22个案例详解Pandas数据分析/预处理时的实用技巧,超简单

作者 | 俊欣
来源 | 关于数据分析与可视化
今天小编打算来讲一讲数据分析方面的内容,整理和总结一下Pandas在数据预处理和数据分析方面的硬核干货,我们大致会说
Pandas计算交叉列表Pandas将字符串与数值转化成时间类型Pandas将字符串转化成数值类型
Pandas当中的交叉列表
首先我们来讲一下Pandas模块当中的crosstab()函数,它的作用主要是进行分组之后的信息统计,里面会用到聚合函数,默认的是统计行列组合出现的次数,参数如下
pandas.crosstab(index, columns,values=None,rownames=None,colnames=None,aggfunc=None,margins=False,margins_name='All',dropna=True,normalize=False)下面小编来解释一下里面几个常用的函数
index: 指定了要分组的类目,作为行
columns: 指定了要分组的类目,作为列
rownames/colnames: 行/列的名称
aggfunc: 指定聚合函数
values: 最终在聚合函数之下,行与列一同计算出来的值
normalize: 标准化统计各行各列的百分比
我们通过几个例子来进一步理解corss_tab()函数的作用,我们先导入要用到的模块并且读取数据集
import pandas as pddf = pd.read_excel(io="supermarkt_sales.xlsx",engine="openpyxl",sheet_name="Sales",skiprows=3,usecols="B:R",nrows=1000,
)output
我们先简单来看几个corsstab()函数的例子,代码如下
pd.crosstab(df['城市'], df['顾客类型'])output
顾客类型 会员 普通
省份
上海 124 115
北京 116 127
四川 26 35
安徽 28 12
广东 30 36
.......这里我们将省份指定为行索引,将会员类型指定为列,其中顾客类型有“会员”、“普通”两种,举例来说,四川省的会员顾客有26名,普通顾客有35名。
当然我们这里只是指定了一个列,也可以指定多个,代码如下
pd.crosstab(df['省份'], [df['顾客类型'], df["性别"]])output
顾客类型 会员 普通
性别 女性 男性 女性 男性
省份
上海 67 57 53 62
北京 53 63 59 68
四川 17 9 16 19
安徽 17 11 9 3
广东 18 12 15 21
.....这里我们将顾客类型进行了细分,有女性会员、男性会员等等,那么同理,对于行索引我们也可以指定多个,这里也就不过多进行演示。
有时候我们想要改变行索引的名称或者是列方向的名称,我们则可以这么做
pd.crosstab(df['省份'], df['顾客类型'],colnames = ['顾客的类型'],rownames = ['各省份名称'])output
顾客的类型 会员 普通
各省份名称
上海 124 115
北京 116 127
四川 26 35
安徽 28 12
广东 30 36要是我们想在行方向以及列方向上加一个汇总的列,就需要用到crosstab()方法当中的margin参数,如下
pd.crosstab(df['省份'], df['顾客类型'], margins = True)output
顾客类型 会员 普通 All
省份
上海 124 115 239
北京 116 127 243
.....
江苏 18 15 33
浙江 119 111 230
黑龙江 14 17 31
All 501 499 1000你也可以给汇总的那一列重命名,用到的是margins_name参数,如下
pd.crosstab(df['省份'], df['顾客类型'],margins = True, margins_name="汇总")output
顾客类型 会员 普通 汇总
省份
上海 124 115 239
北京 116 127 243
.....
江苏 18 15 33
浙江 119 111 230
黑龙江 14 17 31
汇总 501 499 1000而如果我们需要的数值是百分比的形式,那么就需要用到normalize参数,如下
pd.crosstab(df['省份'], df['顾客类型'],normalize=True)output
顾客类型 会员 普通
省份
上海 0.124 0.115
北京 0.116 0.127
四川 0.026 0.035
安徽 0.028 0.012
广东 0.030 0.036
.......要是我们更加倾向于是百分比,并且保留两位小数,则可以这么来做
pd.crosstab(df['省份'], df['顾客类型'],normalize=True).style.format('{:.2%}')output
顾客类型 会员 普通
省份
上海 12.4% 11.5%
北京 11.6% 12.7%
四川 26% 35%
安徽 28% 12%
广东 30% 36%
.......下面我们指定聚合函数,并且作用在我们指定的列上面,用到的参数是aggfunc参数以及values参数,代码如下
pd.crosstab(df['省份'], df['顾客类型'],values = df["总收入"],aggfunc = "mean")output
顾客类型 会员 普通
省份
上海 15.648738 15.253248
北京 14.771259 14.354390
四川 20.456135 14.019029
安徽 10.175893 11.559917
广东 14.757083 18.331903
.......如上所示,我们所要计算的是地处“上海”并且是“会员”顾客的总收入的平均值,除了平均值之外,还有其他的聚合函数,如np.sum加总或者是np.median求取平均值。
我们还可以指定保留若干位的小数,使用round()函数
df_1 = pd.crosstab(df['省份'], df['顾客类型'],values=df["总收入"],aggfunc="mean").round(2)output
顾客类型 会员 普通
省份
上海 15.65 15.25
北京 14.77 14.35
四川 20.46 14.02
安徽 10.18 11.56
广东 14.76 18.33
.......时间类型数据的转化
对于很多数据分析师而言,在进行数据预处理的时候,需要将不同类型的数据转换成时间格式的数据,我们来看一下具体是怎么来进行
首先是将整形的时间戳数据转换成时间类型,看下面的例子
df = pd.DataFrame({'date': [1470195805, 1480195805, 1490195805],'value': [2, 3, 4]})
pd.to_datetime(df['date'], unit='s')output
0 2016-08-03 03:43:25
1 2016-11-26 21:30:05
2 2017-03-22 15:16:45
Name: date, dtype: datetime64[ns]上面的例子是精确到秒,我们也可以精确到天,代码如下
df = pd.DataFrame({'date': [1470, 1480, 1490],'value': [2, 3, 4]})
pd.to_datetime(df['date'], unit='D')output
0 1974-01-10
1 1974-01-20
2 1974-01-30
Name: date, dtype: datetime64[ns]下面则是将字符串转换成时间类型的数据,调用的也是pd.to_datetime()方法
pd.to_datetime('2022/01/20', format='%Y/%m/%d')output
Timestamp('2022-01-20 00:00:00')亦或是
pd.to_datetime('2022/01/12 11:20:10',format='%Y/%m/%d %H:%M:%S')output
Timestamp('2022-01-12 11:20:10')这里着重介绍一下Python当中的时间日期格式化符号
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 表示的是月份(01-12)
%d 表示的是一个月当中的一天(0-31)
%H 表示的是24小时制的小时数
%I 表示的是12小时制的小时数
%M 表示的是分钟数 (00-59)
%S 表示的是秒数(00-59)
%w 表示的是星期数,一周当中的第几天,从星期天开始算
%W 表示的是一年中的星期数
当然我们进行数据类型转换遇到错误的时候,pd.to_datetime()方法当中的errors参数就可以派上用场,
df = pd.DataFrame({'date': ['3/10/2000', 'a/11/2000', '3/12/2000'],'value': [2, 3, 4]})
# 会报解析错误
df['date'] = pd.to_datetime(df['date'])output

