一文介绍机器学习中的三种特征选择方法

作者 | luanhz
来源 | 小数志
导读
机器学习中的一个经典理论是:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。也正因如此,特征工程在机器学习流程中占有着重要地位。广义的特征工程一般可分为三个环节:特征提取、特征选择、特征衍生,三个环节并无明确的先手顺序之分。本文主要介绍三种常用的特征选择方法。

机器学习中的特征需要选择,人生又何尝不是如此?
特征选择是指从众多可用的特征中选择一个子集的过程,其目的和预期效果一般有如下三方面考虑:
改善模型效果,主要是通过过滤无效特征或者噪声特征来实现;
加速模型训练,更为精简的特征空间自然可以实现模型训练速度的提升
增强特征可解释性,这方面的作用一般不是特别明显,比如存在共线性较高的一组特征时,通过合理的特征选择可仅保留高效特征,从而提升模型的可解释性
另一方面,理解特征选择方法的不同,首先需要按照特征对训练任务的价值高低而对特征作出如下分类:
高价值特征,这些特征对于模型训练非常有帮助,特征选择的目的就是尽可能精准的保留这些特征
低价值特征,这些特征对模型训练帮助不大,但也属于正相关特征,在特征选择比例较低时,这些特征可以被舍弃;
高相关性特征,这些特征对模型训练也非常有帮助,但特征与特征之间往往相关性较高,换言之一组特征可由另一组特征替代,所以是存在冗余的特征,在特征选择中应当将其过滤掉;
噪声特征,这些特征对模型训练不但没有正向作用,反而会干扰模型的训练效果。有效的特征选择方法应当优先将其滤除。
在实际应用中,特征选择方法主要可分为如下三类:
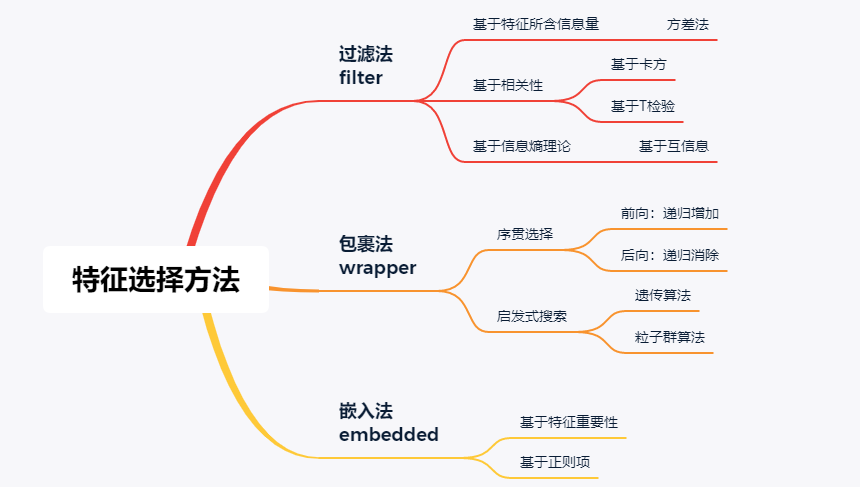
本文将围绕这三种方法分别介绍,最后以sklearn中自带的数据集为例给出简单的应用和效果对比。
01 过滤法
基于过滤法(Filter)实现特征选择是最为简单和常用的一种方法,其最大优势是不依赖于模型,仅从特征的角度来挖掘其价值高低,从而实现特征排序及选择。实际上,基于过滤法的特征选择方案,其核心在于对特征进行排序——按照特征价值高低排序后,即可实现任意比例/数量的特征选择或剔除。显然,如何评估特征的价值高低从而实现排序是这里的关键环节。
为了评估特征的价值高低,大体可分为如下3类评估标准:
基于特征所含信息量的高低:这种一般就是特征基于方差法实现的特征选择,即认为方差越大对于标签的可区分性越高;否则,即低方差的特征认为其具有较低的区分度,极端情况下当一列特征所有取值均相同时,方差为0,对于模型训练也不具有任何价值。当然,实际上这里倘若直接以方差大小来度量特征所含信息量是不严谨的,例如对于[100, 110, 120]和[1, 5, 9]两组特征来说,按照方差计算公式前者更大,但从机器学习的角度来看后者可能更具有区分度。所以,在使用方差法进行特征选择前一般需要对特征做归一化
基于相关性:一般是基于统计学理论,逐一计算各列与标签列的相关性系数,当某列特征与标签相关性较高时认为其对于模型训练价值更大。而度量两列数据相关性的指标则有很多,典型的包括欧式距离、卡方检验、T检验等等
基于信息熵理论:与源于统计学的相关性方法类似,也可从信息论的角度来度量一列特征与标签列的相关程度,典型的方法就是计算特征列与标签列的互信息。当互信息越大时,意味着提供该列特征时对标签的信息确定程度越高。这与决策树中的分裂准则思想其实是有异曲同工之妙
当然,基于过滤法的特征选择方法其弊端也极为明显:
因为不依赖于模型,所以无法有针对性的挖掘出适应模型的最佳特征体系;
特征排序以及选择是独立进行(此处的独立是指特征与特征之间的独立,不包含特征与标签间的相关性计算等),对于某些特征单独使用价值低、组合使用价值高的特征无法有效发掘和保留。
02 包裹法
过滤法是从特征重要性高低的角度来加以排序,从而完成目标特征选择或者低效特征滤除的过程。如前所述,其最大的弊端之一在于因为不依赖任何模型,所以无法针对性的选择出相应模型最适合的特征体系。同时,其还存在一个隐藏的问题:即特征选择保留比例多少的问题,实际上这往往是一个超参数,一般需要人为定义或者进行超参寻优。
