目录
- 一、背景介绍
- 二、常见方案
- 1. 停机迁移
- 2. 业务双写
- 3. 增量迁移
- 三、Change Stream 介绍
- 监听的目标
- 变更事件
- 四、实现增量迁移
- 五、后续优化
- 小结
- 附参考文档
一、背景介绍
最近微服务架构火的不行,但本质上也只是风口上的一个热点词汇。
作为笔者的经验来说,想要应用一个新的架构需要带来的变革成本是非常高的。
尽管如此,目前还是有许多企业踏上了服务化改造的道路,这其中则免不了"旧改"的各种繁杂事。
所谓的"旧改",就是把现有的系统架构来一次重构,拆分成多个细粒度的服务后,然后找时间
升级割接一把,让新系统上线。这其中,数据的迁移往往会成为一个非常重要且繁杂的活儿。
拆分服务时数据迁移的挑战在哪?
首先是难度大,做一个迁移方案需要了解项目的前身今世,评估迁移方案、技术工具等等;
其次是成本高。由于新旧系统数据结构是不一样的,需要定制开发迁移转化功能。很难有一个通用的工具能一键迁移;
再者,对于一些容量大、可靠性要求高的系统,要能够不影响业务,出了问题还能追溯,因此方案上还得往复杂了想。
二、常见方案
按照迁移的方案及流程,可将数据迁移分为三类:
1. 停机迁移
最简单的方案,停机迁移的顺序如下:
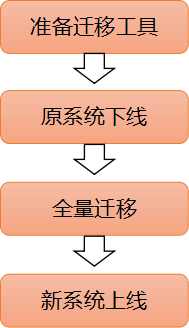
采用停机迁移的好处是流程操作简单,工具成本低;然而缺点也很明显,
迁移过程中业务是无法访问的,因此只适合于规格小、允许停服的场景。
2. 业务双写
业务双写是指对现有系统先进行改造升级,支持同时对新库和旧库进行写入。
之后再通过数据迁移工具对旧数据做全量迁移,待所有数据迁移转换完成后切换到新系统。
示意图:
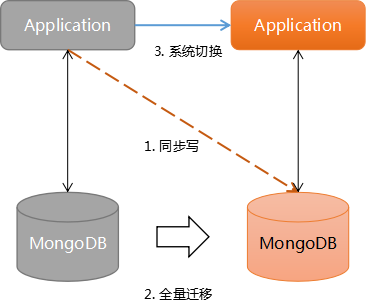
业务双写的方案是平滑的,对线上业务影响极小;在出现问题的情况下可重新来过,操作压力也会比较小。
笔者在早些年前尝试过这样的方案,整个迁移过程确实非常顺利,但实现该方案比较复杂,
需要对现有的代码进行改造并完成新数据的转换及写入,对于开发人员的要求较高。
在业务逻辑清晰、团队对系统有足够的把控能力的场景下适用。
3. 增量迁移
增量迁移的基本思路是先进行全量的迁移转换,待完成后持续进行增量数据的处理,直到数据追平后切换系统。
示意图:
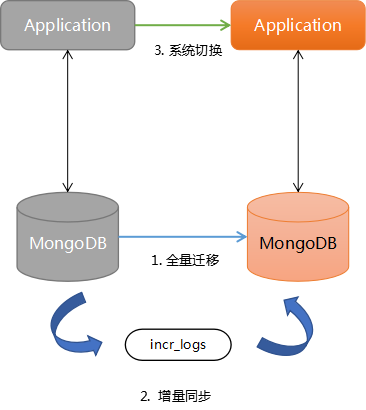
关键点
要求系统支持增量数据的记录。
对于MongoDB可以利用oplog实现这点,为避免全量迁移过程中oplog被冲掉,
在开始迁移前就必须开始监听oplog,并将变更全部记录下来。
如果没有办法,需要从应用层上考虑,比如为所有的表(集合)记录下updateTime这样的时间戳,
或者升级应用并支持将修改操作单独记录下来。增量数据的回放是持续的。
在所有的增量数据回放转换过程中,系统仍然会产生新的增量数据,这要求迁移工具
能做到将增量数据持续回放并将之追平,之后才能做系统切换。
MongoDB 3.6版本开始便提供了Change Stream功能,支持对数据变更记录做监听。
这为实现数据同步及转换处理提供了更大的便利,下面将探讨如何利用Change Stream实现数据的增量迁移。
三、Change Stream 介绍
Chang Stream(变更记录流) 是指collection(数据库集合)的变更事件流,应用程序通过db.collection.watch()这样的命令可以获得被监听对象的实时变更。
在该特性出现之前,你可以通过拉取 oplog达到同样的目的;但 oplog 的处理及解析相对复杂且存在被回滚的风险,如果使用不当的话还会带来性能问题。
Change Stream 可以与aggregate framework结合使用,对变更集进行进一步的过滤或转换。
由于Change Stream 利用了存储在 oplog 中的信息,因此对于单进程部署的MongoDB无法支持Change Stream功能,
其只能用于启用了副本集的独立集群或分片集群
监听的目标
| 名称 | 说明 |
|---|---|
| 单个集合 | 除系统库(admin/local/config)之外的集合,3.6版本支持 |
| 单个数据库 | 除系统库(admin/local/config)之外的数据库集合,4.0版本支持 |
| 整个集群 | 整个集群内除去系统库( (admin/local/config)之外的集合 ,4.0版本支持 |
变更事件
一个Change Stream Event的基本结构如下所示:
{_id : { <BSON Object> },"operationType" : "<operation>","fullDocument" : { <document> },"ns" : {"db" : "<database>","coll" : "<collection"},"documentKey" : { "_id" : <ObjectId> },"updateDescription" : {"updatedFields" : { <document> },"removedFields" : [ "<field>", ... ]}"clusterTime" : <Timestamp>,"txnNumber" : <NumberLong>,"lsid" : {"id" : <UUID>,"uid" : <BinData>}
}字段说明
| 名称 | 说明 |
|---|---|
| _id | 变更事件的Token对象 |
| operationType | 变更类型(见下面介绍) |
| fullDocument | 文档内容 |
| ns | 监听的目标 |
| ns.db | 变更的数据库 |
| ns.coll | 变更的集合 |
| documentKey | 变更文档的键值,含_id字段 |