我们来看一下errors参数的作用,代码如下
df['date'] = pd.to_datetime(df['date'], errors='ignore')
dfoutput
date value
0 3/10/2000 2
1 a/11/2000 3
2 3/12/2000 4或者将不准确的值转换成NaT,代码如下
df['date'] = pd.to_datetime(df['date'], errors='coerce')
dfoutput
date value
0 2000-03-10 2
1 NaT 3
2 2000-03-12 4数值类型的转换
接下来我们来看一下其他数据类型往数值类型转换所需要经过的步骤,首先我们先创建一个DataFrame数据集,如下
df = pd.DataFrame({'string_col': ['1','2','3','4'],'int_col': [1,2,3,4],'float_col': [1.1,1.2,1.3,4.7],'mix_col': ['a', 2, 3, 4],'missing_col': [1.0, 2, 3, np.nan],'money_col': ['£1,000.00','£2,400.00','£2,400.00','£2,400.00'],'boolean_col': [True, False, True, True],'custom': ['Y', 'Y', 'N', 'N']})output
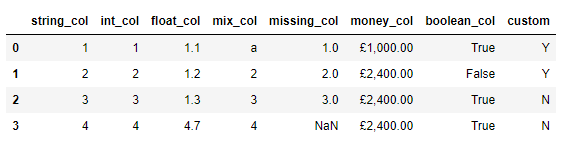
我们先来查看一下每一列的数据类型
df.dtypesoutput
string_col object
int_col int64
float_col float64
mix_col object
missing_col float64
money_col object
boolean_col bool
custom object
dtype: object可以看到有各种类型的数据,包括了布尔值、字符串等等,或者我们可以调用df.info()方法来调用,如下
df.info()output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 8 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 string_col 4 non-null object 1 int_col 4 non-null int64 2 float_col 4 non-null float643 mix_col 4 non-null object 4 missing_col 3 non-null float645 money_col 4 non-null object 6 boolean_col 4 non-null bool 7 custom 4 non-null object
dtypes: bool(1), float64(2), int64(1), object(4)
memory usage: 356.0+ bytes我们先来看一下从字符串到整型数据的转换,代码如下
df['string_col'] = df['string_col'].astype('int')
df.dtypesoutput
string_col int32
int_col int64
float_col float64
mix_col object
missing_col float64
money_col object
boolean_col bool
custom object
dtype: object看到数据是被转换成了int32类型,当然我们指定例如astype('int16')、astype('int8')或者是astype('int64'),当我们碰到量级很大的数据集时,会特别的有帮助。
那么类似的,我们想要转换成浮点类型的数据,就可以这么来做
df['string_col'] = df['string_col'].astype('float')
df.dtypesoutput
string_col float64
int_col int64
float_col float64
mix_col object
missing_col float64
money_col object
boolean_col bool
custom object
dtype: object同理我们也可以指定转换成astype('float16')、astype('float32')或者是astype('float128')
而如果数据类型的混合的,既有整型又有字符串的,正常来操作就会报错,如下
df['mix_col'] = df['mix_col'].astype('int')output

