基于 OpenCV 的表格文本内容提取

作者 | 小白
来源 | 小白学视觉
小伙伴们可能会觉得从图像中提取文本是一件很麻烦的事情,尤其是需要提取大量文本时。PyTesseract是一种光学字符识别(OCR),该库提了供文本图像。
PyTesseract确实有一定的效果,用PyTesseract来检测短文本时,结果相当不错。但是,当我们用它来检测表格中的文本时,算法执行失败。
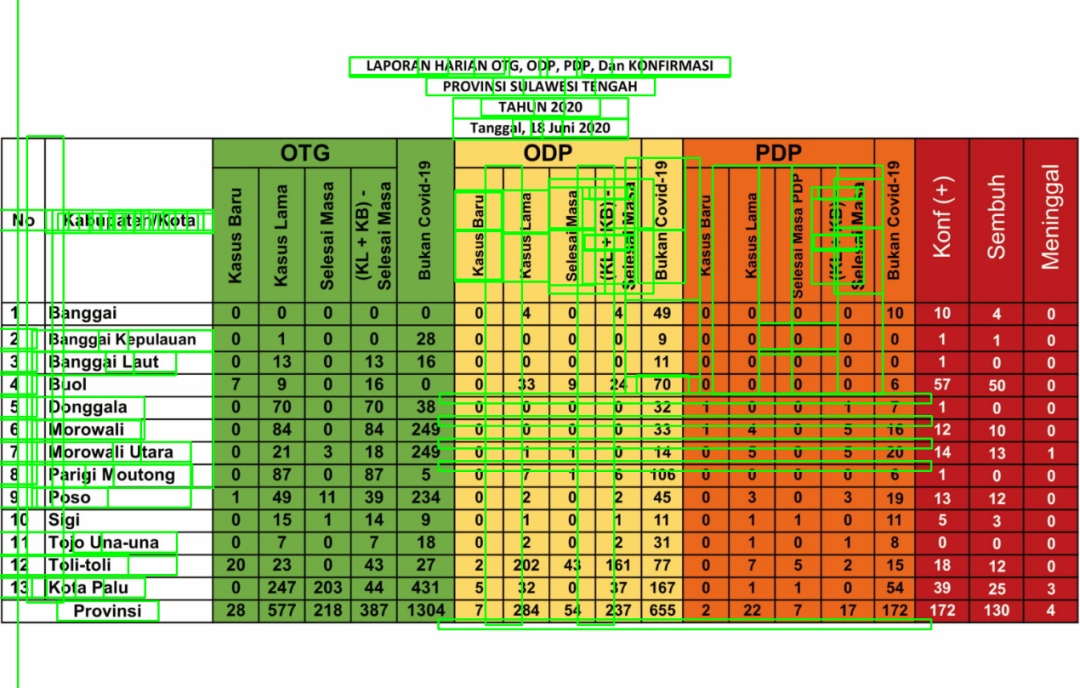
图1.直接使用PyTesseract检测表中的文本
图1描绘了文本检测结果,绿色框包围了检测到的单词。可以看出算法对于大部分文本都无法检测,尤其是数字。而这些数字却是展示了每日COVID-19病例的相关信息。那么,如何提取这些信息?
简介
在编写算法时,我们通常应该以我们人类理解问题的方式来编写算法。这样,我们可以轻松地将想法转化为算法。
当我们阅读表格时,首先注意到的就是单元格。一个单元格使用边框(线)与另一个单元格分开,边框可以是垂直的也可以是水平的。识别单元格后,我们继续阅读其中的信息。将其转换为算法,您可以将过程分为三个过程,即单元格检测、区域(ROI)选择和文本提取。
在执行每个任务之前,让我们先导入必要内容
import cv2 as cv
import numpy as np
filename = 'filename.png'
img = cv.imread(cv.samples.findFile(filename))
cImage = np.copy(img) #image to draw lines
cv.imshow("image", img) #name the window as "image"
cv.waitKey(0)
cv.destroyWindow("image") #close the window单元格检测
查找表格中的水平线和垂直线可能是最容易开始的。有多种检测线的方法,这里我们采用OpenCV库中的Hough Line Transform。
在应用霍夫线变换之前,需要进行一些预处理。第一是将存在的RGB图像转换为灰度图像。因为灰度图像对于Canny边缘检测而言非常重要。
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
cv.imshow("gray", gray)
cv.waitKey(0)
cv.destroyWindow("gray")
canny = cv.Canny(gray, 50, 150)
cv.imshow("canny", canny)
cv.waitKey(0)
cv.destroyWindow("canny")下面的两幅图分别显示了灰度图像和Canny图像。

