让我们谈谈RAID
转自:http://soft.zdnet.com.cn/techupdate/2004/0330/397707.shtml 更新时间: 2004-03-30 17:14:00 作者: 赵效民
感觉写的很好就转来了。
RAID的种类
RAID的英文全称为Redundant Array of Inexpensive(或Independent) Disks,而不是某些词典中所说的“ Redundant Access Independent Disks”。中文名称是廉价(独立)磁盘冗余阵列。
RAID的初衷主要是为了大型服务器提供高端的存储功能和冗余的数据安全。在系统中,RAID被看作是一个逻辑分区,但是它是由多个硬盘组成的(最少两块)。它通过在多个硬盘上同时存储和读取数据来大幅提高存储系统的数据吞吐量(Throughput),而且在很多RAID模式中都有较为完备的相互校验/恢复的措施,甚至是直接相互的镜像备份,从而大大提高了RAID系统的容错度,提高了系统的稳定冗余性,这也是Redundant一词的由来。
RAID以前一直是SCSI领域的独有产品,因为它当时的技术与成本也限制了其在低端市场的发展。今天,随着RAID技术的日益成熟与厂商的不断努力,我们已经能够享受到相对成本低廉得多的IDE-RAID系统,虽然稳定与可靠性还不可能与SCSI-RAID相比,但它相对于单个硬盘的性能优势对广大玩家是一个不小的诱惑。事实上,对于日常的低强度操作,IDE-RAID已足能胜任了。
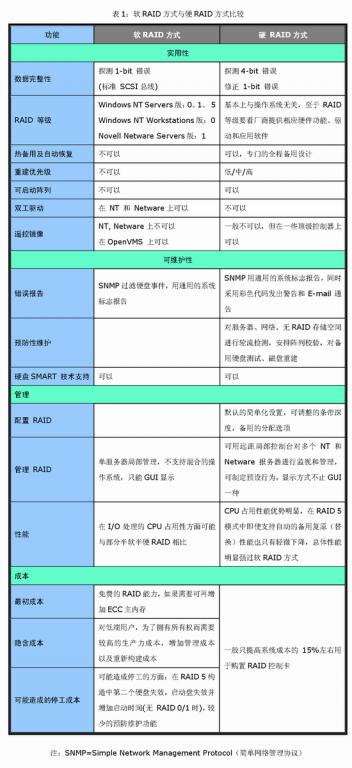
与Modem一样,RAID也有全软、半软半硬与全硬之分,全软RAID就是指RAID的所有功能都是操作系统(OS)与CPU来完成,没有第三方的控制/处理(业界称其为RAID协处理器——RAID Co-Processor)与I/O芯片。这样,有关RAID的所有任务的处理都由CPU来完成,可想而知这是效率最低的一种RAID。半软半硬RAID则主要缺乏自己的I/O处理芯片,所以这方面的工作仍要由CPU与驱动程序来完成。而且,半软半硬RAID所采用的RAID控制/处理芯片的能力一般都比较弱,不能支持高的RAID等级。全硬的RAID则全面具备了自己的RAID控制/处理与I/O处理芯片,甚至还有阵列缓冲(Array Buffer),对CPU的占用率以及整体性能是这三种类型中最优势的,但设备成本也是三种类型中最高的。早期市场上所出现的使用HighPoint HPT 368、370以及PROMISE芯片的IDE RAID卡与集成它们的主板都是半软半硬的RAID,并不是真正的硬RAID,因为它们没有自己专用的I/O处理器。而且,这两个公司的RAID控制/处理芯片的能力较弱,不能完成复杂的处理任务,因此还不支持RAID 5等级。著名的Adpatec公司所出品的AAA-UDMA RAID卡则是全硬RAID的代表之作,其上有专用的高级RAID Co-Processor和Intel 960专用I/O处理器,完全支持RAID 5等级,是目前最高级的IDE-RAID产品。表1 就是典型的软件RAID与硬RAID在行业应用中的比较。
RAID发展至今共有10个主要的等级,下面我们就将依次介绍
RAID-0等级
Striped Disk Array without Fault Tolerance(没有容错设计的条带磁盘阵列)
图中一个圆柱就是一块磁盘(以下均是),它们并联在一起。从图中可以看出,RAID 0在存储数据时由RAID控制器(硬件或软件)分割成大小相同的数据条,同时写入阵列中的磁盘。如果发挥一下想象力,你会觉得数据象一条带子横跨过所有的阵列磁盘,每个磁盘上的条带深度则是一样的。至于每个条带的深度则要看所采用的RAID类型,在NT系统的软RAID 0等级中,每个条带深度只有64KB一种选项,而在硬RAID 0等级,可以提供8、16、32、64以及128KB等多种深度参数。Striped是RAID的一种典型方式,在很多RAID术语解释中,都把Striped指向RAID 0。在读取时,也是顺序从阵列磁盘中读取后再由RAID控制器进行组合再传送给系统,这也是RAID的一个最重要的特点。
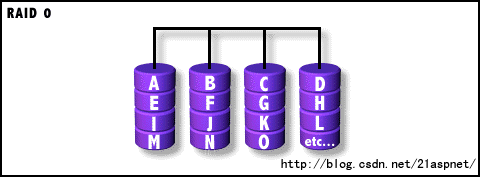
RAID-0结构图解
这样,数据就等于并行的写入和读取,从而非常有助于提高存储系统的性能。对于两个硬盘的RAID 0系统,提高一倍的读写性能可能有些夸张,毕竟要考虑到也同时缯加的数据分割与组合等与RAID相关的操作处理时间,但比单个硬盘提高50%的性能是完全可以的。
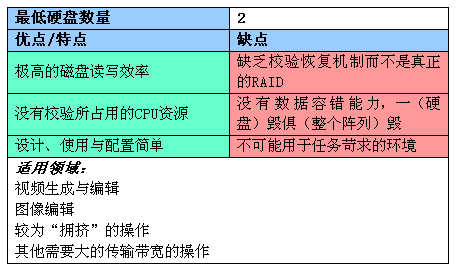
不过,RAID 0还不能算是真正的RAID,因为它没有数据冗余能力。由于没有备份或校验恢复设计,在RAID 0阵列中任何一个硬盘损坏就可导致整个阵列数据的损坏,因为数据都是分布存储的。下面总结一下RAID 0的特点:
RAID-1等级
Mirroring and Duplexing(相互镜像)
对比RAID 0等级,我们能发现硬盘的内容是两两相同的。这就是镜像——两个硬盘的内容完全一样,这等于内容彼此备份。比如阵列中有两个硬盘,在写入时,RAID控制器并不是将数据分成条带而是将数据同时写入两个硬盘。这样,其中任何一个硬盘的数据出现问题,可以马上从另一个硬盘中进行恢复。注意,这两个硬盘并不是主从关系,也就是说是相互镜像/恢复的。
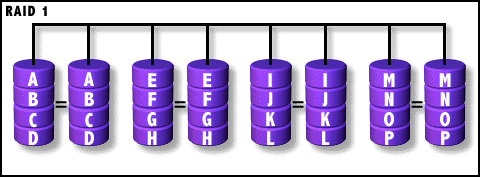
RAID-1结构图解
RAID 1已经可以算是一种真正的RAID系统,它提供了强有力的数据容错能力,但这是由一个硬盘的代价所带来的效果,而这个硬盘并不能增加整个阵列的有效容量。下面总结一下RAID 1的特点:

RAID-2等级
Hamming Code ECC(汉明码错误检测与修正)
现在我们要接触到RAID系统中最为复杂的等级之一。RAID 2之所以复杂就是因为它采用了早期的错误检测与修正技术——汉明码(Hamming Code)校验技术。因此在介绍RAID 2之前有必要讲讲汉明码的原理。
汉明码的原理:
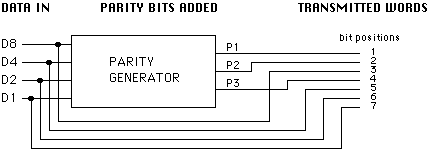
针对4位数据的汉明码编码示意图
汉明码是一个在原有数据中插入若干校验码来进行错误检查和纠正的编码技术。以典型的4位数据编码为例,汉明码将加入3个校验码,从而使实际传输的数据位达到7个(位),它们的位置如果把上图中的位置横过来就是:
数据位 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
代码 | P1 | P2 | D8 | P3 | D4 | D2 | D1 |
说明 | 第1个汉明码 | 第2个汉明码 | 第1个数据码 | 第3个汉明码 | 第2个数据码 | 第3个数据码 | 第4个数据码 |
注:Dx中的x是2的整数幂(下面的幂都是指整数幂)结果,多少幂取决于码位,D1是0次幂,D8是3次幂,想想二进制编码就知道了
现以数据码1101为例讲讲汉明码的编码原理,此时D8=1、D4=1、D2=0、D1=1,在P1编码时,先将D8、D4、D1的二进制码相加,结果为奇数3,汉明码对奇数结果编码为1,偶数结果为0,因此P1值为1,D8+D2+D1=2,为偶数,那么P2值为0,D4+D2+D1=2,为偶数,P3值为0。这样,参照上文的位置表,汉明码处理的结果就是1010101。在这个4位数据码的例子中,我们可以发现每个汉明码都是以三个数据码为基准进行编码的。下面就是它们的对应表:
汉明码 | 编码用的数据码 |
P1 | D8、D4、D1 |
P2 | D8、D2、D1 |
P3 | D4、D2、D1 |
从编码形式上,我们可以发现汉明码是一个校验很严谨的编码方式。在这个例子中,通过对4个数据位的3个位的3次组合检测来达到具体码位的校验与修正目的(不过只允许一个位出错,两个出错就无法检查出来了,这从下面的纠错例子中就能体现出来)。在校验时则把每个汉明码与各自对应的数据位值相加,如果结果为偶数(纠错代码为0)就是正确,如果为奇数(纠错代码为1)则说明当前汉明码所对应的三个数据位中有错误,此时再通过其他两个汉明码各自的运算来确定具体是哪个位出了问题。
还是刚才的1101的例子,正确的编码应该是1010101,如果第三个数据位在传输途中因干扰而变成了1,就成了1010111。检测时,P1+D8+D4+D1的结果是偶数4,第一位纠错代码为0,正确。P1+D8+D2+D1的结果是奇数3,第二位纠错代码为1,有错误。P3+D4+D2+D1的结果是奇数3,第三但纠错代码代码为1,有错误。那么具体是哪个位有错误呢?三个纠错代码从高到低排列为二进制编码110,换算成十进制就是6,也就是说第6位数据错了,而数据第三位在汉明码编码后的位置正好是第6位。
那么汉明码的数量与数据位的数量之间有何比例呢?上面的例子中数据位是4位,加上3位汉明码是7位,而2的3次幂是8。这其中就存在一个规律,即2P≥P+D+1,其中P代表汉明码的个数,D代表数据位的个数,比如4位数据,加上1就是5,而能大于5的2的幂数就是3(23=8,22=4)。这样,我们就能算出任何数据位时所需要的汉明码位数:7位数据时需要4位汉明码(24>4+7+1),64位数据时就需要7位汉明码(27>64+7+1),大家可以依此推算。此时,它们的编码规也与4位时不一样了。
另外,汉明码加插的位置也是有规律的。以四位数据为例,第一个是汉明码是第一位,第二个是第二位,第三个是第四位,1、2、4都是2的整数幂结果,而这个幂次数是从0开始的整数。这样我们可以推断出来,汉明码的插入位置为1(20)、2(21)、4(22)、8(23)、16(24)、32(25)……
说完汉明码,下面就开始介绍RAID 2等级。
RAID 2等级介绍:
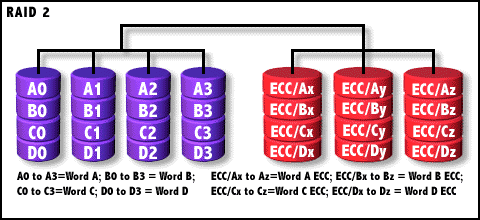
RAID-2结构图解
由于汉明码是位为基础进行校验的,那么在RAID2中,一个硬盘在一个时间只存取一位的信息。没错,就是这么恐怖。如图中所示,左边的为数据阵列,阵列中的每个硬盘一次只存储一个位的数据。同理,右边的阵列(我们称之为校验阵列)则是存储相应的汉明码,也是一位一个硬盘。所以RAID 2中的硬盘数量取决于所设定的数据存储宽度。如果是4位的数据宽度(这由用户决定),那么就需要4个数据硬盘和3个汉明码校验硬盘,如果是64位的位宽呢?从上文介绍的计算方法中,就可以算出来,数据阵列需要64块硬盘,校验阵列需要7块硬盘。
