刻意练习:机器学习实战 -- Task01. K邻近算法
背景
这是我们为拥有 Python 基础的同学推出的精进技能的“机器学习实战” 刻意练习活动,这也是我们本学期推出的第三次活动了。
我们准备利用8周时间,夯实机器学习常用算法,完成以下任务:
- 分类问题:K邻近算法
- 分类问题:决策树
- 分类问题:朴素贝叶斯
- 分类问题:逻辑回归
- 分类问题:支持向量机
- 分类问题:AdaBoost
- 回归问题:线性回归、岭回归、套索方法、逐步回归等
- 回归问题:树回归
- 聚类问题:K均值聚类
- 相关问题:Apriori
- 相关问题:FP-Growth
- 简化数据:PCA主成分分析
- 简化数据:SVD奇异值分解
本次任务的核心是熟悉K邻近算法的原理,并实现《机器学习实战》这本书给出的两个案例。
算法原理
KNN 算法采用测量不同特征之间的距离方法进行分类,通俗的讲就是:给定一个样本数据集,并且样本集中每个数据都存在标签,即我们知道样本集中每个数据与所属分类的对应关系。对新输入没有标签的实例,在训练数据集中找到与该实例最邻近的 k 个实例,这 k 个实例的多数属于某个类,就把该输入实例分为这个类。
对于每一个在数据集中的数据点:计算目标的数据点(需要分类的数据点)与该数据点的距离将距离排序:从小到大选取前 K 个最短距离选取这 K 个中最多的分类类别返回该类别来作为目标数据点的预测值
项目案例1:优化约会网站的配对效果
项目概述
海伦使用约会网站寻找约会对象。经过一段时间之后,她发现曾交往过三种类型的人:
- 1:不喜欢的人
- 2:魅力一般的人
- 3:极具魅力的人
她希望:
- 不喜欢的人则直接排除掉
- 工作日与魅力一般的人约会
- 周末与极具魅力的人约会
现在她收集到了一些约会网站未曾记录的数据信息,这更有助于匹配对象的归类。
开发流程
Step1:收集数据
此案例书中提供了文本文件。
海伦把这些约会对象的数据存放在文本文件 datingTestSet2.txt 中,总共有 1000 行。海伦约会的对象主要包含以下 3 种特征:
Col1:每年获得的飞行常客里程数Col2:玩视频游戏所耗时间百分比Col3:每周消费的冰淇淋公升数
文本文件数据格式如下:
40920 8.326976 0.953952 3
14488 7.153469 1.673904 2
26052 1.441871 0.805124 1
75136 13.147394 0.428964 1
38344 1.669788 0.134296 1
Step2:准备数据
使用 Python 解析文本文件。将文本记录转换为 NumPy 的解析程序如下所示:
import numpy as npdef file2matrix(filename):"""Desc:导入训练数据parameters:filename: 数据文件路径return:数据矩阵 returnMat 和对应的类别 classLabelVector"""fr = open(filename)# 获得文件中的数据行的行数lines = fr.readlines()numberOfLines = len(lines) # type: int# 生成对应的空矩阵# 例如:zeros(2,3)就是生成一个 2*3的矩阵,各个位置上全是 0returnMat = np.zeros((numberOfLines, 3)) # prepare matrix to returnclassLabelVector = [] # prepare labels returnindex = 0for line in lines:# str.strip([chars]) --返回已移除字符串头尾指定字符所生成的新字符串line = line.strip()# 以 '\t' 切割字符串listFromLine = line.split('\t')# 每列的属性数据returnMat[index, :] = listFromLine[0:3]# 每列的类别数据,就是 label 标签数据classLabelVector.append(int(listFromLine[-1]))index += 1# 返回数据矩阵returnMat和对应的类别classLabelVectorreturn returnMat, classLabelVector
Step3:分析数据
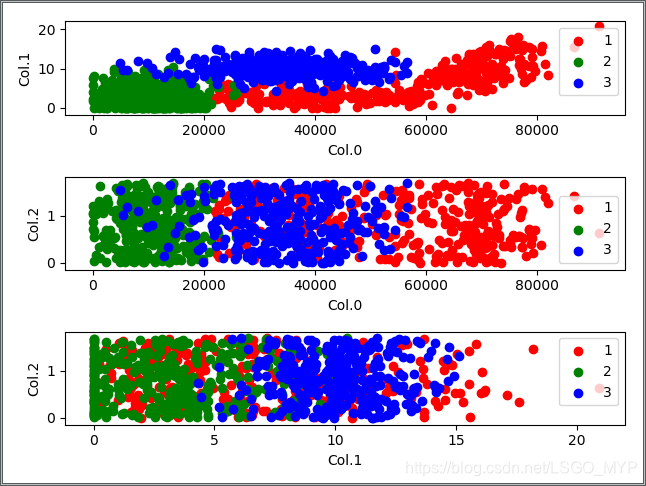
使用 Matplotlib 画二维散点图。
import matplotlib.pyplot as pltif __name__ == '__main__':datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')color = ['r', 'g', 'b']fig = plt.figure()ax = fig.add_subplot(311)for i in range(1, 4):index = np.where(np.array(datingLabels) == i)ax.scatter(datingDataMat[index, 0], datingDataMat[index, 1], c=color[i - 1], label=i)plt.xlabel('Col.0')plt.ylabel('Col.1')plt.legend()bx = fig.add_subplot(312)for i in range(1, 4):index = np.where(np.array(datingLabels) == i)bx.scatter(datingDataMat[index, 0], datingDataMat[index, 2], c=color[i - 1], label=i)plt.xlabel('Col.0')plt.ylabel('Col.2')plt.legend()cx = fig.add_subplot(313)for i in range(1, 4):index = np.where(np.array(datingLabels) == i)cx.scatter(datingDataMat[index, 1], datingDataMat[index, 2], c=color[i - 1], label=i)plt.xlabel('Col.1')plt.ylabel('Col.2')plt.legend()plt.show()
图中清晰地标识了三个不同的样本分类区域,具有不同爱好的人其类别区域也不同。
归一化特征值,消除特征之间量级不同导致的影响。
def autoNorm(dataSet):"""Desc:归一化特征值,消除特征之间量级不同导致的影响parameter:dataSet: 数据集return:归一化后的数据集 normDataSet.ranges和minVals即最小值与范围,并没有用到归一化公式:Y = (X-Xmin)/(Xmax-Xmin)其中的 min 和 max 分别是数据集中的最小特征值和最大特征值。该函数可以自动将数字特征值转化为0到1的区间。"""# 计算每种属性的最大值、最小值、范围minVals = np.min(dataSet, axis=0)maxVals = np.max(dataSet, axis=0)# 极差ranges = maxVals - minValsm = dataSet.shape[0]# 生成与最小值之差组成的矩阵normDataSet = dataSet - np.tile(minVals, (m, 1))# 将最小值之差除以范围组成矩阵normDataSet = normDataSet / np.tile(ranges, (m, 1)) # element wise dividereturn normDataSet, ranges, minVals
Step4:训练算法
此步骤不适用于 k-近邻算法。因为测试数据每一次都要与全部的训练数据进行比较,所以这个过程是没有必要的。
import operatordef classify0(inX, dataSet, labels, k):dataSetSize = dataSet.shape[0]# 距离度量 度量公式为欧氏距离diffMat = np.tile(inX, (dataSetSize, 1)) - dataSetsqDiffMat = diffMat ** 2sqDistances = np.sum(sqDiffMat, axis=1)distances = sqDistances ** 0.5# 将距离排序:从小到大sortedDistIndicies = distances.argsort()# 选取前K个最短距离, 选取这K个中最多的分类类别classCount = {}for i in range(k):voteIlabel = labels[sortedDistIndicies[i]]classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)return sortedClassCount[0][0]
Step5:测试算法
计算错误率,使用海伦提供的部分数据作为测试样本。如果预测分类与实际类别不同,则标记为一个错误。
def datingClassTest():"""Desc:对约会网站的测试方法parameters:nonereturn:错误数"""# 设置测试数据的的一个比例hoRatio = 0.1 # 测试范围,一部分测试一部分作为样本# 从文件中加载数据datingDataMat, datingLabels = file2matrix('datingTestSet2.txt') # load data setfrom file# 归一化数据normMat, ranges, minVals = autoNorm(datingDataMat)# m 表示数据的行数,即矩阵的第一维m = normMat.shape[0]# 设置测试的样本数量, numTestVecs:m表示训练样本的数量numTestVecs = int(m * hoRatio)print('numTestVecs=', numTestVecs)errorCount = 0.0for i in range(numTestVecs):# 对数据测试classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)print("分类器返回结果: %d, 实际结果: %d" % (classifierResult, datingLabels[i]))if classifierResult != datingLabels[i]:errorCount += 1.0print("错误率: %f" % (errorCount / float(numTestVecs)))print(errorCount)
Step6:使用算法
产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
约会网站预测函数如下:
def classifyPerson():resultList = ['不喜欢的人', '魅力一般的人', '极具魅力的人']ffMiles = float(input("每年获得的飞行常客里程数?"))percentTats = float(input("玩视频游戏所耗时间百分比?"))iceCream = float(input("每周消费的冰淇淋公升数?"))datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')normMat, ranges, minVals = autoNorm(datingDataMat)inArr = np.array([ffMiles, percentTats, iceCream])intX = (inArr - minVals) / rangesclassifierResult = classify0(intX, normMat, datingLabels, 3)print("这个人属于: ", resultList[classifierResult - 1])
实际运行效果如下:
if __name__ == '__main__':classifyPerson()'''
每年获得的飞行常客里程数? 10000
玩视频游戏所耗时间百分比? 10
每周消费的冰淇淋公升数? 0.5
这个人属于: 魅力一般的人
'''
项目案例2:手写识别系统
项目概述
构造一个能识别数字 0 到 9 的基于 KNN 分类器的手写数字识别系统。
需要识别的数字是存储在文本文件中的具有相同的色彩和大小:宽高是 32 像素 * 32 像素的黑白图像。
开发流程
Step1:收集数据
本案例书中提供了文本文件。
目录 trainingDigits 中包含了大约 2000 个例子,每个例子内容如下图所示,每个数字大约有 200 个样本;目录 testDigits 中包含了大约 900 个测试数据。

