学习器群,并根据聚类假设,将余弦相似度量作为判断样本之间相似性的基本依据。通过对无标记数据的新标签进行标签置信度的评估,将学习器集群的平均预测结果作为最终预测结果。实验表明,MCM算法与采用随机分割视图的协同训练,自训练等算法相比较拥有较高的准确性。
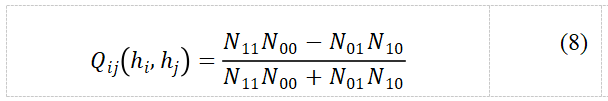

表6 MCM与其他半监督学习方法的比较结果(5%标记率)
从表6的实验结果可以看出,MCM算法相对于随机分割视图(FAKE-CO)协同训练算法和自训练算法(SELF1, SELF2)具有更高的准确率。
3.2.5 学习器差异性的测量
随着模型的不断迭代训练,不同学习器会逐渐趋于一致。为了维持学习器之间的差异性,Qiao等人基于协同训练中的相容性原则,认为对于同一样本,不同的学习器应该有相似的预测结果,如公式(9)。其中,c1, c2是分别是两个视图的分类器,xi1,xi2分别是样本xi在两个视图下的样本。Qiao等人计算学习器之间输出值的JS散度,并将其加入了损失函数,并且考虑到视图之间的差异约束,利用对抗学习的思想构建X’,并在损失函数中加入相关项来鼓励学习器学习到视图之间的差异性,如公式(10)。其中,X’是对抗例样本空间,其与X满足公式(11)中的关系。Qiao等人将自己提出的基于深度学习的协同训练算法在CIFAR-10等数据集上进行了实验。表7的实验结果表明,与其他算法相比,使用8个视图的错误率最低,在传统的损失函数的基础上加入基于视图一致性和差异性的两项损失函数项效果会更好。Peng等人在此基础上将该方法应用于图像分割领域并取得了较好的效果。
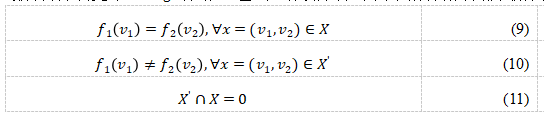
Zhou等人基于集成学习中的随机森林(Random Forest) 算法提出了Co-Forest。由于随机森林在树的学习过程中注入了一定的随机性,即使使用的相同的训练集任意两棵决策树也会有很大的差异性。Zhou等人沿用了三体训练法的标签置信度估计方式:投票法,在UCI数据集上的实验验证了Co-Forest的有效性。
初始学习器的设计往往关乎着模型的效果与计算资源的开销。协同训练算法一般都会使用多个学习器同时进行训练,如果学习器结构复杂,会导致计算资源开销巨大,模型成型慢等问题。因此,对于现有模型算法的改进使得算法的时间复杂度降低也是未来的一个研究方向。
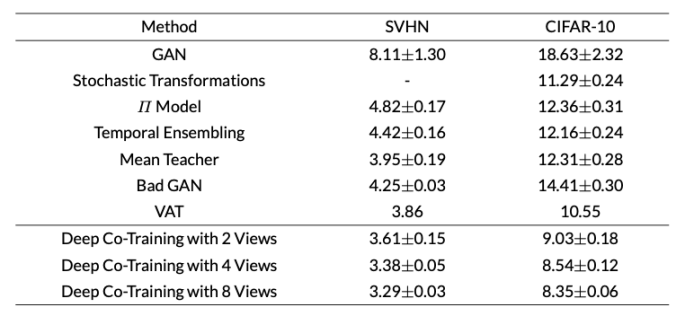
表7 SVHN(1000标记)和CIFAR-10(4000标记)数据集基准的错误率。
3.3 标签置信度的评估
标签置信度的评估是Self-Training增量式算法中重要的一环,其目的是防止给无标记样本贴上错误的标签,进而造成学习器性能恶化,依据标签置信度的评估方式我们可以将标签置信度的评估分为显式评估和隐式评估。大多数隐式评估算法都是利用学习者结果之间的差异程度来反映当前伪标签的置信度,而显式评估算法则使用精确的数字来显示标签的置信度。显式评估方法包括:伪标记数据进行训练的模型的前后准确度的差异,模型的概率输出,未标记数据与周围已标记数据的相似度。
3.3.1 隐式评估
