2019独角兽企业重金招聘Python工程师标准>>> 
最近总是需要进行xml的相关操作。
不免的要进行xml的读取修改等,于是上网搜索,加上自己的小改动,整合了下xml的常用操作。
读取XML配置文件
首先我们需要通过DocumentBuilderFactory获取xml文件的工厂实例。
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();dbf.setIgnoringElementContentWhitespace(true);创建文档对象
1 DocumentBuilder db = dbf.newDocumentBuilder();
2 Document doc = db.parse(xmlPath); // 使用dom解析xml文件最后遍历列表,进行数据提取
1 NodeList sonlist = doc.getElementsByTagName("son");
2 for (int i = 0; i < sonlist.getLength(); i++) // 循环处理对象
3 {
4 Element son = (Element)sonlist.item(i);;
5
6 for (Node node = son.getFirstChild(); node != null; node = node.getNextSibling()){
7 if (node.getNodeType() == Node.ELEMENT_NODE){
8 String name = node.getNodeName();
9 String value = node.getFirstChild().getNodeValue();
10 System.out.println(name+" : "+value);
11 }
12 }
13 }全部代码


1 public static void getFamilyMemebers(){
2 DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
3 dbf.setIgnoringElementContentWhitespace(true);
4 try {
5 DocumentBuilder db = dbf.newDocumentBuilder();
6 Document doc = db.parse(xmlPath); // 使用dom解析xml文件
7
8 NodeList sonlist = doc.getElementsByTagName("son");
9 for (int i = 0; i < sonlist.getLength(); i++) // 循环处理对象
10 {
11 Element son = (Element)sonlist.item(i);;
12
13 for (Node node = son.getFirstChild(); node != null; node = node.getNextSibling()){
14 if (node.getNodeType() == Node.ELEMENT_NODE){
15 String name = node.getNodeName();
16 String value = node.getFirstChild().getNodeValue();
17 System.out.println(name+" : "+value);
18 }
19 }
20 }
21 } catch (Exception e) {
22 e.printStackTrace();
23 }
24 }在XML文件中增加节点
差不多同样的步骤,先获取根节点,创建一个新的节点,向其中添加元素信息,最后把这个新节点添加到根节点中
1 Element root = xmldoc.getDocumentElement();
2
3 //删除指定节点
4
5 Element son =xmldoc.createElement("son");
6 son.setAttribute("id", "004");
7
8 Element name = xmldoc.createElement("name");
9 name.setTextContent("小儿子");
10 son.appendChild(name);
11
12 Element age = xmldoc.createElement("name");
13 age.setTextContent("0");
14 son.appendChild(age);
15
16 root.appendChild(son);最后不要忘记保存新增的文件,对源文件进行覆盖。
1 TransformerFactory factory = TransformerFactory.newInstance();
2 Transformer former = factory.newTransformer();
3 former.transform(new DOMSource(xmldoc), new StreamResult(new File(xmlPath)));全部代码:
1 public static void createSon() {
2 DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
3 dbf.setIgnoringElementContentWhitespace(false);
4
5 try{
6
7 DocumentBuilder db=dbf.newDocumentBuilder();
8 Document xmldoc=db.parse(xmlPath);
9
10 Element root = xmldoc.getDocumentElement();
11
12 //删除指定节点
13
14 Element son =xmldoc.createElement("son");
15 son.setAttribute("id", "004");
16
17 Element name = xmldoc.createElement("name");
18 name.setTextContent("小儿子");
19 son.appendChild(name);
20
21 Element age = xmldoc.createElement("name");
22 age.setTextContent("0");
23 son.appendChild(age);
24
25 root.appendChild(son);
26 //保存
27 TransformerFactory factory = TransformerFactory.newInstance();
28 Transformer former = factory.newTransformer();
29 former.transform(new DOMSource(xmldoc), new StreamResult(new File(xmlPath)));
30
31 }catch(Exception e){
32 e.printStackTrace();
33 }
34 }在XML中修改节点信息
通过XPath来获取目标节点
1 public static Node selectSingleNode(String express, Element source) {
2 Node result=null;
3 XPathFactory xpathFactory=XPathFactory.newInstance();
4 XPath xpath=xpathFactory.newXPath();
5 try {
6 result=(Node) xpath.evaluate(express, source, XPathConstants.NODE);
7 } catch (XPathExpressionException e) {
8 e.printStackTrace();
9 }
10
11 return result;
12 }获取目标节点,进行修改,完成后,保存文件。
1 Element root = xmldoc.getDocumentElement();
2
