SLAM闭合回环————视觉词典BOW小结
在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/dorian3d/DBoW2,而bag of words 又运用了数据挖掘的K-means聚类算法,笔者只通过bag of words 模型用在图像处理中进行形象讲解,并没有涉及太多对SLAM的闭环检测的应用。
PART ONE 1.Bag-of-words模型简介
Bag-of-words模型是信息检索领域常用的文档表示方法。在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。 也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。举个例子就好理解:
例如有如下两个文档:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “likes”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数。不过,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序。
Bag-of-words模型应用于图像表示:
为了表示一幅图像,我们可以将图像看作文档,即若干个“视觉词汇”的集合,同样的,视觉词汇相互之间没有顺序。
视觉词典的生成流程:
于图像中的词汇不像文本文档中的那样是现成的,我们需要首先从图像中提取出相互独立的视觉词汇,这通常需要经过三个步骤:(1)特征检测,(2)特征表示,(3)单词本的生成。 下图是从图像中提取出相互独立的视觉词汇:
过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛, 嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
构建BOW码本步骤:
利用K-Means算法构造单词表。用K-means对第二步中提取的N个SIFT特征进行聚类,K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。聚类中心有k个(在BOW模型中聚类中心我们称它们为视觉词),码本的长度也就为k,计算每一幅图像的每一个SIFT特征到这k个视觉词的距离,并将其映射到距离最近的视觉词中(即将该视觉词的对应词频+1)。完成这一步后,每一幅图像就变成了一个与视觉词序列相对应的词频矢量。
假定我们将K设为4,那么单词表的构造过程如下图所示:
第三步:
利用单词表的中词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维数值向量。将这些特征映射到为码本矢量,码本矢量归一化,最后计算其与训练码本的距离,对应最近距离的训练图像认为与测试图像匹配。请看下图:
我们从人脸、自行车和吉他三个目标类图像中提取出的不同视觉词汇,而构造的词汇表中,会把词义相近的视觉词汇合并为同一类,经过合并,词汇表中只包含了四个视觉单词,分别按索引值标记为1,2,3,4。通过观察可以看到,它们分别属于自行车、人脸、吉他、人脸类。统计这些词汇在不同目标类中出现的次数可以得到每幅图像的直方图表示:
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]
其实这个过程非常简单,就是针对人脸、自行车和吉他这三个文档,抽取出相似的部分(或者词义相近的视觉词汇合并为同一类),构造一个词典,词典中包含4个视觉单词,即Dictionary = {1:”自行车”, 2. “人脸”, 3. “吉他”, 4. “人脸类”},最终人脸、自行车和吉他这三个文档皆可以用一个4维向量表示,最后根据三个文档相应部分出现的次数画成了上面对应的直方图。一般情况下,K的取值在几百到上千,在这里取K=4仅仅是为了方便说明。
总结一下步骤:
第一步:利用SIFT算法从不同类别的图像中提取视觉词汇向量,这些向量代表的是图像中局部不变的特征点;
第二步:将所有特征点向量集合到一块,利用K-Means算法合并词义相近的视觉词汇,构造一个包含K个词汇的单词表;
第三步:统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个K维数值向量。
具体的,假设有5类图像,每一类中有10幅图像,这样首先对每一幅图像划分成patch(可以是刚性分割也可以是像SIFT基于关键点检测的),这样,每一个图像就由很多个patch表示,每一个patch用一个特征向量来表示,咱就假设用Sift表示的,一幅图像可能会有成百上千个patch,每一个patch特征向量的维数128。
接下来就要进行构建Bag of words模型了,假设Dictionary词典的Size为100,即有100个词。那么咱们可以用K-means算法对所有的patch进行聚类,k=100,我们知道,等k-means收敛时,我们也得到了每一个cluster最后的质心,那么这100个质心(维数128)就是词典里德100个词了,词典构建完毕。
词典构建完了怎么用呢?是这样的,先初始化一个100个bin的初始值为0的直方图h。每一幅图像不是有很多patch么?我们就再次计算这些patch和和每一个质心的距离,看看每一个patch离哪一个质心最近,那么直方图h中相对应的bin就加1,然后计算完这幅图像所有的patches之后,就得到了一个bin=100的直方图,然后进行归一化,用这个100维德向量来表示这幅图像。对所有图像计算完成之后,就可以进行分类聚类训练预测之类的了。
图像的特征用到了Dense Sift,通过Bag of Words词袋模型进行描述,当然一般来说是用训练集的来构建词典,因为我们还没有测试集呢。虽然测试集是你拿来测试的,但是实际应用中谁知道测试的图片是啥,所以构建BoW词典我这里也只用训练集。
用BoW描述完图像之后,指的是将训练集以及测试集的图像都用BoW模型描述了,就可以用SVM训练分类模型进行分类了。
在这里除了用SVM的RBF核,还自己定义了一种核: histogram intersection kernel,直方图正交核。因为很多论文说这个核好,并且实验结果很显然。能从理论上证明一下么?通过自定义核也可以了解怎么使用自定义核来用SVM进行分类。
PART THREE 2.词袋模型在slam中的应用?
DBoW3库介绍
DBoW3是DBoW2的增强版,这是一个开源的C++库,用于给图像特征排序,并将图像转化成视觉词袋表示。它采用层级树状结构将相近的图像特征在物理存储上聚集在一起,创建一个视觉词典。DBoW3还生成一个图像数据库,带有顺序索引和逆序索引,可以使图像特征的检索和对比非常快。
DBoW3与DBoW2的主要差别:
1、DBoW3依赖项只有OpenCV,DBoW2依赖项DLIB被移除;
2、DBoW3可以直接使用二值和浮点特征描述子,不需要再为这些特征描述子重写新类;
3、DBoW3可以在Linux和Windows下编译;
4、为了优化执行速度,重写了部分代码(特征的操作都写入类DescManip);DBoW3的接口也被简化了;
5、可以使用二进制视觉词典文件;二进制文件在加载和保存上比.yml文件快4-5倍;而且,二进制文件还能被压缩;
6、仍然和DBoW2yml文件兼容。
DBoW3有两个主要的类:Vocabulary和Database。视觉词典将图像转化成视觉词袋向量,图像数据库对图像进行索引。
ORB-SLAM2中的ORBVocabulary保存在文件orbvoc.dbow3中,二进制文件在Github上:https://github.com/raulmur/ORB_SLAM2/tree/master/Vocabulary
二、K-Means聚类的效率优化
影响效率的一个方面是构建词典时的K-means聚类,我在用的时候遇到了两个问题:
1、内存溢出。这是由于一般的K-means函数的输入是待聚类的完整的矩阵,在这里就是所有patches的特征向量f合成的一个大矩阵,由于这个矩阵太大,内存不顶了。我内存为4G。
2、效率低。因为需要计算每一个patch和每一个质心的欧拉距离,还有比较大小,那么要是循环下来这个效率是很低的。
为了解决这个问题,我采用一下策略,不使用整一个数据矩阵X作为输入的k-means,而是自己写循环,每次处理一幅图像的所有patches,对于效率的问题,因为matlab强大的矩阵处理能力,可以有效避免耗时费力的自己编写的循环迭代。
三、代码
代码下载链接:PG_BOW_DEMO.zip
Demo中的图像是我自己研究中用到的一些Action的图像,我都采集的简单的一共6类,每一类60幅,40训练20测试。请注意图像的版权问题,自己研究即可,不能商用。分类器用的是libsvm,最好自己mex重新编译一下。
如果libsvm版本不合适或者没有编译成适合你的平台的,会报错,例如:
Classification using BOW rbf_svm
??? Error using ==> svmtrain at 172
Group must be a vector.
下面是默认的demo结果:
Classification using BOW rbf_svm
Accuracy = 75.8333% (91/120) (classification)Classification using histogram intersection kernel svm
Accuracy = 82.5% (99/120) (classification)Classification using Pyramid BOW rbf_svm
Accuracy = 82.5% (99/120) (classification)Classification using Pyramid BOW histogram intersection kernel svm
Accuracy = 90% (108/120) (classification)
当然结果这个样子是因为我已经把6类图像提前弄成一样大了,而且每一类都截取了最关键的子图,不太符合实际,但是为了demo方便,当然图像大小可以是任意的。
下图就是最好结果的混淆矩阵,最好结果就是Pyramid BoW+hik-SVM:
图6 分类混淆矩阵
这是在另一个数据集上的结果(7类分类问题):
Classification using BOW rbf_svm
Accuracy = 34.5714% (242/700) (classification)Classification using histogram intersection kernel svm
Accuracy = 36% (252/700) (classification)Classification using Pyramid BOW rbf_svm
Accuracy = 43.7143% (306/700) (classification)Classification using Pyramid BOW histogram intersection kernel svm
Accuracy = 55.8571% (391/700) (classification)
PART TWO 一、单目视觉SLAM
1.环境特征
分类:自然特征和人工特征;
必要性:移动SLAM机器人必须通过实时检测周围环境特征来对自身进行一个定位。
2.面临问题:
既包括路标位姿的估计,也包括机器人位姿与轨迹的优化。(在很多实际应用中,环境地图和移动机器人的位置都是未知的,且定位和地图构建二者相互依赖、互为耦合,使得问题求解非常复杂。)
3.解决方案
目前主要有两种解决方案:基于滤波器的方法和基于图的方法。

(2) 基于图的SLAM(Graph-basedSLAM)

算法致力于寻找一个最大可能的节点结构,得到一个最优位姿地图(近年来随着高效求解方法的出现,基于图的SLAM 方法重新得到重视,成为当前 SLAM研究的一个热点)
二、自然特征提取及视觉词典创建
2.1自然路标
优点:不改变工作环境,不需要额外设施和额外信息,并且在环境中大量存在;
缺点:受环境的影响较大,易受光线、遮挡、视角及环境相似度等变化的影响
2.2视觉词典
视觉词典是图像分类检索等领域的图像建模方法,该方法源于文档分析领域中的词典表示,词典表示将文档描述为词典中关键词出现频率的向量
2.3自然特征视觉词典创建框架

2.4具体实施
(1)用SURF(SpeededUp Robust Features)算子提取图像的自然局部视觉特征向量;(优点:保存了图像原有的色彩,而且改进了SIFT 算法计算数据量大、时间复杂度高、算法耗时长等缺点,可以用 64维向量建立特征点描述符,进一步提高了快速性和准确性)
(2)把相似的SURF 自然视觉特征向量划分为相同的自然视觉单词(采用 K-means算法对局部视觉特征集合进行聚类,一个聚类中心即为一个视觉单词);
(3)自然视觉词典的每一自然视觉单词采用GMM(GaussianMixture Model)方法进行建模自然视觉单词的概率模型,通过概率模型建立了更为精确的局部自然视觉特征与自然视觉单词间的匹配


2.5实例
包括:室内走廊和室外视觉词典





三、视觉词典的人工路标模型创建



四、闭环检测
目前视觉 SLAM 闭环检测领域大部分算法都是首先准确建立基于图像外观的场景模型,然后基于场景外观进行闭环检测
BoVW(Bagof visual words)算法步骤:
①用SIFT或SURF算子提取图像的局部特征,每个局部特征用相同维数的特征向量表示;
②将检测到的局部特征集合进行聚类,每个聚类中心对应一个视觉单词;
③构建表征图像的视觉词典,动态调整视觉单词数量以评估视觉词典的大小;
④图像由视觉词典中的视觉单词权重向量表征。
BoVW(Bag of Visual Words)算法将一副图像类比为一篇文档
①SLAM采集图像具有时间连续性,利用时间连续性提升检测的准确性。
②图像匹配的相似度计算方法与视觉 SLAM 的时间连续特征,利用贝叶斯滤波融合当前观测量(也即当前图像匹配的相似度)和前一时刻的检测信息计算当前时刻闭环检测的概率,由此设计一种基于贝叶斯滤波的闭环检测跟踪算法;
4.1基于人工视觉词典的闭合检测算法:

4.2基于贝叶斯滤波闭环检测算法:
相似度

图像内存管理


五、混合人工自然特征的单目视SLAM
5.1算法整体框架



六、发展方向
借助Wifi或者伪卫星信号;三维场景地图实时性构建;机器人陌生环境内学习(模拟人类学习过程)以及高效内存管理模式;
设定室内路标的规范;POS系统微型化;
引用博客来自:
[1]https://blog.csdn.net/u011326478/article/details/52463556?locationNum=4&fps=1
[2]http://www.cnblogs.com/zjiaxing/p/5548265.html
[3]https://blog.csdn.net/chapmancp/article/details/80179765
个人学习使用,如有疑问,请联系博主惊醒修正
相关文章:

【Codeforces】53D Physical Education (有点像冒泡)
http://codeforces.com/problemset/problem/53/D 从上面所给的序列变成下面所给的序列 交换的时候只能交换相邻的两个数字 输出每一步的交换方法,输出的是该元素在序列中的位置(第一个数的位置是1) 不要求输出步数最少的那一种方法 当同…
js脚本冷知识
js中有个很恶心的写法。比如这个var adsf(function(){})();这样的写法,主要是原生的,能在dom元素加载完之后实现自动加载这个脚本文件到里面去。可以验证这个(function(){.......)();在.......里面可以直接…

Python中is同一性运算符和==相等运算符区别
2019独角兽企业重金招聘Python工程师标准>>> 在区分is和这两种运算符区别之前,需要知道Python中对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。 比较对象的value(值) 是python标准操作符中的比较操作符…
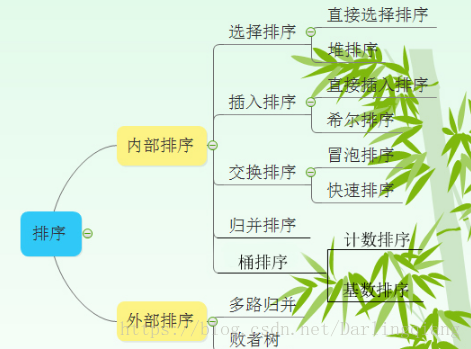
C++实现十大排序算法(冒泡,选择,插入,归并,快速,堆,希尔,桶,计数,基数)排序算法时间复杂度、空间复杂度、稳定性比较(面试经验总结)
排序算法分类 内部排序算法又分为基于比较的排序算法和不基于比较的排序算法,其分类如下: 比较排序: 直接插入排序 希尔排序 (插入) 冒泡排序 快速排序 (交换) 直接选择排序 堆排序(选择&#…
32位处理器是什么意思
问题描述:朋友那个32位处理器,2的32次方算出来的单位是不是应该是4294967296位(bit)吧,怎么就成字节了呢?单位错了,那个32位是指32位地址总线,而不是32位数据。地址的数量单位是个&a…

【Codeforces】913C Party Lemonade (贪...)。
http://codeforces.com/contest/913/problem/C 这个题和以前见过的有点不一样,可以重复选择,这个有点emmm 首先将a数组优化,举个例子,如果1L20元,2L50元,那么将a[1]赋值为40,而不是50。 之后…

GDB 调试 Mysql 实战(二)GDB 调试打印
背景 在 https://mengkang.net/1328.html 实验中,我们通过optimizer_trace发现group by会使用intermediate_tmp_table,而且里面的的row_length是20,抱着"打破砂锅问到底"的求学精神,所以想通过 gdb 调试源码的方式看这个…

移动端AR的适用分析(二)
移动端AR的适用分析(二)1. 单目SLAM难点 2. 视觉SLAM难点 3. 可能的解决思路 单目slam的障碍来自于理论和实践两个方面。理论障碍可以看做是固有的,无法通过硬件选型或软件算法来解决的,例如单目初始化和尺度问题。实践问题包括计…
新的理念、 新的解决方案、 新的Azure Stack技术预览
Jeffrey Snover 我们很高兴地宣布︰ Azure Stack Technical Preview 2(TP2)已发布!我们朝着向您的数据中心提供Azure服务能力的目标又更近一步。自发布第一个技术预览版(TP1)以来,我们访问了很多用户&…
【HDU】1084 What Is Your Grade? (结构体 sort)
http://acm.hdu.edu.cn/showproblem.php?pid1084 题目的关键: 1、Note, only 1 student will get the score 95 when 3 students have solved 4 problems. If you can solve 4 problems, you can also get a high score 95 or 90 (you can get the former(前者)…
FastDFS之Linux下搭建
1.软件环境 CentOS6.5 FastDFS v5.05 libfastcommon- - master.zip(是从 FastDFS 和 FastDHT 中提取出来的公共 C 函数库) fastdfs- - nginx- - module_v1.16.tar.gz nginx- - 1.6.2.tar.gz fastdfs_client_java._v1.25.tar.gz 2.FastDFS集群规划 描述 …
Linux进程与线程的区别 详细总结(面试经验总结)
首先,简要了解一下进程和线程。对于操作系统而言,进程是核心之核心,整个现代操作系统的根本,就是以进程为单位在执行任务。系统的管理架构也是基于进程层面的。在按下电源键之后,计算机就开始了复杂的启动过程…
【HDU/POJ/ZOJ】Calling Extraterrestrial Intelligence Again (素数打表模板)
http://poj.org/problem?id1411 POJ http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode1689 ZOJ http://acm.hdu.edu.cn/showproblem.php?pid1239 HDU 都是同一个题,但是可能你在HDU上AC,在POJ和ZOJ上是TLE(所以还有待…

[AVR]使用AVR单片机驱动舵机
最近参加了三系举办的小车比赛(好像叫什么"驭远杯")。领导要求我驱动3-4个舵机。研究了几日,总算折腾出一个方案..、 1.舵机驱动的基本原理 (可以参考http://blog.sina.com.cn/s/blog_8240cbef01018hu1.html) "控制信号由接收…
高阶函数的使用
问题 字节跳动面试时问题:原函数例如fetchData是一个异步函数,尝试从服务器端获取一些信息并返回一个Promise。写一个新的函数可以自动重试一定次数,并且在使用上和原函数没有区别。 思路 这个问题其实不是很难,不过可能是太菜了紧…
内存溢出和内存泄漏的定义,产生原因以及解决方法(面试经验总结)
一、定义(概念与区别) 内存溢出 out of memory,是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory;比如申请 了一个integer,但给它存了long才能存下的数,那就是内存溢出。 …
【Codeforces】716B Complete the Word (26个字母)
http://codeforces.com/contest/716/problem/B 给你一个字符串该字符串中是否存在长度为26且这26个字母没有重复 一个满足上述条件但是部分区域是问号的话,需要用剩下的字母覆盖掉问号,其余部分的问号可以随便赋值 没有的话输出-1 暴力即可。 #incl…

MySQL ERROR 1878 解决办法
MySQL ERROR 1878报错解决办法错误重现Part1:大表修改字段mysql> ALTER TABLE erp-> ADD COLUMN eas_status tinyint(3) unsigned NOT NULL DEFAULT 0 AFTER totalprice;ERROR 1878 (HY000): Temporary file write failure.mysql> \q这里可以看到,添加字…
共享程序集和强命名程序集(3):强命名程序集的一些作用
强命名程序集能防篡改 用私钥对程序集进行签名,并将公钥和签名嵌入程序集,CLR就可以炎症程序集未被修改或破坏。程序集安装到GAC时,系统对包含清单的那个文件的内容进行哈希处理,将Hash值与PE文件中嵌入的RSA数字签名进行比较。如…
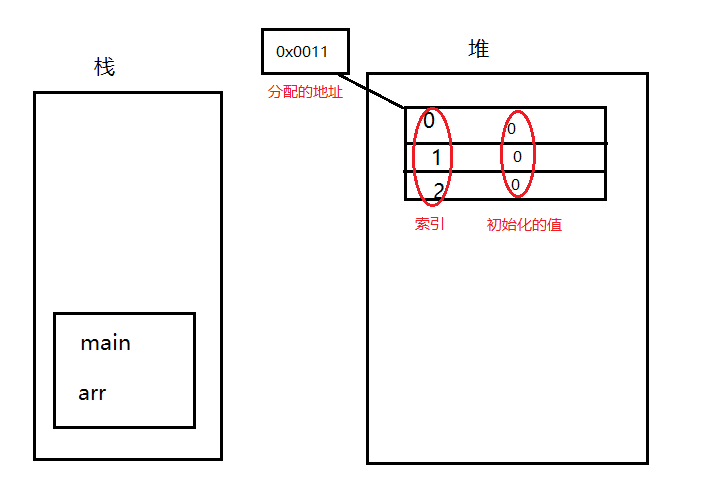
堆和栈的区别(面试经验总结)
C中,内存分为5个区:堆、栈、自由存储区、全局/静态存储区和常量存储区。 栈:是由编译器在需要时自动分配,不需要时自动清除的变量存储区。通常存放局部变量、函数参数等。 堆:是由new分配的内存块,由程序员…

百度Q3财报里的“大生意”
在今日发布的Q3财报中,百度花了不少篇幅来介绍人工智能业务的进展,作为百度的技术核心,近段时间几乎所有百度业务都在与人工智能做深入结合,这预示着移动互联网信息化技术发展已经全面开启人工智能时代,而百度势必要在…
【Codeforces/HDU】76A Plus and xor / 2095 find your present (2)(异或)。
http://codeforces.com/contest/76/problem/D A X Y B X xor Y 异或(不进位加法):两个二进制数,对应的位置上,相同为0,不同为1 性质:a^a0,a^0a,满足交换律 所以…
前端项目如何管理
前端项目如何管理 前端项目的管理分为两个维度:项目内的管理与多项目之间的管理。 1. 项目内的管理 在一个项目内,当有多个开发者一起协作开发时,或者功能越来越多、项目越来越庞大时,保证项目井然有序的进行是相当重要的。 一般会…
CMake学习(一)
什么是 CMake 你或许听过好几种 Make 工具,例如 GNU Make ,QT 的 qmake ,微软的 MS nmake,BSD Make(pmake),Makepp,等等。这些 Make 工具遵循着不同的规范和标准,所执行…
【Codeforces】1104C Grid game (变异的俄罗斯方块)
http://codeforces.com/problemset/problem/1104/C 4 X 4 的方格 放置 1*2的矩形(用1表示)和2*1的矩形(用0表示) 只要有一行或者一列都填满了,就会自动消除,就可以放心的矩形了,只要不重叠就可…
如何创建.gitignore文件,忽略git不必要提交的文件
1、在需要创建 .gitignore 文件的文件夹, 右键选择Git Bash 进入命令行,进入项目所在目录。 2、输入 touch .gitignore ,生成“.gitignore”文件。 3、在”.gitignore” 文件里输入你要忽略的文件夹及其文件就可以了。(注意格式) …
软件安全访谈:ZipSlip、NodeJS安全性和BBS攻击
正如Nodejs Security WG成员和Snyk开发者布道师Liran Tal所写的那样,自BBS早期以来,这种漏洞利用的矢量攻击已经为人所知。InfoQ采访了Tal,了解了更多有关软件安全性(尤其是Nodejs安全性)的相关信息。今年早些时候&…
客户端与服务器的数据交互
毕设需要接粗到一些关于app和前端后端的东西,学习记录一下。 首先不要管安卓端还是苹果端,现在一般都是响应式的app,放到安卓或者苹果或者pc或者平板都是没有问题的。一般采用的是http接口通讯,或者socket连接。具体你要去查资料…
【Codeforces】908B New Year and Buggy Bot(暴力+全排列)
http://codeforces.com/contest/908/problem/B 0 1 2 3 可以对应 上下左右。(具体哪个对应哪个,试过才知道) str 的 长度 为 100,0 1 2 3 的全排列一共24种,最坏的情况可以看成遍历长为2400的字符串,不会…
swoole实现数据库连接池
2019独角兽企业重金招聘Python工程师标准>>> 原生 PHP CURD 让我们来回顾一下PHP中数据库的使用 <?php # curd.php$id 1;$dbh new PDO(); $stmt $dbh->prepare(SELECT * FROM user WHERE id:id); $stmt ->bindValue(:id, $id); $user $stmt->f…