Python 批量处理 Excel 数据后,导入 SQL Server

作者 | 老表
来源 | 简说Python
1、前言
2、开始动手动脑
2.1 拆解+明确需求
2.2 安装第三方包
2.3 读取excel数据
2.4 特殊数据数据处理
2.5 其他需求
2.6 完整调用代码
1、前言
今天教大家一个需求:有很多Excel,需要批量处理,然后存入不同的数据表中。
2、开始动手动脑
2.1 拆解+明确需求
1) excel数据有哪些需要修改?
有一列数据
DocketDate是excel短时间数值,需要转变成正常的年月日格式;
eg. 44567 --> 2022/1/6部分数据需要按
SOID进行去重复处理,根据DocketDate保留最近的数据;有一列数据需要进行日期格式转换。
eg. 06/Jan/2022 12:27 --> 2022-1-6
主要涉及:日期格式处理、数据去重处理
2) 每一个Excel都对应一个不同数据表吗?表名和Excel附件名称是否一致?
有些Excel对应的是同一个表,有些是单独的
表名和Excel附件名称不一致,不过是有对应关系的
eg. 附件test1 和 test2 对应表 testa,附件test3 对应 testb
主要涉及:数据合并处理
2.2 安装第三方包
pip3 install sqlalchemy pymssql pandas xlrd xlwtsqlalchemy:可以将关系数据库的表结构映射到对象上,然后通过处理对象来处理数据库内容;
pymssql:python连接sqlserver数据库的驱动程序,也可以直接使用其连接数据库后进行读写操作;
pandas:处理各种数据,内置很多数据处理方法,非常方便;
xlrd xlwt:读写excel文件,pandas读写excel会调用他们。
导入包:
import pandas as pd
from datetime import date, timedelta, datetime
import time
import os
from sqlalchemy import create_engine
import pymssql2.3 读取excel数据
读取数据比较简单,直接调用pandas的read_excel函数即可,如果文件有什么特殊格式,比如编码,也可以自定义设置。
# 读取excel数据
def get_excel_data(filepath):data = pd.read_excel(filepath)return data2.4 特殊数据数据处理
“1)日期天数转短日期
”
这个有一定难度,excel里直接转很简单,直接选中需要转的数据,然后在开始-数据格式栏选择短日期即可。
