如何打造一流的视觉AI技术
本次分享主要分以下几个部分:首先简要介绍一下计算机视觉技术的相关背景,然后结合格灵深瞳的实践,从算法研发、训练平台、智能数据处理、异构计算等几个方面着重介绍如何打造一流的视觉AI技术,最后介绍格灵深瞳在相关技术落地方面的情况。
1、计算机视觉及其相关技术
1.1 计算机视觉概述
计算机视觉作为人工智能领域最重要的技术方向之一,其基础是机器学习算法,而深度学习算法无疑是当前最受欢迎的机器学习算法。随着计算机算力的不断增强,海量数据的增长,深度学习算法的提出使得用更大量数据训练更深的网络成为可能,在限定的场景下,一些图像识别算法的准确率已经超越了人类。从应用角度,我们正处于计算机视觉应用爆炸性增长的智能时代,包括移动互联网、自动驾驶、智慧城市、智慧医疗、机器人、增强现实、智慧工业等在内的多个方向,都取得了非常多的进步。从另外一个视角看,计算机视觉是对物理世界的数字化,是智慧物联网时代最大入口,和大数据技术结合拥有非常广阔的应用场景。
1.2 计算机视觉技术愿景
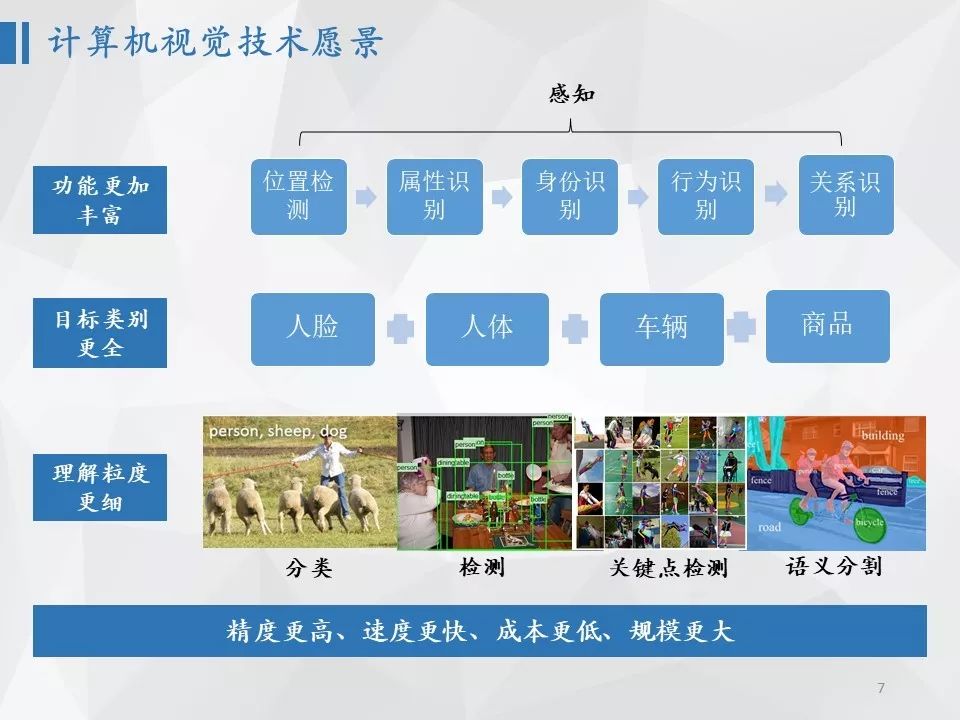
计算机视觉技术从广义上讲是让计算机看懂世界,狭义上讲就是通过丰富的视觉传感器,理解物理世界中每个物体的位置、属性、身份以及行为等信息。
计算机视觉技术从算法方面期待:
功能更加丰富:感知方面从位置检测、属性识别、身份识别,逐步向行为识别和关系识别(不同物体间的关系)发展;
目标类别更全:分析目标从人脸、人体、车辆,拓展到商品,再拓展到其它物体;
理解粒度更细:从理解图像中包含什么物体的分类任务,到理解物体在图中的具体位置和数目的检测任务,进一步到理解物体的部件以及关键点位置的关键点定位技术,更进一步到理解每个像素所属类别的语义分割任务。
计算机视觉技术从产品性能角度则期待:
精度更高、速度更快、成本更低、支持规模更大、功能更丰富。
2. 如何打造一流的视觉AI技术
2.1 构建计算机视觉系统的基本流程
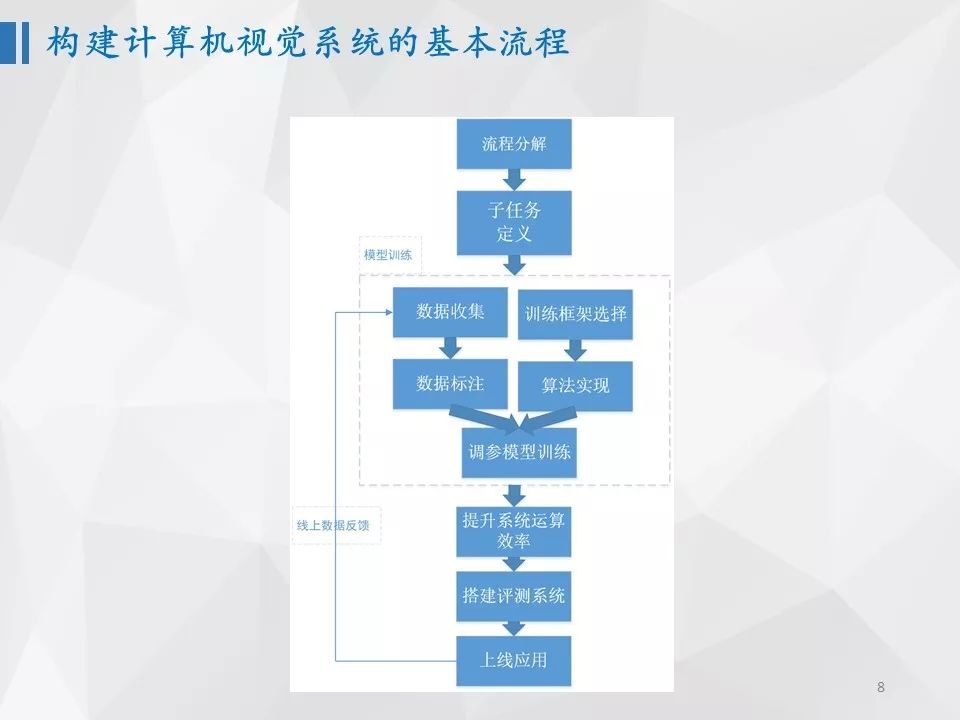
对于一个视觉应用系统而言,需要先将应用系统划分为不同的子模块,比如人脸识别系统,就包括人脸检测、特征点定位、人脸识别等不同子模块。对于每一个子模块,都由输入输出定义、数据收集、数据标注,训练框架选择,算法实现,模型训练,模型选择,模型上线等不同步骤组成。
2.2 构建视觉计算系统的关键因素
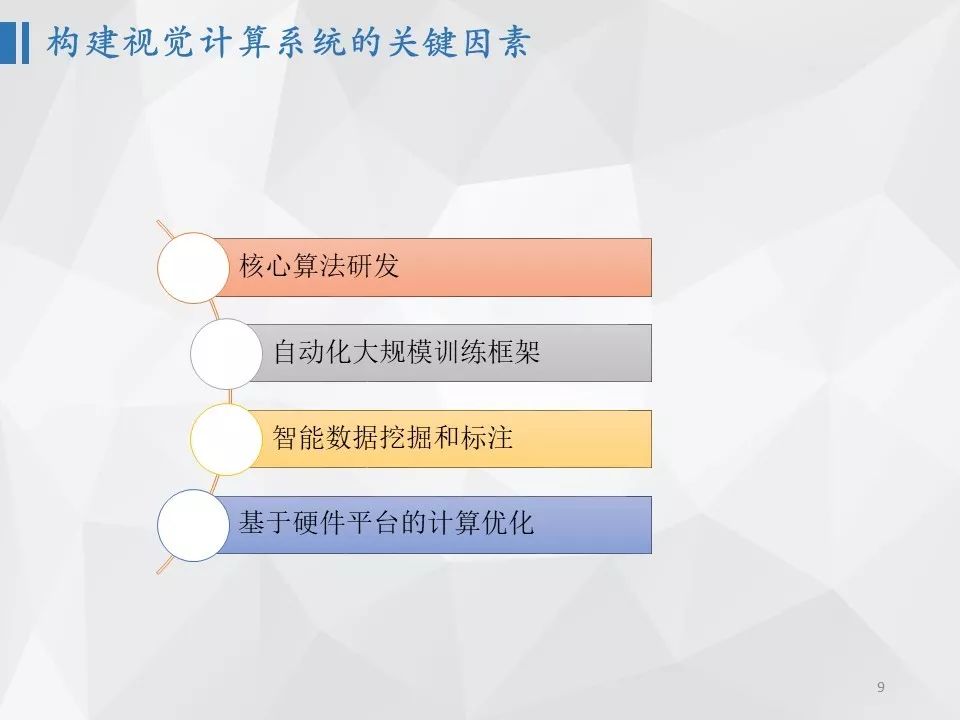
构建计算机视觉计算系统主要包含下面几个关键因素:
- 核心算法研发:即如何开发出更准确、更快、更多功能的算法;
- 自动化大规模训练框架:即如何支持更大规模集群,更加自动化地训练算法;
- 智能数据挖掘和标注:即如何做到高效的数据挖掘和低成本的标注;
- 基于硬件平台的计算优化:即如何选择硬件平台,以及在硬件平台上做性能优化。
2.2.1 核心算法研发

