第3次翻译了 Pandas 官方文档,叒写了这一份R万字肝货操作!

作者 | 黄伟呢
来源 | 数据分析与统计学之美
今天,我继续为大家讲述Pandas如何实现R语言的相关操作。
由于 Pandas 旨在提供人们使用 R 进行的大量数据操作和分析功能,因此本页开始提供更详细的 R 语言及其与 Pandas 相关的许多第三方库的介绍。
与 R 和 CRAN 库相比,我们关心以下几点:
① 功能/灵活性:每个工具可以/不能做什么;
② 性能:操作的速度。硬数字/基准是可取的;
③ 易于使用:是一种更容易/更难使用的工具吗(鉴于并排代码比较,您可能必须对此做出判断);
此页面还为这些 R 包的用户提供了一些翻译指南。
要将 DataFrame 对象从 Pandas 传输到 R,一种选择是使用 HDF5 文件。
1. 快速参考
我们将从快速参考指南开始,将使用 dplyr 的一些常见 R 操作与 Pandas 等价配对。
① 查询、过滤、采样

R对列子范围 ( select(df, col1:col3) )的简写可以在 Pandas 中清晰地使用,如果您有列列表,例如 df[cols[1:3]] 或 df.drop(cols[1:3]),但按列名执行此操作有点麻烦。
② 排序
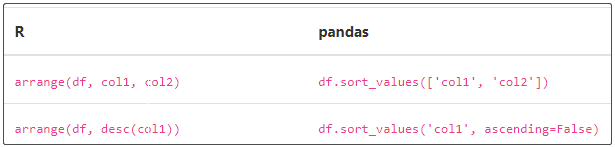
③ 转换
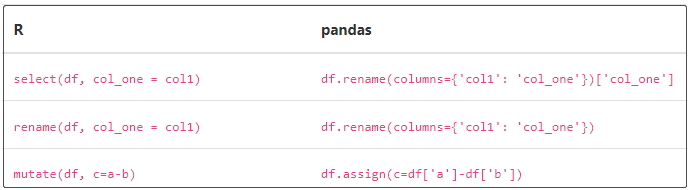
④ 分组和汇总

2. 基于R
① 用 R 的 c 切片
R 使得按名称访问 data.frame 列变得容易。
df <- data.frame(a=rnorm(5), b=rnorm(5), c=rnorm(5), d=rnorm(5), e=rnorm(5))
df[, c("a", "c", "e")]或按整数位置。
df <- data.frame(matrix(rnorm(1000), ncol=100))
df[, c(1:10, 25:30, 40, 50:100)]在 Pandas 中,按名称选择多列很简单。
df = pd.DataFrame(np.random.randn(10, 3), columns=list("abc"))
df[["a", "c"]]
df.loc[:, ["a", "c"]]结果如下:

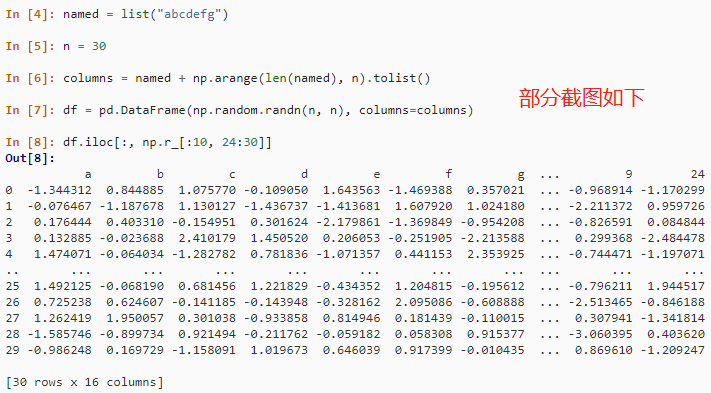
可以通过 iloc 索引器属性和 numpy.r_ 的组合,来实现按整数位置选择多个非连续列。
named = list("abcdefg")
n = 30
columns = named + np.arange(len(named), n).tolist()
df = pd.DataFrame(np.random.randn(n, n), columns=columns)
df.iloc[:, np.r_[:10, 24:30]]结果如下:
② aggregate
在 R 中,您可能希望将数据拆分为子集并计算每个子集的平均值。使用名为 df 的 data.frame 并将其分为 by1 和 by2 组。
df <- data.frame(v1 = c(1,3,5,7,8,3,5,NA,4,5,7,9),v2 = c(11,33,55,77,88,33,55,NA,44,55,77,99),by1 = c("red", "blue", 1, 2, NA, "big", 1, 2, "red", 1, NA, 12),by2 = c("wet", "dry", 99, 95, NA, "damp", 95, 99, "red", 99, NA, NA))
aggregate(x=df[, c("v1", "v2")], by=list(mydf2$by1, mydf2$by2), FUN = mean)groupby() 方法类似于基 R的聚合函数。
df = pd.DataFrame({"v1": [1, 3, 5, 7, 8, 3, 5, np.nan, 4, 5, 7, 9],"v2": [11, 33, 55, 77, 88, 33, 55, np.nan, 44, 55, 77, 99],"by1": ["red", "blue", 1, 2, np.nan, "big", 1, 2, "red", 1, np.nan, 12],"by2": ["wet","dry",99,95,np.nan,"damp",95,99,"red",99,np.nan,np.nan,]})
g = df.groupby(["by1", "by2"])
g[["v1", "v2"]].mean()结果如下:

③ match(%in%)
在 R 中选择数据的一种常用方法是使用 %in% ,它是使用函数 match 定义的。运算符 %in% 用于返回一个逻辑向量,指示是否存在匹配。
s <- 0:4
s %in% c(2,4)isin() 方法类似于 R %in% 运算符。
s = pd.Series(np.arange(5), dtype=np.float32)
s.isin([2, 4])结果如下:

match 函数在其第二个参数中,返回其第一个参数的匹配位置向量。
s <- 0:4
match(s, c(2,4))④ tapply
tapply类似于aggregate,但数据可以在一个参差不齐的数组中,因为子类的大小可能是不规则的。使用名为baseball的data.frame,并根据数组检索信息team。
baseball <-data.frame(team = gl(5, 5,labels = paste("Team", LETTERS[1:5])),player = sample(letters, 25),batting.average = runif(25, .200, .400))tapply(baseball$batting.average, baseball.example$team,max)在 Pandas 中,我们可以使用 pivot_table() 方法来处理这个。
import random
import stringbaseball = pd.DataFrame({"team": ["team %d" % (x + 1) for x in range(5)] * 5,"player": random.sample(list(string.ascii_lowercase), 25),"batting avg": np.random.uniform(0.200, 0.400, 25)})baseball.pivot_table(values="batting avg", columns="team", aggfunc=np.max)结果如下:

⑤ subset
query() 方法类似于基本的 R 子集函数。在 R 中,您可能想要获取 data.frame 的某些行,其中一列的值小于另一列的值。
df <- data.frame(a=rnorm(10), b=rnorm(10))
subset(df, a <= b)
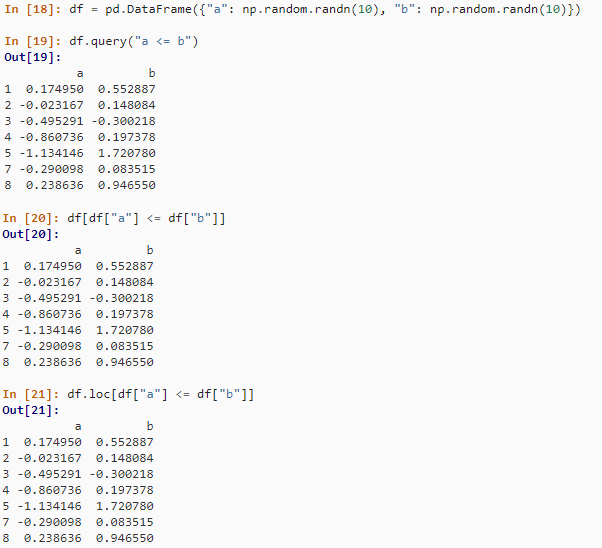
df[df$a <= df$b,]在 Pandas 中,有几种方法可以执行子集化。您可以使用 query() 或传递表达式,就好像它是索引/切片以及标准布尔索引一样。
df = pd.DataFrame({"a": np.random.randn(10), "b": np.random.randn(10)})
df.query("a <= b")
df[df["a"] <= df["b"]]
df.loc[df["a"] <= df["b"]]结果如下:
⑥ with
使用df在 R 中调用的带有列的 data.frame 的表达式a, b将使用with如下方式进行评估。
df <- data.frame(a=rnorm(10), b=rnorm(10))
with(df, a + b)
df$a + df$b在 Pandas 中,使用 eval() 方法的等效表达式为。
df = pd.DataFrame({"a": np.random.randn(10), "b": np.random.randn(10)})
df.eval("a + b")
df["a"] + df["b"]结果如下:
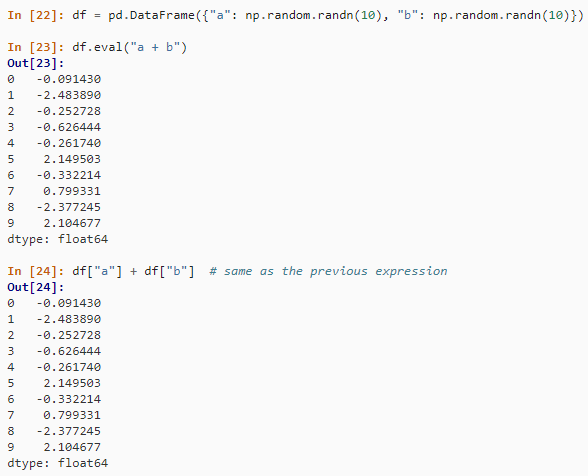
在某些情况下eval()会比纯 Python 中的评估快得多。
3. plyr库
plyr 是用于数据分析的拆分-应用-组合策略的 R 库。这些函数围绕 R 中的三个数据结构展开,a 代表数组,l 代表列表,d 代表 data.frame。下表显示了如何在 Python 中映射这些数据结构。
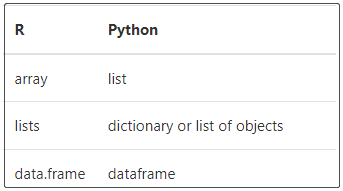
① ddply库
在 R 中使用名为 df 的 data.frame 的表达式,您要在其中按月汇总 x。
require(plyr)
df <- data.frame(x = runif(120, 1, 168),y = runif(120, 7, 334),z = runif(120, 1.7, 20.7),month = rep(c(5,6,7,8),30),week = sample(1:4, 120, TRUE)
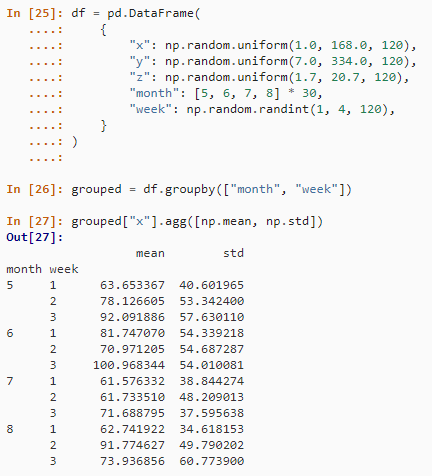
)ddply(df, .(month, week), summarize,mean = round(mean(x), 2),sd = round(sd(x), 2))在 Pandas 中,使用 groupby() 方法的等效表达式为。
df = pd.DataFrame({"x": np.random.uniform(1.0, 168.0, 120),"y": np.random.uniform(7.0, 334.0, 120),"z": np.random.uniform(1.7, 20.7, 120),"month": [5, 6, 7, 8] * 30,"week": np.random.randint(1, 4, 120)})grouped = df.groupby(["month", "week"])
grouped["x"].agg([np.mean, np.std])结果如下:
4. 重塑
① melt.array
使用 R 中称为 a 的 3 维数组的表达式,您希望将其融合到 data.frame 中。
a <- array(c(1:23, NA), c(2,3,4))
data.frame(melt(a))在 Python 中,由于 a 是一个列表,您可以简单地使用列表推导式。
a = np.array(list(range(1, 24)) + [np.NAN]).reshape(2, 3, 4)
pd.DataFrame([tuple(list(x) + [val]) for x, val in np.ndenumerate(a)])结果如下:

② melt.list
使用 R 中称为 a 的列表的表达式,您要将其融合到 data.frame 中。
a <- as.list(c(1:4, NA))
data.frame(melt(a))在 Python 中,此列表将是元组列表,因此 DataFrame() 方法会根据需要将其转换为数据帧。
a = list(enumerate(list(range(1, 5)) + [np.NAN]))
pd.DataFrame(a)结果如下:

③ melt.data.frame
在 R 中使用名为 cheese 的 data.frame 的表达式,您要在其中重塑 data.frame。
cheese <- data.frame(first = c('John', 'Mary'),last = c('Doe', 'Bo'),height = c(5.5, 6.0),weight = c(130, 150)
)
melt(cheese, id=c("first", "last"))在 Python 中,melt() 方法与 R 等效。
cheese = pd.DataFrame({"first": ["John", "Mary"],"last": ["Doe", "Bo"],"height": [5.5, 6.0],"weight": [130, 150]})pd.melt(cheese, id_vars=["first", "last"])
cheese.set_index(["first", "last"]).stack() # alternative way结果如下:

④ cast
在 R 中 acast 是一个表达式,它使用 R 中名为 df 的 data.frame 来转换为更高维数组。
df <- data.frame(x = runif(12, 1, 168),y = runif(12, 7, 334),z = runif(12, 1.7, 20.7),month = rep(c(5,6,7),4),week = rep(c(1,2), 6)
)mdf <- melt(df, id=c("month", "week"))
acast(mdf, week ~ month ~ variable, mean)在 Python 中,最好的方法是使用 pivot_table()。
df = pd.DataFrame({"x": np.random.uniform(1.0, 168.0, 12),"y": np.random.uniform(7.0, 334.0, 12),"z": np.random.uniform(1.7, 20.7, 12),"month": [5, 6, 7] * 4,"week": [1, 2] * 6}
)mdf = pd.melt(df, id_vars=["month", "week"])pd.pivot_table(mdf,values="value",index=["variable", "week"],columns=["month"],aggfunc=np.mean
)结果如下:

类似的 dcast 使用 R 中名为 df 的 data.frame 来聚合基于 Animal 和 FeedType 的信息。
df <- data.frame(Animal = c('Animal1', 'Animal2', 'Animal3', 'Animal2', 'Animal1','Animal2', 'Animal3'),FeedType = c('A', 'B', 'A', 'A', 'B', 'B', 'A'),Amount = c(10, 7, 4, 2, 5, 6, 2)
)dcast(df, Animal ~ FeedType, sum, fill=NaN)
# Alternative method using base R
with(df, tapply(Amount, list(Animal, FeedType), sum))Python 可以通过两种不同的方式来解决这个问题。首先,类似于上面使用pivot_table()。
df = pd.DataFrame({"Animal": ["Animal1","Animal2","Animal3","Animal2","Animal1","Animal2","Animal3",],"FeedType": ["A", "B", "A", "A", "B", "B", "A"],"Amount": [10, 7, 4, 2, 5, 6, 2]})df.pivot_table(values="Amount", index="Animal", columns="FeedType", aggfunc="sum")结果如下:

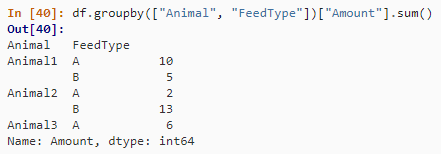
第二种方法是使用 groupby() 方法。
df.groupby(["Animal", "FeedType"])["Amount"].sum()结果如下:
⑤ factor
pandas 具有用于分类数据的数据类型。
cut(c(1,2,3,4,5,6), 3)
factor(c(1,2,3,2,2,3))在Pandas中,这是通过 pd.cut 和 astype("category") 完成的。
pd.cut(pd.Series([1, 2, 3, 4, 5, 6]), 3)
pd.Series([1, 2, 3, 2, 2, 3]).astype("category")结果如下:


往
期
回
顾
技术
用python写3D游戏,太赞了
资讯
算力超越iPhone,芯片堪比Mac
技术
31个好用的Python字符串方法
资讯
GPT-3平替版语言模型,性能更优化

分享

点收藏

点点赞

点在看
相关文章:

PHP autoload机制详解
PHP autoload机制详解 转载自 jeakcccPHP autoload机制详解(1) autoload机制概述在使用PHP的OO模式开发系统时,通常大家习惯上将每个类的实现都存放在一个单独的文件里,这样会很容易实现对类进行复用,同时将来维护时也很便利。这 也是OO设计…
有关博客的一些断想
作者:朱金灿来源:http://blog.csdn.net/clever101随着微博、微信等短平快社交媒体的兴起,文字相对严肃的博客毫无疑问受到很大的冲击。我在想博客会不会因此而消亡呢。我相信不会,因为喜欢轻快的文字固然是人类的天性,…
pythonl学习笔记——爬虫的基本常识
1 robots协议 Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。 如: …

hibernate相关收集
2019独角兽企业重金招聘Python工程师标准>>> 1、Hibernate SQL方言 如果出现如下错误,则可能是Hibernate SQL方言 (hibernate.dialect)设置不正确。 Caused by: java.sql.SQLException: [Microsoft][SQLServer 2000 Driver for JDBC][SQLServer]last_ins…

盘一盘 2021 年程序员们喜欢的网站数据
作者 | 周萝卜来源 | 萝卜大杂烩世界上流量最大的网站有哪些,也许我们都能脱口而出,比如 Google,YouTube,Facebook 还有 PxxnHub 等等,今天我们就通过多个维度来看看,那些叱咤全球的流量网站!数…
烽火18台系列之十一:刚需中的刚需——网站篡改监控
网站篡改事件近些年来越演越烈,其中包括政府、教育、金融、事业企业单位等。根据国家互联网应急响应中心发布的《2015年中国互联网网络安全报告》中指出,“2015年CNCERT/CC工检测到境内被篡改的网站数量为24550个,其中境内政府网站篡改数量为…
Http与RPC通信协议的比较
OSI网络结构的七层模型 各层的具体描述如下:第七层:应用层 定义了用于在网络中进行通信和数据传输的接口 - 用户程式;提供标准服务,比如虚拟终端、文件以及任务的传输 和处理; 第六层:表示层 掩…

基于 Python 和 OpenCV 构建智能停车系统
作者 | 努比来源 | 小白学视觉当今时代最令人头疼的事情就是找不到停车位,尤其是找20分钟还没有找到停车位。根据复杂性和效率的不同,任何问题都具有一个或多个解决方案。目前智能停车系统的解决方案,主要包括基于深度学习实现,以…
js获取鼠标位置
1.PageX/PageX:鼠标在页面上的位置,从页面左上角开始,即是以页面为参考点,不随滑动条移动而变化2.clientX/clientY:鼠标在页面上可视区域的位置,从浏览器可视区域左上角开始,即是以浏览器滑动条此刻的滑动到的位置为参考点,随滑动条移动 而变化. 可是悲剧的是,PageX只有FF…
Lua保留指定小数位数
默认会四舍五入 比如:%0.2f 会四舍五入后,保留小数点后2位print(string.format("%.1f",0.26)) ---会输出0.3,而不是0.2 Lua保留一位小数 --- nNum 源数字 --- n 小数位数 function Tool. GetPreciseDecimal(nNum, n)if type(nNum)…
htaccess文件用法收集整理
1.时区设置有些时候,当你在PHP里使用date或mktime函数时,由于时区的不同,它会显示出一些很奇怪的信息。下面是解决这个问题的方法之一。就是设置你的服务器的时区。你可以在这里找到所有支持的时区的清单。 1.SetEnv TZ Australia/Melbourne …

手把手教你使用 YOLOV5 训练目标检测模型
作者 | 肆十二来源 | CSDN博客这次要使用YOLOV5来训练一个口罩检测模型,比较契合当下的疫情,并且目标检测涉及到的知识点也比较多。先来看看我们要实现的效果,我们将会通过数据来训练一个口罩检测的模型,并用pyqt5进行封装&#x…