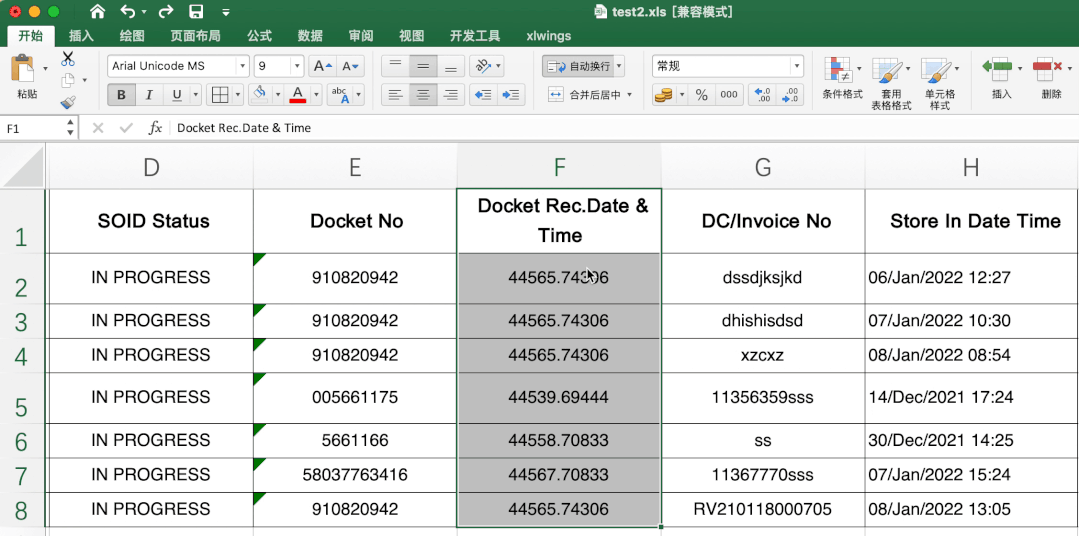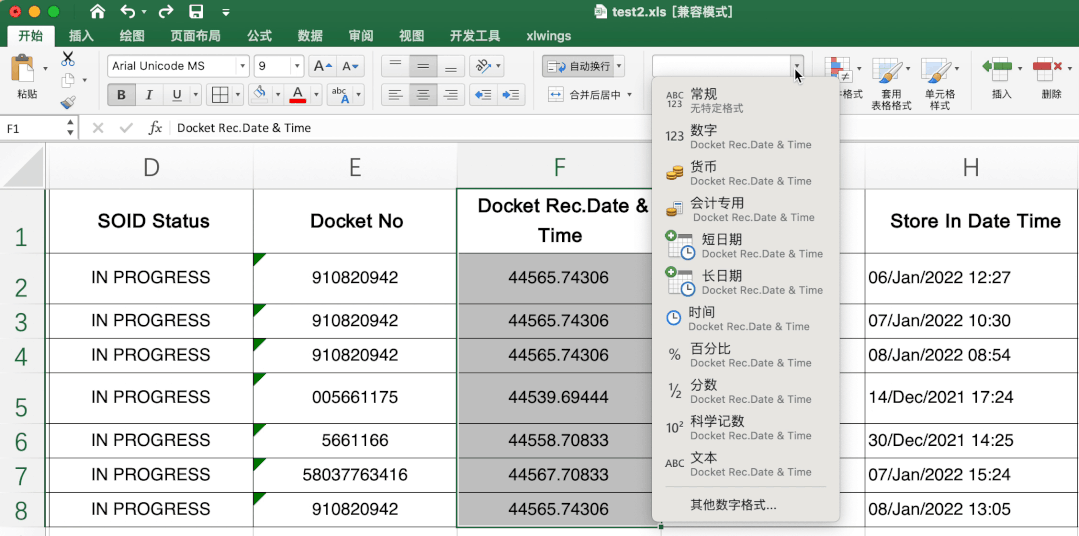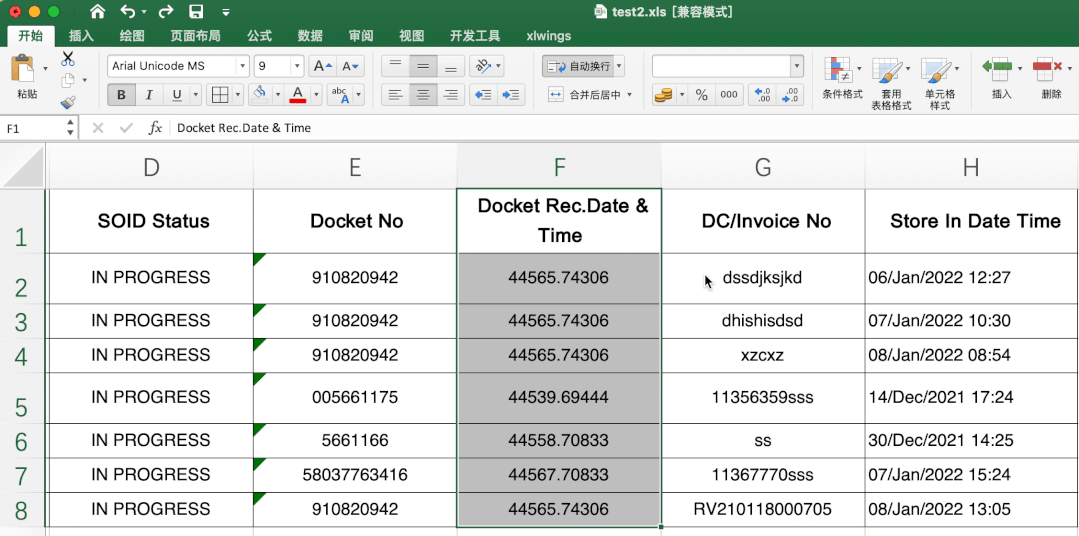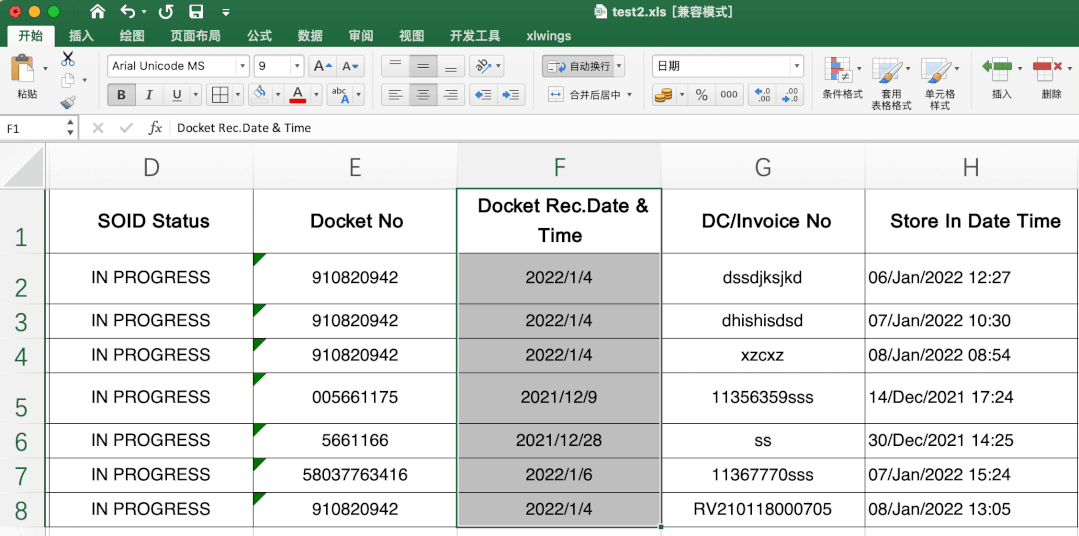
当时第一眼不知道其中的转换规律,搜索了很久,也没发现有类似问题或说明,首先肯定不是时间戳,感觉总有点关系,最后发现是天数,计算出天数计算起始日期就可以解决其他数据转变问题啦。
首先我们要判断空值,然后设置日期天数计算起始时间,利用datetime模块的timedelta函数将时间天数转变成时间差,然后直接与起始日期进行运算即可得出其代表的日期。
# 日期天数转短日期
def days_to_date(days):# 处理nan值if pd.isna(days):return # 44567 2022/1/6# 推算出 excel 天数转短日期 是从1899.12.30开始计算start = date(1899,12,30) # 将days转换成 timedelta 类型,可以直接与日期进行计算delta = timedelta(days)# 开始日期+时间差 得到对应短日期offset = start + deltareturn offset这里比较难想的就是天数计算起始日期,不过想明白后,其实也好算,从excel中我们可以直接将日期天数转成短日期,等式已经有了,只有一个未知数x,我们只需列一个一元一次方程即可解出未知数x。
from datetime import date, timedeltadate_days = 44567
# 将天数转成日期类型时间间隔
delta = timedelta(date_days)
# 结果日期
result = date(2022,1,6)
# 计算未知的起始日期
x = result - delta
print(x)'''
输出:1899-12-30
'''“2)将日期中的英文转成数字
”
最开始我想的是使用正则匹配,将年月日都在取出来,然后将英文月份转变成数字,后来发现日期里可以直接识别英文的月份。
代码如下,首先将字符串按格式转变成日期类型数据,原数据为06/Jan/2022 12:27(数字日/英文月/数字年 数字小时:数字分钟),按日期格式化符号解释表中对应关系替换即可。
# 官方日期格式转换成常见格式
def date_to_common(time):# 处理nan值if pd.isna(time):return # 06/Jan/2022 12:27 2022-1-6# 测试 print(time,':', type(time))# 将字符串转成日期time_format = datetime.strptime(time,'%d/%b/%Y %H:%M') # 转换成指定日期格式common_date = datetime.strftime(time_format, '%Y-%m-%d') return common_date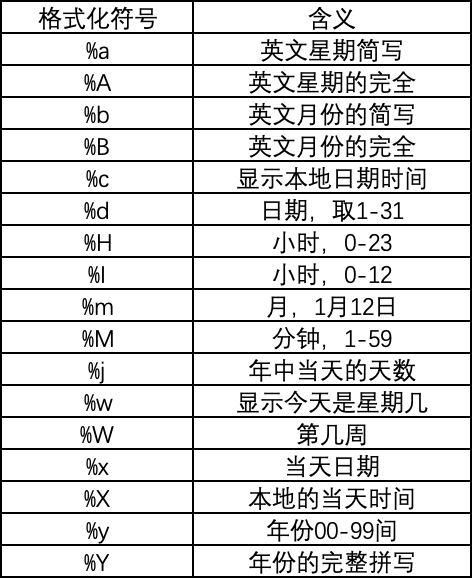
