MapReduce对交易日志进行排序的Demo(MR的二次排序)
1.日志源文件 (各个列分别是: 账户,营业额,花费,日期)

zhangsan@163.com 6000 0 2014-02-20
lisi@163.com 2000 0 2014-02-20
lisi@163.com 0 100 2014-02-20
zhangsan@163.com 3000 0 2014-02-20
wangwu@126.com 9000 0 2014-02-20
wangwu@126.com 0 200 2014-02-20想要的结果: (计算出每个账户的总营业额和总花费,要求营业额排序降序,如果营业额相同则花费少的在上面)
zhangsan@163.com 9000 0 9000
wangwu@126.com 9000 200 8800
lisi@163.com 2000 100 19002.写代码:
InfoBean.java 对账户的后三个字段封装成一个Bean对象
1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.WritableComparable; 6 7 //要和其他的InfoBean类型进行比较,所以此处泛型T为InfoBean 8 public class InfoBean implements WritableComparable<InfoBean> { 9 10 private String account; 11 private double income; 12 private double expenses; 13 private double surplus; 14 15 /* 16 *如果不写这个方法,封装InfoBean对象的时候就要分别set这个对象的各个属性. 17 */ 18 public void set(String account,double income,double expenses){ 19 this.account = account; 20 this.income = income; 21 this.expenses = expenses; 22 this.surplus = income -expenses; 23 } 24 @Override 25 public void write(DataOutput out) throws IOException { 26 out.writeUTF(account); 27 out.writeDouble(income); 28 out.writeDouble(expenses); 29 out.writeDouble(surplus); 30 } 31 32 @Override 33 public void readFields(DataInput in) throws IOException { 34 this.account = in.readUTF(); 35 this.income = in.readDouble(); 36 this.expenses = in.readDouble(); 37 this.surplus = in.readDouble(); 38 } 39 40 @Override 41 public int compareTo(InfoBean o) { 42 if(this.income == o.getIncome()){ 43 return this.expenses > o.getExpenses() ? 1 : -1; 44 } else { 45 return this.income > o.getIncome() ? -1 : 1; 46 } 47 } 48 49 @Override 50 //toString()方法输出的格式最好和源文件trade_info.txt中的格式一样, 字段通过Tab键分隔. 51 //而且在SumReducer类输出k3,v3的时候会输出k3(context.write(key, v);) 所以这个地方没有必要再输出k3(account) 52 public String toString() { 53 // return "InfoBean [account=" + account + ", income=" + income 54 // + ", expenses=" + expenses + ", surplus=" + surplus + "]"; 55 return this.income + "\t" + this.expenses+"\t" + this.surplus; 56 } 57 public double getIncome() { 58 return income; 59 } 60 61 public void setIncome(double income) { 62 this.income = income; 63 } 64 65 public double getExpenses() { 66 return expenses; 67 } 68 69 public void setExpenses(double expenses) { 70 this.expenses = expenses; 71 } 72 73 public double getSurplus() { 74 return surplus; 75 } 76 77 public void setSurplus(double surplus) { 78 this.surplus = surplus; 79 } 80 81 public String getAccount() { 82 return account; 83 } 84 85 public void setAccount(String account) { 86 this.account = account; 87 } 88 89 }
SumStep.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.Mapper; 9 import org.apache.hadoop.mapreduce.Reducer; 10 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 12 13 public class SumStep { 14 15 public static class SumMapper extends Mapper<LongWritable, Text, Text, InfoBean>{ 16 private Text k = new Text(); 17 private InfoBean bean = new InfoBean(); 18 19 @Override 20 protected void map(LongWritable key, Text value,Mapper<LongWritable, Text, Text, InfoBean>.Context context) 21 throws IOException, InterruptedException { 22 23 String line = value.toString(); 24 String [] fields = line.split("\t"); 25 String account = fields[0]; 26 double income = Double.parseDouble(fields[1]); 27 double expenses = Double.parseDouble(fields[2]); 28 k.set(account); 29 bean.set(account, income, expenses); 30 context.write(k, bean); 31 } 32 } 33 public static class SumReducer extends Reducer<Text, InfoBean, Text, InfoBean>{ 34 private InfoBean v = new InfoBean(); 35 @Override 36 protected void reduce(Text key, Iterable<InfoBean> values,Reducer<Text, InfoBean, Text, InfoBean>.Context context) 37 throws IOException, InterruptedException { 38 double sum_in = 0; 39 double sum_out = 0; 40 for(InfoBean bean : values){ 41 sum_in += bean.getIncome(); 42 sum_out += bean.getExpenses(); 43 } 44 /* 45 * 在crxy的流量统计的案例中 是如下的方式写出k3和v3的 在reduce方法中new这个封装好的对象. 46 * 但是如果数据量比较大的情况下 是可能会造成内存溢出的. 47 * TrafficWritable v3 = new TrafficWritable(t1, t2, t3, t4); 48 * context.write(k2, v3); 49 * 50 * 所以建议把这个封装的对象写在"脑袋顶上" 如上所示....private InfoBean v = new InfoBean(); 51 * 但是如果你Java基础比较好的话可能会说 在Java中是引用传递...所以后面的v会覆盖前面的v,造成最后只有最有一个v 52 * 其实这里是不会产生问题的,因为context.write()方法会直接把v3对应的InfoBean对象序列化. 53 * 虽然之前对象的引用确实覆盖了,但是之前对象的值等都保存了下来.是可以放在这个类的"脑袋顶上"的. 54 * 让这个类公用这个InfoBean对象. 55 */ 56 57 v.set(key.toString(),sum_in,sum_out); 58 context.write(key, v); 59 } 60 } 61 public static void main(String[] args) throws Exception { 62 Configuration conf = new Configuration(); 63 Job job = Job.getInstance(conf); 64 job.setJarByClass(SumStep.class); 65 66 job.setMapperClass(SumMapper.class); 67 //以下两行可以在满足一定条件的时候省略掉. 68 //在满足k2和k3,v2和v3一一对应的时候就可以省略掉. 看SumReducer类所在行的泛型. 69 job.setMapOutputKeyClass(Text.class); 70 job.setMapOutputValueClass(InfoBean.class); 71 72 FileInputFormat.setInputPaths(job, new Path(args[0])); 73 74 job.setReducerClass(SumReducer.class); 75 job.setOutputKeyClass(Text.class); 76 job.setOutputValueClass(InfoBean.class); 77 FileOutputFormat.setOutputPath(job, new Path(args[1])); 78 job.waitForCompletion(true); 79 } 80 }
项目打成jar包放到Linux中,日志源文件上传到HDFS上.运行结果如下:
hadoop jar /root/itcastmr.jar itcastmr.SumStep /user/root/trade_info.txt /tradeout