| updateDescription | 变更描述 |
| updateDescription.updatedFields | 变更中更新字段 |
| updateDescription.removedFields | 变更中删除字段 |
| clusterTime | 对应oplog的时间戳 |
| txnNumber | 事务编号,仅在多文档事务中出现,4.0版本支持 |
| lsid | 事务关联的会话编号,仅在多文档事务中出现,4.0版本支持 |
Change Steram支持的变更类型有以下几个:
| 类型 | 说明 |
|---|---|
| insert | 插入文档 |
| delete | 删除文档 |
| replace | 替换文档,当执行replace操作指定upsert时,可能是insert事件 |
| update | 更新文档,当执行update操作指定upsert时,可能是insert事件 |
| invalidate | 失效事件,比如执行了collection.drop或collection.rename |
利用以下的shell脚本,可以打印出集合 T_USER上的变更事件:
watchCursor=db.T_USER.watch()
while (!watchCursor.isExhausted()){if (watchCursor.hasNext()){printjson(watchCursor.next());}
}下面提供一些样例,感受一下
insert 事件
{"_id": {"_data": "825B5826D10000000129295A10046A31C593902B4A9C9907FC0AB1E3C0DA46645F696400645B58272321C4761D1338F4860004"},"operationType": "insert","clusterTime": Timestamp(1532503761, 1),"fullDocument": {"_id": ObjectId("5b58272321c4761d1338f486"),"name": "LiLei","createTime": ISODate("2018-07-25T07:30:43.398Z")},"ns": {"db": "appdb","coll": "T_USER"},"documentKey": {"_id": ObjectId("5b58272321c4761d1338f486")}
}update事件
{"_id" : {"_data" : "825B5829DF0000000129295A10046A31C593902B4A9C9907FC0AB1E3C0DA46645F696400645B582980ACEC5F345DB998EE0004"},"operationType" : "update","clusterTime" : Timestamp(1532504543, 1),"ns" : {"db" : "appdb","coll" : "T_USER"},"documentKey" : {"_id" : ObjectId("5b582980acec5f345db998ee")},"updateDescription" : {"updatedFields" : {"age" : 15},"removedFields" : [ ]}
}
replace事件
{"_id" : {"_data" : "825B58299D0000000129295A10046A31C593902B4A9C9907FC0AB1E3C0DA46645F696400645B582980ACEC5F345DB998EE0004"},"operationType" : "replace","clusterTime" : Timestamp(1532504477, 1),"fullDocument" : {"_id" : ObjectId("5b582980acec5f345db998ee"),"name" : "HanMeimei","age" : 12},"ns" : {"db" : "appdb","coll" : "T_USER"},"documentKey" : {"_id" : ObjectId("5b582980acec5f345db998ee")}
}delete事件
{"_id" : {"_data" : "825B5827A90000000229295A10046A31C593902B4A9C9907FC0AB1E3C0DA46645F696400645B58272321C4761D1338F4860004"},"operationType" : "delete","clusterTime" : Timestamp(1532503977, 2),"ns" : {"db" : "appdb","coll" : "T_USER"},"documentKey" : {"_id" : ObjectId("5b58272321c4761d1338f486")}
}invalidate 事件
执行db.T_USER.drop() 可输出
{"_id" : {"_data" : "825B582D620000000329295A10046A31C593902B4A9C9907FC0AB1E3C0DA04"},"operationType" : "invalidate","clusterTime" : Timestamp(1532505442, 3)
}更多的Change Event 信息可以参考这里
四、实现增量迁移
本次设计了一个简单的论坛帖子迁移样例,用于演示如何利用Change Stream实现完美的增量迁移方案。
背景如下:
现有的系统中有一批帖子,每个帖子都属于一个频道(channel),如下表
| 频道名 | 英文简称 |