当中有一个字符串的数据"a",这个时候我们可以调用pd.to_numeric()方法以及里面的errors参数,代码如下
df['mix_col'] = pd.to_numeric(df['mix_col'], errors='coerce')
df.head()output
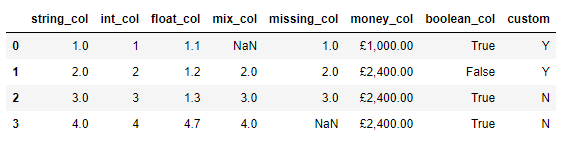
我们来看一下各列的数据类型
df.dtypesoutput
string_col float64
int_col int64
float_col float64
mix_col float64
missing_col float64
money_col object
boolean_col bool
custom object
dtype: object"mix_col"这一列的数据类型被转换成了float64类型,要是我们想指定转换成我们想要的类型,例如
df['mix_col'] = pd.to_numeric(df['mix_col'], errors='coerce').astype('Int64')
df['mix_col'].dtypesoutput
Int64Dtype()而对于"money_col"这一列,在字符串面前有一个货币符号,并且还有一系列的标签符号,我们先调用replace()方法将这些符号给替换掉,然后再进行数据类型的转换
df['money_replace'] = df['money_col'].str.replace('£', '').str.replace(',','')
df['money_replace'] = pd.to_numeric(df['money_replace'])
df['money_replace']output
0 1000.0
1 2400.0
2 2400.0
3 2400.0
Name: money_replace, dtype: float64要是你熟悉正则表达式的话,也可以通过正则表达式的方式来操作,通过调用regex=True的参数,代码如下
df['money_regex'] = df['money_col'].str.replace('[\£\,]', '', regex=True)
df['money_regex'] = pd.to_numeric(df['money_regex'])
df['money_regex']另外我们也可以通过astype()方法,对多个列一步到位进行数据类型的转换,代码如下
df = df.astype({'string_col': 'float16','int_col': 'float16'
})或者在第一步数据读取的时候就率先确定好数据类型,代码如下
df = pd.read_csv('dataset.csv', dtype={'string_col': 'float16','int_col': 'float16'}
)

