20 个 Pandas 数据实战案例,干货多多

作者 | 俊欣
来源 | 关于数据分析与可视化
今天我们讲一下pandas当中的数据过滤内容,小编之前也写过也一篇相类似的文章,但是是基于文本数据的过滤,大家有兴趣也可以去查阅一下。
下面小编会给出大概20个案例来详细说明数据过滤的方法,首先我们先建立要用到的数据集,代码如下
import pandas as pd
df = pd.DataFrame({"name": ["John","Jane","Emily","Lisa","Matt"],"note": [92,94,87,82,90],"profession":["Electrical engineer","Mechanical engineer","Data scientist","Accountant","Athlete"],"date_of_birth":["1998-11-01","2002-08-14","1996-01-12","2002-10-24","2004-04-05"],"group":["A","B","B","A","C"]
})output
name note profession date_of_birth group
0 John 92 Electrical engineer 1998-11-01 A
1 Jane 94 Mechanical engineer 2002-08-14 B
2 Emily 87 Data scientist 1996-01-12 B
3 Lisa 82 Accountant 2002-10-24 A
4 Matt 90 Athlete 2004-04-05 C筛选表格中的若干列
代码如下
df[["name","note"]]output
name note
0 John 92
1 Jane 94
2 Emily 87
3 Lisa 82
4 Matt 90再筛选出若干行
我们基于上面搜索出的结果之上,再筛选出若干行,代码如下
df.loc[:3, ["name","note"]]output
name note
0 John 92
1 Jane 94
2 Emily 87
3 Lisa 82根据索引来过滤数据
这里我们用到的是iloc方法,代码如下
df.iloc[:3, 2]output
0 Electrical engineer
1 Mechanical engineer
2 Data scientist通过比较运算符来筛选数据
df[df.note > 90]output
name note profession date_of_birth group
0 John 92 Electrical engineer 1998-11-01 A
1 Jane 94 Mechanical engineer 2002-08-14 Bdt属性接口
dt属性接口是用于处理时间类型的数据的,当然首先我们需要将字符串类型的数据,或者其他类型的数据转换成事件类型的数据,然后再处理,代码如下:
df.date_of_birth = df.date_of_birth.astype("datetime64[ns]")
df[df.date_of_birth.dt.month==11]output
name note profession date_of_birth group
0 John 92 Electrical engineer 1998-11-01 A或者我们也可以
df[df.date_of_birth.dt.year > 2000]output
name note profession date_of_birth group
1 Jane 94 Mechanical engineer 2002-08-14 B
3 Lisa 82 Accountant 2002-10-24 A
4 Matt 90 Athlete 2004-04-05 C多个条件交集过滤数据
当我们遇上多个条件,并且是交集的情况下过滤数据时,代码应该这么来写
df[(df.date_of_birth.dt.year > 2000) & (df.profession.str.contains("engineer"))]output
name note profession date_of_birth group
1 Jane 94 Mechanical engineer 2002-08-14 B多个条件并集筛选数据
当多个条件是以并集的方式来过滤数据的时候,代码如下
df[(df.note > 90) | (df.profession=="Data scientist")]output
name note profession date_of_birth group
0 John 92 Electrical engineer 1998-11-01 A
1 Jane 94 Mechanical engineer 2002-08-14 B
2 Emily 87 Data scientist 1996-01-12 BQuery方法过滤数据
Pandas当中的query方法也可以对数据进行过滤,我们将过滤的条件输入
df.query("note > 90")output
name note profession date_of_birth group
0 John 92 Electrical engineer 1998-11-01 A
1 Jane 94 Mechanical engineer 2002-08-14 B又或者是
df.query("group=='A' and note > 89")output
name note profession date_of_birth group
0 John 92 Electrical engineer 1998-11-01 Ansmallest方法过滤数据
pandas当中的nsmallest以及nlargest方法是用来找到数据集当中最大、最小的若干数据,代码如下
df.nsmallest(2, "note")output
name note profession date_of_birth group
3 Lisa 82 Accountant 2002-10-24 A
2 Emily 87 Data scientist 1996-01-12 Bdf.nlargest(2, "note")output
name note profession date_of_birth group
1 Jane 94 Mechanical engineer 2002-08-14 B
0 John 92 Electrical engineer 1998-11-01 Aisna()方法
isna()方法功能在于过滤出那些是空值的数据,首先我们将表格当中的某些数据设置成空值
df.loc[0, "profession"] = np.nan
df[df.profession.isna()]output
name note profession date_of_birth group
0 John 92 NaN 1998-11-01 Anotna()方法
notna()方法上面的isna()方法正好相反的功能在于过滤出那些不是空值的数据,代码如下
df[df.profession.notna()]output
name note profession date_of_birth group
1 Jane 94 Mechanical engineer 2002-08-14 B
2 Emily 87 Data scientist 1996-01-12 B
3 Lisa 82 Accountant 2002-10-24 A
4 Matt 90 Athlete 2004-04-05 Cassign方法
pandas当中的assign方法作用是直接向数据集当中来添加一列
df_1 = df.assign(score=np.random.randint(0,100,size=5))
df_1output
name note profession date_of_birth group score
0 John 92 Electrical engineer 1998-11-01 A 19
1 Jane 94 Mechanical engineer 2002-08-14 B 84
2 Emily 87 Data scientist 1996-01-12 B 68
3 Lisa 82 Accountant 2002-10-24 A 70
4 Matt 90 Athlete 2004-04-05 C 39explode方法
explode()方法直译的话,是爆炸的意思,我们经常会遇到这样的数据集
Name Hobby
0 吕布 [打篮球, 玩游戏, 喝奶茶]
1 貂蝉 [敲代码, 看电影]
2 赵云 [听音乐, 健身]Hobby列当中的每行数据都以列表的形式集中到了一起,而explode()方法则是将这些集中到一起的数据拆开来,代码如下
Name Hobby
0 吕布 打篮球
0 吕布 玩游戏
0 吕布 喝奶茶
1 貂蝉 敲代码
1 貂蝉 看电影
2 赵云 听音乐
2 赵云 健身当然我们会展开来之后,数据会存在重复的情况,
df.explode('Hobby').drop_duplicates().reset_index(drop=True)output
Name Hobby
0 吕布 打篮球
1 吕布 玩游戏
2 吕布 喝奶茶
3 貂蝉 敲代码
4 貂蝉 看电影
5 赵云 听音乐
6 赵云 健身