@CSDN-划船的使者
“3)按订单编号SOID去重
”
这里去重复除了按指定列去重外,还需要按日期保留最新数据。
我的想法是,首先调用pandas的sort_values函数将所有数据根据日期列进行升序排序,然后,调用drop_duplicates函数指定按SOID列进行去重,并指定keep值为last,表示重复数据中保留最后一行数据。
代码如下:
# 去除重复值 SOID重复 按日期去除最早的数据
def delete_repeat(data):# 先按日期列 Docket Rec.Date & Time 排序 默认降序 保证留下的日期是最近的data.sort_values(by=['Docket Rec.Date & Time'], inplace=True)# 按 SOID 删除重复行data.drop_duplicates(subset=['SOID #'], keep='last', inplace=True)return data2.5 其他需求
“多个Excel数据对应一张数据库的表
”
可以写一个字典,来存储数据库表和对应Excel数据名称,然后一个个存储到对应的数据库表中即可(或者提前处理好数据后,再合并)。
合并同类型Excel表
# 相同表合并数据 传入合并excel列表
def merge_excel(elist, files_path):data_list = [get_excel_data(files_path+i) for i in elist]data = pd.concat(data_list)return data这里传入同一类型Excel文件名列表(elist)和数据存储文件夹绝对/相对路径(files_path)即可,通过文件绝对/相对路径+Excel文件名即可得到Excel数据表文件的绝对/相对路径,再调用get_excel_data函数即可读取出数据。
遍历读取Excel表数据利用了列表推导式,最后利用pandas的concat函数即可将对应数据进行合并。
数据存储到sqlserver
# 初始化数据库连接引擎
# create_engine("数据库类型+数据库驱动://数据库用户名:数据库密码@IP地址:端口/数据库",其他参数)
engine = create_engine("mssql+pymssql://sa:123456@localhost/study?charset=GBK")# 存储数据