在写入时,RAID 2在写入数据位同时还要计算出它们的汉明码并写入校验阵列,读取时也要对数据即时地进行校验,最后再发向系统。通过上文的介绍,我们知道汉明码只能纠正一个位的错误,所以RAID 2也只能允许一个硬盘出问题,如果两个或以上的硬盘出问题,RAID 2的数据就将受到破坏。但由于数据是以位为单位并行传输,所以传输率也相当快。
RAID 2是早期为了能进行即时的数据校验而研制的一种技术(这在当时的RAID 0、1等级中是无法做到的),从它的设计上看也是主要为了即时校验以保证数据安全,针对了当时对数据即时安全性非常敏感的领域,如服务器、金融服务等。但由于花费太大(其实,从上面的分析中可以看出如果数据位宽越大,用于校验阵列的相对投资就会越小,就如上面的4:3与64:7),成本昂贵,目前已基本不再使用,转而以更高级的即时检验RAID所代替,如RAID 3、5等。
现在让我们总结一下RAID 2的特点:
RAID-3等级
Parallel transfer with parity(并行传输及校验)
RAID 2等级的缺点相信大家已经很明白了,虽然能进行即时的ECC,但成本极为昂贵。为此,一种更为先进的即时ECC的RAID等级诞生,这就是RAID 3。
RAID 3是在RAID 2基础上发展而来的,主要的变化是用相对简单的异或逻辑运算(XOR,eXclusive OR)校验代替了相对复杂的汉明码校验,从而也大幅降低了成本。XOR的校验原理如下表:
A值 | B值 | XOR结果 |
0 | 0 | 0 |
1 | 0 | 1 |
0 | 1 | 1 |
1 | 1 | 0 |
这里的A与B值就代表了两个位,从中可以发现,A与B一样时,XOR结果为0,A与B不一样时,XOR结果就是1,而且知道XOR结果和A与B中的任何一个数值,就可以反推出另一个数值。比如A为1,XOR结果为1,那么B肯定为0,如果XOR结果为0,那么B肯定为1。这就是XOR编码与校验的基本原理。
RAID 3的结构图如下:
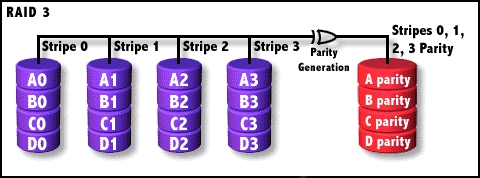
RAID-3结构图解
从图中可以发现,校验盘只有一个,而数据与RAID 0一样是分成条带(Stripe)存入数据阵列中,这个条带的深度的单位为字节而不再是bit了。在数据存入时,数据阵列中处于同一等级的条带的XOR校验编码被即时写在校验盘相应的位置,所以彼此不会干扰混乱。读取时,则在调出条带的同时检查校验盘中相应的XOR编码,进行即时的ECC。由于在读写时与RAID 0很相似,所以RAID 3具有很高的数据传输效率。
RAID 3在RAID 2基础上成功地进行结构与运算的简化,曾受到广泛的欢迎,并大量应用。直到更为先进高效的RAID 5出现后,RAID 3才开始慢慢退出市场。下面让我们总结一下RAID 3的特点:
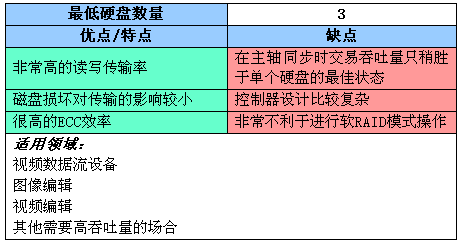
注:主轴同步是指阵列中所有硬盘的主轴马达同步
RAID-4等级
Independent Data disks with shared Parity disk(独立的数据硬盘与共享的校验硬盘)
RAID 3 英文定义是Parallel transfer with parity,即并行传输及校验。与之相比,RAID 4则是一种相对独立的形式,这也是它与RAID 3的最大不同。
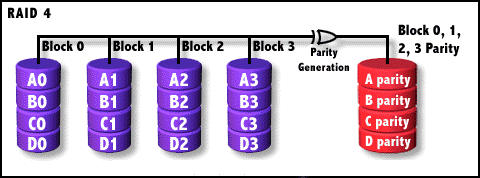
RAID-4结构图解
与RAID 3相比,我们发现关键之处是把条带改成了“块”。即RAID 4是按数据块为单位存储的,那么数据块应该怎么理解呢?简单的话,一个数据块是一个完整的数据集合,比如一个文件就是一个典型的数据块。当然,对于硬盘的读取,一个数据块并不是一个文件,而是由操作系统所决定的,这就是我们熟悉的簇(Cluster)。RAID 4这样按块存储可以保证块的完整,不受因分条带存储在其他硬盘上而可能产生的不利影响(比如当其他多个硬盘损坏时,数据就完了)。
不过,在不同硬盘上的同级数据块也都通过XOR进行校验,结果保存在单独的校验盘。所谓同级的概念就是指在每个硬盘中同一柱面同一扇区位置的数据算是同级。在写入时,RAID就是按这个方法把各硬盘上同级数据的校验统一写入校验盘,等读取时再即时进行校验。因此即使是当前硬盘上的数据块损坏,也可以通过XOR校验值和其他硬盘上的同级数据进行恢复。由于RAID 4在写入时要等一个硬盘写完后才能写一下个,并且还要写入校验数据所以写入效率比较差,读取时也是一个硬盘一个硬盘的读,但校验迅速,所以相对速度更快。总之,RAID 4并不为速度而设计。下面我们总结一下RAID 4的特点:
RAID-5等级
Independent Data disks with distributed parity blocks(独立的数据磁盘与分布式校验块)
今天我们将介绍在高级RAID系统中最常见的等级——RAID 5,由于其出色的性能与数据冗余平衡设计而被广泛采用。与RAID 3、4一样,它也是一种即时校验RAID系统,但设计更为巧妙,而管理也相对复杂。其结构见图:

RAID-5结构图解
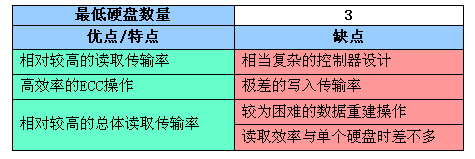
与RAID 4相对照,我们可以发现它仍采用了数据块的存储方式,但没有独立的校验硬盘,这是因为它在每个独立的数据盘中都开辟了单独的区域用于存储同级数据的XOR校验数据,至于什么是同级数据,在上一期中已经讲过了。在写入时,同级校验数据将即时生成并写入,在读取时,同级校验数据也将被即时读出并检查源数据的正确性。从图中可以发现,RAID 5的硬盘利用率较高,数据吞吐量比较容易得到发挥。
RAID 5是目前最常用的高级RAID等级,是RAID 3、4的理想替代者,许多高档RAID控制器都提供了对RAID 5的支持,并以此做为高档RAID系统的标志。
下面就来总结一下RAID 5的特点:

RAID-6等级
Independent Data disks with two independent distributed parity schemes(独立的数据硬盘与两个独立分布式校验方案)
RAID 6等级是在RAID 5基础上,为了进一步加强数据保护而设计的一种RAID方式,实际上是一种扩展RAID 5等级。与RAID 5的不同之处于除了每个硬盘上都有同级数据XOR校验区外,还有一个针对每个数据块的XOR校验区。当然,当前盘数据块的校验数据不可能存在当前盘而是交错存储的,具体形式见图。
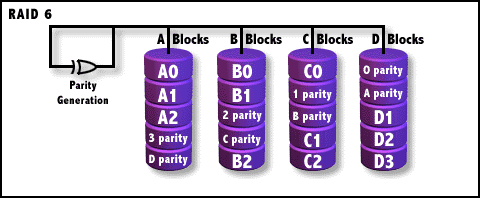
RAID-6结构图解
这样一来,等于每个数据块有了两个校验保护屏障(一个分层校验,一个是总体校验),因此RAID 6的数据冗余性能相当好。但是,由于增加了一个校验,所以写入的效率较RAID 5还差,而且控制系统的设计也更为复杂,第二块的校验区也减少了有效存储空间。
由于RAID 6相对于RAID 5在校验方面的微弱优势和在性能与性价比方面的较大劣势,RAID 6等级基本没有实际应用过,只是对更高级的数据的冗余进行的一种技术与思路上的尝试,下面我们就做一个总结:
RAID-7等级
Optimized Asynchrony for High I/O Rates as well as High Data Transfer Rates(最优化的异步高I/O速率和高数据传输率)
RAID 7等级是至今为止,理论上性能最高的RAID模式,因为它从组建方式上就已经和以往的方式有了重大的不同。基本成形式见图,你会发现在,以往一个硬盘是一个组成阵列的“柱子”,而在RAID 7中,多个硬盘组成一个“柱子”,它们都有各自的通道,也正因为如此,你可以把这个图分解成一个个硬盘连接在主通道上,只是比以前的等级更为细分了。这样做的好处就是在读/写某一区域的数据时,可以迅速定位,而不会因为以往因单个硬盘的限制同一时间只能访问该数据区的一部分,在RAID 7中,以前的单个硬盘相当于分割成多个独立的硬盘,有自己的读写通道,效率也就不言自明了。

