7000 字精华总结,Pandas/Sklearn 进行机器学习之特征筛选,有效提升模型性能

作者 | 俊欣
来源 | 关于数据分析与可视化
今天小编来说说如何通过pandas以及sklearn这两个模块来对数据集进行特征筛选,毕竟有时候我们拿到手的数据集是非常庞大的,有着非常多的特征,减少这些特征的数量会带来许多的好处,例如
提高预测的精准度
降低过拟合的风险
加快模型的训练速度
增加模型的可解释性
事实上,很多时候也并非是特征数量越多训练出来的模型越好,当添加的特征多到一定程度的时候,模型的性能就会下降,从下图中我们可以看出,
因此我们需要找到哪些特征是最佳的使用特征,当然我们这里分连续型的变量以及离散型的变量来讨论,毕竟不同数据类型的变量处理的方式不同,我们先来看一下对于连续型的变量而言,特征选择到底是怎么来进行的。

计算一下各个变量之间的相关性
我们先导入所需要用到的模块以及导入数据集,并且用pandas模块来读取
from sklearn.datasets import load_boston
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.feature_selection import RFE
from sklearn.linear_model import RidgeCV, LassoCV, Ridge, Lasso这次用到的数据集是机器学习中尤其是初学者经常碰到的,波士顿房价的数据集,其中我们要预测的这个对象是MEDV这一列
x = load_boston()
df = pd.DataFrame(x.data, columns = x.feature_names)
df["MEDV"] = x.target
X = df.drop("MEDV",1) #将模型当中要用到的特征变量保留下来
y = df["MEDV"] #最后要预测的对象
df.head()output
CRIM ZN INDUS CHAS NOX ... TAX PTRATIO B LSTAT MEDV
0 0.00632 18.0 2.31 0.0 0.538 ... 296.0 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0.0 0.469 ... 242.0 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0.0 0.469 ... 242.0 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0.0 0.458 ... 222.0 18.7 394.63 2.94 33.4
4 0.06905 0.0 2.18 0.0 0.458 ... 222.0 18.7 396.90 5.33 36.2我们可以来看一下特征变量的数据类型
df.dtypesoutput
CRIM float64
ZN float64
INDUS float64
CHAS float64
NOX float64
RM float64
AGE float64
DIS float64
RAD float64
TAX float64
PTRATIO float64
B float64
LSTAT float64
MEDV float64
dtype: object我们看到都是清一色的连续型的变量,我们来计算一下自变量和因变量之间的相关性,通过seaborn模块当中的热力图来展示,代码如下
plt.figure(figsize=(10,8))
cor = df.corr()
sns.heatmap(cor, annot=True, cmap=plt.cm.Reds)
plt.show()相关系数的值一般是在-1到1这个区间内波动的
相关系数要是接近于0意味着变量之间的相关性并不强
接近于-1意味着变量之间呈负相关的关系
接近于1意味着变量之间呈正相关的关系
我们来看一下对于因变量而言,相关性比较高的自变量有哪些
# 筛选出于因变量之间的相关性
cor_target = abs(cor["MEDV"])
# 挑选于大于0.5的相关性系数
relevant_features = cor_target[cor_target>0.5]
relevant_featuresoutput
RM 0.695360
PTRATIO 0.507787
LSTAT 0.737663
MEDV 1.000000
Name: MEDV, dtype: float64筛选出3个相关性比较大的自变量来,然后我们来看一下自变量之间的相关性如何,要是自变量之间的相关性非常强的话,我们也只需要保留其中的一个就行,
print(df[["LSTAT","PTRATIO"]].corr())
print("=" * 50)
print(df[["RM","LSTAT"]].corr())
print("=" * 50)
print(df[["PTRATIO","RM"]].corr())output
LSTAT PTRATIO
LSTAT 1.000000 0.374044
PTRATIO 0.374044 1.000000
==================================================RM LSTAT
RM 1.000000 -0.613808
LSTAT -0.613808 1.000000
==================================================PTRATIO RM
PTRATIO 1.000000 -0.355501
RM -0.355501 1.000000从上面的结果中我们可以看到,RM变量和LSTAT这个变量是相关性是比较高的,我们只需要保留其中一个就可以了,我们选择保留LSTAT这个变量,因为它与因变量之间的相关性更加高一些
递归消除法