Step2:准备数据
编写函数 img2vector(), 将图像文本数据转换为分类器使用的向量。
def img2vector(filename):returnVect = np.zeros((1, 1024))fr = open(filename)for i in range(32): # 32行lineStr = fr.readline()for j in range(32): # 32列returnVect[0, 32 * i + j] = int(lineStr[j])return returnVect
Step3:分析数据
在 Python 命令提示符中检查数据,确保它符合要求。
testVector = img2vector(r'./digits/trainingDigits/0_13.txt')
print(testVector[0, 0:32])
# [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
print(testVector[0, 32:64])
# [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
Step4:训练算法
此步骤不适用于 k-近邻算法。因为测试数据每一次都要与全部的训练数据进行比较,所以这个过程是没有必要的。
Step5:测试算法
计算错误率,编写函数使用提供的部分数据集作为测试样本,如果预测分类与实际类别不同,则标记为一个错误。
import osdef handwritingClassTest():# 1. 导入训练数据hwLabels = []trainingFileList = os.listdir(r'./digits/trainingDigits') # load the training setm = len(trainingFileList)trainingMat = np.zeros((m, 1024))# hwLabels存储0~9对应的index位置, trainingMat存放的每个位置对应的图片向量for i in range(m):fileNameStr = trainingFileList[i]fileStr = fileNameStr.split('.')[0] # take off .txtclassNumStr = int(fileStr.split('_')[0])hwLabels.append(classNumStr)# 将 32*32的矩阵->1*1024的矩阵trainingMat[i, :] = img2vector(r'./digits/trainingDigits/%s' % fileNameStr)# 2. 导入测试数据testFileList = os.listdir(r'./digits/testDigits') # iterate through the test seterrorCount = 0.0mTest = len(testFileList)for i in range(mTest):fileNameStr = testFileList[i]fileStr = fileNameStr.split('.')[0] # take off .txtclassNumStr = int(fileStr.split('_')[0])vectorUnderTest = img2vector(r'./digits/testDigits/%s' % fileNameStr)classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)print("分类器返回结果: %d, 实际结果: %d" % (classifierResult, classNumStr))if classifierResult != classNumStr:errorCount += 1.0print("分类错误数量: %d" % errorCount)print("分类错误率: %f" % (errorCount / float(mTest)))
Step6:使用算法
可以构造一个小的软件系统,从图像中提取数字,并完成数字识别,我们现实中使用的OCR,以及车牌识别都类似于这样的系统。
总结
到此为止 KNN 算法的两个案例就全部搞定了,这个算法看起来很简单,但参数 K 的选择,距离的选择都需要不断的配置和测试才能得到满意的效果。当然,KNN 算法的主要缺点是不提取训练数据的特征,测试实例需要与每个训练实例计算距离导致算法的执行速度很慢。为了提升搜索 K 个最邻近实例的速度,后面有了K-D Tree的结构,这些都不是这本书的重点了,我们主要是先掌握基本算法,有个武器能处理数据再说,等后面实际应用的时候再来考虑效率问题。好了,就这样吧!See You!
参考文献
- https://github.com/apachecn/AiLearning/tree/master/docs/ml
- https://blog.csdn.net/c406495762/column/info/16415
- https://www.bilibili.com/video/av36993857
- https://space.bilibili.com/97678687/channel/detail?cid=22486
- https://space.bilibili.com/97678687/channel/detail?cid=13045
往期活动
LSGO软件技术团队会定期开展提升编程技能的刻意练习活动,希望大家能够参与进来一起刻意练习,一起学习进步!
- Python基础刻意练习活动即将开启,你参加吗?
- Task01:变量、运算符与数据类型
- Task02:条件与循环
- Task03:列表与元组
- Task04:字符串与序列
- Task05:函数与Lambda表达式
- Task06:字典与集合
- Task07:文件与文件系统
- Task08:异常处理
- Task09:else 与 with 语句(1day)
- Task10:类与对象
- Task11:魔法方法
- Task12:模块
相关文章:

RIFF格式声音文件的实现(转)
摘要:本文简述RIFF格式声音文件的构成,通过调用多媒体文件I/O的三个重要函数及WAVEFormatX结构数据的使用方法来实例阐述RIFF格式声音文件的实现过程。 关键词:RIFF[资源交换文件]格式 函数 结构数据 声音是多媒体的一个重要组成部份,在应用程…

使用PermissionsDispatcher轻松解决Android权限问题
之前也处理过6.0后的权限问题,直接处理很是麻烦。这次在github上搜到了关于权限星数最多的PermissionsDispatcher这个库,几个注释完美解决权限问题。 第一步 添加各种注释 1.RuntimePermissions 注释在需要权限的Activity和Fragment RuntimePermissions …

什么人适合学习web前端?怎样学好web前端开发?
web前端在IT互联网行业的发展前景是非常可观的,越来越多的人都在学习web前端技术,那么什么人适合学习web前端?怎样学好web前端开发?相信大家都想了解这些问题,我们来看看下面的详细介绍。 什么人适合学习web前端?怎样学好web前端开发? 一…
浏览器缓存导致FLASH资源更新问题的解决方案
在网上搜浏览器缓存问题时,遇上了很多问题。一是不知道应该用何种关键字搜索,二是一搜出来,就全是讲的是如何禁用浏览器缓存的方案。 作为大型点的FLASH WEBGAME来说,不缓存显然是不行的。总体上来说,我们要想达到的目…
技术图文:Python的属性装饰器详解
背景 我们在以前的一篇图文 Python基础 – Task10. 类与对象 中介绍过利用property()方法既能保护类的封装特性,又能让开发者可以使用“对象.属性”的方式操作类属性。 class property([fget[, fset[, fdel[, doc]]]])用于在新式类中返回属性值。 fget – 获取属…
又一个强大的PHP5.3依赖注入容器
简单的服务容器 一个简单的 php 5.3 依赖注入容器。 项目地址:https://github.com/godruoyi/easy-container Why 目前比较流行的 PHP 容器: PimpleLaravel Container其他依赖注入容器Pimple 是一个简单优秀的 php 5.3 容器,也是目前用得最多的…

软件测试培训:如何搭建测试环境
如何搭建测试环境?这是很多测试人员都需要了解的,测试是每个产品上线前必备的一个检验,不管是什么产品,做好有效的测试是对产品质量的一个负责,软件测试环境要考虑的就是软件在什么软硬件下能正常运行,什么环境下不能…

技术图文:如何爬取一个地区的气象数据(上)?
背景 架空线路主要指架空明线,架设在地面之上,是用绝缘子将输电导线固定在直立于地面的杆塔上以传输电能的输电线路。架设及维修比较方便,成本较低,但容易受到气象和环境(如大风、雷击、污秽、冰雪等)的影…
C#按关闭按钮实现最小化,按ESC才关闭的实现【含系统消息大全】
protected override void WndProc(ref Message m) { const int WM_SYSCOMMAND 0x0112; const int SC_CLOSE 0xF060; if (m.Msg WM_SYSCOMMAND && (int)m.WParam SC_CLOSE) { // 屏蔽传入的消息事件 …
眠眠interview Question
1. Wkwebkit在异步回调 如何像webview的回调 一样在主线程回调。可以使用runloop 解决么? dispatch get main queue http://www.jianshu.com/p/a2fc399075e0 转载于:https://www.cnblogs.com/tufei7/p/7657617.html

哪些人适合参加软件测试培训
软件测试是现在很多企业需求都非常大的一个岗位,只要是互联网行业基本都是有需求的,那么想要学习软件测试,哪些人适合参加软件测试培训呢?来看看下面的详细介绍。 哪些人适合参加软件测试培训? 想从零开始进入软件技术行业 软件测试的优势是…
从iso镜像升级ubuntu
步骤: 1.从网上下载Alternate版本的ISO镜像 2.加载ubuntu镜像 # mount -t iso9660 -o loop ubuntu-11.10-alternate-i386.iso /mnt/cdrom/3.进入/mnt/cdrom/ 运行cdromupgrade 程序 # cd /mnt/cdrom/ # ./cdromupgrade转载于:https://www.cnblogs.com/dudp/archive…
技术图文:如何爬取一个地区的气象数据(下)?
背景 架空线路常见的故障有:风偏闪络故障、雷击跳闸故障、雷击断股故障、线路覆冰故障、线路污闪故障、线路外力破坏故障、线路鸟害故障等等。从这些故障中,我们可以看出天气对线路的安全运行起到非常重要的作用。 在上一篇图文 如何爬取一个地区的气象…
Android :landscape||portrait 切换
可在AndroidManifest.xml里面配置屏幕发现。 在<Activity>中加入这一行android:screenOrientation"landscape/portrait " android中每次屏幕的切换动会重启Activity(可以在Activity销毁前保存当前活动的状态,在Activity再次Create的时候…

web前端开发培训完就业前景怎么样
很多人都在学习web前端技术,认为学好这一项编程技术,找工作是非常稳定的,那么到底web前端开发培训完就业前景怎么样呢?来看看下面的详细介绍就知道了。 web前端开发培训完就业前景怎么样? web前端薪资待遇 从图中我们能够看到web前端从业者…
技术图文:如何改进算法的运行效率?
背景 前段时间,一位好友发给我如下的文件: 每个CSV文件中的数据由三个属性组成,第一个属性为ID,第二个属性为X坐标,第三个属性为Y坐标。由于是二维数据,可以绘制出每个文件的散点图,把这些散点…
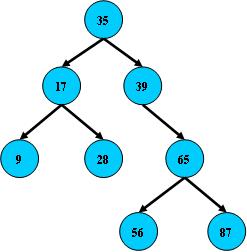
B树,B+树,B-树和B*树
B树 即二叉搜索树: 1.所有非叶子结点至多拥有两个儿子(Left和Right); 2.所有结点存储一个关键字; 3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树; 如: …
JS对象直接量,数组直接量和函数直接量
对象直接量创建一个对象: var obj {x:[1,2],y:23}; 代码跟下面是一样的。 var objnew Object(); obj.xnew Array(1,2); obj.y23; 测试:for(var i in obj) alert(obj[i]); 函数直接量:它是一个表达式而不是语句。 (function(){})() 如下例&am…

学习Java编程培训的书籍有哪些
学习java技术除了线上线下的培训学习,书籍的知识也是非常重要的,今天小编为大家整理的就是学习Java的一些书籍,Java书籍是程序员学习提升技能的重要学习渠道,通过书籍Java程序员可以学习当前流行、重要的相关技能。下面我们一起来…
Datawhale组队学习:数据结构与算法课程任务
背景 Datawhale 是国内很有名的一个开源学习组织。这个组织将渴望改变的学习者以及一群有能力有想法的青年人集结在一起,营造出一种互促高效的学习环境,一起为开源学习付出努力。 Datawhale 近期将推出三门课程的组队学习。我先将 数据结构与算法&…
live555学习笔记2-基础类
二 基础类 讲几个重要的基础类: BasicUsageEnvironment和UsageEnvironment中的类都是用于整个系统的基础功能类.比如UsageEnvironment代表了整个系统运行的环境,它提供了错误记录和错误报告的功能,无论哪一个类要输出错误&#x…