def data_to_sql(data, table_naem, columns):# 再对数据进行一点处理,选取指定列存入数据库data1 = data[columns]# 第一个参数:表名# 第二个参数:数据库连接引擎# 第三个参数:是否存储索引# 第四个参数:如果表存在 就追加数据t1 = time.time() # 时间戳 单位秒print('数据插入开始时间:{0}'.format(t1))data1.to_sql(table_naem, engine, index=False, if_exists='append')t2 = time.time() # 时间戳 单位秒print('数据插入结束时间:{0}'.format(t2))print('成功插入数据%d条,'%len(data1), '耗费时间:%.5f秒。'%(t2-t1))sqlalchemy+pymssql连接sqlserver的时候注意坑:要指定数据库编码,slqserver创建的数据库默认是GBK编码。
2.6 完整调用代码
'''
批量处理所有excel数据
'''
# 数据文件都存储在某个指定目录下,如:
files_path = './data/'
bf_path = './process/'# 获取当前目录下所有文件名称
# files = os.listdir(files_path)
# files# 表名:附件excel名
data_dict = {'testa': ['test1.xls', 'test2.xls'], 'testb': ['test3.xls'], 'testc': ['test4.xls']
}# 选取附件中的指定列,只存入指定列数据
columns_a = ['S/No', 'SOID #', 'Current MileStone', 'Store In Date Time']
columns_b = ['Received Part Serial No', 'Received Product Category', 'Received Part Desc']
columns_c = ['From Loc', 'Orig Dispoition Code']columns = [columns_a, columns_b, columns_c]
flag = 0 # 列选择标记# 遍历字典 合并相关excel 然后处理数据后,存入sql
for k,v in data_dict.items():table_name = kdata = merge_excel(v, files_path)# 1、处理数据if 'SOID #' not in data.columns:# 不包含要处理的列,则直接简单去重后、存入数据库data.drop_duplicates(inplace=True)else:# 特别处理数据data = process_data(data)# 2、存储数据# 保险起见 本地也存一份data.to_excel(bf_path+table_name+'.xls')# 存储到数据库data_to_sql(data, table_name, columns[flag])flag+=1

