MySQL索引背后的数据结构及算法原理【转】
http://blog.codinglabs.org/articles/theory-of-mysql-index.html
MySQL索引背后的数据结构及算法原理【转】
摘要
本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题。特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等。为了避免混乱,本文将只关注于BTree索引,因为这是平常使用MySQL时主要打交道的索引,至于哈希索引和全文索引本文暂不讨论。
文章主要内容分为三个部分。
第一部分主要从数据结构及算法理论层面讨论MySQL数据库索引的数理基础。
第二部分结合MySQL数据库中MyISAM和InnoDB数据存储引擎中索引的架构实现讨论聚集索引、非聚集索引及覆盖索引等话题。
第三部分根据上面的理论基础,讨论MySQL中高性能使用索引的策略。
数据结构及算法基础
索引的本质
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。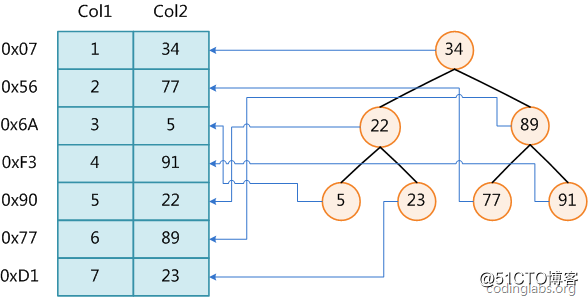
图1
图1展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含本身的索引键值和一个可以直接定位到数据的行号(指针)信息,这样就可以运用二叉查找在O(log2n)
虽然这是一个货真价实的索引,但是实际的数据库系统几乎没有使用二叉查找树或其进化品种红黑树(red-black tree)实现的,原因会在下文介绍。
B-Tree和B+Tree
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构,在本文的下一节会结合存储器原理及计算机存取原理讨论为什么B-Tree和B+Tree在被如此广泛用于索引,这一节先单纯从数据结构角度描述它们。
B-Tree
为了描述B-Tree,首先定义一条数据记录为一个二元组[key, data],key为记录的键值,对于不同数据记录,key是互不相同的;data为数据记录除key外的数据。那么B-Tree是满足下列条件的数据结构:
d为大于1的一个正整数,称为B-Tree的度。
h为一个正整数,称为B-Tree的高度。
每个非叶子节点由n-1个key和n个指针组成,其中d<=n<=2d。
每个叶子节点最少包含一个key和两个指针,最多包含2d-1个key和2d个指针,叶节点的指针均为null 。
所有叶节点具有相同的深度,等于树高h。
key和指针互相间隔,节点两端是指针。
一个节点中的key从左到右非递减排列。
所有节点组成树结构。
每个指针要么为null,要么指向另外一个节点。
如果某个指针在节点node最左边且不为null,则其指向节点的所有key小于v(key1)
如果某个指针在节点node最右边且不为null,则其指向节点的所有key大于v(keym)
如果某个指针在节点node的左右相邻key分别是keyi
图2是一个d=2的B-Tree示意图 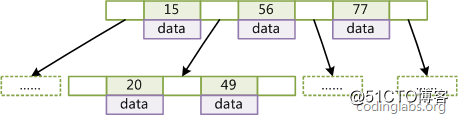
图2
由于B-Tree的特性,在B-Tree中按key检索数据的算法非常直观:首先从根节点进行二分查找,如果找到则返回对应节点的data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或找到null指针,前者查找成功,后者查找失败。B-Tree上查找算法的伪代码如下:
复制代码
BTree_Search(node, key) {
if(node == null) return null;
foreach(node.key)
{
if(node.key[i] == key) return node.data[i];
if(node.key[i] > key) return BTree_Search(point[i]->node);
}
return BTree_Search(point[i+1]->node);
}
data = BTree_Search(root, my_key);
复制代码
关于B-Tree有一系列有趣的性质,例如一个度为d的B-Tree,设其索引N个key,则其树高h的上限为logd((N+1)/2)logd((N+1)/2),检索一个key,其查找节点个数的渐进复杂度为O(logdN)O(logdN)。从这点可以看出,B-Tree是一个非常有效率的索引数据结构。
另外,由于插入删除新的数据记录会破坏B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质,本文不打算完整讨论B-Tree这些内容,因为已经有许多资料详细说明了B-Tree的数学性质及插入删除算法。
B+Tree
B-Tree有许多变种,其中最常见的是B+Tree,例如MySQL就普遍使用B+Tree实现其索引结构。
与B-Tree相比,B+Tree有以下不同点:
每个节点的指针上限为2d而不是2d+1。
内节点不存储data,只存储key;叶子节点不存储指针。
图3是一个简单的B+Tree示意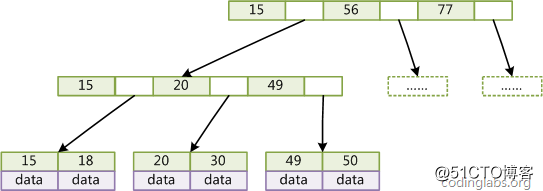
图3
由于并不是所有节点都具有相同的域,因此B+Tree中叶节点和内节点一般大小不同。这点与B-Tree不同,虽然B-Tree中不同节点存放的key和指针可能数量不一致,但是每个节点的域和上限是一致的,所以在实现中B-Tree往往对每个节点申请同等大小的空间。
一般来说,B+Tree比B-Tree更适合实现外存储索引结构,具体原因与外存储器原理及计算机存取原理有关,将在下面讨论。
带有顺序访问指针的B+Tree
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。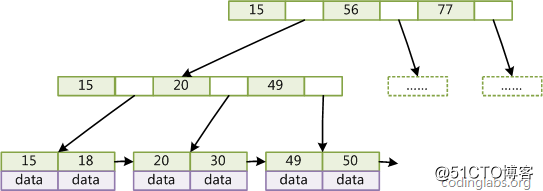
图4
如图4所示,在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
这一节对B-Tree和B+Tree进行了一个简单的介绍,下一节结合存储器存取原理介绍为什么目前B+Tree是数据库系统实现索引的首选数据结构。
为什么使用B-Tree(B+Tree)
上文说过,红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构,这一节将结合计算机组成原理相关知识讨论B-/+Tree作为索引的理论基础。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。下面先介绍内存和磁盘存取原理,然后再结合这些原理分析B-/+Tree作为索引的效率。
主存存取原理
目前计算机使用的主存基本都是随机读写存储器(RAM),现代RAM的结构和存取原理比较复杂,这里本文抛却具体差别,抽象出一个十分简单的存取模型来说明RAM的工作原理。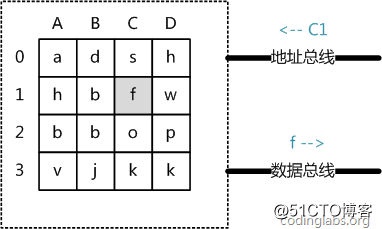
图5
从抽象角度看,主存是一系列的存储单元组成的矩阵,每个存储单元存储固定大小的数据。每个存储单元有唯一的地址,现代主存的编址规则比较复杂,这里将其简化成一个二维地址:通过一个行地址和一个列地址可以唯一定位到一个存储单元。图5展示了一个4 x 4的主存模型。
内存的存取过程如下:
当需要从内存读取数据时,系统将地址信号放到地址总线上传给内存,内存读到地址信号后,解析信号并定位到指定存储单元,然后将此存储单元数据放到数据总线上,返回供其它部件读取。
写内存的过程类似,系统将要写入单元地址和数据分别放在地址总线和数据总线上,主存读取两个总线的内容,做相应的写操作。
这里可以看出,内存存取的时间仅与存取次数呈线性关系,因为不存在机械操作,两次存取的数据的“距离”不会对时间有任何影响,例如,先取A0再取A1和先取A0再取D3的时间消耗是一样的。
磁盘存取原理
上文说过,索引一般以文件形式存储在磁盘上,索引检索需要磁盘I/O操作。与内存不同,磁盘I/O存在机械运动耗费,因此磁盘I/O的时间消耗是巨大的。
图6是磁盘的整体结构示意图。
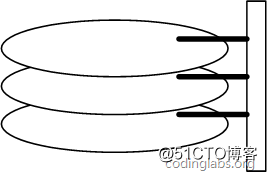
图6
一个磁盘由大小相同且同轴的圆形盘片组成,磁盘可以转动(各个磁盘必须同步转动)。在磁盘的一侧有磁头支架,磁头支架固定了一组磁头,每个磁头负责存取一个盘片的内容。磁头不能转动,但是可以沿磁盘半径方向运动(实际是斜切向运动),每个磁头同一时刻也必须是同轴的,即从正上方向下看,所有磁头任何时候都是重叠的(不过目前已经有多磁头独立技术,可不受此限制)。
图7是磁盘结构的示意图 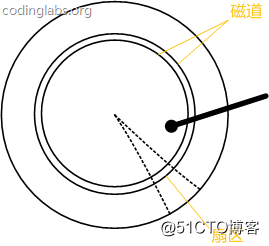
图7
盘片被划分成一系列同心环,圆心是盘片中心,每个同心环叫做一个磁道,所有半径相同的磁道组成一个柱面。磁道被沿半径线划分成一个个小的段,每个段叫做一个扇区,每个扇区是磁盘的最小存储单元。为了简单起见,我们下面假设磁盘只有一个盘片和一个磁头。
当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,然后磁头需要移动对应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。
局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比内存慢很多,再加上机械运动耗费,磁盘的存取速度往往是内存的几百分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。
程序运行期间所需要的数据通常比较集中,由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将内存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),内存和磁盘以页为单位交换数据。当程序要读取的数据不在内存中时,会触发一个缺页异常,向磁盘进行读取,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
B-/+Tree索引的性能分析
到这里终于可以分析B-/+Tree索引的性能了。
上文说过一般使用磁盘I/O次数评价索引结构的优劣。先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)