图2.灰度和Canny图像
霍夫线变换
在OpenCV中,此算法有两种类型,即标准霍夫线变换和概率霍夫线变换。标准变换为我们提供直线方程,因此我们无法得知直线的起点和终点。概率变换将为我们提供线列表,即直线起点与终点的坐标值列表。我们优先选用的是概率变化。

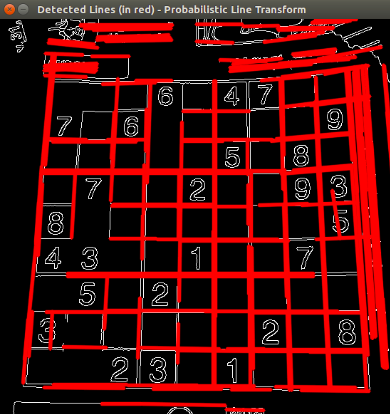
图3.霍夫线变换结果示例(来源:OpenCV)
对于HoughLinesP函数,有如下几个输入参数:
image -8位单通道二进制源图像。该图像可以通过该功能进行修改。
rho —累加器的距离分辨率,以像素为单位。
theta —弧度的累加器角度分辨率。
threshold-累加器阈值参数。仅返回那些获得足够投票的行
line — 线的输出向量。这里设置为无,该值保存到linesP
minLineLength —最小行长。短于此的线段将被拒绝。
maxLineGap —同一线上的点之间允许链接的最大间隙。
# cv.HoughLinesP(image, rho, theta, threshold[, lines[, minLineLength[, maxLineGap]]]) → lines
rho = 1
theta = np.pi/180
threshold = 50
minLinLength = 350
maxLineGap = 6
linesP = cv.HoughLinesP(canny, rho , theta, threshold, None, minLinLength, maxLineGap)为了区分水平线和垂直线,我们定义了一个函数并根据该函数的返回值添加列表。
def is_vertical(line):return line[0]==line[2]
def is_horizontal(line):return line[1]==line[3]
horizontal_lines = []
vertical_lines = []if linesP is not None:for i in range(0, len(linesP)):l = linesP[i][0]if (is_vertical(l)):vertical_lines.append(l)elif (is_horizontal(l)):horizontal_lines.append(l)
for i, line in enumerate(horizontal_lines):cv.line(cImage, (line[0], line[1]), (line[2], line[3]), (0,255,0), 3, cv.LINE_AA)for i, line in enumerate(vertical_lines):cv.line(cImage, (line[0], line[1]), (line[2], line[3]), (0,0,255), 3, cv.LINE_AA)cv.imshow("with_line", cImage)
cv.waitKey(0)
cv.destroyWindow("with_line") #close the window
图4.霍夫线变换结果—没有重叠滤波器
重叠滤波器
检测到的线如上图所示。但是,霍夫线变换结果中有一些重叠的线。较粗的线由多个相同位置,长度不同的线组成。为了消除此重叠线,我们定义了一个重叠过滤器。
最初,基于分类索引对线进行分类,水平线的y₁和垂直线的x₁。如果下一行的间隔小于一定距离,则将其视为与上一行相同的行。