往
期
回
顾
资讯
Meta开发AI语音助手,助力元宇宙
技术
霸占CSDN榜一的20个Python用例
技术
20个Pandas数据实战案例,干货多
资讯
安全隐患:神经网络可以隐藏恶意软件

分享

点收藏

点点赞

点在看
相关文章:

最经典的计算机网络新书推荐--计算机网络(第5版)Tanenbaum著中文版上市
作者:Tanenbaum是全球最著名的计算机科学家。linux之父Linus当年就是参考Tanenbaum写的MINIX! Tanenbaum《计算机网络(第5版) 》《现代操作系统(第3版) 》《操作系统设计与实现(第3版) 》《分布式系统原理与范型(第2版) 》《计算机组成结构化方法&#x…

elasticsearch简单操作(二)
让我们建立一个员工目录,假设我们刚好在Megacorp工作,这时人力资源部门出于某种目的需要让我们创建一个员工目录,这个目录用于促进人文关怀和用于实时协同工作,所以它有以下不同的需求:1、数据能够包含多个值的标签、数…

苹果放大招?「廉价版」5G iPhone 将揭晓,M2芯片来袭?
整理 | 张洁来源 | CSDN3 月 2 日,苹果公司正式宣布将于北京时间 3 月 9 日凌晨 2 点举办 2022 年的首场活动,主题为“peek performance(高能传送)”。与去年一样,苹果 2022 年的第一场活动将继续以线上的方式进行。活…
PHP 预编译加速: eAccelerator的安装和性能比较
eAccelerator已经是很常用的PHP平台预编译加速的手段了。今天在自己机器上尝试安装了一下,备忘如下: 获得源代码:http://bart.eaccelerator.net/source/编译:需要有autoconf支持,解包后在源程序目录下:/usr…

合并区间(LintCode)
合并区间 给出若干闭合区间,合并所有重叠的部分。 样例 给出的区间列表 > 合并后的区间列表: [ [[1, 3], [1, 6],[2, 6], > [8, 10],[8, 10], [15, 18][15, 18] ] ]挑战 O(…
Kylin集群部署和cube使用
Kylin集群部署和cube使用 安装集群环境节点 Kylin节点模式 Ip 内存 磁盘Node1 All 192.167.71.11 2G 80GNode2 query 192.168.71.12 1.5G 80GNode3 query 192.168.71.13 1.5G 80GKylin工作原理如下: 集群时间同步Ntp服务自行设置安装kylin之前所需要的环境Hadoop-2.…

就是个控制结构,Scala 能有什么新花样呢?
作者 | luanhz来源 | 小数志导读编程语言中最为基础的一个概念是控制结构,几乎任何代码都无时无刻不涉及到,其实也就无外乎3种:顺序、分支和循环。本文就来介绍Scala中控制结构,主要是分支和循环。Scala中的控制结构实质上与其他编…