但是这个结果并没有排序.还是按照账号的字典排序.
以这个MR的输出当做输入对其根据InfoBean对象进行排序.....
上代码SortStep.java:
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.NullWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Job; 9 import org.apache.hadoop.mapreduce.Mapper; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 12 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 13 14 public class SortStep { 15 //这个Mapper读取的HDFS文件是SumStep Reduce计算输出的文件. 16 public static class SortMapper extends Mapper<LongWritable, Text, InfoBean, NullWritable>{ 17 private InfoBean k = new InfoBean(); 18 @Override 19 protected void map(LongWritable key,Text value,Mapper<LongWritable, Text, InfoBean, NullWritable>.Context context) 20 throws IOException, InterruptedException { 21 String line = value.toString(); 22 String [] fields = line.split("\t"); 23 String account = fields[0]; 24 double income = Double.parseDouble(fields[1]); 25 double expenses = Double.parseDouble(fields[2]); 26 k.set(account, income, expenses); 27 //现在是要求按照InfoBean对象中的规则排序(InfoBean中有compareTo方法)...所以InfoBean对象当做k2... 28 context.write(k,NullWritable.get());//不能传null,NullWritable.get() 是获得的this对象. 29 } 30 } 31 public static class SortReducer extends Reducer<InfoBean, NullWritable, Text, InfoBean>{ 32 private Text k = new Text(); 33 @Override 34 protected void reduce(InfoBean bean, Iterable<NullWritable> values,Reducer<InfoBean, NullWritable, Text, InfoBean>.Context context) 35 throws IOException, InterruptedException { 36 String account = bean.getAccount(); 37 k.set(account); 38 context.write(k, bean); 39 } 40 } 41 42 public static void main(String[] args) throws Exception { 43 Configuration conf = new Configuration(); 44 Job job = Job.getInstance(conf); 45 job.setJarByClass(SortStep.class); 46 47 job.setMapperClass(SortMapper.class); 48 //以下两行可以在满足一定条件的时候省略掉. 49 //在满足k2和k3,v2和v3一一对应的时候就可以省略掉. 看SumReducer类所在行的泛型. 50 job.setMapOutputKeyClass(InfoBean.class); 51 job.setMapOutputValueClass(NullWritable.class); 52 53 FileInputFormat.setInputPaths(job, new Path(args[0])); 54 55 job.setReducerClass(SortReducer.class); 56 job.setOutputKeyClass(Text.class); 57 job.setOutputValueClass(InfoBean.class); 58 FileOutputFormat.setOutputPath(job, new Path(args[1])); 59 job.waitForCompletion(true); 60 } 61 }
打成jar包,然后运行命令....输入为上面SumStep.java的输出
hadoop jar /root/itcastmr.jar itcastmr.SortStep /tradeout /trade_sort_out
排序之后的结果:

在MapReduce读取输入数据的时候,如果这个文件是以下划线开始的话,那么会不会读取这个文件中的内容...."_SUCCESS"文件就不会读取....
如果想对某个类进行排序,
1.这个类要实现WritableComparable接口,
2.还要重写compareTo方法. 根据自己的业务逻辑自定义排序.
只需要把要排序的类当做k2 就可以了...框架自动排序.
要排序对象的compareTo方法是框架调用的,框架在shuffle这个阶段会调用排序.
shuffle后面会讲,shuffle由很多很多的阶段组成,分区,排序,分组,combiner等等...把这些小的细节都讲完了之后再讲shuffle.
本文转自SummerChill博客园博客,原文链接:http://www.cnblogs.com/DreamDrive/p/7398455.html,如需转载请自行联系原作者
相关文章:

HTTP中Get与Post的区别
Http定义了与服务器交互的不同方法,最基本的方法有4种,分别是GET,POST,PUT,DELETE。URL全称是资源描述符,我们可以这样认 为:一个URL地址,它用于描述一个网络上的资源,而…

sdut AOE网上的关键路径(spfa+前向星)
http://acm.sdut.edu.cn/sdutoj/showproblem.php?pid2498&cid1304 题目描述 一个无环的有向图称为无环图(Directed Acyclic Graph),简称DAG图。 AOE(Activity On Edge)网:顾名思义,用边表示活动的网ÿ…

苹果新功能惹网友众怒,还有隐私可言吗?
编译 | 禾木木出品 | AI科技大本营(ID:rgznai100)大部分人选择 iPhone 的一大理由就是信息安全,这家公司对于个人隐私的保护一直为人称赞。最近苹果公司宣布,为了让儿童能够更加安全地上网,他们决定在iOS 15、iPADOS 15、macOS Monterey系统中…
让Ubuntu拥有SUSE一样的GRUB启动界面
SUSE的漂亮大家可能都见识过,尤其是那个Grub启动画面。我身边的朋友为了在自己的系统上也能使用SUSE的GRUB启动画面,用了一种原理比较简 单,过程比较白痴的方法:先安装SUSE,把/boot单独分区,然后把除了/boo…

计算机编程简史图
计算机编程简史图www.21kaiyun.com 21世纪开运网 算准你每天的桃花运 帮忙推广下我的网站 谢谢
HTML5 模板推荐
http://www.yundic.com/转载于:https://www.cnblogs.com/lsl8966/p/4133484.html

Windows 11 再惹“众怒”!网友:微软就是逼我去买新电脑!
整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)一般来说,不论是移动还是桌面操作系统,如若要升级版本,大多用户都不会产生过大的抵触情绪,毕竟更新往往都是为了确保用户获得最佳体验。但近来用户对微软…

