太好玩了,爬虫、部署API、加小程序,一条龙玩转知乎热榜!

作者 | 周萝卜
来源 | 萝卜大杂烩
一直想做一个从爬虫到数据处理,到API部署,再到小程序展示的一条龙项目,最近抽了些时间,实现了一个关于知乎热榜的,今天就来分享一下!
数据爬取
首先我们看下需要爬取的知乎热榜
https://www.zhihu.com/billboard
这个热榜可以返回50条热榜数据,而这些数据都是通过页面的一个 JavaScript 返回的
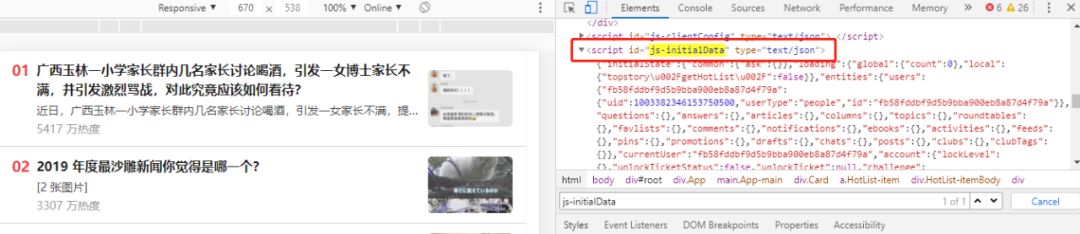
于是我们就可以通过解析这段 JS 代码来获取对应数据
url = 'https://www.zhihu.com/billboard'
headers = {"User-Agent": "", "Cookie": ""}def get_hot_zhihu():res = requests.get(url, headers=headers)content = BeautifulSoup(res.text, "html.parser")hot_data = content.find('script', id='js-initialData').stringhot_json = json.loads(hot_data)hot_list = hot_json['initialState']['topstory']['hotList']return hot_list然后我们再点击一个热榜,查看下具体的热榜页面,我们一直向下下拉页面,并打开浏览器的调试板,就可以看到如下的一个请求
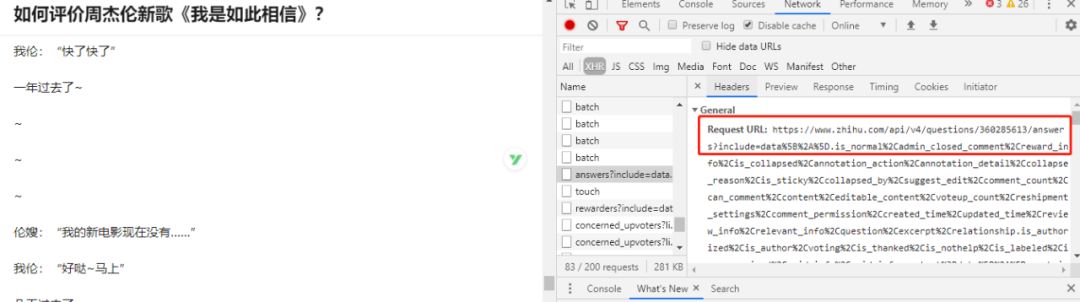
该接口返回了一个包含热榜回答信息的 json 文件,可以通过解析该文件来获取对应的回答
def get_answer_zhihu(id):url = 'https://www.zhihu.com/api/v4/questions/%s/answers?include=' % idheaders = {"User-Agent": "", "Cookie": ""}res = requests.get(url + Config.ZHIHU_QUERY, headers=headers)data_json = res.json()answer_info = []for i in data_json['data']:if 'paid_info' in i:continueanswer_info.append({'author': i['author']['name'], 'voteup_count': i['voteup_count'],'comment_count': i['comment_count'], 'content': i['content'],'reward_info': i['reward_info']['reward_member_count']})return answer_info数据存储
获取到数据之后,我们需要存储到数据库中,以便于后续使用。因为后面准备使用 Flask 来搭建 API 服务,所以这里存储数据的过程也基于 Flask 来做,用插件 flask_sqlalchemy。
定义数据结构
我们定义三张表,分别存储知乎热榜的详细列表信息,热榜的热度信息和热榜对应的回答信息
class ZhihuDetails(db.Model):__tablename__ = 'ZhihuDetails'id = db.Column(db.Integer, primary_key=True)hot_id = db.Column(db.String(32), unique=True, index=True)hot_name = db.Column(db.Text)hot_link = db.Column(db.String(64))hot_cardid = db.Column(db.String(32))class ZhihuMetrics(db.Model):__tablename__ = 'ZhihuMetrics'id = db.Column(db.Integer, primary_key=True)hot_metrics = db.Column(db.String(64))hot_cardid = db.Column(db.String(32), index=True)update_time = db.Column(db.DateTime)class ZhihuContent(db.Model):__tablename__ = 'ZhihuContent'id = db.Column(db.Integer, primary_key=True)answer_id = db.Column(db.Integer, index=True)author = db.Column(db.String(32), index=True)voteup_count = db.Column(db.Integer)comment_count = db.Column(db.Integer)reward_info = db.Column(db.Integer)content = db.Column(db.Text)定时任务
由于我们需要定时查询热榜列表和热榜的热度值,所以这里需要定时运行相关的任务,使用插件 flask_apscheduler 来做定时任务
我们的定时任务,涉及到了网络请求和数据入库的操作,把这部分定时任务代码单独拉出来,在 Flask 项目的根目录下创建一个文件 apschedulerjob.py,由于在运行该文件时,是没有 Flask app 变量的,所以我们需要手动调用 app_context() 方法来创建 app 上下文
def opera_db():with scheduler.app.app_context():
...当然,这里的 scheduler 变量是在 create_app 中初始化过的