Zhou等人的Tri-training算法,利用三个分类器投票隐式解决了标签置信度评估的问题。其具体机制如下:先用Bootstrap采样机制在原数据集上产生三个数据集,分别用来训练三个有差异的基础分类器h1, h2, h3。将h2与h3分类结果一致的无标记数据进行标注,并加入h1的训练集,其余类推。该算法使用分类器投票即少数服从多数对标签置信度进行了隐式估计,避免了使用更加耗时的十倍交叉验证思想。Zhou等人将该算法的表现与半监督学习中的标准协同训练算法,自训练算法做了对比,结果显示Tri-training算法利用无标记数据给分类器性能带来的提升相较于其他算法更大,且分类错误率更低。在此基础上,Wang等人选取LSTM网络、BLSTM 网络及GRU网络作为三个模型进行实验,有标记数据集的比例设置为20%,TMNN模型相较于三种单一模型表现效果最佳。Ge等人在图像分类任务中也沿用了三体训练的投票法。
虽然投票思想能够统计学习器分类结果的差异,但缺陷是无标记数据的伪标签仅由票数一个因素决定,忽略了每个分类器的预测结果的概率,若作为大多数一方的学习器置信度都较差,而少数方的学习器置信度较高,则容易给数据贴上错误的标签。
3.3.2 显式评估
最早的显示估计方法是当两个充分冗余的属性子集不存在时,在每次训练迭代中使用十折交叉验证(Ten-fold Cross Validation)来估计未标记数据的置信度。但是,十折交叉验证方法有计算开销巨大,耗时长的缺陷。Zhou等人提出了Democratic Co-learning算法来改善投票法的缺点。该算法在投票机制的基础上,进一步比较多数方学习器与少数方学习器的平均置信度的加和,若多数方学习器所得置信平均值的加和大于少数方则可以对当前无标记数据进行标注,反之则不行。Zhou等人将C4.5决策树、朴素贝叶斯和神经网络作为Democratic Co-learning的三个基本模型进行测试,并与DNA数据集上集成这三种模型的协同训练算法进行比较。从图6的结果可以看出,在整个迭代过程中,民主协同学习算法的准确率高于其他算法。
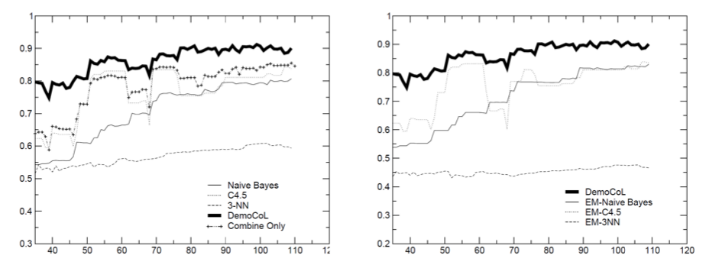
图6 DNA数据上的测试结果。x轴为已标记数量,y轴为模型准确度。
Zhou和Zhang利用数据审计技术结合切边权重统计技巧(Cut Edge Weight Statistic),并且用k近邻作为切分标准构建样本图结构,依据流形假设即正确分类的样本应该与周围样本的标签相似,提出了可以对无标记数据进行显式的置信度评估的COTRADE算法,并且通过最小化错误率来确定每轮迭代加入训练集的伪标注样本的数量,标签置信度主要通过公式(12)进行计算。通过比较COTRADE算法与标准协同训练算法、自训练算法等算法,实验结果如表8所示,表明COTRADE在course和ads12数据集上取得了比其他算法更好的结果。
Tseng等人在Tri-training的基础上加入置信阈值,提出了NDMTT算法,在投票机制的基础上进一步筛选了伪标记样本,使得置信度评估的准确率进一步提高。其中,置信阈值的设定将根据模型准确率来调整,在实验初始阶段置信阈值设定较小,以保证获得较多的新样本,随着模型准确率的提升,慢慢增大置信阈值。虽然显示估计准确率较高,但计算复杂,开销较大;隐式估计规则简单,但准确率较低。无论是显示评估或是隐式评估,都要注重减少错误标记的样本个数,防止噪声在迭代过程中进一步放大以造成模型的坍塌。
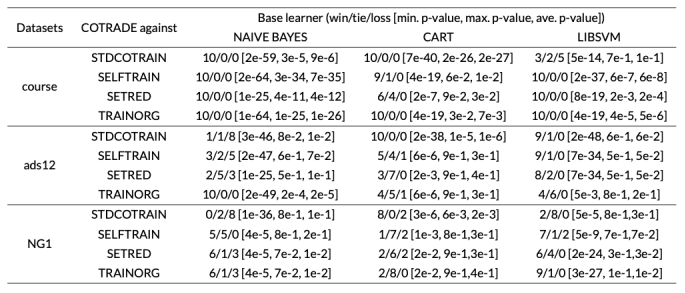
表8 基于不同基础模型的COTRADE与其他算法比较结果,评价指标为WIN/TIE/LOSS。