往
期
回
顾
资讯
Meta开发AI语音助手,助力元宇宙
技术
霸占CSDN榜一的20个Python用例
一行代码搞定Python逐行内存消耗
资讯
M2芯片终于要来了?全线换新

分享

点收藏

点点赞

点在看
相关文章:

Python创建和访问字典
>>> dict1 {a:1,b:2,c:3,d:4}>>> print(a的值是:,dict1[a])a的值是: 1>>> dict4 dict(我 快乐, 你 伤悲)SyntaxError: keyword cant be an expression>>> dict4[你] 改变悲伤>>> dict4{我: 快乐, 你: 改变悲伤}>>>…
C语言九阴真经
发现记忆力越来越差,所以干脆搞这么一个东西,就是把C语言的最常用的语法汇编在一起,不断完善。这样以后只要经常把这个回顾一下就可以了。不然去翻书太多了。。。f.h#define Area 1000 struct student{char *last_name;int student_id;char …

听障人士的“有声桥梁”:百度智能云曦灵-AI手语平台发布
在刚刚落幕的冰雪赛事中,百度智能云曦灵为央视新闻打造的AI手语主播正式上岗,她以流畅、专业的手语服务实时传递冰雪运动的激情。然而在日常生活中,听障人士想要方便地获取信息仍面临着众多困难,无障碍窗口稀缺的问题亟待解决。 …
模拟实现: strstr strcpy strlen strcat strcmp memcpy memmove
模拟实现:strstrstrcpystrlenstrcatstrcmpmemcpymemmove1 strstr 字符串中查找子字符串char * my_strstr(const char *dest, const char *src) {const char *ret dest;const char *p dest;const char *q src;assert(dest ! NULL && src ! NULL); while(r…
【Spring Security】五、自定义过滤器
在之前的几篇security教程中,资源和所对应的权限都是在xml中进行配置的,也就在http标签中配置intercept-url,试想要是配置的对象不多,那还好,但是平常实际开发中都往往是非常多的资源和权限对应,而且写在配…
一星期没完成Ansible任务
这个星期,前4天,我在看Nginx,没有深入Ansible。 这几天我有思考做Ansible的哪个方面,现在我用Ansible可以用,但是没有生产环境,我对基础部分热情不是特别大,应该是基础部分大家在弄,…

Python 批量处理 Excel 数据后,导入 SQL Server
作者 | 老表来源 | 简说Python1、前言2、开始动手动脑2.1 拆解明确需求2.2 安装第三方包2.3 读取excel数据2.4 特殊数据数据处理2.5 其他需求2.6 完整调用代码1、前言今天教大家一个需求:有很多Excel,需要批量处理,然后存入不同的数据表中。2…

最经典的计算机网络新书推荐--计算机网络(第5版)Tanenbaum著中文版上市
作者:Tanenbaum是全球最著名的计算机科学家。linux之父Linus当年就是参考Tanenbaum写的MINIX! Tanenbaum《计算机网络(第5版) 》《现代操作系统(第3版) 》《操作系统设计与实现(第3版) 》《分布式系统原理与范型(第2版) 》《计算机组成结构化方法&#x…
elasticsearch简单操作(二)
让我们建立一个员工目录,假设我们刚好在Megacorp工作,这时人力资源部门出于某种目的需要让我们创建一个员工目录,这个目录用于促进人文关怀和用于实时协同工作,所以它有以下不同的需求:1、数据能够包含多个值的标签、数…

苹果放大招?「廉价版」5G iPhone 将揭晓,M2芯片来袭?
整理 | 张洁来源 | CSDN3 月 2 日,苹果公司正式宣布将于北京时间 3 月 9 日凌晨 2 点举办 2022 年的首场活动,主题为“peek performance(高能传送)”。与去年一样,苹果 2022 年的第一场活动将继续以线上的方式进行。活…
PHP 预编译加速: eAccelerator的安装和性能比较
eAccelerator已经是很常用的PHP平台预编译加速的手段了。今天在自己机器上尝试安装了一下,备忘如下: 获得源代码:http://bart.eaccelerator.net/source/编译:需要有autoconf支持,解包后在源程序目录下:/usr…

合并区间(LintCode)
合并区间 给出若干闭合区间,合并所有重叠的部分。 样例 给出的区间列表 > 合并后的区间列表: [ [[1, 3], [1, 6],[2, 6], > [8, 10],[8, 10], [15, 18][15, 18] ] ]挑战 O(…
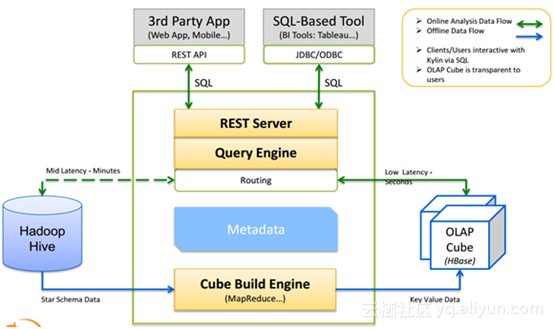
Kylin集群部署和cube使用
Kylin集群部署和cube使用 安装集群环境节点 Kylin节点模式 Ip 内存 磁盘Node1 All 192.167.71.11 2G 80GNode2 query 192.168.71.12 1.5G 80GNode3 query 192.168.71.13 1.5G 80GKylin工作原理如下: 集群时间同步Ntp服务自行设置安装kylin之前所需要的环境Hadoop-2.…

就是个控制结构,Scala 能有什么新花样呢?
作者 | luanhz来源 | 小数志导读编程语言中最为基础的一个概念是控制结构,几乎任何代码都无时无刻不涉及到,其实也就无外乎3种:顺序、分支和循环。本文就来介绍Scala中控制结构,主要是分支和循环。Scala中的控制结构实质上与其他编…

快速开发一个PHP扩展
快速开发一个PHP扩展 作者:heiyeluren时间:2008-12-5博客:http://blog.csdn.net/heiyeshuwu 本文通过非常快速的方式讲解了如何制作一个PHP 5.2 环境的扩展(PHP Extension),希望能够在图文的方式下让想快速…
oracle11g的安装
目录层次:linux->oracle软件->dbca数据库安装过程:虚拟机->linux->VMtools->拷贝数据库软件->创建一个目录mkdir->创建组.用户->修改根目录->设置参数->解压 >安装->oracle完成参考:安装oracle软件linu…

python 100例(10)
2019独角兽企业重金招聘Python工程师标准>>> 题目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多…
cocos2dx-3.9 集成admob
Part 1: 安装GoogleMobileAds framework (即admob) 1. 安装Cocoapods,否则解决依赖关系和配置真的会把人不累死也得烦死 sudo gem install cocoapods 国内用户安装过程中可能遇到SSL连接出错的问题,请参考 Cocoapod安装过程中的幺…
用C语言扩展PHP功能
用C语言扩展PHP功能建议读者群:熟悉c,linux,php PHP经过最近几年的发展已经非常的流行,而且PHP也提供了各种各样非常丰富的函数。但有时候我们还是需要来扩展PHP。比如:我们自己开发了一个数据库系统,而且有自己的库函数来操作数…
手把手快速实现 Resnet 残差模型实战
作者 | 李秋键 出品 | AI科技大本营(ID:rgznai100) 引言:随着深度学习的发展,网络模型的深度也随之越来越深,但随着网络模型深度的加深,往往会曾在这随着模型深度的加大,模型准确率反而下降的问…
JHipster开发环境安装
这里采用官方推荐的Yarn安装方法,默认操作系统为CentOS 7.4。 1 安装JDK 推荐版本:OpenJDK 1.8.0-64bit。 完整安装说明,请参考这里 2 安装Nodejs 推荐版本: v8.11.3 完整安装说明,请参考这里 3 安装Yarn 推荐版本&…