def overlapping_filter(lines, sorting_index):filtered_lines = []lines = sorted(lines, key=lambda lines: lines[sorting_index])separation = 5for i in range(len(lines)):l_curr = lines[i]if(i>0):l_prev = lines[i-1]if ( (l_curr[sorting_index] - l_prev[sorting_index]) > separation):filtered_lines.append(l_curr)else:filtered_lines.append(l_curr)return filtered_lines实现重叠滤镜并在图像上添加文本,现在代码应如下所示:
horizontal_lines = []
vertical_lines = []if linesP is not None:for i in range(0, len(linesP)):l = linesP[i][0]if (is_vertical(l)): vertical_lines.append(l)elif (is_horizontal(l)):horizontal_lines.append(l)horizontal_lines = overlapping_filter(horizontal_lines, 1)vertical_lines = overlapping_filter(vertical_lines, 0)
for i, line in enumerate(horizontal_lines):cv.line(cImage, (line[0], line[1]), (line[2], line[3]), (0,255,0), 3, cv.LINE_AA)cv.putText(cImage, str(i) + "h", (line[0] + 5, line[1]), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1, cv.LINE_AA)
for i, line in enumerate(vertical_lines):cv.line(cImage, (line[0], line[1]), (line[2], line[3]), (0,0,255), 3, cv.LINE_AA)cv.putText(cImage, str(i) + "v", (line[0], line[1] + 5), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1, cv.LINE_AA)cv.imshow("with_line", cImage)
cv.waitKey(0)
cv.destroyWindow("with_line") #close the window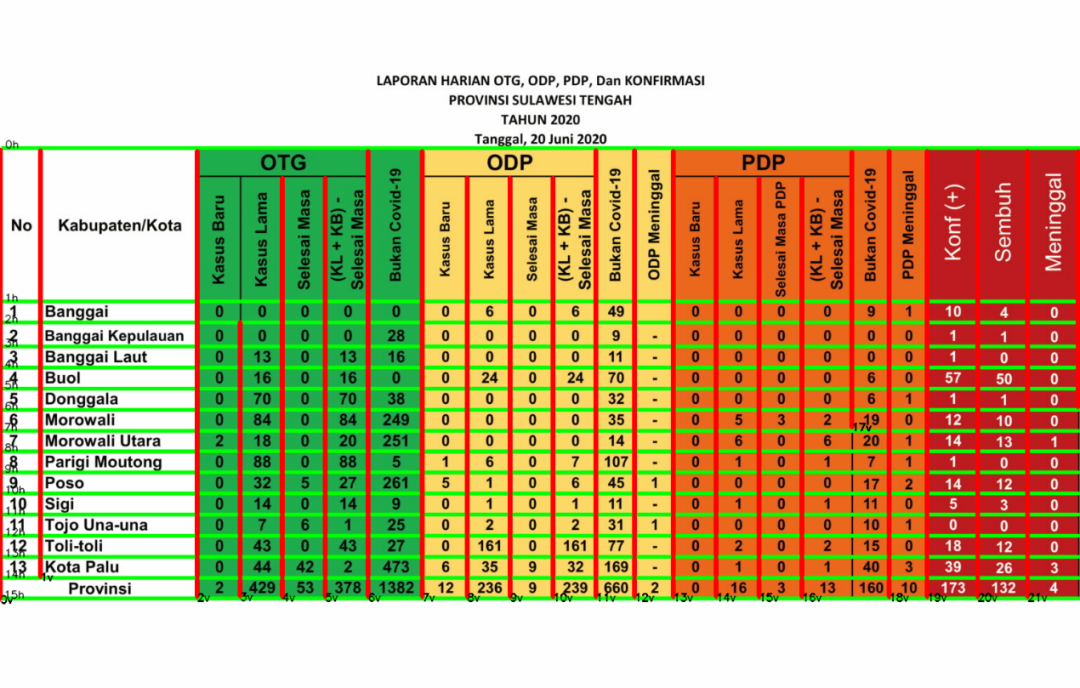
图5.霍夫线变换结果—带重叠滤波器
有了这个代码,就不会提取出重叠的行了。此外,我们还将在图像中写入水平和垂直线的索引,这将有利于ROI的选择。
ROI选择
首先,我们需要定义列数和行数。这里我们只对第二行第十四行以及所有列中的数据感兴趣。对于列,我们定义了一个名为关键字的列表,将其用于字典关键字。
## set keywords
keywords = ['no', 'kabupaten', 'kb_otg', 'kl_otg', 'sm_otg', 'ks_otg', 'not_cvd_otg','kb_odp', 'kl_odp', 'sm_odp', 'ks_odp', 'not_cvd_odp', 'death_odp','kb_pdp', 'kl_pdp', 'sm_pdp', 'ks_pdp', 'not_cvd_pdp', 'death_pdp','positif', 'sembuh', 'meninggal']dict_kabupaten = {}for keyword in keywords:dict_kabupaten[keyword] = []## set counter for image indexing