快速开发一个PHP扩展
快速开发一个PHP扩展 作者:heiyeluren时间:2008-12-5博客:http://blog.csdn.net/heiyeshuwu 本文通过非常快速的方式讲解了如何制作一个PHP 5.2 环境的扩展(PHP Extension),希望能够在图文的方式下让想快速…
oracle11g的安装
目录层次:linux->oracle软件->dbca数据库安装过程:虚拟机->linux->VMtools->拷贝数据库软件->创建一个目录mkdir->创建组.用户->修改根目录->设置参数->解压 >安装->oracle完成参考:安装oracle软件linu…

python 100例(10)
2019独角兽企业重金招聘Python工程师标准>>> 题目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多…
cocos2dx-3.9 集成admob
Part 1: 安装GoogleMobileAds framework (即admob) 1. 安装Cocoapods,否则解决依赖关系和配置真的会把人不累死也得烦死 sudo gem install cocoapods 国内用户安装过程中可能遇到SSL连接出错的问题,请参考 Cocoapod安装过程中的幺…
用C语言扩展PHP功能
用C语言扩展PHP功能建议读者群:熟悉c,linux,php PHP经过最近几年的发展已经非常的流行,而且PHP也提供了各种各样非常丰富的函数。但有时候我们还是需要来扩展PHP。比如:我们自己开发了一个数据库系统,而且有自己的库函数来操作数…
手把手快速实现 Resnet 残差模型实战
作者 | 李秋键 出品 | AI科技大本营(ID:rgznai100) 引言:随着深度学习的发展,网络模型的深度也随之越来越深,但随着网络模型深度的加深,往往会曾在这随着模型深度的加大,模型准确率反而下降的问…
JHipster开发环境安装
这里采用官方推荐的Yarn安装方法,默认操作系统为CentOS 7.4。 1 安装JDK 推荐版本:OpenJDK 1.8.0-64bit。 完整安装说明,请参考这里 2 安装Nodejs 推荐版本: v8.11.3 完整安装说明,请参考这里 3 安装Yarn 推荐版本&…

用C语言写PHP扩展
用C语言写PHP扩展 1:预定义 在home目录,也可以其他任意目录,写一个文件,例如caleng_module.def 内容是你希望定义的函数名以及参数: int a(int x,int y)string b(string str,int n) 2:到php源码目录的ext目…
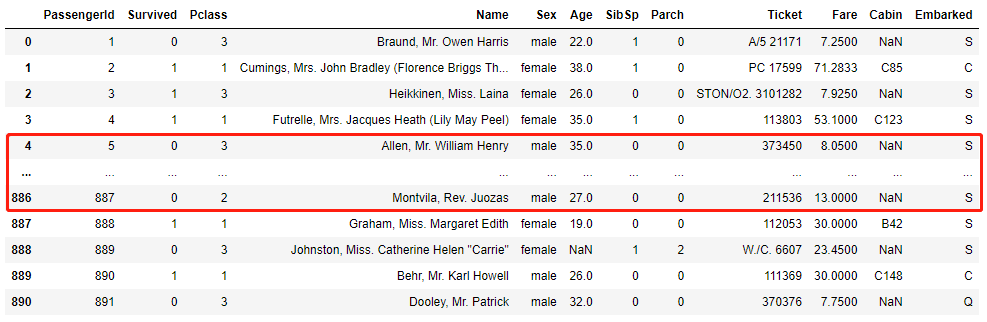
Pandas 数据挖掘与分析时的常用方法
今天我们来讲一下用Pandas模块对数据集进行分析的时候,一些经常会用到的配置,通过这些配置的帮助,我们可以更加有效地来分析和挖掘出有价值的数据。数据集的准备这次我们需要用到的数据集是广为人所知的泰坦尼克号的乘客数据,我们…
MySQL基本概念
1. 分清几个概念:数据库,数据库对象和数据; 数据库分为:系统数据库和用户数据库; 系统数据库 是安装完MySQL服务器后自带的数据库,会记录一些必要的信息,用户不能直接修改这些系统数据库。转载…
SpringMvc+ajax实现文件跨域上传
最近开始学习SpringMVC框架,在学习数据绑定的时候,发现可以使用RequestParam注解绑定请求数据,实现了文件上传。但是如果一个项目是前后端分离的,前端系统向后端服务上传文件该怎么解决了? 首先考虑前端用哪一种方式进…
使用Nmap获取目标服务器开放的服务以及操作系统信息
http://nmap.org/download.html 1.下载安装rpm -vhU http://nmap.org/dist/nmap-5.61TEST5-1.i386.rpmrpm -vhU http://nmap.org/dist/zenmap-5.61TEST5-1.noarch.rpmrpm -vhU http://nmap.org/dist/ncat-5.61TEST5-1.i386.rpmrpm -vhU http://nmap.org/dist/nping-0.5.61TEST5…
Pandas 数据类型概述与转换实战
作者 | 周萝卜 来源 | 萝卜大杂烩 在进行数据分析时,确保使用正确的数据类型是很重要的,否则我们可能会得到意想不到的结果或甚至是错误结果。对于 pandas 来说,它会在许多情况下自动推断出数据类型 尽管 pandas 已经自我推断的很好了&#x…
7.10 数据注解特性--NotMapped
NotMapped特性可以应用到领域类的属性中,Code-First默认的约定,是为所有带有get,和set属性选择器的属性创建数据列。。 NotManpped特性打破了这个约定,你可以使用NotMapped特性到某个属性上面,然后Code-First就不会为这个属性就不…
Condition
2019独角兽企业重金招聘Python工程师标准>>> 1、Condition的简介 线程通信中的互斥除了用synchronized、Object类的wait()和notify()/notifyAll()方式实现外,方法JDK1.5中提供的Condition配套Lock可以实现相同的功能。Condition中的await()和signal()/si…