数据仓库数据模型之:极限存储--历史拉链表
摘要: 在数据仓库的数据模型设计过程中,经常会遇到文内所提到的这样的需求。而历史拉链表,既能满足对历史数据的需求,又能很大程度的节省存储资源。在数据仓库的数据模型设计过程中,经常会遇到这样的需求:1. 数据量比较…
super的用法(带了解)
super的用法(带了解) super的用法(带了解)posted on 2018-05-11 21:31 leolaosao 阅读(...) 评论(...) 编辑 收藏 转载于:https://www.cnblogs.com/leolaosao/p/9026686.html
Posted content type isn't multipart/form-data
版权声明:欢迎转载,请注明沉默王二原创。 https://blog.csdn.net/qing_gee/article/details/48712507 在有文件上传的表单提交过程中,搞不好就会报Posted content type isnt multipart/form-data的错误。 解决办法 <form class"form-…

CSDN 十大技术主题盘点-AI篇
关于2021,我们能看到的技术变化有很多。当云原生向下而生,当分布式数据库席卷而至,当低代码平台扩展了开发的边界,当万物互联蔚然成风……我们看到了太多在2021年形成的变化,但也能看到这些趋势非但没有结束࿰…
PHP编程问题集锦
1. Win32下apache2用get方法传递中文参数会出错 test.php?a你好&b你也好传递参数是会导致一个内部错误解决办法:"test.php?a".urlencode(你好)."&b".urlencode(你也好)2. win32下的session不能正常工作 php.ini默认的session.save_path /tmp 这…

jsonp详解
json相信大家都用的多,jsonp我就一直没有机会用到,但也经常看到,只知道是“用来跨域的”,一直不知道具体是个什么东西。今天总算搞明白了。下面一步步来搞清楚jsonp是个什么玩意。 同源策略 首先基于安全的原因,浏览器…
PHP面向对象精华
PHP面向对象精华1 使用extends实现继承以及重载、魔术方法的含义 class B extends A 声明的时候B里可以没有A里的方法 调用的时候$bnew B(); $b->A里的方法(); $b->A里的属性1; $b->B里的方法(); $b->B里的方法(); 如果$anew A(); 可以 $a->A里的方法(); $a->…

springmvc和mybatis整合关键配置
springmvcmybaits的系统架构: 第一步:整合dao层 mybatis和spring整合,通过spring管理mapper接口。 使用mapper的扫描器自动扫描mapper接口在spring中进行注册。 第二步:整合service层 通过spring管理 service接口。 使用配置方式将…

阿里亲制明信片,字节、百度直接发锅……这些公司的新年礼盒越来越会玩~
整理 | 王晓曼出品 | 程序人生(ID:coder _life)每到年末,各大互联网大厂的新年礼盒都会作为…
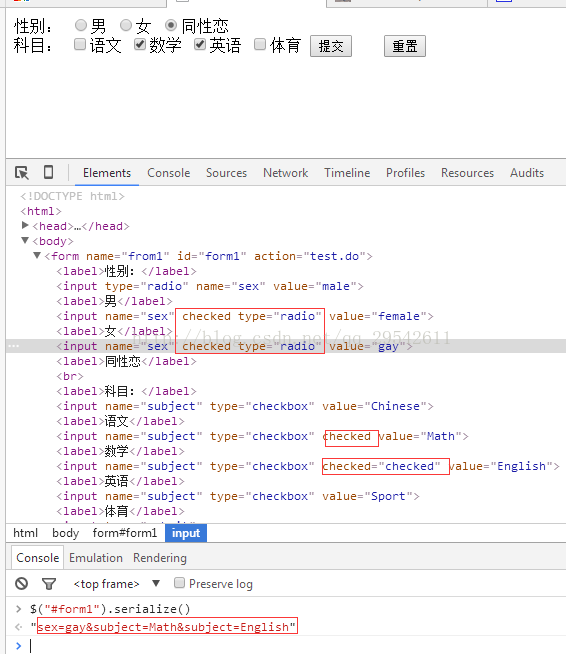
html中radio、checkbox选中状态研究(静下心来看,静下心来总结)
html中radio、checkbox选中状态研究(静下心来看,静下心来总结) 一、总结 1、单选框的如果有多个checked 会以最后一个为准 2、js动态添加checked属性:不行:通过 $("[namesex]:eq(1)").attr("checked&q…