counter = 0## set line index
first_line_index = 1
last_line_index = 14然后,要选择ROI,我们定义了一个函数,该函数将图像(水平线和垂直线都作为输入)以及线索引作为边框。此函数返回裁剪的图像及其在图像全局坐标中的位置和大小
def get_cropped_image(image, x, y, w, h):cropped_image = image[ y:y+h , x:x+w ]return cropped_image
def get_ROI(image, horizontal, vertical, left_line_index, right_line_index, top_line_index, bottom_line_index, offset=4):x1 = vertical[left_line_index][2] + offsety1 = horizontal[top_line_index][3] + offsetx2 = vertical[right_line_index][2] - offsety2 = horizontal[bottom_line_index][3] - offsetw = x2 - x1h = y2 - y1cropped_image = get_cropped_image(image, x1, y1, w, h)return cropped_image, (x1, y1, w, h)裁剪的图像将用于下一个任务,即文本提取。返回的第二个参数将用于绘制ROI的边界框
文字提取
现在,我们定义了ROI功能。我们可以继续提取结果。我们可以通过遍历单元格来读取列中的所有数据。列数由关键字的长度指定,而行数则由定义。
首先,让我们定义一个函数来绘制文本和周围的框,并定义另一个函数来提取文本。
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
def draw_text(src, x, y, w, h, text):cFrame = np.copy(src)cv.rectangle(cFrame, (x, y), (x+w, y+h), (255, 0, 0), 2)cv.putText(cFrame, "text: " + text, (50, 50), cv.FONT_HERSHEY_SIMPLEX, 2, (0, 0, 0), 5, cv.LINE_AA)return cFrame
def detect(cropped_frame, is_number = False):if (is_number):text = pytesseract.image_to_string(cropped_frame,config ='-c tessedit_char_whitelist=0123456789 --psm 10 --oem 2')else:text = pytesseract.image_to_string(cropped_frame, config='--psm 10')return text将图像转换为黑白以获得更好的效果,让我们开始迭代!
counter = 0
print("Start detecting text...")
(thresh, bw) = cv.threshold(gray, 100, 255, cv.THRESH_BINARY)