往
期
回
顾
资讯
冬奥会夺金背后的杀手锏,是他
资讯
首个深度强化学习AI,控制核聚变
技术
真香,邮件分类准确识别垃圾邮件
技术
程序员元宵节的正确打开方式

分享

点收藏

点点赞

点在看
相关文章:

PL/SQL 中Returning Into的用法
ORACLE的DML语句中可以指定RETURNING INTO语句。RETURNING INTO语句的使用在很多情况下可以简化PL/SQL编程,少一次select into语句。DELETE操作:RETURNING返回的是DELETE之前的结果; INSERT操作:RETURNING返回的是INSERT之后的结果…

Java常用多线程辅助工具---countdownLatch
为什么80%的码农都做不了架构师?>>> 前言 上一篇博文说到semaphore,一个加强版的synchronized,该多线程辅助工具适用于控制对资源操作或者访问的场景。现在有一张场景是,需要等各个线程都都执行完了再进行下一步的操作…

听说,英特尔要对外开放 x86 授权?
整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)同为主流芯片架构,相较于可申请授权的 ARM 和开源的 RISC-V,x86 一直以来都保持着“高高在上”的立场——唯有英特尔和 AMD 拥有 x86 授权。但目前看来,x86 的“高冷…
Linux下gedit显示行号
Gedit 编辑->视图
关于String数组的用法
android ContextWrapper.getResources(ContextWrapper.java:89) getResources()报错原因是在OnCreate方法外 无法完成Context的初始化 正确做法: String[] names;names new String[6];names[0] getResources().getString(R.string.a);names[1] getResources().g…
使用RabbitMQ做数据接收和处理时,自动关闭
场景:N个客户端向MQ里发送数据;服务器上有另一个控制台程序(假设叫ServerClient)来处理这里数据(往数据库保存)。方向为Client * n→MQSERVER→ServerClient 问题:ServerClient自动关闭,没有错误日志&#…

在 Python 中妙用短路机制
作者 | 费弗里来源 | Python大数据分析本期我们即将学习的是:Python中短路机制的妙用。不同于物理学中的「短路」(Short circuit)那般危险,Python中的短路机制非常有用,跟很多其他编程语言中的短路机制作用类似&#x…
《Advanced PHP Programming》读书笔记
此书无中文版,但是写的极好!本来想翻译的,可是时间不允许了。 http://www.amazon.com/Advanced-PHP-Programming-George-Schlossnagle/dp/0672325616/refpd_rhf_dp_p_t_1约定:加粗字体表示章节,由于时间关系解释性的说…
cookie记录用户的浏览商品的路径
在电子商务的网站中,经常要记录用户的浏览路径,以判断用户到底对哪些商品感兴趣,或者哪些商品之间存在关联。 下面将使用cookie记录用户的浏览过的历史页面。该网站将每个页面的标题保存在该页面的$TITLE 变量中,用户每访问一次&a…
如何快速写一个违背双亲委托机制的classloader
很多情况下,不得以必须写个classloader来满足需求。例如你一个工程里你想用相同的数据库的多个版本,自己制定了一个jar包目录,没有classloader管理等等。如果是一个遵循java已经规定好的机制的classloader(双亲委托以及加载依赖类…
让我们谈谈RAID
转自:http://soft.zdnet.com.cn/techupdate/2004/0330/397707.shtml 更新时间: 2004-03-30 17:14:00 作者: 赵效民 感觉写的很好就转来了。 RAID的种类 RAID的英文全称为Redundant Array of Inexpensive(或Independent) Disks&…

Ampere 携手 Rigetti 开发混合量子经典计算机
该合作旨在为价值 160 亿美元的机器学习市场提供服务,赋能机器学习应用的发展双方将把 Ampere Altra Max 处理器和 Rigetti 量子处理单元进行优化结合,为机器学习提供整合的云平台 2022 年 2 月 21 日,安晟培半导体科技有限公司(A…