from flask_apscheduler import APSchedulerscheduler = APScheduler()def create_app(config_name):app = Flask(__name__)app.config.from_object(config[config_name])config[config_name].init_app(app)db.init_app(app)scheduler.init_app(app)
...接着,我们就可以根据前面的两个爬虫函数,来分别入库数据了
入库热榜热度数据
update_metrics = ZhihuMetrics(hot_metrics=i['target']['metricsArea']['text'],hot_cardid=i['cardId'],update_time=datetime.datetime.now())入库热榜列表数据
new_details = ZhihuDetails(hot_id=i['id'], hot_name=i['target']['titleArea']['text'],hot_link=i['target']['link']['url'], hot_cardid=i['cardId'])入库热榜回答数据
new_content = ZhihuContent(answer_id=answer_id, author=answer['author'], voteup_count=answer['voteup_count'],comment_count=answer['comment_count'], reward_info=answer['reward_info'],content=answer['content'])最后我们就可以在 Flask 的入口程序中启动定时任务了
import os
from app import create_app, schedulerapp = create_app(os.getenv('FLASK_CONFIG') or 'default')if __name__ == '__main__':scheduler.start()app.run(debug=True)编写 API
热榜列表 API
我们首先来做热榜列表的接口,在数据库表 ZhihuMetrics 中拿到当天热榜的最新热度信息,然后再根据热榜热度信息来获取对应的列表信息,可以总结到如下的一个函数中
def zhihudata():current_time = '%s-%s-%s 00:00:00' % (datetime.now().year, datetime.now().month, datetime.now().day,)zhihumetrics_data = ZhihuMetrics.query.filter(ZhihuMetrics.update_time > current_time).group_by(ZhihuMetrics.hot_cardid).order_by(ZhihuMetrics.update_time).all()metrics_list = db_opera.db_to_list(zhihumetrics_data)details_list = []for d in metrics_list:zhihudetails_data = ZhihuDetails.query.filter_by(hot_cardid=d[1]).first()details_list.append([zhihudetails_data.hot_name, zhihudetails_data.hot_link, d[0], d[1], d[2]])return details_list接着定义一个视图函数返回 json 数据
@api.route('/api/zhihu/hot/')
def zhihu_api_data():zhihu_data = zhihudata()data_list = []for data in zhihu_data:data_dict = {'title': data[0], 'link': data[1], 'metrics': data[2], 'hot_id': data[3], 'update_time': data[4]}data_list.append(data_dict)return jsonify({'code': 0, 'content': data_list}), 200热榜详情 API
下面再来做热榜详情接口,该接口可以返回热榜热度走势信息,为前端画图提供数据。
def zhihudetail(hot_id):zhihumetrics_details = ZhihuMetrics.query.filter_by(hot_cardid=hot_id).order_by(ZhihuMetrics.update_time).all()Column = {'categories': [], 'series': [{'name': '热度走势', 'data': []}]}for i in zhihumetrics_details:Column['categories'].append(datetime.strftime(i.update_time, "%Y-%m-%d %H:%M"))Column['series'][0]['data'].append(int(i.hot_metrics.split()[0]))return Column@api.route('/api/zhihu/detail/<id>/')
def zhihu_api_detail(id):zhihu_detail = zhihudetail(id)return jsonify({'code': 0, 'data': zhihu_detail}), 200接入小程序
对于小程序端,我们这里使用了 uni-app 框架,这是一个可以一份代码多端运行的框架,还是比较不错的。
创建项目