for i in range(first_line_index, last_line_index):for j, keyword in enumerate(keywords):counter += 1left_line_index = jright_line_index = j+1top_line_index = ibottom_line_index = i+1cropped_image, (x,y,w,h) = get_ROI(bw, horizontal, vertical, left_line_index, right_line_index, top_line_index, bottom_line_index)if (keywords[j]=='kabupaten'):text = detect(cropped_image)dict_kabupaten[keyword].append(text)else:text = detect(cropped_image, is_number=True)dict_kabupaten[keyword].append(text)image_with_text = draw_text(img, x, y, w, h, text)问题解决
这是文本提取的结果!我们只选择了最后三列,因为它对某些文本给出了奇怪的结果,其余的很好,所以我不显示它。
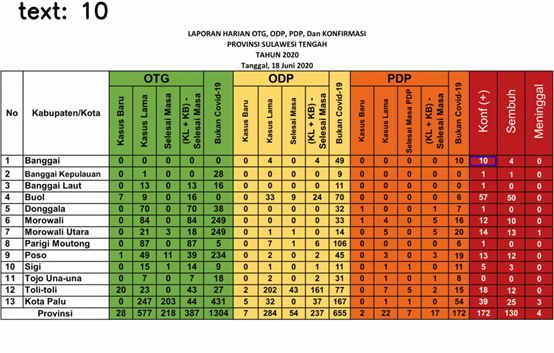
图6.检测到的文本—版本1
一些数字被检测为随机文本,即39个数据中的5个。这是由于最后三列与其余列不同。文本为白色时背景为黑色,会以某种方式影响文本提取的性能。
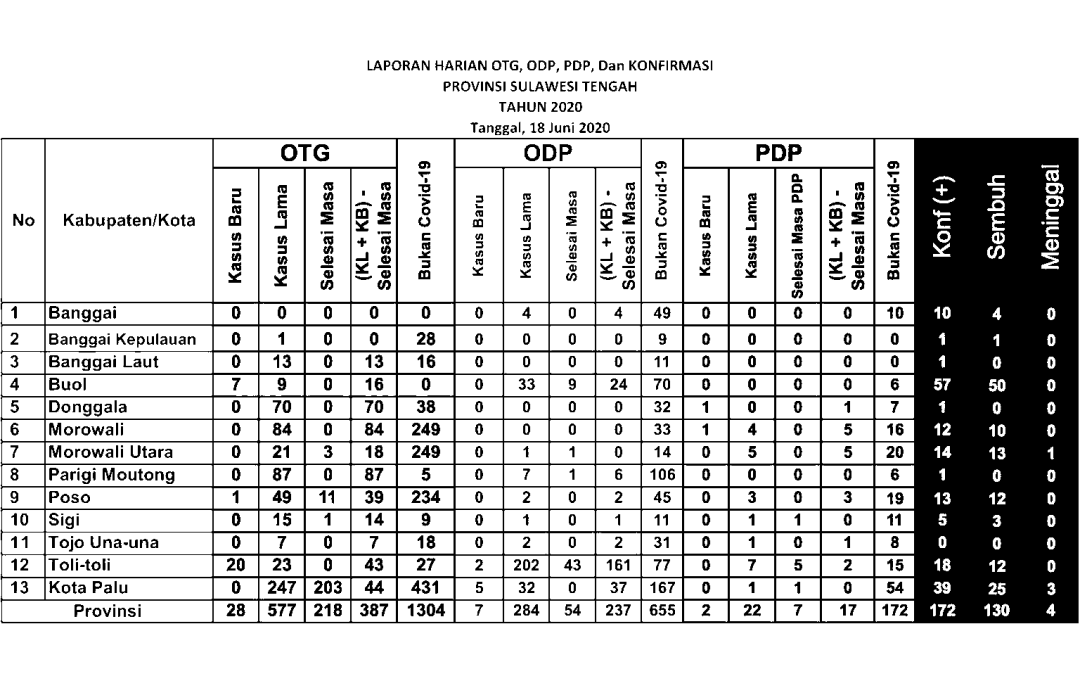
图7.二进制图像
为了解决这个问题,让我们倒数最后三列。
def invert_area(image, x, y, w, h, display=False):ones = np.copy(image)ones = 1image[ y:y+h , x:x+w ] = ones*255 - image[ y:y+h , x:x+w ]if (display): cv.imshow("inverted", image)cv.waitKey(0)cv.destroyAllWindows()return image
left_line_index = 17
right_line_index = 20
top_line_index = 0
bottom_line_index = -1cropped_image, (x, y, w, h) = get_ROI(img, horizontal, vertical, left_line_index, right_line_index, top_line_index, bottom_line_index)
gray = get_grayscale(img)
bw = get_binary(gray)
bw = invert_area(bw, x, y, w, h, display=True)结果如下所示。
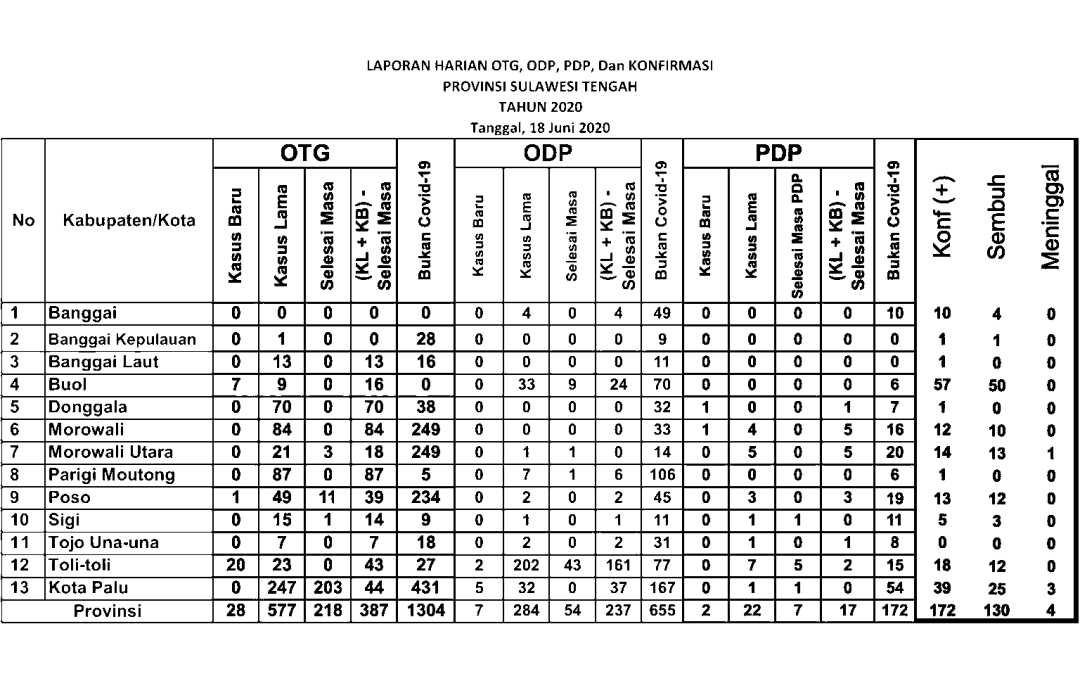
图8.处理后的二进制图像
结果
反转图像后,重新执行步骤,这是最终结果!
算法成功检测到文本后,现在可以将其保存到Python对象(例如Dictionary或List)中。由于Tesseract训练数据中未包含某些地区名称(“ Kabupaten / Kota”中的名称),因此无法准确检测到。但是,由于可以精确检测到地区的索引,因此这不会成为问题。文本提取可能无法检测到其他字体的文本,具体取决于所使用的字体,如果出现误解,例如将“ 5”检测为“ 8”,则可以进行诸如腐蚀膨胀之类的图像处理。
源代码:https://github.com/fazlurnu/Text-Extraction-Table-Image