与之不同,包裹法将特征选择看做是一个黑盒问题:即仅需指定目标函数(这个目标函数一般就是特定模型下的评估指标),通过一定方法实现这个目标函数最大化,而不关心其内部实现的问题。进一步地,从具体实现的角度来看,给定一个含有N个特征的特征选择问题,可将其抽象为从中选择最优的K个特征子集从而实现目标函数取值最优。易见,这里的K可能是从1到N之间的任意数值,所以该问题的搜索复杂度是指数次幂:O(2^N)。
当然,对于这样一个具有如此高复杂度的算法,聪明的前辈们是不可能去直接暴力尝试的,尤其是考虑这个目标函数往往还是足够expensive的(即模型在特定的特征子集上的评估过程一般是较为耗时的过程),所以具体的实现方式一般有如下两种:
序贯选择。美其名曰序贯选择,其实就是贪心算法。即将含有K个特征的最优子空间搜索问题简化为从1->K的递归式选择(Sequential Feature Selection, SFS)或者从N->K的递归式消除(Sequential Backward Selection, SBS)的过程,其中前者又称为前向选择,后者相应的称作后向选择。
具体而言,以递归式选择为例,初始状态时特征子空间为空,尝试逐一选择每个特征加入到特征子空间中,计算相应的目标函数取值,执行这一过程N次,得到当前最优的第1个特征;如此递归,不断选择得到第2个,第3个,直至完成预期的特征数目K。这一过程的目标函数执行次数为O(K^2),相较于指数次幂的算法复杂度而言已经可以接受。当然,在实际应用过程中还衍生了很多改进算法,例如下面流程图所示:
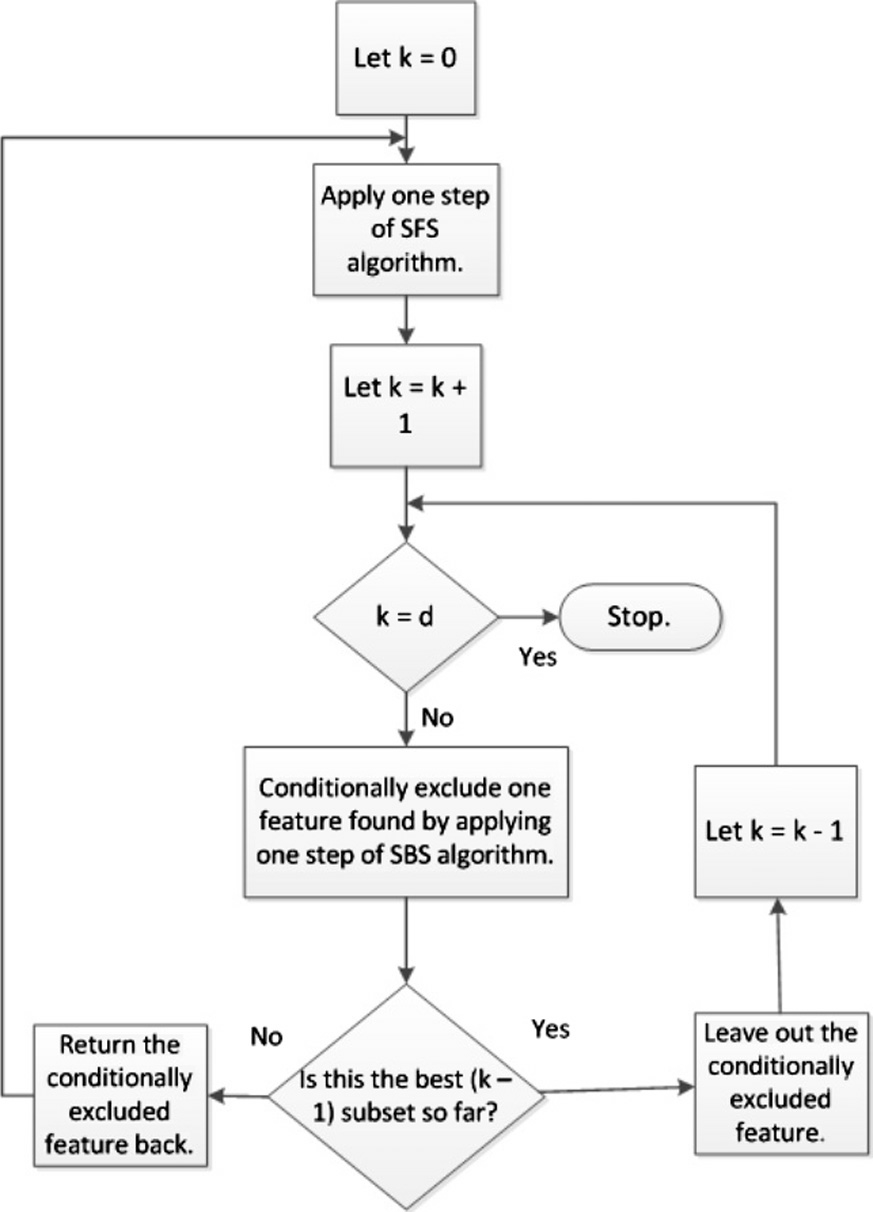
图源:《A survey on feature selection methods》
启发式搜索。启发式搜索一般是应用了进化算法,例如在优化领域广泛使用的遗传算法。在具体实现中,需要考虑将特征子空间如何表达为种群中的一个个体(例如将含有N个特征的选择问题表达为长度为N的0/1序列,其中1表示选择该特征,0表示不选择,序列中1的个数即为特征子空间中的特征数量),进而可将模型在相应特征子空间的效果定义为对应个体在种群中的适应度;其次就是定义遗传算法中的主要操作:交叉、变异以及繁殖等进化过程。
基于包裹法的特征选择方案是面向模型的实现方案,所以理论而言具有最佳的选择效果。但实际上在上述实现过程中,其实一般也需要预先指定期望保留的特征数量,所以也就涉及到超参的问题。此外,基于包裹法的最大缺陷在于巨大的计算量,虽然序贯选择的实现方案将算法复杂度降低为平方阶,但仍然是一个很大的数字;而以遗传算法和粒子群算法为代表的启发式搜索方案,由于其均是population-based的优化实现,自然也更是涉及大量计算。
03 嵌入法
与包裹法依赖于模型进行选择的思想相似,而又与之涉及巨大的计算量不同:基于嵌入法的特征选择方案,顾名思义,是将特征选择的过程"附着"于一个模型训练任务本身,从而依赖特定算法模型完成特征选择的过程。
个人一直以为,"嵌入"(embedded)一词在机器学习领域是一个很魔性的存在,甚至在刚接触特征选择方法之初,一度将嵌入法和包裹法混淆而不能感性理解。
实际上,行文至此,基于嵌入法的特征选择方案也就呼之欲出了,最为常用的就是树模型和以树模型为基础的系列集成算法,由于模型提供了特征重要性这个重要信息,所以其可天然的实现模型价值的高低,从而根据特征重要性的高低完成特征选择或滤除的过程。另外,除了决策树系列模型外,LR和SVM等广义线性模型也可通过拟合权重系数来评估特征的重要程度。
基于嵌入法的特征选择方案简洁高效,一般被视作是集成了过滤法和包裹法两种方案的优点:既具有包裹法中面向模型特征选择的优势,又具有过滤法的低开销和速度快。但实际上,其也具有相应的短板:不能识别高相关性特征,例如特征A和特征B都具有较高的特征重要性系数,但同时二者相关性较高,甚至说特征A=特征B,此时基于嵌入法的特征选择方案是无能为力的。
04 三种特征选择方案实战对比
本小节以sklearn中的乳腺癌数据集为例,给出三种特征选择方案的基本实现,并简单对比特征选择结果。
加载数据集并引入必备包:
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectFromModel, SelectKBest, RFE
from sklearn.ensemble import RandomForestClassifier默认数据集训练模型,通过在train_test_split中设置随机数种子确保后续切分一致:
%%time
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=3)rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_train, y_train)
rf.score(X_test, y_test)# 输出结果
CPU times: user 237 ms, sys: 17.5 ms, total: 254 ms
Wall time: 238 ms
0.9370629370629371过滤法的特征选择方案,调用sklearn中的SelectKBest实现,内部默认采用F检验来度量特征与标签间相关性,选择特征维度设置为20个:
%%time
X_skb = SelectKBest(k=20).fit_transform(X, y)
X_skb_train, X_skb_test, y_train, y_test = train_test_split(X_skb, y, random_state=3)rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_skb_train, y_train)
rf.score(X_skb_test, y_test)# 输出结果
CPU times: user 204 ms, sys: 7.14 ms, total: 211 ms
Wall time: 208 ms
0.9300699300699301包裹法的特征选择方案,调用sklearn中的RFE实现,传入的目标函数也就是算法模型为随机森林,特征选择维度也设置为20个:
%%time
X_rfe = RFE(RandomForestClassifier(), n_features_to_select=20).fit_transform(X, y)
X_rfe_train, X_rfe_test, y_train, y_test = train_test_split(X_rfe, y, random_state=3)rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_rfe_train, y_train)
rf.score(X_rfe_test, y_test)# 输出结果
CPU times: user 2.76 s, sys: 4.57 ms, total: 2.76 s
Wall time: 2.76 s
0.9370629370629371嵌入法的特征选择方案,调用sklearn中的SelectFromModel实现,依赖的算法模型也设置为随机森林,特征选择维度仍然是20个:
%%time
X_sfm = SelectFromModel(RandomForestClassifier(), threshold=-1, max_features=20).fit_transform(X, y)
X_sfm_train, X_sfm_test, y_train, y_test = train_test_split(X_sfm, y, random_state=3)rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_sfm_train, y_train)
rf.score(X_sfm_test, y_test)# 输出结果
CPU times: user 455 ms, sys: 0 ns, total: 455 ms
Wall time: 453 ms
0.9370629370629371通过以上简单的对比实验可以发现:相较于原始全量特征的方案,在仅保留20维特征的情况下,过滤法带来了一定的算法性能损失,而包裹法和嵌入法则保持了相同的模型效果,但嵌入法的耗时明显更短。

往
期
回
顾
资讯
Meta开发AI语音助手,助力元宇宙
技术
Pandas重复数据处理大全
技术
5个短小精悍的Python趣味脚本
资讯
M2芯片终于要来了?全线换新

分享

点收藏

点点赞

点在看
相关文章:

[转化率预估-1]引言
原文:hhttp://www.flickering.cn/ads/2014/06/%E8%BD%AC%E5%8C%96%E7%8E%87%E9%A2%84%E4%BC%B0%E2%80%94%E2%80%94%E5%BC%95%E8%A8%80/ 最近几年,“计算广告学”的概念风生水起,让我们这些从事在线广告匹配技术的程序猿着实荣耀了一把。这在参…

reportNG定制化之失败截图及日志
先从github上拉下 reportNg的源代码 reportng 拉下源码后我们使用IDEA进行导入 1、reportng.properties 增加部分类表项 这里我们直接在末尾添加 logLog Info screenshotScreen Shot durationDuration2、results.html.vm 修改结果的html,我们目前只修改fail的情况下…
基于 OpenCV 的手掌检测和手指计数
作者 | 努比 来源 | 小白学视觉 利用余弦定理使用OpenCV-Python实现手指计数与手掌检测。 手检测和手指计数 接下来让我们一起探索以下这个功能是如何实现的。 OpenCV OpenCV(开源计算机视觉库)是一个开源计算机视觉和机器学习软件库。OpenCV的构建旨在为…

side menu待研究
2019独角兽企业重金招聘Python工程师标准>>> http://fontawesome.bootstrapcheatsheets.com/ http://www.queness.com/post/14666/recreate-google-nexus-menu http://www.jqueryscript.net/demo/Sliding-Side-Menu-Panel-with-jQuery-Bootstrap-BootSideMenu/ &a…
Gitlab Issue Tracker and Wiki(一)
本节内容:创建第一个问题创建第一个合并请求接受合并请求工作里程碑在提交中引用问题创建维基百科页使用Gollum管理维基百科一. 创建问题1. 登陆Gitlab服务器2. 切换到想要创建问题的项目3. 点击Issues.4. 点击【New issue】5. 根据情况进行填写。二. 创建合并请求1…

runtime实践之Method Swizzling
利用 Objective-C 的 Runtime 特性,我们可以给语言做扩展,帮助解决项目开发中的一些设计和技术问题。这一篇,我们来探索一些利用 Objective-C Runtime 的黑色技巧。这些技巧中最具争议的或许就是 Method Swizzling 。 介绍一个技巧࿰…

网络协议关系拓扑图 很全面 很好
NETWORK ASSOCIATES GUIDE TO COMMUNICATIONS PROTOCOLS 网络协议关系拓扑图 很全面 很好 值得收藏!

一行代码搞定 Python 逐行内存消耗分析
作者 | 费弗里来源 | Python大数据分析我们即将学习的是:一行代码分析Python代码行级别内存消耗。很多情况下,我们需要对已经写好的Python程序的内存消耗进行优化,但是一段代码在运行过程中的内存消耗是动态变化的,这种时候就可以…
崛起于Springboot2.X之Mybatis-全注解方式操作Mysql(4)
为什么80%的码农都做不了架构师?>>> 1、使用注解方式对mysql增删改查,它很方便,不像一些逆向工程工具一样生成的都是乱七八糟,虽然很全的方法,完全手写sql 基于上一篇博客,我们只需要新建一个目录dao层&am…
hdu 1247
Problem DescriptionA hat’s word is a word in the dictionary that is the concatenation of exactly two other words in the dictionary.You are to find all the hat’s words in a dictionary.InputStandard input consists of a number of lowercase words, one per li…
php执行URL解析
方法一: $url"http://www.baidu.com";file_get_contents($url);方法二: // CURL 方法$url"http://www.baidu.com";$ch curl_init( );curl_setopt( $ch,CURLOPT_URL,$url );curl_setopt( $ch,CURLOPT_HEADER,0 );curl_setopt( $ch,…

Python 来分析,堪比“唐探系列”!B站9.5分好评如潮!
作者 | 菜鸟哥来源 | 菜鸟学PythonHello 小伙伴们,最近一部非常不错的悬疑侦探喜剧 电影,登上B站热榜!菜鸟哥看完之后,大呼过瘾,简直就是一本非常棒的"剧本杀"!演员都是实力派,演技超…
10进制转换为二十六进制字符串A-Z
def convert10to26(num): ...: 10进制转为26进制字母 A-Z, 输入参数10进制数num, 返回26位的字母A-Z 参数type: num: int return: str ...: ...: digit_list [] # 列表当栈使用,存储每次求余的结果 ...: while num !0: ...: digit_list.append(num%26)…

从hello world 说程序运行机制
http://www.cnblogs.com/yanlingyin/archive/2012/03/05/2379199.html 开篇 学习任何一门编程语言,都会从hello world 开始。对于一门从未接触过的语言,在短时间内我们都能用这种语言写出它的hello world。然而,对于hello world 这个简单程序…

爱耳日腾讯天籁行动再升级 助力100位青年听障人才打破“屏障”
公益是解决社会问题的重要切入口,科技是提升效率的强有力工具。当产业技术走入公益场景,科技也在发挥更大的社会价值。 《中国听力健康报告(2021)》显示,过度的噪音曝露,正让全球11亿年轻人面临听力受损的风…
IOS推送详解
为什么80%的码农都做不了架构师?>>> IOS推送详解 一.关于推送通知 推送通知,也被叫做远程通知,是在iOS 3.0以后被引入的功能。是当程序没有启动或不在前台运行时,告诉用户有新消息的一种途径,是从外部服务…
redis(4)
redis-cli -p 6380redis-cli -p 6379 info server | grep run_idpsync ? -1
PHP也玩并发,巧用curl 并发减少后端访问时间
说明:本人源自3篇博文 http://blog.csdn.net/zuiaituantuan/article/details/7048782首先,先了解下 php中的curl多线程函数:# curl_multi_add_handle# curl_multi_close# curl_multi_exec# curl_multi_getcontent# curl_multi_info_read# cur…
ADSL自动更换IP地址源代码
有些网站限制IP地址,什么一个IP地址只能一次之类的。特别是投票网址,为了防止刷票,限制1个IP只允许投票一次! 此程序采用Vs2010C#开发,提供全部源代码!方便程序猿朋友二次开发! 可以后台运行&am…
安全隐患:神经网络可以隐藏恶意软件
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 凭借数百万和数十亿的数值参数,深度学习模型可以做到很多的事情,例如,检测照片中的对象、识别语音、生成文本以及隐藏恶意软件。加州大学圣地亚哥分校和伊利诺伊大学…
实现一个完美符合Promise/A+规范的Promise
原文在我的博客中:原文地址 如果文章对您有帮助,您的star是对我最好的鼓励~ 简要介绍:Promise允许我们通过链式调用的方式来解决“回调地狱”的问题,特别是在异步过程中,通过Promise可以保证代码的整洁性和…
用递归法计算斐波那契数列的第n项
斐波纳契数列(Fibonacci Sequence)又称黄金分割数列,指的是这样一个数列:1、1、2、3、5、8、13、21、……在数学上,斐波纳契数列以如下被以递归的方法定义:F00,F11,FnF(n-1)F(n-2)&a…
ArrayList的内存泄露
2019独角兽企业重金招聘Python工程师标准>>> 大家先运行下下面这段代码,看看结果 public class MemoryLeak {public static void main(String[] args) throws InterruptedException {new Thread(new Runnable() {Overridepublic void run() {for (int i …

给 Python 初学者推荐的 IDE 哦!
作者 | 黄伟呢来源 | 数据分析与统计学之美总有一些Python初学者,会问到:学习Python,应该用什么Python IDE?了解到他们使用Python做什么之后,我总结了这篇文章。IDE是集成开发环境的缩写,通俗地说ÿ…
django 2.0路由配置变化
urlpatterns变量的语法 urlpatterns应该是path()和/或re_path()实例的Python列表。 首先,Django会使用根路由解析模块(root URLconf)来解析路由。 通常,这是ROOT_URLCONF设置的值,但是如果传入的HttpRequest对象具有urlconf属性ÿ…

用ext_skel,实现一个PHP扩展,添加到PHP并调用
http://www.shinrun.com/PHP 一、开始之前 1. 系统环境:FreeBSD 8.22. AP环境:即已经装好的Apache2.2.17、PHP5.3.8环境3. PHP源码:下载稳定版本源码到当前用户的目录,如,下载PHP 5.3.8到/usr/home/abc下。4. 其它要求…
关于第三方IOS的checkBox框架的使用
关于第三方IOS的checkBox框架的使用 这个框架是从github上下载获取的:M13Checkbox。 只是github的源码项目工程比较久远,所以我把代码部分拷贝到XCode 7.1.0新建的项目里。 下面是展示效果 客户端源码使用参考: 1 #import "ViewControll…

20 个 Pandas 数据实战案例,干货多多
作者 | 俊欣来源 | 关于数据分析与可视化今天我们讲一下pandas当中的数据过滤内容,小编之前也写过也一篇相类似的文章,但是是基于文本数据的过滤,大家有兴趣也可以去查阅一下。下面小编会给出大概20个案例来详细说明数据过滤的方法࿰…
Python创建和访问字典
>>> dict1 {a:1,b:2,c:3,d:4}>>> print(a的值是:,dict1[a])a的值是: 1>>> dict4 dict(我 快乐, 你 伤悲)SyntaxError: keyword cant be an expression>>> dict4[你] 改变悲伤>>> dict4{我: 快乐, 你: 改变悲伤}>>>…
C语言九阴真经
发现记忆力越来越差,所以干脆搞这么一个东西,就是把C语言的最常用的语法汇编在一起,不断完善。这样以后只要经常把这个回顾一下就可以了。不然去翻书太多了。。。f.h#define Area 1000 struct student{char *last_name;int student_id;char …