我们可以尝试这么一种策略,我们选择一个基准模型,起初将所有的特征变量传进去,我们再确认模型性能的同时通过对特征变量的重要性进行排序,去掉不重要的特征变量,然后不断地重复上面的过程直到达到所需数量的要选择的特征变量。
LR= LinearRegression()
# 挑选出7个相关的变量
rfe_model = RFE(model, 7)
# 交给模型去进行拟合
X_rfe = rfe_model.fit_transform(X,y)
LR.fit(X_rfe,y)
# 输出各个变量是否是相关的,并且对其进行排序
print(rfe_model.support_)
print(rfe_model.ranking_)output
[False False False True True True False True True False True FalseTrue]
[2 4 3 1 1 1 7 1 1 5 1 6 1]第一行的输出包含True和False,其中True代表的是相关的变量对应下一行的输出中的1,而False包含的是不相关的变量,然后我们需要所需要多少个特征变量,才能够使得模型的性能达到最优
#将13个特征变量都依次遍历一遍
feature_num_list=np.arange(1,13)
# 定义一个准确率
high_score=0
# 最优需要多少个特征变量
num_of_features=0
score_list =[]
for n in range(len(feature_num_list)):X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.3, random_state = 0)model = LinearRegression()rfe_model = RFE(model,feature_num_list[n])X_train_rfe_model = rfe_model.fit_transform(X_train,y_train)X_test_rfe_model = rfe_model.transform(X_test)model.fit(X_train_rfe_model,y_train)score = model.score(X_test_rfe_model,y_test)score_list.append(score)if(score>high_score):high_score = scorenum_of_features = feature_num_list[n]
print("最优的变量是: %d个" %num_of_features)
print("%d个变量的准确率为: %f" % (num_of_features, high_score))output
最优的变量是: 10个
10个变量的准确率为: 0.663581从上面的结果可以看出10个变量对于整个模型来说是最优的,然后我们来看一下到底是哪10个特征变量
cols = list(X.columns)
model = LinearRegression()
# 初始化RFE模型,筛选出10个变量
rfe_model = RFE(model, 10)
X_rfe = rfe.fit_transform(X,y)
# 拟合训练模型
model.fit(X_rfe,y)
df = pd.Series(rfe.support_,index = cols)
selected_features = df[df==True].index
print(selected_features)output
Index(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'DIS', 'RAD', 'PTRATIO','LSTAT'],dtype='object')正则化
例如对于Lasso的正则化而言,对于不相关的特征而言,该算法会让其相关系数变为0,因此不相关的特征变量很快就会被排除掉了,只剩下相关的特征变量
lasso = LassoCV()
lasso.fit(X, y)
coef = pd.Series(lasso.coef_, index = X.columns)然后我们看一下哪些变量的相关系数是0
print("Lasso算法挑选了 " + str(sum(coef != 0)) + " 个变量,然后去除掉了" + str(sum(coef == 0)) + "个变量")output
Lasso算法挑选了10个变量,然后去除掉了3个变量我们来对计算出来的相关性系数排个序并且做一个可视化
imp_coef = coef.sort_values()
matplotlib.rcParams['figure.figsize'] = (8, 6)
imp_coef.plot(kind = "barh")
plt.title("Lasso Model Feature Importance")output
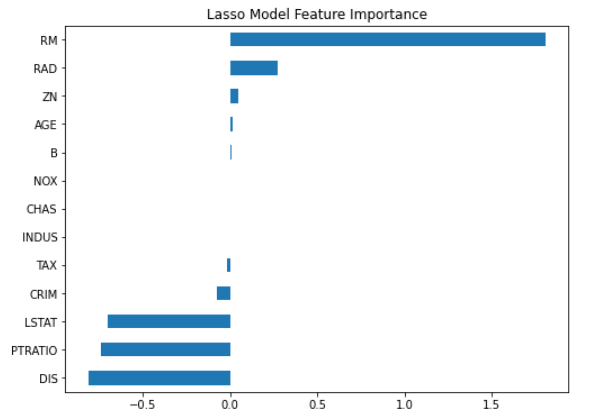
可以看到当中有3个特征,‘NOX’、'CHAS'、'INDUS'的相关性为0
根据缺失值来进行判断
下面我们来看一下如何针对离散型的特征变量来做处理,首先我们可以根据缺失值的比重来进行判断,要是对于一个离散型的特征变量而言,绝大部分的值都是缺失的,那这个特征变量也就没有存在的必要了,我们可以针对这个思路在进行判断。
首先导入所需要用到的数据集
train = pd.read_csv("credit_example.csv")
train_labels = train['TARGET']
train = train.drop(columns = ['TARGET'])我们可以先来计算一下数据集当中每个特征变量缺失值的比重
missing_series = train.isnull().sum() / train.shape[0]