使用who.is查域名DNS信息以及用sameip.org查其他网站
www.who.is网站可以查域名信息,非常好用:例如查 hack-test.com然后我们可以找找同个IP上的其他站点(旁站:sameip.org)参考: 黑客是怎么攻击一个网站的?

基于 OpenCV 的人脸追踪
作者 | 努比 来源 | 小白学视觉 在Raspberry上启动项目很简单,所以让我们开始吧。 01. 产品清单 Raspberry Pi 4 Model B — 4GB 适用于Raspberry Pi的Pan-Tilt HAT Pi Camera v2 8MP 微型SD卡 迷你HDMI电缆 Raspberry Pi摄像头电缆—尺寸:457mm x …
-bash: /bin/rm: Argument list too long的解决办法
-bash: /bin/rm: Argument list too long的解决办法 当目录下文件太多时,用rm删除文件会报错: -bash: /bin/rm: Argument list too long 提示文件数目太多。 解决的办法是使用如下命令: ls | xargs -n 10 rm -fr ls 输出所有的文件名(用…
React使用ES6语法重构组件代码
首次使用react,要注意react不同版本库,是ES5还是ES6的写法,如何做到统一。下面对于ES6语法重构组件的代码如下:(1)原始代码: <script type"text/babel">var destinationdocumen…

PHP哈希表碰撞攻击原理
哈希表碰撞攻击(Hashtable collisions as DOS attack)的话题不断被提起,各种语言纷纷中招。本文结合PHP内核源码,聊一聊这种攻击的原理及实现。 哈希表碰撞攻击的基本原理 哈希表是一种查找效率极高的数据结构,很多语言…
Java8(jdk1.8)中文档注释处理工具javadoc的环境参量配置及使用方法
Java8(jdk1.8)中文档注释处理工具javadoc的环境参量配置及使用方法Java语言提供了一种功能强大的注释形式:文档注释。如果编写Java源代码时添加了合适的文档注释,然后通过JDK提供的javadoc工具可以直接将源代码里的文档注释提取成一份系统的API文档。jav…

如何读取Excel表格中不同sheet表的同一位置单元格数据,并绘制条形图呢?
作者 | 黄伟呢来源 | 数据分析与统计学之美今天,有位朋友在群里面咨询了一个问题:如何读取Excel表格中"不同sheet表"的同一位置单元格数据,并绘制条形图呢?有人提议用vba,但是不得不说,没有学过v…
vue-router学习笔记
配置路由模式 const routernew VueRouter({routes }) hash模式(默认):通过url的hash来模拟一个完整的url,于是当url改变时,页面不会重新加载。history模式:通过history完成url跳转而不需要重新加载页面。注意:为了防止404错误&…