刚学习了linux的DHCP 配置.呵呵.自己上来总结下.
先来看DHCP的工作原理.DHCP (Dynamic Host Configuration Protocol)下面的部分是google找的....~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~DHCP来自ITwiki,开放的信息技术大百科DHCP是Dynamic Host Configuration Protocol的…
App_Offline.htm 一个静态页面实现整站维护时统一页面
在ASP.NET 2.0 站点根目录下,只要存在 App_Offline.htm 文件,那么所有对.aspx的请求都将转向App_Offline.htm 。而且浏览器的地址栏显示的是所请求的.aspx的URL。 这样当我们的站点需要维护时,只要把App_Offline.htm 拷贝到站点根目录下即…
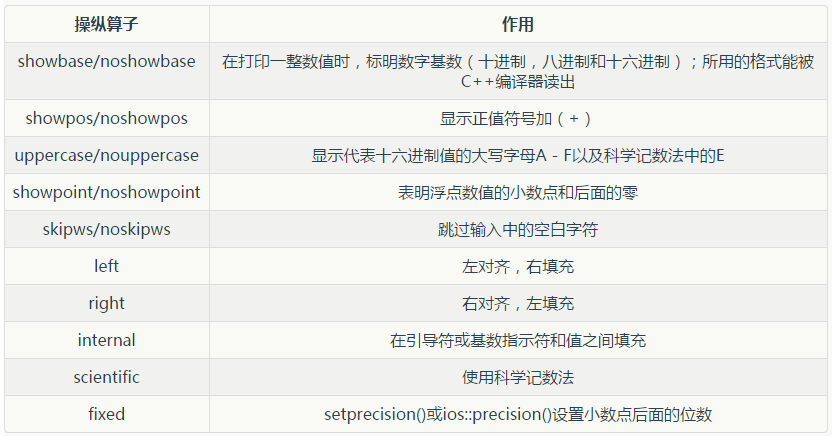
C++编程思想重点笔记(上)
C和C指针的最重要的区别在于:C是一种类型要求更强的语言。就void *而言,这一点表现得更加突出。C虽然不允许随便地把一个类型的指针指派给另一个类型,但允许通过void *来实现。例如: bird* b;rock* r;void* v;v r;b v; C不允许…

一行命令实现录屏,支持热键和鼠标操作,区域、帧率、格式任你选择
作者:天元浪子来源:CSDN 博客市面上的录屏工具软件有很多,基本都是窗口程序。毕竟,离开GUI的支持,设置参数、选择录像区域等操作都会变得非常困难。不过,窗口程序也并非无往不胜,即便是屏幕录像…

SMO学习笔记(二)——还原(恢复)篇之完整恢复
SQLSERVER2005恢复介绍: 三种恢复模式(一).简单恢复模式 事务日志被自动截断,不能使用日志文件进行恢复。(二).完整恢复模式 保留所有操作的完整事务日志。(三).大容量日志恢复模式 简要记录大容量操作(索引创建和大容…

linux内核map图
linux内核map图
Linux下tcpdump用法
根据使用者的定义对网络上的数据包进行截获的包分析工具。tcpdump将网络中传送的数据包的“头”完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供了and、 or、not等逻 辑语句来帮助过滤不必要的信息; 默认情况下&#…

终于有人站出来为程序员说话了
【CSDN 编者按】刘少山博士是《程序员》杂志的作者之一,多年来投稿了大量无人驾驶领域相关的优质内容,《新程序员》上线后,他带着自己多年来对技术行业的思考以及对程序员群体的殷切期望重新回归,希望能对大家有所启迪。作者 | 刘…

给 Windows 驱动程序安装提速
对比各种主流操作系统,在 Windows 上安装驱动程序是最直观最方便的,不仅可以通过设备管理器查看所有硬件的信息并安装驱动,在有新硬件插入时也有人性化的驱动程序安装提示和安装向导,甚至还可以在线安装驱动,这都是其他…
web标准化设计:常用的CSS命名规则
常用的CSS命名规则 头:header 内容:content/container 尾:footer 导航:nav 侧栏:sidebar 栏目:column 页面外围控制整体布局宽度:wrapper 左右中:left right center 登录条ÿ…

鲲鹏应用创新大赛山西区域赛圆满落幕,鲲鹏生态助力信创变革
鲲鹏入晋,万里腾飞,8 月 6 日,2021 鲲鹏应用创新大赛山西赛区决赛在太原圆满落幕。今年鲲鹏应用创新大赛区域赛山西赛区是山西省内数字化转型的重要赛事,经过层层选拔,共 35 个队伍进入山西赛区决赛,参加政…