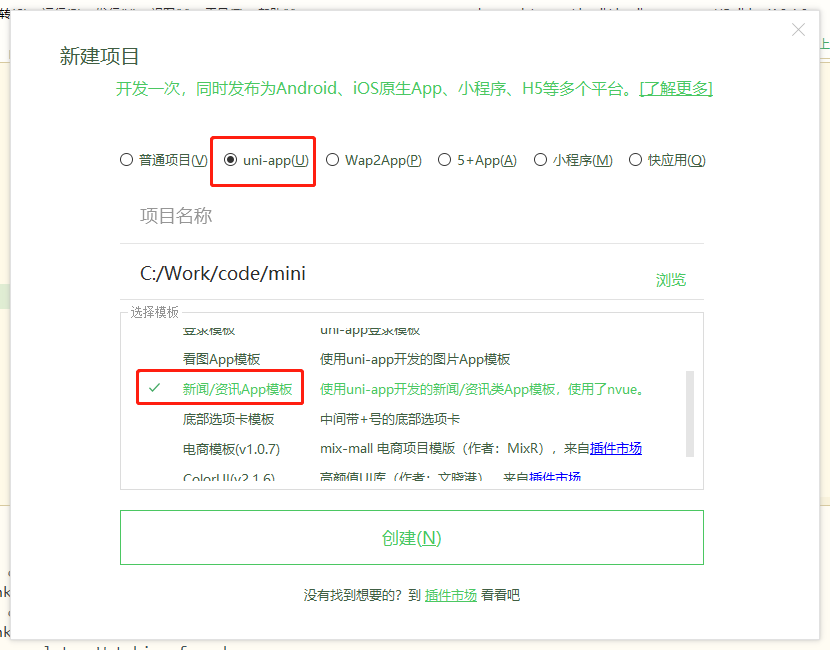
首先通过 IDE HBuilder 创建一个 uni-app 模板
改造项目
我们简单改造下该模板,首先修改下 index.nvue 文件,把 tabList 修改如下
data() {return {tabList: [{id: "tab01",name: '知乎热榜',newsid: 0}, {id: "tab02",name: '微博热榜',newsid: 23},我们暂时只保留两个 tab 页签,没错后面还要再做微博的热榜!
接下来打开 news-page.nvue 文件,修改网络请求地址
uni.request({url: 'http://127.0.0.1:5000/api/zhihu/hot/',data: '',把 URL 地址指向我们自己的 API 服务地址
然后再添加我们自己的新闻参数
hot_id: news.hot_id,
metrics: news.metrics,
news_url: news.link再修改函数 goDetail 如下
goDetail(detail) {if (this.navigateFlag) {return;}this.navigateFlag = true;uni.navigateTo({url: '/pages/detail/detail-new?query=' + encodeURIComponent(JSON.stringify(detail))});setTimeout(() => {this.navigateFlag = false;}, 200)},点击每条热榜时,就会跳转到 url 对应的 /pages/detail/detail-new 页面
引入 uCharts
下面编写 detail-new.nvue 文件,这里主要用到了 uni-app 的插件 uCharts。这是一个高性能的跨端图表插件,非常好用。
template 部分
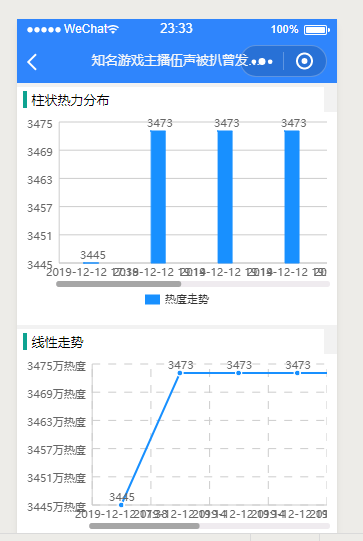
<template><view class="qiun-columns"><view class="qiun-bg-white qiun-title-bar qiun-common-mt" ><view class="qiun-title-dot-light">柱状热力分布</view></view><view class="qiun-charts" ><canvas canvas-id="canvasColumn" id="canvasColumn" class="charts" @touchstart="touchColumn"></canvas></view><view class="qiun-bg-white qiun-title-bar qiun-common-mt" ><view class="qiun-title-dot-light">线性走势</view></view><view class="qiun-charts" ><canvas canvas-id="canvasLine" id="canvasLine" class="charts" @touchstart="touchColumn"></canvas></view></view>
</template>创建两个 view,分别用于展示柱状图和折线图
再编写 script 部分
getServerData(){uni.request({url: 'http://127.0.0.1:5000/api/zhihu/detail/' + this.details.hot_id,data:{},success: function(res) {_self.serverData=res.data.data;let Column={categories:[],series:[]};Column.categories=res.data.data.categories;Column.series=res.data.data.series;_self.showColumn("canvasColumn",Column);_self.showLine("canvasLine",Column);},fail: () => {_self.tips="网络错误,小程序端请检查合法域名";},});}再根据 uCharts 的官方文档编写对应的展示图表函数
showColumn(canvasId,chartData){canvaColumn=new uCharts({$this:_self,canvasId: canvasId,type: 'column',legend:{show:true},fontSize:11,background:'#FFFFFF',pixelRatio:_self.pixelRatio,animation: true,categories: chartData.categories,series: chartData.series,enableScroll: true,xAxis: {disableGrid:true,scrollShow:true,itemCount:4,},yAxis: {//disabled:true},dataLabel: true,width: _self.cWidth*_self.pixelRatio,height: _self.cHeight*_self.pixelRatio,extra: {column: {type:'group',width: _self.cWidth*_self.pixelRatio*0.45/chartData.categories.length}}});}这样,我们就完成了基本的项目开发
我们可以到小程序的模拟器来查看效果啦
热榜列表页面
热榜详情页面
基本的效果是有了,不过还有很多需要优化的地方,下一次,我会分享出优化后的代码以及如何把 API 服务部署到云端,同时还是提供出供大家练习的 API,不要错过哦!