算法研发是一个不断迭代、精心打磨的过程,工业界和学术界最大的区别是学术界希望创造更多的算法,追求更多的是新颖性和创造性,而工业界追求的是系统的功能、性能、稳定性指标,并不要求发明最新颖的算法,而是要依据业务需求和资源限制做出最好用的系统。**在工业界进行算法改进,包括很多维度,如数据如何处理、数据规模和来源,参数设置、模型结构,还包括损失函数设计,模型加速算法等,每一个因素都可能对最终结果影响很大。还有非常重要的一点是,需要从系统角度去解决问题,比如设计新的系统处理流程,比如把问题定义为检测问题还是识别问题。
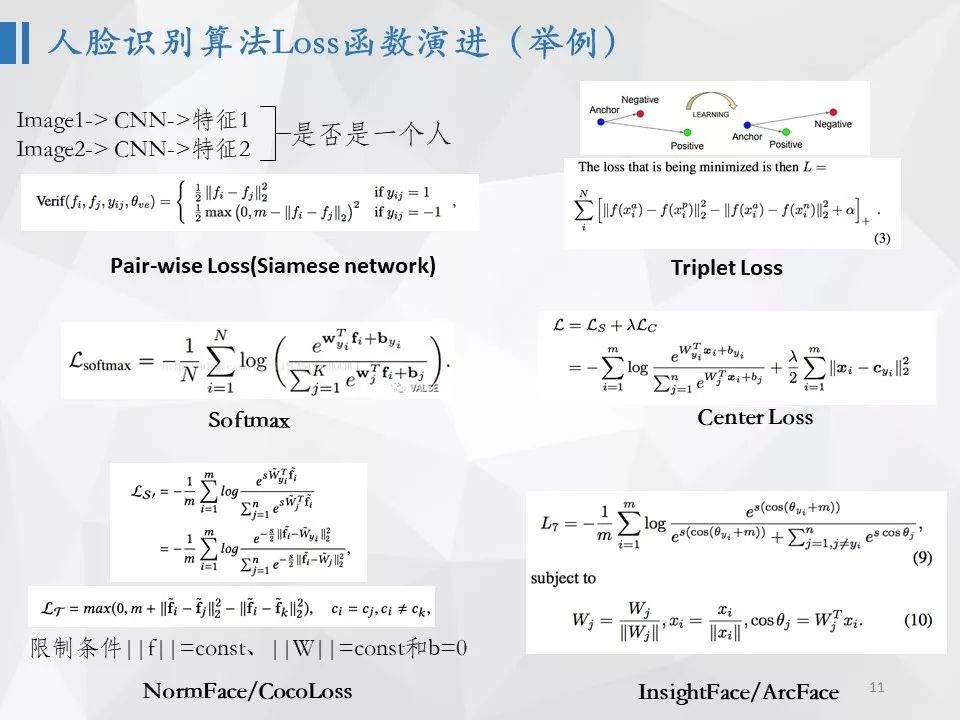
人脸识别损失函数演进
以人脸识别算法为例,由于我们无法训练一个能分类世界上所有人的分类模型,所以人脸识别最终是希望训练一个将人脸图像转换为表示能力非常强的特征模型,这里面非常核心的是损失函数的设计。最早的人脸识别算法是采用了softmax损失函数,但softmax损失函数的缺陷是当类别数非常大时参数规模非常大,并且,要求每个人的样本数比较均衡,且不能太少,很多时候无法满足。后来出现了pair-wise形式的损失函数,这个损失函数将分类转换为两类问题,即同一个人以及不同人两类,希望同一个人两张图片之间的距离尽可能小,而不同人两张图片之间的距离尽可能大,从而不会有类别太多的参数规模问题,且不对样本数目有太多要求。后来还出现了Triplet 损失函数形式,要求同一个人图片之间的距离小于不同人图片之间的距离。但是pair-wise和triplet损失函数的缺陷是容易受数据噪声影响,比较难训练,收敛也比较慢。后来大家又发现,将softmax形式做改进可以取得很好的效果,包括对特征的归一化、权重矩阵的归一化以及加margin等。所以,我们看到仅仅是人脸识别损失函数这样一个技术点,就包含了非常多的选择和迭代。在工业界,想真正做好一个算法模型,就都需要跟踪很多工作,同时由于论文里的很多结论在大规模实际数据情况下,和论文中的结果可能会不同,所以需要结合实际数据和场景进行一一验证。这要求我们在工业界真正想做一流的算法,不仅仅要求我们可以正确理解论文中的算法思路,还要求能够在工业界的数据规模下正确实现,并设置正确的参数和训练技巧,同时还需要结合实际情况去改进。

对于人脸识别系统而言,损失函数是影响人脸模型表示的一个因素。除此之外还包括训练数据的数据量、纯度和数据分布,数据增强的方式,比如收集的数据往往数据质量比较高,为了使得模型在低分辨率数据上有好的效果,需要在训练过程加入相应的扰动。除此之外,人脸识别的前序模块,比如人脸检测和特征点定位的精度也会影响识别效果。还有包括如何利用模型蒸馏等方法进行速度提升,如何利用人脸的多个部件融合进行效果提升,在视频中,如何通过人脸质量属性选择最优的人脸进行识别,如何融合多帧图像进行处理等。对于一个人脸识别系统而言,上述的每一个因素都会影响最终的系统效率和用户体验,每一点都需要精细打磨。
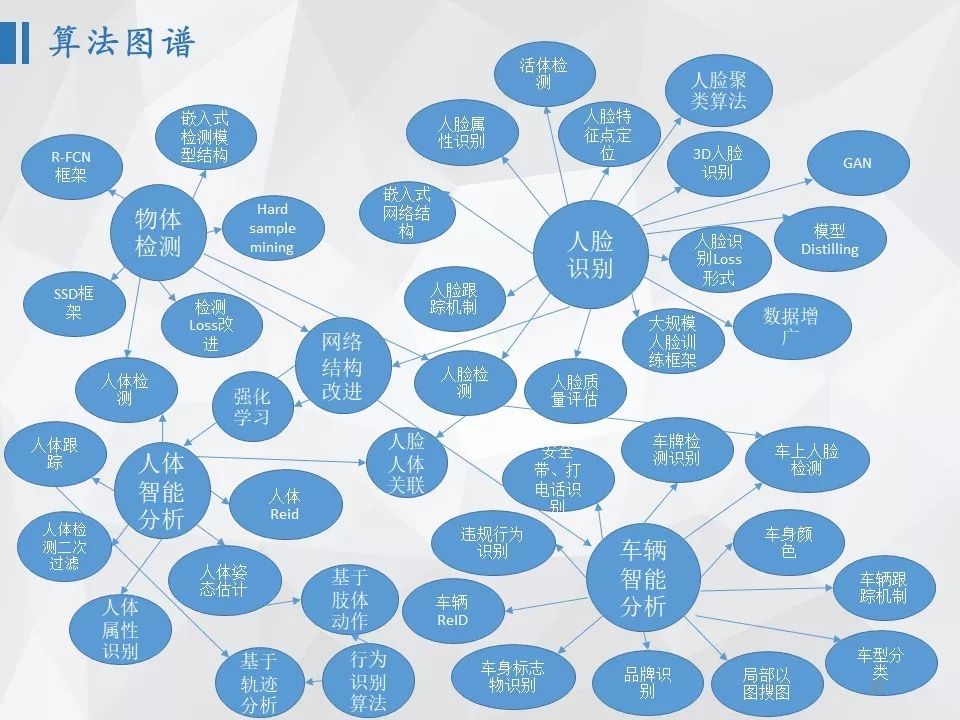
每一个智能系统都是由多个智能算法模型组成的,以我们针对智慧城市、智慧商业领域研发的智能视频理解系统而言,包括几百个模型。这个系统里面,从大的方面讲,包括物体检测、人脸识别、人体智能分析、车辆智能分析等几个大模块,具体到比如智能车辆分析这个子方向而言,则包括车牌识别、车型车款识别、车辆以图搜图(ReID)、车身颜色识别、标志物识别、未系安全带、开车打电话等很多子模型。
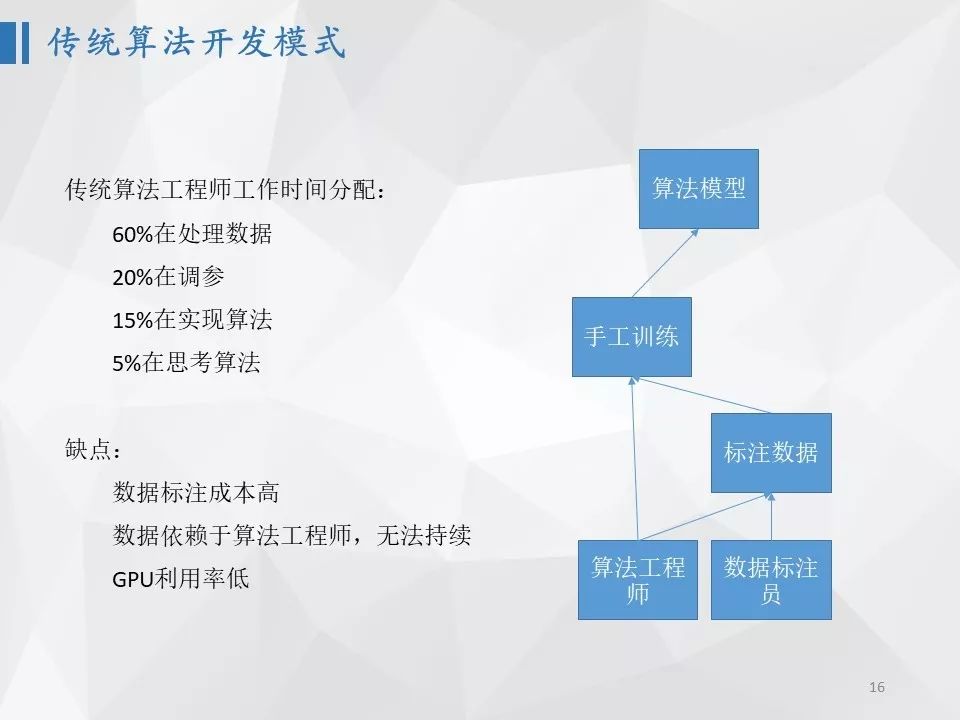
对于如此多的算法模型,如果每个模型都需要不断迭代,同时要支持不同硬件平台的不同版本,在研发人员和训练硬件资源受限条件下,如何持续打磨核心算法是一个很大的挑战。传统的算法开发模式,算法工程师往往提起数据标注任务,由数据标注员标注完成数据标注,但算法工程师需要关心如何开发标注工具、如何培训标注人员、如何转换数据格式、如何提纯标注完的数据,最后再手工方式在一台物理机上将模型训练出来。这种模式下,算法工程师有60%的时间都在处理和数据相关的工作,比如搜集数据、指导开发标注工具、清洗标注数据或者发起二次标注;还有20%的时间是在调参数,看训练日志,包括处理磁盘空间不足、GPU被别人占用等意外;其实只有大约15%左右的时间在实现算法,仅有5%的时间在思考算法。同时,这个模式的缺点是数据标注成本很高,算法工程师的时间利用率很低,同时由于没有统一协调,GPU或者空闲或者被大家抢占,GPU的利用率也很低。
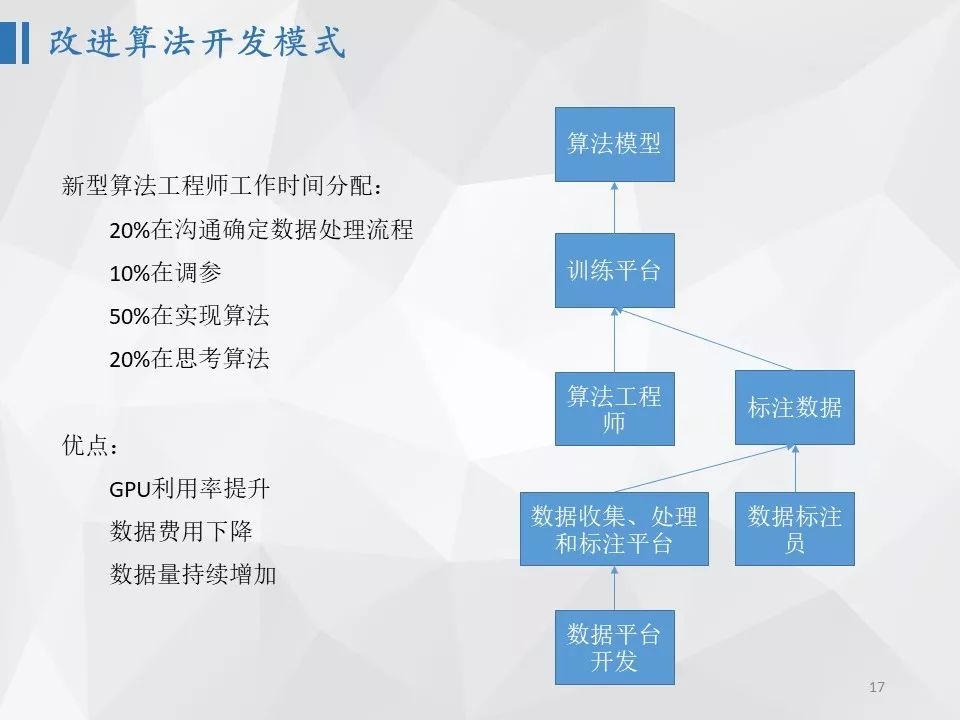
更好的一种模式是为算法研发团队配备一个数据平台开发团队,专门负责算法团队所需要的数据以及训练平台。也就是说,算法团队仅仅需要提出数据的需求和要求,其它都由数据平台团队去完成。数据平台团队负责数据的收集、标注前处理、标注工具开发、标注后处理、训练和测试数据管理等工作,其目标是为算法团队用最高效低成本的方式提供高质量的训练数据。同时,为了提升训练效率,数据平台团队还需要负责打造统一的训练平台。这种模式下,算法工程师的工作20%花在沟通确定数据处理流程,同时由于有统一的训练平台,算法工程师只需要花费大约10%的时间在训练调参上。那么自然就会花费更多的时间在实现算法和思考算法上。这种模式下,不仅仅算法工程师的效率得到提升,而且数据标注成本在降低,数据增长速度在提升,GPU利用率也在提高。还有一点非常重要的是,智能数据处理平台在正常运行下,只需要标注人员进行标注,数据量就会不断增长,不依赖算法以及开发人员的投入,这是未来任何一个智能学习系统需要具备的特性。
2.2.2 自动化大规模训练框架
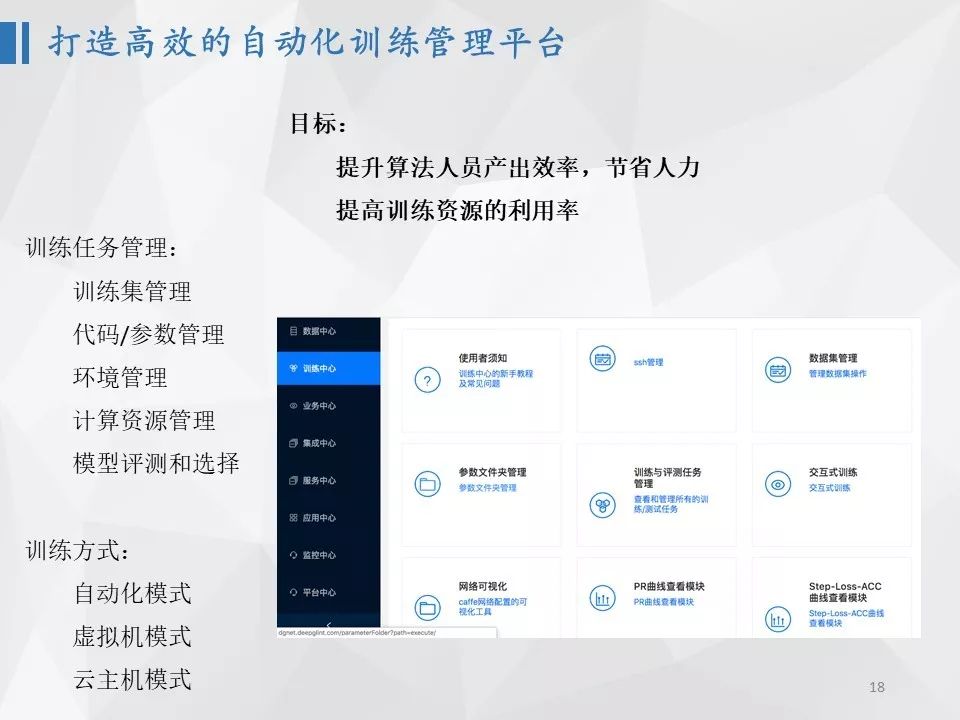
构建自动化训练管理平台的目的是为了提升人员产出效率,节省人力,提高训练资源的利用率。一方面对训练数据进行统一管理,每台机器都能访问,避免在机器间拷贝;第二,对训练代码和参数进行管理,实现代码、参数、环境自由在多台机器间拷贝,省去环境搭建的时间;第三,对计算资源和任务进行管理,省去工程师关注资源空闲的时间,同时,可以在没有空闲资源时任务排队,省去关注时间,同时提升资源利用效率。此外,为了避免算法人员看日志的时间花费,增加模型评估和选择,自动评估和选择模型。对算法人员而言,可以在网页新建任务,选择训练数据,确定代码和参数,就可以开始训练,同时可以设置几套参数进行训练,最终等待训练产出的最优模型即可。
现在已经有很多优秀的深度学习开源框架,比如tensorflow、mxnet、pytorch等。有一些创业公司,自己自行开发了一套自己的开源框架,但我个人认为其实没有太大的必要。一方面,私有的框架,很难保证比开源框架更加先进,开源框架吸收了世界上最先进的思想,有很多优秀的人会产生贡献,创业公司很难有这样的实力做得更好。此外,自己开发的框架,对于新入职员工而言有使用门槛,此外,由于很多好的算法都是在开源软件基础上做的,使用自己的框架也不利于进行技术交流。但是,是不是直接利用开源软件就够了呢?我想答案也是否定的。现在的开源框架,在大规模数据训练方面做得还不是很好,总是会有一些特别的任务是开源软件无法支持的。所以,基于现有开源软件,根据自己的任务做框架改进是一个对大多数公司而言都更加合理的选择。
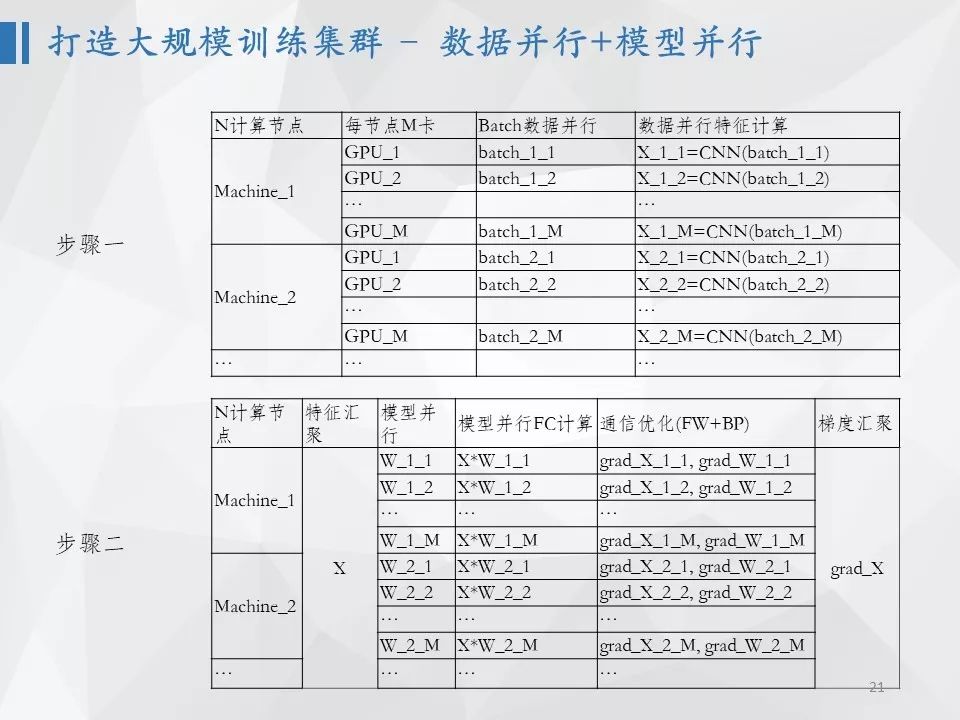
比如对于人脸识别任务而言,最终是一个上亿类别的分类问题,如果直接采用现有框架,是无法完成这个任务的。采用softmax作为损失函数,在特征维度仅仅是128维时,最后一个权重矩阵的数据规模是几十G,远远超过了现在显卡的显存。我们必须实现一种新的框架来完成数亿类别的训练任务。我们采用了一种“数据并行+模型并行”的方法,先将数据分配到不同的GPU上,先进行前向预测计算得到经过卷积网络之后的特征,然后将不同卡上的特征进行汇聚。但权重矩阵在一台机器上是无法保存下的,因此,需要把权重矩阵分配到不同的机器上进行运算这个时候就用到模型并行思路。我们知道,在并行计算中,计算是比较容易通过并行解决的,但是,通信量往往会成为瓶颈。我们设计的这个数据并行加模型并行的方式,只需要把所有样本的特征在多机间做同步,数据量很少,所以可以得到很高的加速比。
2.2.3 智能数据挖掘和标注

我们大家都知道数据很重要,但如何低成本、高效地获取大量高质量数据其实是一件不那么容易的事情。最简单处理数据的方法就是收集数据直接人工标注,但直接标注的缺陷是效率很低,比如直接标注百万级别人脸数据,需要花费近百万费用,如果标注数亿数据,费用显然是无法承受的。一种常见思路是选择标注工作量小的有先验约束的数据源,如相册数据,每个人的相册基本上都是来自于家人或者朋友的数据,这样的数据,直接标注也不合理,比如隐私问题,比如人的标注准确率问题。
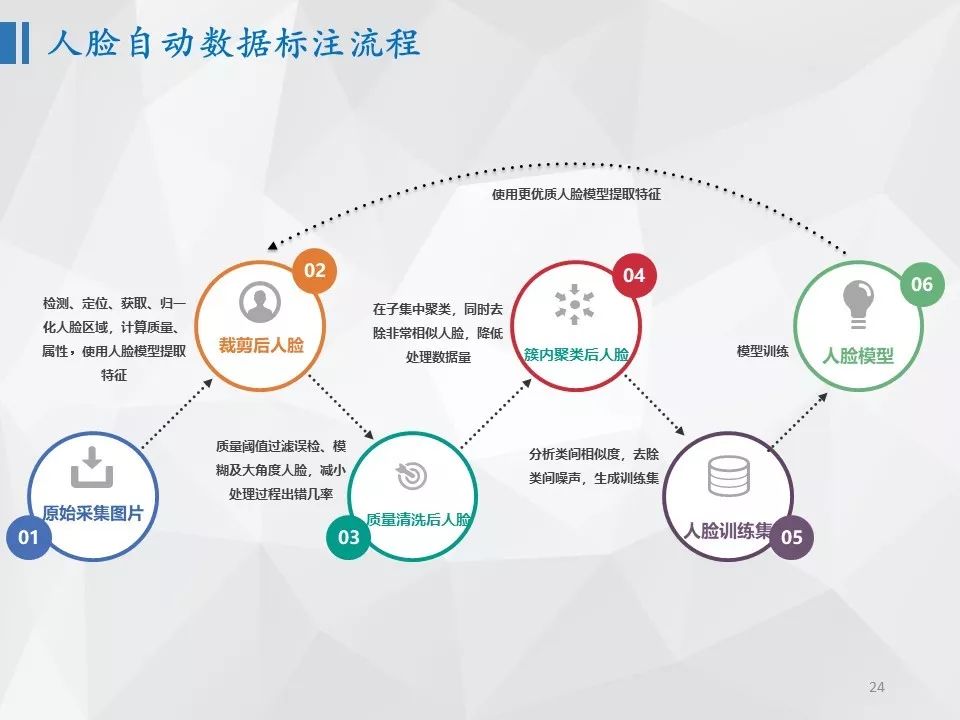