3 Element per =(Element) selectSingleNode("/father/son[@id='001']", root);
4 per.getElementsByTagName("age").item(0).setTextContent("27");
5
6 TransformerFactory factory = TransformerFactory.newInstance();
7 Transformer former = factory.newTransformer();
8 former.transform(new DOMSource(xmldoc), new StreamResult(new File(xmlPath)));全部代码:
1 public static void modifySon(){
2 DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
3 dbf.setIgnoringElementContentWhitespace(true);
4 try{
5
6 DocumentBuilder db=dbf.newDocumentBuilder();
7 Document xmldoc=db.parse(xmlPath);
8
9 Element root = xmldoc.getDocumentElement();
10
11 Element per =(Element) selectSingleNode("/father/son[@id='001']", root);
12 per.getElementsByTagName("age").item(0).setTextContent("27");
13
14 TransformerFactory factory = TransformerFactory.newInstance();
15 Transformer former = factory.newTransformer();
16 former.transform(new DOMSource(xmldoc), new StreamResult(new File(xmlPath)));
17 }catch(Exception e){
18 e.printStackTrace();
19 }
20 }删除XML中的节点
通过XPath获取目标节点, 进行删除,最后保存
1 Element root = xmldoc.getDocumentElement();
2
3 Element son =(Element) selectSingleNode("/father/son[@id='002']", root);
4 root.removeChild(son);
5
6 TransformerFactory factory = TransformerFactory.newInstance();
7 Transformer former = factory.newTransformer();
8 former.transform(new DOMSource(xmldoc), new StreamResult(new File(xmlPath)));全部代码:
1 public static void discardSon(){
2
3 DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
4 dbf.setIgnoringElementContentWhitespace(true);
5
6 try{
7
8 DocumentBuilder db=dbf.newDocumentBuilder();
9 Document xmldoc=db.parse(xmlPath);
10
11 Element root = xmldoc.getDocumentElement();
12
13 Element son =(Element) selectSingleNode("/father/son[@id='002']", root);
14 root.removeChild(son);
15
16 TransformerFactory factory = TransformerFactory.newInstance();
17 Transformer former = factory.newTransformer();
18 former.transform(new DOMSource(xmldoc), new StreamResult(new File(xmlPath)));
19
20 }catch(Exception e){
21 e.printStackTrace();
22 }
23 }综上,基本XML的操作就如此了。下面是整合所有的代码,可以直接运行的,前提是在src下自己配好Xml文件。
XML
1 <?xml version="1.0" encoding="UTF-8" standalone="no"?><father>
2 <son id="001">
3 <name>老大</name>
4 <age>27</age>
5 </son>
6 <son id="002">
7 <name>老二</name>
8 <age>13</age>
9 </son>
10 <son id="003">
11 <name>老三</name>
12 <age>13</age>
13 </son>
14 </father>xmlManage.java
1 package xmlManger;
2
3 import java.io.File;
4
5 import javax.xml.parsers.DocumentBuilder;
6 import javax.xml.parsers.DocumentBuilderFactory;
7 import javax.xml.transform.Transformer;
8 import javax.xml.transform.TransformerFactory;
9 import javax.xml.transform.dom.DOMSource;
10 import javax.xml.transform.stream.StreamResult;
11 import javax.xml.xpath.XPath;
12 import javax.xml.xpath.XPathConstants;
13 import javax.xml.xpath.XPathExpressionException;
14 import javax.xml.xpath.XPathFactory;
15
16 import org.w3c.dom.Document;
17 import org.w3c.dom.Element;
18 import org.w3c.dom.Node;
19 import org.w3c.dom.NodeList;
20
21
22
23 public class xmlManage {
24
25 private static String xmlPath = "E:\\Eclipse(Plugin)\\workspace\\xmlManger\\src\\family.xml";
26
27
28 public static void getFamilyMemebers(){
29 DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
30 dbf.setIgnoringElementContentWhitespace(true);
31 try {
32 DocumentBuilder db = dbf.newDocumentBuilder();
33 Document doc = db.parse(xmlPath); // 使用dom解析xml文件
34
35 NodeList sonlist = doc.getElementsByTagName("son");
36 for (int i = 0; i < sonlist.getLength(); i++) // 循环处理对象
37 {
38 Element son = (Element)sonlist.item(i);;
39
40 for (Node node = son.getFirstChild(); node != null; node = node.getNextSibling()){