基于协同训练的应用
随着协同训练理论的不断发展,协同训练的思想逐渐被引入到不同的研究场景中,在数据标注、图像分割、图像分类、图像识别等任务中发挥着重要作用。Xia等人提出了Uncertainty Aware Multi-view Co-training(UMCT)方法,通过旋转或替换3D数据生成不同的视图,在Pancreas and LiTS NIH liver Tumor数据集上验证了所提出的方法的有效性。Du等人通过从训练样本中提取特征,将其划分为两个视图,减小合成孔径雷达识别任务中对标记样本的依赖。Tseng等通过添加第三种算法来辅助判断伪标记样本的可信度,改进了基于协同训练的自动数据标注过程,提高了标记数据的有效性。
Abdel等人采用离散小波变换提取电流波形和电压波形中的隐藏特征, 并将协同训练用于故障检测和分类, 提高了故障分类的准确性。在识别任务中,Zhou等人通过多视角协同训练和SVM Hesen正则化的新方法,进一步提高有杆抽油机井状态识别精度和实用性。Duan等人利用协同训练对原有的多模态识别算法进行改进,并将改进后的算法和原有方法应用到Audio Visual Person识别任务中,大大提高了分类精度和原方法的收敛性。

总结与展望
本文从协同训练算法中的三个关键步骤入手,综述了近些年来协同训练算法的创新与发展以及法中潜在的一些问题。协同训练无论是单视图学习还是多视图学习,目的都是为了让机器可以像人一样从多个角度思考问题,因此,如何有效地划分数据视图,如何科学地设计学习器,如何准确地评估标签的置信度是协同训练算法面临的本质问题。虽然许多学者在协同训练方向进行了大量实验,但离协同训练算法真正的工业化应用还有很长的路要走。
综上所述,本文对协同训练未来研究方向有以下建议:1)协同训练算法中的许多新创新还停留在文献中特定的数据集上。而实际情况中要比实验中的数据集复杂得多,这些创新需要一些实践或理论验证去证明其有效性。2)协同训练算法无论是单视图与多视图都无法避免同时训练多个模型,这直接导致了计算资源开销巨大。因此,如何对现有算法进行优化减轻其计算量也是一个研究方向。3)对于协同训练算法使用的无标记数据与有标记数据的比例需进一步探究。4)对于机器学习中的回归任务,由于其输出是连续值,标签置信度较难评估。因此,目前协同训练算法解决回归问题较少,需进一步研究。5)大多数文献的实验都没有在统一的数据集上进行实验,对于整个协同训练家族缺少一个通用的数据集。
作者简介:宁欣,中科院博士毕业,现任中国科学院半导体研究所副研究员,发表学术论文40余篇。
其他作者:王鑫然,许少辉,蔡蔚蔚,张丽萍,于丽娜,李文法
论文信息:Xin Ning, Xinran Wang, Shaohui Xu, Weiwei Cai, Liping Zhang, Lina Yu and Wenfa Li. A Review of Research on Co-training. Concurrency and Computation : practice and experience[J], 2021.
论文下载地址:https://www.researchgate.net/publication/350194568_A_review_of_research_on_co-training
CSDN协同行业大佬
打造13长热门知识图谱及IT成长路线
助力千万IT人成长,快速实现职场进阶!
更多精彩推荐
☞百度香港二次上市,12 岁开发者、AI 机器人同台敲响“芯片代码锣”☞GitLab 在中国成立公司极狐,GitHub 还会远吗?☞无代码的时代真的来了吗?点分享点收藏点点赞点在看
相关文章:

PHP设计模式(4)命令链模式
命令链 模式以松散耦合主题为基础,发送消息、命令和请求,或通过一组处理程序发送任意内容。每个处理程序都会自行判断自己能否处理请求。如果可以,该请求被处理,进程停止。您可以为系统添加或移除处理程序,而不影响其他…

MFC界面库BCGControlBar v25.3新版亮点:Gauge Controls
2019独角兽企业重金招聘Python工程师标准>>> 亲爱的BCGSoft用户,我们非常高兴地宣布BCGControlBar Professional for MFC和BCGSuite for MFC v25.3正式发布!新版本添加了对Visual Studio 2017的支持、增强对Windows 10的支持等。接下来几篇文…

如何使用 ASP.NET 实用工具加密凭据和会话状态连接字符串
文章编号:329290最后修改:2006年4月10日修订:8.0 重要说明:本文包含有关如何修改注册表的信息。修改注册表之前,一定要先进行备份,并且一定要知道在发生问题时如何还原注册表。有关如何备份、还原和修改注册表的更多信息,请单击下…

16款小米新品,刚刚雷军只发了5款
会前,雷军在微博上提前疯狂剧透小米即将发布的新品信息。要发布的产品实在太多了,整合提前发布的信息来看,此次发布会可能会是小米有史以来时间跨度最长、新品数量最多的新品发布会,包括小米11 Pro/Ultra、小米MIX新机、小米11青春…

windows下使用aspell开启emacs的单词拼写检查功能
第一步,你需要下载aspell安装文件和至少一个字典,下载地址为http://aspell.net/win32/. 下载之后,分别安装aspell和字典. 需要注意的是,在64位的WIN7下,“C:\Program Files (x86)”是32位安装程序的默认安装目录,而“C:\Program Files"是64位安装程序的默认安装目录,因此a…

老板来了:人脸识别 + 手机推送,老板来了你立刻知道!
背景介绍 学生时代,老师站在窗外的阴影挥之不去。大家在玩手机,看漫画,看小说的时候,总是会找同桌帮忙看着班主任有没有来。 一转眼,曾经的翩翩少年毕业了,新的烦恼来了,在你刷知乎,…
在C#中使用COM+实现事务控制
.NET技术是微软大力推广的下一代平台技术,自从.NET技术架构的正式发布,此项技术也逐渐走向成熟和稳定。按照微软的平台系统占有率,我们不难想象得到,在未来的一两年内.NET技术必定会势如破竹一般的登上主流的技术平台,…
深入理解 JavaScript 中的 replace 方法
2019独角兽企业重金招聘Python工程师标准>>> 字符串替换字符串 1 I am loser! .replace( loser , hero ) //I am hero! 直接使用字符串能让自己从loser变成hero,但是如果有2个loser就不能一起变成hero了。 1 I am loser,You are loser .replace( loser ,…