[C++] NULL VS nullptr
NULL VS nullptr 转载于:https://www.cnblogs.com/tianhangzhang/p/4945623.html
swift 的defer使得资源的分配和释放代码可以放到一起
只是一种语法和逻辑上的优化
烂泥:haproxy学习之手机规则匹配
2019独角兽企业重金招聘Python工程师标准>>> 本文由ilanniweb提供友情赞助,首发于烂泥行天下 想要获得更多的文章,可以关注我的微信ilanniweb。 今天我们来介绍下有关haproxy匹配手机的一些规则配置。 一、业务需要 现在根据业务的实际需要&a…
jQuery日期选择器插件date-input
官网:http://jonathanleighton.com/projects/date-input/下载: http://ajax.googleapis.com/ajax/libs/jquery/1.3.1/jquery.min.js http://github.com/jonleighton/date_input/raw/master/jquery.date_input.js http://github.com/jonleighton/date_inp…

厉害了,用Python绘制动态可视化图表,并保存成gif格式
作者 | 俊欣来源 | 关于数据分析与可视化最近有粉丝问道说“是不是可以将这些动态的可视化图表保存成gif图”,小编立马就回复了说后面会写一篇相关的文章来介绍如何进行保存gif格式的文件。那么我们就开始进入主题,来谈一下Python当中的gif模块。安装相关…
facade-门面模式
解决问题 客户端调用逻辑与业务代码有效隔离,使得客户端调用只和Facade进行交互,内部的调用逻辑由Facade进行实现。此模式也可以和接口化编程结合,进一步降低客户端与业务逻辑的耦合 应用场景 它主要应用在代码结构的设计,合理组织…
淘宝李晓拴:淘宝网PHP电子商务应用
源自:http://tech.qq.com/a/20110512/000298.htm 大家好,大家知道淘宝搜索是一个典型PHP架构。在座同学不知道有多少人使用过淘宝搜索可以举手示意一下?在开始这个话题之前我们先谈一下Polyglot,多语言混合编程,淘宝有…

玩爬虫不会登陆?这个工具拿走不谢!
作者 | 周萝卜来源 | 萝卜大杂烩在日常学习当中,我们或多或少都会到网上抓取一些数据,比如豆瓣、微博等等,但是这些网站在非登录的情况只能拿到部分数据,有很多数据都是需要登陆之后才可以获取的,那么模拟登陆就成为了…
Oracle分页
先看以下两条语句的执行结果: 语句一:select rownum,empno,sal from emp order by empno; ROWNUM EMPNO SAL ---------- ---------- ---------- 1 7369 800 2 7499 1600 3 7521 …
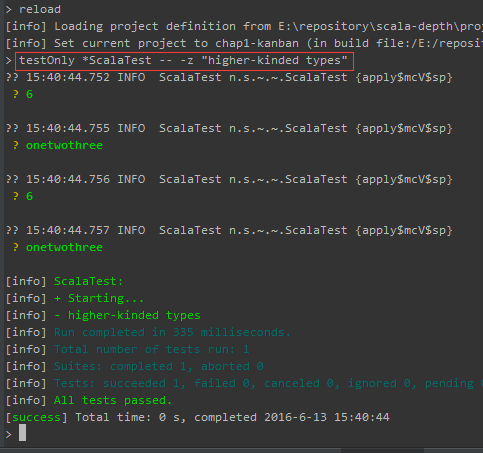
Scala类型系统——高级类类型(higher-kinded types)
高级类类型就是使用其他类型构造成为一个新的类型,因此也称为 类型构造器(type constructors)。它的语法和高阶函数(higher-order functions)相似,高阶函数就是将其它函数作为参数的函数;高级类类型则是将构造类类型作为参数类型。一个高级类…
android休眠唤醒驱动流程分析【转】
转自:http://blog.csdn.net/hanmengaidudu/article/details/11777501标准linux休眠过程:l power management notifiers are executed with PM_SUSPEND_PREPAREl tasks are frozenl target system sleep state is announced to the …
PHP使用curl_multi_add_handle并行处理
http://www.php.net/manual/zh/function.curl-multi-add-handle.php<?php// 创建一对cURL资源$ch1 curl_init();$ch2 curl_init();// 设置URL和相应的选项curl_setopt($ch1, CURLOPT_URL, "http://www.baidu.com/");curl_setopt($ch1, CURLOPT_HEADER, 0);curl…

