仅用 480 块 GPU 跑出万亿参数!全球首个“低碳版”巨模型 M6 来了

继今年 3 月阿里达摩院发布国内首个千亿参数多模态大模型 M6(MultiModality-to-MultiModality MultitaskMega-transformer,以下简称 M6) 之后,6 月 25 日,达摩院宣布对 M6 进行全新升级,带来“低碳版”巨模型 M6,在全球范围内首次大幅降低了万亿参数超大模型训练能耗,更加符合业界对低碳、高效训练 AI 大模型的迫切需求。
通过一系列突破性的技术创新,达摩院团队仅使用 480 卡 GPU,即训练出了规模达人类神经元 10 倍的万亿参数多模态大模型 M6,与英伟达、谷歌等海外公司实现万亿参数规模相比,能耗降低超八成、效率提升近 11 倍。
在本文中,我们将从万亿参数多模态大模型 M6 所带来的创新突破为起点,分享其背后所采用的 MoE 架构原理和实现,以及达摩院对 MoE 架构的探索与发现。

何为大模型?
大模型将成下一代人工智能基础设施,在 AI 圈内已成共识。与生物体神经元越多往往越聪明类似,参数规模越大的 AI 模型,往往拥有更高的智慧上限,训练大模型或将让人类在探索通用人工智能上更进一步。然而,大模型算力成本也相当高昂,很大程度阻碍了学界、工业界对大模型潜力的深入研究。
对此,达摩院与阿里云机器学习 PAI 平台、EFLOPS 计算集群等团队改进了 MoE(Mixture-of-Experts)框架,大大扩增了单个模型的承载容量。同时,通过加速线性代数、混合精度训练、半精度通信等优化技术,大幅提升了万亿模型训练速度,且在效果接近无损的前提下有效降低了所需计算资源。

万亿参数的 M6-MoE 模型
大模型研究的一大技术挑战是,模型扩展到千亿及以上参数的超大规模时,将很难放在一台机器上。如果使用模型+流水并行的分布式策略,一方面在代码实现上比较复杂,另一方面由于前向和反向传播 FLOPs 过高,模型的训练效率将非常低,在有限的时间内难以训练足够的样本。
为了解决这一难题,达摩院智能计算实验室团队采用了 Mixture-of-Experts(MoE)技术方案,该技术能够在扩展模型容量并提升模型效果的基础上,不显著增加运算 FLOPs,从而实现高效训练大规模模型的目的。
普通 Transformer 与 MoE 的对比如下图所示。在经典的数据并行 Transformer 分布式训练中,各 GPU 上同一 FFN 层使用同一份参数。当使用图中最右侧所示的 MoE 策略时,则不再将这部分参数在 GPU 之间共享,一份 FFN 参数被称为 1 个 expert,每个 GPU 上将存放若干份参数不同的 experts。
在前向过程中,对于输入样本的每个 token,达摩院团队使用 gate 机制为其选择分数最高的 k 个 experts,并将其 hiddenstates 通过 all-to-all 通信发送到这些 experts 对应的 GPU 上进行 FFN 层计算,待计算完毕后发送回原 GPU,k 个 experts 的输出结果根据 gate 分数加权求和,再进行后续运算。为了避免部分 experts 在训练中接收过多 tokens 从而影响效率,MoE 往往设定一个 capacity 超参指定每个 expert 处理 token 的最大数量,超出 capacity 的 token 将在 FFN 层被丢弃。不同的 GPU 输入不同的训练数据分片。通过这种 expert 并行的策略,模型的总参数和容量大大扩增。由于单个样本经过 gate 稀疏激活后只使用有限个 experts,每个样本所需要的计算量并没有显著增加,这带来了突破千亿乃至万亿规模的可能性。
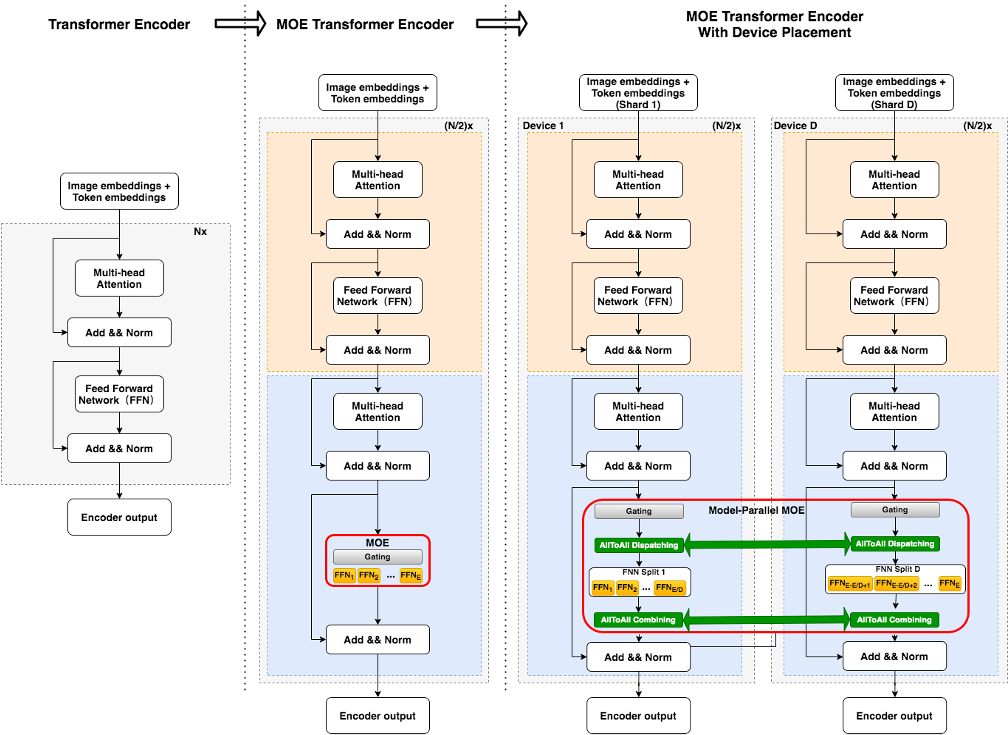
在 MoE 模型的具体实现上,谷歌的工作依赖 mesh tensorflow 和 TPU。达摩院则使用阿里云自研框架 Whale 开发万亿 M6-MoE 模型。将 FFN 层改造成 expert 并行,达摩院主要使用了 Whale 的算子拆分功能。在实现基本 MoE 策略的基础上,达摩院团队进一步整合 Gradient checkpointing、XLA 优化、混合精度训练、半精度通信等训练效率优化技术,并采用了 Adafactor 优化器,成功在 480 张 NVIDIA V100-32GB 上完成万亿模型的训练。
在训练中,他们采用绝对值更小的初始化,并且适当减小学习率,保证了训练的稳定性,实现正常的模型收敛,而训练速度也达到了约480 samples/s。通过对比1000亿、2500亿和10000亿参数规模的模型收敛曲线(如下图所示),达摩院团队发现参数规模越大确实能带来效果上的进一步提升。
然而,值得注意的是,目前扩参数的方式还是横向扩展(即增加expert数和intermediate size),而非纵向扩展(即扩层数),未来该团队也将进一步探索纵向扩展,寻求模型深度与宽度的最优平衡。