df = pd.DataFrame(missing_series).rename(columns = {'index': '特征变量', 0: '缺失值比重'})
df.sort_values("缺失值比重", ascending = False).head()output
缺失值比重
COMMONAREA_AVG 0.6953
COMMONAREA_MODE 0.6953
COMMONAREA_MEDI 0.6953
NONLIVINGAPARTMENTS_AVG 0.6945
NONLIVINGAPARTMENTS_MODE 0.6945我们可以看到缺失值最高的比重将近有70%,我们也可以用可视化的根据来绘制一下缺失值比重的分布图
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.figure(figsize = (7, 5))
plt.hist(df['缺失值比重'], bins = np.linspace(0, 1, 11), edgecolor = 'k', color = 'blue', linewidth = 2)
plt.xticks(np.linspace(0, 1, 11));
plt.xlabel('缺失值的比重', size = 14);
plt.ylabel('特征变量的数量', size = 14);
plt.title("缺失值分布图", size = 14);output
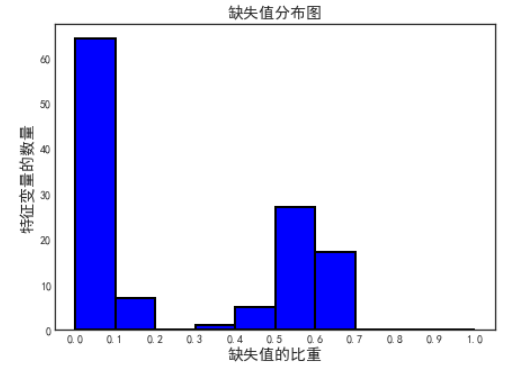
我们可以看到有一部分特征变量,它们缺失值的比重在50%以上,有一些还在60%以上,我们可以去除掉当中的部分特征变量
计算特征的重要性
在基于树的众多模型当中,会去计算每个特征变量的重要性,也就是feature_importances_属性,得出各个特征变量的重要性程度之后再进行特征的筛选
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
# 模型拟合数据
clf.fit(X,Y)
feat_importances = pd.Series(clf.feature_importances_, index=X.columns)
# 筛选出特征的重要性程度最大的10个特征
feat_importances.nlargest(10)我们同时也可以对特征的重要性程度进行可视化,
feat_importances.nlargest(10).plot(kind='barh', figsize = (8, 6))output
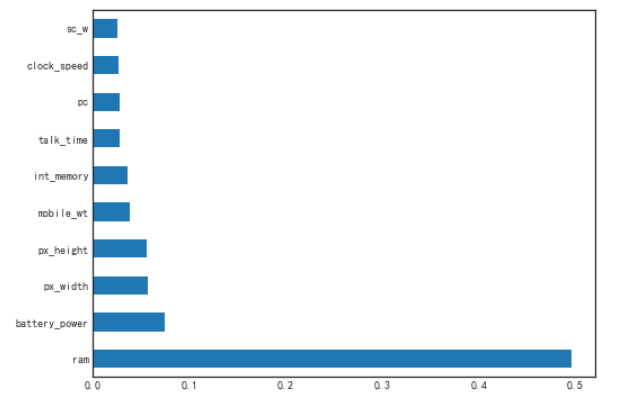
除了随机森林之外,基于树的算法模型还有很多,如LightGBM、XGBoost等等,大家也都可以通过对特征重要性的计算来进行特征的筛选
Select_K_Best算法
在Sklearn模块当中还提供了SelectKBest的API,针对回归问题或者是分类问题,我们挑选合适的模型评估指标,然后设定K值也就是既定的特征变量的数量,进行特征的筛选。
假定我们要处理的是分类问题的特征筛选,我们用到的是iris数据集
iris_data = load_iris()
x = iris_data.data
y = iris_data.targetprint("数据集的行与列的数量: ", x.shape)output
数据集的行与列的数量: (150, 4)对于分类问题,我们采用的评估指标是卡方,假设我们要挑选出3个对于模型最佳性能而言的特征变量,因此我们将K设置成3
select = SelectKBest(score_func=chi2, k=3)
# 拟合数据
z = select.fit_transform(x,y)
filter_1 = select.get_support()
features = array(iris.feature_names)
print("所有的特征: ", features)
print("筛选出来最优的特征是: ", features[filter_1])output
所有的特征: ['sepal length (cm)' 'sepal width (cm)' 'petal length (cm)''petal width (cm)']
筛选出来最优的特征是: ['sepal length (cm)' 'petal length (cm)' 'petal width (cm)']那么对于回归的问题而言,我们可以选择上面波士顿房价的例子,同理我们想要筛选出对于模型最佳的性能而言的7个特征变量,同时对于回归问题的评估指标用的是f_regression
boston_data = load_boston()
x = boston_data.data
y = boston_data.target然后我们将拟合数据,并且进行特征变量的筛选
select_regression = SelectKBest(score_func=f_regression, k=7)
z = select_regression.fit_transform(x, y)filter_2 = select_regression.get_support()
features_regression = array(boston_data.feature_names)print("所有的特征变量有:")
print(features_regression)print("筛选出来的7个特征变量则是:")
print(features_regression[filter_2])output
所有的特征变量有:
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO''B' 'LSTAT']
筛选出来的7个特征变量则是:
['CRIM' 'INDUS' 'NOX' 'RM' 'TAX' 'PTRATIO' 'LSTAT']