RAID-7结构图解
然而,RAID 7的设计与相应的组成规模注定了它是一揽子承包计划。总体上说,RAID 7是一个整体的系统,有自己的操作系统,有自己的处理器,有自己的总线,而不是通过简单的插卡就可以实现的。归纳起来,RAID 7的主要特性如下:
所有的I/O传输都是异步的,因为它有自己独立的控制器和带有Cache的接口,与系统时钟并不同步
所有的读与写的操作都将通过一个带有中心Cache的高速系统总线,我们称之为X-Bus
专用的校验硬盘可以用于任何通道
带有完整功能的即时操作系统内嵌于阵列控制微处理器,这是RAID 7的心脏,它负责各通道的通信以及Cache的管理,这也是它与其他等级最大不同之一
连通性:可增至12个主机接口
扩展性:线性容量可增至48个硬盘
开放式系统,运用标准的SCSI硬盘、标准的PC总线、主板以及SIMM内存
高速的,集成Cache的数据总线(就是上文提到的X-bus)
在Cache内部完成校验生成工作
多重的附加驱动可以随时热机待命,提高冗余率和灵活性
易管理性:SNMP(Simple Network Management Protocol,简单网络管理协议) 可以让管理员远程监视并实现系统控制
按照RAID 7设计者的说法,这种阵列将比其他RAID等级提高150-600%写入时的I/O性能,虽然这引起了不小的争议。
RAID 7已经被SCC公司(Storage Computer Corporation)注册了商标,下面就让我们做一个总结:
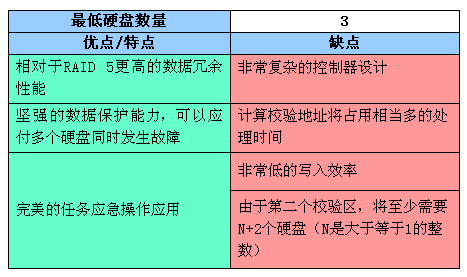
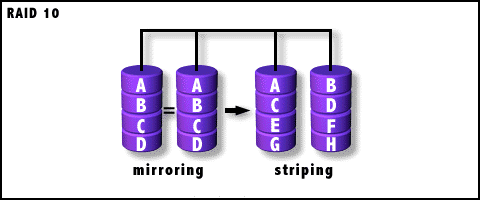
RAID-10等级
Very High Reliability combined with High Performance(高可靠性与高性能的组合)
现在我们将进入对组合RAID等级的介绍,所谓组合RAID是指在这个RAID等级中是由多个RAID等级(一般是两个)组合而成,RAID 10即是如此。
RAID 10是建立在RAID 0和RAID 1基础上的,具体的组合结构看图:
RAID-10结构图解
从中可以看出,RAID 1在这里就是一个冗余的备份阵列,而RAID 0则负责数据的读写阵列。其实,图1只是一种RAID 10方式,更多的情况是从主通路分出两路(以4个硬盘时为例),做Striping操作,即把数据分割,而这分出来的每一路则再分两路,做Mirroring操作,即互做镜像。这就是RAID 10名字的来历(也因此被很多人称为RAID 0+1),而不是像RAID 5、3那样的全新等级。
由于利用了RAID 0极高的读写效率和RAID 1较高的数据保护、恢复能力,使RAID 10成为了一种性价比较高的等级,目前几乎所有的RAID控制卡都支持这一等级。但是,RAID 10对存储容量的利用率和RAID 1一样低,只有50%。下面就让我们总结一下它的特点:

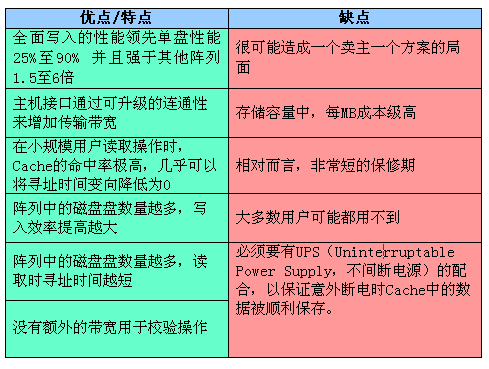
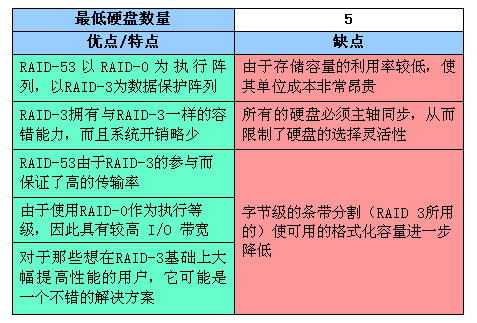
RAID-53等级
High I/O Rates and Data Transfer Performance(高带宽与数据传输性能)
与RAID 10一样,RAID 53也是一种组合RAID 等级,但不要拿RAID 10的观点套用,认为它是RAID 5和RAID 3的组合,事实上,RAID 53应该称为RAID 30或RAID 03(也可以说是RAID 0+3),即RAID 3与RAID 0的组合,具体形式见图:
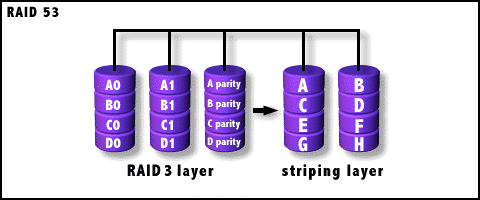
RAID-53结构图解
与图1相对比,可以发现,RAID 53中将备份等级由RAID 0变为了RAID 3,也就是说把原来的镜像阵列变成了分割式(Segments)存储阵列。但它不是对每个RAID 0硬盘都用一个RAID 3系统进行,而是用RAID 3对所有数据进行冗余存储(或者说是校验),而且读写与ECC效率比RAID 0要高不少。
值得注意的是,RAID 3在RAID 53的数据传输中占有相当重要的位置。在介绍RAID 3时,曾说过它有很高的读写传输率。因此,在进行大数据量吞吐时,由于RAID 3的传输率高的缘故,RAID 53的性能要比RAID 10好(因为冗余备份的时间缩短)。而且,借助于RAID 0,其I/O带宽并没有降低。不过,从它的配置形式上就可以看出来,它的存储空间利用率要比RAID 10低,为40%。下面就让我们总结一下RAID 53的特点:
结束语
至此,有关RAID各主要等级的介绍就到此告一段落了。但本文所介绍的并不是全部的RAID等级,比如RAID 50(5+0)、RAID 51(5+1)以及最新的RAID 100。其中,前两者都是组合RAID等级,从括号中的名字上就可以看出组合的方式。
RAID 100则是在RAID 1基础上改进而成,提高了读敢效率(RAID 100采用了独特的写入方式,以两个硬盘为例,数据的一半从第一个硬盘的最外圈磁道和第二个硬盘的最内圈存起,另一半则从第一个硬盘的最内圈和第二个硬盘的最外圈磁道存起,配合专用的读取算法,使两个硬盘的外圈磁道交替工作,由于总是尽可能地从外道开始读取,所以提高了读取效率)。以上三种等级由于知名度较低,而且现在还很少见到应用,就不在此详细介绍了。
另外值得一提的是Intel准备在未来的ICH-6R上提供的Matrix RAID功能,它可以用两硬盘通过逻辑卷的功能组成RAID-0和RAID-1两种模式的阵列,具体结构见下图:
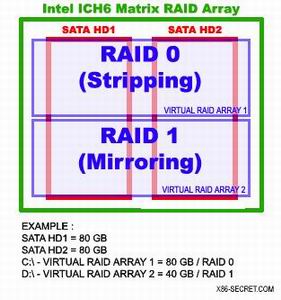
Matrix RAID结构图解
很明显,以这新闻的例子分析,每个硬盘分出40GB分别用于RAID 0和1,用于RAID 0的是分区C,容量是40+40=80GB,用于RAID 1的是分区D,容量是(40+40)/2=40GB。由于Matrix RAID还没有真正交付应用,我们在此也就不具体介绍了。
好啦,本期RAID专题就到此结束了,有关RAID的话题欢迎大家来到http://blog.csdn.net/21aspnet来进一步讨论!
相关文章:

Ampere 携手 Rigetti 开发混合量子经典计算机
该合作旨在为价值 160 亿美元的机器学习市场提供服务,赋能机器学习应用的发展双方将把 Ampere Altra Max 处理器和 Rigetti 量子处理单元进行优化结合,为机器学习提供整合的云平台 2022 年 2 月 21 日,安晟培半导体科技有限公司(A…

[C++] NULL VS nullptr
NULL VS nullptr 转载于:https://www.cnblogs.com/tianhangzhang/p/4945623.html

swift 的defer使得资源的分配和释放代码可以放到一起
只是一种语法和逻辑上的优化

烂泥:haproxy学习之手机规则匹配
2019独角兽企业重金招聘Python工程师标准>>> 本文由ilanniweb提供友情赞助,首发于烂泥行天下 想要获得更多的文章,可以关注我的微信ilanniweb。 今天我们来介绍下有关haproxy匹配手机的一些规则配置。 一、业务需要 现在根据业务的实际需要&a…
jQuery日期选择器插件date-input
官网:http://jonathanleighton.com/projects/date-input/下载: http://ajax.googleapis.com/ajax/libs/jquery/1.3.1/jquery.min.js http://github.com/jonleighton/date_input/raw/master/jquery.date_input.js http://github.com/jonleighton/date_inp…

厉害了,用Python绘制动态可视化图表,并保存成gif格式
作者 | 俊欣来源 | 关于数据分析与可视化最近有粉丝问道说“是不是可以将这些动态的可视化图表保存成gif图”,小编立马就回复了说后面会写一篇相关的文章来介绍如何进行保存gif格式的文件。那么我们就开始进入主题,来谈一下Python当中的gif模块。安装相关…
facade-门面模式
解决问题 客户端调用逻辑与业务代码有效隔离,使得客户端调用只和Facade进行交互,内部的调用逻辑由Facade进行实现。此模式也可以和接口化编程结合,进一步降低客户端与业务逻辑的耦合 应用场景 它主要应用在代码结构的设计,合理组织…
淘宝李晓拴:淘宝网PHP电子商务应用
源自:http://tech.qq.com/a/20110512/000298.htm 大家好,大家知道淘宝搜索是一个典型PHP架构。在座同学不知道有多少人使用过淘宝搜索可以举手示意一下?在开始这个话题之前我们先谈一下Polyglot,多语言混合编程,淘宝有…