往
期
回
顾
技术
100行python代码制作鞭炮
资讯
算力超越iPhone,芯片堪比Mac
技术
31个好用的Python字符串方法
资讯
游戏圈地震级消息,微软收购动视暴雪

分享

点收藏

点点赞

点在看
相关文章:

Redis以及Redis的php扩展安装无错版
安装Redis 下载最新的 官网:http://redis.io/ 或者 http://code.google.com/p/redis/downloads/list第一步:下载安装编译 #wget http://redis.googlecode.com/files/redis-2.4.4.tar.gz#tar zxvf redis-2.4.4.tar.gz#cd redis-2.4.4#make #make instal…
Android UI SurfaceView的使用-绘制组合图型,并使其移动
绘制容器类: //图形绘制容器 public class Contanier {private List<Contanier> list;private float x0,y0;public Contanier(){listnew ArrayList<Contanier>();}public void draw(Canvas canvas){canvas.save();canvas.translate(getX(), getY());chi…

新型混合共识机制及抗量子特性的 Hcash 主链测试链即将上线
由上海交通大学密码与计算机安全实验室(LoCCS)及上海观源信息科技有限公司负责研发的、具有新型混合共识机制及抗量子特性的 Hcash 主链代码已完成并在 2017 年 12 月18 日之前上传至github: https://github.com/HcashOrg/hcashd https://git…
CentOS 6虚拟机安装
这篇博客已经被合并到这里了: 虚拟机安装CentOS以及SecureCRT设置【完美无错版】 下面不用看了,看上面即可 1.下载虚拟机Oracle VM VirtualBox最新的下载地址: http://download.virtualbox.org/virtualbox/4.1.6/VirtualBox-4.1.6-74713-Win…

开发中新游戏《庞加莱》
三体题材的游戏,表现三体人在三体星上生活和冒险。收集水和物器,躲避火焰与巨日,探索遗迹并与巨型生物战斗。温度会因太阳位置不同而发生变化,进而对环境产生一定影响。 游戏开发中。 ---- 2017-4-27版视频: http://v.…

介绍一个打怪升级练习 Python 的网站,寓教于乐~
作者 | 周萝卜来源 | 萝卜大杂烩这是一个学习 Python 的趣味网站,通过关卡的形式来锻炼 Python 水平。一共有 33 关,每一关都需要利用 Python 知识解题找到答案,然后进入下一关。很考验对 Python 的综合掌握能力,比如有的闯关需要…
hive基本操作与应用
通过hadoop上的hive完成WordCount 启动hadoop ssh localhost cd /usr/local/hadoop ./sbin/start-dfs.sh cd /usr/local/hive/lib service mysql start start-all.sh Hdfs上创建文件夹 hdfs dfs -mkdir test1 hdfs dfs -ls /user/hadoop 上传文件至hdfs hdfs dfs -put ./try.tx…
PHP源代码分析-字符串搜索系列函数实现详解
今天和同事在讨论关键字过虑的算法实现,前几天刚看过布隆过滤算法,于是就想起我们公司内部的查找关键字程序,好奇是怎么实现的。于是查找了一下源代码,原来可以简单地用stripos函数查找, stripos原型如下: …

麻省理工研究:深度图像分类器,居然还会过度解读
作者 | 青苹果来源 | 数据实战派某些情况下,深度学习方法能识别出一些在人类看来毫无意义的图像,而这些图像恰恰也是医疗和自动驾驶决策的潜在隐患所在。换句话说,深度图像分类器可以使用图像的边界,而非对象本身,以超…
Oracle 查询转换之子查询展开
概念:子查询展开(Subquery Unnesting)是优化器处理带子查询的目标sql的一种优化手段,它是指优化器不再将目标sql中子查询当作一个独立的处理单元来单独执行,而是将该子查询转换为它自身和外部查询之间等价的表连接。这种等价连接转…
Xcode中通过删除原先版本的程序来复位App
可以在Xcode菜单中点击 Product->Clean Build Folder (按住Option键,在windows键盘中是Alt键.) 此时Xcode将会从设备中删除(卸载uninstall)任何该app之前部署的版本. 接下来重启Xcode,再试一下,有时这可以修复非常奇怪(really weird)的问题.
深入理解PHP之OpCode
OpCode是一种PHP脚本编译后的中间语言,就像Java的ByteCode,或者.NET的MSL。 此文主要基于《 Understanding OPcode》和 网络,根据个人的理解和修改,特记录下来 :PHP代码: <?phpecho "Hello World";$a 1…

关于 AIOps 的过去与未来,微软亚洲研究院给我们讲了这些故事
作者 | 贾凯强出品 | AI科技大本营(ID:rgznai100)在过去的15年里,云计算实现了飞速发展,而这种发展也为诸多的前沿技术奠定了基础,AIOps便在此环境中获得了良好的发展契机。在数字化转型的浪潮下,云计算已经…
JS 正则表达式 0.001 ~99.999
^(0|[1-9][0-9]?)(\.[0-9]{0,2}[1-9])?$转载于:https://www.cnblogs.com/wahaha603/p/9050130.html
深入浅出PHP(Exploring PHP)
一直以来,横观国内的PHP现状,很少有专门介绍PHP内部机制的书。呵呵,我会随时记录下研究的心得,有机会的时候,汇总成书。:) 今天这篇,我内心是想打算做为一个导论: PHP是一个被广泛应用的脚本语言…