往
期
回
顾
直播
TeaTalk 线上直播倒计时
资讯
人工智能监考VS传统方式监考
资讯
Meta研发触觉手套助力元宇宙
资讯
自动驾驶图书馆,热爱阅读的er

分享

点收藏

点点赞

点在看
相关文章:
徒手撸出一个类Flask微框架(三)根据业务进行路由分组
所谓分组就是按照前缀分布映射如:/product/(\w)/(?P<id>\d # 匹配/product/123123 的前缀比如什么类别,类别下的什么产品 等,用request path进行正则匹配,所以需要用到正则分组分析我们当前代码,只有__…

TCP编程函数和步骤
TCP编程的服务器端一般步骤是1、 创建一个socket,用函数socket();2、 设置socket属性,用函数setsockopt(); * 可选3、 绑定IP地址、端口等信息到socket上,用函数bind();4、 开启监听,用函数listen();5、 接…
OSD的主要实现方法和类型(转)
源:OSD的主要实现方法和类型 目前有两种主要的OSD实现方法:外部OSD发生器与视频处理器间的叠加合成;视频处理器内部 支持OSD,直接在视频缓存内部叠加OSD信息。 外部OSD发生器与视频处理器间的叠加合成的实现原理是:由一个MCU内建的…

为什么要研究游戏 AI 呢?
作者 | 叶鑫来源 | DatawhaleAI作为时下计算机算法的超级巨星,在例如CV、NLP、语音、机器人等诸多领域都有广泛的应用。而在游戏领域,AI的应用往往被认为只是把游戏角色拟人化,算法的第一印象也通常是强化学习。但实际当中,AI在游…
oracle 工具:tkprof
https://docs.oracle.com/cd/B10501_01/server.920/a96533/ex_plan.htm http://blog.csdn.net/dba_waterbin/article/details/8010629 oracle sql执行计划怎么看 https://zhidao.baidu.com/question/1178766860347033659.html
Linux环境编程--文件基本操作
Linux 下目录是/这样的 而windows是\怎么记呢?\和w是不是一样的反向?所以Linux的目录就是反的反向,好记了。 一:open函数名称:open目标:打开一个文件。头文件:#include <sys/types.h>#in…