玩爬虫不会登陆?这个工具拿走不谢!
作者 | 周萝卜来源 | 萝卜大杂烩在日常学习当中,我们或多或少都会到网上抓取一些数据,比如豆瓣、微博等等,但是这些网站在非登录的情况只能拿到部分数据,有很多数据都是需要登陆之后才可以获取的,那么模拟登陆就成为了…
Oracle分页
先看以下两条语句的执行结果: 语句一:select rownum,empno,sal from emp order by empno; ROWNUM EMPNO SAL ---------- ---------- ---------- 1 7369 800 2 7499 1600 3 7521 …
Scala类型系统——高级类类型(higher-kinded types)
高级类类型就是使用其他类型构造成为一个新的类型,因此也称为 类型构造器(type constructors)。它的语法和高阶函数(higher-order functions)相似,高阶函数就是将其它函数作为参数的函数;高级类类型则是将构造类类型作为参数类型。一个高级类…
android休眠唤醒驱动流程分析【转】
转自:http://blog.csdn.net/hanmengaidudu/article/details/11777501标准linux休眠过程:l power management notifiers are executed with PM_SUSPEND_PREPAREl tasks are frozenl target system sleep state is announced to the …
PHP使用curl_multi_add_handle并行处理
http://www.php.net/manual/zh/function.curl-multi-add-handle.php<?php// 创建一对cURL资源$ch1 curl_init();$ch2 curl_init();// 设置URL和相应的选项curl_setopt($ch1, CURLOPT_URL, "http://www.baidu.com/");curl_setopt($ch1, CURLOPT_HEADER, 0);curl…

斯坦福团队是如何构建更好用的聊天 AI 呢?
作者:Standford AI译者:Yang来源:数据实战派2019 年,凭借着 Chirpy Cardinal 机器人,斯坦福首次在 Alexa Prize Socialbot Grand Challenge 3 中赢得了第二名。本文将进一步揭示 Chirpy Cardinal 开发细节,…
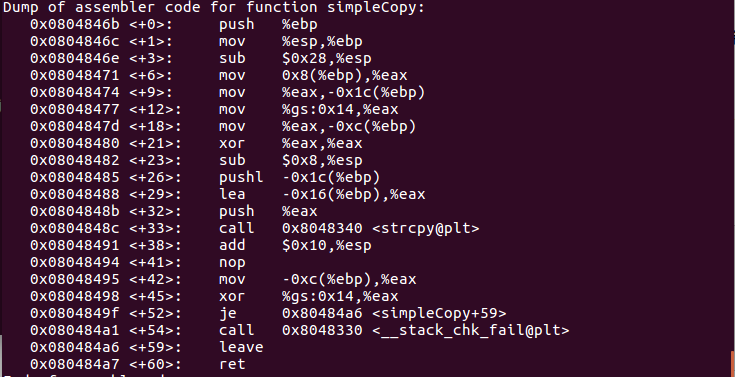
使用Linux进行缓冲区溢出实验的配置记录
在基础的软件安全实验中,缓冲区溢出是一个基础而又经典的问题。最基本的缓冲区溢出即通过合理的构造输入数据,使得输入数据量超过原始缓冲区的大小,从而覆盖数据输入缓冲区之外的数据,达到诸如修改函数返回地址等目的。但随着操作…
Javascript导出Excel的方法
<SCRIPT LANGUAGE"javascript"> function method1(tableid) {//整个表格拷贝到EXCEL中 var curTbl document.getElementById(tableid); var oXL new ActiveXObject("Excel.Application"); //创建AX对象excel var oWB oXL.Workbooks.Add(); //获取…

Top 15 不起眼却有大作用的 .NET功能集
目录1. ObsoleteAttribute2. 设置默认值属性: DefaultValueAttribute3. DebuggerBrowsableAttribute4. ??运算符5. Curry 及 Partial 方法6. WeakReference7. Lazy8. BigInteger9. 非官方关键字:__arglist __reftype __makeref __…
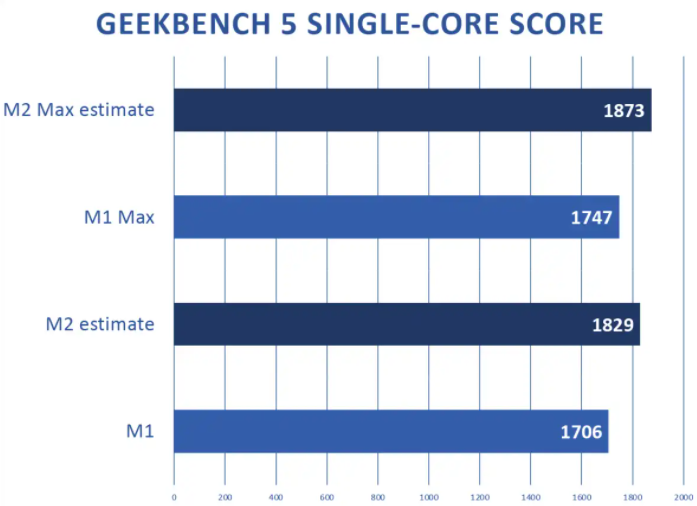
M2 芯片终于要来了?全线换新,性能远超M1 Max
不知不觉日历已翻至 2 月下旬,掐指一算,距离苹果一年一度春季新品发布会的召开似乎已越来越近。根据年初统计的 2022 年苹果新品预测,预计今年的苹果“小春晚”将在 Mac 方面有大动作。 那么,苹果将如何“动作”,又…

Python抓取新浪新闻数据(三)
非同步载入一般在XHR下查找,但是没有发现XHR下有相关内容。 转载于:https://blog.51cto.com/2290153/2126862