懒人神器 !一个创意十足的 Python 命令行工具
作者 | 写代码的明哥来源 | Python编程时光当听到某些人说 xx 库非常好用的时候,我们总是忍不住想要去亲自试试。有一些库,之所以好用,是对一些库做了更高级的封闭,你装了这个库,就会附带装了 n 多依赖库,就…
Regular Expression Matching
正则匹配 Regular Expression Matching Implement regular expression matching with support for . and *. . Matches any single character. * Matches zero or more of the preceding element.The matching should cover the entire input string (not partial).The functio…

PI校正环节的程序实现推导过程
PI校正环节在经典控制论中非常有用,特别是对负反馈控制系统,基本上都有PI校正环节。1.下面分别说明比例环节和积分环节的作用,以阶跃信号为例。①比例环节单独作用以上分析说明,若只有比例环节的控制系统,阶跃响应也是…

几行 Python 代码实现邮件解析,超赞~
作者 | Yunlor来源 | CSDN博客前言如何通过python实现邮件解析?邮件的格式十分复杂,主要是mime协议,本文主要是从实现出发,具体原理可以自行研究。一、安装通过mailgun开源的Flanker库实现邮件解析。该库包含了邮件地址解析和邮件…
深入理解PHP原理之变量(Variables inside PHP)
或许你知道,或许你不知道,PHP是一个弱类型,动态的脚本语言。所谓弱类型,就是说PHP并不严格验证变量类型(严格来讲,PHP是一个中强类型语言,这部分内容会在以后的文章中叙述),在申明一个变量的时候࿰…

jQuery中的.height()、.innerHeight()和.outerHeight()
jQuery中的.height()、.innerHeight()和.outerHeight()和W3C的盒模型相关的几个获取元素尺寸的方法。对应的宽度获取方法分别为.width()、.innerWidth()和.outerWidth(),在此不详述。1. .height()获取匹配元素集合中的第一个元素的当前计算高度值 或 设置每一个匹配…

Python实战之logging模块使用详解
用Python写代码的时候,在想看的地方写个print xx 就能在控制台上显示打印信息,这样子就能知道它是什么了,但是当我需要看大量的地方或者在一个文件中查看的时候,这时候print就不大方便了,所以Python引入了logging模块来…
深入理解PHP原理之变量作用域
作者:laruence(http://www.laruence.com/)地址: http://www.laruence.com/2008/08/26/463.html PHP变量的内部表示是如何和用户脚本中的变量联系起来的呢?也就是说,如果我在脚本中写下:<?php $var"laruen…
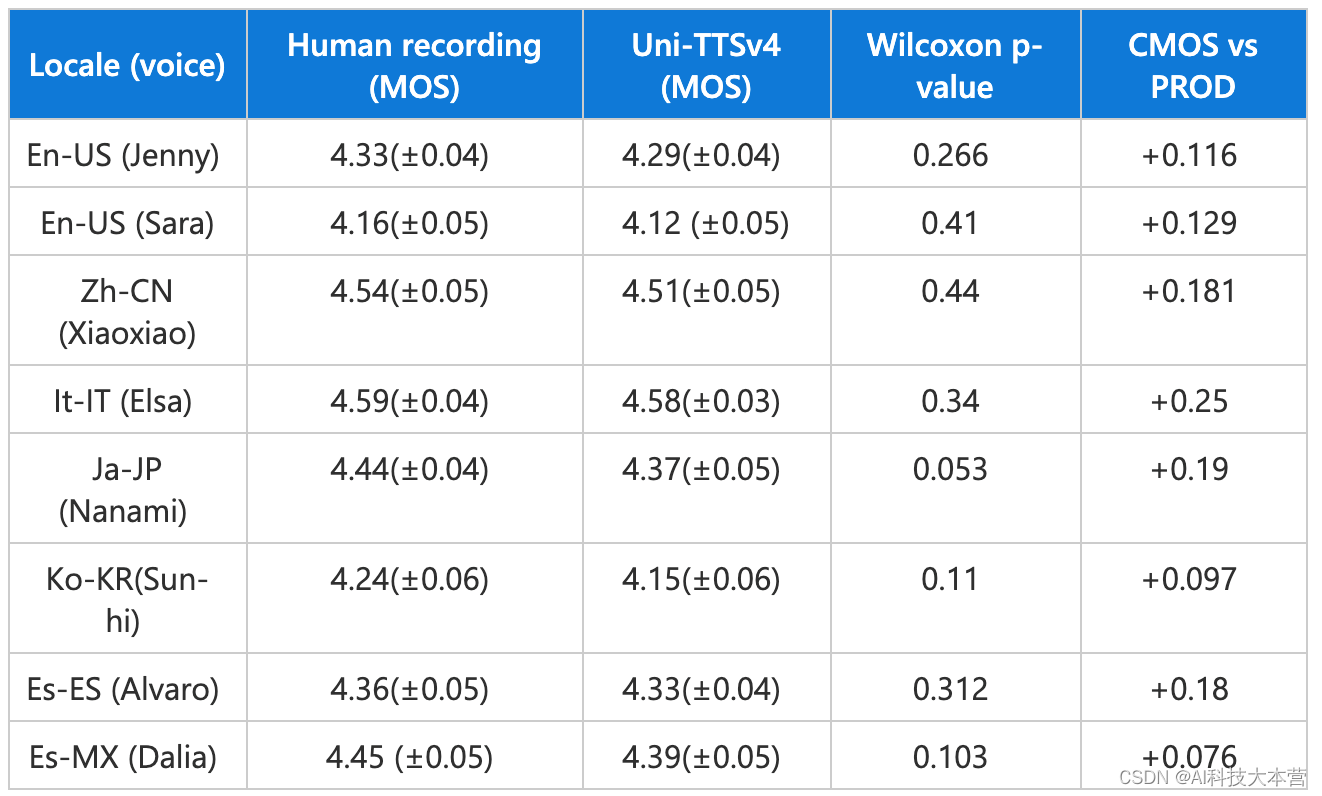
Azure AI的又一里程碑,Neural TTS新模型呈现真人般情感饱满的AI语音
在人与人之间的对话中,即使是同样的字句,也会因为所处情景和情感的不同而表现出丰富的抑扬顿挫,而这种动态性恰恰是各种AI合成语音的“软肋”。相比于人类讲话时丰富多变的语气,AI语音的“心平气和”往往给人带来明显的违和感。 …
VS2010中“工具选项中的VC++目录编辑功能已被否决”解决方法
http://blog.csdn.net/chaijunkun/article/details/6658923 这是VS2010的改变,不能够在“工具-选项”中看到“VC目录”了。 但是呢,我们可以在另外一个地方找到它,请看下边的对比照片。 VS2008中: VS2010中: 打开方式非…
Bminer 7.0.0 ETH挖矿教程(Linux 64)
Bminer产品介绍Bminer是目前最快的挖矿程序,Bminer是基于NVIDIA GPU深度优化的挖矿软件。Bminer支持Equihash和Ethash两种算法的虚拟币,包括:ETH(以太坊),ETC,ZEC(零币),…
深入理解PHP原理之变量分离/引用(Variables Separation)
引自: http://www.laruence.com/ [风雪之隅 ]在前面的文章中我已经介绍了PHP的变量的内部表示(深入理解PHP原理之变量(Variables inside PHP)),以及PHP中作用域的实现机制(深入理解PHP原理之变量作用域(Scope inside PHP))。这节我们就接着前面的文章,继…
C# 属性、索引
属性(property): public string Name {get{return _name;}set{_name value;} } 简写为: public string Name { set; get;} 索引器(index): 索引器为C#程序语言中泪的一种成员,它是的对象可…