斯坦福团队是如何构建更好用的聊天 AI 呢?
作者:Standford AI译者:Yang来源:数据实战派2019 年,凭借着 Chirpy Cardinal 机器人,斯坦福首次在 Alexa Prize Socialbot Grand Challenge 3 中赢得了第二名。本文将进一步揭示 Chirpy Cardinal 开发细节,…
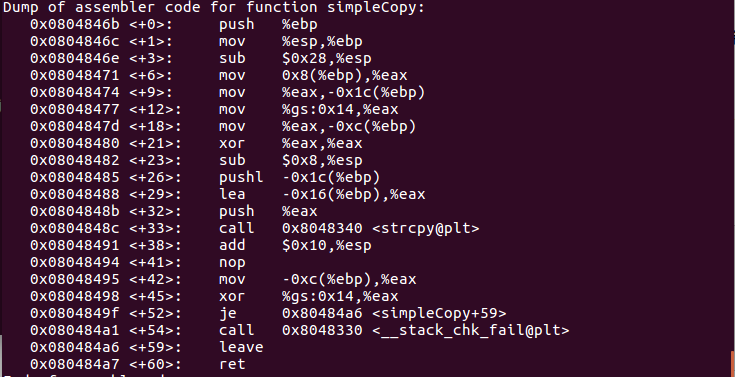
使用Linux进行缓冲区溢出实验的配置记录
在基础的软件安全实验中,缓冲区溢出是一个基础而又经典的问题。最基本的缓冲区溢出即通过合理的构造输入数据,使得输入数据量超过原始缓冲区的大小,从而覆盖数据输入缓冲区之外的数据,达到诸如修改函数返回地址等目的。但随着操作…
Javascript导出Excel的方法
<SCRIPT LANGUAGE"javascript"> function method1(tableid) {//整个表格拷贝到EXCEL中 var curTbl document.getElementById(tableid); var oXL new ActiveXObject("Excel.Application"); //创建AX对象excel var oWB oXL.Workbooks.Add(); //获取…

Top 15 不起眼却有大作用的 .NET功能集
目录1. ObsoleteAttribute2. 设置默认值属性: DefaultValueAttribute3. DebuggerBrowsableAttribute4. ??运算符5. Curry 及 Partial 方法6. WeakReference7. Lazy8. BigInteger9. 非官方关键字:__arglist __reftype __makeref __…
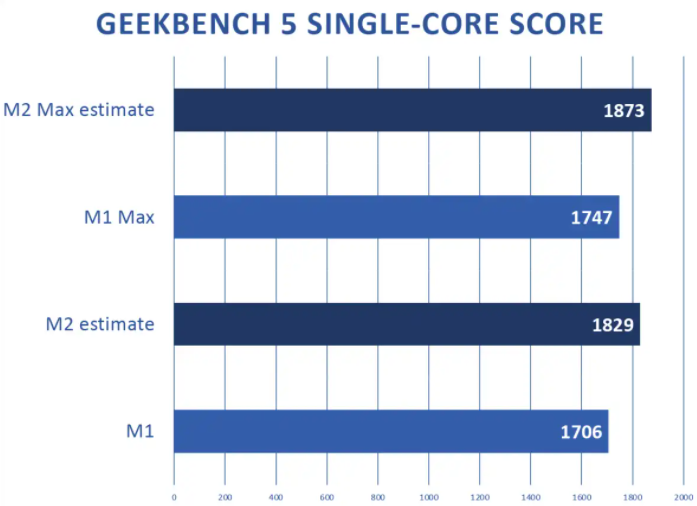
M2 芯片终于要来了?全线换新,性能远超M1 Max
不知不觉日历已翻至 2 月下旬,掐指一算,距离苹果一年一度春季新品发布会的召开似乎已越来越近。根据年初统计的 2022 年苹果新品预测,预计今年的苹果“小春晚”将在 Mac 方面有大动作。 那么,苹果将如何“动作”,又…

Python抓取新浪新闻数据(三)
非同步载入一般在XHR下查找,但是没有发现XHR下有相关内容。 转载于:https://blog.51cto.com/2290153/2126862