往
期
回
顾
资讯
活体人脑细胞5分钟学会打游戏
资讯
AI 技术大牛纷纷回归学术界
资讯
380万播放量,机器学习视频
技术
从深度学习到深度森林方法

分享

点收藏

点点赞

点在看
相关文章:

linux的more 命令
名称:more 使用权限:所有使用者 使用方式:more [-dlfpcsu] [-num] [/pattern] [linenum] [fileNames..] 说明:类似 cat ,不过会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(…
20155222卢梓杰 实验三 免杀原理与实践
实验三 免杀原理与实践 1.正确使用msf编码器,msfvenom生成如jar之类的其他文件,veil-evasion,自己利用shellcode编程等免杀工具或技巧 实验步骤如下 1.先对实验二中生成的exe进行检测 65款杀毒软件有36款认为不安全 39款杀毒软件有6款认为不安…
Linux wc命令详解
通常利用Linux的wc命令和其他命令结合来计算行和其他信息。在Linux下用wc进行计数。返回文件的行数、字数、字节数等。看个例子:wc wc1.txt3 5 16 wc1.txt输出信息依次是:行数 字数 字节数 文件名称。再具体点,单个统计。#wc -m filename&…
(剑指Offer)面试题54:表示数值的字符串
题目: 请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。例如,字符串"100","5e2","-123","3.1416"和"-1E-16"都表示数值。 但是"12e","1a3.14"…