我们实现了一套人脸自动数据标注系统,包括如何从图片中检测、定位人脸,包括人脸区域割取、特征提取,包括人脸质量获取,以及基于人脸质量做过滤,包括做子集中的聚类,以及类间去重,以及训练人脸模型,同时,人脸模型还可以反馈重新进行人脸特征提取和聚类,不断迭代。当然,实际系统要更加复杂,有非常多的参数和细节逻辑,但是,这样的一套系统,使得人脸识别数据标注成为一个自动化的过程,基本上不需要人工再参与,节省了大量的标注人力。类似的案例还有很多,比如可以依据车牌号码进行车辆相关数据收集,可以只标注一辆车的属性就可以得到同一个车牌的多辆车的结果。总之,实践表明,在数据上花费的所有努力都是值得的,这已经成为技术驱动的创新型公司的核心竞争力之一。
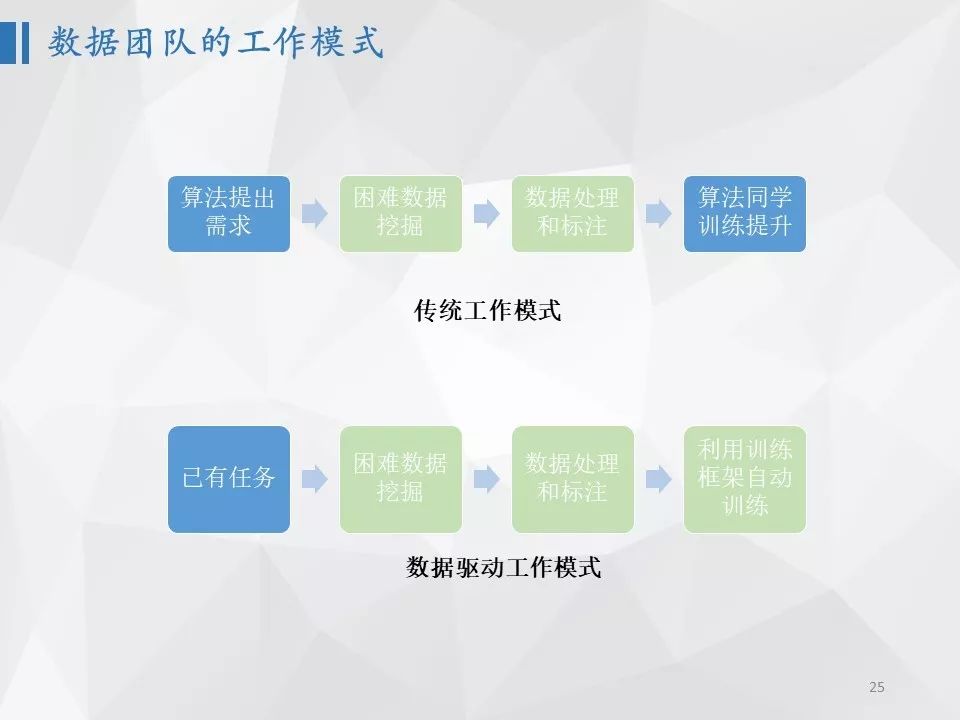
数据平台团队,除了准备数据和开发训练平台外,还可以参与算法的训练和改进工作。很多算法,经过算法工程师的迭代之后,在算法方面已经相对确定,更多的是调参和数据相关工作。这一块是可以由数据平台工程师通过数据驱动的方式来改进的。比如,我们在一些任务中,就在算法工程师基本不需要参与的情况下,数据平台工程师通过高效挖掘困难数据并标注的方式可以使算法持续改善。
上述的智能数据处理和自动化训练平台系统,结合起来,在我们的内部被称为深瞳大脑项目。深瞳大脑的终极目标是希望将人工智能中人工的部门减少到最少,打造一套动态更新的“数据采集-\u0026gt;标注-\u0026gt;算法研发-\u0026gt;模型训练-\u0026gt;产品落地-\u0026gt;数据产生”的闭环系统,最终仅仅在数据标注环节依赖人工,成为一套真正的基于自主学习的智能系统。
2.2.4 基于硬件平台的计算优化

除了算法效果、算法功能外,还需要考虑预测速度以及承载硬件的成本。最底层是芯片等硬件平台的选择,之上是预测框架,再之上是sdk封装以及处理流程和分布式架构,再上层则是各种视觉应用。

这其中涉及很多工作,如硬件的选择,GPU、Arm、FPGA、DSP还有专门为深度学习设计的ASIC芯片。硬件平台对整个计算机视觉识别系统非常重要,为了做一个正确的平台选择,需要考虑主芯片的计算能力、成本,接口支持丰富程度,以及编解码、ISP,软件兼容性以及平台易用程度等。选定硬件平台之后,首先应该从算法角度考虑如何减少计算量。比较简单的是基于经典网络去改变总的层数以及每层特征通道数目。进一步,可以结合各种经典网络去设计自己的网络,比如在嵌入式平台上,可以参考Depth-Wise结构、Shuffle Net结构中的核心思路设计自己的新网络。还可以基于强化学习模型搜索更优的网络。此外,还有一个非常重要的思路,就是如何通过模型蒸馏的方法去使得一个小网络训练得到接近大网络的效果。除了算法层面外,还可以从异构计算层面利用各个平台特性进行优化,比如英伟达GPU平台可以优先考虑TensorRT以及CUDA指令进行优化。
3. 格灵深瞳公司介绍及相关应用落地情况
3.1 公司愿景
格灵深瞳成立于2013年,公司的愿景是让计算机理解世界,让AI使生活更美好。我们专注于研发包括计算机视觉在内的人工智能核心算法,并把先进的人工智能科技转化为具备低成本、大规模部署能力的产品和服务,并深度结合应用场景,为用户提供高性能、可靠实用的智慧解决方案。
在核心算法层面,我们在人脸识别、人体再识别、车辆智能分析等方向都处于行业领先水平。以人脸识别为例,在十亿次误识一次的情况下,识别率可以达到90%;在车辆的主品牌、子品牌和年款识别上,总类别数可以达到20000种;在行人再识别上,我们的线上模型在没有针对测试数据训练的情况下,在Market1501上面首选识别率达到98.1%,超过目前所有的公开结果。
在核心引擎层面,我们打造了一套全目标视频结构化引擎,支持人脸识别、人体识别、车辆识别以及非机动车识别,支持视频、图像、历史流、历史视频文件等多种模式,而且性能指标非常高,普通模式下单机可以做到320路,高速模式下单机可以做到1000路。
3.2 以深瞳大脑为核心的技术产品研发架构
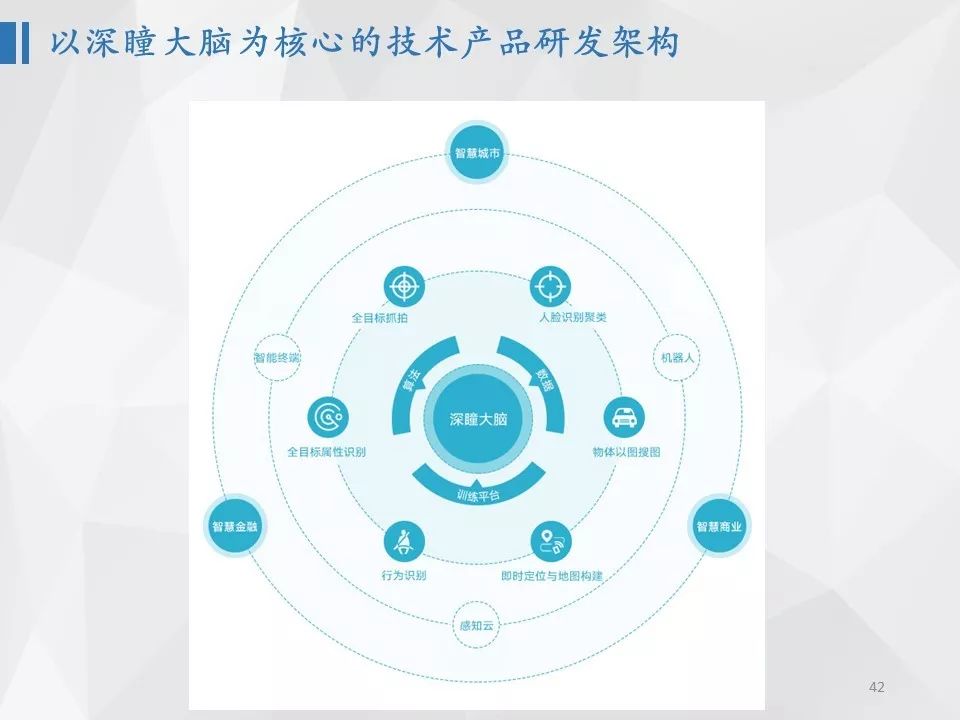
以数据、算法、训练平台为核心,我们构建了深瞳大脑架构,基于深瞳大脑,我们可以不断地产出业界领先的各种算法,比如全目标抓拍算法、全目标属性识别算法、人脸识别聚类算法、物体以图搜图算法、行为识别算法、即时定位和地图构建等技术。再结合大数据分析技术、高性能计算以及智能硬件技术,我们可以研发出各种各样的智能终端、感知云和机器人产品。而基于这些产品,我们可以打造针对公共安全、智能交通、智能银行、智慧社区、智慧校园、智能零售等行业的解决方案。
3.3 应用及解决方案
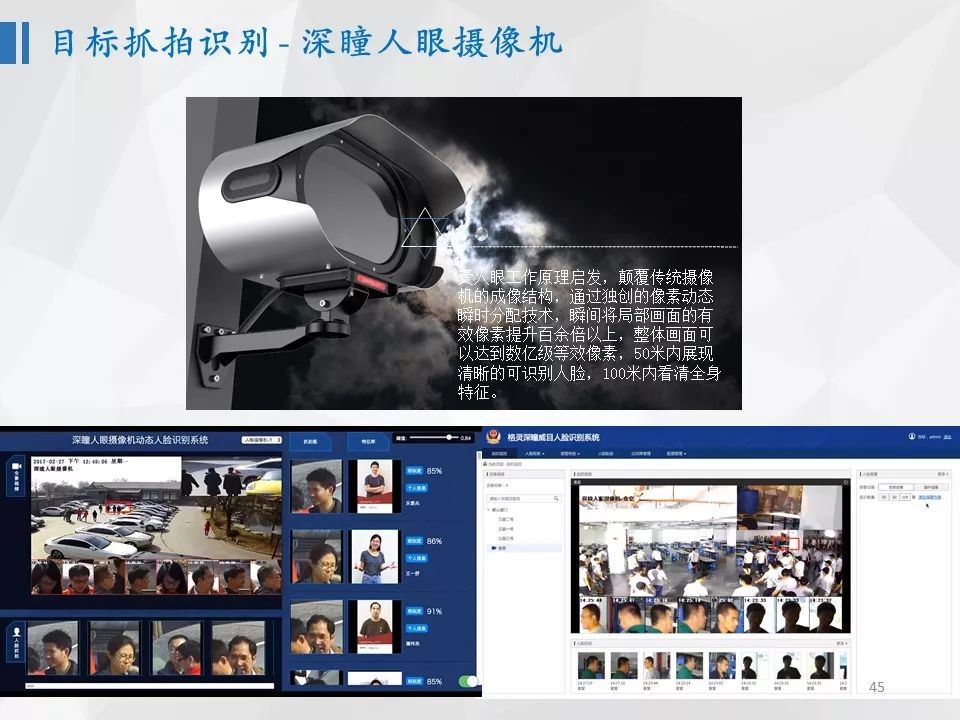

我们开发了各种不同的智能硬件产品,包括模仿人眼的可以抓拍到五十米之外人脸的深瞳人眼摄像机,包括可以利用3D信息识别人体行为的皓目行为分析仪,还包括智能机器人。在行业应用上,我们针对智慧城市和智能商业上也做了很多智能解决方案。这里举两个小例子。
对于公安中最常见的视频找人应用,以前都是基于人脸识别做,但是很多摄像头因为角度因素或分辨率是拍不到人脸信息的。可以先利用人体图像搜索得到附近摄像头中的一系列人体图像,在这些人体图像中,有些会包含正面人脸,再利用人脸图像进行人脸检索,最后得到人的身份。这样的方式,可以很好的利用公安的现有摄像头,在实战中非常实用,已经帮助用户破获了多起案件。
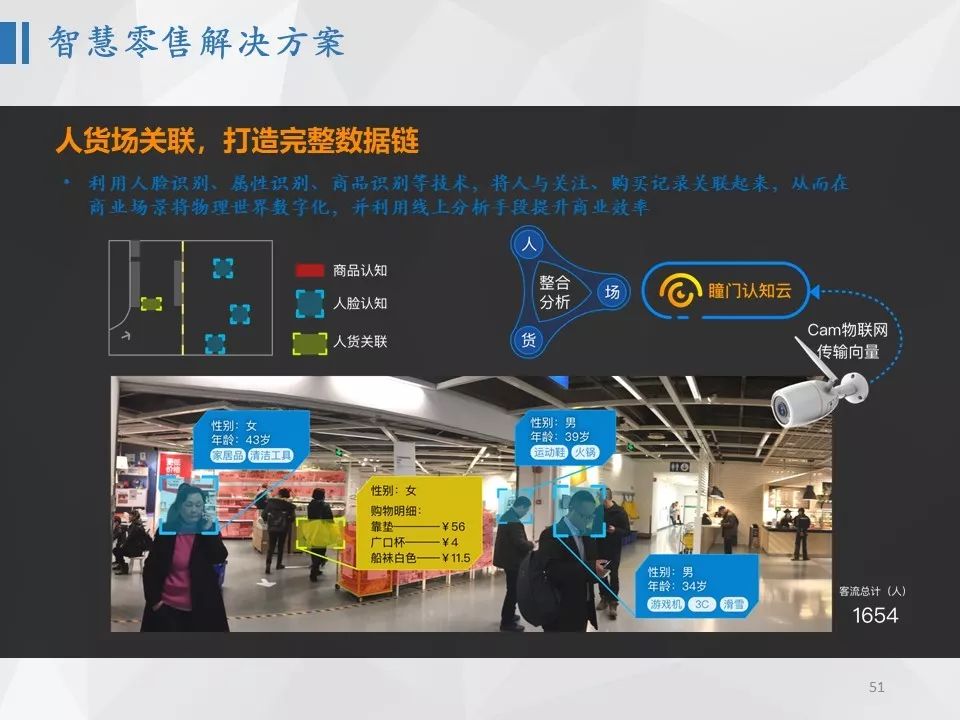
智慧零售也是计算机视觉非常重要的应用场景,其核心思想是希望通过计算机视觉技术,将线下的人、货、场数据进行数字化,帮助更好的做商业运营和智能营销。一个很有趣的应用场景是,通过人脸识别技术,将人脸作为人的身份标识,将一个人多次消费或关注的数据关联起来,从而能把线下购买数据数字化,并更好的对人进行建模,同时还可以形成商场里面的动线和热力图。
4. 未来趋势
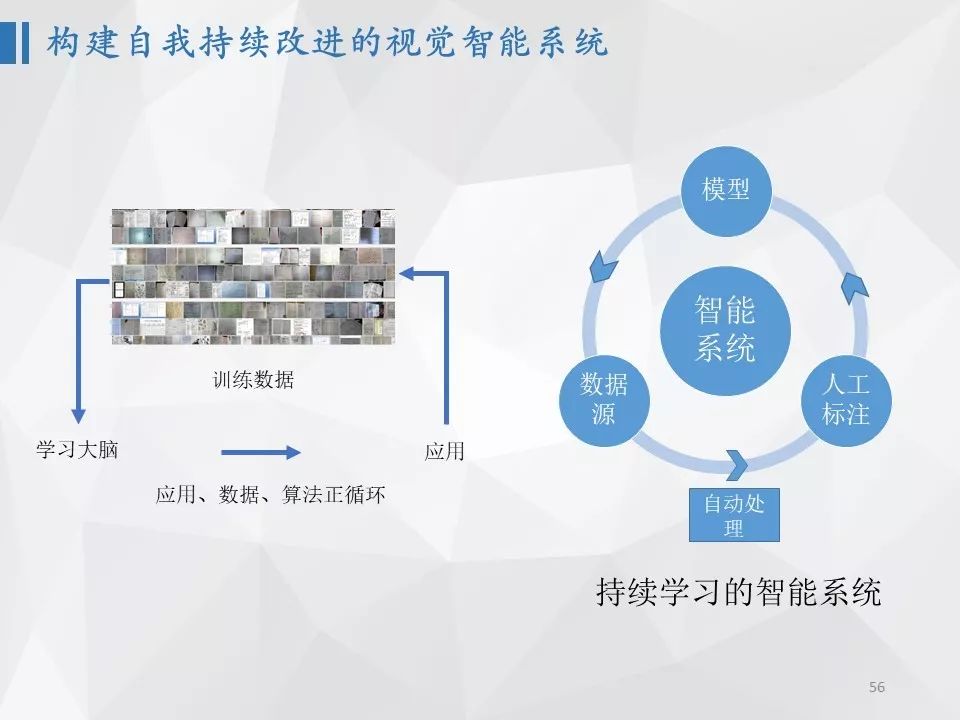
未来,希望可以构建一个数据驱动、自我学习的智能视觉系统,随着应用、数据和算法的不断演进逐渐变好。
人们往往高估一项技术的短期表现,却又低估其长期表现,人工智能的路还很长,最终必然是一次长跑。我们希望能够做对人类有价值的人工智能,做有温度的人工智能!
作者介绍

邓亚峰,北京格灵深瞳信息技术有限公司CTO,毕业于清华大学,曾任职百度深度学习研究院,负责人脸识别方向,具有16年的计算机视觉和人工智能方向的研发经验。发表过论文十余篇,申请中国专利超过100项,其中已经授权的有95项。
本文来自邓亚峰在 DataFun 社区的演讲,由 DataFun 编辑整理。
相关文章:

MATLAB【六】 ———— matlab 随机散斑模拟
%% %input for image size(NX,NY) <散斑图大小(像素)> NX 1280; NY 800; %input for numble of speckles(S)<散斑数量> S 9226; %输入的散斑大小 a 4; %input for peak intensity of each speckle(I0)<散斑峰值强度> I0 1; %input …
【Python】zip函数
zip()函数用于将可迭代对象作为参数,将对象中对应的元素打包成一个个元组,然后返回这些由元组组成的列表。 如果各个迭代器的元素不一致,则返回列表长度与最短的对象相同。 利用*号操作符,可将元组解压为列表。 >>> a …
CentOS 7.0,启用iptables防火墙
CentOS 7.0默认使用的是firewall作为防火墙,这里改为iptables防火墙。1、关闭firewall:systemctl stop firewalld.service #停止firewallsystemctl disable firewalld.service #禁止firewall开机启动2、安装iptables防火墙yum install iptables-services…
手撸 webpack4.x 配置(一)
现在的前端开发框架 ,都绕不开 webpack 打包 。 但绝大数前端开发人员 基本都是用 脚手架 自动生成 一套开发环境 如: vue-cli , create-react-app等 , 但开发中总会遇到各种问题 ,基本都是 webpack 配置问题 , 每次遇到基本都是…
MATLAB【七】———— matlab 高斯核使用,超像素图像模拟,矩阵转图像,深度相机模型实践实现
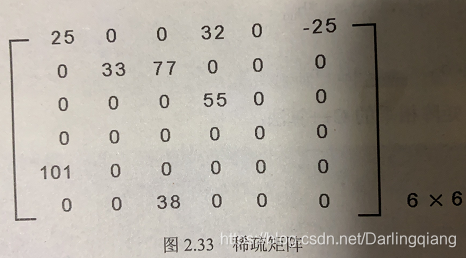
深度模型,图片转稀疏矩阵,稀疏矩阵转图片 %% mat to 2array temp_speckle ref_speckle; [row_index,col_index,v]find(temp_speckle); obj_matrix [row_index,col_index]; [obj_matrix_height,obj_matrix_width] size(obj_matrix);%% depth camera m…
jsp 出现cannot be resolved to a type问题解决办法
(1)检查<% page import>是否导入了相关的包。若是没有则需导入 (2)若导入相应的包后问题仍然存在则需创建相关的servlet转载于:https://www.cnblogs.com/wth21-1314/p/6126655.html
U盘中毒了?教你如何删除System Volume Information这个顽固文件夹
不得不说cmd命令很好用呢。最近我的U盘中毒了,格式化都删除不了System Volume Information这个顽固的文件夹,真心伤不起哇!还好现在解决了问题。看来以后得好好对待U盘,不能乱用了。本篇文章教大家如何删除System Volume Informat…
69亿美元英伟达史上最大收购!这家基金又赢了
。另一方面,在虚拟货币的浪潮告一段落之后,英伟达需要给增速放缓的数据中心业务注入一枚强心剂。 有意思的是,英伟达对Mellanox的收购也成就了国际知名维权对冲基金Starboard Value LP的又一次投资胜利。 击败微软、英特尔,交易…
基础数据结构【一】————数组
二维数组相乘,矩阵相乘, #include <iostream> using namespace std;void MatrixMultiply(int*, int*, int*, int, int, int); int main() {int M, N, P;int i, j;//矩阵A部分 cout << "请输入矩阵A的维数(M,N): " << endl;…
Fragment 和 FragmentActivity的使用
Fragment 和 FragmentActivity的使用 http://blog.csdn.net/izy0001989624/article/details/17072211转载于:https://www.cnblogs.com/as3lib/p/6126761.html
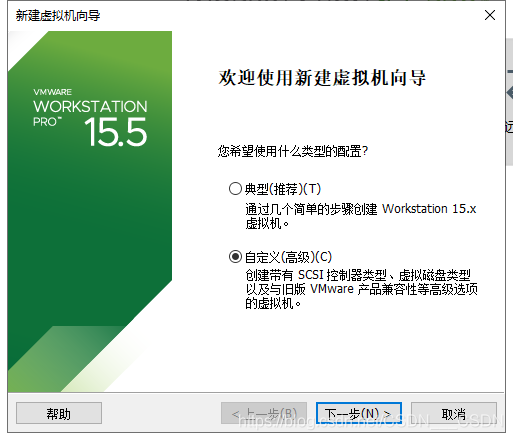
win10 VMware15 安装 CentOS6.4 64位(慢慢弄吧,别急)
参考:CentOS 6.4安装(超级详细图解教程) 可以都不勾,有需要,以后使用中有需要再手动安装 除了KDE,其他都选就可以了 系统管理、虚拟化、负载平衡器、高可用性可以都不选
Nginx网站常见的跳转配置实例
相信大家在日常运维工作中如果你用到nginx作为前端反向代理服务器的话,你会对nginx的rewrite又爱又恨,爱它是因为你搞定了它,完成了开发人员的跳转需求后你会觉得很爽,觉得真的很强大,恨它是因为当一些稀奇古怪跳转的需…
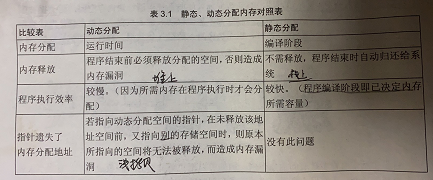
基础数据结构【二】————动态数组,单向链表及链表的反转
DEMO1: 动态分配变量(链表,而静态数组是线性表,意味着动态数组访问和遍历复杂度为O(n),而插入和删除复杂度为O(1),而静态数组线性表则完全相反) int* in…

VMware15克隆虚拟机Centos
在克隆虚拟机之前,我们需要了解以下文件: 1、/etc/udev/rules.d/70-persistent-net.rules 这是网卡有关信息的配置文件,我们可以先查看一下master的网卡信息(当然也可以用ifconfig命令查看) 要注意的是网卡名称以及…
EXPDP 时ORA-27054 问题处置
现象:[oracleoracle1 ~]$ expdp xian/xian schemasxian directorydumpdir dumpfilexian.dmp LOGFILExian.logExport: Release 10.2.0.5.0 - 64bit Production on Friday, 02 December, 2016 20:19:48Copyright (c) 2003, 2007, Oracle. All rights reserved.Connec…