分享几段祖传的 Python 代码,拿来直接使用!
作者 | 周萝卜来源 | 萝卜大杂烩今天分享几段工作生活中常用的代码,都是最为基础的功能和操作,而且大多还都是出现频率比较高的,很多都是可以拿来直接使用或者简单修改就可以放到自己的项目当中日期生成很多时候我们需要批量生成日期…
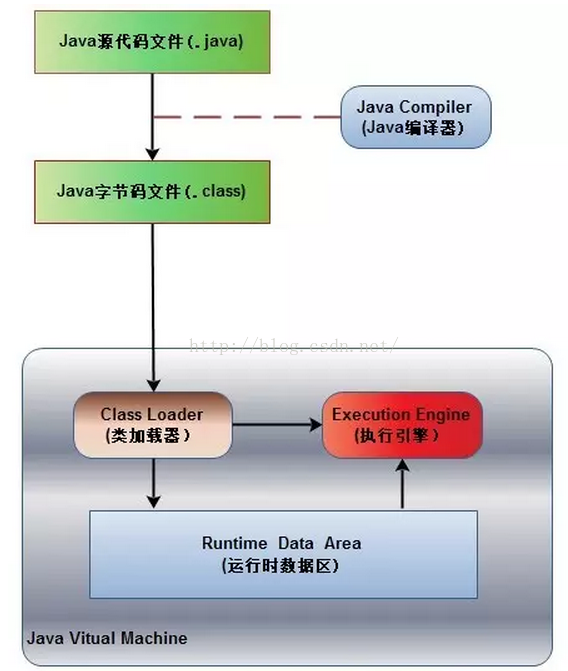
JVM——Java虚拟机架构
Java虚拟机(Java virtualmachine)实现了Java语言最重要的特征:即平台无关性。 平台无关性原理:编译后的 Java程序(.class文件)由 JVM执行。JVM屏蔽了与具体平台相关的信息,使程序可以在多种平台…