不畏浮云遮望眼--离散数学和组合数学
不畏浮云遮望眼,基础很重要!离散数学是算法和数据结构的基础,而算法和数据结构又是什么的基础?不解释了。1.《离散数学及其应用》作者: (美)Kenneth H. R出版社: 机械工业出版社出版年: 2007-6页数: 804定价: 79.00元丛书: 计算机…
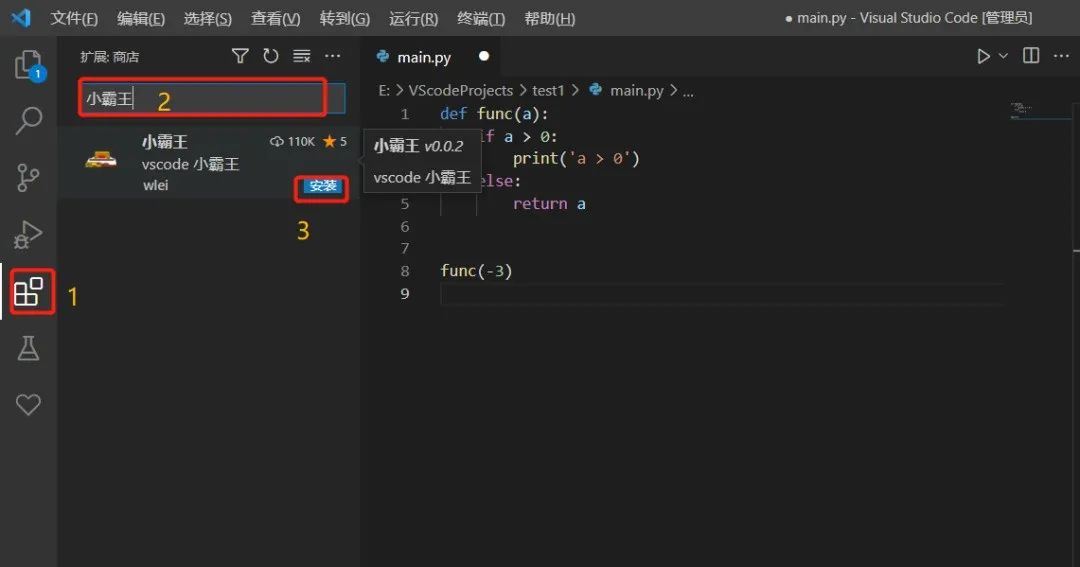
上班摸鱼,刚刚发现在 VScode 中可玩魂斗罗,超级玛丽
今天,再给大家介绍一款更加有意思的vscode插件——“小霸王”。 GitHub传送门:https://github.com/gamedilong/anes-repository 安装方式: 对于插件的安装,可以按照上图的操作流程。 1.打开VScode,然后点击拓展。 2.在输入框中&am…
JSP 三 :九大隐式对象
2019独角兽企业重金招聘Python工程师标准>>> ###细节 每个JSP页面在第一次被访问时,web容器都会把请求交给JSP引擎(即一个Java程序)去处理。JSP引擎先将JSP翻译成一个_jspServlet(实质上也是一个servlet),然后按照servlet的调用方…

阿里90后工程师利用ARM硬件特性开启安卓8终端“上帝模式”
文/图 阿里安全潘多拉实验室 团控 编者按:团控,阿里安全潘多拉实验室研究人员,该实验室主要聚焦于移动安全领域,包括对iOS和Android系统安全的攻击和防御技术研究。团控的主攻方向为安卓系统级漏洞的攻防研究。在今年3月的BlackHa…
c语言模拟实现oc引用计数
#include<stdio.h> #include<stdlib.h> //在c中引入 引用计数机制 // 要解决的问题: 1,指向某块动态内存的指针有几个? // 应该让这块动态内存记录指针的数量 // 所以开辟的动态内存大小应该取多大? // …
ATT与Intel汇编语言的比较
转自 陈莉君 一书《深入分析Linux内核源码》 http://www.kerneltravel.net/kernel-book/第二章%20Linux运行的硬件基础/2.6.1.htm2.6.1 AT&T与Intel汇编语言的比较我们知道,Linux是Unix家族的一员,尽管Linux的历史不长,但与其相关的很多事…

最近,又发现了 Pandas 中三个好用的函数
作者 | luanhz来源 | 小数志导读近日,在github中查看一些他人提交的代码时,发现了Pandas中这三个函数,在特定场景中着实好用,遂成此文以作分享。程序的基本结构大体包含三种,即顺序结构、分支结构和循环结构࿰…
Java Web的Maven项目中Properties文件的使用(2)
为什么80%的码农都做不了架构师?>>> 背景 Java Web中常用一些Properties文件进行部署配置,其中如果在里面配置OS的路径,需要跨平台,主要就是考虑win系统的路径是“\”,而Linux的路径是“/”。 …
TCP/IP 计算机网络协议
2019独角兽企业重金招聘Python工程师标准>>> 应用层: (典型设备:应用程序,如FTP,SMTP ,HTTP) DHCP(Dynamic Host Configuration Protocol)动态主机分配协议,使用 UDP 协议工作,主要有两个用途:给…

5分钟速通 AI 计算机视觉发展应用
作者 | 李秋键 出品 | AI科技大本营(ID:rgznai100) 计算机视觉是进步最大、发展最快的领域之一。根据 Global VIEW 的研究,全球计算机视觉市场规模在 2020 的价值为 113 亿 2000 万美元,预计从2021 到 2028 的复合年增长率为 7.3%…
javascript解析json
下载json库 http://www.json.org/json-zh.html自己找javascript的 或者直接去下面的 https://github.com/douglascrockford/JSON-jsphp生成json格式使用页面 <script src"scripts/json.js"></script>alert(data.toJSONString());如果返回false说明没数据…