视频分享网站首页:最新视频特效
2019独角兽企业重金招聘Python工程师标准>>> <!DOCTYPE> <html> <head><title></title><style>.newVideo{width:208px;height:116px;border:0px solid #000; position:relative;cursor:pointer;}.newVideoImg{position:relativ…
Metasploit攻击Oracle的环境搭建
Metasploit中关于Oracle的攻击模块默认并不完全,需要自己做一些工作。本文主要记录在搭建环境的中的一些错误(操作系统Backtrack 5)。在默认情况下使用oracle的一些攻击功能会出现类似如下错误:ary module execution completed m…
jQuery / jQuery mvc plugin
jMVC专为 Qt WRT 设计。Qt WRT 将随新版Qt发布,支持 Symbian ^3 和 Meego 设备。jMVC 采用延迟加载设计,代码分布在不同的.js文件中,调用时通过xhr加载。 在web环境中会严重影响性能,所以jMVC不适合开发web site。目前大部分web b…
【转发】什么时候该用委托,为什么要用委托,委托有什么好处
好多人一直在问:什么时候该用委托,为什么要用委托,委托有什么好处.... 看完下面的文章你将茅塞顿开..(看不懂的直接TDDTDS) 概念虽然我不喜欢讲太多 我们直接先来YY 个场景:我很喜欢打游戏,但运气不好每次打游戏都会被主管看到,朱老板不喜欢他的员工在上班的时 间打游戏,所以朱…

一位合格软件工程师应该具备怎样的工程化、交付能力?
大厂待遇高、福利也好相信很多同学都对大厂有着向往,然而现实却是......有的同学成功拿到offer进入大厂,有的同学还在为备考大厂迷茫苦恼着:我之前从未面试过,这次冒险投了字节,几乎是抱着积累经验和技术交流的心态去了…

Flex通信-Java服务端通信实例
Flex与Java通信的方式有很多种,比较常用的有以下方式: WebService:一种跨语言的在线服务,只要用特定语言写好并部署到服务器,其它语言就可以调用 HttpService:通过http请求的形式访问服务器 RmoteObject&am…
jQuery性能优化指南
1,总是从ID选择器开始继承 在jQuery中最快的选择器是ID选择器,因为它直接来自于JavaScript的getElementById()方法。 例如有一段HTML代码: <div id"content"> <form method"post" action"#"> &l…

速度快到飞起 如何跟蜻蜓的大脑学习计算?
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 科学家研究了其中一种大型昆虫蜻蜓的大脑,希望利用这些昆虫的专长来设计计算系统,这些系统针对拦截来袭导弹或跟踪气味羽流等任务进行了优化。通过利用蜻蜓神经系统的速度、简单性和效率,目…
Python、Unicode和中文
python的中文问题一直是困扰新手的头疼问题,这篇文章将给你详细地讲解一下这方面的知识。当然,几乎可以确定的是,在将来的版本中,python会彻底解决此问题,不用我们这么麻烦了。先来看看python的版本:>&g…
提高mysql性能的开源软件
今天发现一个开源软件,看介绍可以提高mysql的性能,这个东西就是Google的开源TCMalloc库,于是拿来装了下看看效果.这个软件下载地址是:http://code.google.com/p/google-perftools/downloads/list,我用的是最新版的google-perftools-1.4.tar.gz.1.安装过程:#tar zxvf google-per…
一款比较实用齐全的jQuery 表单验证插件
一款比较实用,并且验证类型齐全的jQuery表单验证插件.英文版原作者Vanadium,由我做中文整理.E文水平有限,如果翻译的有问题的,请大家指出,在此感谢~可以验证哪些? 文字,日期,邮箱,网址,数字,AJAX用户名验证以及自定义的正则等等几乎所有我们要用到的验证.不多说,看DEMO吧: 点此…
[原]VS2012编译GLEW 1.11
1、到http://glew.sourceforge.net/下载源代码 2、使用vs2012打开build下vc6的glew.dsw ,自动生成2012工程(一路点确定)特别注意:不要使用build下的vc12之类的 本人亲测不好使 坑了我很久 3、直接生成解决方案,会在根目…