用C语言写PHP扩展
用C语言写PHP扩展 1:预定义 在home目录,也可以其他任意目录,写一个文件,例如caleng_module.def 内容是你希望定义的函数名以及参数: int a(int x,int y)string b(string str,int n) 2:到php源码目录的ext目…
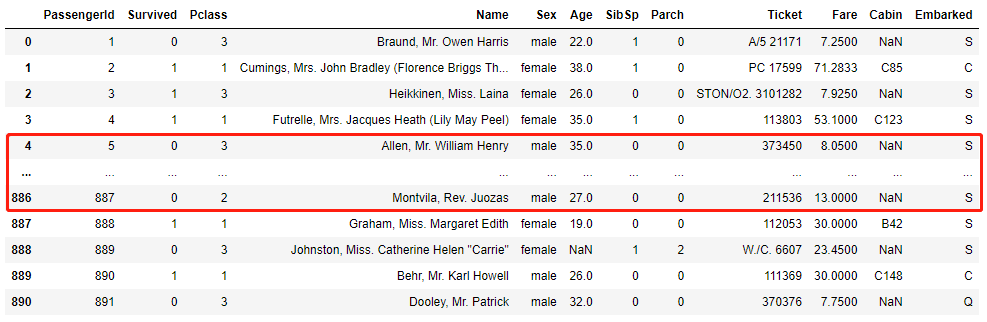
Pandas 数据挖掘与分析时的常用方法
今天我们来讲一下用Pandas模块对数据集进行分析的时候,一些经常会用到的配置,通过这些配置的帮助,我们可以更加有效地来分析和挖掘出有价值的数据。数据集的准备这次我们需要用到的数据集是广为人所知的泰坦尼克号的乘客数据,我们…
MySQL基本概念
1. 分清几个概念:数据库,数据库对象和数据; 数据库分为:系统数据库和用户数据库; 系统数据库 是安装完MySQL服务器后自带的数据库,会记录一些必要的信息,用户不能直接修改这些系统数据库。转载…
SpringMvc+ajax实现文件跨域上传
最近开始学习SpringMVC框架,在学习数据绑定的时候,发现可以使用RequestParam注解绑定请求数据,实现了文件上传。但是如果一个项目是前后端分离的,前端系统向后端服务上传文件该怎么解决了? 首先考虑前端用哪一种方式进…
使用Nmap获取目标服务器开放的服务以及操作系统信息
http://nmap.org/download.html 1.下载安装rpm -vhU http://nmap.org/dist/nmap-5.61TEST5-1.i386.rpmrpm -vhU http://nmap.org/dist/zenmap-5.61TEST5-1.noarch.rpmrpm -vhU http://nmap.org/dist/ncat-5.61TEST5-1.i386.rpmrpm -vhU http://nmap.org/dist/nping-0.5.61TEST5…
Pandas 数据类型概述与转换实战
作者 | 周萝卜 来源 | 萝卜大杂烩 在进行数据分析时,确保使用正确的数据类型是很重要的,否则我们可能会得到意想不到的结果或甚至是错误结果。对于 pandas 来说,它会在许多情况下自动推断出数据类型 尽管 pandas 已经自我推断的很好了&#x…
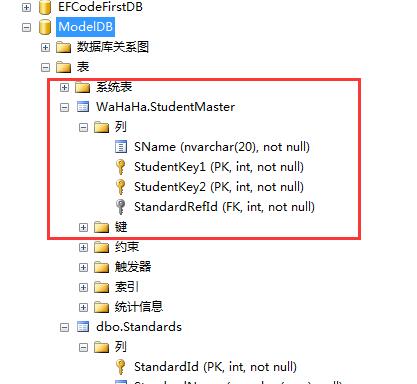
7.10 数据注解特性--NotMapped
NotMapped特性可以应用到领域类的属性中,Code-First默认的约定,是为所有带有get,和set属性选择器的属性创建数据列。。 NotManpped特性打破了这个约定,你可以使用NotMapped特性到某个属性上面,然后Code-First就不会为这个属性就不…
Condition
2019独角兽企业重金招聘Python工程师标准>>> 1、Condition的简介 线程通信中的互斥除了用synchronized、Object类的wait()和notify()/notifyAll()方式实现外,方法JDK1.5中提供的Condition配套Lock可以实现相同的功能。Condition中的await()和signal()/si…

使用who.is查域名DNS信息以及用sameip.org查其他网站
www.who.is网站可以查域名信息,非常好用:例如查 hack-test.com然后我们可以找找同个IP上的其他站点(旁站:sameip.org)参考: 黑客是怎么攻击一个网站的?