新年新气象,100 行 Python 代码制作动态鞭炮
作者 | FrigidWinter来源 | CSDN博客放鞭炮贺新春,在我国有两千多年历史。关于鞭炮的起源,有个有趣的传说。西方山中有焉,长尺余,一足,性不畏人。犯之令人寒热,名曰年惊惮,后人遂象其形…
php 反射类简介
反射是操纵面向对象范型中元模型的API,其功能十分强大,可帮助我们构建复 杂,可扩展的应用。其用途如:自动加载插件,自动生成文档,甚至可用来扩充 PHP 语言。php 反射api 由若干类组成,可帮助我们…
shell时间
Shell 调用系统时间变量 Linux常用命令获取今天时期:date %Y%m%d 或 date %F 或 $(date %y%m%d) 获取昨天时期:date -d yesterday %Y%m%d 获取前天日期:date -d -2day %Y%m%d 依次类推比如获取10天前的日期:date -d -10day %Y%m%d…
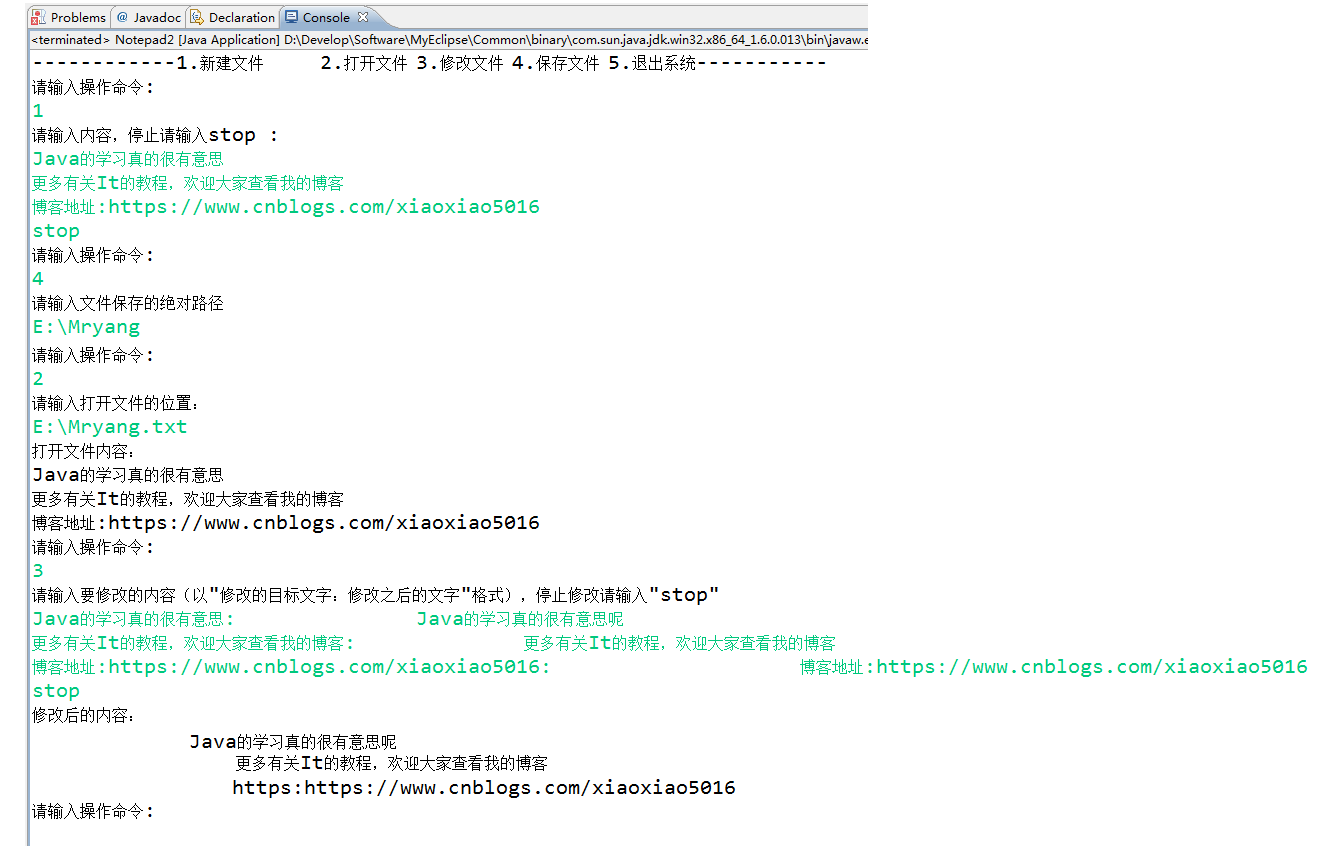
杨老师课堂_Java核心技术下之控制台模拟记事本案例...
预览效果图: 背景介绍: 编写一个模拟记事本的程序通过在控制台输入指令,实现在本地新建文件打开文件和修改文件等功能。 要求在程序中: 用户输入指令1代表“新建文件”,此时可以从控制台获取用户输入的文件内容&#x…
PHP的URL处理
完整URL地址: http://username:passwordhostname/path?argvalue#auchor 协议:http:// 用户名和密码: username:password 以:将两者分隔 主机名:hostname 和/为分隔符 路径: /path 以/开头、包含/符号 参…
UnitOfWork以及其在ABP中的应用
Unit Of Work(UoW)模式在企业应用架构中被广泛使用,它能够将Domain Model中对象状态的变化收集起来,并在适当的时候在同一数据库连接和事务处理上下文中一次性将对象的变更提交到数据中。 从字面上我们可以我们可以把UnitOfWork叫…