透过计算机视觉,看看苏伊士运河堵船
作者 | Edison_G来源 | 计算机视觉研究院头图 | 下载于视觉中国3月29日,长赐号终于重新上浮。船运代理公司Inchcape和苏伊士运河管理局皆证实,长赐号已经重新漂浮在水面上,但目前还不清楚需要多少时间重启运河。这张图片,相信大家…

泼点冷水,P2P借款限额是不是想的太美好?
8月24日等待了大半年的P2P网贷监管规则《网络借贷信息中介机构业务活动管理暂行办法(评估稿)》终于出现。办法中最引人注意的是对借款上限的规定: 同一自然人在同一网络借贷信息中介机构平台的借款余额上限不超过人民币20万元,在不…
SQL语句优化技术分析
SQL语句优化技术分析 操作符优化 IN 操作符 用IN写出来的SQL的优点是比较容易写及清晰易懂,这比较适合现代软件开发的风格。 但是用IN的SQL性能总是比较低的,从ORACLE执行的步骤来分析用IN的SQL与不用IN的SQL有以下区别: ORACLE试图将…

官方抓虫,PyTorch 新版本修复 13 项 Bug
整理 | 寇雪芹头图 | 下载于视觉中国出品 | AI科技大本营(ID:rgznai100)近日,PyTorch 发布了新版本 PyTorch 1.8.1,相比3月4日从 PyTorch 1.7 到 1.8 的重要更新( 1.8 版本主要包括编译器和分布式训练更新&…

开发webpart时建立图像文件夹和CSS,js文件夹
如图所示:是通过添加映射来完成,做好之后,把图像拷到文件夹时,当ascx文件里需要用到图像时,直接把图像拖到ascx文件里的位置。这样就知道该图像的路径 了。转载于:https://www.cnblogs.com/oymx/p/3490175.html

AI金融若不解决这些问题,等于在制造新的不可解问题
人们对新事物总是充满恐惧。就在大家担心无人驾驶汽车是否弊大于利的时候,AI重塑金融规律的创新也引起许多人对其中的法律和道德问题的顾虑。 让一个软件程序来决定,谁拥有投资开户的资格,谁能够获得贷款(征信)&#x…

Java 领域 offer 收割:程序员黄金 5 年进阶心得!
怎样才能拿到大厂的offer?没有掌握绝对的技术,那么就要不断的学习。如何拿下阿里等大厂的offer的呢,今天分享一个秘密武器,资深架构师整理的Java核心知识点,面试时面试官必问的知识点,篇章包括了很多知识点…

TCP连接的状态转换图深度剖析
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接,如图1所示。(1)第一次握手:建立连接时,客户端A发送SYN包(SYNj)到服务器B,并进入SYN_SE…

ASP.Net中的TreeView控件中对节点的上移和下移操作
Web中的TreeView中的没有PreNode和NextNode属性。 但它的集合属性中有一个IndexOf属性,从而能够找到它的前一个节点知后一个节点。 TreeView中要么只有一个根节点;要么没有根节点,都是并列排的,这个要判断。 这里主要是用了递归&a…

大数据流通存隐忧 产业信任体系亟待建立
就在今年10月,始于美国东部的“DDoS攻击”席卷了整个美国,引起了人们对数据安全的恐慌,大数据安全问题逐渐暴露。在第三届世界互联网大会的大数据分论坛上,中国科学院秘书长邓麦村在致辞中指出,如何突破大数据关键技术…