OSC源创会往期图文回顾链接地址收藏
为什么80%的码农都做不了架构师?>>> 格式:源创会报名链接地址 - 源创会结束后图文回顾链接地址 【深圳】第1期】- 图文回顾【广州】第2期】- 图文回顾【北京】第3期】- 图文回顾【珠海】第4期】- 图文回顾【深圳】第5期】- 图文回顾--------…

ionic + cordova+angularJs 搭建的H5 App完整版总结
为期半个月的项目实践开发,已完整告一段落,团队小组获得第一名,辛苦总算没有白费,想起有一天晚上,整个小组的人,联调到12点才从公司回去,真是心酸。这里总结一下,项目过程中遇到的问…
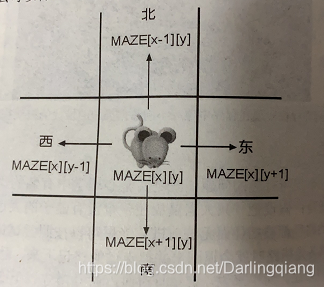
基础数据结构【三】————老鼠走迷宫问题————堆栈应用
假设:老鼠在一个二维地图中i行走,地图中大部分路径被墙阻断,无法前进。老鼠可以按照尝试错误的方法找到出口。只是,这只老鼠必须具备走错路时候就退回来,并且把走过的路记下来,避免下次走重复路,…
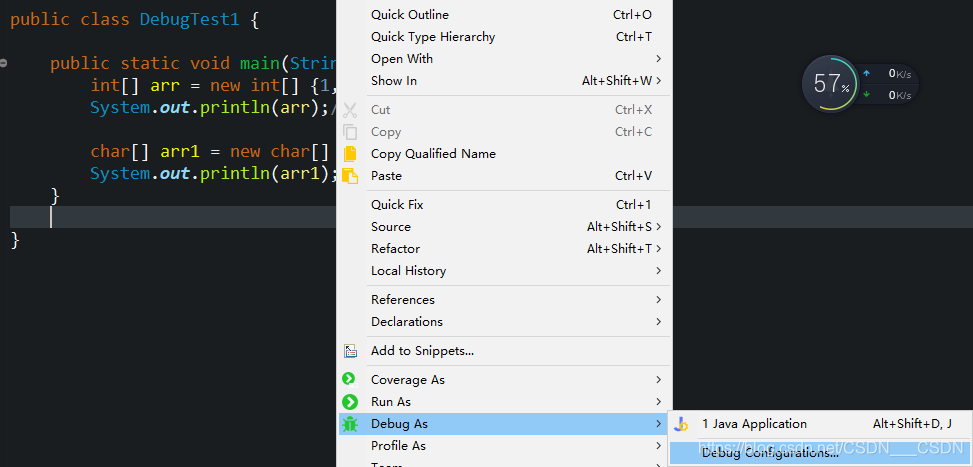
eclipse Debug中step into功能失灵的问题
step into 和 step over功能一样,无法进入方法内部,解决方法如下: 需要使用jdk中的jre,而不是独立安装的jre 再次Debug,当运行到断点的时候,点击step into(F5)就可以看见println函数…
Linux 基金会宣布红队项目,致力于孵化开源安全工具
百度智能云 云生态狂欢季 热门云产品1折起>>> 谁都想软件有着很高的安全性吧。毕竟,每一天都会有不一样的安全漏洞,从糟糕软件的沼泽中冒出来。 在近期举办的开源领导力峰会上,Linux 基金会宣布了新的红队项目(Red Tea…
基础数据结构【四】————环形链表与多项式
主要演示环形列表节点的创建插入, 删除,遍历,环形链表连接 。双向链表节点的建立与插入 ,双向链表中节点的删除 以及环形链表在多项式中的应用 DEMO1:环形链表节点的创建与插入 /* [名称]:ch03_08.cpp [示范]:环形链表节点的创…
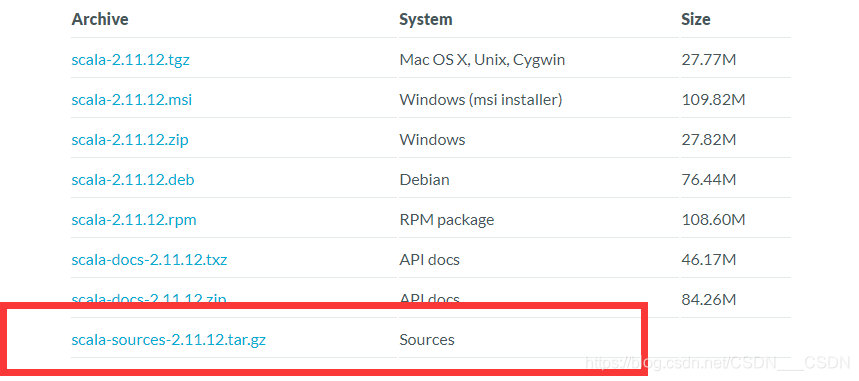
关联scala源码
首先需要去官网下载sources 将下载好的压缩包拷贝到scala安装的lib目录下,解压 ctrlb以后 查看源码, 选择要查看的方法或者类, 输入 ctrl b import scala.io.StdIn 如果想看StdIn的源码,则将光标放在StdIn处,ctrlb 如果想查看io包下的内容&…
MySQL安装使用的2个问题
问题:1.遇到不输入密码能登上 ,使用密码报错.2.(解压版的) 在cmd输入>mysql –u root –p 时,按enter回车时,会叫你输入密码Enter password____,否则出现错误:ERROR 1045(28000):Access denied for user’root’’localhost’(using passw…
Flink1.7.2 sql 批处理示例
Flink1.7.2 sql 批处理示例 源码 https://github.com/opensourceteams/flink-maven-scala概述 本文为Flink sql Dataset 示例主要操作包括:Scan / Select,as (table),as (column),limit,Where / Filter,between and (where),Sum,min,max,avg,(group by ),group by having,disti…
ISP 【一】————boost标准库使用——批量读取保存文件 /boost第三方库的使用及其cmake添加,图像gramma
CMakeLists.txt文件中需要添加第三方库,并企鹅在CMakeLists.txt中添加 include_directories(${PROJECT_SOURCE_DIR}/../3party/gflags-2.2.2/include) link_directories(${PROJECT_SOURCE_DIR}/../3party/boost-1.73.0/lib-import) target_link_libraries( gram…
简单ajax类, 比较小, 只用ajax功能时, 可以考虑它
忘了哪儿转来的了, 不时的能够用上, 留存一下<script language"javascript" type"text/javascript"> /***var ajaxAjax();/*get使用方式* /ajax.get("php_server.php?id1&namexxx", function(data){ alert(data); //d…
Hadoop 三大发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。 Apache版本最原始(最基础)的版本,对于入门学习最好。 Cloudera在大型互联网企业中用的较多。 Hortonworks文档较好。 1. Apache Hadoop 官网地址:http://had…
MongoDB主动撤回SSPL的开源许可申请
2018年10月,MongoDB将其开源协议更换为SSPL,虽然在当时引起了很大的争议,但是MongoDB始终坚信SSPL符合符合开源计划的批准标准,并向Open Source Initiative (以下简称OSI)提交了申请。不过,近日…
MATLAB【八】———— matlab 读取单个(多个)文件夹中所有图像
0.matlab 移动(复制)文件到另一个文件夹 sourcePath .\Square_train; targetPath .\Square_test; fileList dir(sourcePath); for k 3 :5: length(fileList) movefile([sourcePath,\,fileList(k).name],targetPath); end %copyfile([sourcePat…
JAVA IO学习
2019独角兽企业重金招聘Python工程师标准>>> 很多初学者接触IO时,总是感觉东西太多,杂乱的分不清楚。其实里面用到了装饰器模式封装,把里面的接口梳理一下之后,就会觉得其实蛮清晰的 相关的接口和类 接口或类描述Input…