Firefox插件
为什么80%的码农都做不了架构师?>>> 网站优化必备的9个Firefox插件 在网页设计制作中经常使用到的火狐浏览器插件工具: 1. Firebug Firebug是开发人员们钟爱火狐浏览器的一个重要原因,Firebug是火狐浏览器上一个集成式的强大调试…

马斯克公开支持“上班摸鱼”:让工作更愉快!
整理 | 王晓曼出品 | 程序人生 (ID:coder _life)11月16日,在国美集团批评员工上班摸鱼的通报中,一名员工在网易云音乐上使用了22.5G的流量格外显眼。11月18日,网易云音乐也紧跟热点上线了摸鱼计算器活动&am…

瀚思首发三款产品 推动大数据安全战略布局
安全已成为了当下社会最为关注的几个问题之一,随着大数据时代的来临,如今的安全问题也变得严峻和复杂。近日,HanSight瀚思在北京召开了产品战略暨融资发布会,推出了瀚思用户行为分析系统(HanSight UBA)、瀚…
Linux环境编程--编辑器基本操作
vim使用 新建文件 #vim hello.c 插入模式 按下I键,底下出现- - 插入- - 换行:按下Enter 删除字符:普通模式下按x 删除整行:按dd 恢复删除:按u 取消命令: CtrlR 对U后果弥补 复制:y y2w复制2个…

2021 IDEA大会开启AI思想盛宴,用“创业精神”做科研
11月22日上午10时许,由深圳市福田区人民政府、深圳市福田区科技创新局和粤港澳大湾区数字经济研究院(International Digital Economy Academy, 简称“IDEA”)联合举办的2021 IDEA大会在深圳福田开幕。大会以“The World Needs a Few Good IDE…
Android不同分辨率和不同密度适配
官方原文地址:http://developer.android.com/training/multiscreen/screendensities.html 本文主要介绍: 1.dip dp sp 简单用法 2.适配不同分辨率屏幕图片的处理方法 支持不同的密度或分辨率 本课介绍如何通过提供不同的资源和使用的测量分辨率独立单元支…

网络工程师成长日记333-某城市政府项目
网络工程师成长日记333-某城市政府项目 这是我的第333篇原创文章,记录网络工程师行业的点点滴滴,结交IT行业有缘之人 直接上干货,拓扑图: 工程目的:排除故障配置如下:LinWei#show running-configBuilding c…

linux环境编程-- ftok()函数
系统建立IPC通讯(如消息队列、共享内存时)必须指定一个ID值。通常情况下,该id值通过ftok函数得到。 ftok原型如下: key_t ftok( char * fname, int id )fname就时你指定的文件名(该文件必须是存在而且可以访问的),id是…

使用 ChatterBot 库制作一个聊天机器人
作者 | 周萝卜来源 | 萝卜大杂烩我们学习一些如何使用 ChatterBot 库在 Python 中创建聊天机器人,该库实现了各种机器学习算法来生成响应对话,还是挺不错的1什么是聊天机器人聊天机器人也称为聊天机器人、机器人、人工代理等,基本上是由人工智…

powerDesign设计随笔
PowerDesigner的Table视图同时显示Code和Name的方法 实现方法:Tools-Display Preference powerDesigner设置 name不自动等于code 从数据库里抽取了数据模型,为了理清思路,需要将name改为中文名称,但是pd自动将name填充为code&…
Apache Kylin在绿城客户画像系统中的实践
前言\\作为国内知名的房地产开发商,绿城经过24年的发展,已为全国25万户、80万人营造了美丽家园,并将以“理想生活综合服务提供商”为目标,持续为客户营造高品质的房产品和生活服务。\\2017年,绿城理想生活集团成立&…
linux环境编程--IPC 之 msg queue
消息队列在UNIX的SystemV版本,AT&T引进了三种新形式的IPC功能(消息队列、信号量、以及共享内存)。但BSD版本的UNIX使用套接口作为主要的IPC形式。Linux系统同时支持这两个版本。系统调用msgget() 如果希望创建一个新的消息队列࿰…