探索 MoE,进一步提升模型效果!
除了规模扩展外,达摩院对 MoE 架构开展了更进一步的探索研究,观察哪些因素对 MoE 模型的效果和效率影响较大。利用 MoE 架构扩大模型规模的一大关键是 expert 并行。而在 expert 并行中,几大因素决定着模型的计算和通信,包括负载均衡策略,topk 策略及对应的 capacity 设计等。
在 M6 团队对负载均衡在 MoE 实验的观察过程中,他们考虑到负载均衡的问题,通过采用启发式的方法解决该问题,如上述的 expert capacity 和对应的 residual connection 的方法。Google 的 Gshard 和 SwitchTransformer 沿用了 MoE 原文经典的做法加入了 auxiliaryload balancing loss。
目前还没有相关工作观察负载均衡的情况究竟有多严重,以及它是不是真的会影响模型的效果。达摩院团队在小规模的 M6 模型上进行了对 auxiliary loss 的消融实验,观察到该 loss 对最终模型效果影响甚微,甚至没有带来正向效果,然而它确实对 loadbalance这个问题非常有效。如下图所示:
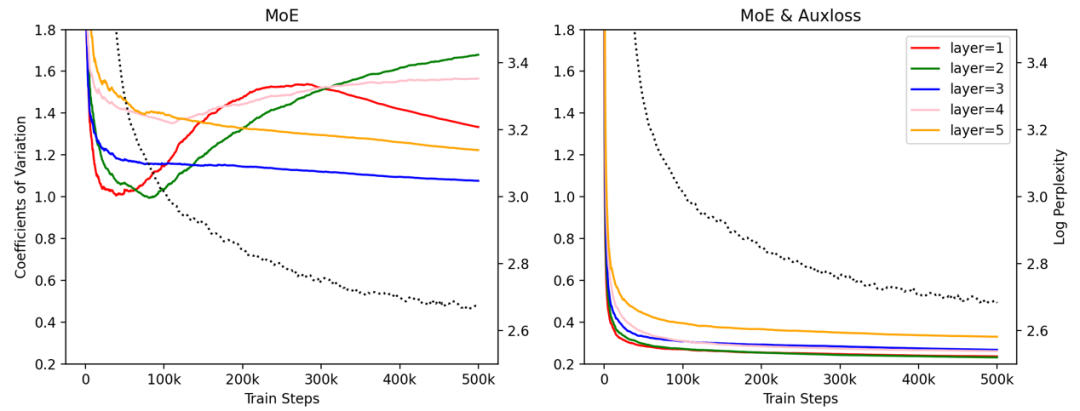
上图彩色曲线线表示各个层的 expert 接收有效 token 的变异系数随着训练进行的变化,灰色曲线表明训练阶段的 log PPL。图中变异系数 CV 表明每一层 expert 负载均衡情况,各曲线表明其随着训练步数的变化。
不难发现,训练初期所有模型均有较严重的负载不均衡问题,刚开始少数的 expert 接收了绝大部分的 token,导致很多 token 直接被丢弃,但它们均能实现快速下降,尤其具备 auxiliary loss 的模型 CV 能降低到 0.3 左右,也可观察到在该水平下均衡程度很高,每个 expert 都能接收大量有效 token。然而与之相反,不加 auxiliary loss 的模型表现非常不同,有的层甚至在训练后期出现 CV 的飙升。但不管对比训练阶段的 log PPL,还是对比下游语言模型任务的 PPL,不带 auxiliary loss 的模型都表现更优。这一定程度上反映其实负载均衡对最终效果的影响并不大。
达摩院 M6 团队进一步探索了关键的 top-k gating 策略 k 值和 capacity(C) 的选择。首先,他们简单地将 k 值扩大,发现k值越大其实效果越好。但考虑到选用不同的 k 值,C 则对应根据公式 进行调整。通过对 C 调整到 k=1 的水平,观察不同 k 值的 MoE 模型的表现,达摩院团队观察到 k 值更大模型依然表现越好,尽管 k 值增加带来的优势逐渐不太明显。
进行调整。通过对 C 调整到 k=1 的水平,观察不同 k 值的 MoE 模型的表现,达摩院团队观察到 k 值更大模型依然表现越好,尽管 k 值增加带来的优势逐渐不太明显。
但 k 值的增加根据 Gshard top-2 gating 的实现,除了存在实现层面上一定的冗余和困难外,循环 argmax 的操作也会导致速度变慢。此外,第二个 expert 的行为会受到第一个 expert 的影响,让训练和测试存在差异。
达摩院团队用 expert prototyping 的简单方式替代,相较 baseline 实现了效果提升,且未显著增加计算成本。expert prototyping,即将 expert 分成 k 组,在每组中再进行 top-k 的操作(通常采用top-1,便于理解),然后将k组的结果进行组合,也称之为k top-1。这种方式实现上更直接简便,并且允许组和组之间并行做top-k操作,更加高效。
达摩院团队观察到,在不同规模的模型上,expert prototyping都能取得比baseline更好的效果,同时速度和计算上也相比top-k更有优势。且其在更大规模的模型上优势变得更大,在百亿模型下游imagecaptioning任务上甚至能观察到优于top-k的表现:

因此达摩院团队将该方法推广到万亿参数M6超大模型,并对应和上述的万亿baseline做了对比。目前,万亿参数模型训练了大约3万步,已经显著优于同等规模的基线模型,呈现约5倍的收敛加速。

沿着这个方向,值得做的工作还有很多:考虑到分组的特性,应当让组和组之间产生足够的差异,让每个组选出来的experts尽可能实现组合的效果等等。

M6:首个实现商业化落地的多模态大模型
随着万亿参数 M6 模型的落地,阿里达摩院在超大规模预训练模型领域迈上新的台阶,且 M6 巨模型也成为国内首个实现商业化落地的多模态大模型。
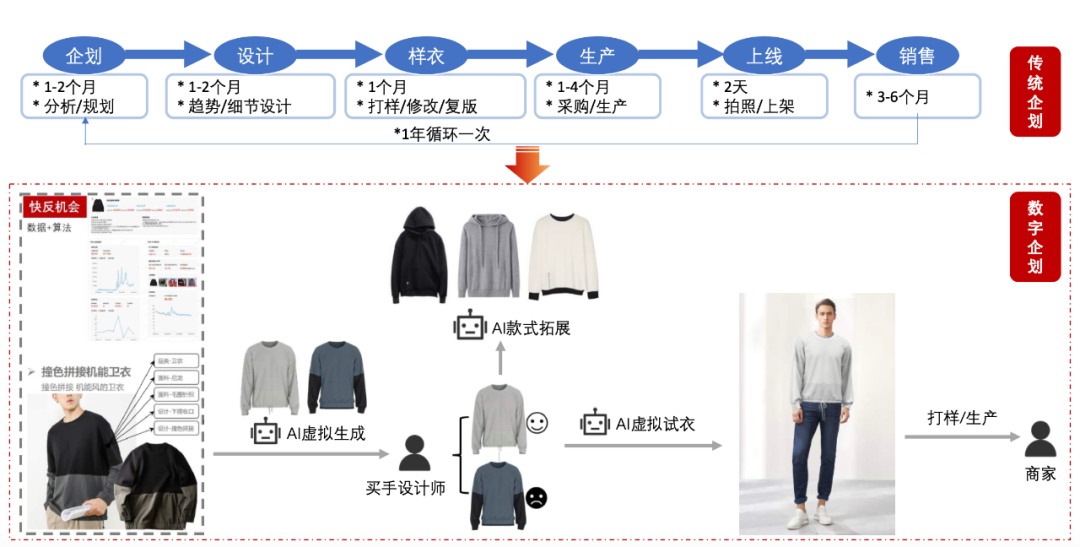
在商业应用层面,M6 拥有超越传统 AI 的认知和创造能力,它擅长绘画、写作、问答,在电商、制造业、文学艺术等诸多领域拥有广泛应用前景。其中以 AI 领域为例,M6 将作为 AI 助理设计师正式上岗阿里新制造平台犀牛智造,通过结合潮流趋势进行快速设计、试穿效果模拟,有望大幅缩短快时尚新款服饰设计周期。随着实践经验的增长,M6 设计的能力还将不断进化。
结合阿里的电商背景,M6 团队希望通过 M6 大模型优异的文字到图片生成能力,和电商领域产业链深度融合,挖掘潜在的应用价值。此前 OpenAI DALL·E 生成图片清晰度达 256×256,M6 则将图片生成清晰度提升至 1024×1024。

(以上为 M6 生成的高清服装设计图的示例)
解放设计师双手,以下为 M6 参与新款服装设计的流程图:
除文生图外,M6 还可以在工业界直接落地图生文能力,能够快速为商品等图片提供描述文案。该能力目前已在淘宝、支付宝部分业务上试应用。同时,多模态大模型为精准的跨模态搜索带来可能。目前M6已建立从文本到图片的匹配能力,未来,或将建立从文字到视频内容的认知能力,为搜索形态带来变革。
达摩院资深算法专家杨红霞表示,“接下来,M6 团队将继续把低碳 AI 做到极致,推进应用进一步落地,并探索对通用大模型的理论研究。”
参考文献
[1] Lepikhin,Dmitry, et al. "Gshard: Scaling giant models with conditional computationand automatic sharding." ICLR, 2021.
[2] Fedus, William, Barret Zoph, and Noam Shazeer. "Switch Transformers:Scaling to Trillion Parameter Models with Simple and Efficient Sparsity."arXiv preprint arXiv:2101.03961 (2021).
[3] Shazeer, Noam, and Mitchell Stern. "Adafactor: Adaptive learning rateswith sublinear memory cost." International Conference on Machine Learning.PMLR, 2018.
[4] Wang, Ang, et al. "Whale: A Unified Distributed TrainingFramework." arXiv preprint arXiv:2011.09208 (2020).


更多精彩推荐
赠书 | GNN 模型在生物化学和医疗健康中的典型应用什么?我要对AI礼貌?人机交互面临的道德漏洞几经沉浮,人工智能前路何方?点分享点收藏点点赞点在看
相关文章:

怎样将jpg转换成pdf软件
为什么80%的码农都做不了架构师?>>> 怎样将jpg转换成pdf软件 序言: 企业或个人通常会遇到设备终端软件的兼容性和支持性问题,比如,JPG转PDF文本,这给等于给用户设置了一个门槛,遇到需要将JPG转换…

二叉树的层次遍历 II
给出一棵二叉树,返回其节点值从底向上的层次序遍历(按从叶节点所在层到根节点所在的层遍历,然后逐层从左往右遍历) 样例 给出一棵二叉树 {3,9,20,#,#,15,7}, 3/ \9 20/ \15 7 按照从下往上的层次遍历为: [[15,7],[…
jquery autocomplete实现solr查询字段自动填充并执行查询
2019独角兽企业重金招聘Python工程师标准>>> 页面引入三个JS: <script type"text/javascript" src"js/jquery-1.7.2.js"></script> <script type"text/javascript" src"js/jquery-ui.js">&l…
C#使用CDO发送邮件
可以引用的COM组件列表,发现里面有一个名为Microsoft CDO For Exchange 2000 Library的COM组件,就是这个,我们可以用它来连接SMTP Server,使用用户名/密码验证发送邮件。 下面是实现的一个例子: Smtp Server使用的Smtp…

干货 | 当 YOLOv5 遇见 OpenVINO,实现自动检测佩戴口罩
YOLOv5网络YOLOv5代码链接:https://github.com/ultralytics/yolov5YOLOv5 于2020年6月横空出世!一经推出,便得到CV圈的瞩目,目前在各大目标检测竞赛、落地实战项目中得到广泛应用。 YOLOv5在COCO上的性能表现:YOLOv5一…
Ubuntu 16.04安装双显卡驱动方法收集
说明:不一定有效,要不断尝试。 http://www.linuxwang.com/html/2150.html http://blog.csdn.net/feishicheng/article/details/70662094>如有问题,请联系我:easonjim#163.com,或者下方发表评论。<
C#中的类型转换
C# 出来也有些日子了,最近由于编程的需要,对 C# 的类型转换做了一些研究,其内容涉及 C# 的装箱/拆箱/别名、数值类型间相互转换、字符的 ASCII 码和 Unicode 码、数值字符串和数值之间的转换、字符串和字符数组/字节数组之间的转换、各种数值…

解构 StyleCLIP:文本驱动、按需设计,媲美人类 P 图师
来源 | HyperAI超神经(ID:HyperAI)作者 | 神经三羊StyleCLIP 是一种新型「P 图法」,它结合了 StyleGAN 和 CLIP,可以仅依据文本描述,对图像进行修改和处理。提起 StyleGAN 大家都不陌生。这个由 NVIDIA 发布的新型生成…
nexus 4 下 DualBootInstallation 安装 ubuntu touch
最近折腾ubuntu for phone ubuntu也算是雷声大雨点小,从edge手机开始,到说兼容一大部分谷歌机,到现在缩水说只适配nexus 4 节操掉了一地啊,对付这种情况,ubuntu touch也就可以只装着玩玩了,还好ubuntu 官方…
我的家庭私有云计划-13
嗯,昨天算由感而发啊,大家看看就好了。 嗯,接着说咱们的云。 先说啊,我没打算在这个领域里面完全自研,我还没那么疯,这个呢属于一体化解决方案,我认为还是社会分工合作的结果,不强调…
C语言return函数
return函数 说到return,有必要提及主函数的定义。很多人甚至市面上的一些书籍,都使用了void main( )这一形式 ,其实这是错误的。 C/C 中从来没有定义过void main( ) 。C 之父 Bjarne Stroustrup 在他的主页上的 FAQ 中明确地写着: The defi…
怎样写出一个较好的高速排序程序
写出一个较好的高速排序程序 高速排序是经常使用的排序算法之中的一个,但要想写出一个又快又准的使用程序,就不是那么简单了须要注意的事项 首先要写正确。通常使用递归实现。其递归相当于二叉树展开,因此假设要用迭代实现的话须要使用一个队…

写代码时发现......还得是 SpringBoot !一篇拿下
关注了很多技术类公众号的读者肯定有这样一个感受,SpringBoot相关的文章铺天盖地,并且SpringBoot相关的文章阅读量、收藏量都很高,这也从侧面反映了SpringBoot技术的火爆。一切都在证明,SpringBoot已经成为了Java程序员必备的技能…
Python的 if .else.elif语句详解
If 语句 是用来判断的 Python 编程中 if 语句用于控制程序执行 用来检测一个条件:如果条件为 (真)true,就会运行这个语法块,如果为Fales 就跳过不执行。 elif是依附于if存在的,两者之间的运算逻辑相同&…
C#中string与byte[]的转换帮助类
在写C#程序时,string和byte[]之间的转换比较烦,在移植一些老程序时感觉很不好。我在C#中使用DES和TripleDES时移植一块老代码时也遇到了同样的情况。为了下次不为同样的事情烦恼,就写了下面的帮助类。 主要实现了以下…

鲲鹏入晋 万里腾飞,鲲鹏应用创新大赛2021山西赛区邀你来战!
2021 年 6 月 29 日,由山西省工业和信息化厅、山西转型综合改革示范区管理委员会为指导单位,华为技术有限公司主办,山西鲲鹏生态创新中心暨华为(山西综改区)DevCloud 创新中心承办,山西长河科技股份有限公司…
tcpdump-根据IP查看程序与服务都用了哪些端口
tcpdump -i em1 -tttt src 116.3.248.157 and port ! 6869 -nn -i 指定端口 -tttt 附带时间戳 -nn 解析域名与端口信息 ############################################# windows下可以使用netstat -nb |find “18999” 与 netstat -ao 结合使用,在通过pid号 查看进程…
快速构建Windows 8风格应用27-漫游应用数据
本篇博文主要介绍漫游应用数据概览、如何构建漫游应用数据、构建漫游应用数据最佳实践。 漫游应用数据概览 1.若应用当中使用了漫游应用数据,用户可以很轻松的在不同的设备间保持应用数据的同步。 2.Windows会将更新的漫游数据同步到云端,并将数据更新到…

jquery和css3打造超梦幻的三维动画背景
今天为大家带来的是一款由jquery和css3实现的超级梦幻的背景效果。绿色的小原点由远到近,由近到远一种飞跃效果。效果非常好看,我们一起看下效果图: 在线预览 源码下载 我们一起看下实现的代码。这是一款由jquey和css3实现的效果。这里引用…
C#时间函数扩展
//本周是本年第几周 private int DatePart(System.DateTime dt) { int weeknow Convert.ToInt32(dt.DayOfWeek);//今天星期几 int daydiff (-1) * (weeknow1);//今日与上周末的天数差 int days System.DateTime.Now.AddDays(daydiff).DayOfYear;//上周末是本年第几天 i…

“我被机器解雇了!”Amazon 63岁员工因算法评分太低被自动开除
整理 | Carol出品 | CSDN(ID:CSDNnews)“我被一个机器解雇了。”63岁“老司机”因跟踪算法被开除一觉醒来,63岁的斯蒂芬 诺曼丁(Stephen Normandin)发现自己居然被莫名其妙解雇了。斯蒂芬是Amazon Flex的一…
微信开放平台手机APP支付
PHP对接APP微信支付 微信开放平台手机APP支付总结 1. 微信开放平台手机APP支付总结 支付功能链接: https://pay.weixin.qq.com/wiki/doc/api/index.html APP支付功能文档: https://pay.weixin.qq.com/wiki/doc/api/app/app.php?chapter8_3 Demo下载地址: https://pay.weixin.q…
VS2005创建CLR自定义触发器
第一步:在Visual Studio 2005中编写代码 using System; using System.Data; using System.Data.Sql; using System.Data.SqlServer; using System.Data.SqlTypes; public partial class Triggers { // Enter existing table or view for the target and unc…
Adobe推出HTML5动画设计工具Edge
2019独角兽企业重金招聘Python工程师标准>>> HTML5和Flash,是敌对?是共存? 尽管Flash现在依然牢牢占据着网络动画的大半江山,但这种状况终将会被改变。 那么,Edge的推出是否意味着Adobe将放弃和屈服于Flash…

AI 算法给手画线稿自动上色指南来了
测试图片作者 | 叶庭云来源 | 修炼Python生成线稿图像手绘效果的特征:黑白灰色、边界线条较重、相同或相近色彩趋于白色、略有光源效果。手绘风格是在对图像进行灰度化的基础上由立体效果和明暗效果叠加而成的,灰度实际代表了图像的明暗变化,…

mysqldump和xtrabackup备份原理实现说明
MySQL数据库备份分为逻辑备份和物理备份两大类,犹豫到底用那种备份方式的时候先了解下它们的差异: 逻辑备份的特点是:直接生成SQL语句,在恢复的时候执行备份的SQL语句实现数据库数据的重现。物理备份的特点是:拷贝相关…
C语言100个经典的算法
POJ上做做ACM的题 语言的学习基础,100个经典的算法C语言的学习要从基础开始,这里是100个经典的算法-1C语言的学习要从基础开始,这里是100个经典的算法 题目:古典问题:有一对兔子,从出生后第3个月…

PornHub:修复百年前情色电影
全球最大不可描述网站 PornHub 最近在自己的官网上,注册了一个名为 「Remastured」的视频发布账号,中文意为「重制」。截止目前,这个账号已经上传了 21 个视频(包含一部项目介绍视频),共计两万的订阅用户和…
jquery 插件开发的作用域及基础
2019独角兽企业重金招聘Python工程师标准>>> 之前一直有开发jquery插件的冲动,所以一直想学习如何进行插件开发,最近一个项目需要使用图片上传组件及自动无限下拉组件,百度地图组件,所以趁着这次我就把他们全部插件化了…

WSUS Troubleshooting guide
Troubleshooting guide for issues where WSUS clients are not reporting in 来自于WSUS TEAM BLOG This guide is written to assist specifically in troubleshooting WSUS when clients are not reporting in. We will examine common troubleshooting considerations that…