分享3个好用到爆的 Python 模块,点赞收藏
作者 | 俊欣来源 | 关于数据分析与可视化今天给大家介绍3个特别好用的Python模块,知道的人可能不多,但是特别的好用。PsutilPendulumPyfigletPsutilPython当中的Psutil模块是个跨平台库,它能够轻松获取系统运行的进程和系统利用率,…
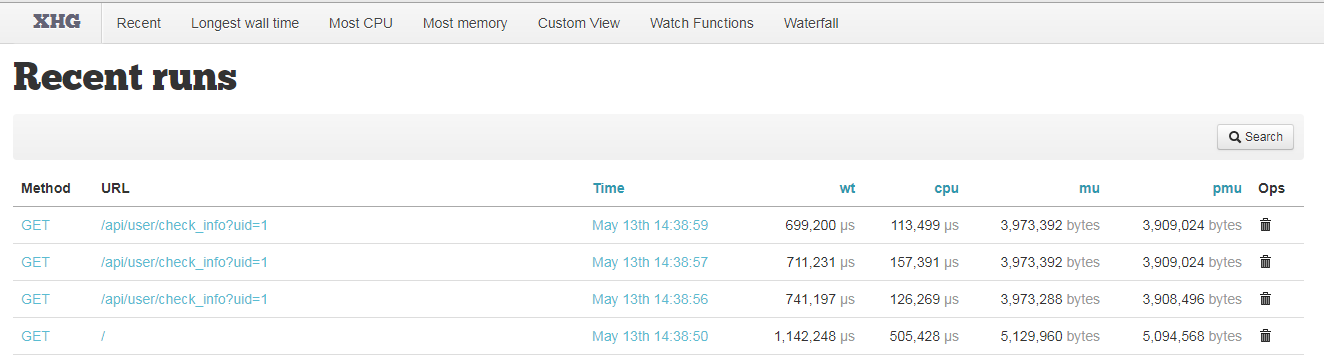
使用XHProf分析PHP性能瓶颈(二)
上一篇文章里,我们介绍了如何基于xhprof扩展来分析PHP性能,并记录到日志里,最后使用xhprof扩展自带的UI在web里展示出来。本篇文章将讲述2个知识点: 使用xhgui代替xhprof的默认UI界面,更便于分析使用tideways扩展替换x…