2021 IDEA大会圆满落幕,一文回顾大会精彩看点
11月23日,为期两天的2021 IDEA大会在深圳福田圆满落幕。2021 IDEA大会由深圳市福田区人民政府、深圳市福田区科技创新局和粤港澳大湾区数字经济研究院(International Digital Economy Academy,简称“IDEA”)联合举办。深圳市科创委…
【转】Android下编译jni库的二种方法(含示例) -- 不错
原文网址:http://blog.sina.com.cn/s/blog_3e3fcadd01011384.html 总结如下:两种方法是:1)使用Android源码中的Make系统2)使用NDK(从NDK r5开始)---------------------------------源码要求&…
linux下如何修改系统时间
我们一般使用“date -s”命令来修改系统时间。比如将系统时间设定成2018年2月23日的命令如下。 #date -s 02/23/2018 将系统时间设定成下午11点12分0秒的命令如下。 #date -s 11:12:00 注意,这里说的是系统时间,是linux由操作系统维…

thttpd服务器
1 引言随着微处理器技术、计算机网络技术的进步,基于嵌入式WEB的网络数字视频监控系统逐渐得到了人们的广泛关注。把图像采集、视频压缩和WEB功能集中到一个体积很小的设备内,可以直接连入局域网和Internet,达到即插即用,省掉多种…

链接产业 聚变未来 | 移动云区块链开发者论坛来了
有人认为,如果说蒸汽机释放了人们的生产力,电力解决了人们基本的生活需求,互联网改变了信息传递的方式,那么区块链作为构造信任的机器,将可能改变整个人类社会价值传递的方式。区块链已走进大众视野,成为社…
Bzoj4016: [FJOI2014]最短路径树问题
题面 传送门 Sol 先\(SPFA\)求出单源最短路,\(Bfs\)建出树,字典序可以用堆解决 然后就是点分治的一眼题 开桶记录到当前根经过边长度相同的最长路,记录它的长度 自己强行\(yy\)了一个这种类型的点分丑陋写法 # include <bits/stdc.h> #…
libevent源码深度剖析
原文地址:http://blog.csdn.net/sparkliang/article/details/4957667libevent源码深度剖析一——序幕张亮1 前言 Libevent是一个轻量级的开源高性能网络库,使用者众多,研究者更甚,相关文章也不少。写这一系列文章的用意在于&#…

元宇宙中可跨语种交流!Meta 发布新语音模型,支持128种语言无障碍对话
编译 | 禾木木出品 | AI科技大本营(ID:rgznai100)语言交流是人类互动一种自然的方式,随着语音技术的发展,我们可以与设备以及未来的虚拟世界进行互动,由此虚拟体验将于我们的现实世界融为一体。然而,语音技…
前端面试官,我为什么讨厌你。
近两年来,参加过的前端面试不下二十场了,吐槽一下。我所经历的,都是小公司,大公司的同学请无视。 招聘信息能否不要装逼?写一大堆你项目根本用不上的,来给谁看?我曾遇到上面写了一堆对js如何要求…

【ASP.NET Core】解决“The required antiforgery cookie xxx is not present”的错误
当你在页面上用 form post 内容时,可能会遇到以下异常: The required antiforgery cookie "????????" is not present. 咱们来重现一下错误。新建一个 ASP.NET Core 项目,模板选【空】就行了,这是老周最喜欢的项…
linux系统级别的能够打开的文件句柄的数file-max命令
简单的说, max-file表示系统级别的能够打开的文件句柄的数量, 而ulimit -n控制进程级别能够打开的文件句柄的数量.man 5 proc, 找到file-max的解释:file-max中指定了系统范围内所有进程可打开的文件句柄的数量限制(系统级别, kernel-level). (The value …

这封以数字构写的蓝图,正在实现笔尖所触即世界
作者 | 贾凯强出品 | AI科技大本营(ID:rgznai100)一撇一捺,一勾一抹,笔走龙蛇,可见真意。笔者小时候字迹潦草,便总是抱怨为什么一定要写字好看?而如今计算机统治了世界,键盘和鼠标早…