ImageNet十年,AI数据标注如何蓬勃发展?
2016 年,AlphaGo 战胜李世石,成为新一代 AI 浪潮的重要里程碑事件。 经此一役,很多人都认识到了算法和算力对 AI 发展的重要性,确忽略了另一个重要因素:数据。 2009 年,时任斯坦福大学任助理教授的李飞飞…
关于webservice的异步调用简单实例
于webservice的异步调用简单实例无论在任何情况下,被调用方的代码无论是被异步调用还是同步调用的情况下,被调用方的代码都是一样的, 下面,我们就以异步调用一个webservice 为例作说明。这是一个webservice <WebMethod(Descrip…
理解NSAttributedString
An NSAttributedString object manages character strings and associated sets of attributes (for example, font and kerning) that apply to individual characters or ranges of characters in the string. 这句话就是对这个类的一个最简明扼要的概括。NSAttributedString…
Redis集群两种配置方式
2019独角兽企业重金招聘Python工程师标准>>> 第一种使用:JedisCluster <bean id"jedisPoolConfig" class"redis.clients.jedis.JedisPoolConfig"><property name"maxTotal" value"30" /><proper…
调用API弹出打印机属性对话框
调用api弹出打印机属性对话框 Author:vitoriatangFrom:Internet.NET Framework封装了很多关于打印的对话框,比如说PrintDialog, PageSetupDialog. 但是有的时候我们还需要关心打印机属性对话框,那么就可以调用API来解决这个问题。有几个API函数与之相关P…
Oracle DBA学习互联网化的内容
搞了多年的Oracle数据库维护,近几年来,个人感觉基本都在舒适区,技术上没啥进步。而且由于个人资料或者学习方法的限制,Oracle数据库技术上再想精进感觉事倍功半。2013年开始,去IOE的声势搞得轰轰烈烈,mysql…

离不开深度学习的自动驾驶
作者 | 小白来源 | 小白学视觉头图 | 下载于视觉中国深度学习在整个自动驾驶技术的各个部分中进行了应用,例如在感知,预测和计划中都有应用。同时,深度学习也可以用于制图,这是高级自动驾驶的关键组成部分。拥有准确的地图对于自动…
IOS -- base64编码
在iOS7以后可以用NSData自带的base64EncodedStringWithOptions进行编解码: 方法如下: - (NSString *)encodeToBase64String:(UIImage *)image {return [UIImagePNGRepresentation(image) base64EncodedStringWithOptions:NSDataBase64Encoding64Charact…
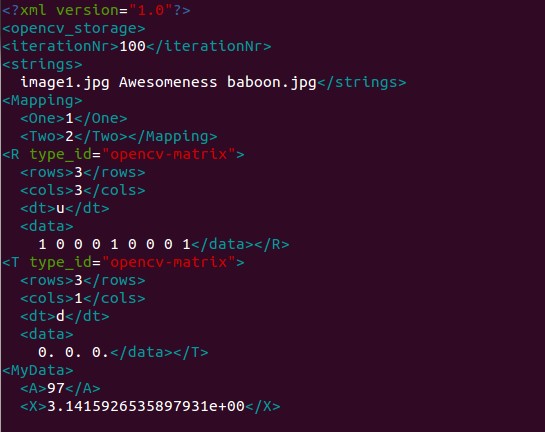
OpenCV持久化(二)
如何利用OpenCV持久化自己的数据结构?我们来看看OpenCV中的一个例子。 MyData.hpp定义自己的数据结构MyData如下: #ifndef MYDATA_HPP #define MYDATA_HPP#include <opencv2/core/core.hpp> #include <iostream> #include <string>using namespac…
Excel、Exchange和C#
摘要:Eric Gunnerson 将向您介绍如何使用 Outlook、Excel 和 C# 创建自定义的日历,该日历可以提供适用于短期项目和长期项目的清晰明了的版式。 下载 csharp05152003_sample.exe 示例文件(英文)。 虽然一月份已经过去了&#x…

这个宝藏工具,给你一种黑客般的感觉
明天要交作业了,吴检正在宿舍熬夜爆肝拼命敲代码,劈里啪啦的键盘声和咔咔的鼠标声格外嘈杂,室友陈琛瞥了一眼,背过身,沉沉睡去,留下他一人在深夜无尽的黑暗中,断断续续却又没有尽头的咔咔声中凌…
LSTM神经网络
LSTM是什么 LSTM即Long Short Memory Network,长短时记忆网络。它其实是属于RNN的一种变种,可以说它是为了克服RNN无法很好处理远距离依赖而提出的。 我们说RNN不能处理距离较远的序列是因为训练时很有可能会出现梯度消失,即通过下面的公式训…