41 if (node.getNodeType() == Node.ELEMENT_NODE){
42 String name = node.getNodeName();
43 String value = node.getFirstChild().getNodeValue();
44 System.out.println(name+" : "+value);
45 }
46 }
47 }
48 } catch (Exception e) {
49 e.printStackTrace();
50 }
51 }
52
53 public static void modifySon(){
54 DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
55 dbf.setIgnoringElementContentWhitespace(true);
56 try{
57
58 DocumentBuilder db=dbf.newDocumentBuilder();
59 Document xmldoc=db.parse(xmlPath);
60
61 Element root = xmldoc.getDocumentElement();
62
63 Element per =(Element) selectSingleNode("/father/son[@id='001']", root);
64 per.getElementsByTagName("age").item(0).setTextContent("27");
65
66 TransformerFactory factory = TransformerFactory.newInstance();
67 Transformer former = factory.newTransformer();
68 former.transform(new DOMSource(xmldoc), new StreamResult(new File(xmlPath)));
69 }catch(Exception e){
70 e.printStackTrace();
71 }
72 }
73
74 public static void discardSon(){
75
76 DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
77 dbf.setIgnoringElementContentWhitespace(true);
78
79 try{
80
81 DocumentBuilder db=dbf.newDocumentBuilder();
82 Document xmldoc=db.parse(xmlPath);
83
84 Element root = xmldoc.getDocumentElement();
85
86 Element son =(Element) selectSingleNode("/father/son[@id='002']", root);
87 root.removeChild(son);
88
89 TransformerFactory factory = TransformerFactory.newInstance();
90 Transformer former = factory.newTransformer();
91 former.transform(new DOMSource(xmldoc), new StreamResult(new File(xmlPath)));
92
93 }catch(Exception e){
94 e.printStackTrace();
95 }
96 }
97
98 public static void createSon() {
99 DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
100 dbf.setIgnoringElementContentWhitespace(false);
101
102 try{
103
104 DocumentBuilder db=dbf.newDocumentBuilder();
105 Document xmldoc=db.parse(xmlPath);
106
107 Element root = xmldoc.getDocumentElement();
108
109 //删除指定节点
110
111 Element son =xmldoc.createElement("son");
112 son.setAttribute("id", "004");
113
114 Element name = xmldoc.createElement("name");
115 name.setTextContent("小儿子");
116 son.appendChild(name);
117
118 Element age = xmldoc.createElement("name");
119 age.setTextContent("0");
120 son.appendChild(age);
121
122 root.appendChild(son);
123 //保存
124 TransformerFactory factory = TransformerFactory.newInstance();
125 Transformer former = factory.newTransformer();
126 former.transform(new DOMSource(xmldoc), new StreamResult(new File(xmlPath)));
127
128 }catch(Exception e){
129 e.printStackTrace();
130 }
131 }
132
133 public static Node selectSingleNode(String express, Element source) {
134 Node result=null;
135 XPathFactory xpathFactory=XPathFactory.newInstance();
136 XPath xpath=xpathFactory.newXPath();
137 try {
138 result=(Node) xpath.evaluate(express, source, XPathConstants.NODE);
139 } catch (XPathExpressionException e) {
140 e.printStackTrace();
141 }
142
143 return result;
144 }
145
146 public static void main(String[] args){
147 getFamilyMemebers();
148 System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
149 modifySon();
150 System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
151 getFamilyMemebers();
152 System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
153 discardSon();
154 System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
155 getFamilyMemebers();
156 System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
157 createSon();
158 System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
159 getFamilyMemebers();
160 }
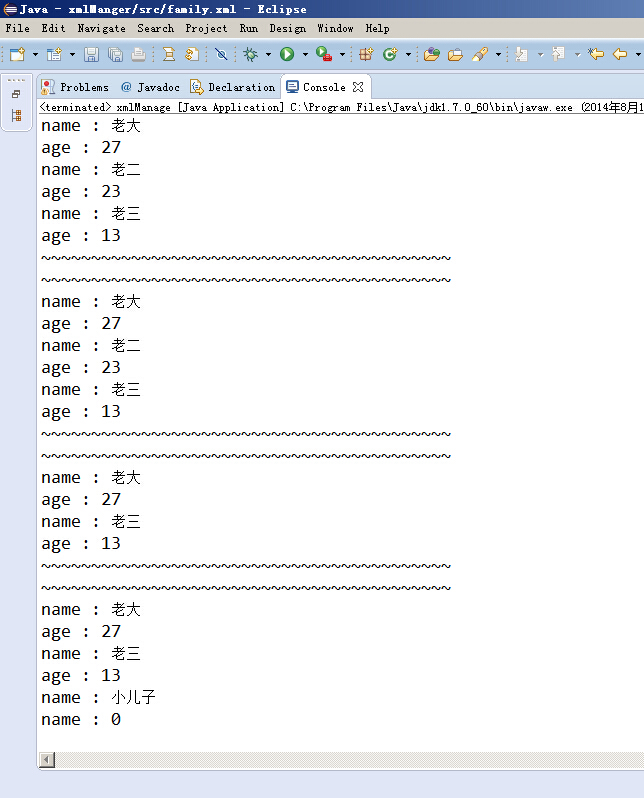
161 }运行结果: