刻意练习:Python基础 -- Task06. 字典与集合
背景
我们准备利用17天时间,将 “Python基础的刻意练习” 分为如下任务:
- Task01:变量、运算符与数据类型(1day)
- Task02:条件与循环(1day)
- Task03:列表与元组(2day)
- Task04:字符串与序列(1day)
- Task05:函数与Lambda表达式(2day)
- Task06:字典与集合(1day)
- Task07:文件与文件系统(2day)
- Task08:异常处理(1day)
- Task09:else 与 with 语句(1day)
- Task10:类与对象(2day)
- Task11:魔法方法(2day)
- Task12:模块(1day)
这是我的第六次打卡内容。我学习 Python 的思路是,先去熟悉 Python 的整体语法框架与自己熟悉的编程语言进行知识点的连接,后面遇到问题再来慢慢补充,慢慢形成自己的知识结构。
Python 基础语法
1. 字典
- 序列是以连续的整数为索引,与此不同的是,字典以"关键字"为索引,关键字可以是任意不可变类型,通常用字符串或数值。
- 字典是 Python 唯一的一个 映射类型,字符串、元组、列表属于序列类型。
那么如何快速判断一个数据类型 X 是不是可变类型的呢?两种方法:
- 麻烦方法:用
id(X)函数,对 X 进行某种操作,比较操作前后的id,如果不一样,则X不可变,如果一样,则X可变。 - 便捷方法:用
hash(X),只要不报错,证明X可被哈希,即不可变,反过来不可被哈希,即可变。
i = 1
print(id(i)) # 140732167000896
i = i + 2
print(id(i)) # 140732167000960l = [1, 2]
print(id(l)) # 4300825160
l.append('Python')
print(id(l)) # 4300825160
- 整数
i在加 1 之后的id和之前不一样,因此加完之后的这个i(虽然名字没变),但是不是加前的那个i了,因此整数是不可更改的。 - 列表
l在附加'Python'之后的id和之前一样,因此列表是可更改的。
print(hash('Name')) # -9215951442099718823print(hash((1, 2, 'Python'))) # 823362308207799471print(hash([1, 2, 'Python']))
# TypeError: unhashable type: 'list'
- 字符和元组 都能被哈希,因此它们是不可更改的。列表不能被哈希,因此它是可更改的。
「字典」定义语法为 {元素1, 元素2, ..., 元素n}
- 其中每一个元素是一个「键值对」- 键:值 (key:value)
- 关键点是「大括号 {}」,「逗号 ,」和「冒号 :」
- 大括号 把所有元素绑在一起
- 逗号 将每个键值对一一分开
- 冒号 将键和值分开
创建和访问字典
- 字典是无序的 键:值对(key:value 对)集合,键必须是互不相同的(在同一个字典之内)。
brand = ['李宁', '耐克', '阿迪达斯']
slogan = ['一切皆有可能', 'Just do it', 'Impossible is nothing']
print('耐克的口号是:', slogan[brand.index('耐克')])
# 耐克的口号是: Just do itdict1 = {'李宁': '一切皆有可能', '耐克': 'Just do it', '阿迪达斯': 'Impossible is nothing'}
print('耐克的口号是:', dict1['耐克'])
# 耐克的口号是: Just do itdict2 = {1: 'one', 2: 'two', 3: 'three'}
print(dict2) # {1: 'one', 2: 'two', 3: 'three'}
print(dict2[1]) # onedict3 = {'rice': 35, 'wheat': 101, 'corn': 67}
print(dict3) # {'wheat': 101, 'corn': 67, 'rice': 35}
print(dict3['rice']) # 35
dict(object)函数用于创建一个字典。dict()-> new empty dictionarydict(mapping)-> new dictionary initialized from a mapping object’s (key, value) pairsdict(iterable)-> new dictionary initialized as if via:
d = {}
for k, v in iterable:d[k] = v
dict(**kwargs)-> new dictionary initialized with the name=value pairs in the keyword argument list. For example: dict(one=1, two=2)
dict4 = dict([('apple', 4139), ('peach', 4127), ('cherry', 4098)])
print(dict4) # {'cherry': 4098, 'apple': 4139, 'peach': 4127}dict4 = dict((('apple', 4139), ('peach', 4127), ('cherry', 4098)))
print(dict4) # {'peach': 4127, 'cherry': 4098, 'apple': 4139}
dict内部存放的顺序和key放入的顺序是没有关系的。dict查找和插入的速度极快,不会随着key的增加而增加,但是需要占用大量的内存。- 把数据放入
dict还可以直接通过key放入。 - 一个
key只能对应一个value,多次对一个key放入value,后面的值会把前面的值冲掉。
dict5 = dict(a=1, b=2, c=3)
print(dict5)
# {'b': 2, 'a': 1, 'c': 3}dict5['a'] = 11
print(dict5)
# {'b': 2, 'a': 11, 'c': 3}dict5['d'] = 4
print(dict5)
# {'d': 4, 'c': 3, 'a': 11, 'b': 2}
字典的内置方法
dict.fromkeys(seq[, value])用于创建一个新字典,以序列seq中元素做字典的键,value为字典所有键对应的初始值。
seq = ('name', 'age', 'sex')
dict6 = dict.fromkeys(seq)
print("新的字典为 : %s" % str(dict6))
# 新的字典为 : {'name': None, 'age': None, 'sex': None}dict6 = dict.fromkeys(seq, 10)
print("新的字典为 : %s" % str(dict6))
# 新的字典为 : {'name': 10, 'age': 10, 'sex': 10}dict6 = dict.fromkeys(seq, ('小马', '8', '男'))
print("新的字典为 : %s" % str(dict6))
# 新的字典为 : {'name': ('小马', '8', '男'), 'age': ('小马', '8', '男'), 'sex': ('小马', '8', '男')}
dict.keys()返回一个可迭代对象,可以使用list()来转换为列表。
dict = {'Name': 'lsgogroup', 'Age': 7}
print(dict.keys()) # dict_keys(['Name', 'Age'])
lst = list(dict.keys()) # 转换为列表
print(lst) # ['Name', 'Age']
dict.values()返回一个迭代器,可以使用 list() 来转换为列表,列表为字典中的所有值。
dict = {'Sex': 'female', 'Age': 7, 'Name': 'Zara'}
print("字典所有值为 : ", list(dict.values()))
# 字典所有值为 : [7, 'female', 'Zara']
dict.items()以列表返回可遍历的(键, 值) 元组数组。
dict = {'Name': 'Lsgogroup', 'Age': 7}
print("Value : %s" % dict.items())
# Value : dict_items([('Name', 'Lsgogroup'), ('Age', 7)])print(tuple(dict.items()))
# (('Name', 'Lsgogroup'), ('Age', 7))
dict.get(key, default=None)返回指定键的值,如果值不在字典中返回默认值。
dict = {'Name': 'Lsgogroup', 'Age': 27}
print("Age 值为 : %s" % dict.get('Age')) # Age 值为 : 27
print("Sex 值为 : %s" % dict.get('Sex', "NA")) # Sex 值为 : NA
key in dictin操作符用于判断键是否存在于字典中,如果键在字典 dict 里返回true,否则返回false。而not in操作符刚好相反,如果键在字典 dict 里返回false,否则返回true。
dict = {'Name': 'Lsgogroup', 'Age': 7}# 检测键 Age 是否存在
if 'Age' in dict:print("键 Age 存在")
else:print("键 Age 不存在")# 检测键 Sex 是否存在
if 'Sex' in dict:print("键 Sex 存在")
else:print("键 Sex 不存在")# not in
# 检测键 Age 是否存在
if 'Age' not in dict:print("键 Age 不存在")
else:print("键 Age 存在")# 键 Age 存在
# 键 Sex 不存在
# 键 Age 存在
dict.clear()用于删除字典内所有元素。
dict = {'Name': 'Zara', 'Age': 7}
print("字典长度 : %d" % len(dict)) # 字典长度 : 2
dict.clear()
print("字典删除后长度 : %d" % len(dict)) # 字典删除后长度 : 0
dict.copy()返回一个字典的浅复制。
Sample1:
dict1 = {'Name': 'Lsgogroup', 'Age': 7, 'Class': 'First'}
dict2 = dict1.copy()
print("新复制的字典为 : ", dict2)
# 新复制的字典为 : {'Age': 7, 'Name': 'Lsgogroup', 'Class': 'First'}
Sample2:直接赋值和 copy 的区别
dict1 = {'user': 'lsgogroup', 'num': [1, 2, 3]}# 引用对象
dict2 = dict1
# 深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用
dict3 = dict1.copy() print(id(dict1)) # 148635574728
print(id(dict2)) # 148635574728
print(id(dict3)) # 148635574344# 修改 data 数据
dict1['user'] = 'root'
dict1['num'].remove(1)# 输出结果
print(dict1) # {'user': 'root', 'num': [2, 3]}
print(dict2) # {'user': 'root', 'num': [2, 3]}
print(dict3) # {'user': 'runoob', 'num': [2, 3]}
dict.pop(key[,default])删除字典给定键key所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。del dict[key]删除字典给定键key所对应的值。
dict1 = {1: "a", 2: [1, 2]}
print(dict1.pop(1), dict1) # a {2: [1, 2]}# 设置默认值,必须添加,否则报错
print(dict1.pop(3, "nokey"), dict1) # nokey {2: [1, 2]}del dict1[2]
print(dict1) # {}
dict.popitem()随机返回并删除字典中的一对键和值,如果字典已经为空,却调用了此方法,就报出KeyError异常。
dict1 = {1: "a", 2: [1, 2]}
print(dict1.popitem()) # (1, 'a')
print(dict1) # {2: [1, 2]}
dict.setdefault(key, default=None)和get()方法 类似, 如果键不存在于字典中,将会添加键并将值设为默认值。
dict = {'Name': 'Lsgogroup', 'Age': 7}
print("Age 键的值为 : %s" % dict.setdefault('Age', None)) # Age 键的值为 : 7
print("Sex 键的值为 : %s" % dict.setdefault('Sex', None)) # Sex 键的值为 : None
print("新字典为:", dict)
# 新字典为: {'Age': 7, 'Name': 'Lsgogroup', 'Sex': None}
dict.update(dict2)把字典参数 dict2 的 key/value(键/值) 对更新到字典 dict 里。
dict = {'Name': 'Lsgogroup', 'Age': 7}
dict2 = {'Sex': 'female', 'Age': 8}
dict.update(dict2)
print("更新字典 dict : ", dict)
# 更新字典 dict : {'Sex': 'female', 'Age': 8, 'Name': 'Lsgogroup'}
2. 集合
- 与
dict类似,set也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
num = {}
print(type(num)) # <class 'dict'>
num = {1, 2, 3, 4}
print(type(num)) # <class 'set'>
集合的创建
- 直接把一堆元素用花括号括起来
{元素1, 元素2, ..., 元素n},重复元素在set中会被自动被过滤。
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # {'banana', 'apple', 'pear', 'orange'}
- 使用
set(value)工厂函数,把列表或元组转换成集合。
a = set('abracadabra')
print(a)
# {'r', 'b', 'd', 'c', 'a'}b = set(("Google", "Lsgogroup", "Taobao", "Taobao"))
print(b)
# {'Taobao', 'Lsgogroup', 'Google'}c = set(["Google", "Lsgogroup", "Taobao", "Google"])
print(c)
# {'Taobao', 'Lsgogroup', 'Google'}
- 去掉列表中重复的元素
lst = [0, 1, 2, 3, 4, 5, 5, 3, 1]temp = []
for item in lst:if item not in temp:temp.append(item)print(temp) # [0, 1, 2, 3, 4, 5]a = set(lst)
print(list(a)) # [0, 1, 2, 3, 4, 5]
从结果发现集合的两个特点:无序 (unordered) 和唯一 (unique)。由于 set 存储的是无序集合,所以我们没法通过索引来访问,但是可以判断一个元素是否在集合中。
访问集合中的值
- 可以使用
for把集合中的数据一个个读取出来。
thisset = set(['Google', 'Baidu', 'Taobao'])
for item in thisset:print(item)# Baidu
# Google
# Taobao
- 可以通过
in或not in判断一个元素是否在集合中已经存在
thisset = set(['Google', 'Baidu', 'Taobao'])
print('Taobao' in thisset) # True
print('Facebook' not in thisset) # True
集合的内置方法
set.add(elmnt)用于给集合添加元素,如果添加的元素在集合中已存在,则不执行任何操作。
fruits = {"apple", "banana", "cherry"}
fruits.add("orange")
print(fruits)
# {'orange', 'cherry', 'banana', 'apple'}fruits.add("apple")
print(fruits)
# {'orange', 'cherry', 'banana', 'apple'}
set.remove(item)用于移除集合中的指定元素。
fruits = {"apple", "banana", "cherry"}
fruits.remove("banana")
print(fruits) # {'apple', 'cherry'}
set.update(set)用于修改当前集合,可以添加新的元素或集合到当前集合中,如果添加的元素在集合中已存在,则该元素只会出现一次,重复的会忽略。
x = {"apple", "banana", "cherry"}
y = {"google", "baidu", "apple"}
x.update(y)
print(x)
# {'cherry', 'banana', 'apple', 'google', 'baidu'}
- 由于 set 是无序和无重复元素的集合,所以两个或多个 set 可以做数学意义上的集合操作。
set.intersection(set1, set2 ...)用于返回两个或更多集合中都包含的元素,即交集。set.union(set1, set2...)返回两个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次。set.difference(set)返回集合的差集,即返回的集合元素包含在第一个集合中,但不包含在第二个集合(方法的参数)中。
a = set('abracadabra')
b = set('alacazam')
print(a) # {'r', 'a', 'c', 'b', 'd'}
print(b) # {'c', 'a', 'l', 'm', 'z'}# 交集
print(a & b) # {'c', 'a'}
c = a.intersection(b)
print(c) # {'a', 'c'}# 并集
print(a | b) # {'l', 'd', 'm', 'b', 'a', 'r', 'z', 'c'}
c = a.union(b)
print(c) # {'c', 'a', 'd', 'm', 'r', 'b', 'z', 'l'}# 差集
print(a - b) # {'d', 'b', 'r'}
c = a.difference(b)
print(c) # {'b', 'd', 'r'}
set.issubset(set)用于判断集合的所有元素是否都包含在指定集合中,如果是则返回 True,否则返回 False。
x = {"a", "b", "c"}
y = {"f", "e", "d", "c", "b", "a"}
z = x.issubset(y)
print(z) # Truex = {"a", "b", "c"}
y = {"f", "e", "d", "c", "b"}
z = x.issubset(y)
print(z) # False
set.issuperset(set)用于判断指定集合的所有元素是否都包含在原始的集合中,如果是则返回 True,否则返回 False。
x = {"f", "e", "d", "c", "b", "a"}
y = {"a", "b", "c"}
z = x.issuperset(y)
print(z) # Truex = {"f", "e", "d", "c", "b"}
y = {"a", "b", "c"}
z = x.issuperset(y)
print(z) # False
3. 不可变集合
frozenset([iterable])返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
a = frozenset(range(10)) # 生成一个新的不可变集合
print(a)
# frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})b = frozenset('lsgogroup')
print(b)
# frozenset({'g', 's', 'p', 'r', 'u', 'o', 'l'})
总结
好了,到此为止有关于 字典 和 集合 部分就介绍完了,大家要根据上面的例子多多体会,只有刻意练习才能掌握一门技术,没有捷径的,加油啊!See You!
参考文献:
- https://www.runoob.com/python3/python3-tutorial.html
- https://www.bilibili.com/video/av4050443
- https://mp.weixin.qq.com/s/DZ589xEbOQ2QLtiq8mP1qQ
相关图文:
- 资料分享:数学建模资料分享 – 图论部分
- 资料分享:数学建模资料分享 – 神经网络部分
- 如何利用 C# 实现 K 最邻近算法?
- 如何利用 C# 实现 K-D Tree 结构?
- 如何利用 C# + KDTree 实现 K 最邻近算法?
- 如何利用 C# 对神经网络模型进行抽象?
- 如何利用 C# 实现神经网络的感知器模型?
- 如何利用 C# 实现 Delta 学习规则?
- 如何利用 C# 实现 误差反向传播 学习规则?
- 如何利用 C# 爬取带 Token 验证的网站数据?
- 如何利用 C# 向 Access 数据库插入大量数据?
- 如何利用 C# + Python 破解猫眼电影的反爬虫机制?
相关文章:

WCF - Session 剖析
WCF中的Session WCF是MS基于SOA建立的一套在分布式环境中各个相对独立系统进行通信的构架,实现了最新的基于WS-*规范。按照SOA的原则,相对独自的业务逻辑以service的形式封装,调用者通过Messaging的方式调用Service。对于承载着某个业务功能的…
mui 微信支付 与springMVC服务器交互
昨天搞定了微信支付,没有想象中的难,主要是官方的demo不全好多东西要自己琢磨,mui端的就不写了支付宝的有了一模一样.上java端的首先是jar包 一个是用来解析xml文件 一个是用来解析json 当然可以替代 然后是工具类当然并不是全都用的到. public class ConfigUtil { /** * 服务…

Python零基础自学会有哪些弊端
Python在人工智能领域的发展前景非常好,很多人都想要学习Python技术,有一些小伙伴会选择通过自学来学习,但是如果是零基础,自学的话一定要注意这些弊端,下面就为大家详细的介绍一下Python零基础自学会有哪些弊端? Pyt…
技术图文:如何利用 Turtle 绘制一棵漂亮的樱花树
背景 最近看到很多机构在推动“青少年编程能力等级标准”的制定以及相关考试的测评,看样子今年年底这个事情就能够确定,明天上半年在一些大中城市就会全面铺开。 《青少年编程能力等级》标准发布,年底前将在部分地区落地青少年编程能力等级…

Python 是否是下一个 PHP?为什么?
前几天和一个看好 Python 的 Rails 开发者聊天,他看好 Python 的原因就是 PHP 统治今天的网络应用开发。而 Python 很像下一个 PHP 。 『下一个 PHP』如何定义?是指流行程度么?如果是的话,我觉得 Python 不会像 PHP 那样流行。根本…

正确使用STL-MAP中Erase函数
一切尽在代码中。 #include <iostream> #include <map> #include <string> using namespace std ;int main(void) { map<int, string> m ;m.insert(pair<int, string>(1, "abc")) ;m.insert(pair<int, string>(2, "def&qu…

学完UI设计可以从事哪些工作
最近有很多同学都会问到一个问题,就是学完UI设计可以从事哪些工作?对于正在学习UI设计的同学和已经学完UI设计的同学们,可以来看看下面文章的详细介绍就知道了。 学完UI设计可以从事哪些工作? 一、交互设计师。 学习UI设计之后就可以做交互设计师了&am…

刻意练习:Python基础 -- Task08. 异常处理
背景 我们准备利用17天时间,将 “Python基础的刻意练习” 分为如下任务: Task01:变量、运算符与数据类型(1day)Task02:条件与循环(1day)Task03:列表与元组(…
Winform 控件自适应 JSP 入门登录案例
明儿在放,先睡转载于:https://www.cnblogs.com/javabin/archive/2011/09/26/2192402.html

MyEclipse对Struts2配置文件较检异常 Invalid result location value/parameter
有时在编写struts.xml时会报错,但是找不出有什么她方有问题。也能正常运行 MyEclipse有地方去struts的xml进行了验证,经查找把这里 的build去掉就可以了 本文转自lpxxn博客园博客,原文链接:http://www.cnblogs.com/li-peng/p/3791…
学Python有哪些优势
Python在人工智能领域应用是比较广泛的,近几年,越来越多的人对Python技术比较感兴趣,想要学习,那么具体学Python有哪些优势呢?我们来看看下面的详细介绍就知道了。 学Python有哪些优势? 1.Python很受欢迎 流行程度似乎不是衡量价…
MongoDB 正则表达式
阅读目录 示例不区分大小写数组使用正则表达式正则中包含变量回到顶部示例 MongoDB 使用 $regex 操作符来设置匹配字符串的正则表达式。 > db.col.find() { "_id" : ObjectId("56c6bbef64799370c0ef358a"), "x" : "hello world", &…
刻意练习:Python基础 -- Task09. else 与 with 语句
背景 我们准备利用17天时间,将 “Python基础的刻意练习” 分为如下任务: Task01:变量、运算符与数据类型(1day)Task02:条件与循环(1day)Task03:列表与元组(…

Java学习必不可少的网站,快收藏起来
java技术在IT互联网行业的发展前景一直在提升,越来越多的人都在学习java技术,今天小编来给大家提供一些学习Java的网站集合,希望能够帮助到正在学习java技术的同学。 Java学习必不可少的网站,快收藏起来! 1. Stackoverflow Stacko…
刻意练习:Python基础 -- Task11. 魔法方法
背景 我们准备利用17天时间,将 “Python基础的刻意练习” 分为如下任务: Task01:变量、运算符与数据类型(1day)Task02:条件与循环(1day)Task03:列表与元组(…
Oracle中的MERGE语句
转自http://blog.chinaunix.net/space.php?uid16981447&doblog&cuid430716做了简单的格式整理,加入了一点点原创的东西。Oracle9i引入了MERGE命令,你能够在一个SQL语句中对一个表同时执行inserts和updates操作. MERGE命令从一个或多个数据源中选择行来upda…
C#从数据库导出数据[excel]
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Data;using MySql.Data.MySqlClient;using Microsoft.Office.Interop.Excel;using Excel Microsoft.Office.Interop.Excel; //使用命名空间别名using System.Reflection; …

UI设计培训中的扁平化理念
本文是为正在学习UI设计的同学们整理的一份资料,主要讲的是UI设计培训中的扁平化理念,扁平化的设计是抛弃一切装饰的设计,扁平化设计使得用户操作起来更加简洁、高效和舒适。简洁大方的交互界面设计自然能够引导用户,并且在短时间…
刻意练习:Python基础 -- Task12. 模块
背景 我们准备利用17天时间,将 “Python基础的刻意练习” 分为如下任务: Task01:变量、运算符与数据类型(1day)Task02:条件与循环(1day)Task03:列表与元组(…
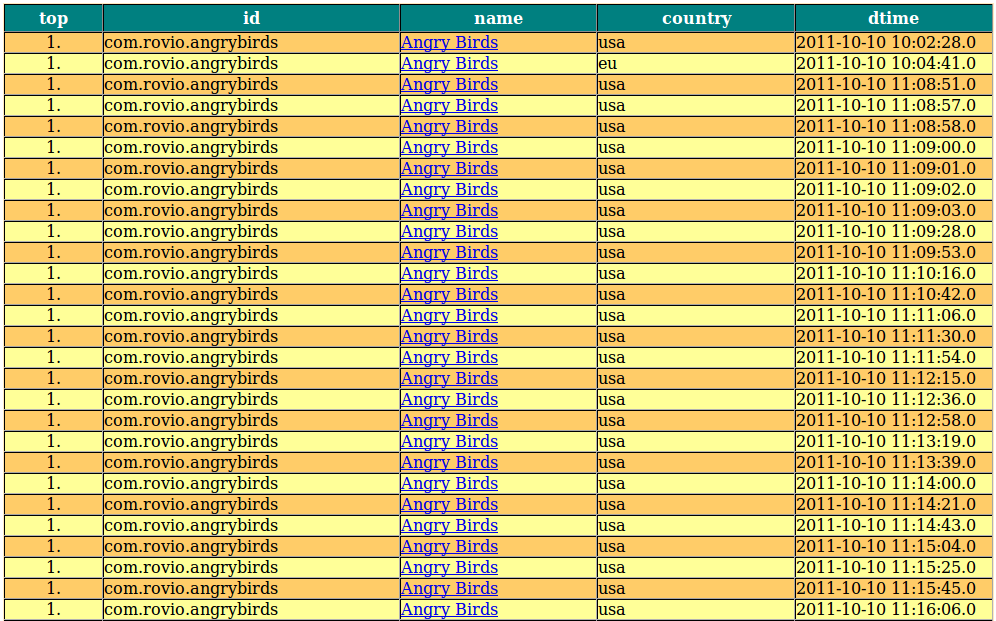
Linux JSP连接MySQL数据库
Linux(Ubuntu平台)JSP通过JDBC连接MySQL数据库,与Windows平台类似,步骤如下: 下载 jdbc: mysql-connector-java-5.1.18.tar.gz 解压 jdbc: tar -zxvf mysql-connector-java-5.1.18.tar.gz 配置 …
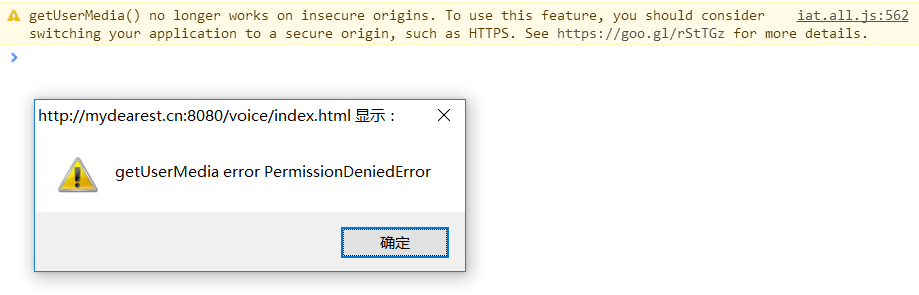
h5 getUserMedia error PermissionDeniedError
HTML5 在使用非 localhost 地址访问时打开摄像头失败 。报getUserMedia error PermissionDeniedError,火狐下是可以正常调取的。 需要https: 火狐: 转载于:https://www.cnblogs.com/cosyer/p/7646672.html

女生零基础学软件测试难不难
软件测试属于一门IT技术编程语言,很多人都觉得IT技术都是男性比较多,按照目前的行业数据来看,确实是男性居多,但最近几年,女性程序猿也越来越多,其中就有软件测试这个岗位,下面具体来看看女生零…

技术图文:NumPy 的简单入门教程
背景 这段时间,LSGO软件技术团队正在组织 “机器学习实战刻意练习”活动,这个活动是“Python基础刻意练习”活动的升级,是对学员们技术的更深层次的打磨。在用 Python 写各类机器学习算法时,我们经常会用到 NumPy库,故…
Android常见错误
1、Unable to resolve target android-2 安装低版本的api,再default.properties 这个文件中把targetandroid-2 改成 targetandroid-7终于就没有问题了。 2、Invalid start tag LinearLayout main.xml放错文件夹了,应该在\res\layout下。 3、INSTALL_FAIL…

【开发】简易教程
本文档将带你一步步创建完成一个微信小程序,并可以在手机上体验该小程序的实际效果。这个小程序的首页将会显示欢迎语以及当前用户的微信头像,点击头像,可以在新开的页面中查看当前小程序的启动日志。下载源码 1. 获取微信小程序的 AppID 登录…

Python未来的发展趋势怎么样
Python未来的发展趋势怎么样?最近很多人都在学习Python技术,但是在学习的过程中,还是比较担心Python是否有发展前景这个问题,我们来看看下面的详细解析。 Python未来的发展趋势怎么样? 一、从事Python的待遇高。 由于Python语言的应用领域很…
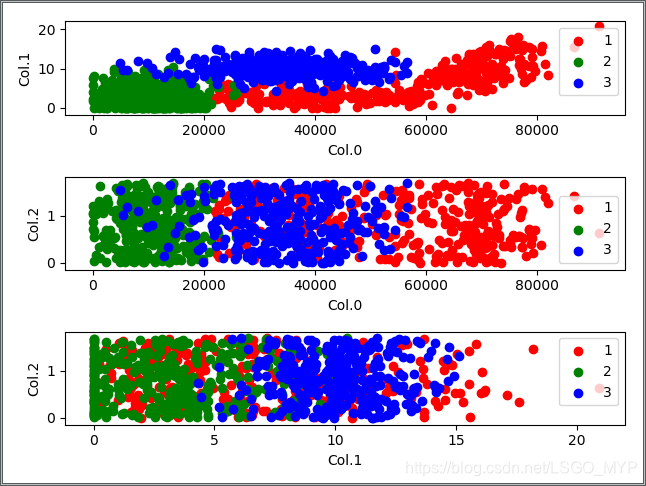
刻意练习:机器学习实战 -- Task01. K邻近算法
背景 这是我们为拥有 Python 基础的同学推出的精进技能的“机器学习实战” 刻意练习活动,这也是我们本学期推出的第三次活动了。 我们准备利用8周时间,夯实机器学习常用算法,完成以下任务: 分类问题:K邻近算法分类问…
RIFF格式声音文件的实现(转)
摘要:本文简述RIFF格式声音文件的构成,通过调用多媒体文件I/O的三个重要函数及WAVEFormatX结构数据的使用方法来实例阐述RIFF格式声音文件的实现过程。 关键词:RIFF[资源交换文件]格式 函数 结构数据 声音是多媒体的一个重要组成部份,在应用程…

使用PermissionsDispatcher轻松解决Android权限问题
之前也处理过6.0后的权限问题,直接处理很是麻烦。这次在github上搜到了关于权限星数最多的PermissionsDispatcher这个库,几个注释完美解决权限问题。 第一步 添加各种注释 1.RuntimePermissions 注释在需要权限的Activity和Fragment RuntimePermissions …

什么人适合学习web前端?怎样学好web前端开发?
web前端在IT互联网行业的发展前景是非常可观的,越来越多的人都在学习web前端技术,那么什么人适合学习web前端?怎样学好web前端开发?相信大家都想了解这些问题,我们来看看下面的详细介绍。 什么人适合学习web前端?怎样学好web前端开发? 一…