自己写的小工具集合
2019独角兽企业重金招聘Python工程师标准>>> 文件夹大小查看工具 用于查看文件夹下每个子文件和子文件夹的大小.以前想统计文件夹大小,只能点右键看属性,而且只能看到文总大小。这个小工具可以通过右键启动,而且能查看文件夹下所有文件和文件夹的大小. 以前用过类似…

哪些人适合学软件测试呢
软件测试是现在很多企业的一个刚需岗位,所以软件测试的发展前景是非常好的,想要了解哪些人适合学软件测试呢?来看看下面的详细介绍就知道了。 哪些人适合学软件测试呢? 1.无编程基础 测试的代码量仅为20%左右,无论是文科生还是非计算机专业…
javabean和EJB的区别
Java Bean 是可复用的组件,对Java Bean并没有严格的规范,理论上讲,任何一个Java类都可以是一个Bean。但通常情况下,由于Java Bean是被容器所创建(如Tomcat)的,所以Java Bean应具有一个无参的构造器,另外&am…
Datawhale组队学习:初级算法梳理课程任务
背景 Datawhale 是国内很有名的一个开源学习组织。这个组织将渴望改变的学习者以及一群有能力有想法的青年人集结在一起,营造出一种互促高效的学习环境,一起为开源学习付出努力。 Datawhale 近期将推出三门课程的组队学习。我先将 初级算法梳理 的任务…
CSS将长文字换行的方法 (转)
大家都知道连续的英文或数字能是容器被撑大,不能根据容器的大小自动换行,下面是 CSS如何将他们换行的方法! 对于div 1.(IE浏览器)white-space:normal; word-break:break-all;这里前者是遵循标准。 #wrap{white-space:n…

学Java的软件哪些比较好用
很多java程序猿在工作的时候都会用一些辅助工具,辅助工具可以很好的帮助程序猿高效率的完成工作,那么具体学Java的软件哪些比较好用呢?来看看下面的详细介绍。 学Java的软件哪些比较好用? 1. Eclipse Eclipse做为一款开发源代码的Java扩展性开发平台&a…
DataTable的Compute功能详解
在为筛选器创建表达式时,用单引号将字符串括起来:"LastName Jones"下面的字符是特殊字符,如下面所解释的,如果它们用于列名称中,就必须进行转义:\n (newline)\t (tab)\r (carriage return)~()#\…

Datawhale第九期组队学习计划
Datawhale 组队学习 第九期Datawhale组队学习计划马上就要开始啦! 这次共组织三个组队学习,涵盖了编程、机器学习理论以及动手实践的内容,大家可以按照需要选择参加。 数据结构与算法(上) 内容设计:光城…
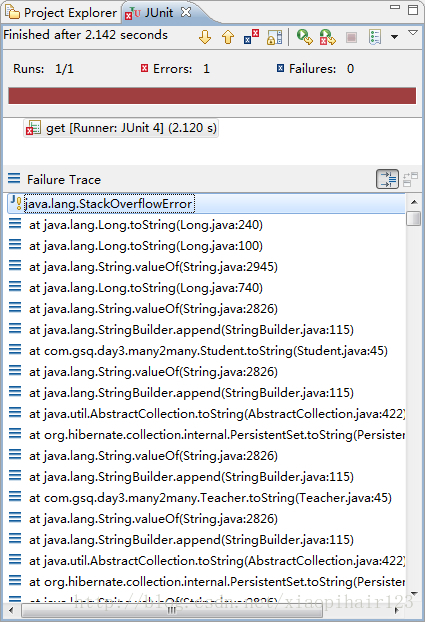
Hibernate获取数据java.lang.StackOverflowError
原因:因为在重写toString()方法时,把关联的属性也放入到toString方法中了,去掉就可以了。 如:重写的toString方法中不能有关联关系IDCard属性idCard public class Person {private Integer id;private String name;private IDCard…