「动手学深度学习」在B站火到没谁,加这个免费实操平台,妥妥天花板!
论 AI 圈活菩萨,非李沐老师莫属。前有编写「动手学深度学习」,成就圈内入门经典,后又在B站免费讲斯坦福 AI 课,一则艰深硬核讲论文的视频播放量36万,不少课题组从导师到见习本科生都在追番。如此给劲的分享,…
spring-redis-data的一个坑
事故原因: 运维报告redis内存直线上升,然后查询发现都是setrange操作,review代码,没法发现setrange操作 代码如下: redisTemplate.opsForValue().set(groupidxxxResult.getSeriesNo(), JSON.toJSONString(xxxRquestDTO…
Linux如何搜索文件的方法
#whereis 查找已经安装的软件 在Linux上查找某个文件是一件比较麻烦的事情。毕竟在Linux中需要我们使用专用的“查找”命令来寻找在硬盘上的文件。 Linux下的文件表达格式非常复杂,不象WINDOWS,DOS下都是统一的AAAAAAA.BBB格式 那么方便查找,在WINDOWS中…
python socket编程
python 编写server的步骤:1.第一步是创建socket对象。调用socket构造函数。如:socket socket.socket( family, type )family参数代表地址家族,可为AF_INET或AF_UNIX。AF_INET家族包括Internet地址,AF_UNIX家族用于同一台机器上的…
AI 语言模型真的是越大越好吗?这个模型优于 Gopher
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 近年来对于 AI 语言模型的有一个争议就是 —— 越大越好。 DeepMind 正在质疑这个理由,并表示给 AI 一个记忆可以帮助与它 25倍大小的模型竞争。 去年 6 月,OpenAI 发布 GPT-3 模…
[20180412]订阅+镜像切换
订阅镜像切换 主数据库挂了之后,镜像数据库没挂,那么就需要把镜像数据库设置成主数据库。1.修改主机名,改成和主数据库一样的,重启2.修改数据库中的主机名IF SERVERPROPERTY(ServerName)<>SERVERNAMEBEGINDECLARE srvname s…

【Cocos2d开发】Cocos2d下安卓环境的搭建
在进行Cocos2d游戏开发前 我们先来配置一下环境,我们先来准备一下工具,我们所需要的工具分别为:1.Cocos2d引擎2.JDK3.SDK4.NDK5.ANT6.ADT1.下载Cocos2d-x引擎,目前最新版本为3.6,本教程的所有例子以3.4版本为例&#x…
Linux时间转化方法
Linux时间转化方法:(1)date -d"2008年 12月 17日 星期三 17:27:22 CST" "%s"该命令将2008年 12月 17日 星期三 17:27:22 CST转化为时间戳结果:1229515680(2)将时间戳1123495443 换算成可以识别的年月日分秒date -d 1970-01-01 UTC 1123495443 s…

有的放矢,远程操控中实时音视频的优化之道
5G远程操控场景,对实时音视频传输的时延、卡顿率和抗弱网等指标都有着非常高的要求,本文将会介绍如何结合5G网络特点,在实时音视频通信链路中进行联合优化,满足行业场景远控需求,降低画面时延。 在上一篇文章中&#x…

Quartz动态添加、修改和删除定时任务
2019独角兽企业重金招聘Python工程师标准>>> Quartz动态添加、修改和删除定时任务 转载于:https://my.oschina.net/haokevin/blog/1795161
Linux下运行run文件
必须到Linux下的终端,不能用远程命令 #chmod 755 文件名 #./文件名

第五届中国企业服务年会:洞见2022数智化的“光与火”
汇智聚能,一起点亮“高增长的下一步”。 在疫情防控与复工复产双重因素的带动下,企业数智化成为不确定环境中的确定项,“ABCD(人工智能、区块链、云计算、数据)X”引爆生产力、生产资料、生产关系和基础设施革命&#…
QTP连接oracle
2019独角兽企业重金招聘Python工程师标准>>> 首先,因为群里很多朋友说QTP连接oracle有点麻烦,我针对于连接oracle做一个完整的教程,希望需要学习的朋友都可以来看一下;具体方法如下: 1、无论是什么语言&am…
java子类对象和成员变量的隐写方法重写
1、子类继承的方法只能操作子类继承和隐藏的成员变量名字类新定义的方法可以操作子类继承和子类新生命的成员变量,但是无法操作子类隐藏的成员变量(需要适用super关键字操作子类隐藏的成员变量。) public class ChengYuanBianLing { publi…
Linux的cron和crontab定时任务
定时任务调用shell本地Windows写一个shell test.sh #!/bin/bashecho "Course Arrange Job runs well at: " date "%Y-%m-%d %H:%M:%S" >> /usr/www/wwwshell/www.txt 先在服务器执行看可不可以 注意需要 # dos2unix ./test.sh 再 # ./test.sh需要…