|---|---|
| 美食 | Food |
| 情感 | Emotion |
| 宠物 | Pet |
| 家居 | House |
| 征婚 | Marriage |
| 教育 | Education |
| 旅游 | Travel |
新系统中频道字段将采用英文简称,同时要求能支持平滑升级。
根据前面篇幅的叙述,我们将使用Change Stream 功能实现一个增量迁移的方案。
相关表的转换如下图:
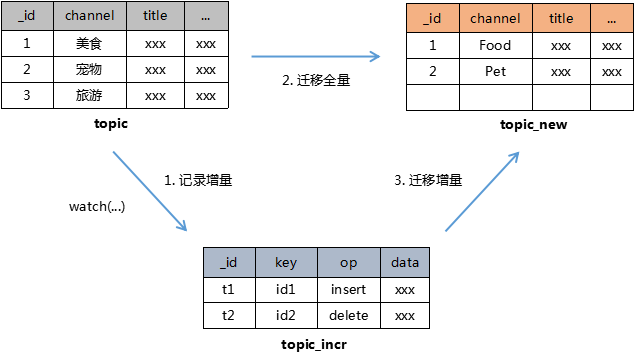
原理
topic 是帖子原表,在迁移开始前将开启watch任务持续获得增量数据,并记录到 topic_incr表中;
接着执行全量的迁移转换,之后再持续对增量表数据进行迁移,直到无新的增量为止。
接下来我们使用Java程序来完成相关代码,mongodb-java--driver 在 3.6 版本后才支持 watch 功能
需要确保升级到对应版本:
<dependency><groupId>org.mongodb</groupId><artifactId>mongo-java-driver</artifactId><version>3.6.4</version>
</dependency>- 定义Channel频道的转换表
public static enum Channel {Food("美食"),Emotion("情感"),Pet("宠物"),House("家居"),Marriage("征婚"),Education("教育"),Travel("旅游");private final String oldName;public String getOldName() {return oldName;}private Channel(String oldName) {this.oldName = oldName;}/*** 转换为新的名称* * @param oldName* @return*/public static String toNewName(String oldName) {for (Channel channel : values()) {if (channel.oldName.equalsIgnoreCase(oldName)) {return channel.name();}}return "";}/*** 返回一个随机频道* * @return*/public static Channel random() {Channel[] channels = values();int idx = (int) (Math.random() * channels.length);return channels[idx];}
}- 为 topic 表预写入1w条记录
private static void preInsertData() {MongoCollection<Document> topicCollection = getCollection(coll_topic);// 分批写入,共写入1w条数据int current = 0;int batchSize = 100;while (current < 10000) {List<Document> topicDocs = new ArrayList<Document>();for (int j = 0; j < batchSize; j++) {Document topicDoc = new Document();Channel channel = Channel.random();topicDoc.append(field_channel, channel.getOldName());topicDoc.append(field_nonce, (int) (Math.random() * nonce_max));topicDoc.append("title", "This is the tilte -- " + UUID.randomUUID().toString());topicDoc.append("author", "LiLei");topicDoc.append("createTime", new Date());topicDocs.add(topicDoc);}topicCollection.insertMany(topicDocs);current += batchSize;logger.info("now has insert {} records", current);}
}上述实现中,每个帖子都分配了随机的频道(channel)
- 开启监听任务,将topic上的所有变更写入到增量表
MongoCollection<Document> topicCollection = getCollection(coll_topic);
MongoCollection<Document> topicIncrCollection = getCollection(coll_topic_incr);// 启用 FullDocument.update_lookup 选项
cursor = topicCollection.watch().fullDocument(FullDocument.UPDATE_LOOKUP).iterator();
while (cursor.hasNext()) {ChangeStreamDocument<Document> changeEvent = cursor.next();OperationType type = changeEvent.getOperationType();logger.info("{} operation detected", type);if (type == OperationType.INSERT || type == OperationType.UPDATE || type == OperationType.REPLACE|| type == OperationType.DELETE) {Document incrDoc = new Document(field_op, type.getValue());incrDoc.append(field_key, changeEvent.getDocumentKey().get("_id"));incrDoc.append(field_data, changeEvent.getFullDocument());topicIncrCollection.insertOne(incrDoc);}
}代码中通过watch 命令获得一个MongoCursor对象,用于遍历所有的变更。
FullDocument.UPDATE_LOOKUP选项启用后,在update变更事件中将携带完整的文档数据(FullDocument)。
watch()命令提交后,mongos会与分片上的mongod(主节点)建立订阅通道,这可能需要花费一点时间。
- 为了模拟线上业务的真实情况,启用几个线程对topic表进行持续写操作;
private static void startMockChanges() {threadPool.submit(new ChangeTask(OpType.insert));threadPool.submit(new ChangeTask(OpType.update));threadPool.submit(new ChangeTask(OpType.replace));threadPool.submit(new ChangeTask(OpType.delete));
}ChangeTask 实现逻辑如下:
while (true) {logger.info("ChangeTask {}", opType);if (opType == OpType.insert) {doInsert();} else if (opType == OpType.update) {doUpdate();} else if (opType == OpType.replace) {doReplace();} else if (opType == OpType.delete) {doDelete();}sleep(200);long currentAt = System.currentTimeMillis();if (currentAt - startAt > change_during) {break;}
}每一个变更任务会不断对topic产生写操作,触发一系列ChangeEvent产生。
- doInsert:生成随机频道的topic后,执行insert
- doUpdate:随机取得一个topic,将其channel字段改为随机值,执行update
- doReplace:随机取得一个topic,将其channel字段改为随机值,执行replace
- doDelete:随机取得一个topic,执行delete
以doUpdate为例,实现代码如下:
private void doUpdate() {MongoCollection<Document> topicCollection = getCollection(coll_topic);Document random = getRandom();if (random == null) {logger.info("update skip");return;}String oldChannel = random.getString(field_channel);Channel channel = Channel.random();random.put(field_channel, channel.getOldName());random.put("createTime", new Date());topicCollection.updateOne(new Document("_id", random.get("_id")), new Document("$set", random));counter.onChange(oldChannel, channel.getOldName());
}- 启动一个全量迁移任务,将 topic 表中数据迁移到 topic_new 新表
final MongoCollection<Document> topicCollection = getCollection(coll_topic);
final MongoCollection<Document> topicNewCollection = getCollection(coll_topic_new);Document maxDoc = topicCollection.find().sort(new Document("_id", -1)).first();
if (maxDoc == null) {logger.info("FullTransferTask detect no data, quit.");return;
}ObjectId maxID = maxDoc.getObjectId("_id");
logger.info("FullTransferTask maxId is {}..", maxID.toHexString());AtomicInteger count = new AtomicInteger(0);topicCollection.find(new Document("_id", new Document("$lte", maxID))).forEach(new Consumer<Document>() {@Overridepublic void accept(Document topic) {Document topicNew = new Document(topic);// channel转换String oldChannel = topic.getString(field_channel);topicNew.put(field_channel, Channel.toNewName(oldChannel));topicNewCollection.insertOne(topicNew);if (count.incrementAndGet() % 100 == 0) {logger.info("FullTransferTask progress: {}", count.get());}}});
logger.info("FullTransferTask finished, count: {}", count.get());在全量迁移开始前,先获得当前时刻的的最大 _id 值(可以将此值记录下来)作为终点。
随后逐个完成迁移转换。
- 在全量迁移完成后,便开始最后一步:增量迁移
注:增量迁移过程中,变更操作仍然在进行
final MongoCollection<Document> topicIncrCollection = getCollection(coll_topic_incr);
final MongoCollection<Document> topicNewCollection = getCollection(coll_topic_new);ObjectId currentId = null;
Document sort = new Document("_id", 1);
MongoCursor<Document> cursor = null;// 批量大小
int batchSize = 100;
AtomicInteger count = new AtomicInteger(0);try {while (true) {boolean isWatchTaskStillRunning = watchFlag.getCount() > 0;// 按ID增量分段拉取if (currentId == null) {cursor = topicIncrCollection.find().sort(sort).limit(batchSize).iterator();} else {cursor = topicIncrCollection.find(new Document("_id", new Document("$gt", currentId))).sort(sort).limit(batchSize).iterator();}boolean hasIncrRecord = false;while (cursor.hasNext()) {hasIncrRecord = true;Document incrDoc = cursor.next();OperationType opType = OperationType.fromString(incrDoc.getString(field_op));ObjectId docId = incrDoc.getObjectId(field_key);// 记录当前IDcurrentId = incrDoc.getObjectId("_id");if (opType == OperationType.DELETE) {topicNewCollection.deleteOne(new Document("_id", docId));} else {Document doc = incrDoc.get(field_data, Document.class);// channel转换String oldChannel = doc.getString(field_channel);doc.put(field_channel, Channel.toNewName(oldChannel));// 启用upsertUpdateOptions options = new UpdateOptions().upsert(true);topicNewCollection.replaceOne(new Document("_id", docId),incrDoc.get(field_data, Document.class), options);}if (count.incrementAndGet() % 10 == 0) {logger.info("IncrTransferTask progress, count: {}", count.get());}}// 当watch停止工作(没有更多变更),同时也没有需要处理的记录时,跳出if (!isWatchTaskStillRunning && !hasIncrRecord) {break;}sleep(200);}
} catch (Exception e) {logger.error("IncrTransferTask ERROR", e);
}增量迁移的实现是一个不断 tail 的过程,利用 **_id 字段的有序特性 ** 进行分段迁移;
即记录下当前处理的 _id 值,循环拉取在 该 _id 值之后的记录进行处理。
增量表(topic_incr)中除了DELETE变更之外,其余的类型都保留了整个文档,
因此可直接利用 replace + upsert 追加到新表。
- 最后,运行整个程序
[2018-07-26 19:44:16] INFO ~ IncrTransferTask progress, count: 2160
[2018-07-26 19:44:16] INFO ~ IncrTransferTask progress, count: 2170
[2018-07-26 19:44:27] INFO ~ all change task has stop, watch task quit.
[2018-07-26 19:44:27] INFO ~ IncrTransferTask finished, count: 2175
[2018-07-26 19:44:27] INFO ~ TYPE 美食:1405
[2018-07-26 19:44:27] INFO ~ TYPE 宠物:1410
[2018-07-26 19:44:27] INFO ~ TYPE 征婚:1428
[2018-07-26 19:44:27] INFO ~ TYPE 家居:1452
[2018-07-26 19:44:27] INFO ~ TYPE 教育:1441
[2018-07-26 19:44:27] INFO ~ TYPE 情感:1434
[2018-07-26 19:44:27] INFO ~ TYPE 旅游:1457
[2018-07-26 19:44:27] INFO ~ ALLCHANGE 12175
[2018-07-26 19:44:27] INFO ~ ALLWATCH 2175查看 topic 表和 topic_new 表,发现两者数量是相同的。
为了进一步确认一致性,我们对两个表的分别做一次聚合统计:
topic表
db.topic.aggregate([{"$group":{"_id":"$channel","total": {"$sum": 1}}},{"$sort": {"total":-1}}])topic_new表
db.topic_new.aggregate([{"$group":{"_id":"$channel","total": {"$sum": 1}}},{"$sort": {"total":-1}}])前者输出结果:

后者输出结果:
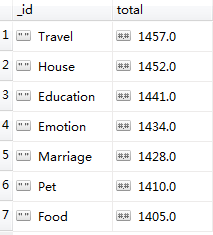
前后对比的结果是一致的!
五、后续优化
前面的章节演示了一个增量迁移的样例,在投入到线上运行之前,这些代码还得继续优化:
写入性能,线上的数据量可能会达到亿级,在全量、增量迁移时应采用合理的批量化处理;
另外可以通过增加并发线程,添置更多的Worker,分别对不同业务库、不同表进行处理以提升效率。
增量表存在幂等性,即回放多次其最终结果还是一致的,但需要保证表级有序,即一个表同时只有一个线程在进行增量回放。容错能力,一旦 watch 监听任务出现异常,要能够从更早的时间点开始(使用startAtOperationTime参数),
而如果写入时发生失败,要支持重试。回溯能力,做好必要的跟踪记录,比如将转换失败的ID号记录下来,旧系统的数据需要保留,
以免在事后追究某个数据问题时找不着北。数据转换,新旧业务的差异不会很简单,通常需要借助大量的转换表来完成。
一致性检查,需要根据业务特点开发自己的一致性检查工具,用来证明迁移后数据达到想要的一致性级别。
BTW,数据迁移一定要结合业务特性、架构差异来做考虑,否则还是在耍流氓。
示例代码
小结
服务化系统中扩容、升级往往会进行数据迁移,对于业务量大,中断敏感的系统通常会采用平滑迁移的方式。
MongoDB 3.6 版本后提供了 Change Stream 功能以支持应用订阅数据的变更事件流,
本文使用 Stream 功能实现了增量平滑迁移的例子,这是一次尝试,相信后续这样的应用场景会越来越多。
欢迎关注"美码师的公众号" -- 唯美食与技术不可辜负" ,期待更多精彩内容^-^
附参考文档
百亿级数据迁移-58沈剑
MongoDB-ChangeStream
Use-ChangeStream To Handle Temperature