综上所述,用B-Tree作为索引结构效率是非常高的。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
上文还说过,B+Tree更适合外存索引,原因和内节点出度d有关。从上面分析可以看到,d越大索引的性能越好,而出度的上限取决于节点内key和data的大小:
dmax=floor(pagesize/(keysize+datasize+pointsize))
floor表示向下取整。由于B+Tree内节点去掉了data域,因此可以拥有更大的出度,拥有更好的性能。
这一章从理论角度讨论了与索引相关的数据结构与算法问题,下一章将讨论B+Tree是如何具体实现为MySQL中索引,同时将结合MyISAM和InnDB存储引擎介绍非聚集索引和聚集索引两种不同的索引实现形式。
MySQL索引实现
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。
MyISAM索引实现
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM索引的原理图: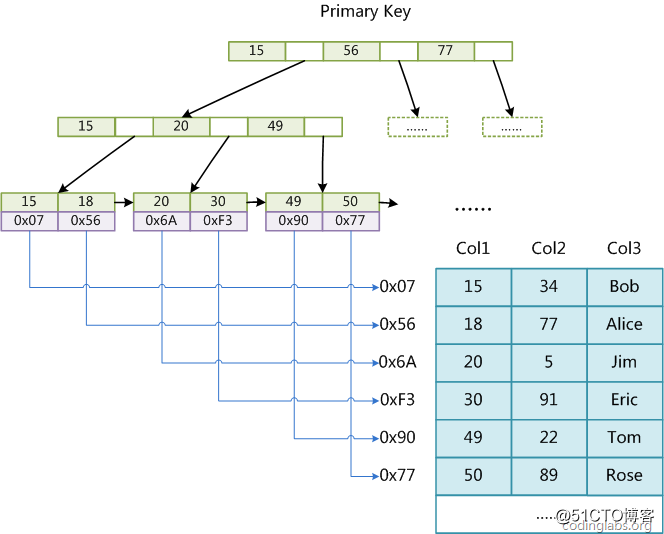
图8
这里设表一共有三列,假设我们以Col1为主键,则图8是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示: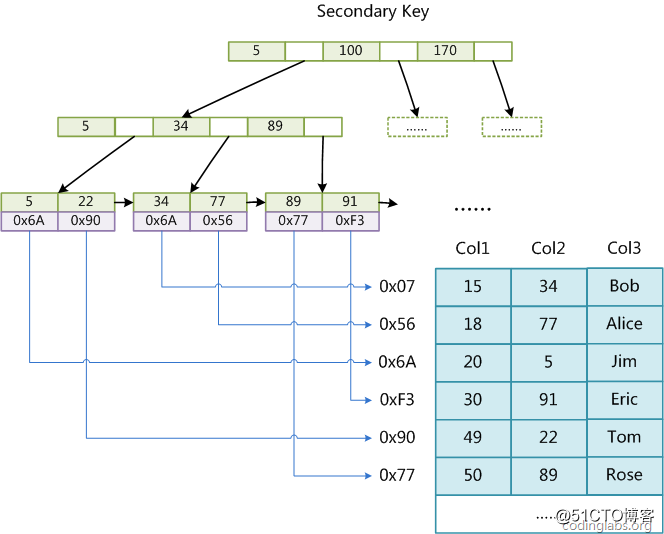
图9
同样也是一颗B+Tree,data域保存数据记录的地址。
因此,MyISAM中索引的算法为:首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。总之,MyISAM的索引除了包含本身的键值信息,还包含了可以直接定位到数据的行号(行指针)。即通过索引可以直接通过行号(指针)找到数据。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
InnoDB索引实现
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。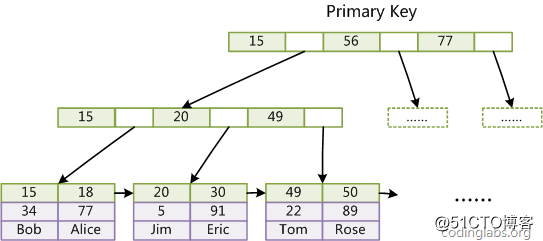
图10
图10是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录,这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长×××。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,图11为定义在Col3上的一个辅助索引: 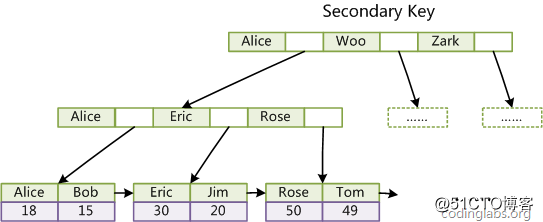
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引(2次IO):首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂产生碎片,十分低效,而使用自增字段作为主键则是一个很好的选择。
更多的信息可以继续阅读:张洋的MySQL索引背后的数据结构及算法原理
转载于:https://blog.51cto.com/9447803/2409066
相关文章:

各种播放器代码
各种播放器代码1.avi格式代码片断如下:<object id"video"width"400"height"200"border"0"classid"clsid:CFCDAA03-8BE4-11cf-B84B-0020AFBBCCFA"><param name"ShowDisplay"value"0"…

算法基础知识科普:8大搜索算法之二叉搜索树(下)
由于微信发代码以及数学符号很吃力,所以我们做知识科普只能利用图片来做,本算法代码较多,所以分为三个部分来介绍。本篇把剩余的部分补齐。当然二叉搜索树也有自己的缺陷,即构造的二叉树跟数据的初始状态以及删除的方法有很大的关…

SpringMvc4中获取request、response对象的方法
springMVC4中获取request和response对象有以下两种简单易用的方法: 1、在control层获取 在control层中获取HttpServletRequest和HttpServletResponse对象有以下两种简单方式: 1)通过方法参数直接在action类中获取 Controller class Action{ R…

JAVA增删改查XML文件
2019独角兽企业重金招聘Python工程师标准>>> 最近总是需要进行xml的相关操作。 不免的要进行xml的读取修改等,于是上网搜索,加上自己的小改动,整合了下xml的常用操作。 读取XML配置文件 首先我们需要通过DocumentBuilderFactory获…
测试一下,你能小学毕业吗?
昨天在群里大家讨论了上面那道小学六年级的五星题,不知道有没有同学能够不用三角函数,不用积分做出来的?先别往后看,测试一下吧!看看是不是要跟小编一起重新背起小书包返回小学,重新学习了。 现在小学生的…
This is A PostXing Test
Test 一下下 试看看~~~ ABC试一下代码...1 public class PostApplicationExitActivationProcess2 {3 /// <summary>4 /// The main entry point for the application.5 /// </summary>6 [STAThread]7 static void Main( string[] args) 8 {9 if (…
缓存穿透、并发和失效的解决方案
我们在用缓存的时候,不管是Redis或者Memcached,基本上会通用遇到以下三个问题: 缓存穿透 缓存并发 缓存失效 缓存穿透 注:上面三个图会有什么问题呢? 我们在项目中使用缓存通常都是先检查缓存中是否存在,…
CentOS 7 命令
Centos 7 目录说明 / / 是根目录。 /bin 软连接到 /usr/bin。可以理解/bin 是 /usr/bin 的快捷方式。 /lib 软连接到 /usr/lib。 /lib64 软连接到 /usr/lib64。 /sbin 软连接到 /usr/sbin。 /usr软件安装位置 /usr/bin 为系统命令所在目录。 /usr/local 为安装程序所在目录。 /…

算法基础知识科普:8大搜索算法之AVL树(上)
前段时间介绍了二叉搜索树(BST),我们知道这种搜索结构存在的弊端是对输入序列存在强依赖,若输入序列基本有序,则BST近似退化为链表。这样就会大大降低搜索的效率。AVL树以及Red-Black树就是为了解决这个问题࿰…

GARFIELD@04-09-2005
a technical facto 转载于:https://www.cnblogs.com/rexhost/archive/2005/04/09/134701.html
Vue.js学习系列(四十二)-- Vue.js组件
2019独角兽企业重金招聘Python工程师标准>>> 组件(Component)是Vue.js最强大的功能之一。组件可以扩展HTML元素,封装可重用的代码。组件系统让我们可以用独立可复用的小组件来构建大型应用,几乎任 意类型的应用的界面都…
java sqlite使用小记
2019独角兽企业重金招聘Python工程师标准>>> Sqlite教程: http://www.runoob.com/sqlite/sqlite-tutorial.html 加载sqlite jdbc驱动: static{ try { Class.forName("org.sqlite.JDBC"); } catch (ClassNotFoundException e) { e.p…

算法基础知识科普:8大搜索算法之AVL树(中)
昨天我们介绍了平衡二叉树的基本概念,通过平衡因子来控制左右子树的深度,使得整个二叉搜索树始终保持平衡状态。这个算法的核心在于当平衡因子超过范围,如何通过旋转的方式来使二叉搜索树保持平衡,以及平衡后对应结点平衡因子如何…
Linux登录那点事
跨平台系列汇总:http://www.cnblogs.com/dunitian/p/4822808.html#linux 我们登录linux的时候基本上不太关注上面的这个提示,其实这个还是有点文章的 简单解释一下: 上一次dnt用户登录的时间,以及终端是tty1 知识普及:…
解决了一个遗留的Portlet奇怪问题
在做Portlet的时候碰到一个奇怪的问题,使用Java应用程序来进行RFT传输好好的,但在Pluto下,同样的一段程序却不行,提示:No client transport named https found! 搜索GT官网的maillist,发现有人提到是AXI…

Python 程序如何高效地调试?
Python在debug方面的支持还是不错的,在明确代码意义的情况下,通过log、print和assert分析错误原因,配合单元测试可以很高效。然而,实际工作中大量代码很可能出自他人之手,这种情况下,使用debugger就显得更加…

selenium中javascript调试
之前写了使用js输入长文件的文章,有同事在使用时,发现竟然无法输入,也不知道是什么原因,且用的还是id方式。 在参考网文后,才发现是js写的有问题,现总结一下 javascript调试,在firefox中就自带有…

算法基础知识科普:8大搜索算法之AVL树(下)
昨天我们介绍了在进行结点插入时,若左子树深度超过右子树深度两层则进行右旋来保持平衡。今天继续介绍,若右子树深度超过左子树深度两层时的左旋操作,以及删除结点后平衡因子的变更问题。 这些都掌握后,基本上对AVL就有一个很全面…
《代码敲不队》第八次团队作业:Alpha冲刺 第二天
项目内容这个作业属于哪个课程任课教师博客主页链接这个作业的要求在哪里作业链接地址团队名称代码敲不队作业学习目标掌握软件编码实现的工程要求。团队项目github仓库地址链接 GitHub 第二天 日期:2019/6/16 今日完成任务情况以及遇到的问题 针对设计好的数据库&a…

我的.net程序为何不能执行?
今天早上习惯性的打开公司内部的网站。不料却发现我在输入地址后,系统竟会弹出一个对话框要求输入用户名和密码。想了想后,输入了AD的密码,就可以进入了网站。不经意间我又发现所有的asp.net的页面都不能打开,而asp的页面却一点问…
利用MySQL触发器实现check和assertion
MySQL虽然输入check语句不会报错,但是实际上并没有check的功能。但是MySQL 依然可以利用触发器来实现相应功能。 本文将根据两个例子简要阐述MySQL实现check和assertion的思路。 MySQL触发器 官方文档 MySQL Signal 官方文档 注意 signal异常处理功能在MySQL5.5版本…

算法基础知识科普:8大搜索算法之红黑树(上)
平衡二叉树(AVL)是一种特殊的二叉搜索树(BST),即每个结点的值都大于其左子树且小于其右子树的值(若存在),并通过引入平衡因子的概念来保持树的平衡。平衡二叉树算法的重点是在插入、…
Java Web学习总结(17)——JSP属性范围
2019独角兽企业重金招聘Python工程师标准>>> 所谓的属性范围就是一个属性设置之后,可以经过多少个其他页面后仍然可以访问的保存范围。 一、JSP属性范围 JSP中提供了四种属性范围,四种属性范围分别指以下四种: 当前页:…
为什么不提供离线Blog管理工具呢?
网络Blog现在是到处开花, 好像全世界的网民都开始写Blog了. 但因为Web的HTTP无状态协议, 网站本身都自己设置有session过期时间. 如果写的Blog文字多,时间一长用户登录状态就没了,当你提交你的文字时系统会出错,结果你回来时,你辛辛苦苦写的长长的文字都没了, 你是不是很气愤?…
javascript a 标签打开相对路径,绝对路径
<a>标签中的href中,如果你写一个路径默认是以相对路径打开的,加上"http://" 消息头那就可以打开绝对路径 html: <a hrefjavascript:void(0); target_blank onclickCommon.openUrl(" rowObject.baiduPanUrl ")…

算法基础知识科普:8大搜索算法之红黑树(中)
红黑树也是一种特殊形式的二叉搜索树,通过结点的颜色以及三条规则来保证二叉搜索树的平衡。规则1:根结点的颜色是黑色,规则2:叶子结点到根结点路径上遇到的黑色结点数目相同,规则3:叶子结点到根结点路径上无…
Java基础学习总结(3)——抽象类
2019独角兽企业重金招聘Python工程师标准>>> 一、抽象类介绍 下面通过一下的小程序深入理解抽象类 因此在类Animal里面只需要定义这个enjoy()方法就可以了,使用abstract关键字把enjoy()方法定义成一个抽象方法,定义如下:public ab…
Knuth(佩服的一塌糊涂)
Donald Knuth自传的开头这样写道:“Donald Knuth真的只是一个人么?”(我觉得不是,^_^)作为世界顶级计算机科学家之一,Knuth教授已经完成了编译程序、属性文法和运算法则的前沿研究,并编著完成了已在程序设计领域中具有…

编程基础知识科普:C#中的问号运算符
C#是一门非常性感的语言,时不时冒出一些语法糖来满足大家的需求,问号运算符就是其中的一种。我们知道基础数据类型的默认值都是基础数据类型的,如int为0,double为0.0,bool为false等等,而引用类型的默认值为…
Listener监听器之HttpSessionListener
编写一个OnlineUserListener。 package anni; import java.util.List; import javax.servlet.ServletContext; import javax.servlet.http.HttpSession; import javax.servlet.http.HttpSessionListener; import javax.servlet.http.HttpSessionEvent;public class OnlineUserL…