用AI创造可持续发展社会价值,第二届腾讯Light·公益创新挑战赛正式启动
12月23日,“创变者”2021年度腾讯Light论坛在厦门正式举办。在论坛上,由全国妇联宣传部指导,腾讯公司联合中国儿童中心主办,企鹅伴成长、腾讯华东总部、腾讯SSV创新办学实验室、企鹅爱地球、腾讯优图实验室、腾讯云AI、腾讯云微搭…
CSS3 @keyframes animate
2019独角兽企业重金招聘Python工程师标准>>> 1.keyframes定义和用法 通过 keyframes 规则,您能够创建动画。 创建动画的原理是,将一套 CSS 样式逐渐变化为另一套样式。 在动画过程中,您能够多次改变这套 CSS 样式。 以百分比来…

linux系统命令学习系列-文件和目录管理
复习上节内容:1. 定时执行任务命令crontab –e, crontab –l,crontab –r2. 作业:定义一个定时任务,每分钟向/tmp/test.txt文件输出hello worldcrontab –e*/1 * * * * echo ‘hello world’>>/tmp/test.txt本节我们来说一下文件和目录…

GPT-3再进化:通过浏览网页来提高事实准确率
作者 | OpenAI来源 | 数据实战派为了让 GPT-3 模型可以更准确地对开放式问题进行回答,研究人员使用了基于文本的网络浏览器对 GPT-3 进行微调。微调后的 WebGPT 模型可以对人类实时回答问题的方法进行学习,比如提交搜索、跟踪链接并上下滚动网页。研究人…
lamp-安装脚本-修订版2
#!/bin/bash #write by zhang_pc #at 2015.08.07 #apache2.4 php.5.4 mysql5.5 #脚本说明,如果脚本所在目录有源码包就用本地的,否则就从互联网下载APR_FILESapr-1.5.2.tar.gz APR_DIRapr-1.5.2 ARP_PRE/usr/local/apr APR_URLhttp://mirror.bit.edu.cn/…
Linux的rc.local自启动服务
linux有自己一套完整的启动体系,抓住了linux启动的脉络,linux的启动过程将不再神秘。本文中假设inittab中设置的init tree为:/etc/rc.d/rc0.d/etc/rc.d/rc1.d/etc/rc.d/rc2.d/etc/rc.d/rc3.d/etc/rc.d/rc4.d/etc/rc.d/rc5.d/etc/rc.d/rc6.d/e…
[日常] Go语言圣经-函数递归习题
练习 5.1: 修改findlinks代码中遍历n.FirstChild链表的部分,将循环调用visit,改成递归调用。 练习 5.2: 编写函数,记录在HTML树中出现的同名元素的次数。 练习 5.3: 编写函数输出所有text结点的内容。注意不…
Centos下安装mysql 总结
一、MySQL安装 Centos下安装mysql 请点开:http://www.centoscn.com/CentosServer/sql/2013/0817/1285.html 二、MySQL的几个重要目录 MySQL安装完成后不象SQL Server默认安装在一个目录,它的数据库文件、配置文件和命令文件分别在不同的目录,了解这些目录…
Linux下的Memcache安装(含libevent的安装)
Linux下Memcache服务器端的安装服务器端主要是安装memcache服务器端,目前的最新版本是 memcached-1.3.0 。下载:http://www.danga.com/memcached/dist/memcached-1.2.2.tar.gz另外,Memcache用到了libevent这个库用于Socket的处理,…
谷歌发布 RLDS,在强化学习生成、共享和使用数据集
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 大多数强化学习和序列决策算法都需要智能体与环境的大量交互生成训练数据,以获得最佳性能。这种方法效率很低,尤其是在很难做到这种交互的情况下,比如用真实的机器人…

浅谈 javascript 中的this绑定问题
javascript语言是在运行时前即进行编译的,而this的绑定也是在运行时进行绑定的。也就是说,this实际上是在函数被调用时候发生绑定的,它指向什么完全取决于函数在哪里被调用。1.默认绑定 例如直接在全局作用域下声明: var a2; console.log(this.a);在全局…